In meinem vorherigen
Artikel habe ich über die Erfahrungen mit der Verwendung der
Gemini- Engine zur Entwicklung von visuellen Tests bzw. visuellen Regressionstests gesprochen. Bei solchen Tests wird überprüft, ob sich nach den nächsten Änderungen etwas in der Benutzeroberfläche „bewegt“ hat, indem die aktuellen Screenshots mit den zuvor festgelegten Referenz-Screenshots verglichen werden. Seitdem hat sich in unseren Ansätzen zum Schreiben von visuellen Tests viel geändert, einschließlich der verwendeten Engine. Jetzt verwenden wir
Hermine , aber in diesem Artikel werde ich nicht nur und nicht so sehr von Hermine erzählen, sondern auch von den Problemen, die sich seitdem angesammelt haben, und wie man sie löst, was unter anderem zum Übergang zu einem neuen Motor führte.
Erstens hatten wir, obwohl die Tests erfolgreich waren, kein klares Verständnis darüber, was von den Tests abgedeckt wurde und was nicht. Es gab natürlich eine Vorstellung von dem Abdeckungsgrad, aber wir haben ihn nicht quantitativ gemessen. Zweitens nahm die Zusammensetzung der Tests mit der Zeit zu und verschiedene Tests testeten oft das Gleiche, weil In verschiedenen Screenshots stimmte ein Teil mit dem gleichen Teil überein, jedoch in einem anderen Screenshot. Infolgedessen können selbst geringfügige Änderungen an CSS viele Tests auf einmal überfordern und die Aktualisierung einer großen Anzahl von Standards erforderlich machen. Drittens tauchte in unserem Produkt ein dunkles Thema auf, und um es irgendwie mit Tests abzudecken, wurden einige Tests selektiv auf die Verwendung eines dunklen Themas umgestellt, was das Problem bei der Bestimmung des Abdeckungsgrads ebenfalls nicht klarer machte.
Leistungsoptimierung
Wir begannen seltsamerweise mit einer optimierten Leistung. Ich werde erklären warum. Unsere visuellen Tests basieren auf dem
Storybook . Jede Story im Storybook ist keine einzelne Komponente, sondern ein ganzer „Block“ (z. B. ein Raster mit einer Liste von Entitäten, einer Entitätskarte, einem Dialog oder sogar der gesamten Anwendung). Um diesen Block anzuzeigen, müssen Sie die Story mit Daten „pumpen“, und zwar nicht nur mit den Daten, die dem Benutzer angezeigt werden, sondern auch mit dem Status der im Block verwendeten Komponenten. Diese Informationen werden zusammen mit dem Quellcode in Form von JSON-Dateien gespeichert, die eine serialisierte Darstellung des Status der Anwendung enthalten (Redux Store). Ja, diese Daten sind, gelinde gesagt, redundant, vereinfachen jedoch die Erstellung von Tests erheblich. Um einen neuen Test zu erstellen, öffnen wir einfach die gewünschte Karte, Liste oder den gewünschten Dialog in der Anwendung, machen einen Schnappschuss des aktuellen Status der Anwendung und serialisieren ihn in eine Datei. Dann fügen wir eine neue Story und Tests hinzu, die Screenshots dieser Story enthalten (alles in wenigen Codezeilen).
Dieser Ansatz erhöht zwangsläufig die Größe des Bündels. Der Grad der Vervielfältigung von Daten in ihm "rollt" nur über. Bei der Ausführung von Tests führt die Gemini-Engine jede Testsuite in einer separaten Browsersitzung aus. Bei jeder Sitzung wird das Bundle erneut geladen, und die Größe des Bundles in einem solchen Schema ist weit vom letzten Wert entfernt.
