
Die Firma, für die ich arbeite, schreibt ein eigenes Verkehrsfiltersystem und schützt das Geschäft damit vor DDoS-Angriffen, Bots, Parsern und vielem mehr. Das Produkt basiert auf einem Prozess wie
Reverse Proxying , mit dessen Hilfe wir große Verkehrsmengen in Echtzeit analysieren und letztendlich nur legitime Benutzeranforderungen zulassen und alle böswilligen herausfiltern.
Das Hauptmerkmal ist, dass unsere Dienste mit unbegrenztem eingehendem Datenverkehr arbeiten. Daher ist es sehr wichtig, alle Ressourcen von Arbeitsstationen so effizient wie möglich zu nutzen. Dabei helfen uns viele Entwicklungserfahrungen in modernem C ++, einschließlich der neuesten Standards und einer Reihe von Bibliotheken namens Boost.
Reverse Proxy
Kehren wir zum Reverse-Proxying zurück und sehen, wie Sie es in C ++ und boost.asio implementieren können. Zunächst benötigen wir zwei Objekte, die als Server- und Clientsitzungen bezeichnet werden. Die Serversitzung stellt eine Verbindung zum Browser her und hält diese aufrecht, die Clientsitzung stellt eine Verbindung zum Dienst her und hält sie aufrecht. Sie benötigen außerdem einen Datenstrompuffer, der die Arbeit mit dem Arbeitsspeicher kapselt, in den die Serversitzung vom Socket liest und aus dem die Clientsitzung in den Socket schreibt. Beispiele für Server- und Client-Sitzungen finden Sie in der Dokumentation zu boost.asio. Wie Sie mit dem Stream Buffer arbeiten, erfahren Sie dort.
Nachdem wir den Reverse-Proxy-Prototyp aus den Beispielen gesammelt haben, wird klar, dass eine solche Anwendung wahrscheinlich nicht unbegrenzten eingehenden Datenverkehr bedienen wird. Dann werden wir beginnen, die Komplexität des Codes zu erhöhen. Denken wir an Multithreading, Woker und Pools für io-Kontexte und vieles mehr. Insbesondere zu vorzeitigen Optimierungen beim Kopieren des Arbeitsspeichers zwischen Server- und Clientsitzungen.
Um welche Art von Speicherkopie handelt es sich? Tatsache ist, dass beim Filtern der Verkehr nicht immer unverändert übertragen wird. Schauen Sie sich das folgende Beispiel an: In diesem entfernen wir einen Header und fügen stattdessen zwei hinzu. Die Anzahl der Benutzerabfragen, für die ähnliche Aktionen ausgeführt werden, steigt mit der Komplexität der Logik innerhalb des Dienstes. In keinem Fall können Sie in solchen Fällen sinnlos Daten kopieren! Wenn sich nur 1% der gesamten Anforderung ändert und 99% unverändert bleiben, sollten Sie nur für diese 1% neuen Speicher zuweisen. Es wird Ihnen bei diesem boost :: asio :: const_buffer und boost :: asio :: mutable_buffer helfen, mit deren Hilfe Sie mehrere zusammenhängende Speicherblöcke mit einer Entität darstellen können.
Userwunsch:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
Das problem
Als Ergebnis haben wir eine fertige Anwendung erhalten, die sich gut skalieren lässt und mit allen möglichen Optimierungen ausgestattet ist. Als wir es in die Produktion einführten, waren wir ziemlich froh, wie lange es gut und stabil funktionierte.
Im Laufe der Zeit haben wir immer mehr Kunden, mit der Zeit ist auch der Verkehr gewachsen. Irgendwann waren wir mit dem Problem der mangelnden Leistung bei der Abwehr großer Angriffe konfrontiert. Nach der Analyse des Dienstes mit dem Dienstprogramm
perf haben wir festgestellt, dass alle Vorgänge mit dem Heap unter Last ganz oben stehen. Dann haben wir eine ähnliche Situation auf der Teststrecke mit
Yandex-Panzern und Patronen
nachgebildet , die auf dem tatsächlichen Verkehr basieren. Als wir einen Service über einen
Verstärker ansahen
, sahen wir das folgende Bild ...
