
Das Entwerfen von Streaming-Analytics- und Streaming-Datenverarbeitungssystemen hat seine eigenen Nuancen, seine eigenen Probleme und seinen eigenen technologischen Stack. Wir haben darüber in der nächsten
offenen Lektion gesprochen , die am Vorabend des Starts des
Data Engineer- Kurses stattfand.
Auf dem Webinar diskutiert:
- wenn Streaming-Verarbeitung benötigt wird;
- Welche Elemente sind in SPOD enthalten, mit welchen Tools können diese Elemente implementiert werden?
- Wie Sie Ihr eigenes Clickstream-Analysesystem erstellen.
Dozent -
Yegor Mateshuk , Senior Data Engineer bei MaximaTelecom.
Wann wird Streaming benötigt? Stream vs Batch
Zunächst müssen wir herausfinden, wann Streaming und Stapelverarbeitung erforderlich sind. Lassen Sie uns die Stärken und Schwächen dieser Ansätze erklären.
Also, die Nachteile der Stapelverarbeitung:- Daten werden mit einer Verzögerung geliefert. Da wir einen bestimmten Berechnungszeitraum haben, hinken wir in diesem Zeitraum immer der Echtzeit nach. Und je mehr Iteration, desto mehr hinken wir hinterher. Dadurch erhalten wir eine Zeitverzögerung, die in einigen Fällen kritisch ist;
- Es entsteht eine Spitzenbelastung des Eisens. Wenn wir eine Menge im Batch-Modus berechnen, haben wir am Ende des Zeitraums (Tag, Woche, Monat) eine Spitzenlast, weil Sie eine Menge Dinge berechnen müssen. Wohin führt das? Erstens beginnen wir uns gegen Grenzen auszuruhen, die, wie Sie wissen, nicht unendlich sind. Infolgedessen läuft das System regelmäßig bis zum Limit, was häufig zu Fehlern führt. Zweitens, da alle diese Jobs zur gleichen Zeit starten, konkurrieren sie und werden relativ langsam berechnet. Sie können also nicht mit einem schnellen Ergebnis rechnen.
Die Stapelverarbeitung hat jedoch folgende Vorteile:- hoher Wirkungsgrad. Wir werden nicht tiefer gehen, da Effizienz mit Komprimierung, Frameworks und der Verwendung von Spaltenformaten usw. verbunden ist. Fakt ist, dass die Stapelverarbeitung effizienter ist, wenn Sie die Anzahl der verarbeiteten Datensätze pro Zeiteinheit berücksichtigen.
- einfache Entwicklung und Unterstützung. Sie können jeden Teil der Daten verarbeiten, indem Sie sie nach Bedarf testen und neu zählen.
Vorteile der Streaming-Datenverarbeitung (Streaming):- Ergebnis in Echtzeit. Wir warten nicht auf das Ende eines Zeitraums: Sobald die Daten (auch nur in sehr geringem Umfang) bei uns eintreffen, können wir sie sofort verarbeiten und weitergeben. Das heißt, das Ergebnis strebt per Definition nach Echtzeit.
- gleichmäßige Belastung des Eisens. Es ist klar, dass es tägliche Zyklen usw. gibt, die Last ist jedoch immer noch über den Tag verteilt, und sie fällt gleichmäßiger und vorhersehbarer aus.
