
Die Geschichte des maschinellen Lernens begann Mitte des letzten Jahrhunderts. Zu dieser Zeit war diese Technologie eher ein Bereich für wissenschaftliche Forschung und Experimente, und leistungsstarke Computer gaben der praktischen Anwendung von ML einen Impuls.
Maschinelles Lernen ist heute ein unbestreitbarer Trend auf dem IT-Markt. Immer mehr Unternehmen aus verschiedenen Branchen bilden Data-Science-Abteilungen, um mithilfe des maschinellen Lernens neue Möglichkeiten für das Wachstum und die Steigerung der Unternehmenseffizienz in den gesammelten Daten zu finden. Diese Initiativen bringen jedoch keine angemessene Rendite. Laut Statistik gehen 8 von 10 bestätigten Fällen nicht in den kommerziellen Betrieb.
Höchstwahrscheinlich haben die meisten von Ihnen den Witz gehört, "der effektivste Weg, um maschinelles Lernen produktiver zu machen, sind PowerPoint-Folien." Leider ist das kein Scherz. Oft sieht der gesamte Prozess so aus: Ein Unternehmen überträgt Daten und einen Geschäftsfall, der von Geschäftssystemen heruntergeladen wurde. Data Scientists entwickeln ein Modell für maschinelles Lernen im Jupiter-Notizbuch, ein Screenshot der Grafiken wird auf einer PowerPoint-Folie platziert und an den Geschäftskunden gesendet. Ist es möglich, die resultierende Folie für Managemententscheidungen zu verwenden? Höchstwahrscheinlich nicht, da die Prognosedaten schnell veraltet sind und sich die Geschäftslage in dieser Zeit erheblich ändern kann.
Um alle Hindernisse zu überwinden und das maschinelle Lernen in Schwung zu bringen, investieren die meisten Unternehmen in die Infrastruktur zur Erfassung, Speicherung und Verarbeitung großer Datenmengen - Data Lake. Dies ist natürlich ein notwendiger Schritt. Aber was ändert sich aus geschäftlicher Sicht? Ist es möglich, Entscheidungen basierend auf maschinellem Lernen zu treffen? Nein, da zwischen Data Lake und Unternehmen eine Lücke besteht. Offensichtlich, warum 86% der befragten Unternehmen der Meinung sind, dass Unternehmensanwendungen der nächsten Generation mit maschinellem Lernen ausgestattet werden sollten.
Wir bei SAP haben uns entschlossen, eine Reihe von Artikeln zu verfassen, um bestehende Schwierigkeiten mit der neuen SAP Data Intelligence-Plattform zu überwinden und ein so leistungsfähiges Tool wie maschinelles Lernen in den Dienst des Geschäfts zu stellen. Und wenn Sie sich für dieses Thema interessieren, lesen Sie weiter :)
Zunächst erzähle ich Ihnen von der ersten und sehr wichtigen Phase in der Entwicklung eines Geschäftsfalls "Datenrecherche und -vorbereitung". In den folgenden Artikeln werden die Phasen "Entwicklung und Schulung von Modellen", "Integration in SAP- und Nicht-SAP-On-Premise- und Cloud-Datenquellen im Detail", "Erstellen von Diensten für die Verwendung von Modellen", "Übertragen von Geschäftsfällen in die Produktivität" und "Überwachen" behandelt und die Abwicklung von Business Cases “und vieles mehr.
Entwicklung eines Business Case basierend auf maschinellem Lernen. Suche und Aufbereitung von Daten.Schauen wir uns den Prozess der Erstellung eines Business Case an (Abbildung 1).
Anfänglich wird eine Idee normalerweise von einem Unternehmen formuliert. Oft tut er es bereitwillig, da er ein klares Ziel hat, Funktionen innerhalb der digitalen Transformation des gesamten Unternehmens zu digitalisieren. Zum Sammeln, Bewerten und Priorisieren von Ideen können Sie beispielsweise SAP Innovation Management verwenden.
