Hallo!
Es kommt vor, dass Sie sich einen Film ansehen und in Ihrem Kopf gibt es nur eine Frage: "Bekomme ich wieder Clickbait?" Wir werden dieses Problem lösen und nur geeignete Filme anschauen. Ich empfehle, ein wenig mit den Daten zu experimentieren und ein einfaches neuronales Netzwerk zu schreiben, um den Film zu bewerten.
Unser Experiment basiert auf der Sentiment-Analyse-Technologie, um die Stimmung des Publikums für ein Produkt zu bestimmen. Als Daten nehmen wir einen Datensatz mit Nutzerkritiken zu IMDb-Filmen. Mit der Entwicklungsumgebung von Google Colab können Sie Ihr neuronales Netzwerk dank des kostenlosen Zugriffs auf die GPU (NVidia Tesla K80) schnell trainieren.
Ich benutze die Keras-Bibliothek, mit deren Hilfe ich ein universelles Modell zur Lösung ähnlicher Probleme des maschinellen Lernens aufbauen werde. Ich benötige das Backend TensorFlow, die Standardversion in Colab 1.15.0, also aktualisiere einfach auf 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Als nächstes importieren wir alle notwendigen Module für die Datenvorverarbeitung und Modellbildung. In früheren Artikeln liegt der Schwerpunkt auf Bibliotheken, die Sie dort nachschlagen können.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Analysieren von IMDb-Daten
Der IMDb-Datensatz enthält 50.000 Filmkritiken von Benutzern, die als positiv (1) und negativ (0) eingestuft wurden.
- Bewertungen werden vorverarbeitet, und jede von ihnen wird durch eine Folge von Wortindizes in Form von ganzen Zahlen codiert
- Wörter in Rezensionen werden nach ihrer Gesamthäufigkeit im Datensatz indiziert. Beispielsweise codiert die Ganzzahl „2“ das zweithäufigste verwendete Wort
- 50.000 Testberichte sind in zwei Gruppen unterteilt: 25.000 für Schulungen und 25.000 für Tests.
Laden Sie das in Keras integrierte Dataset herunter. Da die Daten in einem Verhältnis von 50: 50 in Training und Test unterteilt sind, werde ich sie kombinieren, damit ich sie später durch 80: 20 teilen kann.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Datenexploration
Schauen wir uns an, womit wir arbeiten.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

Sie können sehen, dass alle Daten zu zwei Kategorien gehören: 0 oder 1, die die Stimmung der Überprüfung darstellen. Der gesamte Datensatz enthält 9998 eindeutige Wörter, die durchschnittliche Bewertungsgröße beträgt 234 Wörter mit einer Standardabweichung von 173.
Schauen wir uns die erste Bewertung aus diesem Datensatz an, die als positiv markiert ist.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

Datenaufbereitung
Es ist Zeit, die Daten vorzubereiten. Wir müssen jede Umfrage vektorisieren und mit Nullen füllen, damit der Vektor genau 10.000 Zahlen enthält. Dies bedeutet, dass jede Überprüfung, die kürzer als 10.000 Wörter ist, mit Nullen gefüllt wird. Ich mache das, weil die größte Übersicht fast dieselbe Größe hat und jedes Eingabeelement unseres neuronalen Netzwerks dieselbe Größe haben sollte. Sie müssen die Variablen auch in einen Float-Typ konvertieren.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
Als nächstes teile ich den Datensatz wie vereinbart in Trainings- und Testdaten 4: 1 auf.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
Erstellen und trainieren Sie ein Modell
Das Ding ist klein, es bleibt nur ein Modell zu schreiben und es zu trainieren. Beginnen Sie mit der Auswahl eines Typs. In Keras sind zwei Arten von Modellen verfügbar: sequenziell und mit einer funktionalen API. Dann müssen Sie Eingabe-, ausgeblendete und Ausgabe-Layer hinzufügen.
Um eine Umschulung zu vermeiden, verwenden wir einen „Ausfall“ zwischen den Ebenen. Auf jeder Ebene verwenden wir die Funktion „Dichte“, um die Ebenen vollständig miteinander zu verbinden. In ausgeblendeten Ebenen wird die Aktivierungsfunktion "relu" verwendet, was fast immer zu zufriedenstellenden Ergebnissen führt. Auf der Ausgabeebene verwenden wir eine Sigmoid-Funktion, die die Werte im Bereich von 0 bis 1 umnormiert.
Ich benutze den Adam Optimizer, der während des Trainings die Gewichte ändert.
Wir verwenden die binäre Kreuzentropie als Verlustfunktion und die Genauigkeit als Messgröße.
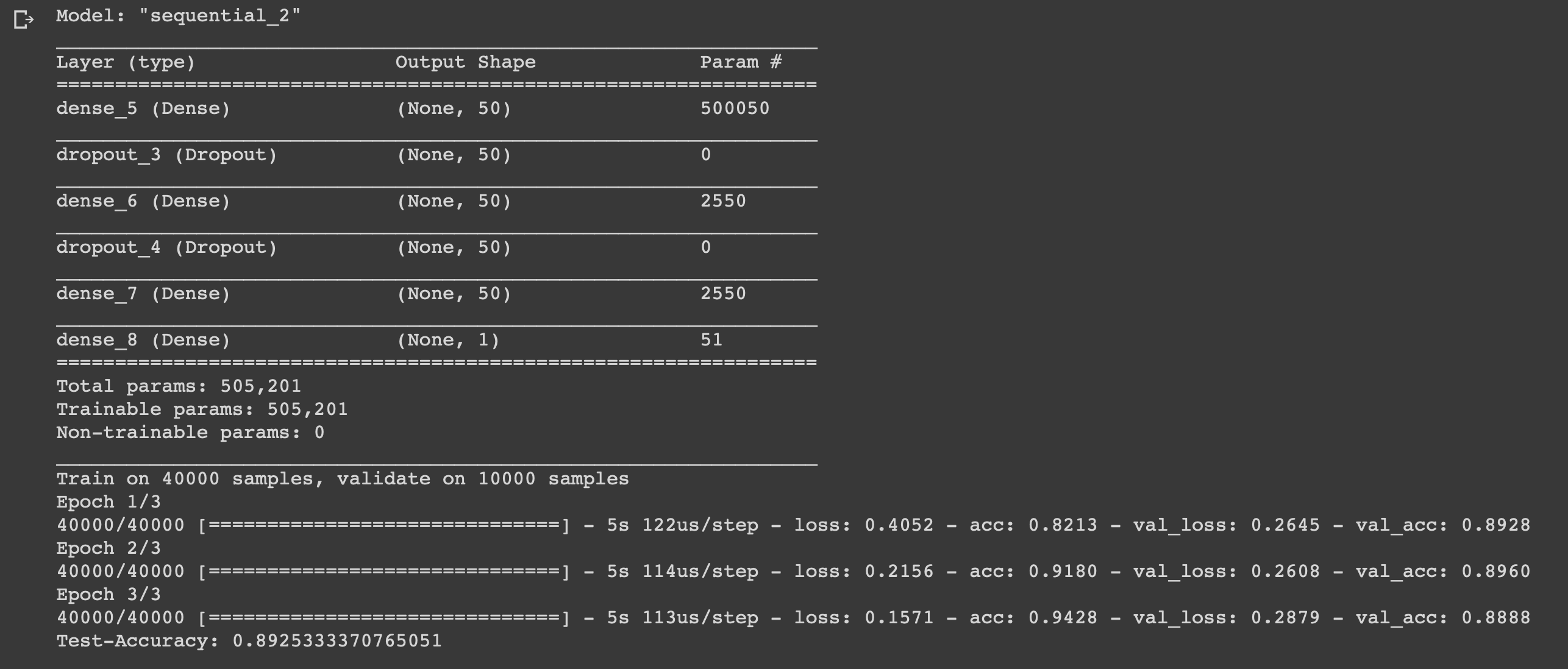
Jetzt können Sie unser Modell trainieren. Wir werden dies mit einer Chargengröße von 500 und nur drei Epochen tun, da sich herausstellte, dass das Modell bei längerem Training neu geschult wird.
model = models.Sequential()
Fazit
Wir haben ein einfaches neuronales Netzwerk mit sechs Schichten erstellt, mit dem die Stimmung von Filmemachern mit einer Genauigkeit von 0,89 berechnet werden kann. Um coole Filme anzusehen, ist es natürlich überhaupt nicht notwendig, ein neuronales Netzwerk zu schreiben, aber dies war nur ein weiteres Beispiel dafür, wie Sie die Daten nutzen und davon profitieren können, denn Sie brauchen sie dafür. Das neuronale Netzwerk ist universell, da es einfach aufgebaut ist und einige Parameter ändert. Sie können es an völlig unterschiedliche Aufgaben anpassen.
Fühlen Sie sich frei, Ihre Ideen in den Kommentaren zu schreiben.