Spring ist ein leistungsfähiges Open Source Java Framework. Ich habe beschlossen, Ihnen zu erklären, für welche Aufgaben das Spring-Backend nützlich ist und welche Vor- und Nachteile es im Vergleich zu anderen Bibliotheken hat: Guice und Dagger 2. Berücksichtigen Sie die Injektion von Abhängigkeiten und die Inversion von Steuerelementen - Sie lernen, wie Sie mit dem Studium dieser Prinzipien beginnen.
- Hallo, mein Name ist Cyril. Heute werde ich über Abhängigkeitsinjektion sprechen.
Wir werden mit dem beginnen, was mein Bericht heißt. "In einem bestimmten Königreich, nicht in einem" springenden "Zustand." Wir werden natürlich über den Frühling sprechen, aber ich möchte auch alles betrachten, was außer ihm ist. Worüber werden wir konkret sprechen?

Ich werde einen kleinen Exkurs machen - erzählen Sie, woran ich arbeite, was mein Projekt ist, warum wir Dependency Injection verwenden. Dann erzähle ich Ihnen, worum es geht, vergleiche Inversion of Control und Dependency Injection und spreche über die Implementierung in den drei bekanntesten Bibliotheken.
Ich arbeite im Yandex.Tracker-Team. Wir machen ein Lebensmittelanalog von Jira oder Trello. [...] Wir haben uns entschlossen, unser eigenes Produkt herzustellen, das zuerst intern war. Jetzt verkaufen wir es aus. Jeder von Ihnen kann mitmachen, seinen eigenen Tracker erstellen und Aufgaben erledigen - zum Beispiel im Bildungs- oder Geschäftsbereich.
Schauen wir uns die Oberfläche an. In den Beispielen werde ich einige Begriffe aus meiner Region verwenden. Wir werden versuchen, ein Ticket zu erstellen und die Kommentare zu lesen, die andere Kollegen mir hinterlassen werden.
Was ist Dependency Injection im Allgemeinen? Dies ist ein Programmiermuster, das dem alten amerikanischen Sprichwort, dem Hollywood-Prinzip, entspricht: "Rufen Sie uns nicht an, wir rufen Sie selbst an." Abhängigkeiten selbst kommen zu uns. Dies ist in erster Linie ein Muster, keine Bibliothek. Daher ist ein solches Muster im Prinzip fast überall verbreitet. Man kann sogar sagen, dass alle Anwendungen Dependency Injection auf die eine oder andere Weise verwenden.

Lassen Sie uns sehen, wie Sie sich Dependency Injection selbst einfallen lassen können, wenn wir bei Null anfangen. Angenommen, ich habe beschlossen, eine so kleine Klasse zu entwickeln, in der ich über unsere API ein Ticket erstellen werde. Erstellen Sie beispielsweise eine Instanz der TrackerApi-Klasse. Es hat eine createTicket-Methode, mit der wir meine E-Mail senden. Wir erstellen unter meinem Konto ein Ticket mit dem Namen: "Bereiten Sie einen Bericht für Java Meetup vor".

Schauen wir uns die Implementierung von TrackerApi an. Hier können wir zum Beispiel Folgendes tun: Eine httpClient-Instanz erstellen. In einfachen Worten werden wir ein Objekt erstellen, über das wir zur API gelangen. Über dieses Objekt rufen wir die Execute-Methode auf.

Zum Beispiel eine benutzerdefinierte. Ich habe externen Code aus diesen Klassen geschrieben, und er wird so etwas verwenden. Ich erstelle einen neuen TicketCreator und rufe die Methode createTicket auf.

Hier gibt es ein Problem: Jedes Mal, wenn wir ein Ticket erstellen, werden wir httpClient neu erstellen und neu erstellen, obwohl dies im Allgemeinen nicht erforderlich ist. httpClients sind sehr ernst zu schaffen.

Versuchen wir es mal. Hier sehen Sie das erste Beispiel für Dependency Injection in unserem Code. Achten Sie darauf, was wir getan haben. Wir haben unsere Variable im Feld herausgenommen und im Konstruktor eingetragen. Die Tatsache, dass wir es im Konstruktor eintragen, bedeutet, dass Abhängigkeiten zu uns kommen. Dies ist die erste Abhängigkeitsinjektion.