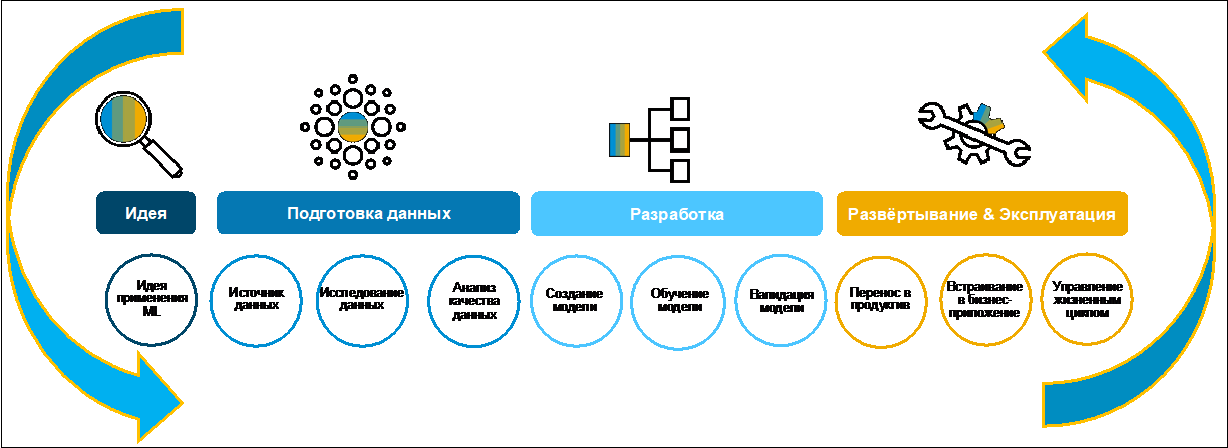 Abbildung 1
Abbildung 1In der ersten Phase der Datenrecherche und -aufbereitung muss verstanden werden, ob sie überhaupt für die Entwicklung eines Geschäftsfalls existieren, wo sie gespeichert sind, in welchen Formaten und in welcher Qualität sie vorliegen. Die moderne typische Landschaft enthält viele heterogene Systeme. Daten können in verschiedenen Anwendungen dupliziert werden. Das Finden der richtigen Informationen kann viel Zeit in Anspruch nehmen. Zu diesem Zweck wurde diese Aufgabe in SAP Data Intelligence mithilfe des Metadatenkatalogs erheblich vereinfacht. Schauen wir uns an, was es ist und wie man es benutzt.
MetadatenkatalogUm den Metadatenkatalog zu verwenden, müssen Sie das Quellsystem mit Data Intelligence verbinden. Datenquellen für Data Intelligence können On-Premise-Systeme wie SAP ERP, BW, Marketing ... und Nicht-SAP MES, Oracle, MS SQL, DB2, Hadoop und viele andere sowie Cloud-Dienste wie Amazon, Azzure und Google SCP sein. Um eine Verbindung zu Datenquellen herzustellen, benötigen Sie Informationen zum Standort der Systeme und technischen Benutzer, die in diesen Systemen speziell für die Integration mit SAP Data Intelligence erstellt wurden. Abbildung 2 zeigt ein Beispiel für eine angepasste Datenlandschaft in SAP Data Intelligence.
 Abbildung 2
Abbildung 2
Nach der Konfiguration im SAP Data Intelligence-Metadatenkatalog können Informationen angezeigt werden, die auf verbundenen Systemen gespeichert sind. Abbildung 3 zeigt die Liste der Dateien im Ordner DAT263 in Hadoop, die mit SAP Data Intelligence verbunden sind.
 Abbildung 3
Abbildung 3Wenn Sie die Daten finden, die zur Implementierung eines Geschäftsfalls erforderlich sind, fügen Sie dem Katalog mithilfe der Veröffentlichungsfunktion Datenobjekte hinzu. Ich werde die Datei autos_history.csv verwenden, die Statistiken zu Gebrauchtwagenverkäufen enthält. In Abbildung 4 sehen Sie, wie Sie ein Datenobjekt und seine Metadaten im Katalog veröffentlichen können, um in Zukunft schnell darauf zugreifen zu können.
 Abbildung 4
Abbildung 4Sie können die Verzeichnisstruktur und die Hierarchieebenen gemäß Ihren Business-Case-Anforderungen anpassen. In meinem Ordner Habr_demo werden beispielsweise alle Metadaten zu den Objekten gesammelt, die ich für diesen Artikel benötige.
Der generierte Metadatenkatalog bietet einen schnellen Zugriff auf Geschäftsfalldaten. Ich werde für die Objekte meines Ordners im SAP Data Intelligence-Metadatenkatalog ein Profil erstellen und deren Qualität analysieren. Das Einstiegsbild des Metadatenkatalogs ist in Abb. 2 dargestellt. 5.
