Am Vorabend des Starts des Backend PHP Developer Kurses hatten wir eine traditionelle offene Stunde . Dieses Mal haben wir uns mit dem Serverless-Konzept vertraut gemacht, über die Implementierung in AWS gesprochen, die Funktionsweise, den Zusammenbau und den Start besprochen und einen einfachen PHP-TG-Bot auf der Basis von AWS Lambda erstellt.
Dozent - Alexander Pryakhin , CTO von Westwing Russland.

Ein kurzer Ausflug in die Geschichte

Wie sind wir zu einem solchen Leben gekommen, dass Serverless Computing auftauchte? Natürlich sahen sie nicht nur so aus, sondern wurden zu einer logischen Fortsetzung bestehender Virtualisierungstechnologien.

Was virtualisieren wir normalerweise? Zum Beispiel ein Prozessor. Sie können den Speicher auch virtualisieren, indem Sie bestimmte Speicherbereiche markieren und für einige Benutzer zugänglich und für andere nicht zugänglich machen. Sie können ein VPN-Netzwerk virtualisieren. Usw.

Virtualisierung ist gut, weil wir Ressourcen besser nutzen und die Produktivität steigern. Es gibt aber auch Nachteile, zum Beispiel gab es einmal Kompatibilitätsprobleme. Es gibt jedoch praktisch keine Architekturen, die mit modernen virtuellen Maschinen nicht kompatibel wären.
Das nächste Minus ist, dass wir eine zusätzliche Abstraktionsebene hinzufügen, einen Hypervisor hinzufügen, eine virtuelle Maschine selbst hinzufügen und natürlich etwas an Geschwindigkeit verlieren können. Etwas kompliziert und die Nutzung des Servers.
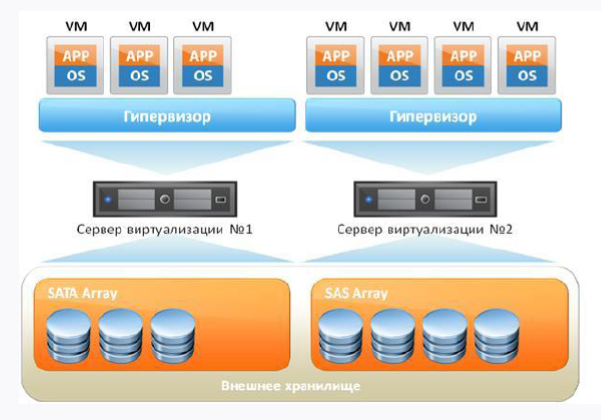
Wenn wir eine standardmäßige virtuelle Maschine mitnehmen, sieht diese ungefähr so aus:

Erstens haben wir einen Eisenserver und zweitens das Betriebssystem, auf dem sich unser Hypervisor drehen wird. Darüber hinaus drehen sich unsere virtuellen Maschinen, in denen sich ein Gastbetriebssystem, Bibliotheken und Anwendungen befinden. Wenn Sie logisch denken, sehen wir bei Vorhandensein des Gastbetriebssystems einen gewissen Overhead, da wir in der Tat zusätzliche Ressourcen ausgeben.
Wie kann ich das Overhead-Problem lösen? Ablehnen von virtuellen Maschinen und Hinzufügen eines Containerverwaltungssystems zum Hauptbetriebssystem. Das derzeit beliebteste System ist natürlich die Docker Engine. Dann verwenden die Bibliotheken im Container den Host-Kernel des Betriebssystems.

