Hallo allerseits, mein Name ist Alexander, ich arbeite als Ingenieur bei CIAN und bin in der Systemadministration und Automatisierung von Infrastrukturprozessen tätig. In den Kommentaren zu einem der vorherigen Artikel wurden wir gebeten, anzugeben, wo wir 4 TB an Protokollen pro Tag erhalten und was wir damit machen. Ja, wir haben viele Protokolle und es wurde ein separater Infrastruktur-Cluster erstellt, um diese zu verarbeiten, sodass wir Probleme schnell lösen können. In diesem Artikel werde ich darüber sprechen, wie wir es im Laufe des Jahres angepasst haben, um mit einem stetig wachsenden Datenfluss zu arbeiten.
Wo haben wir angefangen?
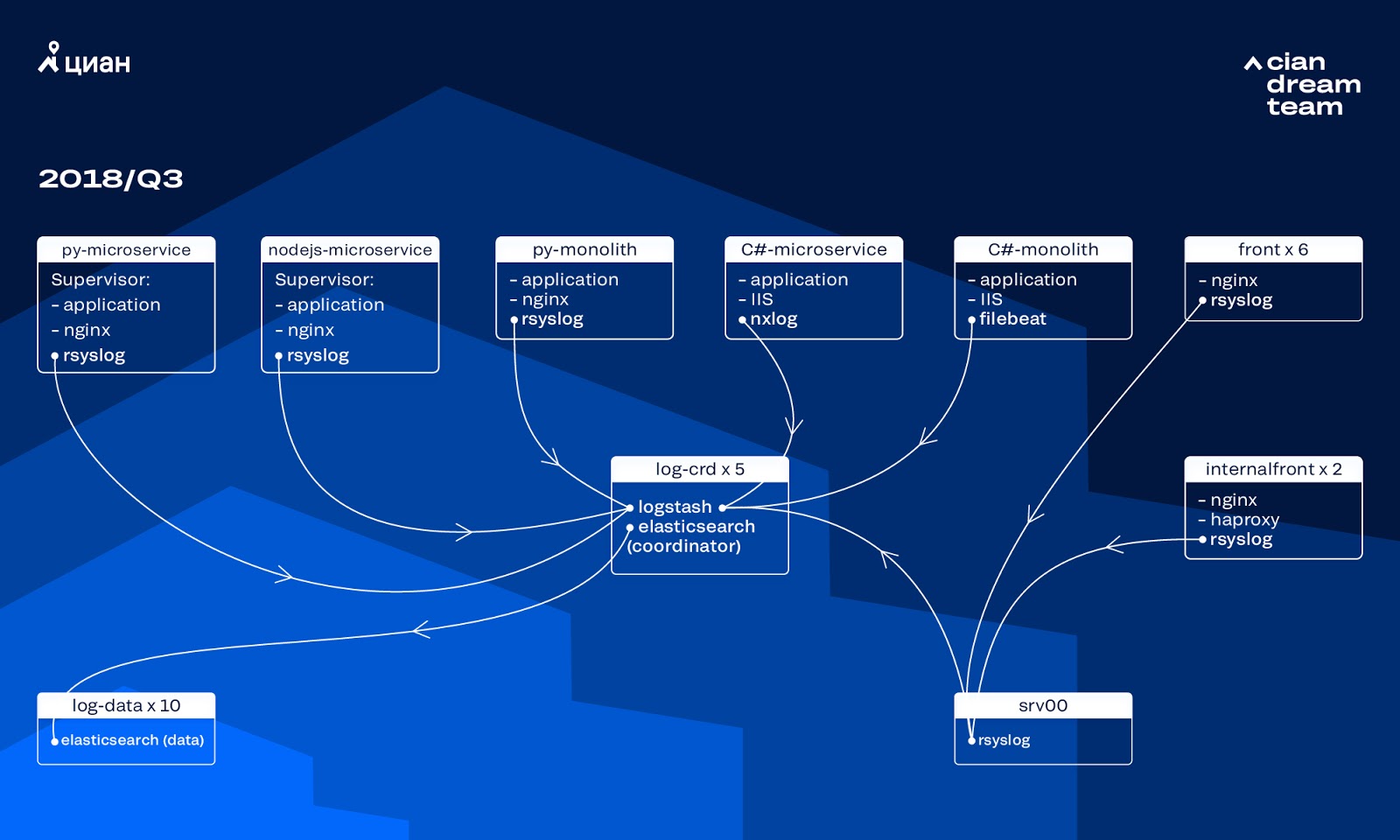
In den letzten Jahren ist die Auslastung von cian.ru sehr schnell gewachsen, und im dritten Quartal 2018 erreichte der Ressourcenverkehr 11,2 Millionen Unique User pro Monat. Zu diesem Zeitpunkt, in kritischen Momenten, haben wir bis zu 40% der Protokolle verloren, weshalb wir Vorfälle nicht schnell bearbeiten konnten und viel Zeit und Mühe auf ihre Behebung verwendet haben. Wir konnten die Ursache des Problems oft nicht finden und es trat nach einiger Zeit wieder auf. Es war die Hölle, mit der du etwas anfangen musstest.
Zu diesem Zeitpunkt verwendeten wir einen Cluster von 10 Datenknoten mit ElasticSearch Version 5.5.2 mit typischen Indexeinstellungen zum Speichern von Protokollen. Es wurde vor mehr als einem Jahr als beliebte und erschwingliche Lösung eingeführt: Damals war der Protokolldatenstrom nicht so groß, und es ergab keinen Sinn, nicht standardmäßige Konfigurationen zu entwickeln.
Logstash auf verschiedenen Ports ermöglichte die Verarbeitung eingehender Protokolle auf fünf ElasticSearch-Koordinatoren. Ein Index, unabhängig von der Größe, bestand aus fünf Scherben. Es wurde eine stündliche und tägliche Rotation organisiert, sodass stündlich etwa 100 neue Scherben im Cluster erschienen. Obwohl es nicht sehr viele Protokolle gab, verwaltete der Cluster und niemand machte auf seine Einstellungen aufmerksam.
Wachstumsprobleme
Das Volumen der generierten Protokolle wuchs sehr schnell, da sich zwei Prozesse überlappten. Einerseits gab es immer mehr Nutzer des Dienstes. Andererseits begannen wir, aktiv auf Microservice-Architektur umzusteigen und unsere alten Monolithen in C # und Python zu zersägen. Mehrere Dutzend neue Mikrodienste, die Teile des Monolithen ersetzten, erzeugten erheblich mehr Protokolle für den Infrastrukturcluster.
Es war die Skalierung, die dazu führte, dass der Cluster praktisch unkontrollierbar wurde. Als die Protokolle mit einer Geschwindigkeit von 20.000 Nachrichten pro Sekunde ankamen, erhöhte die häufige nutzlose Rotation die Anzahl der Shards auf 6.000, und auf einen Knoten entfielen mehr als 600 Shards.
Dies führte zu Problemen bei der Zuweisung des Arbeitsspeichers. Als ein Knoten ausfiel, begannen alle Shards gleichzeitig zu verschieben, den Datenverkehr zu vervielfachen und die verbleibenden Knoten zu laden. Dies machte das Schreiben von Daten in den Cluster nahezu unmöglich. Und während dieser Zeit blieben wir ohne Protokolle. Und bei einem Serverproblem haben wir im Prinzip 1/10 des Clusters verloren. Eine große Anzahl kleiner Indizes erhöhte die Komplexität.
Ohne Protokolle haben wir die Ursachen des Vorfalls nicht verstanden und konnten früher oder später wieder auf den gleichen Rechen treten. In der Ideologie unseres Teams war dies jedoch inakzeptabel, da alle Arbeitsmechanismen, an denen wir gearbeitet hatten, genau umgekehrt waren - wiederholen Sie niemals dieselben Probleme. Zu diesem Zweck benötigten wir eine vollständige Menge von Protokollen und deren Lieferung in nahezu Echtzeit, da ein Team von Einsatzingenieuren Warnungen nicht nur anhand von Messwerten, sondern auch anhand von Protokollen überwachte. Um das Ausmaß des Problems zu verstehen - zu diesem Zeitpunkt betrug das Gesamtvolumen der Protokolle etwa 2 TB pro Tag.
Wir haben uns zum Ziel gesetzt, den Verlust von Protokollen vollständig zu vermeiden und die Zeit bis zu deren Zustellung an den ELK-Cluster während höherer Gewalt auf maximal 15 Minuten zu verkürzen (wir haben uns in Zukunft auf diese Zahl als internen KPI gestützt).
Neuer Rotationsmechanismus und heiß-warme Knoten
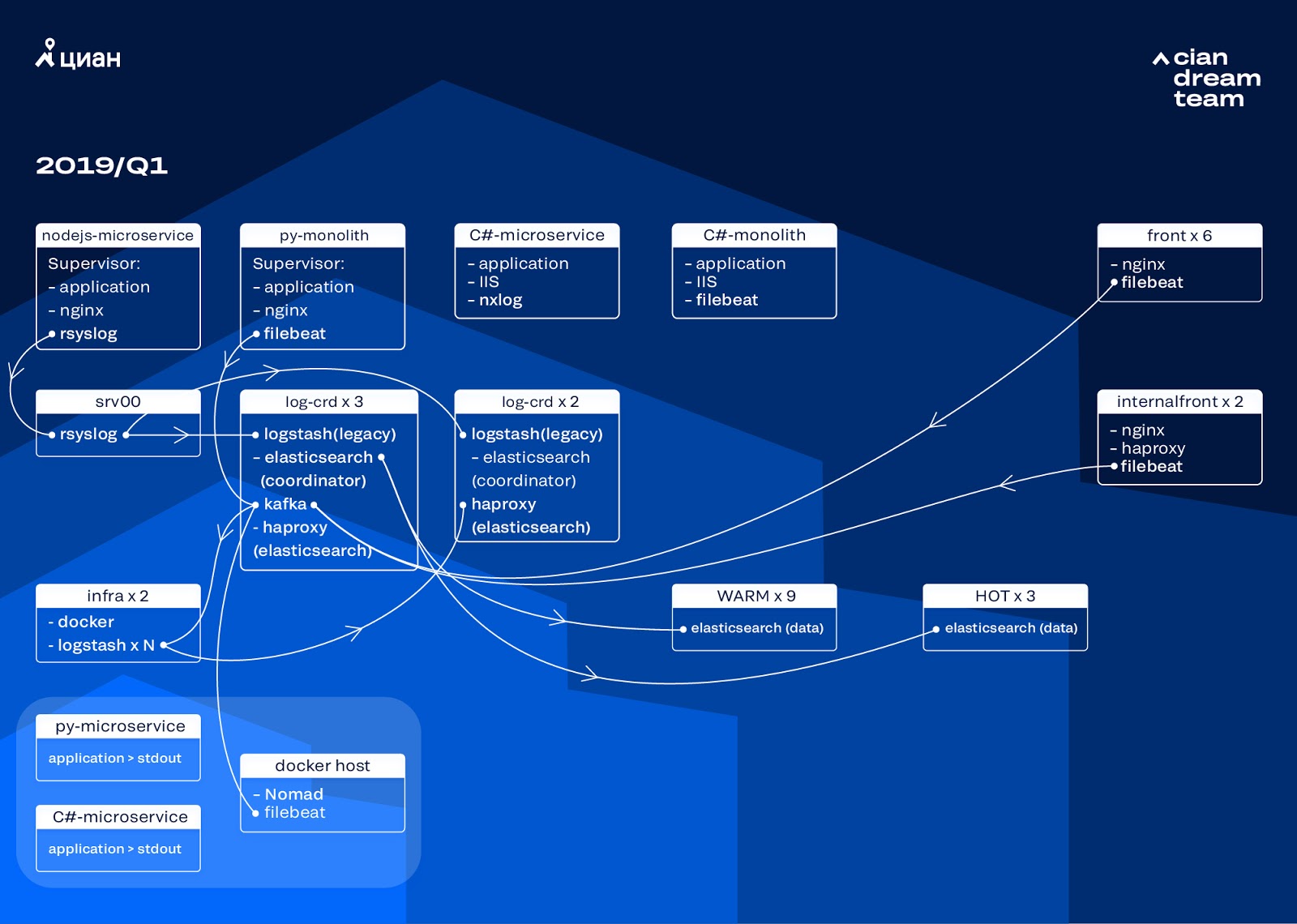
Wir haben die Cluster-Transformation gestartet, indem wir die Version von ElasticSearch von 5.5.2 auf 6.4.3 aktualisiert haben. Wieder einmal ist ein Cluster der Version 5 auf uns heruntergekommen, und wir haben beschlossen, es zurückzuzahlen und vollständig zu aktualisieren - es sind noch keine Protokolle vorhanden. So haben wir diesen Übergang in nur wenigen Stunden geschafft.
Die ehrgeizigste Transformation in dieser Phase war die Einführung von drei Knoten mit dem Koordinator als Zwischenpuffer Apache Kafka. Der Nachrichtenbroker hat uns vor dem Verlust von Protokollen bei Problemen mit ElasticSearch bewahrt. Gleichzeitig haben wir dem Cluster zwei Knoten hinzugefügt und auf eine Hot-Warm-Architektur mit drei „Hot“ -Knoten umgestellt, die in verschiedenen Racks im Rechenzentrum angeordnet sind. Wir haben Protokolle an diese weitergeleitet, die auf keinen Fall verloren gehen sollten - nginx sowie Anwendungsfehlerprotokolle. Kleinere Protokolle - Debugging, Warnung usw. - wurden an andere Knoten gesendet und nach 24 Stunden wurden wichtige Protokolle von aktiven Knoten verschoben.
Um die Anzahl der kleinen Indizes nicht zu erhöhen, haben wir von der Zeitrotation auf den Rollover-Mechanismus umgestellt. In den Foren gab es viele Informationen darüber, dass die Drehung um die Indexgröße sehr unzuverlässig ist. Daher haben wir uns für die Drehung um die Anzahl der Dokumente im Index entschieden. Wir haben jeden Index analysiert und die Anzahl der Dokumente aufgezeichnet, nach denen die Rotation funktionieren soll. Damit haben wir die optimale Größe des Shards erreicht - nicht mehr als 50 GB.
Cluster-Optimierung
Die Probleme haben wir jedoch nicht ganz beseitigt. Leider erschienen kleine Indizes trotzdem: Sie erreichten nicht das festgelegte Volumen, drehten sich nicht und wurden durch die globale Bereinigung von Indizes, die älter als drei Tage waren, gelöscht, da wir die Drehung nach Datum entfernt haben. Dies führte zu Datenverlusten, da der Index aus dem Cluster vollständig verschwand und der Versuch, in einen nicht vorhandenen Index zu schreiben, die für die Steuerung verwendete Kuratorenlogik unterbrach. Der Alias für die Aufzeichnung wurde in einen Index umgewandelt und brach die Rollover-Logik, was zu einem unkontrollierten Wachstum einiger Indizes auf 600 GB führte.
So konfigurieren Sie beispielsweise die Drehung:
urator-elk-rollover.yaml --- actions: 1: action: rollover options: name: "nginx_write" conditions: max_docs: 100000000 2: action: rollover options: name: "python_error_write" conditions: max_docs: 10000000
In Abwesenheit eines Rollover-Alias ist ein Fehler aufgetreten:
ERROR alias "nginx_write" not found. ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Wir haben die Lösung für dieses Problem für die nächste Iteration hinterlassen und eine andere Frage aufgeworfen: Wir haben auf die Logik von Logstash umgestellt, die eingehende Protokolle verarbeitet (unnötige Informationen entfernen und anreichern). Wir haben es in docker platziert, das wir über docker-compose ausführen, und logstash-exporter an derselben Stelle platziert, wodurch Prometheus die Metriken für die Betriebsüberwachung des Protokolldatenstroms erhält. Deshalb haben wir uns die Möglichkeit gegeben, die Anzahl der für die Verarbeitung der einzelnen Protokolltypen verantwortlichen Protokollstash-Instanzen reibungslos zu ändern.
Während wir den Cluster verbesserten, stieg der Traffic von cian.ru auf 12,8 Millionen Unique User pro Monat. Infolgedessen stellte sich heraus, dass unsere Conversions nicht mit den Änderungen in der Produktion Schritt hielten und wir mit der Tatsache konfrontiert waren, dass die "warmen" Knoten die Last nicht bewältigen konnten und die gesamte Zustellung von Protokollen verlangsamten. Wir haben die "heißen" Daten ohne Fehler erhalten, mussten jedoch in die Zustellung der restlichen Daten eingreifen und einen manuellen Rollover durchführen, um die Indizes gleichmäßig zu verteilen.
Gleichzeitig wurde das Skalieren und Ändern der Einstellungen von Logstash-Instanzen im Cluster durch die Tatsache erschwert, dass es sich um einen lokalen Docker-Compose handelte und alle Aktionen von Hand ausgeführt wurden (um neue Aufgaben hinzuzufügen, mussten Sie alle Server mit Ihren Händen durchgehen und Docker-Compose-D überall ausführen).
Log redistribution
Im September dieses Jahres sahen wir immer noch den Monolithen, die Auslastung des Clusters nahm zu und der Protokolldatenstrom näherte sich 30.000 Nachrichten pro Sekunde.
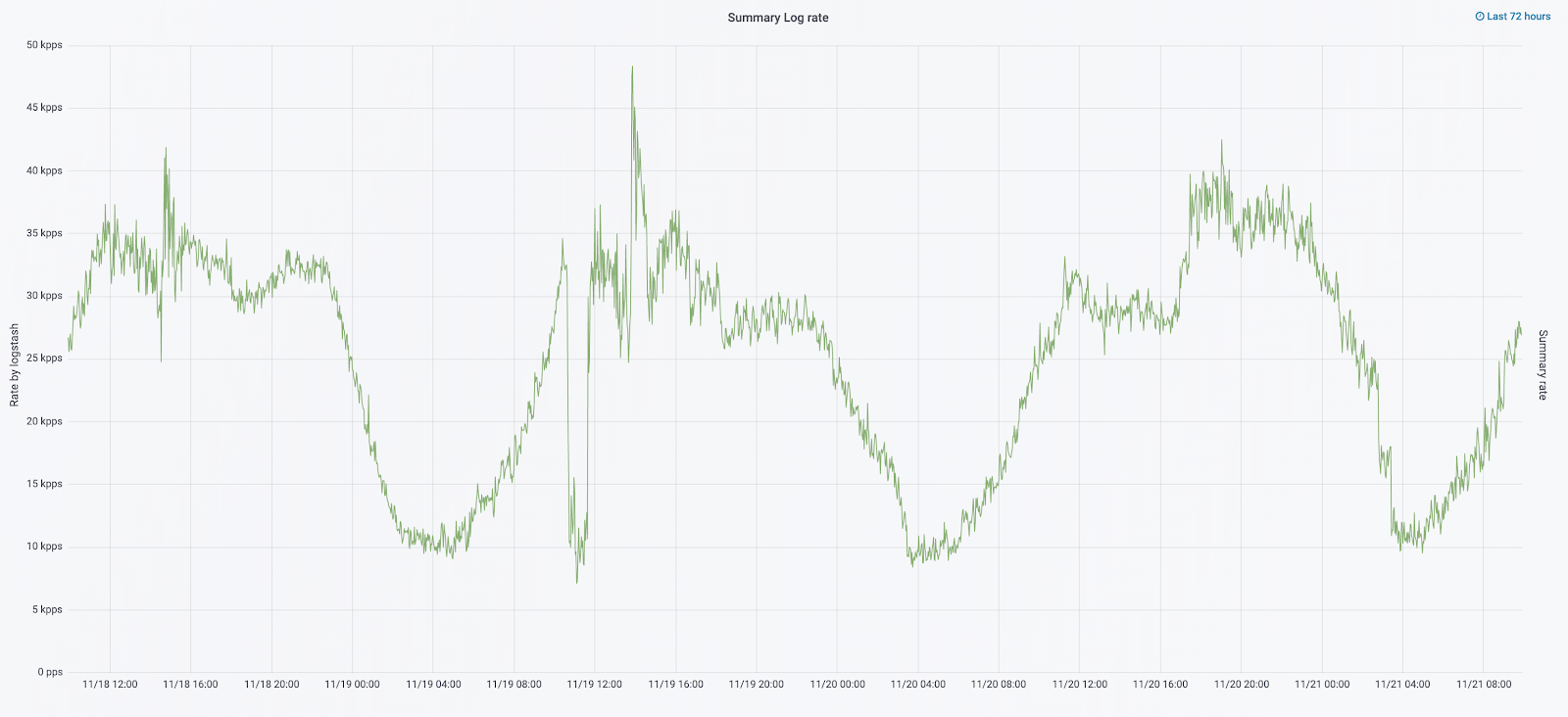
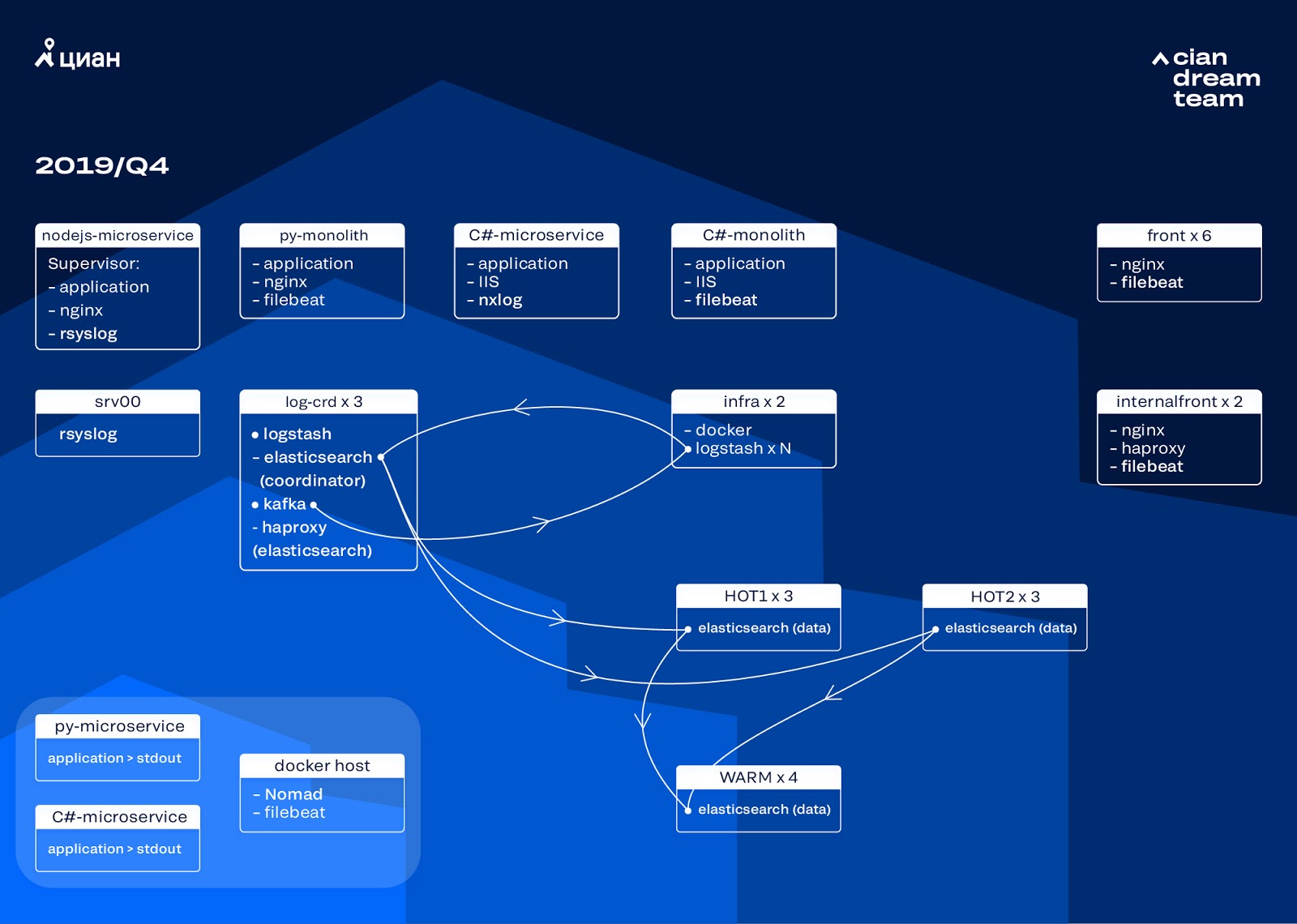
Wir begannen die nächste Iteration mit der Aktualisierung des Eisens. Wir wechselten von fünf auf drei Koordinatoren, ersetzten Datenknoten und gewannen in Bezug auf Geld und Speichervolumen. Für Knoten verwenden wir zwei Konfigurationen:
- Für Hot Nodes: E3-1270 v6 / 960 Gb SSD / 32 Gb x 3 x 2 (3 für Hot1 und 3 für Hot2).
- Für warme Knoten: E3-1230 v6 / 4 TB SSD / 32 GB x 4.
Bei dieser Iteration haben wir den Index mit den Zugriffsprotokollen für Mikroservices, der genauso viel Speicherplatz beansprucht wie die Front-End-Nginx-Protokolle, in die zweite Gruppe von drei Hot Nodes aufgenommen. Wir speichern jetzt Daten auf Hot Nodes für 20 Stunden und übertragen sie dann in andere Protokolle.
Wir haben das Problem des Verschwindens kleiner Indizes gelöst, indem wir ihre Rotation neu konfiguriert haben. Indizes werden jetzt ohnehin alle 23 Stunden gedreht, auch wenn nur wenige Daten vorliegen. Dies erhöhte leicht die Anzahl der Shards (sie wurden ungefähr 800), aber aus Sicht der Cluster-Leistung ist dies tolerierbar.
Infolgedessen wurden sechs "heiße" und nur vier "warme" Knoten im Cluster gefunden. Dies führt zu einer leichten Verzögerung der Anforderungen über lange Zeitintervalle, aber eine Erhöhung der Anzahl der Knoten in der Zukunft wird dieses Problem lösen.
In dieser Iteration wurde auch das Problem des Fehlens einer halbautomatischen Skalierung behoben. Zu diesem Zweck haben wir einen Infrastruktur-Nomad-Cluster bereitgestellt - ähnlich dem, den wir bereits für die Produktion bereitgestellt haben. Die Anzahl der Logstashs ändert sich zwar nicht automatisch je nach Auslastung, aber wir werden darauf zurückkommen.
Zukunftspläne
Die implementierte Konfiguration lässt sich gut skalieren, und jetzt speichern wir 13,3 TB an Daten - alle Protokolle in 4 Tagen, was für die Notfallanalyse von Warnungen erforderlich ist. Wir konvertieren einen Teil der Protokolle in Metriken, die wir zu Graphite hinzufügen. Um den Ingenieuren die Arbeit zu erleichtern, verfügen wir über Metriken für den Infrastrukturcluster und Skripte zur halbautomatischen Behebung typischer Probleme. Nachdem wir die Anzahl der Datenknoten erhöht haben, die für das nächste Jahr geplant ist, werden wir von 4 auf 7 Tage umstellen. Dies wird für die operative Arbeit ausreichen, da wir immer versuchen, Vorfälle so schnell wie möglich zu untersuchen und Telemetriedaten für Langzeituntersuchungen zur Verfügung stehen.
Im Oktober 2019 stieg der Traffic von cian.ru auf 15,3 Millionen Unique User pro Monat. Dies war ein schwerwiegender Test der Architekturlösung für die Lieferung von Protokollen.
Jetzt bereiten wir ein Upgrade von ElasticSearch auf Version 7 vor. Hierzu müssen wir jedoch die Zuordnung vieler Indizes in ElasticSearch aktualisieren, da sie von Version 5.5 verschoben wurden und in Version 6 als veraltet deklariert wurden (sie sind in Version 7 einfach nicht vorhanden). Und das bedeutet, dass es während des Aktualisierungsprozesses mit Sicherheit zu höherer Gewalt kommen wird, die uns vorerst ohne Protokolle lässt. Von den 7 Versionen freuen wir uns am meisten auf Kibana mit einer verbesserten Benutzeroberfläche und neuen Filtern.
Wir haben das Hauptziel erreicht: Wir haben den Verlust von Protokollen gestoppt und die Ausfallzeit des Infrastrukturclusters von 2-3 Ausfällen pro Woche auf ein paar Stunden Service pro Monat reduziert. All diese Arbeiten an der Produktion sind fast unsichtbar. Jetzt können wir jedoch genau bestimmen, was mit unserem Service passiert. Wir können dies schnell und leise tun und müssen uns keine Sorgen mehr machen, dass die Protokolle verloren gehen. Im Allgemeinen sind wir zufrieden, glücklich und bereiten uns auf neue Exploits vor, über die wir später sprechen werden.