Die klassische Frage, die ein Entwickler an seinen DBA oder einen Geschäftsinhaber, einen PostgreSQL-Berater, stellt, klingt fast immer gleich:
„Warum werden Abfragen so lange in der Datenbank ausgeführt?“Die traditionellen Gründe:
- ineffizienter Algorithmus
als Sie beschlossen, mehrere CTEs für ein paar Zehntausende von Datensätzen zu verbinden - irrelevante Statistiken
wenn sich die tatsächliche Verteilung der Daten in der Tabelle bereits stark von der letzten Erfassung durch ANALYZE unterscheidet - "Gag" von Ressourcen
und die zugewiesene Rechenleistung der CPU reicht bereits nicht aus, Gigabyte Speicher werden ständig gepumpt oder die Festplatte hält nicht mit der gesamten Datenbank „Wishlist“ mit - Blockierung von konkurrierenden Prozessen
Und wenn die Sperren sehr schwer zu erfassen und zu analysieren sind, benötigen wir für alles andere
einen Abfrageplan , der mit
dem EXPLAIN-Operator (
besser natürlich sofort EXPLAIN (ANALYZE, BUFFERS) ... ) oder
dem auto_explain-Modul abgerufen werden kann .
Aber, wie in der gleichen Dokumentation gesagt,
"Den Plan zu verstehen ist eine Kunst, und um ihn zu meistern, braucht man etwas Erfahrung, ..."
Aber Sie können darauf verzichten, wenn Sie das richtige Werkzeug verwenden!
Wie sieht ein Abfrageplan normalerweise aus? So etwas in der Art:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
oder so:
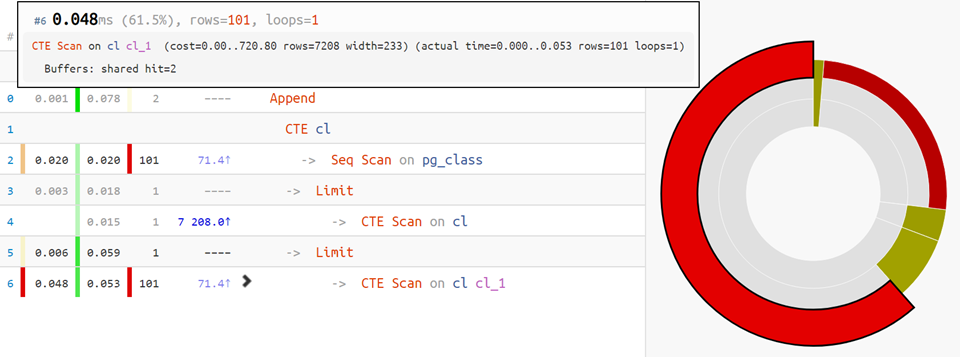
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
Aber den Plan mit dem Text „vom Blatt“ zu lesen, ist sehr schwierig und beliebt:
- Der Knoten zeigt die Summe der Teilbaumressourcen an
Das heißt, um zu verstehen, wie viel Zeit es gedauert hat, einen bestimmten Knoten auszuführen, oder wie viel genau dieses Lesen aus der Tabelle Daten von der Festplatte ausgelöst hat - Sie müssen irgendwie eine von der anderen subtrahieren - Die Knotenzeit muss mit Schleifen multipliziert werden
Ja, Subtraktion ist nicht die schwierigste Operation, die „im Kopf“ ausgeführt werden muss. Schließlich wird die Laufzeit über eine Ausführung des Knotens gemittelt angezeigt, und es können Hunderte von ihnen vorhanden sein - Nun, und all dies zusammen macht es schwierig, die Hauptfrage zu beantworten - also, wer ist das „schwächste Glied“ ?
Als wir versuchten, dies einigen hundert unserer Entwickler zu erklären, stellten wir fest, dass es von außen ungefähr so aussieht:

Und das heißt, wir brauchen ...
Instrument
Darin haben wir versucht, alle Schlüsselmechaniken zu sammeln, die gemäß dem Plan helfen, und zu verstehen, "wer schuld ist und was zu tun ist". Teilen Sie der Community einige Ihrer Erfahrungen mit.