Auf diese Weise entfernen wir den Overhead, aber Docker ist auch nicht ideal und es hat seine eigenen Probleme und Arbeitsfunktionen, die nicht jedem gefallen.
Das Wichtigste ist, dass Docker und virtuelle Maschine unterschiedliche Ansätze sind und nicht gleichgesetzt werden müssen. Docker ist keine Mikrovirtualität, mit der Sie wie mit einer virtuellen Maschine arbeiten können, denn der Container ist dafür und der Container. Der Container ermöglicht uns jedoch Flexibilität und einen völlig anderen Ansatz für die kontinuierliche Lieferung, wenn wir Dinge an die Produktion liefern und verstehen, dass sie bereits getestet wurden und funktionieren.
Cloud-Technologie
Mit der Weiterentwicklung der Virtualisierung begannen sich auch Cloud-Technologien zu entwickeln. Dies ist eine gute Lösung, aber es ist erwähnenswert, dass Wolken kein Wundermittel und kein Allheilmittel für alle Übel sind. Hier kann man sich nur an ein berühmtes Zitat erinnern:
„Wenn ich jemanden höre, der die Cloud als Wundermittel für alle Computerprobleme ankündigt, ersetze ich„ Cloud “stillschweigend durch„ Clown “und mache mit einem zenartigen Lächeln weiter.“
Amy reich
Für mittelständische Unternehmen, die ein gewisses Maß an Service und Fehlertoleranz ohne große finanzielle Mittel erhalten möchten, sind die Clouds jedoch eine gute Option. Und für viele Unternehmen ist es viel teurer, ihr Rechenzentrum mit demselben SLA zu betreiben, als in der Cloud bedient zu werden. Darüber hinaus können wir die Clouds für unsere Bedürfnisse verwenden, da sie einige Dinge mit nur wenigen Mausklicks bereitstellen, was sehr praktisch ist. Zum Beispiel die Möglichkeit, eine virtuelle Maschine oder ein Netzwerk mit wenigen Klicks zu heben.
Ja, es gibt Einschränkungen, zum Beispiel das 152. Bundesgesetz, das die Speicherung personenbezogener Daten im Ausland verbietet, so dass derselbe Amazon für uns während eines Audits nicht geeignet sein wird. Vendor-lock nicht vergessen. Viele Cloud-Lösungen lassen sich nicht miteinander portieren, obwohl die meisten Anbieter denselben S3-kompatiblen Speicher unterstützen.
Clouds bieten uns die Möglichkeit, ohne eng fokussiertes Wissen unterschiedliche Servicelevels zu erhalten. Je weniger Wissen Sie benötigen, desto mehr werden wir bezahlen. In der folgenden Abbildung sehen Sie die Pyramide, in der von unten nach oben der Rückgang des technischen Wissensbedarfs bei Verwendung der Cloud angezeigt wird:

Serverless und FaaS (Funktion als Service)
Serverless ist eine relativ junge Methode zum Ausführen von Skripten in den Clouds, z. B. AWS (in Bezug auf AWS ist der Server in Lambda implementiert). * Die in der obigen Pyramide aufgelisteten AaS-Ansätze sind bereits bekannt: IaaS (EC2, VDS), PaaS (Shared Hosting), SaaS (Office 365, Tilda). Serverless ist also eine Implementierung des FaaS-Ansatzes. Und dieser Ansatz besteht darin, dem Benutzer eine vorgefertigte Plattform für die Entwicklung, den Start und die Verwaltung bestimmter Funktionen zur Verfügung zu stellen, ohne sich selbst vorbereiten und konfigurieren zu müssen.
Stellen Sie sich vor, Sie haben ein Gerät, das nachts Dokumente verarbeitet, von 00:00 bis 6:00 Uhr Aufgaben ausführt und in den restlichen Stunden nicht verwendet wird. Die Frage ist: Warum tagsüber bezahlen? Und warum nicht kostenlose Ressourcen für etwas anderes nutzen? Dieser Wunsch nach Optimierung und der Wunsch, Geld nur für das auszugeben, was Sie wirklich nutzen, führten zur Entstehung von FaaS.
Serverless ist eine Ressource zum Ausführen von Code und sonst nichts. Dies bedeutet nicht, dass sich hinter unserem Skript kein Server befindet - dies ist der Fall, aber wir haben tatsächlich keine speziell zugewiesene Ressource, auf der unser Lambda gestartet wird. Wenn wir unser Skript ausführen, entfaltet sich die Mikroinfrastruktur sofort darunter, und dies ist im Prinzip nicht Ihr Problem - Sie denken nur, dass Sie den Code ausgeführt haben, und Sie brauchen sich um nichts anderes zu kümmern.
Dies erfordert natürlich eine bestimmte Herangehensweise an die Entwicklung Ihres Codes. Beispielsweise können Sie in dieser Umgebung nichts speichern, sondern müssen alles herausnehmen. Handelt es sich um Daten, wird eine externe Datenbank benötigt. Handelt es sich um ein Protokoll, handelt es sich um einen externen Protokolldienst, handelt es sich um eine Datei, handelt es sich um einen externen Dateispeicher. Glücklicherweise bietet jeder Serverless-Anbieter die Möglichkeit, eine Verbindung zu externen Systemen herzustellen.
Sie haben nur Code, Sie arbeiten im zustandslosen Paradigma, Sie haben keinen Zustand. Für die gleiche Welt von PHP bedeutet dies beispielsweise, dass Sie den Standard-Sitzungsmechanismus vergessen können. Im Prinzip können Sie sogar Ihre Serverless bauen, und kürzlich gab es auf Habré einen Artikel zu diesem Thema .
Die Grundidee von Serverless ist, dass die Infrastruktur keine Unterstützung durch das Team erfordert. Alles fällt auf die Schultern der Plattform, für die Sie tatsächlich Geld bezahlen. Von den Minuspunkten - Sie haben keine Kontrolle über die Ausführungsumgebung und wissen nicht, wo was ausgeführt wird.
So serverlos:
- bedeutet nicht die physische Abwesenheit des Servers;
- kein Killer von Virtualoks und Docker;
- kein Hype hier und jetzt.
Serverless sollte bewusst und bewusst vorangetrieben werden. Zum Beispiel, wenn Sie schnell eine Hypothese testen müssen, ohne die Hälfte des Teams einzubeziehen. So erhalten Sie Function As A Service. Die Funktion reagiert auf einige Ereignisse, und da es eine Reaktion auf Ereignisse gibt, müssen diese Ereignisse von etwas aufgerufen werden - dafür gibt es in derselben AWS viele Trigger.
FaaS-Funktionen:
- Infrastruktur erfordert keine Konfiguration;
- "Out of the Box" -Ereignismodell;
- Staatenlos;
- Die Skalierung ist sehr einfach und wird automatisch entsprechend den Benutzeranforderungen durchgeführt.
AWS Lambda
Die erste und öffentlich verfügbare Implementierung von FaaS ist AWS Lambda. Wenn es sich um eine Diplomarbeit handelt, hat sie folgende Eigenschaften:
- verfügbar seit 2014;
- unterstützt standardmäßig Java, Node.js, Python, Go und benutzerdefinierte Laufzeiten;
- wir bezahlen für:
Anzahl der Anrufe;
Vorlaufzeit.
AWS Lambda: Warum wird es benötigt:
Entsorgung Sie zahlen nur für die Zeit, in der der Dienst ausgeführt wird.
Geschwindigkeit. Lambda selbst steigt auf und arbeitet sehr schnell.
Funktional. Lambda bietet viele Funktionen für die Integration in AWS-Services.
Leistung. Ein Lambda zu setzen ist ziemlich schwer. Parallel dazu können je nach Region maximal 1000 bis 3000 Exemplare erstellt werden. Falls gewünscht, kann dieses Limit durch Schreiben in den Support erhöht werden.
Wir haben den Körper eines Lambda, einen Online-Editor, VPC als virtuelles Rechengitter, die Protokollierung, den Code selbst, Umgebungsvariablen und Trigger, die ein Lambda verursachen (die Versionierung funktioniert übrigens sehr gut). In diesem Artikel wird die ausgezeichnete Lambda-Anatomie beschrieben .
Der Code wird entweder im Hauptteil (sofern diese Sprachen standardmäßig unterstützt werden) oder in Ebenen gespeichert. Wir haben einen Trigger, der das Lambda aufruft, das Lambda liest die temporären Umgebungen, zieht sie zu sich selbst und führt unseren Code aus:

Wenn wir eine benutzerdefinierte Laufzeit haben, müssen wir den Code in einer Ebene platzieren. Wenn Sie mit Docker gearbeitet haben, ist die Docker-Ebene der Lambda-Ebene sehr ähnlich - eine Art Quasi-Speicher, in dem sich unsere erforderliche Bindung befindet. Dort haben wir die ausführbare Datei der Umgebung (wenn es sich um PHP handelt, sollten Sie die kompilierte PHP-Binärdatei im Voraus platzieren), die Lambda-Bootstrap-Datei (standardmäßig gespeichert) und die direkt aufgerufenen Skripte, die ausgeführt werden.

Bei der Lieferung ist nicht alles so rosig:

Das heißt, wir können Dateien mit dem Code aufnehmen, in das ZIP-Archiv hochladen, in die Ebene hochladen und unseren Code ausführen. Es ist absolut cool, dass dies in der offiziellen Dokumentation von Amazon angeboten wird.