 Abbildung 5
Abbildung 5Und hier ist genau das Datenobjekt, das ich im Ordner Habr_demo veröffentlicht habe (Abb. 6)
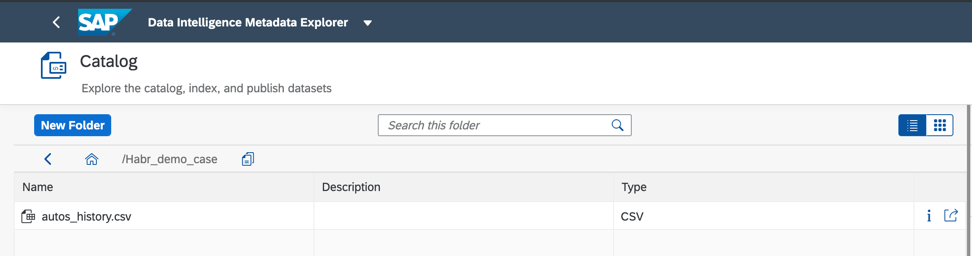 Abbildung 6
Abbildung 6Um die Suche zu verbessern und zu beschleunigen, können wir außerdem Tags oder Labels im Katalog der Datenobjekte zuweisen, wie in Abb. 2 dargestellt. 7.
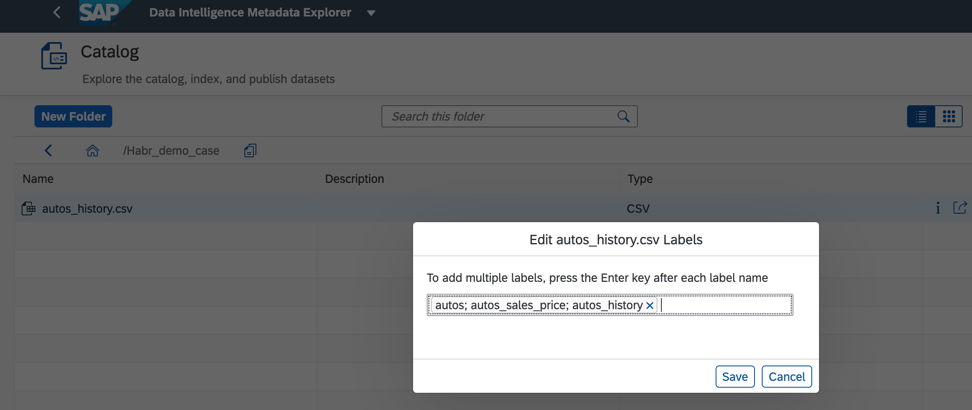 Abbildung 7
Abbildung 7Mit dem Metadatenkatalog können Sie Objekte nach Namen, Feldern und Beschriftungen suchen. Ein einzelnes Datenobjekt kann mehrere Bezeichnungen haben. Dies ist praktisch, wenn mehrere Entwickler damit arbeiten, jeder seinem Geschäftsfall ein Label zuweisen und schnell alles finden kann, was Sie benötigen. Tags können auch persönliche und vertrauliche Daten hervorheben, auf die strengstens beschränkt werden sollte.
Im betrachteten Datensatz ergibt eine Suche nach Label und Feldnamen ein schnelles Ergebnis (Abb. 8). Stimmen Sie zu, es ist sehr bequem!
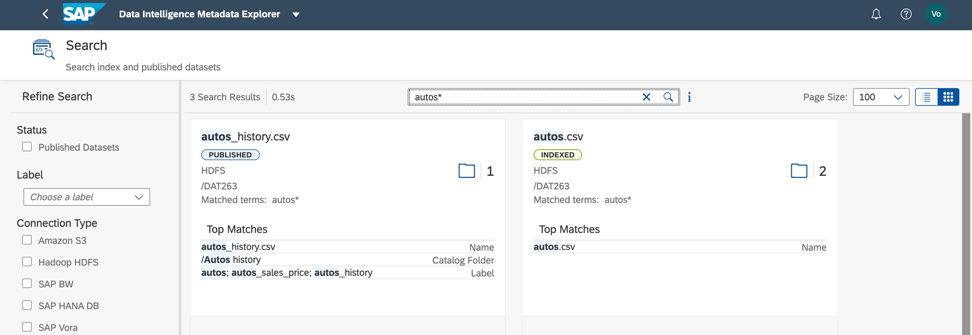 Abbildung 8
Abbildung 8Als nächstes müssen wir verstehen, wie unsere Datei gefüllt ist. Dazu können wir die Daten profilieren. Wir starten den Prozess auch aus dem Metadatenkatalog und dem Kontextmenü für Datenobjekte (Abb. 9).
