
Meine Hauptaufgabe ist zum größten Teil die Bereitstellung von Softwaresystemen, das heißt, ich verbringe viel Zeit damit, die folgenden Fragen zu beantworten:
- Diese Software funktioniert für den Entwickler, aber nicht für mich. Warum?
- Gestern hat diese Software für mich funktioniert, aber heute nicht. Warum?
Dies ist eine Art von Debugging, die sich geringfügig vom regulären Software-Debugging unterscheidet. Beim normalen Debugging geht es um Codelogik, beim Deployment-Debugging jedoch um die Interaktion von Code und Umgebung. Auch wenn die Ursache des Problems ein logischer Fehler ist, bedeutet die Tatsache, dass alles auf einer Maschine und nicht auf einer anderen Maschine funktioniert, dass die Angelegenheit irgendwie in der Umgebung liegt.
Anstelle der üblichen Debugging-Tools wie gdb habe ich ein anderes Set von Tools zum Debuggen der Bereitstellung. Und mein Lieblingstool für ein Problem wie "Warum pflügt es diese Software nicht?" genannt strace .
Was ist Strace?
strace ist ein Tool zum Verfolgen eines Systemaufrufs. Ursprünglich unter Linux erstellt, können jedoch dieselben Debugging-Chips mit Tools für andere Systeme ( DTrace oder ktrace ) gedreht werden.
Die Hauptanwendung ist sehr einfach. Sie müssen nur strace mit einem beliebigen Befehl ausführen und es werden alle Systemaufrufe an den Dump gesendet (obwohl Sie wahrscheinlich zuerst strace selbst installieren müssen ):
$ strace echo Hello ...Snip lots of stuff... write(1, "Hello\n", 6) = 6 close(1) = 0 close(2) = 0 exit_group(0) = ? +++ exited with 0 +++
Was sind diese Systemaufrufe? Es ist eine Art API für den Kern des Betriebssystems. Es war einmal, als die Software direkten Zugriff auf die Hardware hatte, auf der sie arbeitete. Wenn Sie beispielsweise etwas auf dem Bildschirm anzeigen möchten, wird es mit Anschlüssen und / oder Speicherregistern für Videogeräte wiedergegeben. Als Multitasking-Computersysteme populär wurden, herrschte Chaos, weil verschiedene Anwendungen um Hardware kämpften. Fehler in einer Anwendung können die Arbeit anderer beeinträchtigen, wenn nicht des gesamten Systems. Dann erschienen in der CPU Privileg-Modi (oder "Ring Protection"). Der Kernel wurde zum privilegiertesten: Er erlangte vollen Zugriff auf die Hardware und schuf weniger privilegierte Anwendungen, die bereits Zugriff vom Kernel anfordern mussten, um mit der Hardware zu interagieren - über Systemaufrufe.
Auf der Binärebene unterscheidet sich ein Systemaufruf geringfügig von einem einfachen Funktionsaufruf, die meisten Programme verwenden jedoch einen Wrapper in der Standardbibliothek. Das heißt Die POSIX C-Standardbibliothek enthält einen Aufruf der Funktion write () , die den gesamten architekturspezifischen Code für den Systemaufruf write enthält.
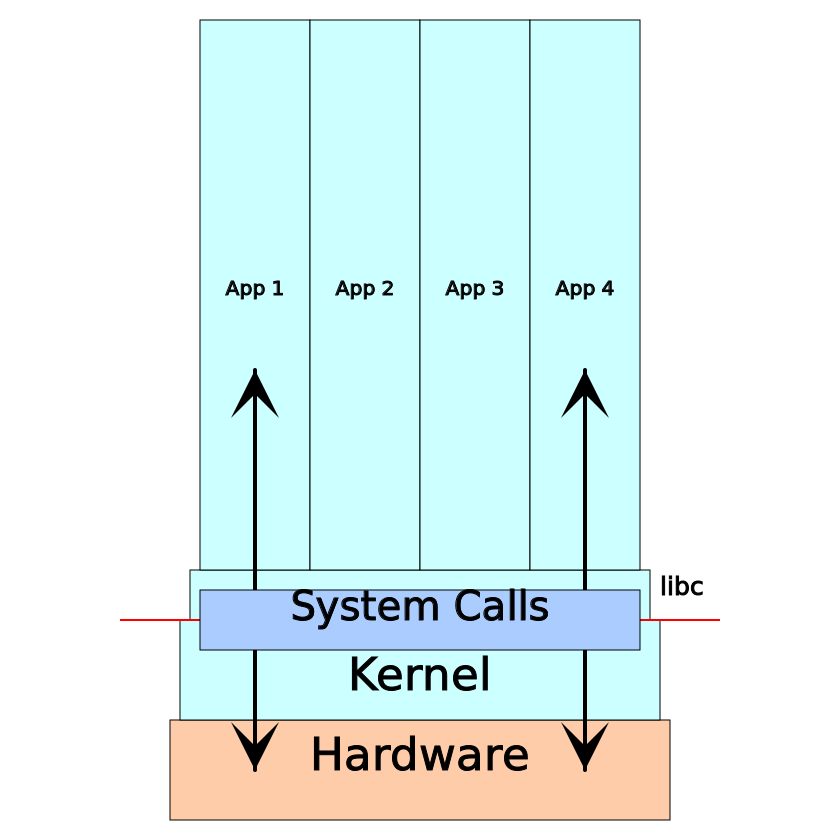
Kurz gesagt, jede Interaktion zwischen der Anwendung und ihrer Umgebung (Computersystemen) erfolgt über Systemaufrufe. Wenn die Software auf einem Computer und nicht auf einem anderen Computer ausgeführt wird, ist es daher hilfreich, die Ergebnisse der Verfolgung von Systemaufrufen zu betrachten. Im Folgenden finden Sie eine Liste typischer Punkte, die mithilfe der Systemaufrufverfolgung analysiert werden können:
- Konsolen-E / A
- Netzwerk Ein- / Ausgang
- Dateisystemzugriff und Datei-E / A
- Prozess- / Thread-Lebensdauermanagement
- Low Level Memory Management
- Zugriff auf bestimmte Gerätetreiber
Wann Strace verwenden?
Theoretisch wird strace für alle Programme im User Space verwendet, da jedes Programm im User Space Systemaufrufe ausführen sollte. Es funktioniert effizienter mit kompilierten, einfachen Programmen, aber es funktioniert auch mit höheren Sprachen wie Python, wenn Sie das zusätzliche Rauschen der Laufzeitumgebung und des Interpreters überwinden können.
In seiner ganzen Pracht manifestiert sich strace beim Debuggen von Software, die auf einem Computer einwandfrei funktioniert, und hört plötzlich auf, an einem anderen zu arbeiten, und gibt verwaschene Nachrichten über Dateien, Berechtigungen oder erfolglose Versuche, einige Befehle oder etwas auszuführen ... Es ist schade, aber nicht so gut Es ist mit allgemeinen Problemen wie Zertifikatverifizierungsfehlern verbunden. Dies erfordert normalerweise eine Kombination aus strace , manchmal ltrace und Tools höherer Ebene (wie das Befehlszeilentool openssl zum Debuggen eines Zertifikats).
Wir arbeiten zum Beispiel an einem eigenständigen Server, die Verfolgung von Systemaufrufen kann jedoch häufig auf komplexeren Bereitstellungsplattformen durchgeführt werden. Sie müssen nur das richtige Toolkit auswählen.
Einfaches Debugging-Beispiel
Nehmen wir an, Sie möchten die großartige foo-Server-Anwendung ausführen, aber es stellt sich heraus, dass:
$ foo Error opening configuration file: No such file or directory
Offensichtlich konnte er die von Ihnen geschriebene Konfigurationsdatei nicht finden. Dies liegt daran, dass Paketmanager beim Kompilieren einer Anwendung manchmal den erwarteten Speicherort der Dateien überschreiben. Und wenn Sie die Installationsanleitung für eine Distribution befolgen, finden Sie die Dateien in einer anderen völlig anders, als ich erwartet hatte. Das Problem kann in wenigen Sekunden behoben werden, wenn in der Fehlermeldung angegeben wird, wo nach der Konfigurationsdatei gesucht werden soll, dies jedoch nicht angegeben wird. Also, wo soll man suchen?
Wenn Sie Zugriff auf den Quellcode haben, können Sie ihn lesen und herausfinden. Ein guter Backup-Plan, aber nicht die schnellste Lösung. Sie können auf einen schrittweisen Debugger wie gdb zurückgreifen und sehen, was das Programm tut. Es ist jedoch viel effizienter, ein Tool zu verwenden, das speziell für die Interaktion mit der Umgebung entwickelt wurde: strace .
Die Schlussfolgerung von strace mag überflüssig erscheinen, aber die gute Nachricht ist, dass das meiste davon sicher ignoriert werden kann. Es ist oft nützlich, den Operator -o zu verwenden, um Trace-Ergebnisse in einer separaten Datei zu speichern:
$ strace -o /tmp/trace foo Error opening configuration file: No such file or directory $ cat /tmp/trace execve("foo", ["foo"], 0x7ffce98dc010 /* 16 vars */) = 0 brk(NULL) = 0x56363b3fb000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=25186, ...}) = 0 mmap(NULL, 25186, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2f12cf1000 close(3) = 0 openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\260A\2\0\0\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=1824496, ...}) = 0 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2f12cef000 mmap(NULL, 1837056, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2f12b2e000 mprotect(0x7f2f12b50000, 1658880, PROT_NONE) = 0 mmap(0x7f2f12b50000, 1343488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x22000) = 0x7f2f12b50000 mmap(0x7f2f12c98000, 311296, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16a000) = 0x7f2f12c98000 mmap(0x7f2f12ce5000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f2f12ce5000 mmap(0x7f2f12ceb000, 14336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2f12ceb000 close(3) = 0 arch_prctl(ARCH_SET_FS, 0x7f2f12cf0500) = 0 mprotect(0x7f2f12ce5000, 16384, PROT_READ) = 0 mprotect(0x56363b08b000, 4096, PROT_READ) = 0 mprotect(0x7f2f12d1f000, 4096, PROT_READ) = 0 munmap(0x7f2f12cf1000, 25186) = 0 openat(AT_FDCWD, "/etc/foo/config.json", O_RDONLY) = -1 ENOENT (No such file or directory) dup(2) = 3 fcntl(3, F_GETFL) = 0x2 (flags O_RDWR) brk(NULL) = 0x56363b3fb000 brk(0x56363b41c000) = 0x56363b41c000 fstat(3, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x8), ...}) = 0 write(3, "Error opening configuration file"..., 60) = 60 close(3) = 0 exit_group(1) = ? +++ exited with 1 +++
Über die gesamte erste Seite der Strace- Ausgabe wird in der Regel ein Low-Level-Start vorbereitet. (Es gibt viele Aufrufe für mmap , mprotect und brk , z. B. das Erkennen von Arbeitsspeicher auf niedriger Ebene und das Anzeigen dynamischer Bibliotheken.) Während des Debuggens werden die strace- Ausgaben am besten von Anfang an gelesen. Unten befindet sich ein Aufruf zum Schreiben , der eine Fehlermeldung anzeigt. Wir schauen oben und sehen den ersten fehlerhaften Systemaufruf - einen openat- Aufruf, der einen ENOENT- Fehler ("Datei oder Verzeichnis nicht gefunden") auslöst und versucht, /etc/foo/config.json zu öffnen. Hier sollte hier die Konfigurationsdatei liegen.
Es war nur ein Beispiel, aber ich würde sagen, dass 90% der Zeit, in der ich Strace benutze , nichts viel schwieriger ist und nicht muss. Nachfolgend finden Sie eine vollständige schrittweise Anleitung zum Debuggen:
- Frustriert von einer verwaschenen System-Fehlermeldung aus einem Programm
- Starten Sie das Programm mit strace neu
- Finden Sie eine Fehlermeldung in den Trace-Ergebnissen
- Gehen Sie nach oben, bis Sie auf den ersten fehlgeschlagenen Systemaufruf stoßen
Es ist sehr wahrscheinlich, dass der Systemaufruf in Schritt 4 zeigt, was falsch gelaufen ist.
Tipps
Bevor ich ein Beispiel für ein komplexeres Debugging zeige , möchte ich Ihnen einige Tricks erläutern , wie Sie strace effektiv einsetzen können:
Mann ist dein Freund
Auf vielen * nix-Systemen kann eine vollständige Liste der Kernel-Systemaufrufe durch Ausführen von man-syscalls abgerufen werden. Sie werden Dinge wie brk (2) sehen , was bedeutet, dass Sie mehr Informationen erhalten können, indem Sie man 2 brk ausführen .
Ein kleiner Fehler: man 2 fork zeigt mir eine Seite für die fork () - Shell in GNU libc , die mithilfe des clone () -Aufrufs implementiert wird. Die Semantik des Fork- Aufrufs bleibt gleich, wenn Sie ein Programm schreiben, das Fork () verwendet und die Ablaufverfolgung startet - ich finde keine Fork- Aufrufe, stattdessen wird es Clone () geben . Solch ein Rechen ist nur verwirrt, wenn Sie damit beginnen, die Quelle mit der Ausgabe von strace zu vergleichen .
Verwenden Sie -o, um die Ausgabe in einer Datei zu speichern
strace kann umfangreiche Ausgaben generieren, daher ist es oft nützlich, Trace-Ergebnisse in separaten Dateien zu speichern (wie im obigen Beispiel). Und es hilft, die Programmausgabe nicht mit der Ausgabe von strace in der Konsole zu verwechseln.
Verwenden Sie -s, um weitere Argumentdaten anzuzeigen
Sie haben wahrscheinlich bemerkt, dass die zweite Hälfte der Fehlermeldung im obigen Trace-Beispiel nicht angezeigt wird. Dies liegt daran, dass strace standardmäßig nur die ersten 32 Bytes des String-Arguments anzeigt . Wenn Sie mehr sehen möchten, fügen Sie dem strace- Aufruf etwas wie -s 128 hinzu .
-y erleichtert das Verfolgen von Dateien \ sockets \ und so weiter.
"Alles ist eine Datei" bedeutet, dass * nix-Systeme alle E / A-Vorgänge mithilfe von Dateideskriptoren ausführen, unabhängig davon, ob dies für eine Datei oder ein Netzwerk oder für die Interprozessierung von Kanälen gilt. Dies ist praktisch für die Programmierung, macht es jedoch schwierig, den Überblick darüber zu behalten, was tatsächlich passiert, wenn Sie das allgemeine Lesen und Schreiben in den Ablaufverfolgungsergebnissen eines Systemaufrufs sehen.
Durch Hinzufügen des Operators -u erzwingen Sie, dass strace jeden Dateideskriptor in der Ausgabe mit einem Vermerk versehen muss, auf den er verweist.
Mit -p ** an einen bereits laufenden Prozess anhängen
Wie aus dem folgenden Beispiel hervorgeht, müssen Sie manchmal ein bereits ausgeführtes Programm verfolgen. Wenn Sie wissen, dass es als Prozess 1337 ausgeführt wird (etwa aus den Schlussfolgerungen von ps ), können Sie es folgendermaßen verfolgen:
$ strace -p 1337 ...system call trace output...
Möglicherweise benötigen Sie Root-Rechte.
Verwenden Sie -f, um untergeordnete Prozesse zu überwachen
strace verfolgt standardmäßig nur einen Prozess. Wenn dieser Prozess untergeordnete Prozesse erzeugt, wird der Systemaufruf zum Erzeugen des untergeordneten Prozesses angezeigt, die Systemaufrufe des untergeordneten Prozesses werden jedoch nicht angezeigt.
Wenn Sie der Meinung sind, dass der Fehler im untergeordneten Prozess liegt, verwenden Sie den Operator -f. Dadurch wird die Ablaufverfolgung aktiviert. Der Nachteil dabei ist, dass Sie die Schlussfolgerung noch mehr verwirren wird. Wenn strace einen Prozess oder einen Thread verfolgt, wird ein einzelner Stream von Aufrufereignissen angezeigt . Wenn mehrere Prozesse gleichzeitig verfolgt werden, wird wahrscheinlich der Beginn des Aufrufs durch die Meldung <unfinished ...> unterbrochen, dann eine Reihe von Aufrufen für andere Ausführungszweige und erst dann das Ende des ersten mit <... foocall resumed> . Alternativ können Sie alle Trace-Ergebnisse auch mit dem Operator -ff in verschiedene Dateien aufteilen (Einzelheiten finden Sie im Strace- Handbuch ).
Filtern Sie den Trace mit -e
Wie Sie sehen, ist das Trace-Ergebnis eine Menge aller möglichen Systemaufrufe. Mit dem Flag -e können Sie den Trace filtern (siehe Strace- Handbuch ). Der Hauptvorteil ist, dass das Ausführen eines Traces mit Filterung schneller ist als das Ausführen eines vollständigen Traces und dann grep . Ehrlich gesagt ist es mir fast immer egal.
Nicht alle Fehler sind schlecht
Ein einfaches und weit verbreitetes Beispiel ist ein Programm, das an mehreren Stellen gleichzeitig nach einer Datei sucht, beispielsweise nach einer Shell, in der das Verzeichnis basket / eine ausführbare Datei enthält:
$ strace sh -c uname ... stat("/home/user/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory) stat("/usr/local/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory) stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0 ...
Eine Heuristik "Letzte fehlgeschlagene Anforderung vor Fehlermeldung" kann relevante Fehler gut finden. Wie dem auch sei, es ist logisch, ganz am Ende anzufangen.
C Programmierhandbücher helfen beim Verstehen von Systemaufrufen
Standardaufrufe an C-Bibliotheken sind keine Systemaufrufe, sondern nur eine dünne Oberflächenschicht. Wenn Sie also zumindest ein wenig verstehen, wie und was in C zu tun ist, ist es für Sie einfacher, die Ergebnisse der Verfolgung eines Systemaufrufs zu verstehen. Wenn Sie beispielsweise Probleme beim Debuggen von Anrufen an vernetzte Systeme haben, lesen Sie den "Network Programming Guide" von Bija .
Komplizierteres Debugging-Beispiel
Ich habe bereits gesagt, dass ein Beispiel für einfaches Debuggen ein Beispiel für etwas ist, mit dem ich mich größtenteils mit Stress auseinandersetzen muss . Manchmal ist jedoch eine echte Untersuchung erforderlich. Hier ist ein echtes Beispiel für ein komplizierteres Debuggen.
bcron ist ein Task Processing Scheduler, eine weitere Implementierung des * nix cron Daemons . Es ist auf dem Server installiert, aber wenn jemand versucht, den Zeitplan zu bearbeiten, geschieht Folgendes:
# crontab -e -u logs bcrontab: Fatal: Could not create temporary file
Okay, also hat bcron versucht, eine bestimmte Datei zu schreiben, aber es hat nicht geklappt und er gibt nicht zu, warum. Strace aufdecken :
# strace -o /tmp/trace crontab -e -u logs bcrontab: Fatal: Could not create temporary file # cat /tmp/trace ... openat(AT_FDCWD, "bcrontab.14779.1573691864.847933", O_RDONLY) = 3 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000 read(3, "#Ansible: logsagg\n20 14 * * * lo"..., 8192) = 150 read(3, "", 8192) = 0 munmap(0x7f82049b4000, 8192) = 0 close(3) = 0 socket(AF_UNIX, SOCK_STREAM, 0) = 3 connect(3, {sa_family=AF_UNIX, sun_path="/var/run/bcron-spool"}, 110) = 0 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000 write(3, "156:Slogs\0#Ansible: logsagg\n20 1"..., 161) = 161 read(3, "32:ZCould not create temporary f"..., 8192) = 36 munmap(0x7f82049b4000, 8192) = 0 close(3) = 0 write(2, "bcrontab: Fatal: Could not creat"..., 49) = 49 unlink("bcrontab.14779.1573691864.847933") = 0 exit_group(111) = ? +++ exited with 111 +++
Ganz am Ende gibt es eine Schreibfehler-Meldung, aber diesmal ist etwas anders. Erstens gibt es keinen relevanten Systemaufruffehler, der normalerweise vorher auftritt. Zweitens ist klar, dass irgendwo schon jemand die Fehlermeldung gelesen hat. Es scheint, dass das eigentliche Problem woanders liegt und bcrontab spielt einfach die Nachricht ab.
Wenn Sie sich man 2 read ansehen, sehen Sie, dass das erste Argument (3) der Dateideskriptor ist, den * nix für die gesamte E / A-Verarbeitung verwendet. Wie kann man herausfinden, für welchen Dateideskriptor 3 steht? In diesem speziellen Fall können Sie strace mit dem Operator -u ausführen (siehe oben), und es wird Ihnen automatisch mitgeteilt , dass es für die Berechnung solcher Dinge nützlich ist, zu wissen, wie die Trace-Ergebnisse gelesen und analysiert werden.
Die Quelle des Dateideskriptors kann einer von vielen Systemaufrufen sein (alles hängt davon ab, was der Deskriptor für die Konsole, den Netzwerk-Socket, die Datei selbst oder etwas anderes ist) Suchen Sie in den Trace-Ergebnissen nach "= 3". Infolgedessen gibt es 2 davon: openat ganz oben und socket in der Mitte. openat öffnet die Datei, aber close (3) zeigt an, dass sie wieder geschlossen wird. (Rake: Dateideskriptoren können beim Öffnen und Schließen wiederverwendet werden.) Der Aufruf socket () ist geeignet, da es sich um den letzten Aufruf vor read () handelt und sich herausstellt, dass bcrontab mit etwas über den Socket funktioniert. Die nächste Zeile zeigt, dass der Dateideskriptor dem Unix-Domain-Socket im Pfad / var / run / bcron-spool zugeordnet ist .
Sie müssen also den Prozess finden, der an den Unix-Socket angeschlossen ist. Zu diesem Zweck gibt es ein paar nützliche Tricks, die sich beide zum Debuggen von Server-Bereitstellungen eignen. Das erste ist, netstat oder neuere ss (Socket-Status) zu verwenden. Beide Befehle zeigen die aktiven Netzwerkverbindungen des Systems an und verwenden den Operator -l , um Listening-Sockets zu beschreiben, und den Operator -p , um mit dem Socket verbundene Programme als Client anzuzeigen. (Es gibt viele weitere nützliche Optionen, aber diese beiden reichen für diese Aufgabe aus.)
# ss -pl | grep /var/run/bcron-spool u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))
Dies deutet darauf hin, dass es sich bei dem Listener um einen Inixserver- Befehl handelt, der mit der Prozess-ID 20629 arbeitet. (Und zufällig wird der Dateideskriptor 3 als Socket verwendet.)
Das zweite wirklich nützliche Werkzeug, um die gleichen Informationen zu finden, heißt lsof . Es listet alle offenen Dateien (oder Dateideskriptoren) im System auf. Oder Sie können Informationen zu einer bestimmten Datei abrufen:
# lsof /var/run/bcron-spool COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME unixserve 20629 cron 3u unix 0x000000005ac4bd83 0t0 1466637 /var/run/bcron-spool type=STREAM
Der 20629-Prozess ist ein langlebiger Server, daher können Sie ihn mit strace -o / tmp / trace -p 20629 verknüpfen . Wenn wir die Cron-Task in einem anderen Terminal bearbeiten, erhalten wir die Ausgabe der Trace-Ergebnisse mit einem Fehler. Und hier ist das Ergebnis:
accept(3, NULL, NULL) = 4 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21181 close(4) = 0 accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21181, si_uid=998, si_status=0, si_utime=0, si_stime=0} --- wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], WNOHANG|WSTOPPED, NULL) = 21181 wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes) rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0 rt_sigreturn({mask=[]}) = 43 accept(3, NULL, NULL) = 4 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21200 close(4) = 0 accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21200, si_uid=998, si_status=111, si_utime=0, si_stime=0} --- wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 111}], WNOHANG|WSTOPPED, NULL) = 21200 wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes) rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0 rt_sigreturn({mask=[]}) = 43 accept(3, NULL, NULL
(Das letzte accept () wird beim Verfolgen nicht abgeschlossen.) Leider enthält dieses Ergebnis auch nicht den gesuchten Fehler. Es werden keine Nachrichten angezeigt, die bcrontag an einen Socket senden oder von diesem empfangen würde. Stattdessen vollständige Kontrolle über den Prozess ( clone , wait4 , SIGCHLD usw.). Dieser Prozess erzeugt einen untergeordneten Prozess, der, wie Sie sich vorstellen können, die eigentliche Arbeit leistet. Und wenn Sie ihre Spur abfangen müssen, fügen Sie dem Aufruf strace -f hinzu . Folgendes finden wir, wenn wir nach der Fehlermeldung im neuen Ergebnis mit strace -f -o / tmp / trace -p 20629 suchen :
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied) 21470 write(1, "32:ZCould not create temporary f"..., 36) = 36 21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84 21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory) 21470 exit_group(111) = ? 21470 +++ exited with 111 +++
Das ist etwas. Der Prozess 21470 erhält den Fehler "Zugriff verweigert", wenn versucht wird, eine Datei im Pfad tmp / spool.21470.1573692319.854640 (bezogen auf das aktuelle Arbeitsverzeichnis) zu erstellen. Wenn wir einfach das aktuelle Arbeitsverzeichnis kennen würden, würden wir den vollständigen Pfad kennen und könnten herausfinden, warum der Prozess keine eigene temporäre Datei darin erstellen kann. Leider wurde der Prozess bereits beendet, sodass Sie nicht nur mit lsof -p 21470 das aktuelle Verzeichnis finden, sondern auch in umgekehrter Richtung arbeiten können. Suchen Sie nach PID 21470-Systemaufrufen, die das Verzeichnis ändern. (Wenn es keine gibt, muss PID 21470 sie vom übergeordneten Element geerbt haben, und dies kann nicht über lsof -p herausgefunden werden .) Dieser Systemaufruf lautet chdir (was mit Hilfe moderner Netzwerksuchmaschinen leicht herauszufinden ist). Und hier ist das Ergebnis von Rückwärtssuchen basierend auf den Trace-Ergebnissen bis zum PID 20629-Server selbst:
20629 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21470 ... 21470 execve("/usr/sbin/bcron-spool", ["bcron-spool"], 0x55d2460807e0 /* 27 vars */) = 0 ... 21470 chdir("/var/spool/cron") = 0 ... 21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied) 21470 write(1, "32:ZCould not create temporary f"..., 36) = 36 21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84 21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory) 21470 exit_group(111) = ? 21470 +++ exited with 111 +++
(Wenn Sie sich verlaufen, möchten Sie möglicherweise meinen vorherigen Beitrag zu * nix process control and shells lesen.) Der PID 20629-Server hat daher keine Berechtigung zum Erstellen einer Datei im Pfad /var/spool/cron/tmp/spool.21470.1573692319.854640 erhalten . , — . :
# ls -ld /var/spool/cron/tmp/ drwxr-xr-x 2 root root 4096 Nov 6 05:33 /var/spool/cron/tmp/ # ps u -p 20629 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND cron 20629 0.0 0.0 2276 752 ? Ss Nov14 0:00 unixserver -U /var/run/bcron-spool -- bcron-spool
! cron, root /var/spool/cron/tmp/ . chown cron /var/spool/cron/tmp/ bcron . ( , — SELinux AppArmor, dmesg .)
Total
, , , , — . , bcron , .
, , , strace , , . , strace . , .