
Kubernetes wurde
bereits vor einigen Jahren auf dem offiziellen GitHub-Blog
diskutiert . Seitdem ist es zur Standardtechnologie für die Bereitstellung von Diensten geworden. Kubernetes verwaltet inzwischen einen erheblichen Teil der internen und öffentlichen Dienste. Als unsere Cluster wuchsen und die Leistungsanforderungen immer höher wurden, stellten wir fest, dass einige Dienste auf Kubernetes sporadisch Verzögerungen aufweisen, die nicht durch das Laden der Anwendung selbst erklärt werden können.
Tatsächlich tritt in Anwendungen eine zufällige Netzwerkverzögerung von bis zu 100 ms oder mehr auf, die zu Zeitüberschreitungen oder erneuten Versuchen führt. Es wurde erwartet, dass Dienste in der Lage sein würden, Anfragen viel schneller als 100 ms zu beantworten. Dies ist jedoch nicht möglich, wenn die Verbindung selbst so lange dauert. Unabhängig davon beobachteten wir sehr schnelle MySQL-Abfragen, die Millisekunden in Anspruch nahmen, und MySQL wirklich in Millisekunden, aber aus Sicht der anfragenden Anwendung dauerte die Antwort 100 ms oder länger.
Es wurde sofort klar, dass das Problem nur beim Herstellen einer Verbindung zum Kubernetes-Host auftritt, auch wenn der Anruf von außerhalb von Kubernetes kam. Der einfachste Weg, das Problem zu reproduzieren, ist der
Vegeta- Test, der von jedem internen Host ausgeführt wird, den Kubernetes-Dienst auf einem bestimmten Port testet und sporadisch eine große Verzögerung registriert. In diesem Artikel sehen wir uns an, wie wir die Ursache für dieses Problem gefunden haben.
Beseitigen Sie unnötige Komplexität in der Fehlerkette
Nachdem wir dasselbe Beispiel reproduziert hatten, wollten wir den Fokus des Problems einschränken und die zusätzlichen Komplexitätsebenen entfernen. Anfangs waren zu viele Elemente im Strom zwischen Vegeta und Schoten auf Kubernetes. Um ein tieferes Netzwerkproblem zu identifizieren, müssen Sie einige davon ausschließen.
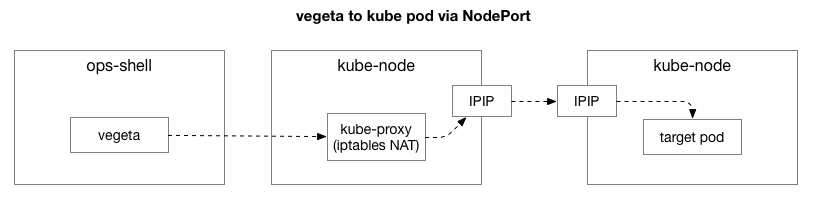
Der Client (Vegeta) erstellt eine TCP-Verbindung mit einem beliebigen Knoten im Cluster. Kubernetes fungiert als Overlay-Netzwerk (zusätzlich zum vorhandenen Rechenzentrumsnetzwerk), das
IPIP verwendet,
dh die IP-Pakete des Overlay-Netzwerks in den IP-Paketen des Rechenzentrums kapselt. Bei Verbindung mit dem ersten Knoten wird die NAT-Netzwerkadressübersetzung (
Network Address Translation ) mit Statusüberwachung durchgeführt, um die IP-Adresse und den Port des Kubernetes-Hosts in die IP-Adresse und den Port im Overlay-Netzwerk (insbesondere den Pod mit der Anwendung) zu konvertieren. Für empfangene Pakete wird die umgekehrte Reihenfolge durchgeführt. Dies ist ein komplexes System mit vielen Zuständen und vielen Elementen, die ständig aktualisiert und geändert werden, wenn Dienste bereitgestellt und verschoben werden.
Das Dienstprogramm
tcpdump im Vegeta-Test gibt während des TCP-Handshakes eine Verzögerung an (zwischen SYN und SYN-ACK). Um diese unnötige Komplexität zu beseitigen, können Sie
hping3 für einfache "Pings" mit SYN-Paketen verwenden. Überprüfen Sie, ob das Antwortpaket eine Verzögerung aufweist, und setzen Sie die Verbindung zurück. Wir können die Daten filtern, indem wir nur Pakete einschließen, die länger als 100 ms sind, und erhalten eine einfachere Option, um das Problem zu reproduzieren als der vollständige Test auf Netzwerkebene 7 in Vegeta. Hier sind die "Pings" des Kubernetes-Hosts unter Verwendung von TCP SYN / SYN-ACK auf dem Host "Port" des Dienstes (30927) mit einem Intervall von 10 ms, gefiltert nach den langsamsten Antworten:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 msSofort kann man die erste Beobachtung machen. Die Seriennummern und Timings zeigen, dass dies keine einmalige Überlastung ist. Die Verzögerung summiert sich häufig und wird letztendlich verarbeitet.
Als nächstes wollen wir herausfinden, welche Komponenten am Auftreten von Staus beteiligt sein können. Vielleicht sind dies einige der Hunderte von Iptables-Regeln in NAT? Oder einige Probleme mit IPIP-Tunneling im Netzwerk? Eine Möglichkeit, dies zu überprüfen, besteht darin, jeden Schritt des Systems durch Ausschließen zu überprüfen. Was passiert, wenn Sie NAT- und Firewall-Logik entfernen und nur einen Teil von IPIP übrig lassen:
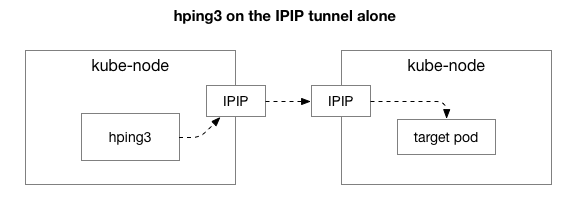
Glücklicherweise erleichtert Linux den direkten Zugriff auf die IP-Overlay-Schicht, wenn sich der Computer im selben Netzwerk befindet:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 msNach den Ergebnissen zu urteilen, bleibt das Problem immer noch! Dies schließt iptables und NAT aus. Das Problem liegt also in TCP? Mal sehen, wie regulär ICMP-Ping funktioniert:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 msDie Ergebnisse zeigen, dass das Problem nicht verschwunden ist. Vielleicht ist dies ein IPIP-Tunnel? Vereinfachen wir den Test:
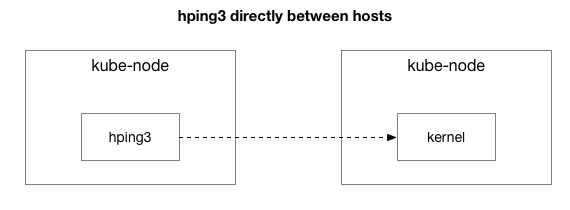
Werden alle Pakete zwischen diesen beiden Hosts gesendet?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 msWir haben die Situation vereinfacht, indem zwei Kubernetes-Hosts beliebige Pakete aneinander senden, sogar ICMP-Ping. Sie sehen immer noch eine Verzögerung, wenn der Zielhost "schlecht" ist (einige schlechter als andere).
