Wenn Sie jemandem das Wertvollste anvertrauen, das Sie haben - die Daten Ihrer Anwendung oder Ihres Dienstes - möchten Sie sich vorstellen, wie dieser jemand mit Ihrem größten Wert umgeht.
Mein Name ist Vladimir Borodin, ich bin der Leiter der Yandex.Cloud-Datenplattform. Heute möchte ich Ihnen sagen, wie alles in den Diensten von Yandex Managed Databases angeordnet ist und funktioniert, warum alles so abläuft und welche Vorteile unsere verschiedenen Lösungen aus Sicht der Benutzer haben. Und natürlich werden Sie bestimmt herausfinden, was wir in naher Zukunft fertigstellen werden, damit der Service für alle, die ihn benötigen, besser und bequemer wird.
Nun, lass uns gehen!

Verwaltete Datenbanken (Yandex Managed Databases) ist einer der beliebtesten Dienste von Yandex.Cloud. Genauer gesagt handelt es sich hierbei um eine ganze Gruppe von Diensten, die nach den virtuellen Maschinen von Yandex Compute Cloud an zweiter Stelle steht.
Mit Yandex Managed Databases können Sie schnell eine funktionierende Datenbank erstellen und folgende Aufgaben übernehmen:
- Skalierung - von der elementaren Fähigkeit, Rechenressourcen oder Speicherplatz hinzuzufügen, bis hin zu einer Zunahme der Anzahl von Replikaten und Shards.
- Installieren Sie kleinere und größere Updates.
- Sichern und wiederherstellen.
- Fehlertoleranz gewährleisten.
- Überwachung
- Bereitstellung bequemer Konfigurations- und Verwaltungstools.
So werden verwaltete Datenbankdienste angeordnet: Draufsicht
Der Service besteht aus zwei Hauptteilen: Kontrollebene und Datenebene. Control Plane ist eine Datenbankverwaltungs-API, mit der Sie Datenbanken erstellen, ändern oder löschen können. Datenebene ist die Ebene der direkten Datenspeicherung.
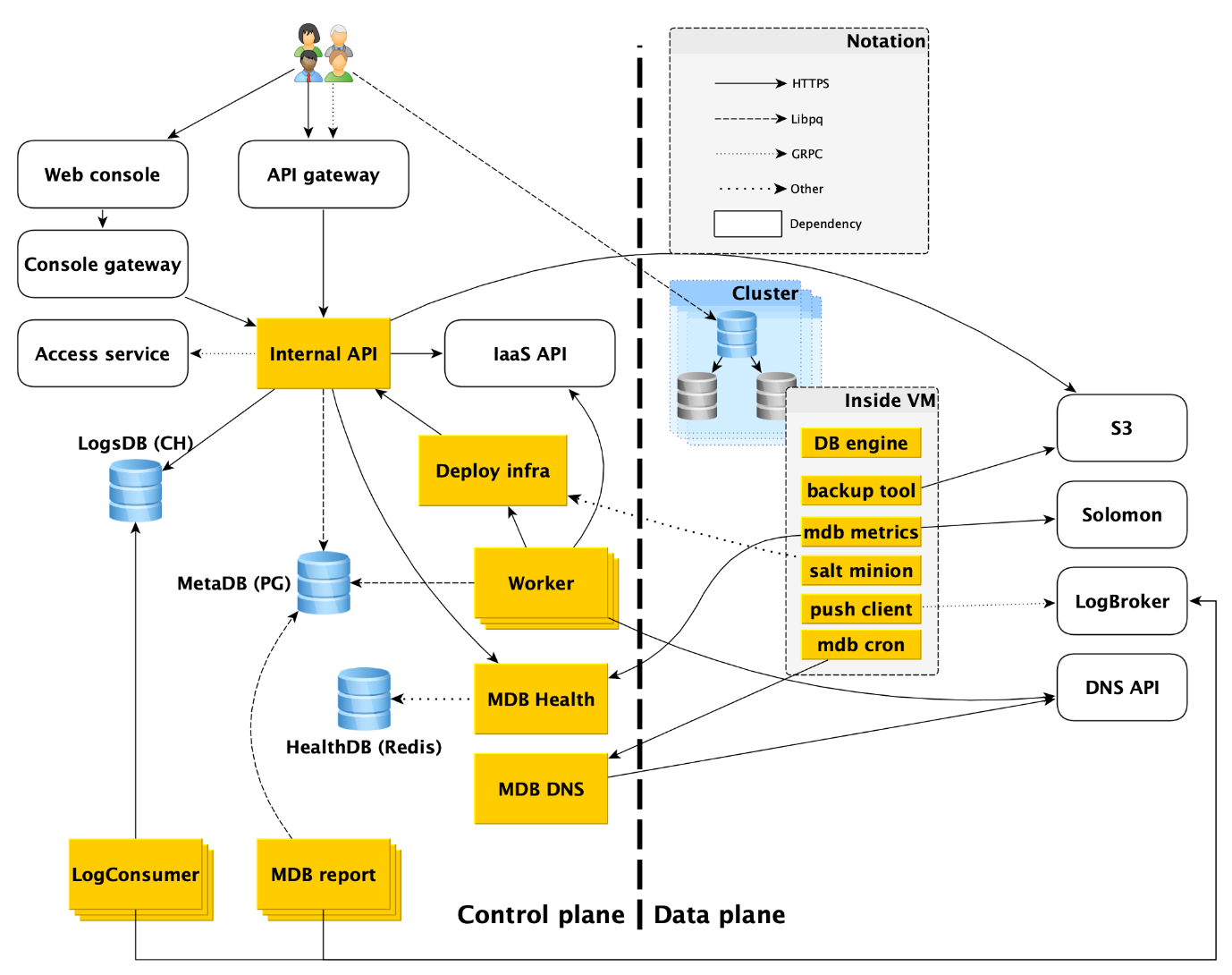
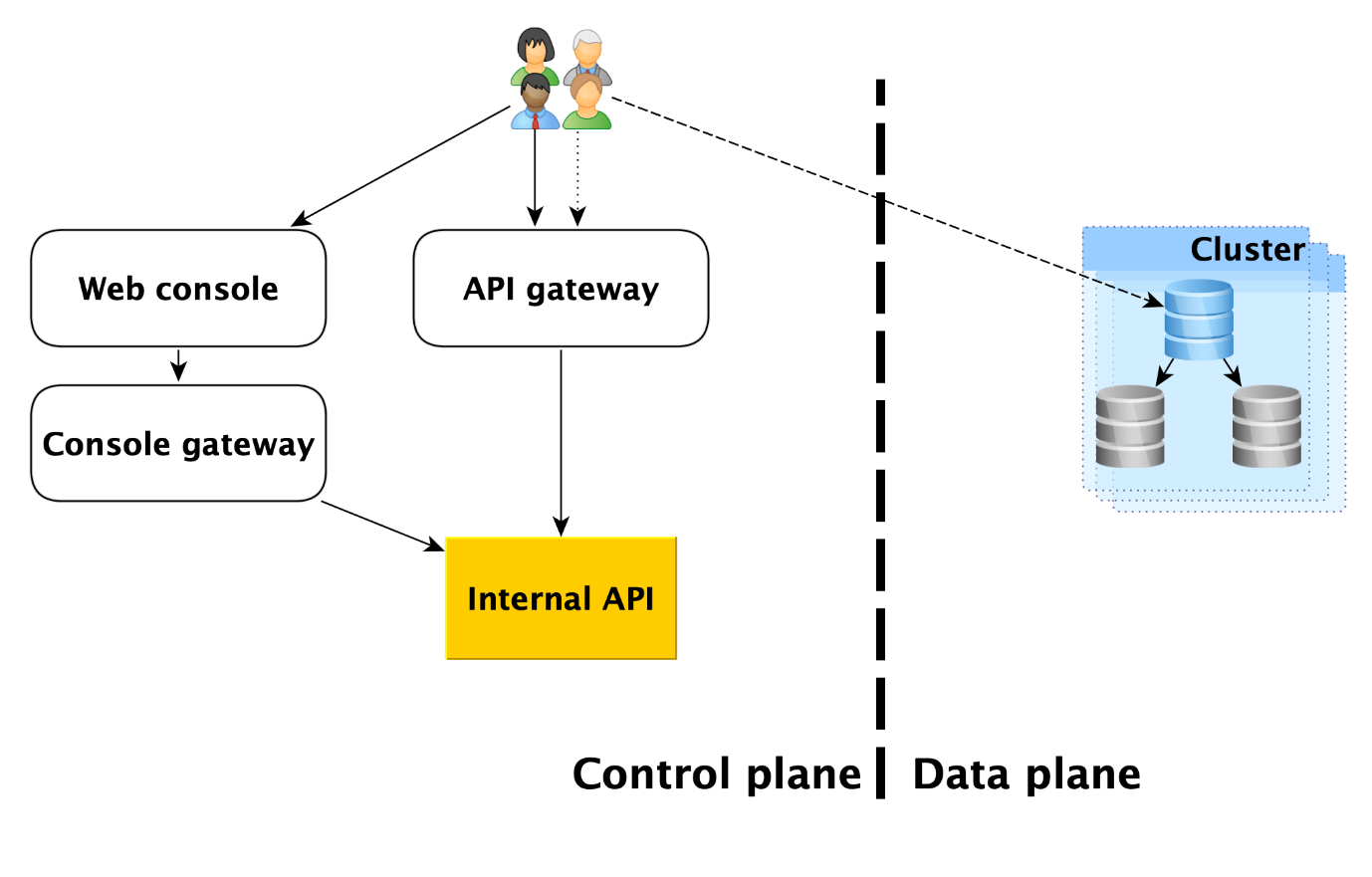
Die Dienstnutzer haben in der Tat zwei Einstiegspunkte:
- In der Kontrollebene. Tatsächlich gibt es viele Eingaben - die Webkonsole, das CLI-Dienstprogramm und die Gateway-API, die die öffentliche API (gRPC und REST) bereitstellt. Letztendlich gehen alle zu dem, was wir die interne API nennen, und deshalb werden wir diesen einen Einstiegspunkt in die Steuerebene betrachten. Dies ist der Punkt, ab dem der Zuständigkeitsbereich des MDB-Dienstes (Managed Databases) beginnt.