 Abbildung 9
Abbildung 9Während der Profilerstellung liest der Metadatenkatalog den Inhalt der Datei, analysiert ihre Struktur und Füllung. Das Ergebnis finden Sie im Fact Sheet (Abb. 10).
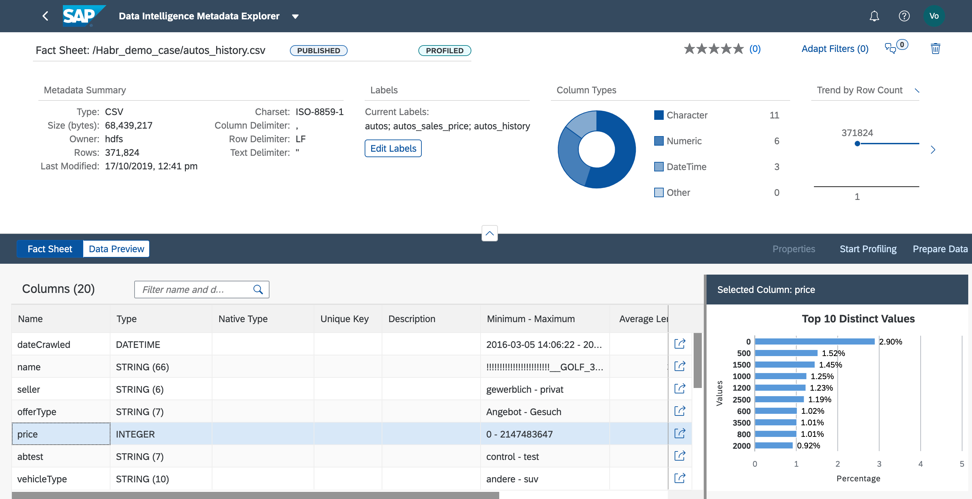 Abbildung 10
Abbildung 10
Im Fact Sheet sehen wir die Dateistruktur und Informationen zum Ausfüllen der Felder.
1. In der ausgewählten Datei haben wir als Ergebnis der Profilerstellung festgestellt: Das Verkäuferfeld hat in allen Zeilen einen Wert I. Dies bedeutet, dass wir dieses Feld aus dem Datensatz entfernen können, um beim Erstellen des Modells kein maschinelles Lernen zu verwenden, da dies keine Auswirkungen auf das Prognoseergebnis hat (Abb. 11).
 Abbildung 11.2.
Abbildung 11.2. Wenn wir die Preisspalte analysieren, verstehen wir, dass fast 3% der uns vorliegenden Daten den Preis Null enthalten. Um diese Datei in unserem Geschäftsfall zu verwenden, müssen wir den Preis entweder mit den tatsächlichen Werten oder dem Durchschnitt für dieses Produkt ausfüllen oder die Zeilen mit dem Preis Null aus der Datei löschen (Abb. 12).
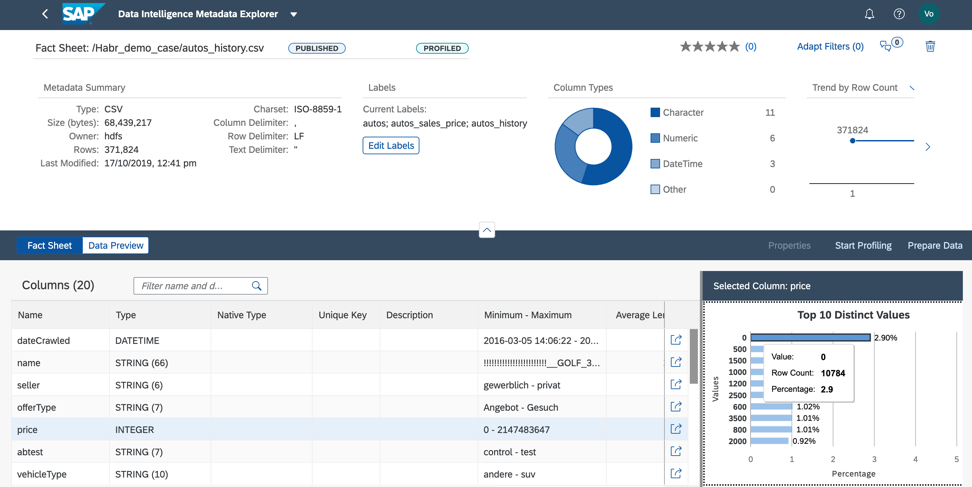 Abbildung 12.
