Während der Arbeit an einem großen Projekt spart die Ausleihe von Modulen und schlüsselfertigen Lösungen anderer Entwickler eine enorme Menge an Zeit und Geld für Investoren. Eines der größten Repositories für solche Lösungen ist mit Abstand Github.
Es gibt einen kleinen Trick unter der Katze, den ich bei der Suche und Auswahl von Github-Lösungen verwende.
Stellen Sie sich die Aufgabe vor, ein großes
OSINT- System zu entwickeln. Nehmen wir an, wir müssen uns alle verfügbaren Lösungen auf github in diese Richtung ansehen. Wir verwenden die standardmäßige globale Github-Suche für das Schlüsselwort osint. Wir haben 1124 Repositories, die nach dem Ort der Schlüsselwortsuche (Code, Commits, Issuse usw.) und der Ausführungssprache filtern können. Und sortieren Sie nach verschiedenen Attributen (wie den meisten / wenigsten Starts, Gabeln usw.).
Die Entscheidung wird nach mehreren Kriterien getroffen: Funktionalität, Anzahl der Sterne, Projektunterstützung, Entwicklungssprache.
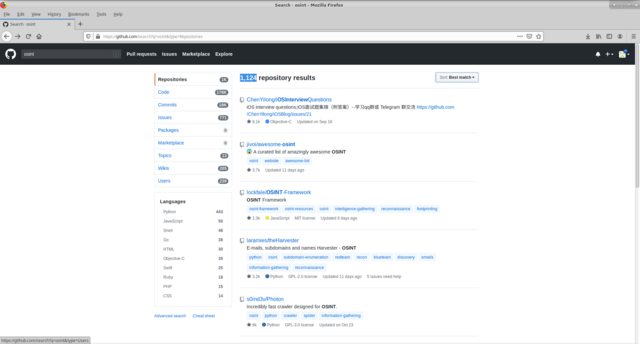
Die Entscheidungen, die mich interessierten, wurden in einer Tabelle zusammengefasst, in der die oben angegebenen Felder ausgefüllt wurden. Auf der Grundlage der Ergebnisse eines bestimmten Tests wurden entsprechende Notizen gemacht.
Der Nachteil dieser Ansicht scheint mir das Fehlen der Fähigkeit zu sein, gleichzeitig über mehrere Felder zu sortieren und zu filtern.
Mit
api_github und python3 skizzieren wir ein einfaches Skript, das ein CSV-Dokument mit für uns interessanten Feldern bildet.
Führen Sie das Skript aus
python3 git_repo_search.py osint
wir bekommen
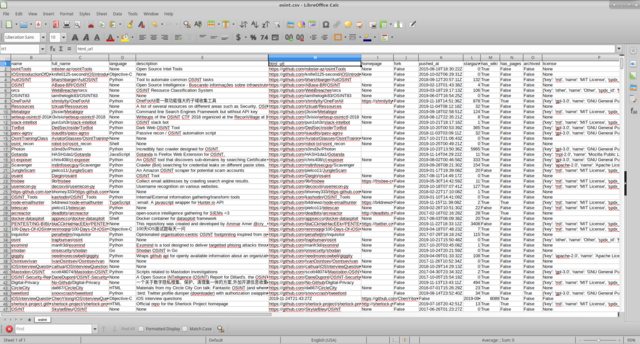
Es scheint mir, dass das Arbeiten mit Informationen bequemer ist, nachdem unnötige Spalten ausgeblendet wurden.
Code
hierIch hoffe, dass jemand nützlich ist.