- In der Datenebene. Dies ist eine direkte Verbindung zu einer laufenden Datenbank über Zugriffsprotokolle auf das DBMS. Wenn es sich beispielsweise um PostgreSQL handelt, handelt es sich um die libpq-Schnittstelle .
Im Folgenden werden wir detaillierter beschreiben, was in der Datenebene geschieht, und wir werden jede der Komponenten der Steuerebene analysieren.
Datenebene
Bevor Sie sich die Komponenten der Steuerebene ansehen, werfen Sie einen Blick auf die Vorgänge in der Datenebene.
In einer virtuellen Maschine
MDB führt Datenbanken auf denselben virtuellen Maschinen aus, die in
Yandex Compute Cloud bereitgestellt werden.
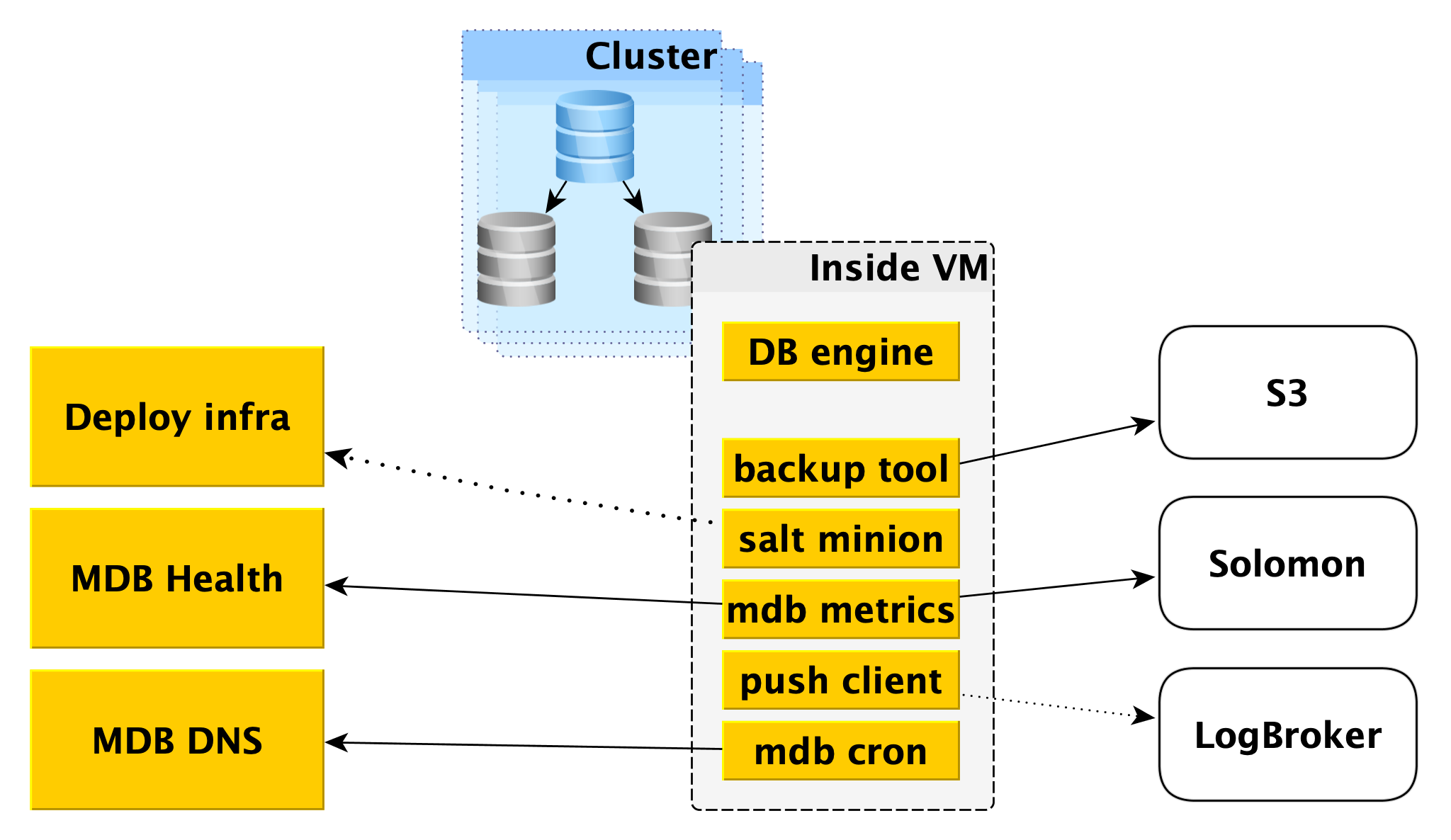
Zunächst wird dort eine Datenbank-Engine, beispielsweise PostgreSQL, implementiert. Parallel können verschiedene Hilfsprogramme gestartet werden. Für PostgreSQL ist dies
Odyssey , der Datenbankverbindungs-Puller.
Auch innerhalb der virtuellen Maschine wird eine bestimmte Standardgruppe von Diensten gestartet, die für jedes DBMS eine eigene ist:
- Dienst zum Erstellen von Backups. Für PostgreSQL ist es ein Open-Source - Tool für WAL-G. Es erstellt Backups und speichert sie im Yandex Object Storage .
- Salt Minion ist eine Komponente des SaltStack- Systems für Betriebs- und Konfigurationsmanagement. Weitere Informationen hierzu finden Sie weiter unten in der Beschreibung der Bereitstellungsinfrastruktur.
- MDB-Metriken, die für die Übertragung von Datenbankmetriken an Yandex Monitoring und an unseren Microservice verantwortlich sind, um den Status von MDB-Integritätsclustern und -Hosts zu überwachen.
- Der Push-Client, der DBMS-Protokolle und Abrechnungsprotokolle an den Logbroker-Service sendet, ist eine spezielle Lösung zum Sammeln und Liefern von Daten.
- MDB Cron - unser Fahrrad, das sich von dem üblichen Cron in der Fähigkeit unterscheidet, periodische Aufgaben mit einer Genauigkeit von einer Sekunde auszuführen.