Um die Testlaufzeit zu verkürzen, haben wir die Anzahl der Testsuiten reduziert, indem wir die Anzahl der darin enthaltenen Tests erhöht haben. Somit kann eine Testsuite mehrere Storys gleichzeitig betreffen. In diesem Schema haben wir praktisch die Möglichkeit verloren, nur einen bestimmten Bereich des Bildschirms zu "screenen", da Sie in Gemini den Screenshot-Bereich nur für die Testsuite als Ganzes festlegen können (obwohl die API dies vor jedem Screenshot zulässt, aber in der Praxis nicht funktioniert).
Die Unfähigkeit, den Bereich des Screenshots in den Tests einzuschränken, führte zu einer Verdoppelung der visuellen Informationen in den Referenzbildern. Obwohl es nicht viele Tests gab, schien dieses Problem nicht signifikant zu sein. Ja, und die Benutzeroberfläche hat sich nicht sehr oft geändert. Dies konnte jedoch nicht ewig so weitergehen - eine Neugestaltung zeichnete sich ab.
Mit Blick auf die Zukunft sage ich, dass in Hermine für jede Aufnahme ein Screenshot-Bereich eingerichtet werden kann und auf den ersten Blick der Wechsel zu einer neuen Engine alle Probleme lösen würde. Aber wir müssten immer noch große Testsuiten "zerquetschen". Tatsache ist, dass visuelle Tests von Natur aus nicht stabil sind (dies kann verschiedene Gründe haben, z. B. Netzwerkverzögerungen, Animationen oder „Wetter auf dem Mars“) und es ist sehr schwierig, auf automatische Wiederholungsversuche zu verzichten. Sowohl Gemini als auch Hermine führen Wiederholungsversuche für die gesamte Testsuite durch. Je „dicker“ die Testsuite ist, desto unwahrscheinlicher ist es, dass sie während der Wiederholungsversuche erfolgreich abgeschlossen wird Bei der nächsten Ausführung fallen möglicherweise Tests aus, die zuvor erfolgreich abgeschlossen wurden. Für dicke Testsuiten mussten wir ein alternatives Wiederholungsschema implementieren, das in die Gemini-Engine integriert war, und wollten dies beim Umstieg auf eine neue Engine nicht noch einmal tun.
Um das Laden der Testsuite zu beschleunigen, haben wir das monolithische Bündel in Teile aufgeteilt und jeden Snapshot des Anwendungszustands in ein separates "Teil" aufgeteilt, das "bei Bedarf" für jede Story separat geladen wird. Der Code zur Erstellung der Story sieht nun folgendermaßen aus:
Zum Erstellen einer Story wird die StoryProvider-Komponente verwendet (der Code wird unten angegeben). Schnappschüsse werden mit der
dynamischen Importfunktion geladen. Verschiedene Geschichten unterscheiden sich nur in Bildern von Staaten. Für ein dunkles Thema wird eine eigene Geschichte generiert, wobei derselbe Schnappschuss als Geschichte für ein helles Thema verwendet wird. Im Kontext eines Bilderbuchs sieht es so aus:
Standard-Themengeschichte Die StoryProvider-Komponente akzeptiert einen Rückruf zum Laden eines Snapshots, in dem die Funktion import () aufgerufen wird. Die Funktion import () arbeitet asynchron, sodass Sie nicht sofort nach dem Laden der Story einen Screenshot machen können - wir riskieren, die Lücke zu entfernen. Um den Moment des Endes des Downloads zu erfassen, rendert der Anbieter das Marker-DOM-Element, das die Test-Engine für die Dauer des Downloads signalisiert. Dies muss mit dem Screenshot verzögert werden:
Deaktivieren Sie außerdem das Hinzufügen von Quellzuordnungen zum Bundle, um die Größe des Bundles zu verringern. Um jedoch nicht die Fähigkeit zu verlieren, die Story zu debuggen (Sie wissen nie was), tun wir dies unter der Bedingung:
.storybook / webpack.config.js Das
Build-Storybook-Skript npm run kompiliert ein statisches Storybook ohne Quellkarte in den Ordner storybook-static. Es wird bei der Durchführung von Tests verwendet. Das
Storybook-Skript npm run wird zum Entwickeln und Debuggen von Teststories verwendet.