Natürlich entspricht dies nicht den modernen Realitäten und dem Geruch von zweitausendstel in der Luft. Glücklicherweise haben freundliche Leute versucht, verschiedene Frameworks zu erstellen. Daher verwenden wir das auf Node.js entwickelte Serverless Framework, mit dem wir Anwendungen auf Basis von AWS Lambda verwalten können. Wenn wir über Bereitstellung und Entwicklung sprechen, möchte ich natürlich nicht wirklich manuell bereitstellen, aber es besteht der Wunsch, etwas Flexibles und Automatisiertes zu tun.
Also brauchen wir:
- AWS CLI - Befehlszeilenschnittstelle für die Arbeit mit AWS-Diensten;
- das oben bereits erwähnte Serverless-Framework (die Entwicklungsversion ist kostenlos und die Funktionalität ist für die Augen ausreichend);
- Die Bref-Bibliothek, die zum Schreiben von Code benötigt wird. Diese Bibliothek wird mit Composer installiert, sodass der Code mit jedem Framework kompatibel ist. Eine großartige Lösung, insbesondere angesichts der Tatsache, dass AWS Lambda das Aufrufen von PHP-Skripten nicht direkt unterstützt.

Passen Sie Ihre Umgebung und AWS an
AWS CLI
Beginnen wir mit der Erstellung eines Kontos und der Installation von AWS CLI. Die AWS-Konsolen-Shell basiert auf Python 2.7+ oder 3.4+. Da AWS Version 3 von Python empfiehlt, werden wir nicht streiten.
Die folgenden Beispiele gelten für Ubuntu.
sudo apt-get -y install python3-pip
Dann installieren Sie direkt AWS CLI:
pip3 install awscli --upgrade --user
Überprüfen Sie die Installation:
aws --version
Jetzt müssen Sie AWS CLI mit Ihrem Konto verbinden. Sie können Ihren vorhandenen Benutzernamen und Ihr Kennwort verwenden. Es ist jedoch besser, wenn Sie einen separaten Benutzer über AWS IAM erstellen und ihm nur die erforderlichen Zugriffsrechte zuweisen. Das Aufrufen der Konfiguration verursacht keine Probleme:
aws configure
Als Nächstes benötigen Sie AWS Secret und AWS Access Key. Sie können in ASW IAM auf der Registerkarte "Sicherheitsanmeldeinformationen" (auf der Seite des gewünschten Benutzers) abgerufen werden. Die Schaltfläche "Zugriffsschlüssel erstellen" hilft bei der Erstellung von Zugriffsschlüsseln. Behalte sie bei dir.

Um einen neuen Bot in Telegram zu registrieren, verwenden Sie @BotFather und den Befehl / newbot. Infolgedessen erhalten Sie das für die Verbindung zu Ihrem Bot erforderliche Token zurück. Schließe es auch ab.
Serverloses Framework
Zur Installation von Serverless Framework benötigen Sie ein Konto unter https://serverless.com/ .
Nach Abschluss der Registrierung fahren wir mit der Installation auf unserer Workstation fort. Node.js 6. und höher wird benötigt.
sudo apt-get -y install nodejs
Um den korrekten Start in unserer Umgebung sicherzustellen, befolgen wir die empfohlenen Schritte:
mkdir ~/.npm-global export PATH=~/.npm-global/bin:$PATH source ~/.profile npm config set prefix '~/.npm-global'
Fügen Sie außerdem hinzu:
~/.npm-global/bin:$PATH
in die Datei / etc / environment.
Setzen Sie nun Serverless:
npm install -g serverless
Aws
Nun, es ist Zeit, zur AWS-Oberfläche zu wechseln und einen Domainnamen hinzuzufügen. Wir erstellen eine AWS Route 53-Zone, einen DNS-Eintrag und ein SSL-Zertifikat dafür.
Außerdem benötigen Sie den ELB, den wir im Service EC2 -> Load Balancer erstellen. Übrigens müssen Sie beim Erstellen einer ELB alle Schritte des Assistenten durchlaufen und das erstellte Zertifikat angeben.
Der Balancer kann mit dem folgenden Befehl über die AWS-CLI erstellt werden:
aws elb create-load-balancer --load-balancer-name my-load-balancer --listeners "Protocol=HTTP,LoadBalancerPort=80,InstanceProtocol=HTTP,InstancePort=80" "Protocol=HTTPS,LoadBalancerPort=443,InstanceProtocol=HTTP,InstancePort=80,SSLCertificateId=arn:aws:iam::123456789012:server-certificate/my-server-cert" --subnets subnet-15aaab61 --security-groups sg-a61988c3
Nach der ersten Bereitstellung wird ein Balancer benötigt. In diesem Fall müssen Sie Anfragen an unsere Domain an diese senden. Um dies zu implementieren, geben Sie in den Einstellungen des DNS-Eintrags (Feld „Alias-Ziel“) den Namen der erstellten ELB ein. Infolgedessen wird eine Dropdown-Liste angezeigt, sodass der gewünschte Eintrag ausgewählt und gespeichert werden muss.