Abbildung 12.Die Datenvorverarbeitung kann auf zwei Arten erfolgen: im Metadatenkatalog oder direkt im Jupiter-Notizbuch. Die Wahl des Tools hängt davon ab, wer für die Vorverarbeitung der Daten für den Geschäftsfall verantwortlich ist. Als Analyst empfehle ich die Verwendung der visuellen Datenvorbereitungsschnittstelle, die im Metadatenkatalog verfügbar ist. Wenn ein Datenwissenschaftler mit der Aufbereitung der Daten befasst ist, sollte die Wahl auf jeden Fall auf das Jupiter-Notizbuch fallen, das auch in Data Intelligence integriert ist.
3. Der Wert des Modellfelds ist gut verteilt, sodass wir das Modell wie in Abbildung 13 qualitativ trainieren können.
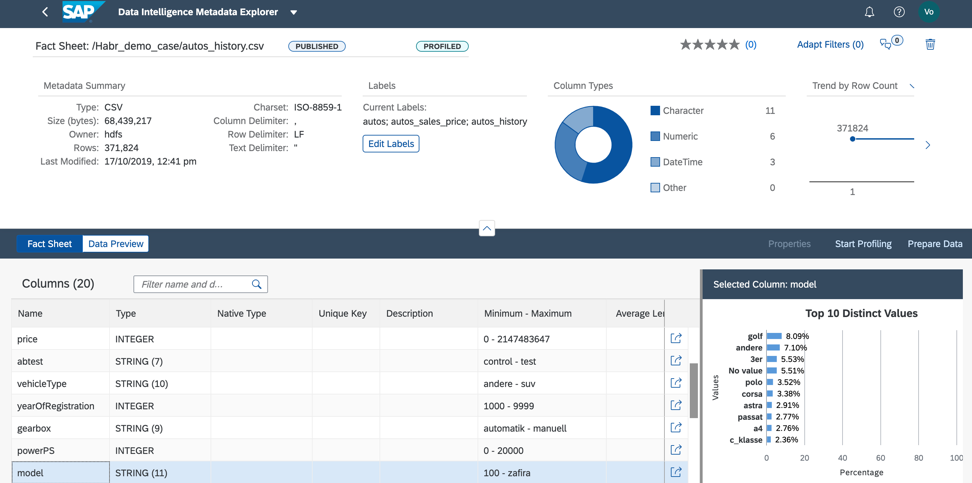 Abbildung 13.
Abbildung 13.
Jetzt wissen wir, welche Datenobjekte zur Implementierung eines Geschäftsfalls erforderlich sind, mit welchen Datenobjekten gefüllt ist, welche Vorverarbeitung wir durchführen müssen, um diese Daten für die Implementierung, das Training und das Testen des Modells zu verwenden. Bevor Sie jedoch mit der Vorverarbeitung beginnen, müssen Sie die Qualität der Daten überprüfen. Zu diesem Zweck stehen Geschäftsregeln im Metadatenkatalog zur Verfügung. Ich stelle sofort fest, dass die Funktionalität von Geschäftsregeln derzeit eine Reihe schwerwiegender Einschränkungen aufweist. Daher empfehle ich eine mehr oder weniger komplizierte Datenvorverarbeitung im Jupiter Notebook, das in SAP Data Intelligence integriert ist.
Kehren wir also zu unserem Datensatz zurück und überprüfen Sie die Einhaltung der Mindest- und Höchstschwellenwerte im Preisfeld, damit wir grob abschätzen können, ob die Daten Anomalien oder falsche Werte aufweisen. Wie Sie bereits verstanden haben, werden Geschäftsregeln auch im Metadatenkatalog konfiguriert, wie in Abb. 14a, c. Das Verhältnis von Regeln und Daten wird im Regelbuch (Rulebook) konfiguriert. Auf diese Weise können Sie dieselben Regeln verwenden, um verschiedene Daten zu überprüfen.
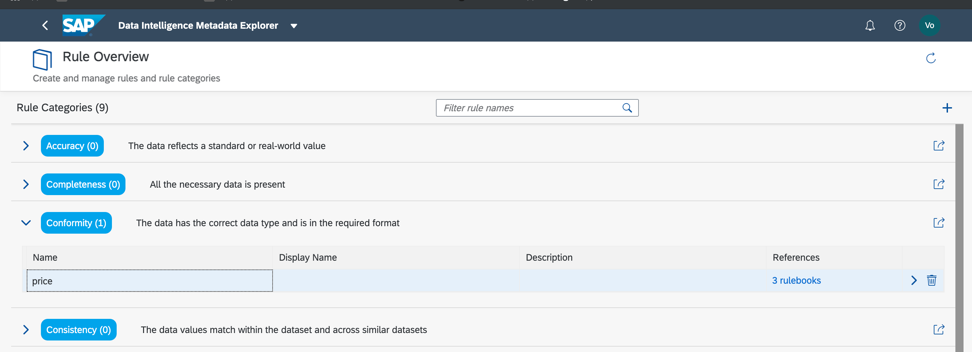 Abbildung 14 a.