Beseitigung von Duplikaten visueller Informationen
Wie bereits erwähnt, können Sie in Gemini für die Testsuite als Ganzes Auswahlmöglichkeiten für den Screenshot-Bereich festlegen. Um das Problem des Duplizierens visueller Informationen in den Screenshots vollständig zu lösen, müssten wir für jeden Screenshot eine eigene Testsuite erstellen. Selbst unter Berücksichtigung der Optimierung des Ladens der Story sah es in Bezug auf die Geschwindigkeit nicht zu optimistisch aus, und wir dachten darüber nach, die Testmaschine zu wechseln.
Eigentlich, warum Hermine? Momentan ist das Gemini-Repository als veraltet markiert und früher oder später mussten wir irgendwohin „umziehen“. Die Struktur der Hermine-Konfigurationsdatei ist identisch mit der Struktur der Gemini-Konfigurationsdatei und wir konnten diese Konfiguration wiederverwenden. Zwillinge und Hermine Plugins sind ebenfalls üblich. Darüber hinaus konnten wir die Testinfrastruktur - virtuelle Maschinen und eingesetztes Selen-Grid - wiederverwenden.
Im Gegensatz zu Gemini ist Hermine nicht nur als Werkzeug für Regressionstests des Layouts positioniert. Die Funktionen zur Browser-Manipulation sind viel umfangreicher und nur durch die Funktionen von
Webdriver IO eingeschränkt . In Kombination mit
Mokka eignet sich diese Engine eher für Funktionstests (Simulation von Benutzeraktionen) als für Layouttests. Für Regressionstests des Layouts stellt Hermine nur die assertView () -Methode zur Verfügung, die einen Screenshot einer Browserseite mit einer Referenz vergleicht. Der Screenshot kann auf den Bereich beschränkt werden, der mit CSS-Selektoren festgelegt wurde.
In unserem Fall würde der Test für jede einzelne Geschichte ungefähr so aussehen:
Mit der waitForVisible () -Methode können Sie trotz ihres Namens nicht nur das Erscheinungsbild, sondern auch das Ausblenden des Elements erwarten, wenn Sie den zweiten Parameter auf true setzen. Hier warten wir damit, bis ein Markerelement ausgeblendet ist. Dies zeigt an, dass der Datenschnappschuss noch nicht geladen ist und die Story noch nicht für einen Screenshot bereit ist.
Wenn Sie versuchen, die waitForVisible () -Methode in der Hermine-Dokumentation zu finden, werden Sie nichts finden. Tatsache ist, dass die waitForVisible ()
-Methode die Webdriver-IO-API-Methode ist . Auch die url () -Methode. Bei der url () -Methode übergeben wir die Frame-Adresse einer bestimmten Story, nicht das gesamte Storybook. Erstens ist dies erforderlich, damit die Story-Liste nicht im Browserfenster angezeigt wird - wir müssen sie nicht testen. Zweitens können wir bei Bedarf auf DOM-Elemente innerhalb des Frames zugreifen (mit den webdriverIO-Methoden können Sie JavaScript-Code in einem Browserkontext ausführen).