Gehen Sie jetzt zum Code.
Einen Code schreiben
Wir werden Bref verwenden, um den Code zu schreiben. Wie bereits erwähnt, wird diese Bibliothek mit Composer installiert, sodass der Code mit jedem Framework kompatibel ist. Übrigens haben die Entwickler bereits den Prozess der Verwendung von Bref mit Laravel und Symfony beschrieben . Es ist jedoch ratsam, an dem "bloßen" PHP zu arbeiten - dies hilft, das Wesentliche besser zu verstehen.
Wir beginnen mit den Abhängigkeiten:
{ "require": { "php": ">=7.2", "bref/bref": "^0.5.9", "telegram-bot/api": "*" }, "autoload": { "psr-4": { "App\": "src/" } } }
Wir werden in PHP 7.2 und höher schreiben und für die Arbeit mit Telegram ist diese Shell für die API für uns geeignet - https://github.com/TelegramBot/Api . Der Code selbst wird im Verzeichnis src abgelegt.
Die serverlose Umgebung durchläuft also einen Konsolendialog. Eine HTTP-Anwendung ist erforderlich. Aus Sicht von Lambda bedeutet dies, dass Skriptaufrufe auf die gleiche Weise ausgeführt werden, wie dies bei Nginx der Fall ist. Die Interpretation wird von PHP-FPM durchgeführt. Im Allgemeinen ähnelt dies eher einem Standard-Konsolenskriptaufruf. Dies ist ein wichtiger Punkt, da wir ohne Berücksichtigung dieser Funktion keine Skripte über HTTP aufrufen können.
Wir führen aus:
vendor/bin/bref init
Wählen Sie im Dialogfeld den Punkt "HTTP-Anwendung" und vergessen Sie nicht, die Region anzugeben, da die Anwendung in derselben Region arbeiten sollte, in der der Balancer arbeitet.
Nach der Initialisierung erscheinen 2 neue Dateien:
index.php - die aufgerufene Datei;
serverless.yml - Bereitstellungskonfigurationsdatei.
Der .serverless-Ordner muss sofort zum .gitignore hinzugefügt werden (er wird nach dem ersten Bereitstellungsversuch angezeigt).
Sobald wir eine Webanwendung haben, legen wir index.php im öffentlichen Ordner ab und wechseln sofort zu serverless.yml. So könnte es in unserer Implementierung aussehen:
# lambda- service: app # provider: name: aws # ! region: eu-central-1 # runtime: provided # , bref 1024. memoryLimit: 256 # stage: dev # environment: BOT_TOKEN: ${ssm:/app/bot-token} # bref plugins: - ./vendor/bref/bref # Lambda- functions: # php-api-dev # service-function-stage api: handler: public/index.php description: '' # in seconds (API Gateway has a timeout of 29 seconds) timeout: 28 layers: - ${bref:layer.php-73-fpm} # API Gateway events: - http: 'ANY /' - http: 'ANY /{proxy+}' # environment: MY_VARIABLE: ${ssm:/app/my_variable}
Analysieren wir nun die nicht offensichtlichen Linien. Wir brauchen meistens Umgebungsvariablen. Wir möchten keine Datenbankverbindungen, externen APIs usw. fest codieren. Wenn wir eine Verbindung zu Telegram herstellen, verfügen wir über ein eigenes Token, das von BotFather empfangen wird. Es wird nicht empfohlen, dieses Token in serverless.yml zu speichern. Es ist daher besser, es an den AWS ssm-Speicher zu senden:
aws ssm put-parameter --region eu-central-1 --name '/app/my_variable' --type String --value '___BOTFATHER'
Wir verweisen übrigens in der Konfiguration darauf.
Diese Variablen sind als Umgebungsvariablen verfügbar, und Sie können mit der Funktion getenv in PHP darauf zugreifen. Wenn wir über unser Beispiel sprechen, behalten wir das Bot-Token der Einfachheit halber im globalen Rahmen. Wir können das Token auch in den Bereich einer einzelnen Funktion übertragen, und der Aufruf selbst wird sich dadurch nicht ändern.
Lass uns weitermachen. Erstellen wir nun eine einfache BotApp-Klasse, die für die Generierung einer Antwort für den Bot verantwortlich ist und auf Befehle reagiert. Telegrammentwickler empfehlen, die Befehle / help und / start für alle Bots zu unterstützen. Fügen wir zum Spaß einen weiteren Befehl hinzu. Die Klasse selbst ist recht einfach und ermöglicht es, Front-Controller in index.php zu implementieren, ohne die Aufrufdatei selbst zu laden. Um eine komplexere Logik zu erhalten, sollte die Architektur entwickelt und kompliziert sein.
<?php namespace App; use TelegramBot\Api\Client; use Telegram\Bot\Objects\Update; class BotApp { function run(): void{ $token = getenv('BOT_TOKEN'); $bot = new Client($token); // start $bot->command('start', function ($message) use ($bot) { $answer = ' !'; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('help', function ($message) use ($bot) { $answer = ': /help - '; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('hello', function ($message) use ($bot) { $answer = '-, - , Serverless '; $bot->sendMessage($message->getChat()->getId(), $answer); }); $bot->run(); } }
Und hier ist die Auflistung von index.php:
<?php require_once('../vendor/autoload.php'); use App\BotApp; try{ $botApp = new BotApp(); $botApp->run(); } catch (Exception $e){ echo $e->getMessage(); print_r($e->getTrace(), 1); }
Es mag seltsam erscheinen, aber alles ist bereit für uns, in die Produktion zu gehen. Führen Sie dazu den folgenden Befehl im Ordner serverless.yml aus:
sls deploy
Im normalen Modus packt serverless die Dateien in ZIP-Archive, erstellt einen S3-Bucket, in dem sie abgelegt werden, erstellt oder aktualisiert die an Lambda angehängte AWS-Anwendung und legt den Code und die Laufzeit in einer separaten Ebene ab.
Während des ersten Starts wird die Gateway-API erstellt (wir haben sie verlassen, um das Testen von Anrufen zu vereinfachen, aber dann ist es ratsam, sie zu löschen). Sie müssen auch den Lambda-Aufruf über ELB konfigurieren, für den wir im Funktionssteuerungsfenster "Trigger hinzufügen" und in der Dropdown-Liste "Application Load Balancer" auswählen. Sie müssen die zuvor erstellte ELB angeben, die Verbindung über HTTPS einrichten, den Host leer lassen und unter Pfad den Pfad angeben, den Lambda aufruft (z. B. / lambda / mytgbot). Infolgedessen ist Ihr Lambda unter der URL mit dem angegebenen Pfad verfügbar.
Jetzt können Sie den Antwortteil des Bot in Telegram registrieren, damit der Messenger versteht, wo er Nachrichten abrufen kann. Rufen Sie dazu die folgende URL im Browser auf, aber vergessen Sie nicht, Ihre eigenen Parameter einzutragen:
https://api.telegram.org/bot_/setWebhook?url=https://my-elb-host.com/lambda/mytgbot
Infolgedessen gibt die API "OK" zurück, woraufhin der Bot verfügbar wird.