Screenshot des Verstärkers (woslab):
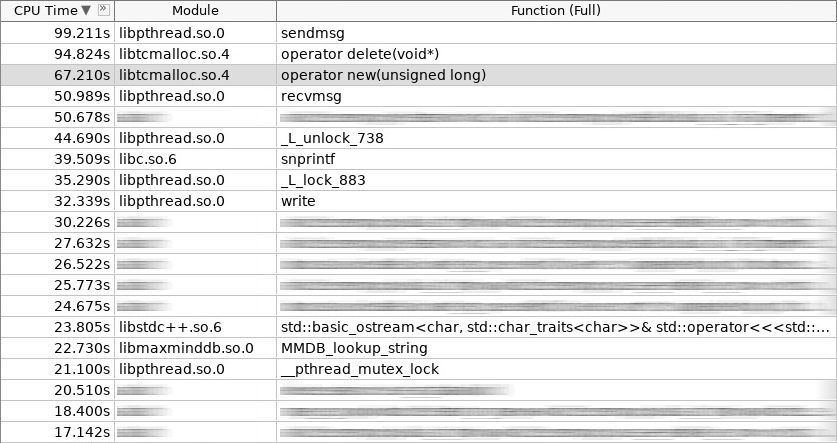
Im Screenshot hat der Operator new 67 Sekunden gearbeitet und der Operator delete noch mehr - 97 Sekunden.
Diese Situation hat uns verärgert. Wie kann die Anwendungsverweilzeit im Operator Neu und im Operator Löschen verkürzt werden? Es ist logisch, dass dies getan werden kann, indem konstante Zuordnungen von häufig erstellten und gelöschten Objekten auf dem Heap aufgegeben werden. Wir haben uns für drei Ansätze entschieden. Zwei davon sind Standard:
Objektpool und
Stapelzuordnung . Clientsitzungen, die beim Start der Anwendung in einem Pool organisiert werden, sind für den ersten Ansatz gut geeignet. Der zweite Ansatz wird überall dort verwendet, wo eine Benutzeranforderung von Anfang bis Ende im selben Stapel verarbeitet wird, dh im selben io-Kontext-Handler. Wir werden darauf nicht näher eingehen. Wir sollten besser über den dritten Ansatz als den komplexesten und interessantesten sprechen. Dies wird als
Plattenzuordnung oder Plattenverteilung bezeichnet.
Die Idee der Plattenverteilung ist nicht neu. Es wurde in Solaris erfunden und implementiert, später auf den Linux-Kernel migriert und besteht darin, dass häufig verwendete Objekte desselben Typs leichter im Pool gespeichert werden können. Wir nehmen das Objekt nur dann aus dem Pool, wenn wir es brauchen, und geben es nach Abschluss der Arbeiten wieder zurück. Keine Anrufe an Betreiber neu und Betreiber löschen! Darüber hinaus ein Minimum an Initialisierung. Im Plattenkern wird die Verteilung für Semaphoren, Dateideskriptoren, Prozesse und Threads verwendet. In unserem Fall war es perfekt für Server- und Client-Sitzungen sowie für alles, was in ihnen enthalten ist.
Diagramm (Plattenverteilung):

Zusätzlich zu der Tatsache, dass sich die Plattenzuordnungen im Kernel befinden, sind ihre Implementierungen auch im Benutzerbereich vorhanden. Es gibt nur wenige von ihnen, und diejenigen, die sich aktiv entwickeln, sind im Allgemeinen wenige. Wir haben uns für eine Bibliothek namens
libsmall entschieden , die Teil von
tarantool ist . Es hat alles was Sie brauchen.
- small :: allocator
- small :: slab_cache (thread local)
- klein :: platte
- klein :: Arena
- small :: quota
Die small :: slab-Struktur ist ein Pool mit einem bestimmten Objekttyp. Die Struktur small :: slab_cache ist ein Cache, der verschiedene Listen von Pools mit einem bestimmten Objekttyp enthält. Die Struktur small :: allocator ist ein Code, der den erforderlichen Cache auswählt, in dem nach einem geeigneten Pool gesucht wird, in dem das angeforderte Objekt verteilt wird. Was small :: arena- und small :: quota-Objekte tun, wird aus den folgenden Beispielen deutlich.