Um das Schreiben von Tests zu vereinfachen, haben wir unseren Wrapper über Mokka-Tests gemacht. Tatsache ist, dass die detaillierte Ausarbeitung von Testfällen für Regressionstests keinen besonderen Sinn macht. Alle Testfälle sind gleich - 'sollte gleich Etalon sein'. Nun, ich möchte auch nicht den Code für das Warten auf das Laden von Daten in jedem Test duplizieren. Daher wird die gleiche Arbeit für alle „Affentests“ an die Wrapper-Funktion delegiert, und die Tests selbst werden deklarativ (fast) geschrieben. Hier ist der Text dieser Funktion:
create-test-suite.js const themes = [ 'default', 'dark' ]; const rootClassName = '.explorer'; const loadingStubClassName = '.loading-stub'; const timeout = 2000; function createTestSuite(testSuite) { const { name, storyName, browsers, testCases, selector } = testSuite;
Ein Objekt, das die Testsuite beschreibt, wird an den Eingang der Funktion übergeben. Jede Testsuite wird gemäß dem folgenden Szenario erstellt: Wir erstellen einen Screenshot des Hauptlayouts (z. B. einen Bereich einer Entitätskarte oder einen Bereich einer Entitätsliste), drücken dann programmgesteuert Schaltflächen, die zum Erscheinen anderer Elemente führen können (z. B. Popup-Bedienfelder oder Kontextmenüs), und erstellen einen Screenshot »Jedes dieser Elemente separat. Daher simulieren wir Benutzeraktionen im Browser, jedoch nicht mit dem Ziel, eine Art Geschäftsszenario zu testen, sondern lediglich die maximal mögliche Anzahl visueller Komponenten zu erfassen. Darüber hinaus ist die Duplizierung visueller Informationen in den Screenshots minimal, weil Screenshots werden "punktweise" mit Selektoren aufgenommen. Beispiel für eine Testsuite:
Bestimmung der Deckung
Also, wir haben die Geschwindigkeit und Redundanz herausgefunden, es bleibt die Effektivität unserer Tests herauszufinden, dh den Grad der Abdeckung des Codes mit Tests zu bestimmen (hier mit Code meine ich CSS-Stylesheets).
Für Teststories haben wir empirisch die kompliziertesten Karten, Listen und anderen Elemente ausgewählt, um mit einem Screenshot so viele Stile wie möglich abzudecken. Um beispielsweise eine Entity-Karte zu testen, wurden Karten mit einer großen Anzahl verschiedener Arten von Steuerelementen (Text, Nummer, Übertragungen, Daten, Raster usw.) ausgewählt. Karten für verschiedene Arten von Entitäten haben ihre eigenen Besonderheiten. Beispielsweise kann ein Bereich mit einer Liste von Dokumentversionen von einer Dokumentkarte angezeigt werden, und die Korrespondenz zu dieser Aufgabe wird auf der Aufgabenkarte angezeigt. Dementsprechend wurden für jeden Entitätstyp eine eigene Story und eine Reihe typenspezifischer Tests usw. erstellt. Am Ende stellten wir uns vor, dass alles mit Tests bedeckt zu sein schien, aber wir wollten ein bisschen mehr Selbstvertrauen als „mögen“.
Um die Abdeckung in Chrome DevTools zu bewerten, gibt es ein Tool mit dem Namen Abdeckung, das für diesen Fall sehr gut geeignet ist:
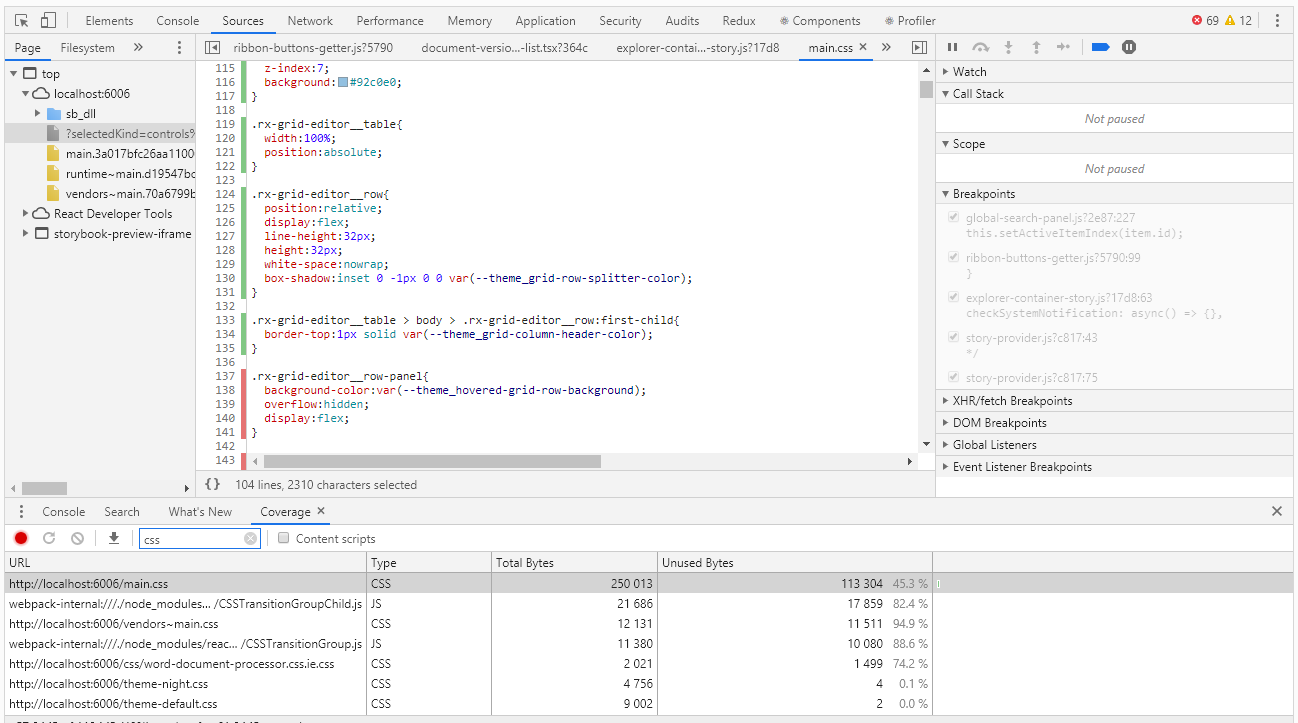
Mit Coverage können Sie bestimmen, welche Stile oder welcher js-Code beim Arbeiten mit der Browserseite verwendet wurden. Der Bericht über die Verwendung von grünen Streifen gibt den verwendeten Code an, rot - nicht verwendet. Und alles wäre in Ordnung, wenn wir eine Anwendung der Ebene "Hallo, Welt" hätten, aber was tun, wenn wir Tausende von Codezeilen haben? Coverage-Entwickler haben dies gut verstanden und konnten den Bericht in eine Datei exportieren, die bereits programmgesteuert bearbeitet werden kann.
Ich muss gleich sagen, dass wir bisher keine Möglichkeit gefunden haben, den Abdeckungsgrad automatisch zu erfassen. Theoretisch kann dies mit dem Headless-Browser des Puppenspielers durchgeführt werden, aber der Puppenspieler arbeitet nicht unter der Kontrolle von Selen, was bedeutet, dass wir den Code unserer Tests nicht wiederverwenden können. Lassen Sie uns dieses äußerst interessante Thema überspringen und mit Stiften arbeiten.