Netzwerktopologie
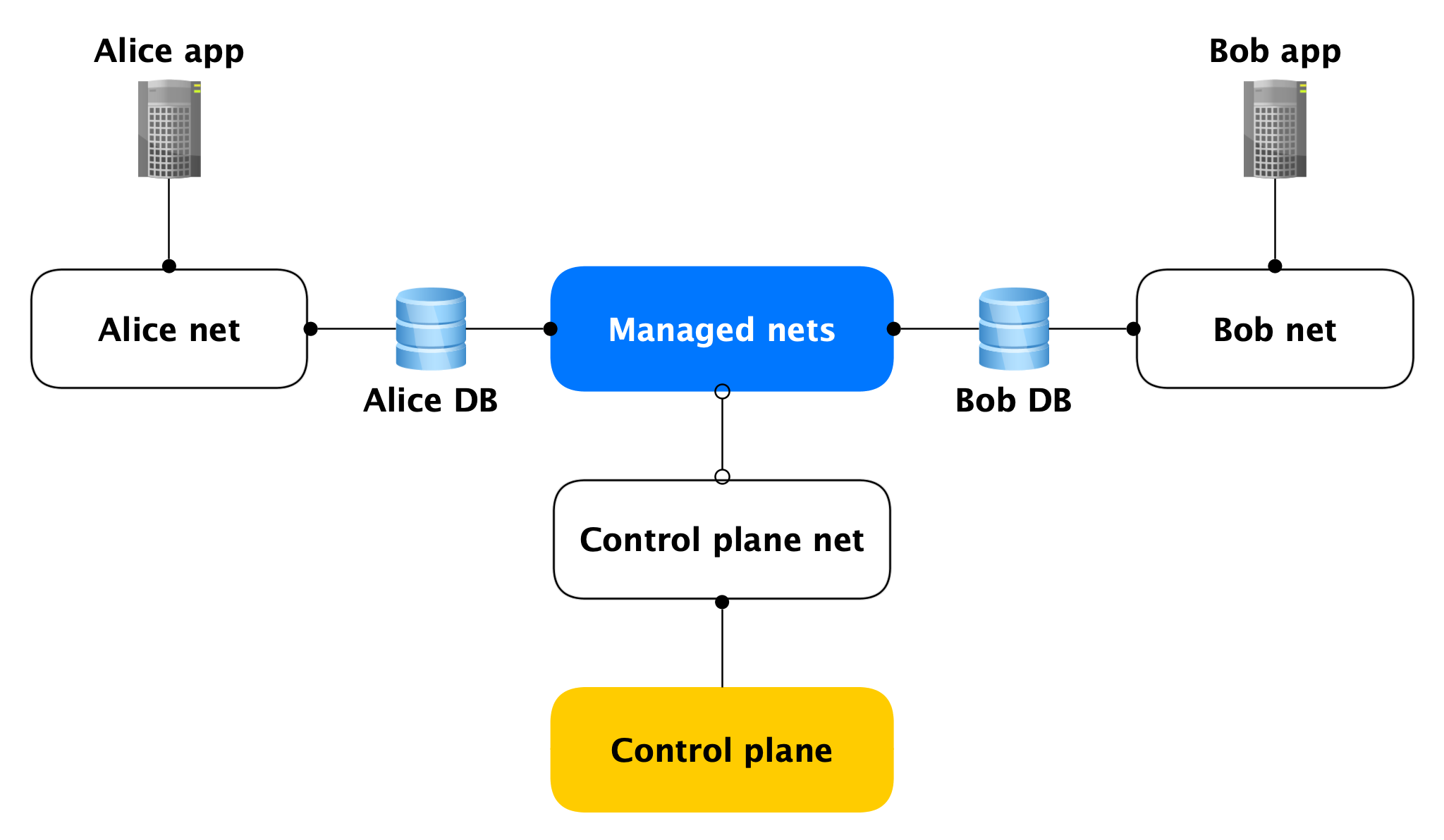
Jeder Data Plane-Host verfügt über zwei Netzwerkschnittstellen:
- Einer von ihnen steckt im Netzwerk des Benutzers. Im Allgemeinen ist es erforderlich, die Produktladung zu warten. Durch sie jagt die Replikation.
- Der zweite Teil befindet sich in einem unserer verwalteten Netzwerke, über das Hosts zur Steuerungsebene wechseln.
Ja, Hosts verschiedener Clients sitzen in einem solchen verwalteten Netzwerk fest, aber das ist nicht beängstigend, da auf der verwalteten Schnittstelle (fast) nichts überwacht wird und ausgehende Netzwerkverbindungen in der Steuerungsebene nur von dort geöffnet werden. Fast niemand, da es offene Ports gibt (z. B. SSH), die jedoch von einer lokalen Firewall geschlossen werden, die nur Verbindungen von bestimmten Hosts zulässt. Wenn ein Angreifer Zugriff auf eine virtuelle Maschine mit einer Datenbank erhält, kann er daher nicht auf die Datenbanken anderer Personen zugreifen.
Sicherheit der Datenebene
Da es sich um Sicherheit handelt, muss gesagt werden, dass wir den Dienst ursprünglich so konzipiert haben, dass der Angreifer auf der virtuellen Cluster-Maschine root wird.
Am Ende haben wir viel Mühe darauf verwendet, Folgendes zu tun:
- Lokale und große Firewall;
- Verschlüsselung aller Verbindungen und Backups;
- Alle mit Authentifizierung und Autorisierung;
- AppArmor
- Selbstgeschriebene IDS.
Betrachten Sie nun die Komponenten der Steuerebene.
Steuerebene
Interne API
Die interne API ist der erste Einstiegspunkt in die Steuerebene. Mal sehen, wie alles hier funktioniert.
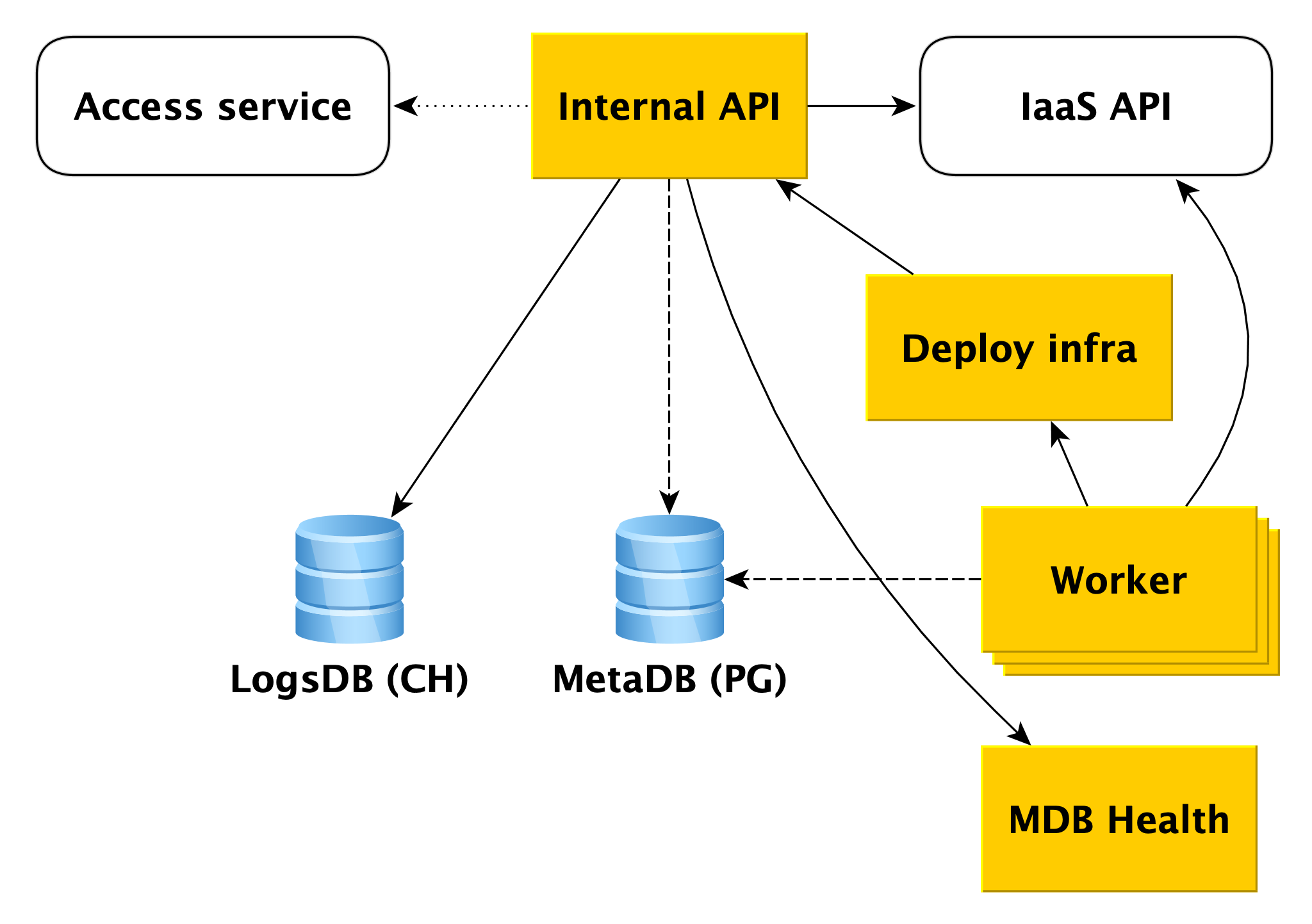
Angenommen, die interne API empfängt eine Anforderung zum Erstellen eines Datenbankclusters.
Zunächst greift die interne API auf den Cloud-Dienst Access Service zu, der für die Überprüfung der Authentifizierung und Autorisierung des Benutzers zuständig ist. Wenn der Benutzer die Überprüfung besteht, überprüft die interne API die Gültigkeit der Anforderung selbst. Beispiel: Eine Anforderung zum Erstellen eines Clusters ohne Angabe des Namens oder mit einem bereits belegten Namen besteht den Test nicht.
Die interne API kann Anforderungen an die API anderer Dienste senden. Wenn Sie einen Cluster in einem bestimmten Netzwerk A und einen bestimmten Host in einem bestimmten Subnetz B erstellen möchten, muss die interne API sicherstellen, dass Sie sowohl für Netzwerk A als auch für das angegebene Subnetz B Rechte haben. Gleichzeitig wird überprüft, ob Subnetz B zu Netzwerk A gehört Dies erfordert den Zugriff auf die Infrastruktur-API.
