In einem
früheren Artikel haben wir uns mit der Vorhersage von Zeitreihen befasst. Eine logische Fortsetzung wird ein Artikel über die Identifizierung von Anomalien sein.
Bewerbung
Die Erkennung von Anomalien wird beispielsweise in folgenden Bereichen verwendet:
1) Vorhersage von Geräteausfällen
Im Jahr 2010 wurden iranische Zentrifugen vom Stuxnet-Virus angegriffen, wodurch die Ausrüstung auf einen optimalen Modus eingestellt und ein Teil der Ausrüstung aufgrund des beschleunigten Verschleißes deaktiviert wurde.
Wenn Anomaliesuchalgorithmen für das Gerät verwendet würden, könnten Fehlersituationen vermieden werden.

Die Suche nach Anomalien beim Betrieb von Anlagen wird nicht nur in der Nuklearindustrie, sondern auch in der Metallurgie und beim Betrieb von Flugzeugturbinen eingesetzt. Und in anderen Bereichen, in denen der Einsatz von prädiktiver Diagnostik bei unvorhersehbaren Ausfällen billiger ist als mögliche Verluste.
2) Betrug vorhersagen
Wenn die Karte, die Sie in Podolsk verwenden, in Albanien abgezogen wird, ist es möglich, dass die Transaktion weiter überprüft werden sollte.
3) Auffällige Verbrauchermuster erkennen
Wenn einige Kunden ein abnormales Verhalten aufweisen, liegt möglicherweise ein Problem vor, das Sie nicht kennen.
4) Feststellung abnormaler Anforderungen und Belastungen
Wenn die Verkäufe im FMCG-Geschäft unter die Grenze des prognostizierten Konfidenzintervalls gefallen sind, sollten Sie den Grund für das Geschehen finden.
Anomalieerkennungsansätze
1) Die Methode zur Unterstützung von Vektoren mit einer Klasse Ein-Klassen-SVM
Geeignet, wenn die Daten im Trainingssatz der Normalverteilung entsprechen, während der Testsatz Anomalien enthält.
Die Einzelklassen-Support-Vektor-Methode konstruiert eine nichtlineare Oberfläche um den Ursprung. Es ist möglich, den Grenzwert festzulegen, der als abnormal eingestuft wird.
Basierend auf der Erfahrung unseres DATA4-Teams ist One-Class SVM der am häufigsten verwendete Algorithmus zur Lösung des Problems der Anomaliesuche.

2) Wald isolieren - Wald isolieren
Bei der "zufälligen" Methode zum Bauen von Bäumen fallen die Emissionen in den frühen Stadien (in einer geringen Tiefe des Baumes) in die Blätter, d. H. Emissionen lassen sich leichter „isolieren“. Anomale Werte werden bei den ersten Iterationen des Algorithmus extrahiert.

3) Elliptische Hüllkurve und statistische Methoden
Wird verwendet, wenn Daten normal verteilt werden. Je näher die Messung am Ende der Verteilungsmischung liegt, desto anomaler ist der Wert.
Andere statistische Methoden können dieser Klasse zugeordnet werden.

 Bild von dyakonov.org
Bild von dyakonov.org4) Metrische Methoden
Zu den Methoden gehören Algorithmen wie k nächste Nachbarn, k nächster Nachbar, ABOD (winkelbasierte Ausreißererkennung) oder LOF (lokaler Ausreißerfaktor).
Geeignet, wenn der Abstand zwischen den Werten in den Zeichen gleich oder normal ist (um die Boa in den Papageien nicht zu messen).
Der Algorithmus von k nächsten Nachbarn legt nahe, dass sich Normalwerte in einem bestimmten Bereich des mehrdimensionalen Raums befinden und der Abstand zu den Anomalien größer ist als zu der sich trennenden Hyperebene.