Der Hauptnachteil der Streaming-Verarbeitung:- Komplexität der Entwicklung und Unterstützung. Erstens ist das Testen, Verwalten und Abrufen von Daten im Vergleich zum Batch etwas schwieriger. Die zweite Schwierigkeit (tatsächlich ist dies das grundlegendste Problem) ist mit Rollbacks verbunden. Wenn Jobs nicht funktionierten und ein Fehler aufgetreten ist, ist es sehr schwierig, genau den Moment zu erfassen, in dem alles kaputt gegangen ist. Die Lösung des Problems erfordert mehr Aufwand und Ressourcen als die Stapelverarbeitung.
Wenn Sie sich überlegen,
ob Sie Streams benötigen , beantworten Sie die folgenden Fragen für sich selbst:
- Benötigen Sie wirklich Echtzeit?
- Gibt es viele Streaming-Quellen?
- Ist es wichtig, einen Datensatz zu verlieren?
Schauen wir uns
zwei Beispiele an :
Beispiel 1. Aktienanalyse für den Einzelhandel:- Die Warenanzeige ändert sich nicht in Echtzeit.
- Daten werden am häufigsten im Batch-Modus geliefert;
- Informationsverlust ist kritisch.
In diesem Beispiel ist es besser, Batch zu verwenden.
Beispiel 2. Analyse für ein Webportal:- Die Analysegeschwindigkeit bestimmt die Reaktionszeit auf ein Problem.
- Daten kommen in Echtzeit;
- Der Verlust einer kleinen Menge von Benutzeraktivitätsinformationen ist akzeptabel.
Stellen Sie sich vor, dass Analytics widerspiegelt, wie sich Besucher eines Webportals mit Ihrem Produkt fühlen. Beispielsweise haben Sie eine neue Version herausgebracht und müssen innerhalb von 10 bis 30 Minuten wissen, ob alles in Ordnung ist, wenn benutzerdefinierte Funktionen fehlerhaft sind. Angenommen, der Text auf der Schaltfläche "Bestellen" ist nicht mehr vorhanden. Mit Analytics können Sie schnell auf einen starken Rückgang der Anzahl der Bestellungen reagieren und sofort erkennen, dass ein Rollback erforderlich ist.
Daher ist es im zweiten Beispiel besser, Streams zu verwenden.
SPOD-Elemente
Datenverarbeitungsingenieure erfassen, verschieben, liefern, konvertieren und speichern genau diese Daten (ja, die Datenspeicherung ist ebenfalls ein aktiver Prozess!).
Um ein Streaming Data Processing System (SPOD) aufzubauen, benötigen wir daher die folgenden Elemente:
- Datenlader (Mittel zur Datenlieferung an den Speicher);
- Datenaustauschbus (dies ist nicht immer erforderlich, aber in Streams ist dies nicht möglich, da Sie ein System benötigen, über das Sie Daten in Echtzeit austauschen können.)
- Datenspeicherung (wie ohne);
- ETL-Engine (für verschiedene Filter-, Sortier- und andere Vorgänge erforderlich);
- BI (um Ergebnisse anzuzeigen);
- Orchestrator (verbindet den gesamten Prozess und organisiert die mehrstufige Datenverarbeitung).
In unserem Fall betrachten wir die einfachste Situation und konzentrieren uns nur auf die ersten drei Elemente.
Tools zur Datenstromverarbeitung
Wir haben mehrere "Kandidaten" für die Rolle des
Datenladers :
- Apache-Gerinne
- Apache nifi
- Streamset
Apache-Gerinne
Das erste, worüber wir sprechen, ist
Apache Flume , ein Tool zum Transportieren von Daten zwischen verschiedenen Quellen und Repositorys.