Wenn die Anforderung gültig ist, werden Informationen zum erstellten Cluster in der Metabasis gespeichert. Wir nennen es MetaDB, es ist auf PostgreSQL implementiert. MetaDB hat eine Tabelle mit einer Warteschlange von Operationen. Die interne API speichert Informationen zum Vorgang und legt die Aufgabe transaktional fest. Danach werden Informationen zum Vorgang an den Benutzer zurückgegeben.
Im Allgemeinen ist es für die Verarbeitung der meisten Anforderungen der internen API ausreichend, MetaDB und die API verwandter Dienste zu verwenden. Es gibt jedoch zwei weitere Komponenten, die von der internen API zur Beantwortung einiger Abfragen verwendet werden: LogsDB, in der sich die Benutzerclusterprotokolle befinden, und MDB Health. Über jedes von ihnen wird unten ausführlicher beschrieben.
Arbeiter
Worker sind einfach eine Reihe von Prozessen, die die Warteschlange von Vorgängen in MetaDB abfragen, abrufen und ausführen.
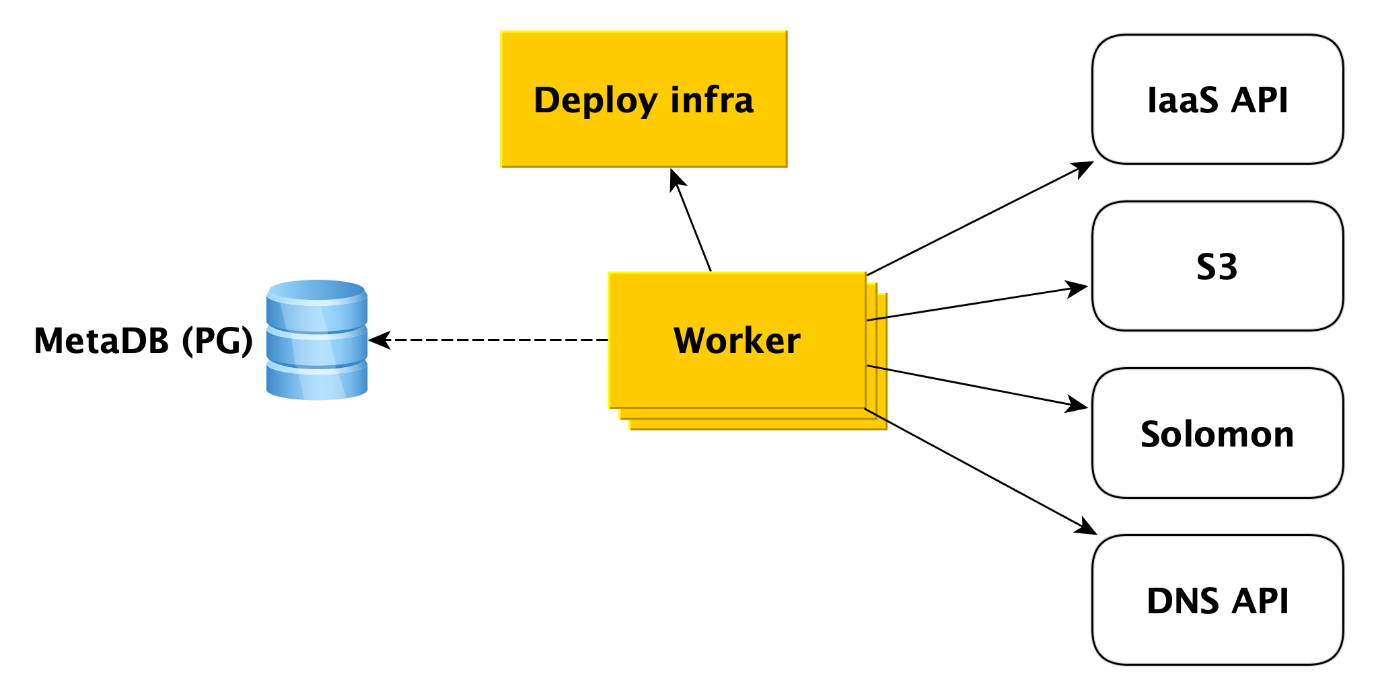
Was genau macht ein Worker, wenn ein Cluster erstellt wird? Zunächst wendet er sich an die Infrastruktur-API, um aus unseren Images virtuelle Maschinen zu erstellen (auf diesen sind bereits alle erforderlichen Pakete installiert und die meisten Dinge sind konfiguriert, die Images werden einmal täglich aktualisiert). Wenn die virtuellen Maschinen erstellt werden und das Netzwerk in ihnen startet, wendet sich der Mitarbeiter an die Bereitstellungsinfrastruktur (wir werden später mehr darüber erzählen), um bereitzustellen, was der Benutzer für die virtuellen Maschinen benötigt.
Darüber hinaus greift der Mitarbeiter auf andere Cloud-Dienste zu. B. an
Yandex Object Storage , um einen Bucket zu erstellen, in dem Clustersicherungen gespeichert werden. An den
Yandex-Überwachungsdienst , der Datenbankmetriken sammelt und visualisiert. Der Arbeiter muss dort Cluster-Metainformationen erstellen. An die DNS-API, wenn der Benutzer den Cluster-Hosts öffentliche IP-Adressen zuweisen möchte.
Im Allgemeinen arbeitet der Arbeiter sehr einfach. Es empfängt die Aufgabe aus der Metabasiswarteschlange und greift auf den gewünschten Dienst zu. Nach Abschluss jedes Schritts speichert der Worker Informationen zum Fortschritt des Vorgangs in der Metabasis. Wenn ein Fehler auftritt, wird der Task einfach neu gestartet und an der Stelle ausgeführt, an der er aufgehört hat. Aber auch ein Neustart von Anfang an ist kein Problem, da fast alle Arten von Aufgaben für die Mitarbeiter ohne Zutun geschrieben werden. Dies liegt daran, dass der Worker den einen oder anderen Schritt des Vorgangs ausführen kann, in MetaDB jedoch keine Informationen dazu vorhanden sind.
Infrastruktur bereitstellen
Ganz unten befindet sich
SaltStack , ein ziemlich verbreitetes Open-Source-Konfigurationsmanagementsystem, das in Python geschrieben wurde. Das System ist sehr
erweiterbar , wofür wir es lieben.
Die Hauptkomponenten von Salt sind Salt Master, in dem Informationen darüber gespeichert werden, was und wo angewendet werden soll, und Salt Minion, ein Agent, der auf jedem Host installiert ist, interagiert mit dem Master und kann das Salz direkt vom Salt Master auf den Host anwenden. Für die Zwecke dieses Artikels verfügen wir über ausreichende Kenntnisse. Weitere
Informationen finden Sie in der
SaltStack-Dokumentation .
Ein Salzmeister ist nicht fehlertolerant und kann nicht auf Tausende von Dienern skaliert werden. Es werden mehrere Meister benötigt. Die direkte Interaktion mit dem Worker ist unpraktisch, und wir haben unsere Bindungen auf Salt geschrieben, das wir das Deploy-Framework nennen.