Wickeln
Die libsmall-Bibliothek ist in C und nicht in C ++ geschrieben, daher mussten wir mehrere Wrapper für die transparente Integration in die Standard-C ++ - Bibliothek entwickeln.
- variti :: slab_allocator
- variti :: platte
- variti :: thread_local_slab
- variti :: slab_allocate_shared
Die Klasse variti :: slab_allocator implementiert die Mindestanforderungen, die der Standard beim Schreiben eines eigenen Allokators festlegt. In variti :: slab-Klassen ist die gesamte Arbeit mit der libsmall-Bibliothek gekapselt. Warum wird variti :: thread_local_slab benötigt? Tatsache ist, dass Verteilungs-Slab-Caches Thread-lokale Objekte sind. Dies bedeutet, dass jeder Thread einen eigenen Satz von Caches hat. Dies geschieht, um die Anzahl der gesperrten Vorgänge beim Verteilen eines neuen Objekts auf Null zu reduzieren. Daher platzieren wir im Speicher jedes Threads unsere Instanz der Klasse variti :: slab, und der Zugriff darauf wird mithilfe des Wrappers variti :: thread_local_slab gesteuert. Ich werde Ihnen später etwas über die Template-Funktion variti :: slab_allocate_shared erzählen.
In der Klasse variti :: slab_allocator ist alles ganz einfach. Er hat die Fähigkeit, sich von einem Typ zu einem anderen zu binden, zum Beispiel von der Leere zur Saibling. Interessanterweise können Sie auf die Prävalenz von nullptr bis zur Ausnahme std :: bad_alloc achten, wenn der Arbeitsspeicher auf der Verteilungsplatte knapp wird. Der Rest leitet Anrufe innerhalb des Wrappers variti :: thread_local_slab weiter.
Snippet (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
Mal sehen, wie der Konstruktor und Destruktor variti :: slab implementiert wird. Im Konstruktor weisen wir allen Objekten insgesamt nicht mehr als 1 GB Speicher zu. Die Größe jedes Pools überschreitet in unserem Fall 1 MiB nicht. Das kleinste Objekt, das wir verteilen können, ist 2 Bytes groß (in der Tat wird es von libsmall auf das erforderliche Minimum erhöht - 8 Bytes). Die verbleibenden Objekte, die über unsere Plattenverteilung verfügbar sind, sind ein Vielfaches von zwei (festgelegt durch die Konstante 2.f). Insgesamt können Sie Objekte der Größe 8, 16, 32 usw. verteilen. Wenn das angeforderte Objekt eine Größe von 24 Byte hat, tritt ein Overhead aus dem Speicher auf. Die Verteilung gibt dieses Objekt an Sie zurück, es wird jedoch in einem Pool abgelegt, der einem Objekt mit einer Größe von 32 Byte entspricht. Die verbleibenden 8 Bytes sind inaktiv.
Snippet (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
Alle diese Einschränkungen gelten für eine bestimmte Instanz der Klasse variti :: slab. Da jeder Thread einen eigenen Thread hat (denken Sie an thread local), beträgt das Gesamtlimit für den Prozess nicht 1 GB, sondern ist direkt proportional zur Anzahl der Threads, die die Plattenverteilung verwenden.
Diagramm (std :: thread :: id):
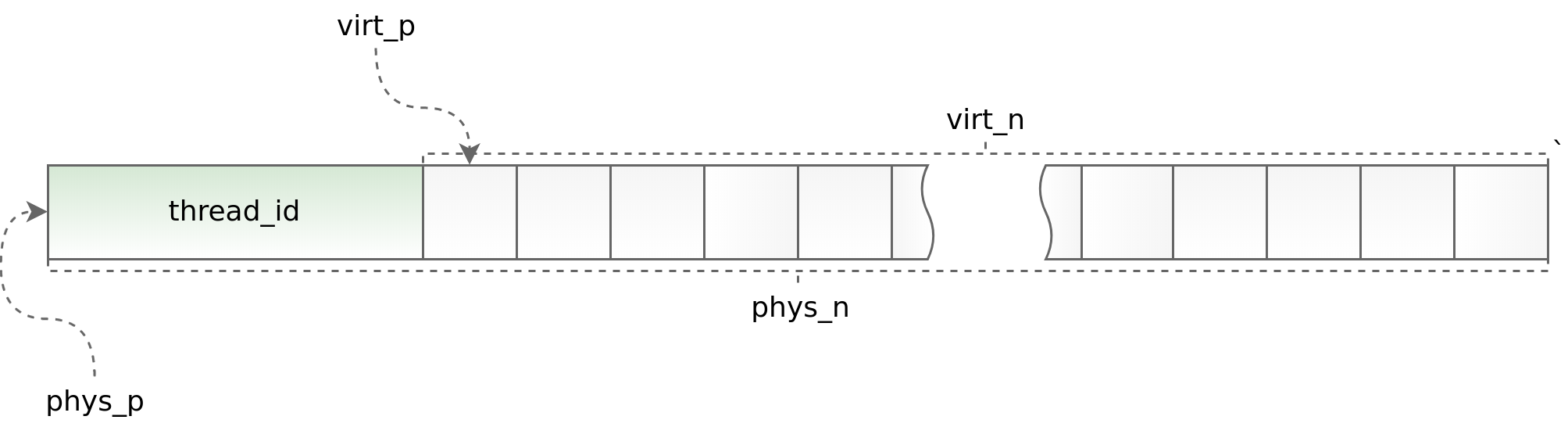
Durch die Verwendung von thread local können Sie einerseits die Arbeit der Plattenverteilung in einer Multithread-Anwendung beschleunigen und andererseits die Architektur der asynchronen Anwendung erheblich einschränken. Sie müssen ein Objekt im selben Stream anfordern und zurückgeben. Dies im Rahmen von boost.asio zu tun, ist manchmal sehr problematisch. Um offensichtlich fehlerhafte Situationen zu verfolgen, platzieren wir am Anfang jedes Objekts den Bezeichner des Streams, in dem die Methode allocate aufgerufen wird. Diese Kennung wird dann in der Freigabemethode überprüft. Die Helfer phys_to_virt_p und virt_to_phys_p helfen dabei.
Snippet (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
Snippet (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
Wenn die Kontrolle über den Stream verloren geht (beim Übertragen eines Objekts zwischen verschiedenen io-Kontexten), ermöglicht ein intelligenter Zeiger die korrekte Freigabe des Objekts. Alles, was er tut, ist, das Objekt zu verteilen, sich an seinen io-Kontext zu erinnern und es dann in std :: shared_ptr mit einem benutzerdefinierten Teiler zu verpacken, der das Objekt nicht sofort an die Verteilung zurückgibt, sondern im zuvor gespeicherten io-Kontext. Dies funktioniert gut, wenn jeder io-Kontext auf einem einzelnen Thread ausgeführt wird. Ansonsten ist dieser Ansatz leider nicht anwendbar.
Snippet (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
Lösung
Nachdem die libsmall-Wrapping-Arbeit abgeschlossen war, haben wir zuerst die Chun-Allokatoren im Stream-Puffer auf die Platte verschoben. Das war ziemlich einfach. Nachdem wir ein positives Ergebnis erhalten hatten, haben wir zunächst den Stream-Puffer selbst und dann alle Objekte in den Server- und Client-Sitzungen mit Plattenzuordnungen versehen.
- variti :: chunk
- variti :: streambuf
- variti :: server_session
- variti :: client_session
Gleichzeitig mussten zusätzliche Probleme gelöst werden, nämlich die Übertragung einfacher Objekte, zusammengesetzter Objekte und Sammlungen an Plattenzuordner. Und wenn es bei den ersten beiden Klassen von Objekten keine ernsthaften Schwierigkeiten gab (zusammengesetzte Objekte werden auf einfache reduziert), stießen wir bei der Übersetzung von Sammlungen auf ernsthafte Schwierigkeiten.
- std :: liste
- std :: deque
- std :: vector
- std :: string
- std :: map
- std :: unordered_map
Eine der Haupteinschränkungen beim Arbeiten mit der Plattenverteilung besteht darin, dass die Anzahl der Objekte unterschiedlicher Typen nicht zu groß sein sollte (je kleiner, desto besser). In diesem Zusammenhang fallen einige Sammlungen möglicherweise unter das Konzept der Plattenverteiler, während andere dies möglicherweise nicht tun.
Für die Platte std :: list funktionieren die Zuweiser hervorragend. Diese Auflistung wird intern mithilfe einer verknüpften Liste implementiert, deren Elemente jeweils eine feste Größe haben. Mit dem Hinzufügen neuer Daten zur std :: -Liste in der Plattenverteilung werden daher keine neuen Objekttypen angezeigt. Die oben angegebene Bedingung ist erfüllt! Die std :: map ist ähnlich aufgebaut. Der einzige Unterschied besteht darin, dass es sich nicht um eine verknüpfte Liste handelt, sondern um einen Baum.
Bei std :: deque sind die Dinge komplizierter. Diese Sammlung wird durch einen zusammenhängenden Speicherblock implementiert, der Zeiger auf Blöcke enthält. Während die Blöcke ziemlich genau sind, verhält sich std :: deque genauso wie std :: list, aber wenn sie enden, wird derselbe Speicherblock neu verteilt. Aus der Sicht von Plattenzuordnern ist jede Speicherumverteilung ein Objekt mit einem neuen Typ. Die Anzahl der Objekte, die der Sammlung direkt hinzugefügt werden, hängt vom Benutzer ab und kann unkontrolliert zunehmen. Diese Situation ist nicht akzeptabel, daher haben wir entweder die Größe von std :: deque vorläufig begrenzt, wo dies möglich war, oder std :: list vorgezogen.
Wenn wir std :: vector und std :: string nehmen, sind sie noch komplizierter. Die Implementierung dieser Auflistungen ähnelt etwas der von std :: deque, nur dass ihr kontinuierlicher Speicherblock erheblich schneller wächst. Wir haben std :: vector und std :: string durch std :: deque und im schlimmsten Fall durch std :: list ersetzt. Ja, wir haben an Funktionalität und sogar an Leistung verloren, aber dies wirkte sich weniger auf das endgültige Bild aus als auf die Optimierungen, für die alles gedacht war.
Wir haben genau dasselbe mit std :: unordered_map gemacht und es zugunsten der selbst geschriebenen variti :: flat_map aufgegeben, die mit std :: deque implementiert wurde. Gleichzeitig haben wir die häufig verwendeten Schlüssel einfach in separaten Variablen zwischengespeichert, wie dies beispielsweise bei den HTTP-Anforderungs-Headern in nginx der Fall ist.
Fazit
Nachdem die Server- und Client-Sitzungen vollständig an die Plattenzuweiser übertragen wurden, haben wir die Zeit für die Arbeit mit einer Gruppe um mehr als das Eineinhalbfache reduziert.
Screenshot des Verstärkers (coldslab):
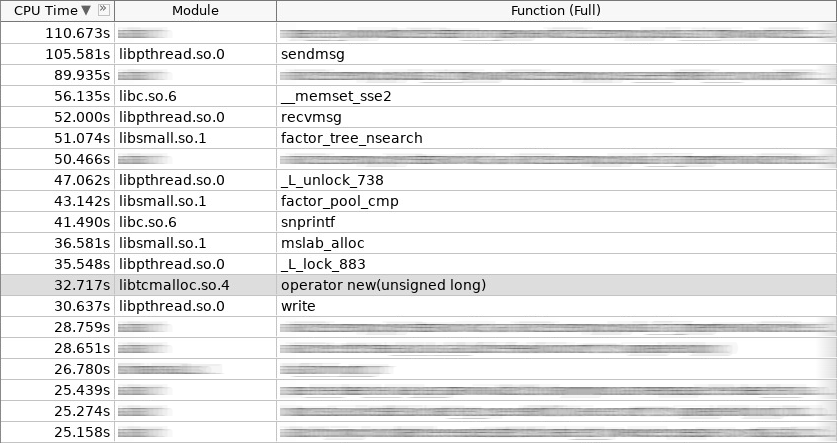
Im Screenshot hat der Operator new 32 Sekunden gearbeitet und der Operator delete - 24 Sekunden. Zu diesem Zeitpunkt wurden weitere Funktionen für die Arbeit mit dem Heap hinzugefügt: smalloc - 21 Sekunden, mslab_alloc - 37 Sekunden, smfree - 8 Sekunden, mslab_free - 21 Sekunden. Insgesamt 143 Sekunden gegenüber 161 Sekunden.