Vorteile:
- es gibt fast überall
- lange gebraucht
- flexibel und erweiterbar genug
Nachteile:
- unbequeme Konfiguration
- schwer zu überwachen
Die Konfiguration sieht ungefähr so aus:

Oben erstellen wir einen einfachen Kanal, der sich auf dem Port befindet, Daten von dort entnimmt und einfach protokolliert. Prinzipiell ist dies, um einen Prozess zu beschreiben, immer noch normal, aber wenn Sie Dutzende solcher Prozesse haben, verwandelt sich die Konfigurationsdatei in eine Hölle. Jemand fügt einige visuelle Konfiguratoren hinzu, aber warum sollte man sich die Mühe machen, wenn es Werkzeuge gibt, die es aus der Box schaffen? Zum Beispiel die gleichen NiFi und StreamSets.
Apache nifi
Tatsächlich hat es die gleiche Funktion wie Flume, verfügt jedoch über eine visuelle Benutzeroberfläche, was insbesondere bei vielen Prozessen ein großes Plus darstellt.
Einige Fakten zu NiFi
- ursprünglich bei der NSA entwickelt;
- Hortonworks wird jetzt unterstützt und weiterentwickelt.
- Teil von HDF von Hortonworks;
- hat eine spezielle Version von MiNiFi zum Sammeln von Daten von Geräten.
Das System sieht ungefähr so aus:
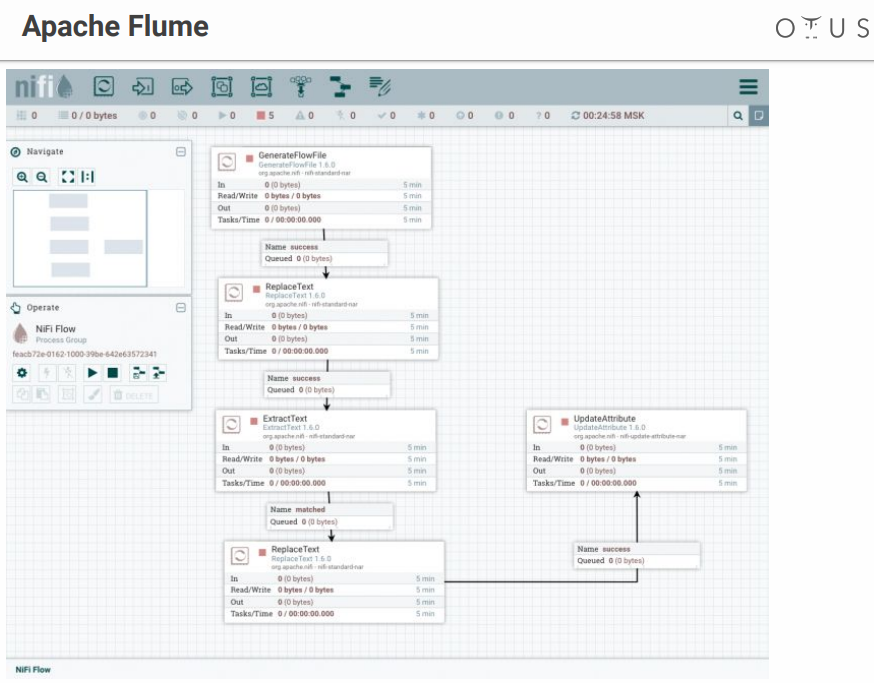
Wir haben ein Feld für Kreativität und Phasen der Datenverarbeitung, die wir dort werfen. Es gibt viele Anschlüsse für alle möglichen Systeme usw.
Streamset
Es ist auch ein Datenfluss-Kontrollsystem mit einer visuellen Schnittstelle. Es wurde von Leuten aus Cloudera entwickelt, ist einfach als Paket auf CDH zu installieren und verfügt über eine spezielle Version von SDC Edge zum Sammeln von Daten von Geräten.
Besteht aus zwei Komponenten:
- DEZA - ein System zur direkten Datenverarbeitung (kostenlos);
- StreamSets Control Hub - ein Kontrollzentrum für mehrere DEZA mit zusätzlichen Funktionen für die Entwicklung von Paylines (kostenpflichtig).
Es sieht ungefähr so aus:

Unangenehmer Moment - StreamSets haben sowohl kostenlose als auch kostenpflichtige Teile.
Datenbus
Nun wollen wir herausfinden, wo wir diese Daten hochladen werden. Bewerber:
Apache Kafka ist die beste Option, aber wenn Sie RabbitMQ oder NATS in Ihrem Unternehmen haben und ein wenig Analyse hinzufügen müssen, ist die Bereitstellung von Kafka von Grund auf nicht sehr rentabel.
In allen anderen Fällen ist Kafka eine gute Wahl. Tatsächlich handelt es sich um einen Nachrichtenbroker mit horizontaler Skalierung und großer Bandbreite. Es ist perfekt in das gesamte Ökosystem der Tools für die Arbeit mit Daten integriert und hält hohen Belastungen stand. Es hat eine universelle Schnittstelle und ist das Kreislaufsystem unserer Datenverarbeitung.
Im Inneren ist Kafka in Topic unterteilt - ein bestimmter separater Datenstrom von Nachrichten mit demselben Schema oder zumindest mit demselben Zweck.
Um die nächste Nuance zu erörtern, müssen Sie berücksichtigen, dass die Datenquellen geringfügig variieren können. Das Datenformat ist sehr wichtig:

Das Apache Avro-Daten-Serialisierungsformat verdient besondere Erwähnung. Das System ermittelt mithilfe von JSON die Datenstruktur (Schema), die in ein
kompaktes Binärformat serialisiert wird. Daher sparen wir eine große Datenmenge, und die Serialisierung / Deserialisierung ist billiger.
Alles scheint in Ordnung zu sein, aber das Vorhandensein separater Dateien mit Schaltkreisen stellt ein Problem dar, da wir Dateien zwischen verschiedenen Systemen austauschen müssen. Es scheint einfach zu sein, aber wenn Sie in verschiedenen Abteilungen arbeiten, können die Kollegen am anderen Ende etwas ändern und sich beruhigen, und alles wird für Sie zusammenbrechen.
Um nicht alle diese Dateien auf Flash-Laufwerke, Disketten und Höhlenmalereien zu übertragen, gibt es einen speziellen Dienst - Schema-Registry. Dies ist ein Dienst zum Synchronisieren von Avro-Schemata zwischen Diensten, die von Kafka schreiben und lesen.

