Ich möchte Ihnen meine ersten erfolgreichen Erfahrungen mit der Wiederherstellung der vollständigen Funktionalität der Postgres-Datenbank mitteilen. Ich habe Postgres DBMS vor einem halben Jahr getroffen, bevor ich überhaupt keine Erfahrung in der Datenbankadministration hatte.

Ich arbeite als Semi-DevOps-Ingenieur in einem großen IT-Unternehmen. Unser Unternehmen entwickelt Software für hochgeladene Dienste, aber ich bin für die Leistung, Wartung und Bereitstellung verantwortlich. Sie haben eine Standardaufgabe für mich festgelegt: Aktualisieren Sie die Anwendung auf einem Server. Die Anwendung ist in Django geschrieben, während des Upgrades werden Migrationen durchgeführt (Änderung der Datenbankstruktur) und vor diesem Vorgang wird der vollständige Datenbankspeicherauszug durch das Standardprogramm pg_dump für alle Fälle entfernt.
Beim Entfernen des Dumps ist ein unerwarteter Fehler aufgetreten (Postgres-Version 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
Der Fehler
"Ungültige Seite im Block" weist auf Probleme auf Dateisystemebene hin, die sehr schlimm sind. In verschiedenen Foren wurde vorgeschlagen,
FULL VACUUM mit der Option
zero_damaged_pages zu
erstellen , um dieses Problem zu lösen. Nun, Popprobeum ...
Vorbereitung der Wiederherstellung
ACHTUNG! Sichern Sie Postgres unbedingt, bevor Sie versuchen, die Datenbank wiederherzustellen. Wenn Sie über eine virtuelle Maschine verfügen, stoppen Sie die Datenbank und erstellen Sie einen Snapshot. Wenn es nicht möglich ist, einen Schnappschuss zu erstellen, stoppen Sie die Datenbank und kopieren Sie den Inhalt des Postgres-Verzeichnisses (einschließlich der Wal-Dateien) an einen sicheren Ort. Die Hauptsache in unserem Geschäft ist es, die Dinge nicht noch schlimmer zu machen. Lesen Sie
dies .
Da die Datenbank für mich insgesamt funktionierte, beschränkte ich mich auf den üblichen Datenbankspeicherauszug, schloss jedoch die Tabelle mit beschädigten Daten aus (Option
-T, --exclude-table = TABLE in pg_dump).
Der Server war physisch, es war unmöglich, einen Schnappschuss zu machen. Die Sicherung wird entfernt, fahren Sie fort.
Dateisystemprüfung
Bevor Sie versuchen, die Datenbank wiederherzustellen, müssen Sie sicherstellen, dass im Dateisystem selbst alles in Ordnung ist. Und korrigieren Sie sie im Fehlerfall, sonst können Sie es nur noch schlimmer machen.
In meinem Fall wurde das Dateisystem mit der Datenbank in
"/ srv" eingebunden und der Typ war ext4.
Wir stoppen die Datenbank:
systemctl stop postgresql@9.5-main.service und überprüfen, ob das Dateisystem von niemandem verwendet wird und ob es mit dem
Befehl lsof ausgehängt werden kann:
lsof + D / srvIch musste die Redis-Datenbank immer noch stoppen, da sie auch
"/ srv" verwendete . Als nächstes habe ich
/ srv (umount)
abgehängt .
Das Überprüfen des Dateisystems wurde mit dem Dienstprogramm
e2fsck mit der Option -f durchgeführt (
Überprüfung erzwingen , auch wenn das Dateisystem als sauber markiert ist ):
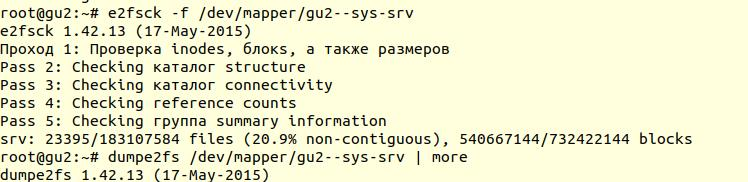
Anschließend können Sie mit dem Dienstprogramm
dumpe2fs (
sudo dumpe2fs / dev / mapper / gu2 - sys-srv | grep checked )
überprüfen , ob die Prüfung tatsächlich durchgeführt wurde:
 e2fsck
e2fsck gibt an, dass auf der Ebene des ext4-Dateisystems keine Probleme
aufgetreten sind. Sie können also weiterhin versuchen, die Datenbank wiederherzustellen, oder stattdessen zu
Vakuum zurückkehren (natürlich müssen Sie das Dateisystem wieder einbinden und die Datenbank starten).
Wenn Ihr Server physisch ist, überprüfen Sie
unbedingt den Status der Festplatten (über
smartctl -a / dev / XXX ) oder des RAID-Controllers, um sicherzustellen, dass sich das Problem nicht auf der Hardwareebene befindet. In meinem Fall stellte sich heraus, dass das RAID "iron" war, und ich bat den lokalen Administrator, den Status des RAID zu überprüfen (der Server war mehrere hundert Kilometer von mir entfernt). Er sagte, dass es keine Fehler gab, was bedeutet, dass wir definitiv mit der Restaurierung beginnen können.
Versuch 1: zero_damaged_pages
Wir stellen über das psql-Konto mit Superuser-Rechten eine Verbindung zur Datenbank her. Wir brauchen genau den Superuser, weil Nur er kann die Option
zero_damaged_pages ändern. In meinem Fall ist dies postgres:
psql -h 127.0.0.1 -U postgres -s [Datenbankname]Die Option
zero_damaged_pages wird benötigt, um Lesefehler (von der postgrespro-Website) zu ignorieren:
Wenn ein beschädigter Seitentitel erkannt wird, meldet Postgres Pro normalerweise einen Fehler und bricht die aktuelle Transaktion ab. Wenn der Parameter zero_damaged_pages aktiviert ist, gibt das System stattdessen eine Warnung aus, löscht die beschädigte Seite im Speicher und setzt die Verarbeitung fort. Dieses Verhalten zerstört Daten, nämlich alle Zeilen in der beschädigten Seite.
Aktivieren Sie die Option und versuchen Sie, vollständige Vakuumtabellen zu erstellen:
VACUUM FULL VERBOSE
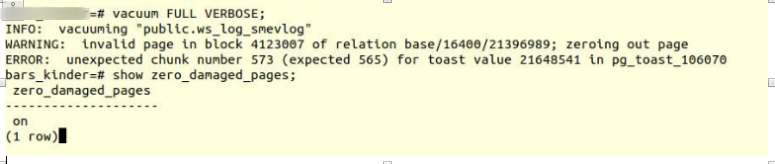
Leider gescheitert.
Wir sind auf einen ähnlichen Fehler gestoßen:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast - der Mechanismus zum Speichern von "langen Daten" in Postgres, wenn diese nicht auf dieselbe Seite passen (standardmäßig 8 KB).
Versuch 2: Neu indizieren
Der erste Google-Tipp hat nicht geholfen. Nach ein paar Minuten der Suche fand ich einen zweiten Tipp -
eine beschädigte Tabelle neu
indizieren zu lassen. Ich habe diesen Rat an vielen Stellen erhalten, aber er hat kein Vertrauen geweckt. Neu indizieren:
reindex table ws_log_smevlog
 Neuindizierung
Neuindizierung ohne Probleme abgeschlossen.
Dies half jedoch nicht,
VACUUM FULL stürzte mit einem ähnlichen Fehler ab. Da ich an Ausfälle gewöhnt war, suchte ich im Internet weiter nach Rat und stieß auf einen recht interessanten
Artikel .
Versuch 3: SELECT, LIMIT, OFFSET
In dem obigen Artikel wurde vorgeschlagen, die Tabelle zeilenweise zu betrachten und die problematischen Daten zu löschen. Zu Beginn war es notwendig, alle Zeilen zu betrachten:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
In meinem Fall enthielt die Tabelle
1.628.991 Zeilen! In guter Weise war es notwendig, die
Partitionierung der Daten zu gewährleisten , aber dies ist ein Thema für eine separate Diskussion. Es war Samstag, ich habe diesen Befehl in tmux ausgeführt und bin schlafen gegangen:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
Am Morgen beschloss ich zu überprüfen, wie es lief. Zu meiner Überraschung stellte ich fest, dass in 2 Stunden nur 2% der Daten gescannt wurden! Ich wollte nicht 50 Tage warten. Ein weiterer völliger Misserfolg.
Aber ich habe nicht aufgegeben. Ich fragte mich, warum der Scan so lange dauerte. Aus der Dokumentation (wieder auf postgrespro) habe ich herausgefunden:
OFFSET gibt an, dass die angegebene Anzahl von Zeilen übersprungen werden soll, bevor mit der Erzeugung von Zeilen begonnen wird.
Wenn sowohl OFFSET als auch LIMIT angegeben sind, überspringt das System zuerst OFFSET-Zeilen und beginnt dann, Zeilen zu zählen, um LIMIT zu begrenzen.
Bei Verwendung von LIMIT ist es auch wichtig, die ORDER BY-Klausel zu verwenden, damit die Ergebniszeilen in einer bestimmten Reihenfolge zurückgegeben werden. Andernfalls werden unvorhersehbare Teilmengen von Zeichenfolgen zurückgegeben.
Offensichtlich war der obige Befehl fehlerhaft: Erstens gab es keine
Reihenfolge , das Ergebnis konnte fehlerhaft sein. Zweitens musste Postgres zuerst OFFSET-Zeilen scannen und überspringen, und mit einer Zunahme von
OFFSET würde die Leistung noch mehr sinken.
Versuch 4: Entfernen Sie den Speicherauszug in Textform
Außerdem kam mir eine scheinbar brillante Idee in den Sinn, den Dump in Textform zu entfernen und die letzte aufgezeichnete Zeile zu analysieren.
Aber zuerst schauen
wir uns die Tabellenstruktur von
ws_log_smevlog an :

In unserem Fall haben wir eine Spalte
„id“ , die einen eindeutigen Bezeichner (Zähler) für die Zeile enthält. Der Plan war:
- Wir fangen an, den Dump in Textform (in Form von SQL-Befehlen) zu entfernen.
- Zu einem bestimmten Zeitpunkt wurde der Speicherauszug aufgrund eines Fehlers unterbrochen, die Textdatei wurde jedoch weiterhin auf der Festplatte gespeichert
- Wir schauen uns das Ende der Textdatei an und finden dabei den Identifier (id) der letzten Zeile, die erfolgreich aufgenommen wurde
Ich habe begonnen, den Dump in Textform zu entfernen:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
Der Dump Dump wurde wie erwartet mit demselben Fehler unterbrochen:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Außerdem habe ich durch
tail auf das Ende des Dumps (
tail -5 ./my_dump.dump )
geschaut und festgestellt, dass der Dump auf der Leitung mit der ID
186 525 unterbrochen wurde. "Das Problem liegt also in der ID 186 526, es ist kaputt und muss gelöscht werden!", Dachte ich. Aber indem Sie eine Anfrage an die Datenbank stellen:
"
Wählen Sie * aus ws_log_smevlog, wobei id = 186529 ". Es stellte sich heraus, dass mit dieser Zeile alles in Ordnung war. Zeilen mit den Indizes 186 530 - 186 540 funktionierten ebenfalls problemlos. Eine weitere „geniale Idee“ ist gescheitert. Später habe ich verstanden, warum dies passiert ist: Beim Löschen / Ändern von Daten aus der Tabelle werden diese nicht physisch gelöscht, sondern als "tote Tupel" markiert. Anschließend wird
automatisch ein Vakuum erzeugt, das diese Zeilen als gelöscht markiert und die erneute Verwendung dieser Zeilen ermöglicht. Wenn die Daten in der Tabelle geändert und das automatische Vakuum aktiviert werden, werden sie nicht nacheinander gespeichert.
Versuch 5: SELECT, FROM, WHERE id =
Misserfolge machen uns stärker. Du solltest niemals aufgeben, du musst bis zum Ende gehen und an dich und deine Fähigkeiten glauben. Aus diesem Grund habe ich mich für eine weitere Option entschieden: Zeigen Sie alle Einträge in der Datenbank einzeln an. Wenn wir die Struktur meiner Tabelle kennen (siehe oben), haben wir ein eindeutiges ID-Feld (Primärschlüssel). In der Tabelle haben wir 1.628.991 Zeilen und
id geht in Reihenfolge, was bedeutet, dass wir sie einfach einzeln durchlaufen können:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Wenn jemand nicht versteht, funktioniert der Befehl wie folgt: Er durchsucht die Tabelle zeilenweise und sendet stdout an
/ dev / null . Wenn der SELECT-Befehl jedoch fehlschlägt, wird der Fehlertext angezeigt (stderr wird an die Konsole gesendet) und eine Zeile mit dem Fehler ausgegeben (dank ||, der) bedeutet, dass select Probleme hatte (der Befehlsrückgabecode ist nicht 0)).
Ich hatte Glück, ich hatte Indizes auf dem
ID- Feld erstellt:

Das bedeutet, dass das Auffinden der Zeile mit der gewünschten ID nicht viel Zeit in Anspruch nehmen sollte. Theoretisch sollte es funktionieren. Führen Sie den Befehl in
tmux aus und schlafen Sie ein.
Am Morgen stellte ich fest, dass ungefähr 90.000 Datensätze angezeigt wurden, was etwas mehr als 5% entspricht. Hervorragendes Ergebnis im Vergleich zur vorherigen Methode (2%)! Aber ich wollte nicht 20 Tage warten ...
Versuch 6: SELECT, FROM, WHERE id> = und id <
Unter der Datenbank wurde dem Kunden ein ausgezeichneter Server zugewiesen:
Intel Xeon E5-2697 v2 mit zwei Prozessoren, an unserem Standort gab es bis zu 48 Threads! Die Serverauslastung war durchschnittlich, wir konnten problemlos ca. 20 Threads aufnehmen. RAM war auch genug: 384 Gigabyte!
Daher musste der Befehl parallelisiert werden:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Hier war es möglich, ein schönes und elegantes Skript zu schreiben, aber ich habe den schnellsten Weg für die Parallelisierung gewählt: Teilen Sie den Bereich 0-1628991 manuell in Intervalle von 100.000 Datensätzen auf und führen Sie 16 Befehle des Formulars separat aus:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Das ist aber noch nicht alles. Theoretisch erfordert das Herstellen einer Verbindung zu einer Datenbank auch einige Zeit und Systemressourcen. 1.628.991 zu verbinden war nicht sehr vernünftig, stimme zu. Extrahieren wir daher 1000 Zeilen in einer Verbindung anstelle von einer. Infolgedessen hat sich das Team in Folgendes verwandelt:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Öffne 16 Fenster in der tmux-Sitzung und führe die folgenden Befehle aus:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Einen Tag später bekam ich die ersten Ergebnisse! Nämlich (die Werte XXX und ZZZ wurden nicht beibehalten):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
Dies bedeutet, dass drei Zeilen einen Fehler enthalten. Die ID des ersten und zweiten Problemdatensatzes lag zwischen 829.000 und 830.000, die ID des dritten zwischen 146.000 und 147.000. Als Nächstes mussten wir nur den genauen ID-Wert der Problemdatensätze ermitteln. Durchsuchen Sie dazu unser Sortiment mit Problemaufzeichnungen in Schritt 1 und identifizieren Sie die ID:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Happy End
Wir haben die problematischen Linien gefunden. Wir gehen über psql in die Datenbank und versuchen, sie zu entfernen:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
Zu meiner Überraschung wurden die Einträge ohne Probleme gelöscht, auch ohne die Option
zero_damaged_pages .
Dann stellte ich eine Verbindung zur Datenbank her, machte
VACUUM FULL (ich glaube, es war nicht notwendig, dies zu tun) und entfernte schließlich erfolgreich die Sicherung mit
pg_dump . Der Dump war fehlerfrei! Das Problem wurde auf so blöde Weise gelöst. Der Freude waren keine Grenzen gesetzt, nach so vielen Misserfolgen gelang es uns, eine Lösung zu finden!
Danksagung und Schlussfolgerungen
Dies ist meine erste Erfahrung bei der Wiederherstellung einer echten Postgres-Datenbank. Ich werde mich noch lange an diese Erfahrung erinnern.
Abschließend möchte ich mich bei PostgresPro für die übersetzte Dokumentation ins Russische und für die
völlig kostenlosen Online-Kurse bedanken, die bei der Analyse des Problems sehr hilfreich waren.