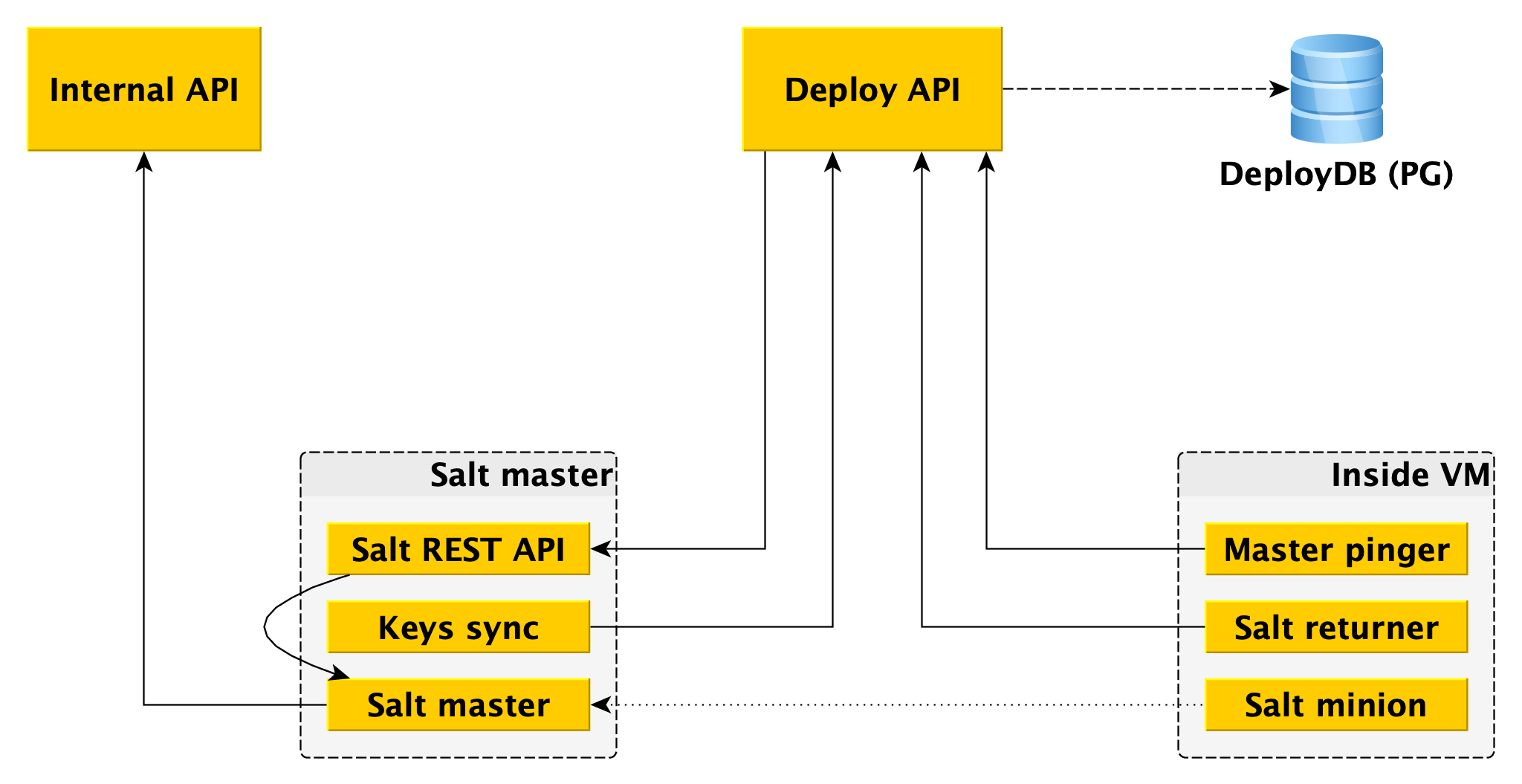
Für den Worker ist der einzige Einstiegspunkt die Deploy-API, die Methoden wie "Anwenden des gesamten Status oder seiner einzelnen Teile auf solche Minions" und "Informieren Sie sich über den Status eines solchen und eines solchen Roll-outs" implementiert. Die Deploy-API speichert Informationen zu allen Rollouts und ihren spezifischen Schritten in DeployDB, wo wir auch PostgreSQL verwenden. Dort werden auch Informationen über alle Diener und Meister sowie über die Zugehörigkeit des Ersten zum Zweiten gespeichert.
Zwei zusätzliche Komponenten sind auf Salzmastern installiert:
- Salt REST API , mit der Deploy API interagiert, um Rollouts zu starten. Die REST-API geht an den lokalen Salt-Master und er kommuniziert bereits mit Minions unter Verwendung von ZeroMQ.
- Das Wesentliche ist, dass es an die Deploy-API geht und die öffentlichen Schlüssel aller Minions erhält, die mit diesem Salt-Master verbunden sein müssen. Ohne einen öffentlichen Schlüssel auf dem Master kann sich der Minion einfach nicht mit dem Master verbinden.
Neben Salt Minion sind zwei Komponenten in der Datenebene installiert:
- Returner - ein Modul (einer der erweiterbaren Teile in Salt), das das Ergebnis des Rollouts nicht nur auf den Salt-Master, sondern auch auf die Deploy-API überträgt. Deploy API (API bereitstellen) leitet die Bereitstellung über die REST-API des Assistenten ein und empfängt das Ergebnis vom Minion über den Returner.
- Master-Pinger, der regelmäßig die Deploy-API abfragt, mit der Master-Minions verbunden werden sollen. Wenn die Bereitstellungs-API eine neue Adresse des Assistenten zurückgibt (z. B. weil die alte Adresse tot oder überlastet ist), konfiguriert Pinger den Minion neu.
Ein weiterer Ort, an dem wir die SaltStack-Erweiterbarkeit verwenden, ist
ext_pillar - die Möglichkeit, von außen auf die
Säule zuzugreifen (einige statische Informationen, z. B. die Konfiguration von PostgreSQL, Benutzern, Datenbanken, Erweiterungen usw.). Wir rufen die interne API unseres Moduls auf, um clusterspezifische Einstellungen abzurufen, da diese in MetaDB gespeichert sind.
Unabhängig davon weisen wir darauf hin, dass die Säule auch vertrauliche Informationen enthält (Benutzerkennwörter, TLS-Zertifikate, GPG-Schlüssel zum Verschlüsseln von Sicherungen). Daher wird zum einen die gesamte Interaktion zwischen allen Komponenten verschlüsselt (nicht in einer unserer Datenbanken) kommen überall ohne TLS, HTTPS, der Minion und der Master verschlüsseln auch den gesamten Verkehr). Und zweitens werden alle diese Geheimnisse in MetaDB verschlüsselt, und wir verwenden die Trennung von Geheimnissen - auf den internen API-Maschinen gibt es einen öffentlichen Schlüssel, der alle Geheimnisse verschlüsselt, bevor sie in MetaDB gespeichert werden, und der private Teil davon liegt auf Salt Masters und nur sie können erhalten offene Geheimnisse für die Übertragung als Säule an einen Diener (wiederum über einen verschlüsselten Kanal).
MDB Gesundheit
Wenn Sie mit Datenbanken arbeiten, ist es hilfreich, deren Status zu kennen. Dafür haben wir den Microservice MDB Health. Es empfängt Hoststatusinformationen von der internen Komponente der MDBs der virtuellen Maschine und speichert sie in einer eigenen Datenbank (in diesem Fall Redis). Wenn in der internen API eine Anforderung zum Status eines bestimmten Clusters eingeht, verwendet die interne API Daten aus MetaDB und MDB Health.
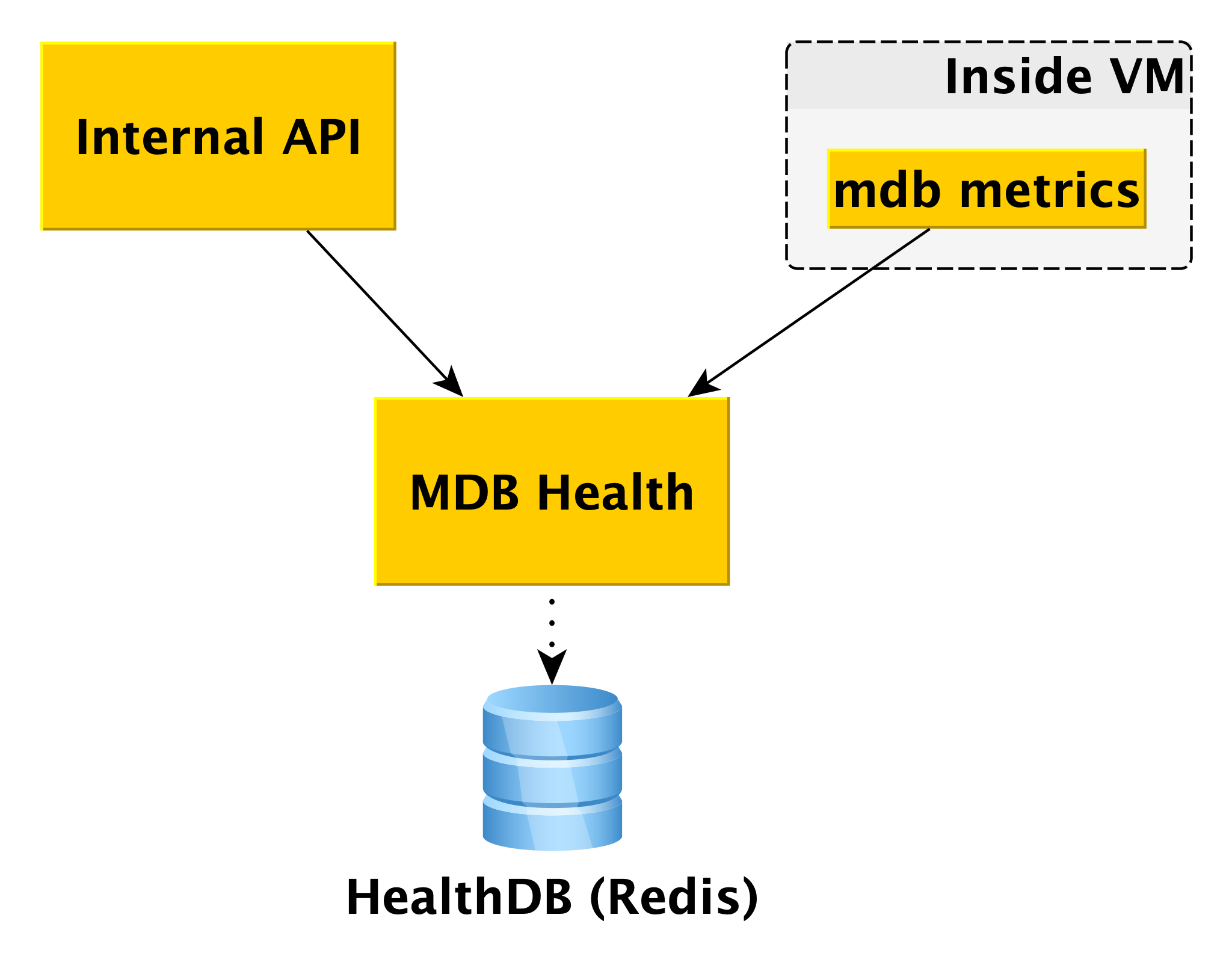
Informationen zu allen Hosts werden verarbeitet und in der API in verständlicher Form dargestellt. Zusätzlich zum Status von Hosts und Clustern für einige DBMS gibt MDB Health zusätzlich zurück, ob ein bestimmter Host ein Master oder ein Replikat ist.
MDB DNS
Der MDB-DNS-Microservice wird zum Verwalten von CNAME-Einträgen benötigt. Wenn der Treiber für die Verbindung zur Datenbank die Übertragung mehrerer Hosts in der Verbindungszeichenfolge nicht zulässt, können Sie eine Verbindung zu einem speziellen
CNAME herstellen , der immer den aktuellen Master im Cluster angibt. Wenn der Master wechselt, ändert sich der CNAME.
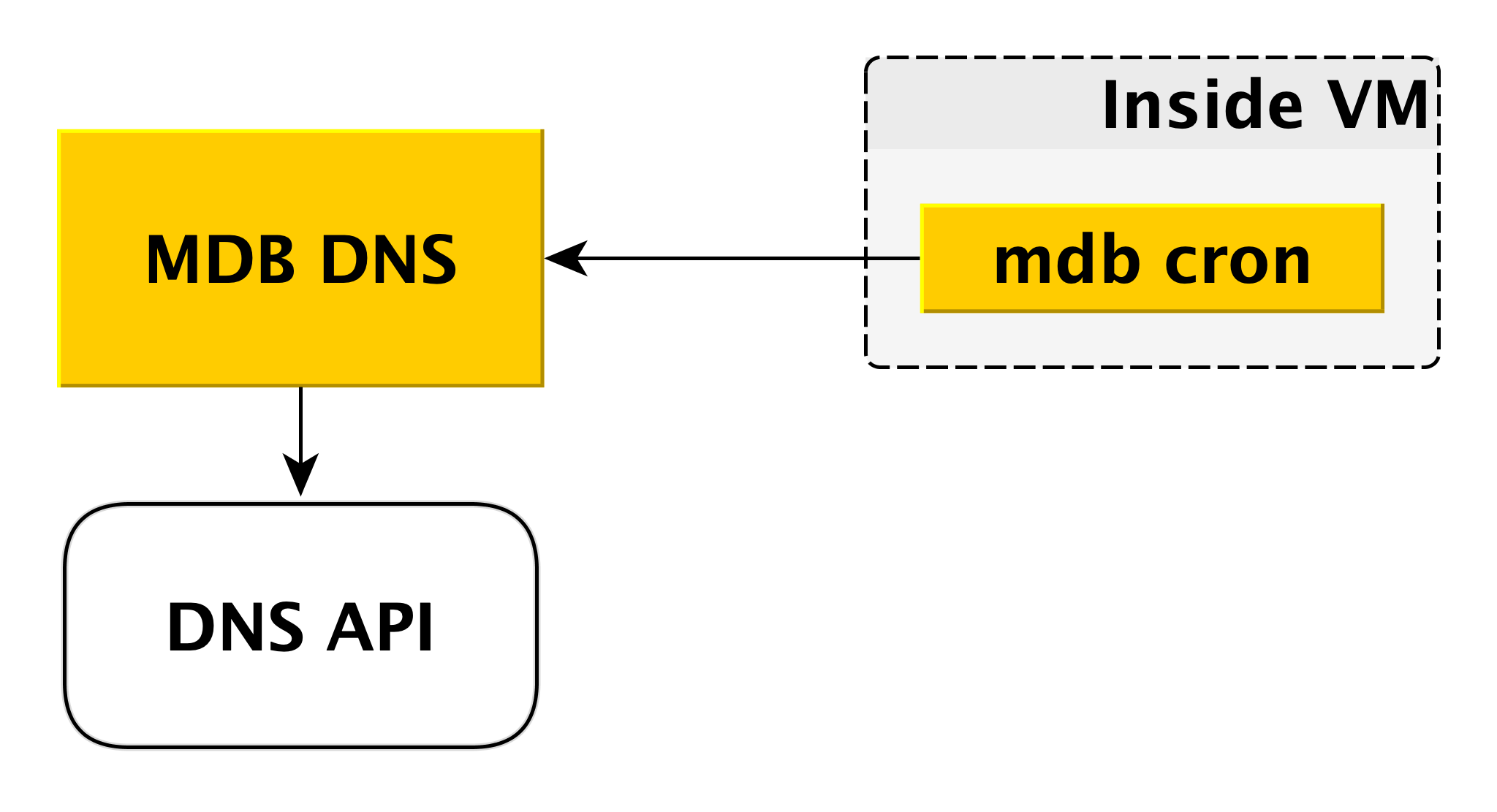
Wie läuft das Wie bereits erwähnt, befindet sich in der virtuellen Maschine ein MDB-Cron, der regelmäßig einen Heartbeat mit den folgenden Inhalten an den MDB-DNS sendet: "In diesem Cluster muss der CNAME-Datensatz auf mich verweisen." MDB DNS akzeptiert solche Nachrichten von allen virtuellen Maschinen und entscheidet, ob CNAME-Einträge geändert werden sollen. Bei Bedarf wird der Eintrag über die DNS-API geändert.
Warum haben wir dafür einen separaten Service gemacht? Weil die DNS-API nur auf Zonenebene Zugriffskontrolle hat. Ein potenzieller Angreifer, der Zugriff auf eine separate virtuelle Maschine erhält, kann die CNAME-Einträge anderer Benutzer ändern. MDB-DNS schließt dieses Szenario aus, da die Autorisierung überprüft wird.
Lieferung und Anzeige von Datenbankprotokollen
Wenn die Datenbank auf der virtuellen Maschine in das Protokoll schreibt, liest die spezielle Push-Client-Komponente diesen Datensatz und sendet die soeben angezeigte Zeile an Logbroker (
sie haben bereits in Habré darüber geschrieben). Die Interaktion des Push-Clients mit LogBroker wird mit genau einer Semantik erstellt: Wir werden sie auf jeden Fall senden und dies auf jeden Fall einmal tun.
Ein separater Maschinenpool - LogConsumers - entnimmt Protokolle aus der LogBroker-Warteschlange und speichert sie in der LogsDB-Datenbank. ClickHouse DBMS wird für die Protokolldatenbank verwendet.
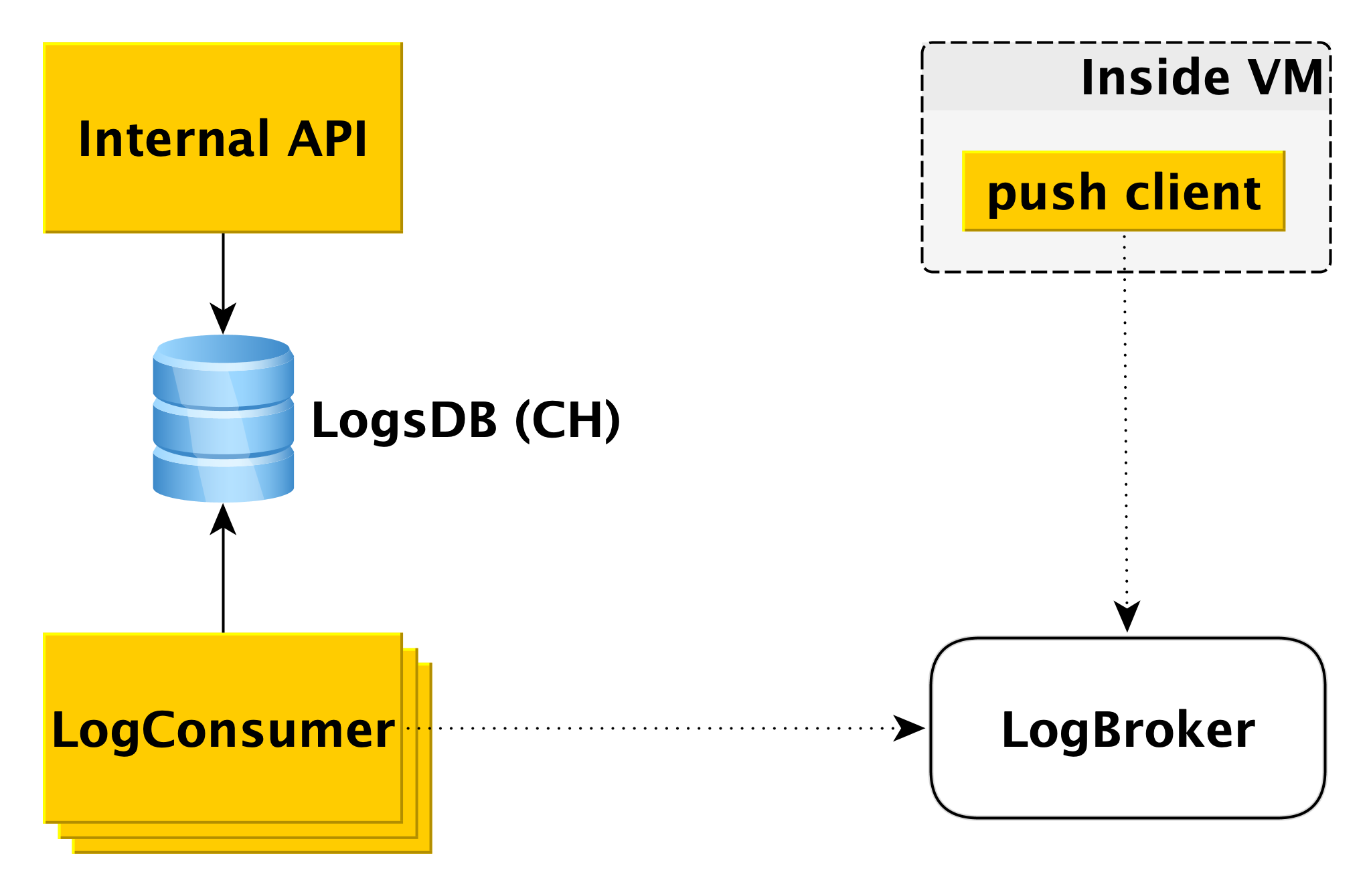
Wenn eine Anforderung an die interne API gesendet wird, um Protokolle für ein bestimmtes Zeitintervall für einen bestimmten Cluster anzuzeigen, überprüft die interne API die Autorisierung und sendet die Anforderung an LogsDB. Somit ist die Protokollübermittlungsschleife vollständig unabhängig von der Protokollanzeigeschleife.
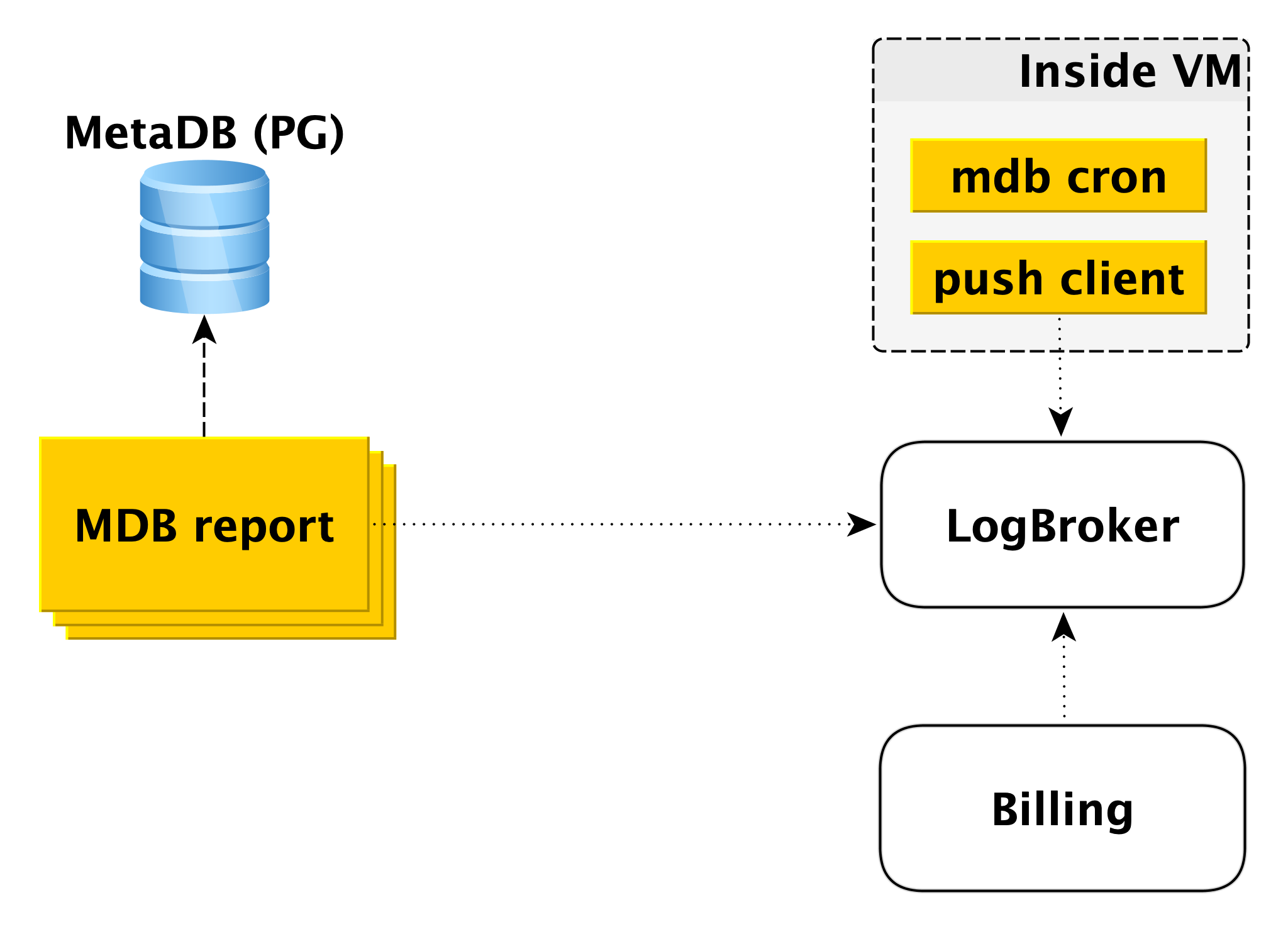
Abrechnung
Das Abrechnungsschema ist ähnlich aufgebaut. Innerhalb der virtuellen Maschine gibt es eine Komponente, die mit einer bestimmten Periodizität prüft, ob in der Datenbank alles in Ordnung ist. Wenn alles in Ordnung ist, können Sie dieses Zeitintervall ab dem Zeitpunkt des letzten Starts abrechnen. In diesem Fall wird ein Datensatz im Abrechnungsprotokoll erstellt, und der Push-Client sendet den Datensatz an LogBroker. Die Daten von Logbroker werden an das Abrechnungssystem übertragen und dort berechnet. Dies ist ein Abrechnungsschema für die Ausführung von Clustern.
Wenn der Cluster deaktiviert ist, wird die Nutzung der Computerressourcen nicht mehr berechnet, der Speicherplatz wird jedoch berechnet. In diesem Fall ist eine Abrechnung von der virtuellen Maschine nicht möglich, und es handelt sich um die zweite Schaltung - die Offline-Abrechnungsschaltung. Es gibt einen separaten Pool von Computern, die die Liste der Shutdown-Cluster aus MetaDB abrufen und in Logbroker ein Protokoll im gleichen Format schreiben.
Die Offline-Abrechnung kann auch für die Abrechnung von Rechnungen und eingeschlossenen Clustern verwendet werden. Dann stellen wir Hosts Abrechnungen, auch wenn diese ausgeführt werden, aber nicht funktionieren. Wenn Sie beispielsweise einem Cluster einen Host hinzufügen, wird dieser aus der Sicherung bereitgestellt und die Replikation wird fortgesetzt. Es ist falsch, dies dem Benutzer in Rechnung zu stellen, da der Host für diesen Zeitraum inaktiv ist.
