Hallo allerseits! Mein Name ist Alexey Skorobogaty, ich bin ein Systemarchitekt bei Lamoda. Im Februar 2019 sprach ich bei Go Meetup, als ich noch die Teamleitung des Kernteams innehatte. Heute möchte ich eine Abschrift meines Berichts vorlegen, die Sie auch sehen können.
Unser Team heißt aus einem Grund Core: Der Verantwortungsbereich umfasst alles, was mit Bestellungen in der E-Commerce-Plattform zu tun hat. Das Team bestand aus PHP-Entwicklern und Spezialisten für unsere Auftragsabwicklung, die zu dieser Zeit ein einziger Monolith war. Wir waren engagiert und beschäftigten uns weiterhin mit der Zersetzung in Mikrodienstleistungen.

Eine Bestellung in unserem System besteht aus verwandten Komponenten: Es gibt eine Liefereinheit und einen Warenkorb, Rabatt- und Zahlungseinheiten, und ganz am Ende befindet sich eine Schaltfläche, die die Bestellung zur Abholung im Lager sendet. In diesem Moment beginnt die Arbeit des Auftragsverarbeitungssystems, in dem alle Auftragsdaten validiert und die Informationen aggregiert werden.
In all dem steckt eine komplexe Multikriteria-Logik. Blöcke interagieren miteinander und beeinflussen sich gegenseitig. Kontinuierliche und ständige Änderungen des Geschäfts erhöhen die Komplexität der Kriterien. Darüber hinaus haben wir verschiedene Plattformen, über die Kunden Bestellungen erstellen können: Website, Anwendungen, Call Center, B2B-Plattform. Sowie strenge SLA / MTTI / MTTR-Kriterien (Registrierungsmetriken und Incident Resolution). All dies erfordert vom Service eine hohe Flexibilität und Stabilität.
Architektonisches Erbe
Wie ich bereits sagte, war das Auftragsverarbeitungssystem zum Zeitpunkt der Bildung unseres Teams ein Monolith - fast 100.000 Codezeilen, die die Geschäftslogik direkt beschreiben. Der Hauptteil wurde 2011 unter Verwendung der klassischen mehrschichtigen MVC-Architektur geschrieben. Es basierte auf PHP (dem ZF1-Framework), das schrittweise mit Adaptern und Symfony-Komponenten für die Interaktion mit verschiedenen Diensten erweitert wurde. Während seiner Existenz hatte das System mehr als 50 Mitwirkende, und obwohl es uns gelungen ist, einen einheitlichen Stil für das Schreiben von Code beizubehalten, hat dies auch seine Beschränkungen auferlegt. Darüber hinaus ergab sich eine Vielzahl von Mischkontexten - aus verschiedenen Gründen wurden einige Mechanismen im System implementiert, die nicht direkt mit der Auftragsabwicklung in Zusammenhang standen. All dies führte dazu, dass wir momentan eine MySQL-Datenbank haben, die größer als 1 Terabyte ist.
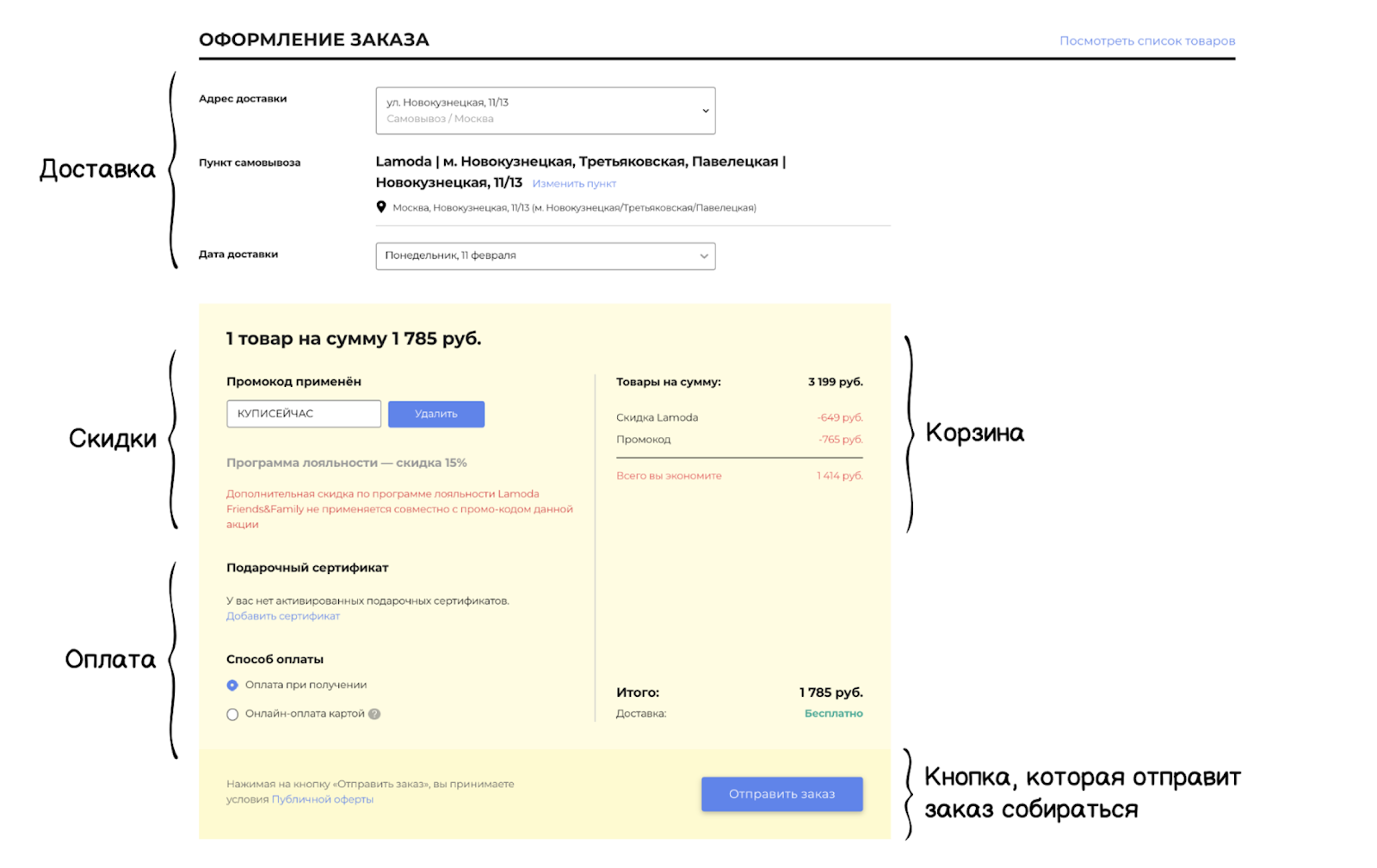
Schematisch kann die ursprüngliche Architektur wie folgt dargestellt werden:
Die Reihenfolge befand sich natürlich auf jeder der Ebenen - aber zusätzlich zur Reihenfolge gab es auch andere Kontexte. Wir haben zunächst den begrenzten Kontext der Bestellung definiert und als Kundenbestellung bezeichnet, da es neben der Bestellung selbst genau die Blöcke gibt, die ich eingangs erwähnt habe: Lieferung, Zahlung usw. Innerhalb des Monolithen war es schwierig, all dies zu handhaben: Änderungen führten zu einer Zunahme der Abhängigkeiten, der Code wurde für eine sehr lange Zeit an den Produkt geliefert, die Wahrscheinlichkeit von Fehlern und Systemausfällen stieg ständig an. Aber wir sprechen über das Erstellen einer Bestellung, der Hauptmetrik eines Online-Shops. Wenn keine Bestellungen erstellt werden, ist der Rest nicht so wichtig. Ein Systemausfall führt zu einem sofortigen Umsatzrückgang.
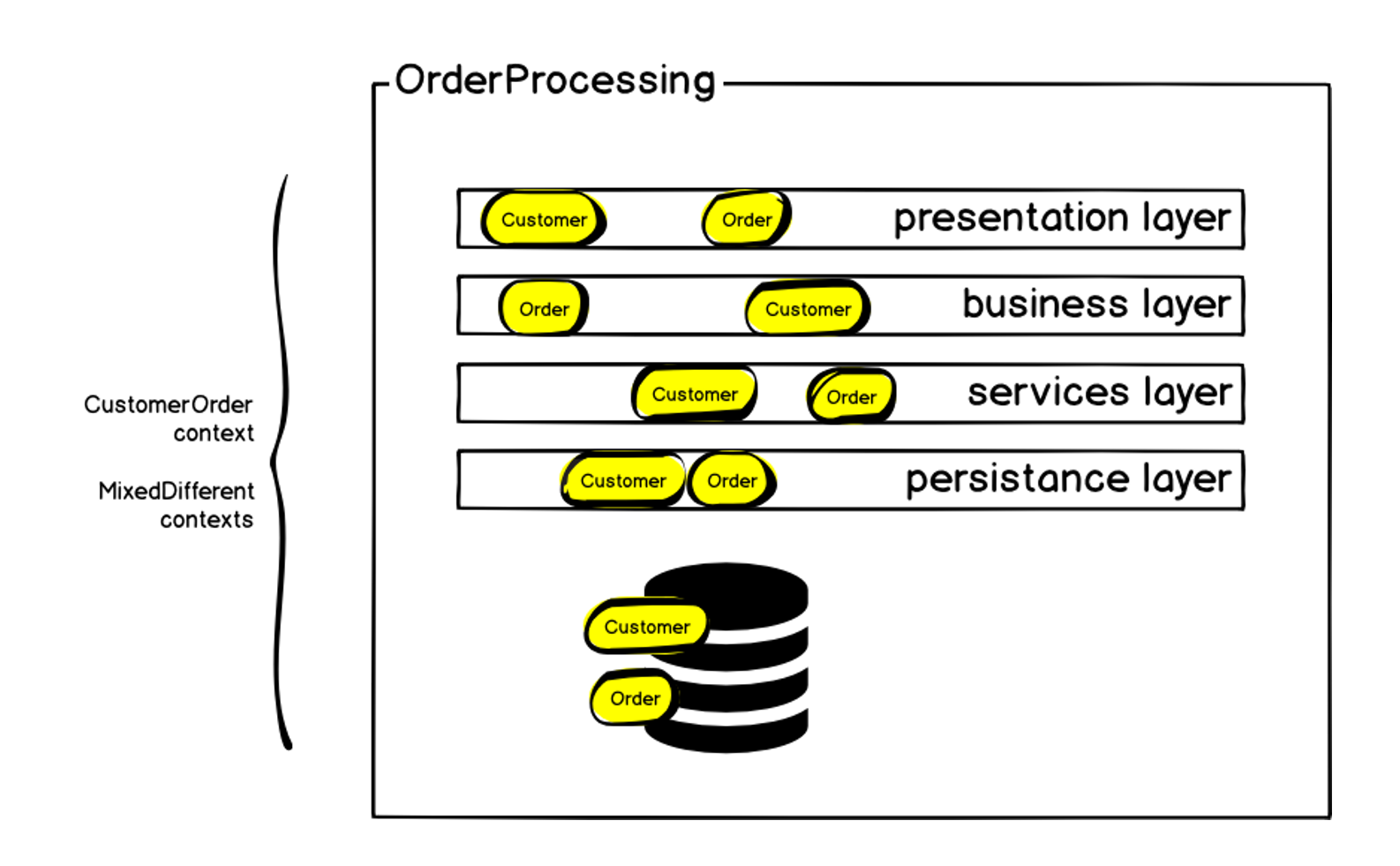
Aus diesem Grund haben wir beschlossen, den Kundenauftragskontext aus dem Auftragsverarbeitungssystem in einen separaten Microservice zu übertragen, der als Auftragsverwaltung bezeichnet wird.
Anforderungen und Werkzeuge
Nachdem wir den Kontext festgelegt hatten, den wir ursprünglich aus dem Monolithen entfernen wollten, formulierten wir die Anforderungen für unseren zukünftigen Service:
- Leistung
- Datenkonsistenz
- Nachhaltigkeit
- Vorhersehbarkeit
- Transparenz
- Inkrementelle Veränderung
Wir wollten, dass der Code so klar und einfach wie möglich zu bearbeiten ist, damit die nächste Entwicklergeneration die für das Unternehmen erforderlichen Änderungen schnell vornehmen kann.
Als Ergebnis kamen wir zu einer bestimmten Struktur, die wir in allen neuen Mikrodiensten verwenden:
Begrenzter Kontext . Jeder neue Microservice, beginnend mit dem Auftragsmanagement, wird basierend auf den Geschäftsanforderungen erstellt. Es muss genau erklärt werden, welcher Teil des Systems und warum es erforderlich ist, es in einen separaten Mikrodienst zu stellen.
Bestehende Infrastruktur und Tools. Wir sind nicht das erste Team in Lamoda, das mit der Implementierung von Go begonnen hat, vor uns gab es Pioniere - das Go-Team selbst, das die Infrastruktur und die Tools vorbereitet hat:
- Gogi (Swagger) ist ein Swagger-Spezifikationsgenerator.
- Gonkey (Test) - für Funktionstests.
- Wir verwenden Json-rpc und generieren eine Client / Server-Bindung durch Swagger. Wir stellen all dies auch für Kubernetes bereit, erfassen Metriken in Prometheus, verwenden ELK / Jaeger für die Rückverfolgung - all dies ist in dem Paket enthalten, das Gogi für jeden neuen Microservice nach Spezifikation erstellt.
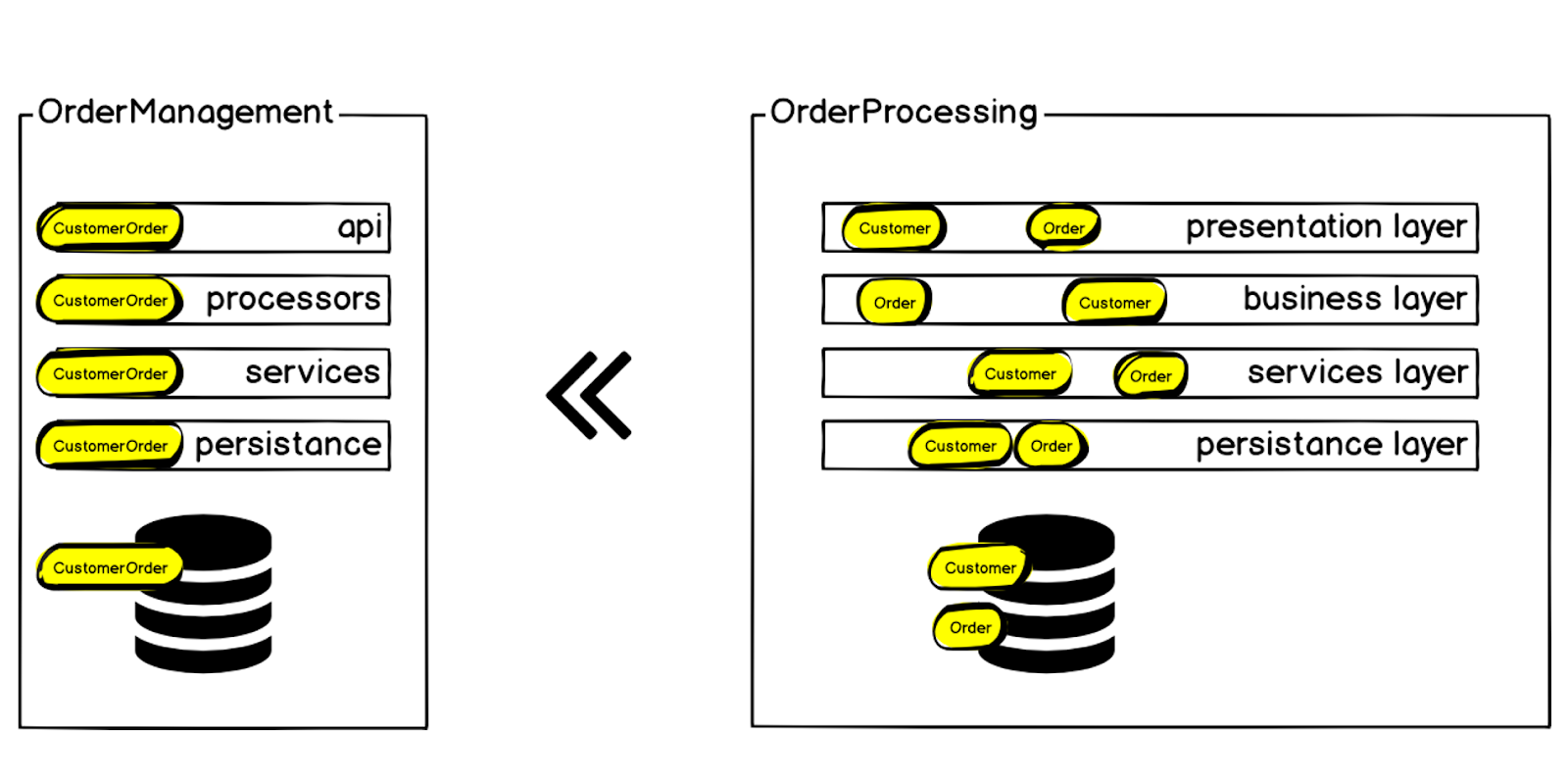
So sieht unser neuer Bestellmanagement-Microservice aus:
Am Eingang haben wir Daten, wir aggregieren sie, validieren sie, interagieren mit Drittanbieterservices, treffen Entscheidungen und übertragen die Ergebnisse weiter in die Auftragsabwicklung - derselbe Monolith, der groß, instabil und ressourcenintensiv ist. Dies muss auch beim Aufbau eines Mikrodienstes berücksichtigt werden.
Paradigmenwechsel
Wenn wir uns für Go entschieden haben, haben wir sofort mehrere Vorteile:
- Statisch starkes Tippen schneidet sofort eine Reihe von möglichen Fehlern ab.
- Das Parallelitätsmodell passt gut zu unseren Aufgaben, da wir herumlaufen und gleichzeitig mehrere Dienste abfragen müssen.
- Zusammensetzung und Schnittstellen helfen uns auch beim Testen.
- Die "Einfachheit" des Studiums - hier wurden nicht nur offensichtliche Pluspunkte entdeckt, sondern auch Probleme.
Go Language schränkt die Vorstellungskraft des Entwicklers ein. Dies wurde zu einem Stolperstein für unser Team, das an PHP gewöhnt war, als wir auf Go umgestiegen sind. Wir stehen vor einem echten Paradigmenwechsel. Wir mussten mehrere Phasen durchlaufen und einige Dinge verstehen:
- Es ist schwer, Abstraktionen zu bauen.
- Man kann sagen, dass Go objektbasiert ist, aber keine objektorientierte Sprache, da es keine direkte Vererbung und einige andere Dinge gibt.
- Go hilft beim expliziten Schreiben, anstatt Objekte hinter Abstraktionen zu verstecken.
- Go hat Pipelining. Dies hat uns dazu inspiriert, Datenverarbeitungsketten aufzubauen.
Infolgedessen haben wir verstanden, dass Go eine prozedurale Programmiersprache ist.

Daten zuerst
Ich habe darüber nachgedacht, wie wir das Problem visualisieren können, mit dem wir konfrontiert waren, und bin auf folgendes Bild gestoßen:
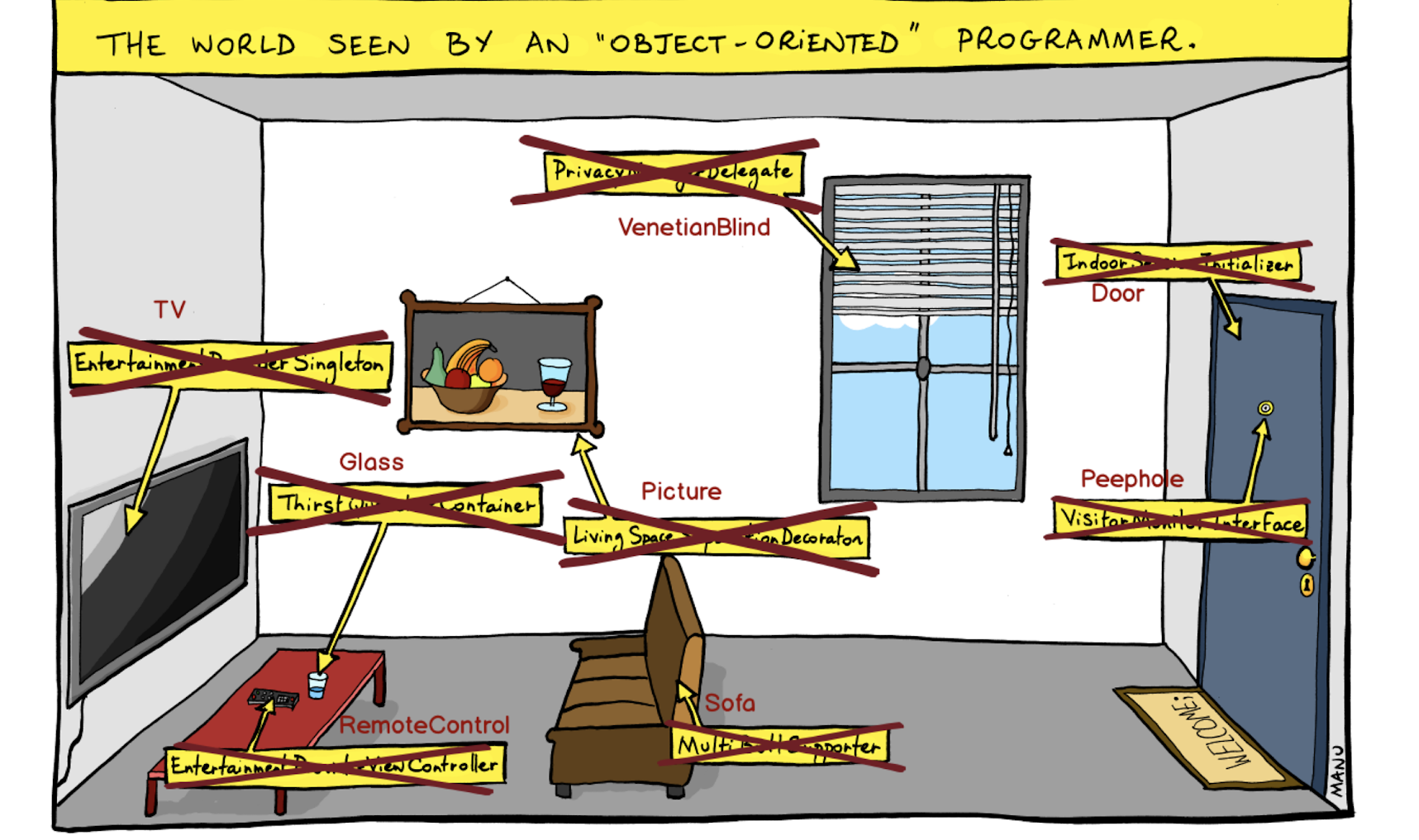
Dies ist eine "objektorientierte" Sicht auf die Welt, in der wir Abstraktionen erstellen und Objekte dahinter schließen. Hier ist zum Beispiel nicht nur eine Tür, sondern ein Indoor Session Initializer. Nicht der Schüler, sondern das Visitor Monitor Interface - und so weiter.
Wir haben diesen Ansatz aufgegeben und Entitäten an erster Stelle gestellt, ohne durch Abstraktionen verdeckt zu werden.
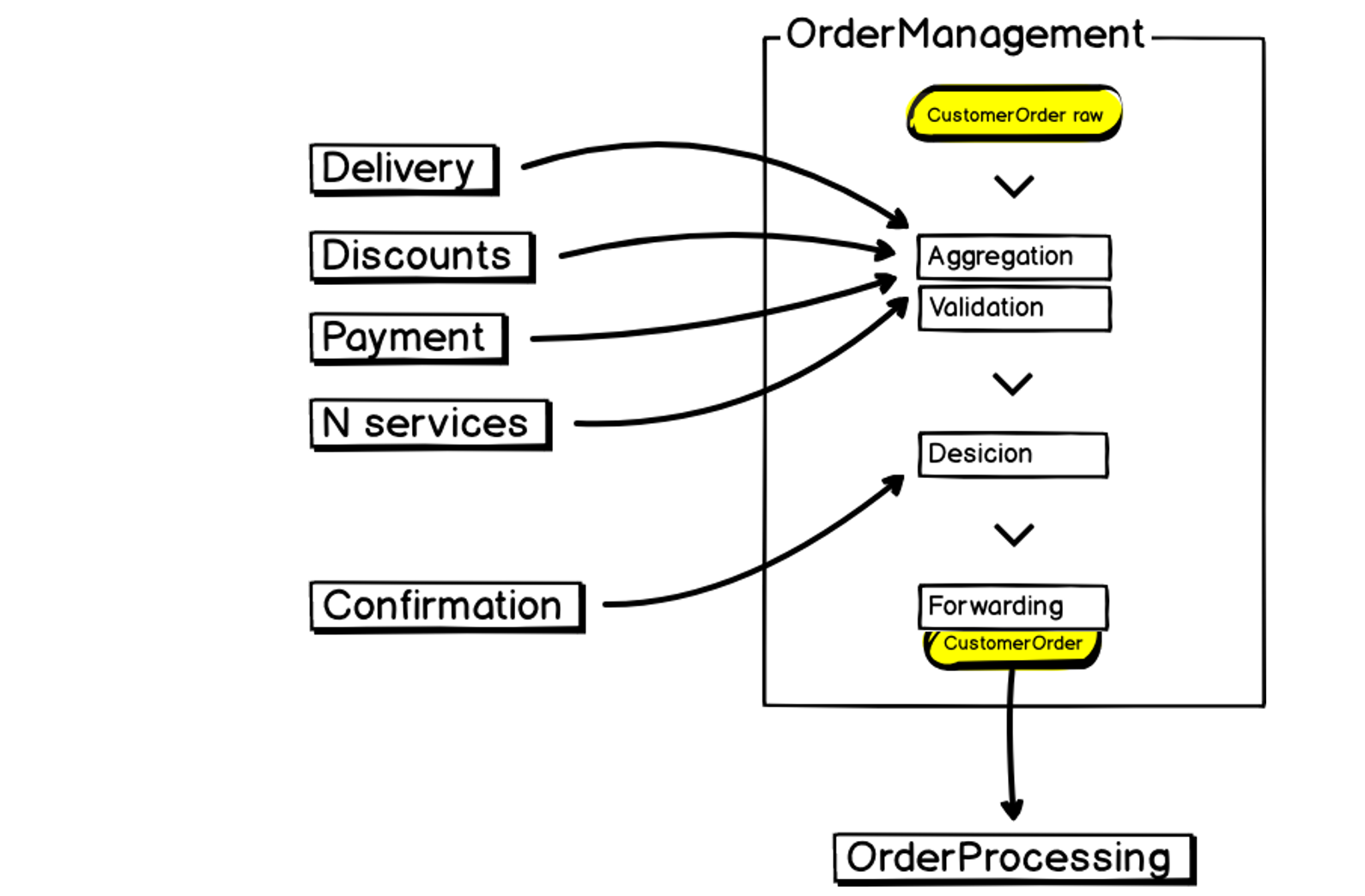
Mit diesen Überlegungen haben wir die Daten an erster Stelle gestellt und das Pipelining in den Dienst aufgenommen:

Zunächst definieren wir ein Datenmodell, das in die Handler-Pipeline eingeht. Daten können geändert werden, und Änderungen können sowohl sequenziell als auch parallel erfolgen. Damit gewinnen wir an Geschwindigkeit.
Zurück in die Zukunft
Plötzlich, als wir Microservices entwickelten, kamen wir zum Programmiermodell der 70er Jahre. Nach den 70er Jahren entstanden große Unternehmensmonolithen, in denen objektorientierte Programmierung und funktionale Programmierung auftraten - große Abstraktionen, die es ermöglichten, Code in diesen Monolithen zu halten. Bei Microservices brauchen wir das alles nicht, und wir können das hervorragende CSP-Modell ( Communicating Sequential Processes ) verwenden, dessen Idee erst in den 70er Jahren von Charles Choir vorgestellt wurde.
Wir verwenden auch Sequence / Selection / Interation - ein strukturelles Programmierparadigma, nach dem der gesamte Programmcode aus den entsprechenden Kontrollstrukturen zusammengesetzt werden kann.
Nun, prozedurale Programmierung, die in den 70ern der Mainstream war :)
Projektstruktur

Wie ich bereits sagte, haben wir die Daten an erster Stelle gestellt. Außerdem haben wir den Bau des Projekts „aus der Infrastruktur“ durch ein geschäftsorientiertes ersetzt. Damit der Entwickler durch Eingabe des Projektcodes sofort sieht, was der Service leistet - genau das ist die Transparenz, die wir als eine der Grundvoraussetzungen für die Struktur unserer Microservices identifiziert haben.
Als Ergebnis haben wir eine flache Architektur: eine kleine API-Schicht plus Datenmodelle. Und die gesamte Logik (die in unserem Kontext durch die Geschäftsanforderungen eines Microservices begrenzt ist) ist in Prozessoren (Handlern) gespeichert.
Wir versuchen, keine neuen, separaten Microservices ohne klare Aufforderung des Unternehmens zu erstellen - so steuern wir die Granularität des gesamten Systems. Wenn es eine Logik gibt, die eng mit dem vorhandenen Mikrodienst verbunden ist, sich aber im Wesentlichen auf einen anderen Kontext bezieht, schließen wir dies zunächst mit den sogenannten Diensten. Und nur wenn ein ständiger Geschäftsbedarf entsteht, nehmen wir ihn in einen separaten Microservice auf, den wir dann über einen RPC-Aufruf abrufen.
Um die Granularität zu kontrollieren und Microservices nicht unnötig zu produzieren, schließen wir eine Logik, die nicht direkt mit diesem Kontext zusammenhängt, sondern eng mit diesem Microservice in der Services-Schicht verbunden ist. Und dann, wenn es einen geschäftlichen Bedarf gibt, bringen wir ihn zu einem separaten Microservice - und verwenden ihn dann mit dem rpc-Aufruf, um darauf zuzugreifen.
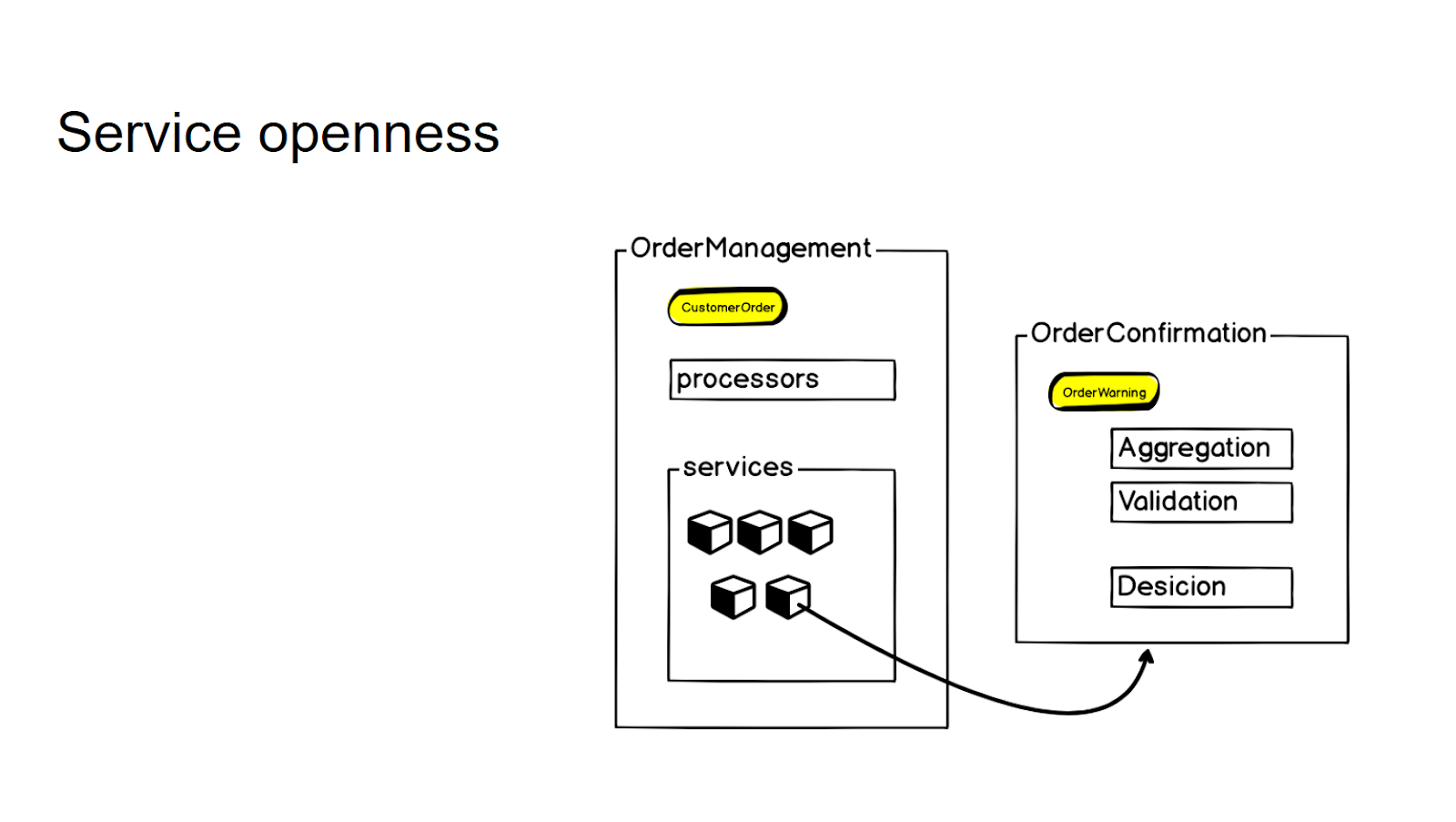
Somit ändert sich für die interne API in den Prozessoren des Dienstes die Interaktion in keiner Weise.
Nachhaltigkeit
Wir haben uns entschieden, keine Bibliotheken von Drittanbietern im Voraus zu nehmen, da die Daten, mit denen wir arbeiten, sehr sensibel sind. Also sind wir ein bisschen gefahren :) Zum Beispiel haben wir selbst einige klassische Mechanismen implementiert - für Idempotenz, Queue-Worker, Fehlertoleranz, Kompensation von Transaktionen. Unser nächster Schritt ist der Versuch, es wiederzuverwenden. In Bibliotheken einwickeln, vielleicht Container in Seitenwagen in Kubernetes Pods. Jetzt können wir diese Muster anwenden.
Wir implementieren in unseren Systemen ein Muster, das als "Graceful Degradation" bezeichnet wird: Der Service muss unabhängig von den externen Aufrufen, in denen wir Informationen aggregieren, weiterhin funktionieren. Beispiel für das Erstellen einer Bestellung: Wenn die Anfrage in den Service eingegangen ist, erstellen wir in jedem Fall eine Bestellung. Auch wenn der benachbarte Dienst ausfällt, ist dieser für einen Teil der Informationen verantwortlich, die wir aggregieren oder validieren müssen. Im Übrigen - wir werden die Bestellung nicht verlieren, auch wenn wir bei der kurzfristigen Ablehnung der Bestellabwicklung nicht dorthin überweisen müssen. Dies ist auch eines der Kriterien, nach denen wir entscheiden, ob wir die Logik in einen separaten Dienst einordnen. Wenn ein Dienst seine Arbeit nicht bereitstellen kann, wenn die folgenden Dienste im Netzwerk nicht verfügbar sind, müssen Sie ihn entweder neu entwerfen oder darüber nachdenken, ob er überhaupt aus dem Monolithen entfernt werden soll.
Go to Go!
Wenn Sie geschäftsorientierte Produktmikroservices aus einer klassischen serviceorientierten Architektur, insbesondere PHP, schreiben, stoßen Sie auf einen Paradigmenwechsel. Und es muss bestanden werden, sonst kann man endlos auf den Rechen treten. Die geschäftsorientierte Struktur des Projekts ermöglicht es uns, den Code nicht noch einmal zu komplizieren und die Granularität des Service zu kontrollieren.
Eine unserer Hauptaufgaben war es, die Stabilität des Dienstes zu erhöhen. Natürlich bietet Go nicht sofort eine erhöhte Stabilität. Meiner Meinung nach erwies es sich im Go-Ökosystem jedoch als einfacher, alle erforderlichen Zuverlässigkeits-Kits auch mit eigenen Händen zu erstellen, ohne auf Bibliotheken von Drittanbietern zurückgreifen zu müssen.
Eine weitere wichtige Aufgabe bestand darin, die Flexibilität des Systems zu erhöhen. Und hier kann ich definitiv sagen, dass die Einführungsrate der vom Unternehmen geforderten Änderungen erheblich gestiegen ist. Dank der Architektur der neuen Microservices bleibt der Entwickler mit den Geschäftsfunktionen allein, er muss nicht mehr über das Erstellen von Clients, das Senden von Überwachungen, das Senden von Tracing und das Einrichten der Protokollierung nachdenken. Wir überlassen dem Entwickler genau die Ebene, auf der die Geschäftslogik geschrieben wird, damit er nicht über das gesamte Infrastrukturpaket nachdenken muss.
Werden wir alles auf Go komplett umschreiben und PHP aufgeben?
Nein, da wir uns von den Geschäftsanforderungen entfernen und es einige Kontexte gibt, in die PHP sehr gut passt - es benötigt keine solche Geschwindigkeit und das gesamte Go-go-Toolkit. Die gesamte Automatisierung der Abläufe für die Auslieferung von Bestellungen und die Verwaltung von Fotostudios erfolgt in PHP. Aber zum Beispiel in der E-Commerce-Plattform auf Kundenseite haben wir fast alles auf Go umgeschrieben, da es dort gerechtfertigt ist.