Wir haben die Verantwortung auf die Benutzer des Codes verlagert, daher müssen wir jetzt einen httpClient erstellen und ihn beispielsweise an TicketCreator übergeben.
Dies ist auch hier nicht sehr gut, da wir jetzt durch Aufrufen dieser Methode jedes Mal wieder httpClient erstellen.

Deshalb bringen wir es wieder aufs Feld. Und hier gibt es übrigens ein nicht offensichtliches Beispiel für die Abhängigkeitsinjektion. Wir können sagen, dass wir Tickets immer unter mir (oder unter jemand anderem) erstellen. Wir werden jedes einzelne TicketCreator-Objekt unter verschiedenen Benutzern erstellen.
Zum Beispiel wird dieser unter mir erschaffen, wenn wir ihn erschaffen. Und die Zeile, die wir an den Konstruktor übergeben, ist auch Abhängigkeitsinjektion.

Wie machen wir es jetzt? Erstellen Sie eine neue Instanz von TrackerTicketCreator und rufen Sie die Methode auf. Jetzt können wir sogar eine benutzerdefinierte Methode erstellen, die ein Ticket mit benutzerdefiniertem Text für uns erstellt. Erstellen Sie beispielsweise ein Ticket "Neuen Auszubildenden einstellen".

Nun wollen wir versuchen zu sehen, wie unser Code aussehen würde, wenn wir Kommentare in diesem Ticket auf die gleiche Weise unter mir lesen wollten. Dies ist ungefähr der gleiche Code. Wir würden die getComments-Methode für dieses Ticket aufrufen.
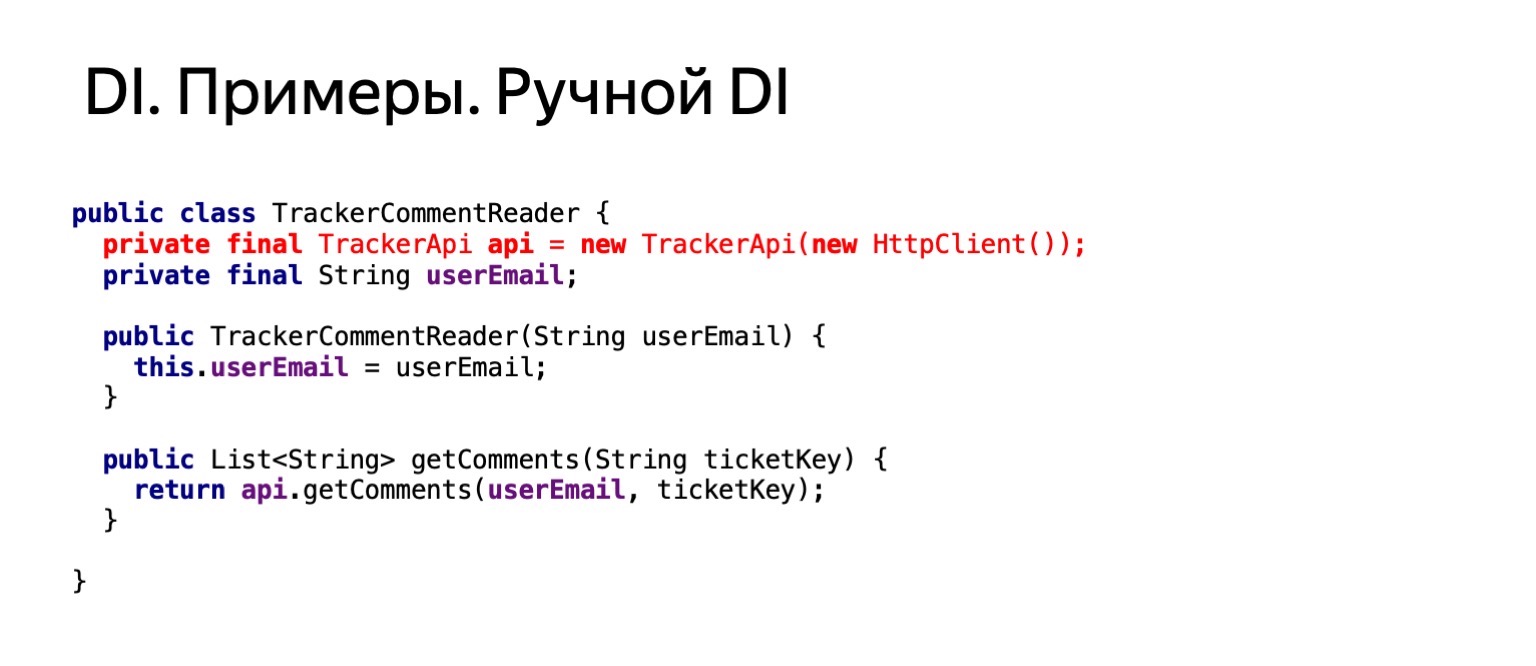
Wie würde er aussehen? Wenn wir diese Funktionalität in einem Kommentar-Reader verwenden und duplizieren, duplizieren wir die Erstellung von httpClient. Das passt nicht zu uns. Wir wollen es loswerden.

Gut Lassen Sie uns nun alle diese Parameter als Abhängigkeitsinjektion und als Konstruktorparameter weiterleiten.

Was ist das Problem hier? Wir haben alles übersprungen, aber in den Benutzercode schreiben wir jetzt "Boilerplate". Dies ist eine Art unnötiger Code, den ein Benutzer normalerweise schreiben muss, um eine relativ kleine logische Aktion auszuführen. Hier müssen wir ständig httpClient, eine API dafür, erstellen und Benutzer-E-Mails auswählen. Jeder TicketCreator-Benutzer muss dies selbst tun. Das ist nicht in Ordnung. Wir werden jetzt versuchen zu sehen, wie es in Bibliotheken aussehen wird, wenn wir versuchen, es zu vermeiden.
Lassen Sie uns nun ein wenig abweichen und untersuchen, was Inversion of Control ist, da viele damit Abhängigkeitsinjektion assoziieren.

Inversion of Control ist ein Programmierprinzip, bei dem die von uns verwendeten Objekte nicht von uns erstellt werden. Wir haben keinerlei Einfluss auf ihren Lebenszyklus. In der Regel wird die Entität, die diese Objekte erstellt, als IoC-Container bezeichnet. Viele von Ihnen haben hier vom Frühling gehört. Die Dokumentation von Spring besagt, dass IoCs auch als Abhängigkeitsinjektion bezeichnet werden. Sie glauben, dass dies ein und dasselbe ist.

Was sind die Grundprinzipien? Objekte werden nicht durch Anwendungscode erstellt, sondern durch einen IoC-Container. Wir als Bibliotheksnutzer tun nichts, alles kommt für uns allein. Natürlich ist IoC relativ. Der IoC-Container selbst erstellt diese Objekte und dies gilt nicht mehr für ihn. Sie könnten denken, dass IoC nicht nur DI-Bibliotheken implementiert. Die bekannten Java-Bibliotheken Servlets und Akka Actors, die jetzt in Scala und in Java-Code verwendet werden.

Reden wir über Bibliotheken. Generell wurden bereits viele Bibliotheken für Java und Kotlin geschrieben. Ich werde die wichtigsten auflisten:
- Frühling, ein großartiger Rahmen. Sein Hauptteil ist Dependency Injection oder, wie sie sagen, Inversion of Control.
- Guice ist eine Bibliothek, die ungefähr zwischen dem zweiten und dritten Frühling geschrieben wurde, als Spring von XML zu Codebeschreibung wechselte. Das heißt, als der Frühling noch nicht so schön war.
- Dolch ist das, was Leute auf Android normalerweise benutzen.
Versuchen wir, unser Beispiel für Spring umzuschreiben.

Wir hatten unseren TrackerApi. Ich habe den Benutzer hier nicht kurz eingeschlossen. Nehmen wir an, wir versuchen in Dependency Injection, dies für httpClient zu tun. Dazu müssen wir es mit einer Anmerkung deklarieren.
Die Komponente , die gesamte Klasse und insbesondere der Konstruktor werden mit der
Autowired- Annotation
deklariert . Was bedeutet das für den Frühling?

Wir haben eine solche Konfiguration im Code, die durch die Annotation
Component Scan angezeigt wird. Dies bedeutet, dass wir versuchen werden, den gesamten Baum unserer Klassen in dem Paket durchzugehen, in dem er enthalten ist. Weiter landeinwärts werden wir versuchen, alle Klassen zu finden, die in der Annotation "
Component" markiert sind.
Diese Komponenten fallen in den IoC-Container. Es ist wichtig für uns, dass alles für uns fällt. Wir markieren nur, was wir ankündigen möchten. Damit etwas zu uns kommt, müssen wir es mit der
Autowired- Annotation im Konstruktor deklarieren.

TicketCreator markieren wir genauso.

Und CommentReader auch.
Nun schauen wir uns noch einmal die Konfiguration an. Wie bereits erwähnt, speichert Component Scan alles in einem IoC-Container. Aber es gibt einen Punkt, die sogenannte Fabrikmethode. Wir haben die httpClient-Methode, die wir nicht als Klasse erstellen, da httpClient aus der Bibliothek zu uns kommt. Er hat kein Verständnis dafür, was Frühling ist usw. Wir werden es direkt in der Konfiguration erstellen. Dazu schreiben wir eine Methode, die sie normalerweise einmal erstellt, und markieren sie mit der Bean-Annotation.

Was sind die Vor- und Nachteile? Das Hauptplus - Frühling ist in der Welt sehr verbreitet. Das nächste Plus und Minus ist das automatische Scannen. Wir sollten nicht explizit angeben, dass wir der IoC einen Container hinzufügen möchten, außer Anmerkungen über die Klassen selbst. Genug Anmerkungen. Und das Minus ist genau das gleiche: Wenn wir im Gegenteil die Kontrolle darüber haben wollen, dann bietet uns Spring dies nicht an. Es sei denn, wir können in unserem Team sagen: „Nein, das werden wir nicht tun. Wir müssen irgendwo eindeutig etwas vorschreiben. Nur in der Konfiguration, wie wir es mit den Bohnen gemacht haben.
Auch aus diesem Grund tritt ein langsamer Start auf. Wenn die Anwendung gestartet wird, muss Spring all diese Klassen durchgehen und herausfinden, was in den IoC-Container eingefügt werden soll. Es verlangsamt ihn. Der größte Nachteil des Frühlings scheint mir der Abhängigkeitsbaum zu sein. Es wird bei der Kompilierung nicht geprüft. Wenn der Frühling irgendwann beginnt, muss er verstehen, ob ich eine solche Abhängigkeit in mir habe. Wenn sich später herausstellt, dass es sich nicht im Abhängigkeitsbaum befindet, erhalten Sie zur Laufzeit einen Fehler. Und wir in Java wollen keinen Laufzeitfehler. Wir möchten, dass der Code für uns kompiliert wird. Das bedeutet, dass es funktioniert.

Werfen wir einen Blick auf Guice. Dies ist eine Bibliothek, die, wie gesagt, zwischen dem zweiten und dritten Frühling entstanden ist. Die Schönheit, die wir gesehen haben, war nicht. Es gab XML. Um dieses Problem zu beheben, und wurde von Guice geschrieben. Und hier sehen Sie, dass wir im Gegensatz zur Konfiguration ein Modul schreiben. Darin deklarieren wir explizit, welche Klassen in dieses Modul eingefügt werden sollen: TrackerAPI, TrackerTicketCreator und alle anderen Klassen. Ein Analogon zur Bean-Annotation hier ist
Provides , das auf die gleiche Weise httpClient erstellt.

Wir müssen jede dieser Bohnen deklarieren. Wir werden ein Beispiel für
Singleton nennen .
Singleton wird jedoch genau sagen, dass eine solche Bean genau einmal erstellt wird. Wir werden es nicht ständig neu erstellen. Und
Inject ist jeweils ein Analogon von
Autowired .

Eine kleine Tablette mit dem, was dazu gehört.

Was sind die Vor- und Nachteile? Vorteile: Es scheint mir einfacher und verständlicher zu sein als die XML-Version von Spring. Schnellerer Start. Und hier kommen die Nachteile: Es erfordert eine explizite Deklaration der verwendeten Bohnen. Wir hätten Bean schreiben sollen. Andererseits ist dies ein Plus, wie wir bereits gesagt haben. Dies ist ein Spiegelbild dessen, was der Frühling hat. Natürlich ist es weniger verbreitet als der Frühling. Das ist sein natürliches Minus. Und es gibt genau das gleiche Problem: Der Abhängigkeitsbaum wird in der Kompilierungsphase nicht überprüft.
Als die Jungs anfingen, Guice für Android zu verwenden, stellten sie fest, dass es ihnen immer noch an Startgeschwindigkeit mangelte. Aus diesem Grund haben sie beschlossen, ein einfacheres und primitiveres Abhängigkeitsinjektionsframework zu schreiben, mit dem sie die Anwendung schnell starten können, da dies für Android sehr wichtig ist.

Hier ist die Terminologie dieselbe. Dolch hat genau die gleichen Module wie Guice. Sie sind jedoch bereits mit Anmerkungen versehen, nicht wie bei der Vererbung durch die Klasse. Daher wird das Prinzip beibehalten.
Das einzige Minus ist, dass wir im Modul immer explizit angeben müssen, wie die Beans erstellt werden. In Guice könnten wir die Kreation von Bohnen innerhalb der Bohne selbst geben. Wir mussten nicht sagen, zu welchen Abhängigkeiten wir weiterleiten müssen. Und hier müssen wir das explizit sagen.

In Dagger gibt es das Konzept einer Komponente, da Sie nicht zu manuell eingeben möchten. Eine Komponente bindet Module, wenn ein Bin von einem Modul deklariert werden soll, damit es in ein anderes Modul übernommen werden kann. Dies ist ein anderes Konzept. Eine Bean aus einem Modul kann mithilfe einer Komponente eine Bean aus einem anderen Modul „injizieren“.

Hier ist ungefähr dieselbe Übersichtstafel - was sich im Fall von Inject oder Modulen geändert hat oder nicht.

Was sind die vorteile Es ist noch einfacher als Guice. Der Start ist noch schneller als bei Guice. Und es wird wahrscheinlich nicht mehr schneller, weil Dagger das Nachdenken völlig aufgegeben hat. Dies ist genau der Teil der Bibliothek in Java, der dafür verantwortlich ist, den Zustand eines Objekts, seine Klasse und Methoden zu untersuchen. Das heißt, Sie erhalten den Status zur Laufzeit. Daher wird keine Reflexion verwendet. Er geht nicht und scannt nicht, welche Abhängigkeiten jemand hat. Aber deshalb fängt er sehr schnell an.
Wie macht er das? Codegenerierung verwenden.
Wenn wir zurückblicken, werden wir die Interface-Komponente sehen. Wir haben keine Implementierung dieser Schnittstelle implementiert, Dagger erledigt dies für uns. Und es wird möglich sein, die Schnittstelle in der Anwendung weiter zu verwenden.
Natürlich ist es in der Android-Welt aufgrund dieser Geschwindigkeit sehr verbreitet. Der Abhängigkeitsbaum wird sofort beim Kompilieren überprüft, da es nichts gibt, was wir zur Laufzeit verzögert überprüfen werden.
Was sind die Nachteile? Er hat weniger Möglichkeiten. Es ist ausführlicher als Guice und Spring.

Innerhalb dieser Bibliotheken entstand in Java eine Initiative - das sogenannte JSR-330. JSR ist eine Anforderung, die Sprachspezifikation zu ändern oder um einige zusätzliche Bibliotheken zu ergänzen. Ein solcher Standard wurde basierend auf Guice vorgeschlagen, und dieser Bibliothek wurden
Inject- Anmerkungen hinzugefügt. Dementsprechend unterstützen es Spring und Guice.
Welche Schlussfolgerungen können gezogen werden? Java hat viele verschiedene Bibliotheken für DI. Und Sie müssen verstehen, warum wir einen bestimmten von ihnen nehmen. Wenn wir Android nehmen, dann gibt es schon keine Wahl, wir benutzen Dolch. Wenn wir in die Backend-Welt gehen, schauen wir uns bereits an, was am besten zu uns passt. Und für die erste Studie zu Dependency Injection scheint mir Guice besser zu sein als Spring. Darin ist nichts überflüssig. Sie können sehen, wie es funktioniert, fühlen.
Für weitere Studien empfehle ich Ihnen, sich mit der Dokumentation all dieser Bibliotheken und der Zusammensetzung von JSR vertraut zu machen:
-
Frühling-
Guice-
Dolch 2-
JSR-330Vielen Dank!