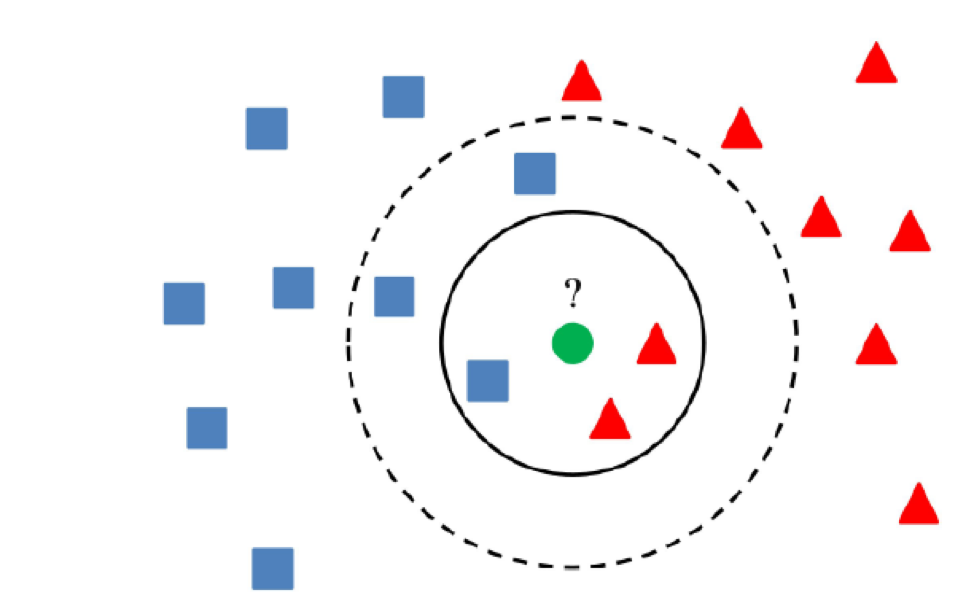
5) Clustermethoden
Das Wesentliche bei Cluster-Methoden ist, dass der Wert als anomal angesehen werden kann, wenn der Wert mehr als einen bestimmten Abstand von den Zentren der Cluster aufweist.
Die Hauptsache ist, einen Algorithmus zu verwenden, der Daten korrekt gruppiert, was von der spezifischen Aufgabe abhängt.
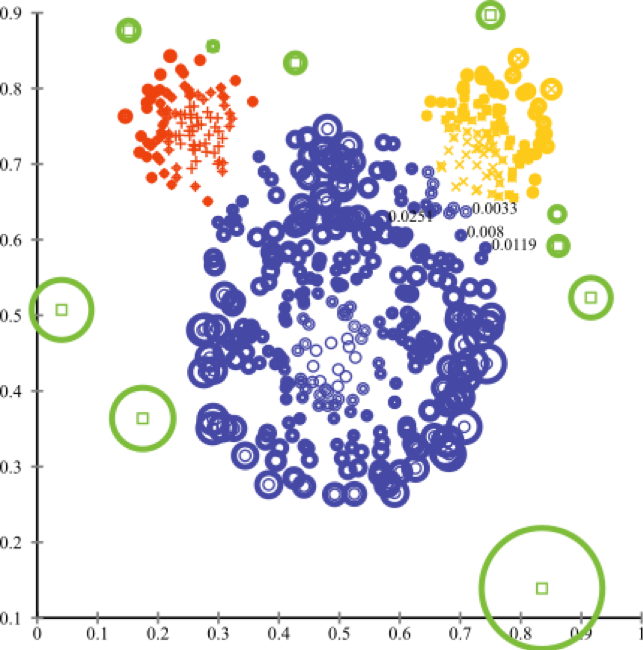
6) Hauptkomponentenmethode
Geeignet, wenn die Bereiche mit den größten Abweichungen hervorgehoben werden.