Diese Messungen wurden jedoch sofort nach dem Start des Dienstes durchgeführt, ohne die Caches in der Plattenverteilung zu initialisieren. Nach mehrmaligem Abfeuern aus einem Yandex-Panzer verbesserte sich das Gesamtbild.
Screenshot des Verstärkers (hotslab):
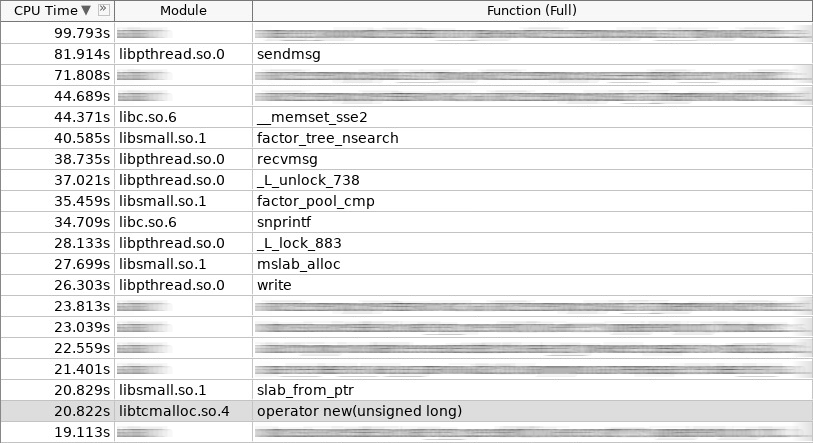
Im Screenshot arbeitete der Operator new 20 Sekunden, smalloc - 16 Sekunden, mslab_alloc - 27 Sekunden, operator delete - 16 Sekunden, smfree - 7 Sekunden, mslab_free - 17 Sekunden. Insgesamt 103 Sekunden gegen 161 Sekunden.
Maßtabelle:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
Im wirklichen Leben sollte das Ergebnis sogar noch besser sein, da Plattenzuweiser nicht nur das Problem der langen Speicherzuweisung und -freigabe lösen, sondern auch die Fragmentierung reduzieren. Ohne Platte sollte sich der Vorgang von Operator Neu und Operator Löschen im Laufe der Zeit nur verlangsamen. Bei Platten bleibt sie immer auf dem gleichen Niveau.
Wie wir sehen können, lösen Plattenzuordner erfolgreich das Speicherzuordnungsproblem häufig verwendeter Objekte. Achten Sie darauf, wenn das Problem des häufigen Erstellens und Entfernens von Objekten für Sie relevant ist. Vergessen Sie jedoch nicht die Einschränkungen, die sie der Architektur Ihrer Anwendung auferlegen! Nicht alle komplexen Objekte können einfach in die Plattenverteilung eingefügt werden. Manchmal muss man viel aufgeben! Je komplexer die Architektur Ihrer Anwendung ist, desto häufiger müssen Sie dafür sorgen, dass das Objekt im Hinblick auf Multithreading wieder in den richtigen Cache gestellt wird. Es kann einfach sein, wenn Sie die Anwendungsarchitektur unter Berücksichtigung der Verwendung von Plattenzuordnern sofort ausgearbeitet haben, aber es wird definitiv Schwierigkeiten bereiten, wenn Sie sich für eine spätere Integration entscheiden.
App
Hier geht es zum Quellcode!