Nachdem wir die Tests im manuellen Modus ausgeführt haben, erhalten wir einen Abdeckungsbericht, der eine JSON-Datei ist. Im Bericht für jedes CSS, JS, TS, etc. Die Datei gibt den Text (in einer Zeile) und die Intervalle des in diesem Text verwendeten Codes (in Form von Zeichenindizes dieser Zeile) an. Unten ist ein Teil des Berichts:
coverage.json [ { "url": "http://localhost:6006/theme-default.css", "ranges": [ { "start": 0, "end": 8127 } ], "text": "... --theme_primary-accent: #5b9bd5;\r\n --theme_primary-light: #ffffff;\r\n --theme_primary: #f4f4f4;\r\n ..." }, { "url": "http://localhost:6006/main.css", "ranges": [ { "start": 0, "end": 610 }, { "start": 728, "end": 754 } ] "text": "... \r\n line-height:1;\r\n}\r\n\r\nol, ul{\r\n list-style:none;\r\n}\r\n\r\nblockquote, q..." ]
Auf den ersten Blick ist es nicht schwierig, nicht verwendete CSS-Selektoren zu finden. Aber was tun mit diesen Informationen? In der Tat müssen wir letztendlich keine spezifischen Selektoren finden, sondern Komponenten, die wir vergessen haben, mit Tests abzudecken. Stile einer Komponente können von mehr als einem Dutzend Selektoren festgelegt werden. Basierend auf den Ergebnissen der Analyse des Berichts erhalten wir Hunderte nicht verwendeter Selektoren, und wenn Sie sich mit jedem von ihnen befassen, können Sie viel Zeit verlieren.
Hier helfen uns reguläre Ausdrücke. Natürlich funktionieren sie nur, wenn die Namenskonventionen für CSS-Klassen erfüllt sind (in unserem Code werden CSS-Klassen gemäß der BEM-Methode benannt - blockname_name_name_modifier). Mithilfe von regulären Ausdrücken berechnen wir die eindeutigen Werte der Blocknamen, die den Komponenten nicht mehr schwer zuzuordnen sind. Natürlich interessieren uns auch Elemente und Modifikatoren, aber nicht an erster Stelle müssen wir uns zuerst mit einem größeren „Fisch“ befassen. Unten finden Sie ein Skript zum Verarbeiten eines Abdeckungsberichts
coverage.js const modules = require('./coverage.json').filter(e => e.url.endsWith('.css')); function processRange(module, rangeStart, rangeEnd, isUsed) { const rules = module.text.slice(rangeStart, rangeEnd); if (rules) { const regex = /^\.([^\d{:,)_ ]+-?)+/gm; const classNames = rules.match(regex); classNames && classNames.forEach(name => selectors[name] = selectors[name] || isUsed); } } let previousEnd, selectors = {}; modules.forEach(module => { previousEnd = 0; for (const range of module.ranges) { processRange(module, previousEnd, range.start, false); processRange(module, range.start, range.end, true); previousEnd = range.end; } processRange(module, previousEnd, module.length, false); }); console.log('className;isUsed'); Object.keys(selectors).sort().forEach(s => { console.log(`${s};${selectors[s]}`); });
Wir führen das Skript aus, indem wir zuerst die aus Chrome DevTools exportierte Datei coverage.json platzieren und den Auspuff in eine CSV-Datei schreiben:
node coverage.js> coverage.csvSie können diese Datei mit Excel öffnen und die Daten analysieren, einschließlich der Bestimmung des Prozentsatzes der Codeabdeckung durch Tests.

Anstelle eines Lebenslaufs
Die Verwendung des Storybooks als Grundlage für visuelle Tests hat sich voll und ganz bewährt - wir haben einen ausreichenden Grad an Abdeckung des CSS-Codes mit Tests mit einer relativ geringen Anzahl von Storys und minimalen Kosten für die Erstellung neuer.
Durch die Umstellung auf eine neue Engine konnten wir doppelte visuelle Informationen in Screenshots vermeiden, was die Unterstützung bestehender Tests erheblich vereinfachte.
Der Abdeckungsgrad des CSS-Codes ist messbar und wird von Zeit zu Zeit überwacht. Es stellt sich natürlich die große Frage, wie man die Notwendigkeit dieser Kontrolle nicht vergisst und wie man beim Sammeln von Informationen über die Berichterstattung etwas verpasst. Idealerweise möchte ich den Abdeckungsgrad bei jedem Testlauf automatisch messen, damit die Tests bei Erreichen der festgelegten Schwelle fehlerhaft abfallen. Wir werden daran arbeiten, wenn es Neuigkeiten gibt, werde ich es Ihnen auf jeden Fall sagen.