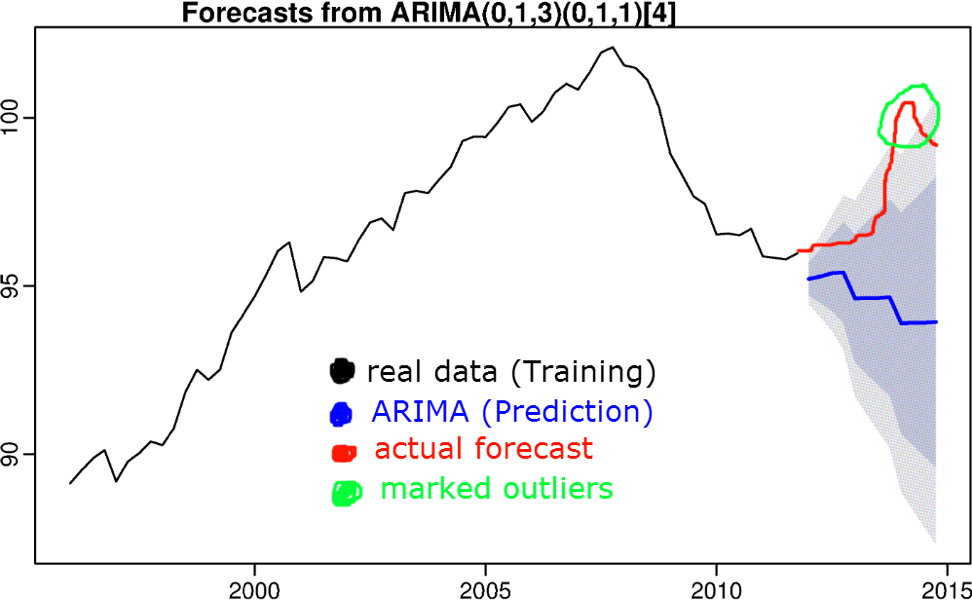
7) Algorithmen basierend auf Zeitreihenprognosen
Die Idee ist, dass, wenn ein Wert aus einem Vorhersage-Konfidenzintervall herausgeschlagen wird, der Wert als abnormal betrachtet wird. Algorithmen wie Triple-Anti-Aliasing, S (ARIMA), Boosten usw. werden verwendet, um die Zeitreihen vorherzusagen.
Algorithmen zur Vorhersage von Zeitreihen wurden in einem früheren Artikel erörtert.
8) Ausbildung mit einem Lehrer (Regression, Klassifizierung)
Wenn die Daten dies zulassen, verwenden wir Algorithmen von der linearen Regression bis zu wiederkehrenden Netzwerken. Wir messen den Unterschied zwischen der Vorhersage und dem tatsächlichen Wert und schließen daraus, wie stark die Daten von der Norm abweichen. Es ist wichtig, dass der Algorithmus über ausreichende Verallgemeinerungsfähigkeiten verfügt und die Trainingsprobe keine abnormalen Werte enthält.
9) Modellversuche
Wir nähern uns dem Problem der Suche nach Anomalien als der Aufgabe, nach Empfehlungen zu suchen. Wir zerlegen unsere Merkmalsmatrix mit SVD- oder Faktorisierungsmaschinen, und die Werte in der neuen Matrix, die sich erheblich von den ursprünglichen unterscheiden, werden als abnormal angesehen.
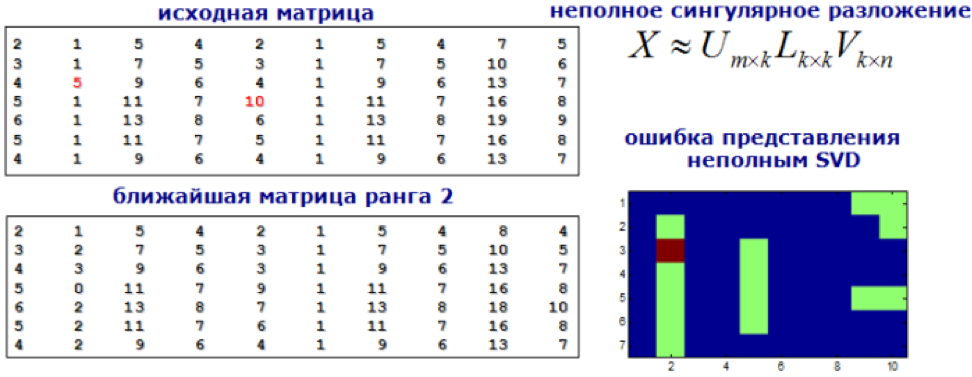 Bild von dyakonov.org
Bild von dyakonov.orgFazit
In diesem Artikel haben wir die grundlegenden Ansätze zur Erkennung von Anomalien untersucht.
Die Suche nach Anomalien kann in vielerlei Hinsicht als Kunst bezeichnet werden. Es gibt keinen idealen Algorithmus oder Ansatz, dessen Anwendung alle Probleme löst. Am häufigsten wird eine Reihe von Methoden verwendet, um einen bestimmten Fall zu lösen. Anomalien werden mithilfe der Einzelklassenmethode von Support-Vektoren, Isolieren von Gesamtstrukturen, Metrik- und Cluster-Methoden sowie mithilfe der Hauptkomponenten und Prognosezeitreihen gesucht.
Wenn Sie andere Methoden kennen, schreiben Sie darüber im Kommentarbereich des Artikels.