Testen Sie den Bot auf Gebietsschemas
Der Bot kann vor dem Einsatz getestet werden. Tatsache ist, dass das Serverless Framework das Starten in Gebietsschemas mit Docker-Containern unterstützt. Befehl aufrufen:
sls invoke local --docker -f myFunction
Vergessen Sie nicht, dass wir Umgebungsvariablen verwendet haben, daher sollten diese während des Aufrufs auch im folgenden Format festgelegt werden:
sls invoke local --docker -f myFunction --env VAR1=val1
Protokolle
Standardmäßig wird die Anrufausgabe in CloudWatch protokolliert. Sie ist im Überwachungsbereich der entsprechenden Lambda-Funktion verfügbar. Hier können Sie die Call Traces im Falle eines Dumps auf der PHP-Seite auslesen. Darüber hinaus können Sie erweiterte Überwachungsdienste anschließen, die jedoch zusätzlich einige Cent pro Monat kosten.
Total
Als Ergebnis haben wir eine relativ schnelle, flexible, skalierbare und auch relativ kostengünstige Lösung erhalten. Ja, Lambda gewinnt nicht immer im Vergleich zu Standard-VMs und -Containern, aber es gibt Situationen, in denen die Anwendung ohne Server dabei hilft, schnell und effizient zu „schießen“. Und das Beispiel des erstellten Bots zeigt dies nur.
Nützliche Materialien zum Thema: