Seit der letzten Veröffentlichung in der Julia-Sprachwelt sind viele interessante Dinge passiert:
- Sie belegte alle ersten Plätze in Bezug auf das Wachstum von Unterstützungspaketen. Dafür liebe ich Statistiken - das Wichtigste ist, eine bequeme Maßeinheit zu wählen, zum Beispiel Prozentsätze wie in der angegebenen Ressource
- Die Version 1.3.0 wurde veröffentlicht. Zu den größten Neuerungen zählen die Modernisierung des Paketmanagers und die Einführung von Multi-Threaded-Concurrency
- Julia bekommt Unterstützung von Nvidia
- Das amerikanische Department of Advanced Studies im Bereich Energie hat viel Geld zur Lösung von Optimierungsproblemen bereitgestellt
Gleichzeitig steigt das Interesse der Entwickler spürbar an, was sich in einem umfassenden Benchmarking niederschlägt:
Wir freuen uns einfach über neue und praktische Tools und lernen sie weiter. Heute Abend widmen wir uns der Textanalyse, der Suche nach verborgenen Bedeutungen in den Reden der Präsidenten und der Texterstellung im Geiste von Shakespeare und Julia Programmer. Zum Nachtisch versorgen wir ein wiederkehrendes Netzwerk von 40.000 Torten.
Kürzlich wurde hier auf Habré die Überprüfung von Paketen für Julia durchgeführt, um Forschungen im Bereich NLP - Julia NLP durchzuführen . Wir verarbeiten Texte . Kommen wir also sofort zur Sache und beginnen mit dem TextAnalysis- Paket.
TextAnalisys
Geben Sie einen Text ein, den wir als String-Dokument darstellen:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
Für ein bequemes Arbeiten mit einer großen Anzahl von Dokumenten ist es möglich, Felder, z. B. Titel, zu ändern. Um die Verarbeitung zu vereinfachen, können Satzzeichen und Großbuchstaben entfernt werden:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
Damit können Sie übersichtliche n-Gramme für Wörter erstellen:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
Es ist klar, dass Interpunktionszeichen und Wörter mit Großbuchstaben separate Einheiten im Wörterbuch sind, was eine qualitative Bewertung der Häufigkeit der Vorkommen der spezifischen Begriffe in unserem Text beeinträchtigt. Deshalb haben wir sie beseitigt. Für n-Gramme ist es einfach, viele interessante Anwendungen zu finden. Sie können beispielsweise zur Fuzzy-Suche im Text verwendet werden. Da wir jedoch nur Touristen sind, werden wir mit Spielzeugbeispielen auskommen, nämlich der Generierung von Text mit Markov-Ketten
Procházení modelového grafu
Eine Markov-Kette ist ein diskretes Modell eines Markov-Prozesses, das aus einer Änderung in einem System besteht, das nur seinen (Modell-) vorherigen Zustand berücksichtigt. Bildlich gesprochen kann man diese Konstruktion als probabilistischen zellulären Automaten wahrnehmen. N-Gramme kommen bei diesem Konzept durchaus vor: Jedes Wort aus dem Lexikon ist mit jeder anderen Verbindung unterschiedlicher Dicke verbunden, die durch die Häufigkeit des Auftretens bestimmter Wortpaare (Gramme) im Text bestimmt wird.

Markovkette für Saite "ABABD"
Die Implementierung des Algorithmus selbst ist bereits eine großartige Aktivität für den Abend, aber Julia hat bereits ein wunderbares Markovify- Paket, das nur für diese Zwecke erstellt wurde. Wir scrollen sorgfältig durch das Handbuch in tschechischer Sprache und fahren mit unseren sprachlichen Ausführungen fort.
Text in Token aufteilen (z. B. Wörter)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
Wir stellen ein Modell erster Ordnung zusammen (nur die nächsten Nachbarn werden berücksichtigt):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
Anschließend implementieren wir die Funktion der generierenden Phrase basierend auf dem bereitgestellten Modell. Tatsächlich sind ein Modell, eine Problemumgehung und die Anzahl der Phrasen erforderlich, die Sie erhalten möchten:
Code function gensentences(model, fun, n) sentences = []
Der Entwickler des Pakets stellte zwei Bypass-Funktionen zur Verfügung: walk und walk2 (die zweite funktioniert länger, bietet jedoch einzigartigere Designs), und Sie können jederzeit Ihre Option bestimmen. Lass es uns versuchen:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
Natürlich ist die Versuchung groß, russische Texte zu probieren, besonders weiße Verse. Für die russische Sprache sind die meisten Sätze aufgrund ihrer Komplexität nicht lesbar. Wie bereits erwähnt , erfordern Sonderzeichen besondere Sorgfalt. Daher speichern wir entweder die Dokumente, aus denen der in UTF-8 codierte Text stammt, oder verwenden zusätzliche Tools .
Auf Anraten seiner Schwester habe ich nach dem Reinigen einiger Bücher von Oster von Sonderzeichen und etwaigen Trennzeichen und dem Festlegen einer zweiten Ordnung für n-Gramm die folgenden satzweisen Einheiten erhalten:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
Sie versicherte, dass durch eine solche Technik Gedanken im weiblichen Gehirn aufgebaut wurden ... ähm, und über wen soll ich streiten ...
Analysiere es
Im Verzeichnis des TextAnalysis-Pakets finden Sie Beispiele für Textdaten, darunter eine Sammlung von Reden amerikanischer Präsidenten vor dem Kongress

Code using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
Nachdem wir diese Dateien gelesen und ein Korps daraus gebildet und von Satzzeichen befreit haben, werden wir das allgemeine Vokabular aller Reden überprüfen:
Code crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
Es kann interessant sein zu sehen, welche Dokumente bestimmte Wörter enthalten. Schauen Sie sich beispielsweise an, wie wir mit Versprechungen umgehen:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
oder mit Pronomenfrequenzen:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
Also wahrscheinlich Wissenschaftler und Vergewaltigungsjournalisten und es gibt eine perverse Einstellung zu den untersuchten Daten.
Matrizen
Wirklich verteilende Semantik beginnt, wenn sich Texte, Gramme und Token in Vektoren und Matrizen verwandeln.
Eine Term Document Matrix ( DTM ) ist eine Matrix mit einer Größe wo - die Anzahl der Dokumente im Fall und - Korpuswörterbuchgröße, d. h. die Anzahl der Wörter (eindeutig), die in unserem Korpus gefunden werden. In der i- ten Zeile ist die j- te Spalte der Matrix eine Zahl - wie oft im i- ten Text das j- te Wort gefunden wurde.
Code dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
Hier sind die ursprünglichen Einheiten Begriffe
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
Warten Sie einen Moment ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
Es wird notwendig sein, detaillierter zu lesen ...
Sie können auch alle Arten von interessanten Daten aus dem Begriff Matrizen extrahieren. Geben Sie die Häufigkeit an, mit der bestimmte Wörter in Dokumenten vorkommen
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
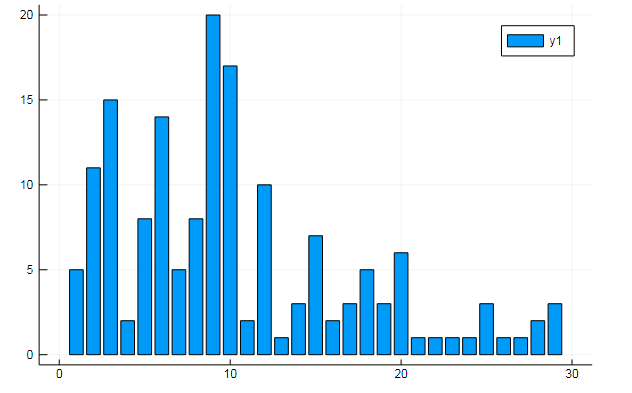
D[:, w1] |> bar
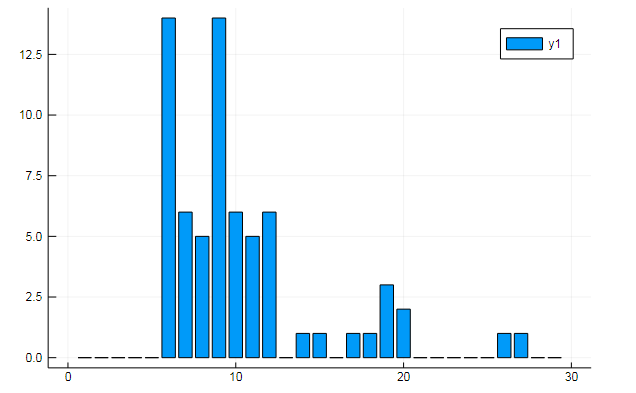
oder Ähnlichkeit von Dokumenten zu einigen versteckten Themen:
k = 3

Die Grafiken zeigen, wie jedes der drei Themen in den Reden offenbart wird
oder Gruppieren von Wörtern nach Themen oder zum Beispiel die Ähnlichkeit des Wortschatzes und die Präferenz bestimmter Themen in verschiedenen Dokumenten
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
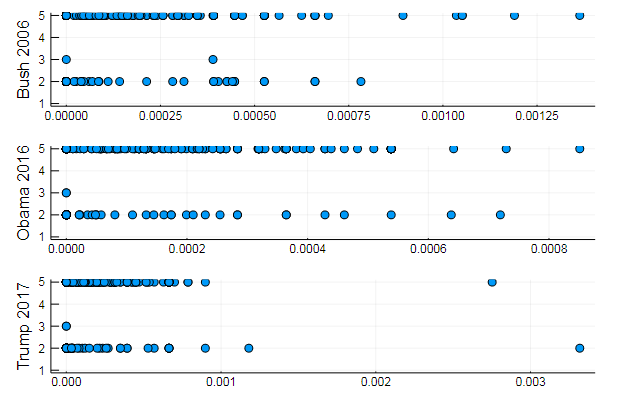
Ganz natürliche Ergebnisse, Leistungen des gleichen Typs. Tatsächlich ist NLP eine interessante Wissenschaft, und Sie können viele nützliche Informationen aus korrekt aufbereiteten Daten extrahieren: Sie können viele Beispiele zu dieser Ressource finden ( Anerkennung des Autors in den Kommentaren , Verwendung von LDA usw.).
Nun, um nicht zu weit zu gehen, werden wir Sätze für den idealen Präsidenten generieren:
Code function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
Langes Kurzzeitgedächtnis
Nun, wie kann es ohne neuronale Netze sein! Sie sammeln mit zunehmender Geschwindigkeit Lorbeeren auf diesem Gebiet, und das Umfeld der Julia-Sprache trägt in jeder Hinsicht dazu bei. Neugierigen raten wir zum Knet- Paket, das im Gegensatz zu dem zuvor untersuchten Flux nicht mit neuronalen Netzwerkarchitekturen als Konstruktor aus Modulen funktioniert, sondern größtenteils mit Iteratoren und Streams. Dies kann von akademischem Interesse sein und zu einem tieferen Verständnis des Lernprozesses beitragen und bietet auch High-Performance-Computing. Wenn Sie auf den oben angegebenen Link klicken, finden Sie Anleitungen, Beispiele und Material für das Selbststudium (z. B. das Erstellen eines Shakespeare-Textgenerators oder eines Juliac-Codes in wiederkehrenden Netzwerken). Einige Funktionen des Knet-Pakets sind jedoch nur für die GPU implementiert. Lassen Sie uns daher zunächst weiter mit Flux arbeiten.
Eines der typischen Beispiele für den Betrieb von Wiederholungsnetzen ist häufig das Modell, mit dem Shakespeares Sonette symbolisch gespeist werden:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
Wenn Sie blinzeln und kein Englisch können, dann scheint das Spiel ziemlich real zu sein .

Auf Russisch ist es einfacher zu verstehen
Aber es ist viel interessanter, die Großen und Mächtigen anzuprobieren, und obwohl es lexikalisch sehr schwierig ist, können Sie primitivere Literatur als Daten verwenden, und zwar in jüngerer Zeit als Avantgarde-Strömung der modernen Poesie - Reime.
Datenerfassung
Pies and Powders - rhythmische Quatrains, oft ohne Reim, in Kleinbuchstaben und ohne Satzzeichen.
Die Wahl fiel auf die Website poetory.ru, auf der admin Genosse hior . Das lange Fehlen einer Antwort auf die Datenanforderung war der Grund für den Beginn der Analyse der Site. Ein kurzer Blick auf das HTML-Tutorial gibt Ihnen ein rudimentäres Verständnis für das Design von Webseiten. Als nächstes finden wir die Mittel der Julia-Sprache für die Arbeit in solchen Bereichen:
- HTTP.jl - HTTP-Client- und Serverfunktionalität für Julia
- Gumbo.jl - Analyse von HTML-Layouts und nicht nur
- Cascadia.jl - Zusatzpaket für Gumbo

Dann implementieren wir ein Skript, das Seiten der Poesie umdreht und die Torten in ein Textdokument speichert:
Code using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
Genauer gesagt ist es in einem Jupiter-Notizbuch zerlegt. Lassen Sie uns die Torten und Schießpulver in einer einzigen Zeile sammeln:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
Und schauen Sie sich das verwendete Alphabet an:
prod(sort([unique(str)..., '_']) )

Überprüfen Sie die heruntergeladenen Daten, bevor Sie den Vorgang starten.
Ay-ah-ah, was für eine Schande! Einige Benutzer verstoßen gegen die Regeln (manchmal drücken sich die Benutzer nur dadurch aus, dass sie in diesen Daten Geräusche machen). Also werden wir unsere Symbolhülle vom Müll befreien
str = lowercase(str)
Wie von rssdev10 empfohlen, wird Code mithilfe regulärer Ausdrücke geändert
Ich habe einen akzeptableren Zeichensatz. Die größte Entdeckung von heute ist, dass es aus Sicht des Maschinencodes mindestens drei verschiedene Bereiche gibt - für Datenjäger ist es schwer zu leben.

Jetzt können Sie Flux mit der anschließenden Darstellung der Daten in Form von onehot Vektoren verbinden:
Flux kommt ins Spiel using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
Wir setzen das Modell aus ein paar LSTM-Schichten, einem vollständig verbundenen Perceptron und Softmax sowie alltäglichen Kleinigkeiten und für die Verlustfunktion und den Optimierer:
Code m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
Das Modell ist bereit für das Training. Wenn Sie also die nachstehende Zeile durchlaufen, können Sie sich selbstständig machen. Die Kosten richten sich nach der Leistung Ihres Computers. In meinem Fall sind dies zwei Vorlesungen über Philosophie, die uns verdammt noch mal spät in der Nacht überreicht wurden ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
Nachdem Sie einen Probengenerator zusammengestellt haben, können Sie die Vorteile Ihrer Arbeit nutzen.
Barmaglot-Generator function sample(m, alphabet, len)
Leichte Enttäuschung aufgrund etwas hoher Erwartungen. Obwohl das Netzwerk nur eine Folge von Zeichen am Eingang hat und nur mit den Frequenzen ihrer Besprechung nacheinander arbeiten kann, hat es die Struktur des Datensatzes vollständig erfasst, einen Anschein von Wörtern hervorgehoben und in einigen Fällen sogar die Fähigkeit gezeigt, den Rhythmus beizubehalten. Möglicherweise hilft die Identifizierung der semantischen Affinität bei der Verbesserung.

Die Gewichte eines trainierten Netzwerks können auf der Festplatte gespeichert und dann leicht gelesen werden
weights = Tracker.data.(params(model)); using BSON: @save
Auch mit Prosa kommt nur abstrakte Cyberpsychedelie zum Vorschein. Es wurde versucht, die Qualität der Breite und Tiefe des Netzwerks sowie die Vielfalt und Fülle der Daten zu verbessern. Besonderer Dank gilt für das gegebene Textkorps dem größten Popularisierer der russischen Sprache

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
Aber wenn Sie ein neuronales Netzwerk auf den Quellcode der Julia-Sprache trainieren , stellt sich heraus, dass es ziemlich cool ist:
Hinzu kommt die Möglichkeit der Metaprogrammierung , wir bekommen ein Programm, das schreibt und läuft, vielleicht sogar unseren eigenen Code! Na ja, oder es wird ein Glücksfall für Filmdesigner über Hacker sein .
Im Allgemeinen ist der Anfang gemacht worden und dann schon, wie die Fantasie zeigt. Erstens sollten Sie ein hochwertiges Gerät kaufen, damit lange Berechnungen den Experimentierdrang nicht unterdrücken. Zweitens müssen wir uns eingehender mit Methoden und Heuristiken befassen, damit wir bessere und optimiertere Modelle entwerfen können. In dieser Ressource finden Sie alles, was mit der Verarbeitung natürlicher Sprache zu tun hat. Anschließend können Sie Ihrem neuronalen Netzwerk beibringen, wie man Gedichte generiert, oder an einem Hackathon zur Textanalyse teilnehmen .
Lassen Sie mich diesbezüglich Abschied nehmen. Daten für das Training in der Wolke , Listen auf dem Github , Feuer in den Augen, ein Ei in einer Ente und gute Nacht allerseits!