Treffen und verwenden -
explain.tensor.ruKlare Pläne
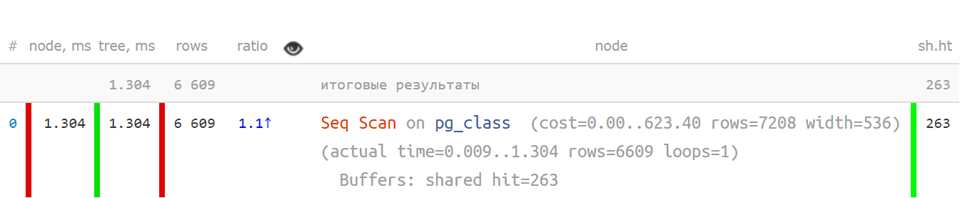
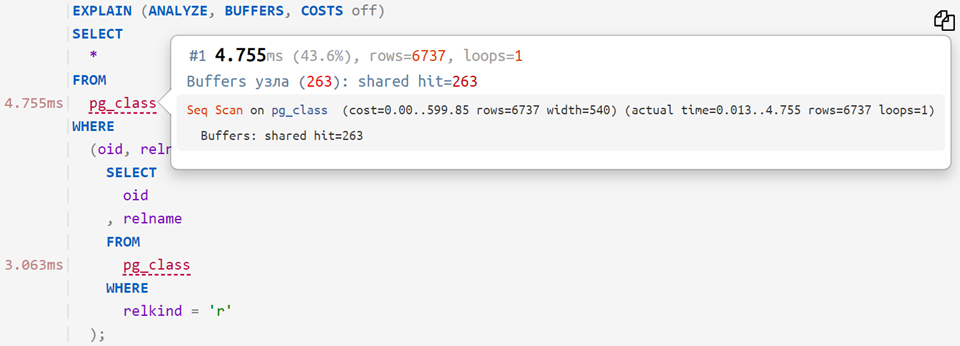
Ist es einfach, einen Plan zu verstehen, wenn er so aussieht?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
Nicht sehr.
Aber so,
in Kurzform , wenn die Schlüsselindikatoren getrennt sind, ist es schon viel klarer:
Wenn der Plan jedoch komplizierter ist,
hilft die Verteilung der Kreisdiagrammzeit nach Knoten:
Nun, für die schwierigsten Optionen beeilt sich
das Ausführungsdiagramm , um zu helfen:
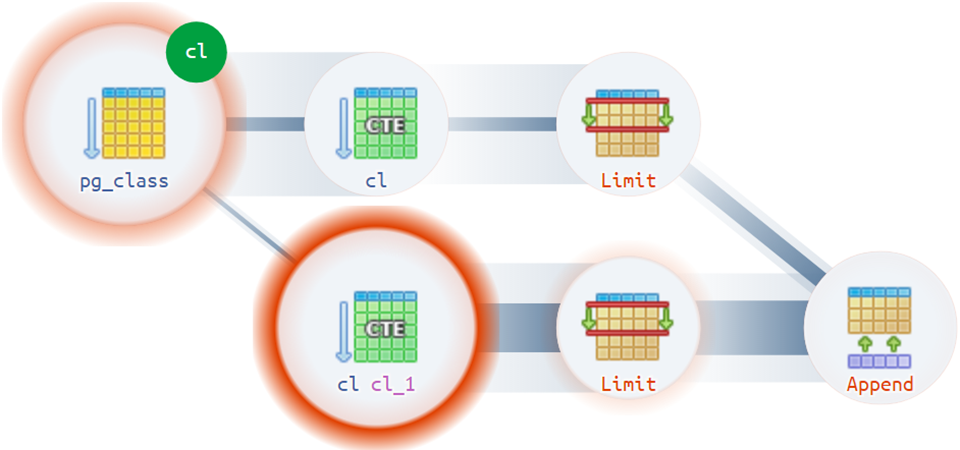
Es gibt zum Beispiel nicht ganz einfache Situationen, in denen ein Plan mehr als eine tatsächliche Wurzel haben kann:
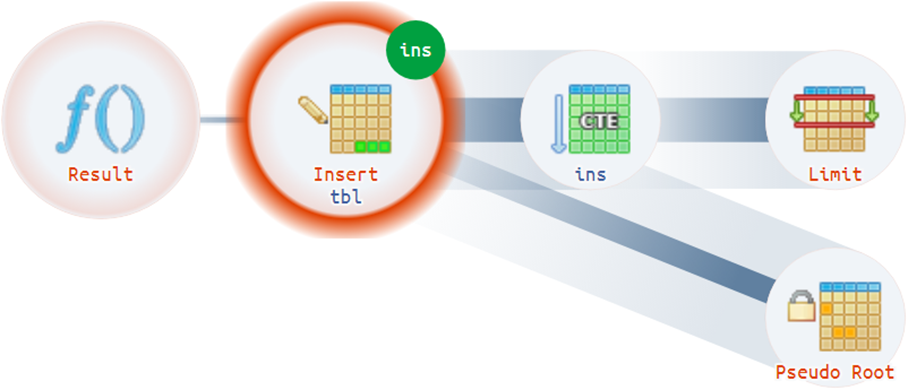
Strukturelle Tipps
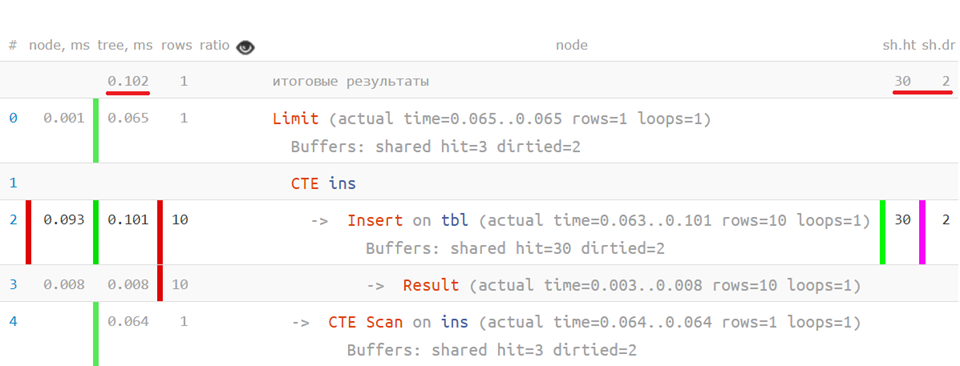
Nun, und wenn die gesamte Struktur des Plans und seine wunden Stellen bereits angelegt und sichtbar sind - warum nicht mit dem Entwickler hervorheben und mit der „russischen Sprache“ erklären?

Wir haben bereits ein paar Dutzend solcher Empfehlungsvorlagen gesammelt.
Abfrage-Profiler
Wenn Sie nun die ursprüngliche Abfrage in den analysierten Plan einfügen, können Sie sehen, wie viel Zeit jeder einzelne Operator in Anspruch genommen hat.
... oder doch so:

Ersetzung von Parametern in der Anfrage
Wenn Sie nicht nur die Anfrage an den Plan "angehängt" haben, sondern auch deren Parameter aus der DETAIL-Zeile des Protokolls, können Sie diese zusätzlich in eine der folgenden Optionen kopieren:
- mit Ersetzung von Werten in der Anfrage
zur direkten Ausführung auf der Basis und weiteren Profilierung
SELECT 'const', 'param'::text;
- mit Wertersetzung über PREPARE / EXECUTE
um die Arbeit des Schedulers zu emulieren, wenn der parametrische Teil ignoriert werden kann - zum Beispiel bei der Arbeit an partitionierten Tabellen
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Pläne Archiv
Einfügen, analysieren, mit Kollegen teilen! Die Pläne bleiben im Archiv, und Sie können später darauf
zurückgreifen :
explain.tensor.ru/archiveWenn Sie jedoch nicht möchten, dass andere Ihren Plan sehen, müssen Sie das Kontrollkästchen "Nicht im Archiv veröffentlichen" aktivieren.
In den folgenden Artikeln werde ich auf die Schwierigkeiten und Lösungen eingehen, die sich bei der Analyse des Plans ergeben.