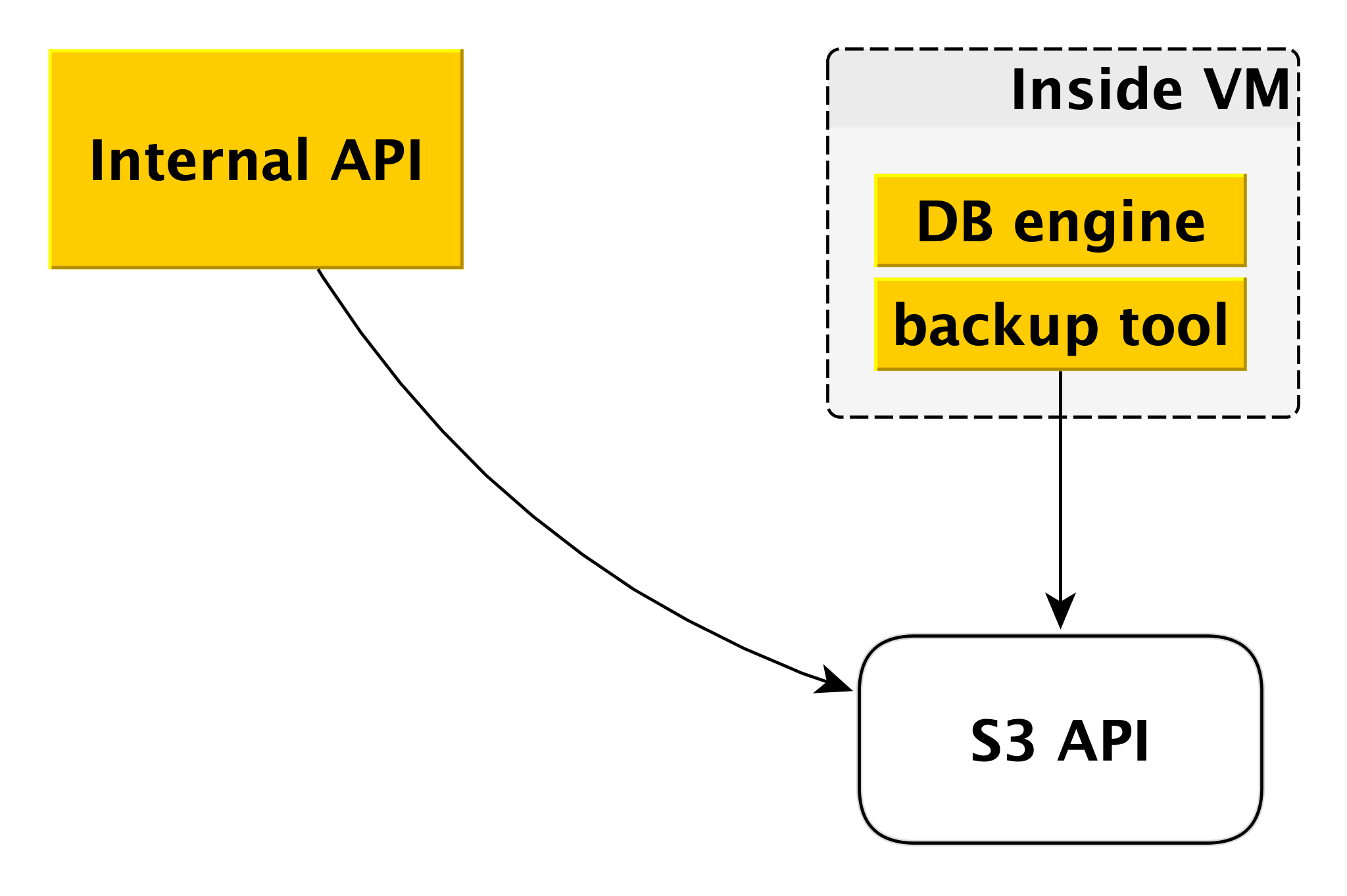
Backup
Das Sicherungsschema kann sich für verschiedene DBMS geringfügig unterscheiden, das allgemeine Prinzip ist jedoch immer dasselbe.
Jedes Datenbankmodul verwendet ein eigenes Sicherungstool. Für PostgreSQL und MySQL ist dies
WAL-G . Es erstellt Backups, komprimiert sie, verschlüsselt sie und legt sie in
Yandex Object Storage ab . Gleichzeitig wird jeder Cluster in einem separaten Bucket abgelegt (zum einen zur Isolierung und zum anderen, um Speicherplatz für Sicherungen zu sparen) und mit einem eigenen Verschlüsselungsschlüssel verschlüsselt.
So funktionieren Control Plane und Data Plane. Daraus wird der verwaltete Datenbankdienst Yandex.Cloud gebildet.
Warum ist alles so angeordnet?
Natürlich könnte auf globaler Ebene etwas nach einfacheren Schemata implementiert werden. Aber wir hatten unsere eigenen Gründe, dem Weg des geringsten Widerstands nicht zu folgen.
Zunächst wollten wir eine gemeinsame Steuerungsebene für alle Arten von DBMS. Es spielt keine Rolle, für welche Sie sich entscheiden, am Ende wird Ihre Anfrage an dieselbe interne API gesendet, und alle Komponenten darunter sind auch allen DBMS gemeinsam. Das macht unser Leben technisch etwas komplizierter. Andererseits ist es viel einfacher, neue Funktionen und Fähigkeiten einzuführen, die alle DBMS betreffen. Dies wird einmal gemacht, nicht sechs.
Der zweite wichtige Moment für uns - wir wollten die Unabhängigkeit der Datenebene von der Kontrollebene so weit wie möglich sicherstellen. Selbst wenn Control Plane heute nicht mehr verfügbar ist, funktionieren alle Datenbanken weiterhin. Der Service stellt deren Zuverlässigkeit und Verfügbarkeit sicher.
Drittens ist die Entwicklung fast aller Dienste immer ein Kompromiss. Im Allgemeinen ist grob gesagt die Geschwindigkeit der Veröffentlichung von Veröffentlichungen und eine zusätzliche Zuverlässigkeit von größerer Bedeutung. Zur gleichen Zeit kann es sich jetzt niemand mehr leisten, ein oder zwei Veröffentlichungen pro Jahr zu machen, das ist offensichtlich. Wenn Sie sich Control Plane anschauen, konzentrieren wir uns hier auf die Geschwindigkeit der Entwicklung, auf die schnelle Einführung neuer Funktionen und darauf, Updates mehrmals pro Woche einzuführen. Und Data Plane ist verantwortlich für die Sicherheit Ihrer Datenbanken und für die Fehlertoleranz. Daher gibt es hier einen völlig anderen Release-Zyklus, der in Wochen gemessen wird. Und diese Flexibilität in Bezug auf die Entwicklung gibt uns auch die gegenseitige Unabhängigkeit.
Ein weiteres Beispiel: In der Regel stellen verwaltete Datenbankdienste Benutzern nur Netzlaufwerke zur Verfügung. Yandex.Cloud bietet auch lokale Laufwerke an. Der Grund ist einfach: Ihre Geschwindigkeit ist viel höher. Mit Netzwerklaufwerken ist es beispielsweise einfacher, die virtuelle Maschine zu vergrößern und zu verkleinern. Es ist einfacher, Backups in Form von Snapshots des Netzwerkspeichers zu erstellen. Viele Benutzer benötigen jedoch eine hohe Geschwindigkeit, weshalb wir die Sicherungswerkzeuge weiterentwickeln.
Zukunftspläne
Und ein paar Worte zu Plänen, den Service mittelfristig zu verbessern. Hierbei handelt es sich um Pläne, die sich auf die gesamte verwaltete Datenbank von Yandex und nicht auf einzelne DBMS auswirken.
Zunächst möchten wir die Häufigkeit der Sicherungserstellung flexibler einstellen. Es gibt Szenarien, in denen während des Tages alle paar Stunden, während der Woche, einmal am Tag, während des Monats, einmal in der Woche, während des Jahres, einmal im Monat Sicherungen durchgeführt werden müssen. Zu diesem Zweck entwickeln wir eine separate Komponente zwischen der internen API und
Yandex Object Storage .
Ein weiterer wichtiger Punkt, der sowohl für die Benutzer als auch für uns wichtig ist, ist die Geschwindigkeit des Betriebs. Wir haben kürzlich wesentliche Änderungen an der Bereitstellungsinfrastruktur vorgenommen und die Ausführungszeit fast aller Vorgänge auf einige Sekunden reduziert. Nicht behandelt wurden nur die Vorgänge zum Erstellen eines Clusters und zum Hinzufügen eines Hosts zum Cluster. Die Ausführungszeit der zweiten Operation hängt von der Datenmenge ab. Das erste Verfahren werden wir jedoch in naher Zukunft beschleunigen, da Benutzer häufig Cluster in ihren CI / CD-Pipelines erstellen und löschen möchten.
Unsere Liste wichtiger Fälle umfasst die Hinzufügung der Funktion zum automatischen Erhöhen der Festplattengröße. Dies geschieht nun manuell, was nicht sehr praktisch und nicht sehr gut ist.
Schließlich bieten wir den Benutzern eine Vielzahl von Grafiken, die zeigen, was mit der Datenbank passiert. Wir geben Zugriff auf die Protokolle. Gleichzeitig stellen wir fest, dass die Daten manchmal nicht ausreichen. Benötigen Sie andere Grafiken, andere Scheiben. Hier planen wir auch Verbesserungen.
Unsere Geschichte über den verwalteten Datenbankdienst erwies sich als langwierig und wahrscheinlich als ziemlich mühsam. Besser als alle Worte und Beschreibungen, nur echte Praxis. Wenn Sie möchten, können Sie daher die Leistungsfähigkeit unserer Dienstleistungen unabhängig voneinander bewerten: