Wahrscheinlich gibt es in jeder Stadt in Weißrussland, in der es Oberleitungsbusse gibt, VK-Gruppen oder Chats auf Telegram, in denen Personen den Standort der Controller verfolgen. Dies geschieht hauptsächlich, um nicht für Reisen und Reisen kostenlos zu bezahlen, obwohl die Beschreibung der Gruppen fast immer das Nachskript „Für Reisen bezahlen“ enthält.
In VC sieht es normalerweise so aus:
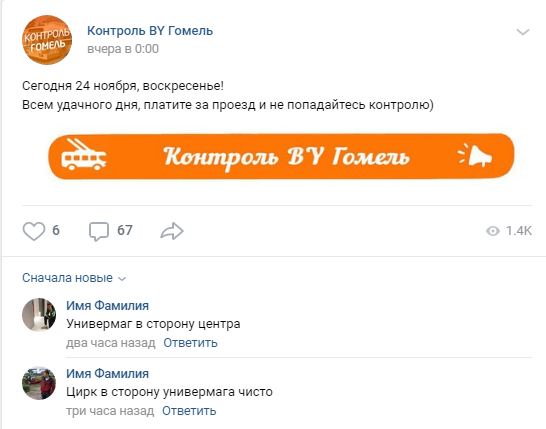
Ein typischer Kommentar sieht so aus:
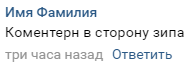
Der Aufbau ist denkbar einfach. Im Kommentar stehen die Namen der Haltestellen, an denen die Controller gerade bemerkt wurden, sowie die Richtung, in der sie stehen:
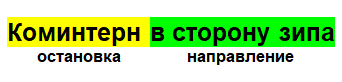
Der Kommentar ist daher ein Objekt mit einem Stopp, einer Uhrzeit und einem Datum sowie einer eindeutigen ID, anhand derer wir ihn identifizieren können. Auf diese Weise können Sie die wahrscheinlichste Position berechnen, an der sich die Steuerungen jetzt befinden.
Vorbereitung
Zuerst müssen Sie die Zielgruppe bestimmen, aus der die Daten analysiert werden. Die Gruppe sollte ziemlich viel Aktivität in den Kommentaren haben, sonst riskieren wir, zu wenig Daten zu bekommen
In meinem Fall ist dies die Gruppe „Control Gomel“.
Wir analysieren Kommentare mit der offiziellen VKontakte-API für Python
Wir authentifizieren uns mit dem Zugriffsschlüssel des Benutzers, da einige Gruppen möglicherweise geschlossen sind und der Zugriff auf ihre Kommentare nur möglich ist, wenn Sie in die Gruppe aufgenommen wurden.
Danach können Sie Kommentare extrahieren:
Kommentare erhalten
Zunächst erhalten wir den letzten verfügbaren Beitrag in der Gruppe, um Kommentare über vk.wall.getComments abzurufen und den DataFrame zu initialisieren, in dem die Daten gespeichert werden.
Jeder Kommentarbeitrag trägt die Aufschrift „Ich wünsche Ihnen einen schönen Tag, bezahle den Fahrpreis und gerate nicht unter Kontrolle“. Laden Sie daher die Kommentare herunter, überprüfen Sie den Inhalt des Beitrags und erhalten Sie eine Reihe von Kommentaren, aus denen Sie Daten abrufen können.
Ich habe Kommentare von Posts in den letzten 3 Monaten gelesen, da täglich 1 Post veröffentlicht wird (jetzt, Ende November, beginnt das Schuljahr im September, und die Betreuer berücksichtigen dies höchstwahrscheinlich und wechseln ihre gewöhnlichen Plätze). Grundsätzlich können auch andere Vorzeichen berücksichtigt werden, wie zum Beispiel die Jahreszeit.
Einige der Kommentare sind mit Nachrichten wie "Gibt es jemanden auf Barykin?" Wenn Sie sich solche (unnötigen) Kommentare ansehen, können Sie einige Anzeichen hervorheben:
- Der Text enthält die Wörter "sauber", "links", "niemand" und dergleichen
- Die Worte "sag mir", "wer", "was", "wie"
- Symbole wie zum Beispiel Emoticons
Danach gehen wir eine Reihe von Kommentaren durch und ziehen eine eindeutige ID, einen eindeutigen Text, eine eindeutige Uhrzeit, ein eindeutiges Datum und einen eindeutigen Wochentag heraus, die wir in den bereits erstellten DataFrame einfügen.
Kommentare erhaltenimport re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID):
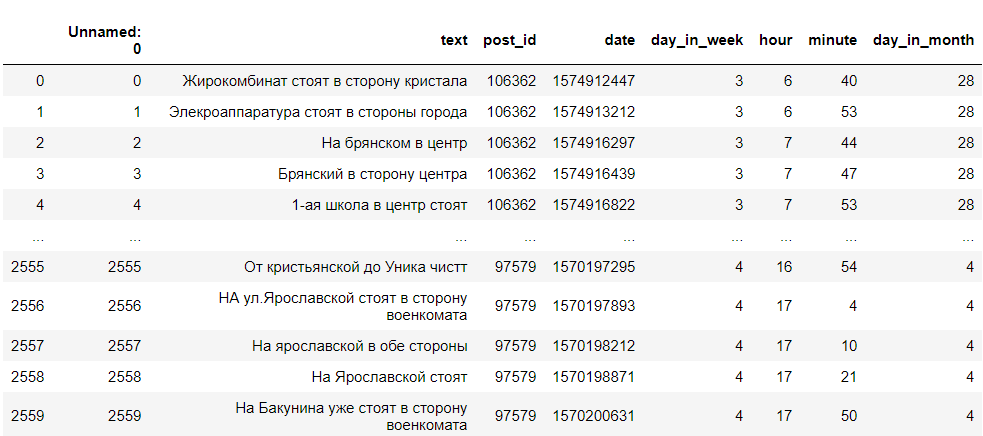
So erhielten wir einen DataFrame mit dem Kommentartext, der ID, dem Wochentag, der Stunde und der Minute, in der der Kommentar geschrieben wurde. Wir brauchen nur den Wochentag, die Schreibstunde und den Text. Es sieht ungefähr so aus:
Datenbereinigung
Jetzt müssen wir die Daten löschen. Es ist notwendig, die Richtung aus dem Kommentar zu entfernen, um weniger Fehler bei der Suche nach der Levenshtein-Entfernung zu machen. Wir finden die Ausdrücke "zur Seite", "gehen", "wie", "in der Nähe", da ihnen normalerweise der Name der zweiten Haltestelle folgt, und wir löschen sie zusammen mit dem, was danach kommt, sowie ersetzen einige umgangssprachliche Namen der Haltestellen durch die üblichen .
Daten löschen from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
Konvertieren mit Levenshtein Abstand
Wir fahren direkt zur Levenshane-Strecke. Eine kleine Hilfe: Levenshtein distance - die minimale Anzahl von Operationen, um ein Zeichen einzufügen, ein Zeichen zu löschen und ein Zeichen durch ein anderes zu ersetzen, die erforderlich sind, um eine Zeile in eine andere zu verwandeln.
Wir werden es mit der
Fuzzywuzzy- Bibliothek finden. Sie können damit schnell und einfach die Levenshtein-Entfernung berechnen. Um die Arbeit zu beschleunigen, empfehlen die Autoren der Bibliothek auch die Installation der Python-Levenshtein-Bibliothek.
Um Stopps von Kommentaren zu erhalten, benötigen wir eine Liste von Stopps. Es wurde mir freundlicherweise vom Entwickler der GoTrans-Anwendung, Alexander Kozlov, zur Verfügung gestellt.
Die Liste musste erweitert werden, um dort einige Haltestellen hinzuzufügen, die nicht vorhanden waren, und um einen Teil der Namen zu ändern, damit sie besser zu finden waren.
StopptHaltestellen = ['Supermarkt', 'Wiese', 'Remybtekhnika', 'Leningrad', 'Jaroslawl', 'Polesskaja',
"Jaroslawl", "Timofeenko", "8. März",
"Rechitsky Handelshaus", "Rechitsky Avenue", "Zirkus", "Kaufhaus", "Chongarskaya",
"Chongarka", "Ggu", "Skorina", "Universität", "Gerät", "1000 kleine Dinge", "Maya", "Station",
"Absolventenpark", "Handel und Wirtschaft", "Jubiläum", "Mikrobezirk 18", "Flughafen", "Gegenverkehr",
'gomelgeodezcentr', 'crystal', 'lake lyubenskoye', 'davydovsky market', 'davydovka',
"Fluss sozh", "gomeldrev",
"Sevruki", "GMU Nr. 1", "etc. Rechitsky", "Kostüm", "Krankenhaus für Infektionskrankheiten", "Möwenlager",
Volotova, Koralle, Gomeltorgmash, Gomelproekt, Vneshgomelstroy, Zeitung,
"Kalenikova", "Eremino", "Brennerei", "spezielle industrielle Automatisierung", "2. Schule", "Barykina",
"Maschineneinheiten", "Jugend", "Casting-Körper", "Chemiker", "Golovatsky", "budenny",
"Spu67", "35th", "Gagarin", "50 Jahre bis zum Werk Gomselmash", "Hügel", "Radiofabrik",
"Großmutter", "Glashütte", "Kastanie", "Anlassen von Motoren", "Astronauten",
"rtsrm initial", "bykhovskaya", "Institut des Ministeriums für Notsituationen", "dk gomselmash", "store", "rechitsky",
"Sevruks", "Osovtsy", "Tourist", "Fleischfabrik", "Holy Trinity", "Medical Town", "Oktober",
"Öldepot", "Gomelloblavtotrans", "Milkavita", "Bakunin", "Zip", "Oma", "Harz",
"Baumarkt Ksk", "Straßenbauer", "Feld", "Kamenetskaya", "Bolschewik", "Jakubovka",
"Borodina", "Hippo-Hypermarkt", "Untergrundhelden", "9. Mai", "Kastanie", "Prothetiker",
"iput station", "communist international", "musikpädagogische Hochschule", "landwirtschaftliche Firma", "Umgehungsstraße", "Sieg",
"westlichen", "Perle", "Vladimir", "trocken", "Apotheke", "Ivanova",
"Maschinenbau", "Birken", "60 Jahre", "Power Engineer", "Centrolite",
"Onkologische Klinik", "Schießstand", "Golovintsy", "Koralle", "Süd", "Frühling",
Efremova, Grenze, Belgut, Gomelstroy, Borisenko, Leichtathletikpalast,
"Mitschurinski", "Solar", "Gastello", "Militär", "Autozentrum", "Sanitär", "Uza",
"Medical College", "Kindergarten 11", "Bolschewiki", "Welpen", "Davydovsky", "Ozean", "Fortschritt",
"Dobrushskaya", "weiß", "GSK", "davydovka", "elektrische Ausrüstung", "Freundschaft",
'70 Jahre ',' Autoreparatur ',' Schwedischer Hügel ',' Rennstrecke ',' Wasserkanal ',' Maschinengomel ',
Volotova, Pionier, RCM, Khimtorg, 2. Wiesenstraße, Bochkina, Bäder,
"Onkologische Klinik", "Square", "Lenin", "1st School", "South Store",
'gomelagrotrans', 'millers', 'lyubensky', 'military enlistment office', 'hospital', 'uza', 'rtsrm',
"lysyukovy", "shop iput", "raton", "tankstelle", "randovskoe", "bauernhaus", "kastanie", "ropovsky",
"Romanovichi", "Iljitsch", "Rudern", "Bauunternehmen", "ansteckend",
"Fettfabrik", "Autoservice", "Agroservice", "klebrig", "Nikolskaya",
"Selbstfahrende Erntemaschinen", "Maurer", "Baustoffe", "Reparaturmaschinen", "Verwaltung",
"Oktober", "Waldmärchen", "Tatiana", "Boris Tsarikov", "Zharkovsky", "Zaitseva",
"Umzug", "Karpovich", "Hausbau", "Stadt Elektromobilität", "Zlin",
"stadium gomselmash", "ap 6", "hydraulischer antrieb", "lokomotivendepot", "automarkt osovtsy",
"Neues Leben", "Schukowa", "Militäreinheit", "Dritte Schule", "Wald", "Roter Leuchtturm",
"Regional", "Davydovskaya", "Karbysheva", "Satellit der Welt", "Jugend", "Stadion Lokomotive",
"Solar", "Ladaservice", "μR 21", "Aresa", "Internationalisten", "Kosareva",
"Bogdanova", "Gomel Eisenbeton", "μr 20a", "μr Rechitsky", "medizinische Ausrüstung", "Juraeva",
"College of Art Crafts", "Ice", "DK Festival", "Einkaufszentrum",
"Kuibyshevsky", "Festival", "Garage Koop 27", "Seismik", "Milcha", "Tube Hospital",
"ptu179", "chemische Produkte", "Feuerwehr", "Krankenhaus", "Busdepot",
"Zeitungskomplex", "Sieg", "Klenkowski", "Diamant", "Motorreparatur", "mkr 19"]
Mit .map und fuzzywuzzy.process.extractOne finden wir die Haltestelle mit dem minimalen Levenshtein-Abstand in der Liste. Danach ersetzen wir den Kommentartext durch den Namen der Haltestelle, wodurch wir einen Datensatz mit den Namen der Haltestellen erhalten.
Der resultierende Datensatz sieht ungefähr so aus:
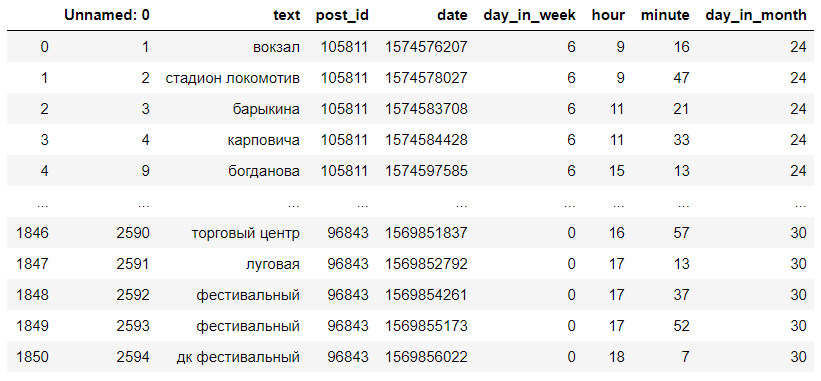
Kommentare werden zu Stopps def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
Datenausgabe
Jetzt können wir davon ausgehen, wo sich die Controller höchstwahrscheinlich zur gegebenen Stunde befinden werden.
Wir suchen in den resultierenden Datensätzen nach einer bestimmten Stunde und einem bestimmten Wochentag. Zum Beispiel am Dienstag, 9 Uhr:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
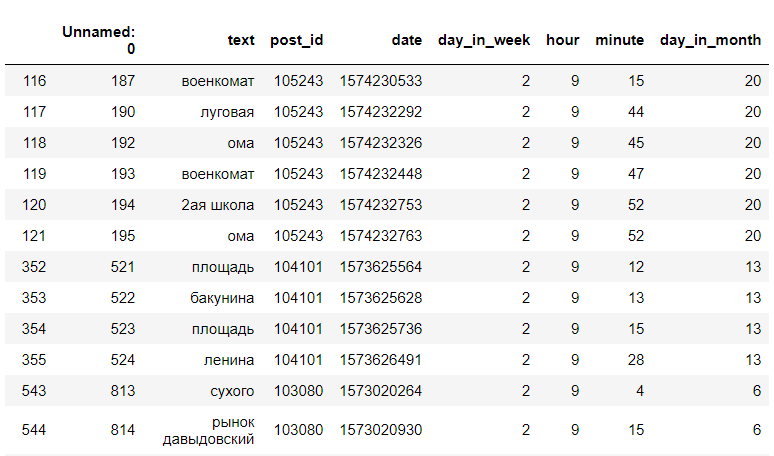 (das sind nicht alle Daten)
(das sind nicht alle Daten)Danach finden wir die Anzahl der eindeutigen Haltestellen und zeigen nur die Haltestellen und ihre Anzahl an:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

Jetzt können wir sagen, dass die Controller am Dienstag um 9 Uhr morgens höchstwahrscheinlich an den Haltestellen Myasokombinat, Ul. Lugovaya, BelGUT, TD "Oma".
Der Hauptfehler bei dieser Methode ist der Mangel an Daten. Nicht für alle Tage und Stunden gibt es Einträge in den Kommentaren, die während der Hauptverkehrszeit gegeben werden, wenn die Leute mehr öffentliche Verkehrsmittel benutzen als die Daten in weniger populären Stunden, wenn Sie jedoch Daten hinzufügen, beispielsweise nicht nur aus den Kommentaren einer Gruppe, sondern auch von alternativen Gruppen oder Telegramm-Chats mit der Anzahl der Einträge wird alles einfacher.
Bot mit VK LongPoll API
Um die Möglichkeit zu geben, zeitabhängig und ohne Bindung an einen Computer Daten über den Standort der Steuerungen zu empfangen, habe ich einen Bot für eine Gruppe in VKontakte erstellt, der auf jede Nachricht mit der Anzahl der Stopps in den Aufzeichnungen unter Berücksichtigung der aktuellen Stunde und des aktuellen Wochentags reagiert.
Bot-Code from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True:
Fazit
Die Qualität solcher Hypothesen wurde von mir mehr als einmal in der Praxis getestet, und alles funktioniert einwandfrei. Es stellte sich heraus, dass die Controller im Grunde genommen an den gleichen Haltestellen sind, obwohl absolut korrekte Vorhersagen nicht gegeben werden können und die Erfolgswahrscheinlichkeit nicht 100% beträgt. Die Entfernung von Levenshtein hat Dutzende verschiedener Anwendungen, angefangen von der Korrektur von Fehlern in einem Wort bis hin zum Vergleich von Genen, Chromosomen und Proteinen, aber auch Potenzial bei solchen angewandten Problemen.
Ich wünsche Ihnen einen schönen Tag und bezahle den Fahrpreis.
Alle Botcode- und Datenmanipulationen werden
hier veröffentlicht .