Nun die letzte Frage: Warum tritt die Verzögerung nur auf Kubeknotenservern auf? Und passiert es, wenn kube-node der Sender oder Empfänger ist? Glücklicherweise ist dies auch recht einfach herauszufinden, indem ein Paket von einem Host außerhalb von Kubernetes gesendet wird, der jedoch denselben "als fehlerhaft bekannten" Empfänger hat. Wie Sie sehen können, ist das Problem nicht verschwunden:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 msDann führen wir dieselben Anforderungen vom vorherigen Quell-Kubeknoten an den externen Host durch (der den ursprünglichen Host ausschließt, da ping sowohl die RX- als auch die TX-Komponenten enthält):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 msNachdem wir die verzögerten Paketerfassungen untersucht hatten, erhielten wir einige zusätzliche Informationen. Insbesondere, dass der Absender (unten) diese Zeitüberschreitung sieht, der Empfänger (oben) sie jedoch nicht sieht - siehe die Delta-Spalte (in Sekunden):

Wenn Sie den Unterschied in der Reihenfolge von TCP- und ICMP-Paketen (nach Sequenznummern) auf der Empfängerseite untersuchen, kommen ICMP-Pakete außerdem immer in der gleichen Reihenfolge an, in der sie gesendet wurden, jedoch mit unterschiedlichem Timing. Gleichzeitig wechseln sich TCP-Pakete manchmal ab, und einige von ihnen bleiben hängen. Insbesondere wenn wir die Ports der SYN-Pakete untersuchen, gehen sie auf der Senderseite in die richtige Reihenfolge, auf der Empfängerseite jedoch nicht.
Es gibt einen subtilen Unterschied, wie
Netzwerkkarten moderner Server (wie in unserem Rechenzentrum) Pakete verarbeiten, die TCP oder ICMP enthalten. Wenn ein Paket ankommt, "hackt" der Netzwerkadapter es über die Verbindung, das heißt, er versucht, die Verbindungen abwechselnd zu trennen und jede Warteschlange an einen separaten Prozessorkern zu senden. Bei TCP enthält dieser Hash sowohl die Quell- als auch die Ziel-IP-Adresse und den Port. Mit anderen Worten, jede Verbindung wird (möglicherweise) anders gehasht. Für ICMP werden nur IP-Adressen gehasht, da keine Ports vorhanden sind.
Eine weitere neue Beobachtung: Während dieses Zeitraums stellen wir ICMP-Verzögerungen bei der gesamten Kommunikation zwischen den beiden Hosts fest, TCP jedoch nicht. Dies sagt uns, dass der Grund wahrscheinlich in einem Hashing der RX-Warteschlangen liegt: Es ist fast sicher, dass die Überlastung eher bei der Verarbeitung von RX-Paketen als beim Senden von Antworten auftritt.
Dies schließt das Senden von Paketen aus der Liste der möglichen Gründe aus. Jetzt wissen wir, dass das Problem bei der Paketverarbeitung auf einigen Kubeknotenservern auf der Empfängerseite liegt.
Grundlegendes zur Paketverarbeitung im Linux-Kernel
Um zu verstehen, warum das Problem beim Empfänger auf einigen Kubeknotenservern auftritt, sehen wir uns an, wie der Linux-Kernel mit Paketen umgeht.
Zur einfachsten herkömmlichen Implementierung zurückkehrend, empfängt die Netzwerkkarte das Paket und sendet eine
Unterbrechung an den Linux-Kernel, der das Paket ist, das verarbeitet werden muss. Der Kernel stoppt eine andere Operation, wechselt den Kontext zum Interrupt-Handler, verarbeitet das Paket und kehrt dann zu den aktuellen Tasks zurück.

Dieser Kontextwechsel ist langsam: Auf 10-Megabyte-Netzwerkkarten war die Latenz in den 1990er-Jahren möglicherweise nicht spürbar, aber auf modernen 10G-Karten mit einem maximalen Durchsatz von 15 Millionen Paketen pro Sekunde kann jeder Kern eines kleinen 8-Core-Servers millionenfach pro Sekunde unterbrochen werden.
Um nicht ständig mit der Interrupt-Behandlung
fertig zu werden, hat Linux vor vielen Jahren
NAPI hinzugefügt: eine Netzwerk-API, mit der alle modernen Treiber die Leistung bei hohen Geschwindigkeiten steigern. Bei niedrigen Geschwindigkeiten akzeptiert der Kernel weiterhin Interrupts von der Netzwerkkarte auf die alte Art und Weise. Sobald eine ausreichende Anzahl von Paketen eintrifft, die den Schwellenwert überschreitet, deaktiviert der Kernel die Interrupts und beginnt stattdessen, den Netzwerkadapter abzufragen und Pakete in Stapeln aufzunehmen. Die Verarbeitung erfolgt in softirq, dh im
Kontext von Software-Interrupts nach Systemaufrufen und Hardware-Interrupts, wenn der Kernel (anders als der Benutzerraum) bereits ausgeführt wird.
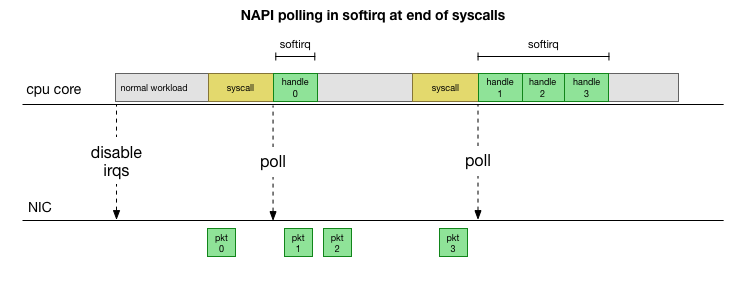
Dies ist viel schneller, verursacht jedoch ein anderes Problem. Wenn zu viele Pakete vorhanden sind, dauert es die ganze Zeit, um Pakete von der Netzwerkkarte zu verarbeiten, und Benutzerraumprozesse haben keine Zeit, diese Warteschlangen tatsächlich zu leeren (Lesen von TCP-Verbindungen usw.). Am Ende füllen sich die Warteschlangen und wir beginnen Pakete abzulegen. Bei dem Versuch, ein Gleichgewicht zu finden, legt der Kernel ein Budget für die maximale Anzahl von Paketen fest, die im Kontext von softirq verarbeitet werden. Sobald dieses Budget überschritten ist, wird ein separater
ksoftirqd Thread
ksoftirqd (Sie sehen einen in
ps für jeden Kern), der diese Softirqs außerhalb des normalen Syscall / Interrupt-Pfads verarbeitet. Dieser Thread wird mit einem Standardprozessplaner geplant, der versucht, Ressourcen gerecht zu verteilen.
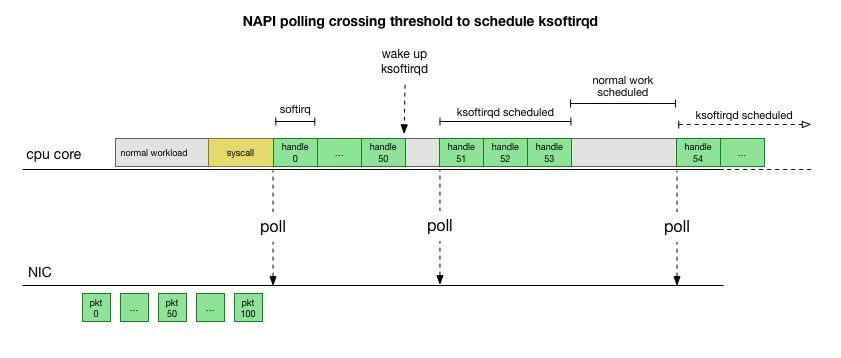
Nachdem Sie untersucht haben, wie der Kernel Pakete verarbeitet, können Sie feststellen, dass eine gewisse Wahrscheinlichkeit einer Überlastung besteht. Wenn Softirq-Anrufe seltener eingehen, müssen Pakete eine Weile warten, bis sie in der Empfangswarteschlange auf der Netzwerkkarte verarbeitet werden. Möglicherweise liegt dies an einer Aufgabe, die den Prozessorkern blockiert, oder daran, dass der Kernel softirq nicht startet.
Wir beschränken die Verarbeitung auf den Kernel oder die Methode
Verzögerungen bei Softirq sind nur eine Annahme. Aber es macht Sinn und wir wissen, dass wir etwas sehr Ähnliches sehen. Daher besteht der nächste Schritt darin, diese Theorie zu bestätigen. Und wenn es bestätigt wird, dann finden Sie den Grund für die Verzögerungen.
Zurück zu unseren Slow Packages:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 msWie bereits erwähnt, werden diese ICMP-Pakete in eine einzelne NIC RX-Warteschlange gehasht und von einem einzelnen CPU-Kern verarbeitet. Wenn wir verstehen möchten, wie Linux funktioniert, ist es hilfreich zu wissen, wo (auf welchem CPU-Kern) und wie (softirq, ksoftirqd) diese Pakete verarbeitet werden, um den Prozess zu verfolgen.
Jetzt ist es Zeit, Tools zu verwenden, mit denen der Linux-Kernel in Echtzeit überwacht werden kann. Hier haben wir
bcc verwendet . Mit diesem Toolkit können Sie kleine C-Programme schreiben, die beliebige Funktionen im Kernel abfangen und Ereignisse in ein Python-Programm im Benutzerbereich puffern, das sie verarbeiten und Ihnen das Ergebnis zurückgeben kann. Hooks für beliebige Funktionen im Kernel sind komplex, aber das Dienstprogramm ist auf maximale Sicherheit ausgelegt und verfolgt genau solche Produktionsprobleme, die in einer Test- oder Entwicklungsumgebung nicht einfach zu reproduzieren sind.
Der Plan hier ist einfach: Wir wissen, dass der Kernel diese ICMP-Pings verarbeitet, daher
binden wir die
Kernelfunktion icmp_echo ein , die das eingehende ICMP-Paket für die
Echoanforderung empfängt und das Senden der ICMP-Antwort für die
Echoantwort initiiert. Wir können das Paket identifizieren, indem wir die icmp_seq-Nummer erhöhen, die oben
hping3 .
Der
bcc-Skriptcode sieht kompliziert aus, ist aber nicht so beängstigend, wie es scheint. Die Funktion
icmp_echo übergibt
struct sk_buff *skb : Dies ist das Paket mit der Anforderung "Echo Request". Wir können es verfolgen, die Sequenz
echo.sequence (die
icmp_seq von hping3
) herausziehen und es an den User-Space senden. Es ist auch praktisch, den aktuellen Prozessnamen / die aktuelle Prozesskennung zu erfassen. Nachfolgend sehen Sie die Ergebnisse, die wir direkt während der Verarbeitung von Paketen durch den Kernel sehen:
TGID PID PROCESS NAME ICMP_SEQ
0 0 swapper / 11.770
0 0 swapper / 11.771
0 0 swapper / 11 772
0 0 swapper / 11 773
0 0 swapper / 11,774
20041 20086 prometheus 775
0 0 swapper / 11.776
0 0 swapper / 11.777
0 0 swapper / 11 778
4512 4542 spokes-report-s 779
Hierbei ist zu beachten, dass im Kontext von
softirq Prozesse, die Systemaufrufe
softirq als "Prozesse"
softirq werden, obwohl dieser Kernel Pakete im Kontext des Kernels sicher verarbeitet.
Mit diesem Tool können wir die Verbindung bestimmter Prozesse mit bestimmten Paketen herstellen, die eine Verzögerung von
hping3 . Wir machen eine einfache
icmp_seq dieser Erfassung für bestimmte
icmp_seq Werte. Pakete, die den obigen icmp_seq-Werten entsprechen, wurden mit ihrer RTT markiert, die wir oben beobachtet haben (in Klammern sind die erwarteten RTT-Werte für Pakete, die wir aufgrund von RTT-Werten von weniger als 50 ms gefiltert haben):
TGID PID PROCESS NAME ICMP_SEQ ** RTT
-
10137 10436 cadvisor 1951
10137 10436 cadvisor 1952
76 76 ksoftirqd / 11 1953 ** 99ms
76 76 ksoftirqd / 11 1954 ** 89ms
76 76 ksoftirqd / 11 1955 ** 79ms
76 76 ksoftirqd / 11 1956 ** 69ms
76 76 ksoftirqd / 11 1957 ** 59ms
76 76 ksoftirqd / 11 1958 ** (49 ms)
76 76 ksoftirqd / 11 1959 ** (39 ms)
76 76 ksoftirqd / 11 1960 ** (29 ms)
76 76 ksoftirqd / 11 1961 ** (19 ms)
76 76 ksoftirqd / 11 1962 ** (9 ms)
-
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75ms
76 76 ksoftirqd / 11 2071 ** 65ms
76 76 ksoftirqd / 11 2072 ** 55ms
76 76 ksoftirqd / 11 2073 ** (45 ms)
76 76 ksoftirqd / 11 2074 ** (35 ms)
76 76 ksoftirqd / 11 2075 ** (25 ms)
76 76 ksoftirqd / 11 2076 ** (15 ms)
76 76 ksoftirqd / 11 2077 ** (5 ms)
Die Ergebnisse sagen uns ein paar Dinge. Erstens behandelt der
ksoftirqd/11 Kontext alle diese Pakete. Dies bedeutet, dass für dieses bestimmte Maschinenpaar ICMP-Pakete auf dem 11-Core am empfangenden Ende gehasht wurden. Wir sehen auch, dass es bei jedem Stau Pakete gibt, die im Kontext des
cadvisor -Systemaufrufs verarbeitet werden. Dann übernimmt
ksoftirqd die Aufgabe und erfüllt die akkumulierte Warteschlange: genau die Anzahl der Pakete, die nach
cadvisor akkumuliert
cadvisor .
Die Tatsache, dass ein
cadvisor immer unmittelbar davor arbeitet, impliziert, dass er sich mit dem Problem befasst. Ironischerweise besteht der Zweck von
cadvisor darin, "die Ressourcennutzung und die Leistungsmerkmale laufender Container zu analysieren", anstatt dieses Leistungsproblem zu verursachen.
Wie bei anderen Aspekten des Containerumschlags handelt es sich hierbei um äußerst fortschrittliche Tools, bei denen unter unvorhergesehenen Umständen Leistungsprobleme zu erwarten sind.
Was macht cadvisor, um die Paketwarteschlange zu verlangsamen?
Jetzt wissen wir ziemlich genau, wie der Fehler auftritt, welcher Prozess ihn verursacht und auf welcher CPU. Wir sehen, dass der Linux-Kernel aufgrund der harten Sperrung keine Zeit hat,
ksoftirqd rechtzeitig zu planen. Und wir sehen, dass Pakete im Kontext von
cadvisor . Es ist logisch anzunehmen, dass
cadvisor einen langsamen
cadvisor startet, nach dem alle zu diesem Zeitpunkt gesammelten Pakete verarbeitet werden:
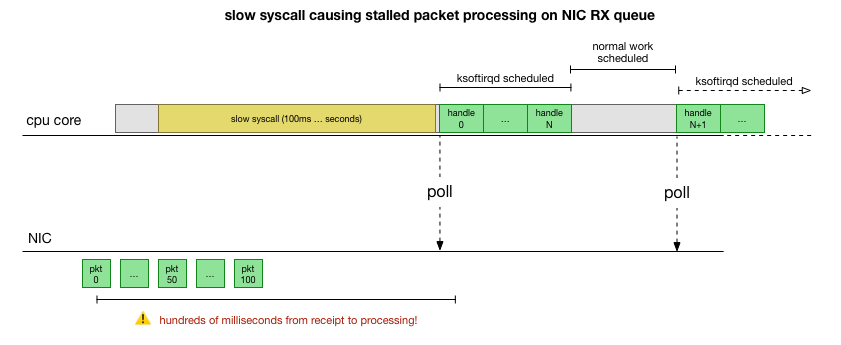
Dies ist eine Theorie, aber wie kann man sie testen? Was wir tun können, ist, den Betrieb des CPU-Kerns während dieses Prozesses zu verfolgen, den Punkt zu finden, an dem das Budget durch die Anzahl der Pakete und ksoftirqd überschritten wird, und dann etwas früher zu schauen - was genau vor diesem Moment auf dem CPU-Kern funktioniert hat. Es ist wie ein Röntgenbild einer CPU alle paar Millisekunden. Es wird ungefähr so aussehen:
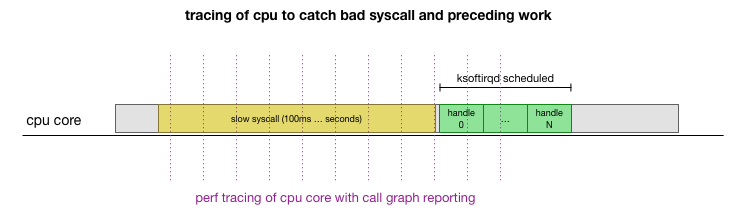
Praktischerweise kann dies alles mit vorhandenen Werkzeugen durchgeführt werden. Beispielsweise überprüft
perf record den angegebenen CPU-Kern mit der angegebenen Häufigkeit und kann einen Zeitplan für Aufrufe an ein laufendes System generieren, der sowohl den Benutzerbereich als auch den Linux-Kernel enthält. Sie können diesen Datensatz mit einem kleinen
Zweig des
FlameGraph- Programms von Brendan Gregg verarbeiten, der die Stapelverfolgungsreihenfolge
beibehält . Wir können einzeilige Stack-Traces alle 1 ms speichern und dann das Sample für 100 Millisekunden auswählen und speichern, bevor
ksoftirqd in den Trace
ksoftirqd :
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100Hier sind die Ergebnisse:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_runHier gibt es eine Menge Dinge, aber die Hauptsache ist, dass wir die Vorlage "cadvisor before ksoftirqd" finden, die wir zuvor im ICMP-Tracer gesehen haben. Was bedeutet das?
Jede Zeile ist ein Trace der CPU zu einem bestimmten Zeitpunkt. Jeder Aufruf des Stapels in einer Zeile wird durch ein Semikolon getrennt. In der Mitte der Zeilen sehen wir syscall mit dem Namen:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... Aus diesem Grund verbringt Cadvisor viel Zeit mit dem Systemaufruf
read() , der sich auf die Funktionen
mem_cgroup_* (ganz oben auf dem Aufrufstapel / Zeilenende)
mem_cgroup_* .
In der Anrufverfolgung ist es unpraktisch zu sehen, was genau gelesen wird. Führen Sie also
strace und sehen Sie, was der Cadvisor tut, und suchen Sie nach Systemanrufen, die länger als 100 ms sind:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>Wie zu erwarten ist, sehen wir hier langsame
read() -Aufrufe. Aus den Inhalten der Leseoperationen und dem
mem_cgroup Kontext ist ersichtlich, dass sich diese
read() -Aufrufe auf die Datei
memory.stat beziehen, in der die Speicherauslastung und die Einschränkungen von cgroup (Docker-Technologie zur Ressourcenisolierung) aufgeführt sind. Das Cadvisor-Tool fragt diese Datei nach Informationen zur Ressourcennutzung für Container ab. Lassen Sie uns überprüfen, ob dieser Core oder Cadvisor etwas Unerwartetes tut:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $Jetzt können wir den Fehler reproduzieren und verstehen, dass der Linux-Kernel mit einer Pathologie konfrontiert ist.
Was macht das Lesen so langsam?
Zu diesem Zeitpunkt ist es viel einfacher, Nachrichten von anderen Benutzern zu ähnlichen Problemen zu finden. Wie sich herausstellte, wurde dieser Fehler im Cadvisor-Tracker als
Problem einer übermäßigen CPU-Auslastung gemeldet. Niemand bemerkte jedoch, dass die Verzögerung auch zufällig im Netzwerkstapel widergespiegelt wurde. Zwar wurde festgestellt, dass Cadvisor mehr Prozessorzeit als erwartet benötigt, dies wurde jedoch nicht besonders berücksichtigt, da unsere Server über viele Prozessorressourcen verfügen, sodass wir das Problem nicht sorgfältig untersucht haben.
Das Problem ist, dass Kontrollgruppen (cgroups) die Speichernutzung im Namespace (Container) berücksichtigen. Wenn alle Prozesse in dieser Kontrollgruppe beendet sind, gibt Docker eine Kontrollgruppe Speicher frei. "Speicher" ist jedoch nicht nur ein Prozessspeicher. Obwohl der Prozessspeicher selbst nicht mehr verwendet wird, stellt sich heraus, dass der Kernel auch zwischengespeicherte Inhalte wie Einträge und Inodes (Verzeichnis- und Dateimetadaten) zuweist, die in der Speicher-Cgroup zwischengespeichert sind. Aus der Beschreibung des Problems:
cgroups-Zombies: Kontrollgruppen, in denen keine Prozesse vorhanden sind und die gelöscht werden, für die jedoch noch Speicher zugewiesen ist (in meinem Fall aus dem Dentry-Cache, aber auch aus dem Page-Cache oder tmpfs).
Das Überprüfen aller Seiten im Cache durch den Kernel, wenn cgroup freigegeben ist, kann sehr langsam sein, daher wird der verzögerte Prozess gewählt: Warten Sie, bis diese Seiten erneut angefordert werden, und löschen Sie cgroup, auch wenn der Speicher wirklich benötigt wird. Bisher wird cgroup bei der Erfassung von Statistiken noch berücksichtigt.
In Bezug auf die Leistung haben sie Speicherplatz für die Leistung geopfert: Die anfängliche Bereinigung wurde beschleunigt, da noch ein Teil des zwischengespeicherten Speichers vorhanden ist. Es ist in Ordnung. Wenn der Kernel den letzten Teil des zwischengespeicherten Speichers verwendet, wird cgroup schließlich gelöscht, sodass dies nicht als "Leck" bezeichnet werden kann. Leider führt die spezielle Implementierung der
memory.stat Suchmaschine in dieser Kernel-Version (4.9) in Verbindung mit der enormen Menge an Speicher auf unseren Servern dazu, dass die Wiederherstellung der neuesten zwischengespeicherten Daten und das Löschen von cgroup-Zombies viel länger dauert.
Es stellt sich heraus, dass es auf einigen unserer Knoten so viele Zombies gab, dass das Lesen und die Latenz eine Sekunde überschritten haben.
Eine Problemumgehung für das Cadvisor-Problem ist das sofortige Löschen von Einträgen / Inodes-Caches im gesamten System, wodurch die Leselatenz sowie die Netzwerklatenz auf dem Host sofort beseitigt werden, da das Löschen des Caches zwischengespeicherte cgroup-Zombieseiten umfasst und diese ebenfalls freigegeben werden. Dies ist keine Lösung, bestätigt jedoch die Ursache des Problems.
Es stellte sich heraus, dass neuere Versionen des Kernels (4.19+) die Leistung des Aufrufs von memory.stat verbesserten, sodass der Wechsel zu diesem Kernel das Problem
memory.stat . Gleichzeitig verfügten wir über Tools zum Erkennen von Problemknoten in Kubernetes-Clustern, zum ordnungsgemäßen Entleeren und zum Neustarten. Wir haben alle Cluster durchsucht, die Knoten mit einer ausreichend hohen Verzögerung gefunden und neu gestartet. Dies gab uns Zeit, das Betriebssystem auf den restlichen Servern zu aktualisieren.
Um es zusammenzufassen
Da dieser Fehler die Verarbeitung von NIC RX-Warteschlangen für Hunderte von Millisekunden stoppte, verursachte er gleichzeitig eine große Verzögerung bei kurzen Verbindungen und eine Verzögerung in der Mitte der Verbindung, beispielsweise zwischen MySQL-Abfragen und Antwortpaketen.
, Kubernetes, . Kubernetes .