Abbildung 14 a.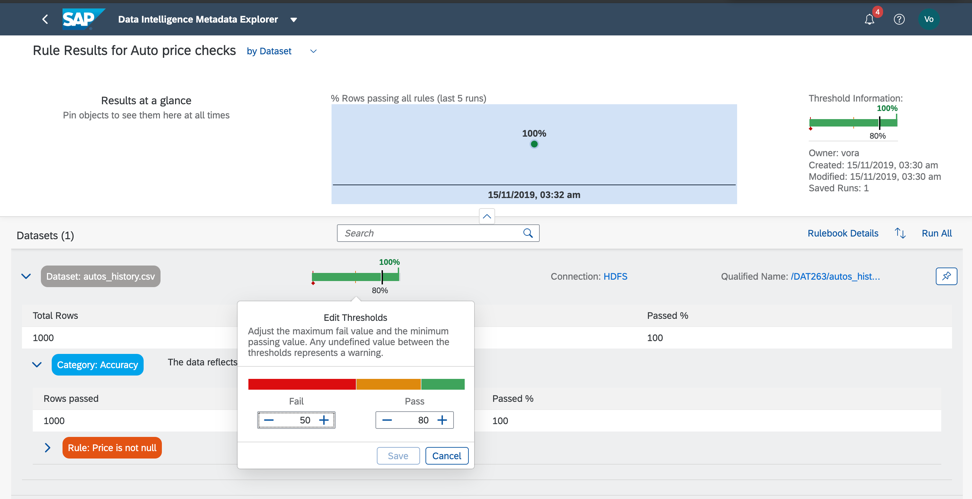 Abbildung 14 c.
Abbildung 14 c.Wie wir sehen, sind unsere Daten also zu 100% korrekt.
Das kommt aber nicht immer vor. Daten können als korrekt angesehen werden, wenn 75% der Datensätze die in den Regeln festgelegten Bedingungen erfüllen.
Es ist möglich, die Datenqualität zu verbessern, und dies geschieht vor allem in Buchhaltungssystemen. Zu diesem Zweck organisieren Unternehmen den Datenverwaltungsprozess. Ein weiterer möglicher Grund sind falsch definierte Datenqualitätskriterien.
Zusammenfassend möchte ich auf die Vor- und Nachteile des Metadatenkatalogs eingehen.
Meiner Meinung nach hat es 3 Hauptvorteile:
- Vereinfachen Sie den Datenzugriff.
- Beschleunigung des Datenabrufs.
- Bequeme und intuitive Benutzeroberfläche, die nicht nur für fortgeschrittene IT- oder Data Science-Spezialisten gedacht ist, sondern auch für Unternehmen, die an der Implementierung und weiteren Unterstützung des Business Case beteiligt sind.
Und natürlich über die Mängel. Sie sind offensichtlich. Derzeit befindet sich die Funktionalität des Metadatenkatalogs in SAP Data Intelligence auf einer grundlegenden Ebene. Es mag ausreichen, mit der Verwendung zu beginnen, die Funktionalität deckt jedoch nicht alle Anforderungen an eine Datenverwaltungslösung ab.
Dies ist eine Folge der Neuheit und Komplexität von SAP Data Intelligence. SAP investiert viel in die Verbesserung dieser Lösung. Dies schafft Vertrauen, dass der Metadatenkatalog in naher Zukunft zu einem leistungsstarken Tool für das Datenmanagement wird. Es besteht die Möglichkeit, komplexe Geschäftsregeln ohne Programmierung zu erstellen. Es wird auch möglich sein, den SAP Information Steward und den SAP Data Hub zu integrieren, um das Thema Datenmanagement voll funktionsfähig abzudecken.
Im nächsten Artikel werden wir über die Phase „Entwicklung und Schulung eines Modells in SAP Data Intelligence“ sprechen. Das Interessanteste voraus!
Gepostet von Elena Ganchenko, SAP CIS Expert