In Bezug auf Kafka ist der Produzent derjenige, der schreibt, der Konsument derjenige, der die Daten konsumiert (liest).
Data Warehouse
Herausforderer (in der Tat gibt es viel mehr Optionen, aber nur wenige):
- HDFS + Hive
- Kudu + Impala
- Clickhouse
Denken Sie vor der Auswahl eines Repositorys daran, was
Idempotenz ist . Wikipedia sagt, dass die Idempotenz (lat. Idem - das Gleiche + Potenzen - fähig) - die Eigenschaft eines Objekts oder einer Operation, wenn die Operation erneut auf das Objekt angewendet wird, dasselbe Ergebnis wie die erste ergibt. In unserem Fall sollte der Prozess der Streaming-Verarbeitung so aufgebaut sein, dass beim erneuten Füllen der Quelldaten das Ergebnis korrekt bleibt.
So erreichen Sie dies in Streaming-Systemen:
- identifiziere eine eindeutige ID (kann zusammengesetzt sein)
- Verwenden Sie diese ID, um Daten zu deduplizieren
Der HDFS + Hive-Speicher
bietet keine Möglichkeit, Aufnahmen
sofort zu streamen. Daher haben wir:
Kudu ist ein für analytische Abfragen geeignetes Repository, das jedoch einen Primärschlüssel für die Deduplizierung besitzt.
Impala ist die SQL-Schnittstelle zu diesem Repository (und mehreren anderen).
Bei ClickHouse handelt es sich um eine Analysedatenbank von Yandex. Der Hauptzweck ist die Analyse einer Tabelle, die mit einem großen Strom von Rohdaten gefüllt ist. Von den Vorteilen - es gibt eine ReplacingMergeTree-Engine für die Schlüsseldeduplizierung (die Deduplizierung ist platzsparend und hinterlässt möglicherweise Duplikate. In einigen Fällen müssen Sie die
Nuancen berücksichtigen).
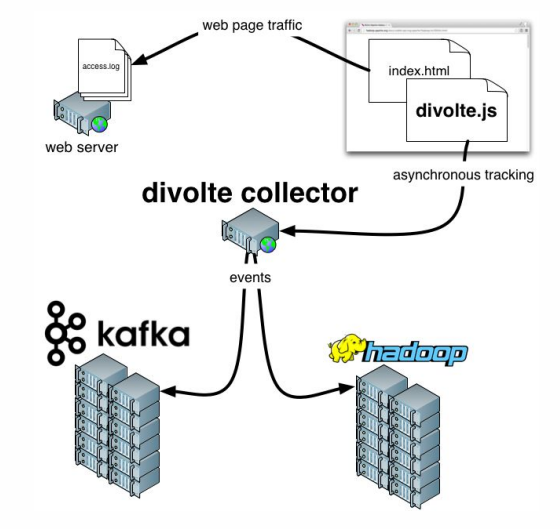
Es bleibt noch ein paar Worte über
Divolte hinzuzufügen . Wenn Sie sich erinnern, haben wir darüber gesprochen, dass einige Daten erfasst werden müssen. Wenn Sie Analysen für ein Portal schnell und einfach organisieren möchten, ist Divolte ein hervorragender Dienst zum Erfassen von Benutzerereignissen auf einer Webseite über JavaScript.
Praktisches Beispiel
Was versuchen wir zu tun?
Versuchen wir, eine Pipeline zu erstellen, um Clickstream-Daten in Echtzeit zu erfassen.
Clickstream ist ein virtueller Footprint, den ein Benutzer auf Ihrer Website hinterlässt. Wir werden Daten mit Divolte erfassen und in Kafka schreiben.

Sie benötigen Docker, um arbeiten zu können. Außerdem müssen Sie das
folgende Repository klonen. Alles, was passiert, wird in Containern gestartet.
Wenn Sie mehrere Container gleichzeitig
ausführen möchten, wird
docker-compose.yml verwendet. Zusätzlich gibt es eine
Docker-Datei , die unsere StreamSets mit bestimmten Abhängigkeiten kompiliert.
Es gibt auch drei Ordner:
- clickhouse-Daten werden in clickhouse-Daten geschrieben
- genau das gleiche daddy ( sdc-daten ) haben wir für streamsets, wo das system konfigurationen speichern kann
- Der dritte Ordner ( Beispiele ) enthält eine Anforderungsdatei und eine Pipe-Konfigurationsdatei für StreamSets

Geben Sie zum Starten den folgenden Befehl ein:
docker-compose up
Und wir freuen uns, wie langsam, aber sicher Container starten. Nach dem Start können wir zur Adresse
http: // localhost: 18630 / gehen und sofort Divolte berühren:

Wir haben also Divolte, die bereits einige Events erhalten und in Kafka aufgenommen hat. Versuchen wir, sie mit StreamSets zu berechnen:
http: // localhost: 18630 / (password / login - admin / admin).

Um nicht zu leiden, ist es besser,
Pipeline zu
importieren und sie beispielsweise als
clickstream_pipeline zu bezeichnen . Und aus dem Beispielordner importieren wir
clickstream.json . Wenn alles in Ordnung ist, sehen
wir folgendes Bild :

Also stellten wir eine Verbindung zu Kafka her, registrierten, welche Kafka wir brauchten, registrierten, welches Thema uns interessierte, wählten dann die Felder aus, die uns interessierten, und steckten dann Kafka ab, um zu registrieren, welche Kafka und welches Thema wir wollten. Die Unterschiede bestehen darin, dass in einem Fall das Datenformat Avro und im zweiten Fall nur JSON ist.
Lass uns weitermachen. Wir können zum Beispiel
eine Vorschau erstellen, die bestimmte Datensätze von Kafka in Echtzeit aufzeichnet. Dann schreiben wir alles auf.
Nach dem Start sehen wir, dass ein Strom von Ereignissen nach Kafka fliegt, und dies geschieht in Echtzeit:

Jetzt können Sie in ClickHouse ein Repository für diese Daten erstellen. Um mit ClickHouse zu arbeiten, können Sie einen einfachen nativen Client verwenden, indem Sie den folgenden Befehl ausführen:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
Bitte beachten Sie, dass diese Zeile das Netzwerk angibt, zu dem Sie eine Verbindung herstellen möchten. Und je nachdem, wie Sie den Ordner mit dem Repository benennen, kann sich Ihr Netzwerkname unterscheiden. Im Allgemeinen lautet der Befehl wie folgt:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
Die Liste der Netzwerke kann mit dem folgenden Befehl angezeigt werden:
docker network ls
Nun, da ist nichts mehr übrig:
1.
Unterzeichnen Sie zunächst unser ClickHouse bei Kafka und „erklären Sie ihm“, welches Format die Daten haben, die wir dort benötigen:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
Nun erstellen wir eine echte Tabelle, in die wir die endgültigen Daten einfügen:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
Und dann stellen wir eine Beziehung zwischen diesen beiden Tabellen her :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
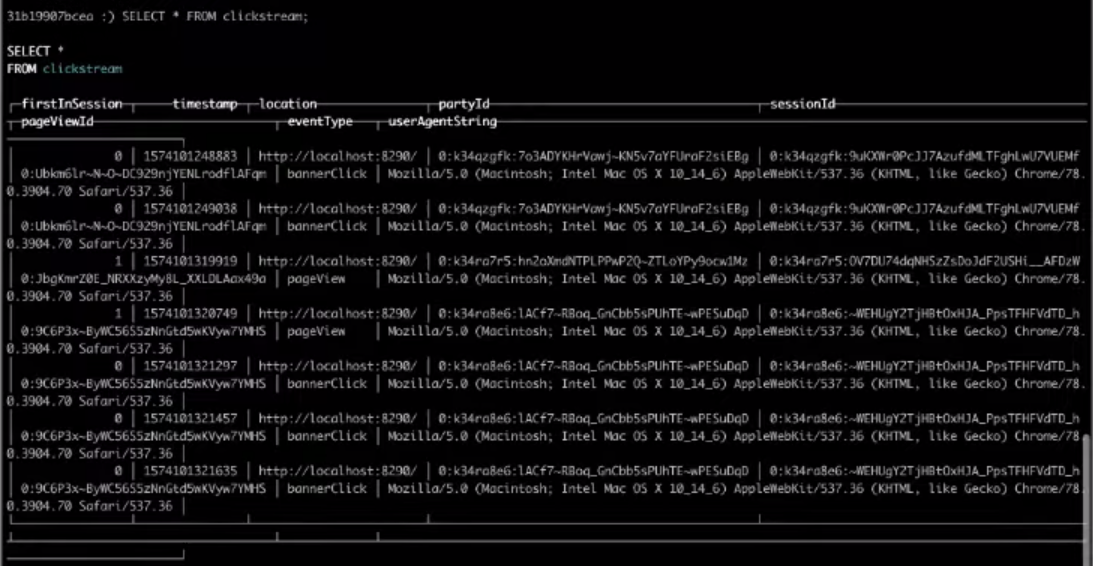
Und jetzt werden wir die erforderlichen Felder auswählen :
SELECT * FROM clickstream;
Infolgedessen liefert die Auswahl aus der Zieltabelle das gewünschte Ergebnis.
Das ist alles, es war der einfachste Clickstream, den Sie erstellen können. Wenn Sie die obigen Schritte selbst
ausführen möchten,
sehen Sie sich das gesamte
Video an .