Infa ist nützlich für JS-Entwickler, die die Grundlagen der Arbeit mit Node.js und Event Loop genau verstehen möchten. Sie können den Programmablauf bewusst und flexibler steuern (Web-Server).
Ich habe diesen Artikel auf der Grundlage meines letzten Berichts an Kollegen zusammengestellt.
Am Ende des Artikels finden Sie nützliche Materialien für unabhängige Studien.
Wie ist Node.js. Asynchrone Funktionen
Sehen wir uns diesen Code an: Er demonstriert perfekt die Synchronisation der Codeausführung in Node.js. Irgendwo auf GitHub wird eine Anfrage gestellt, dann wird eine Datei gelesen und das Ergebnis in der Konsole angezeigt. Was ergibt sich aus diesem Synchroncode?
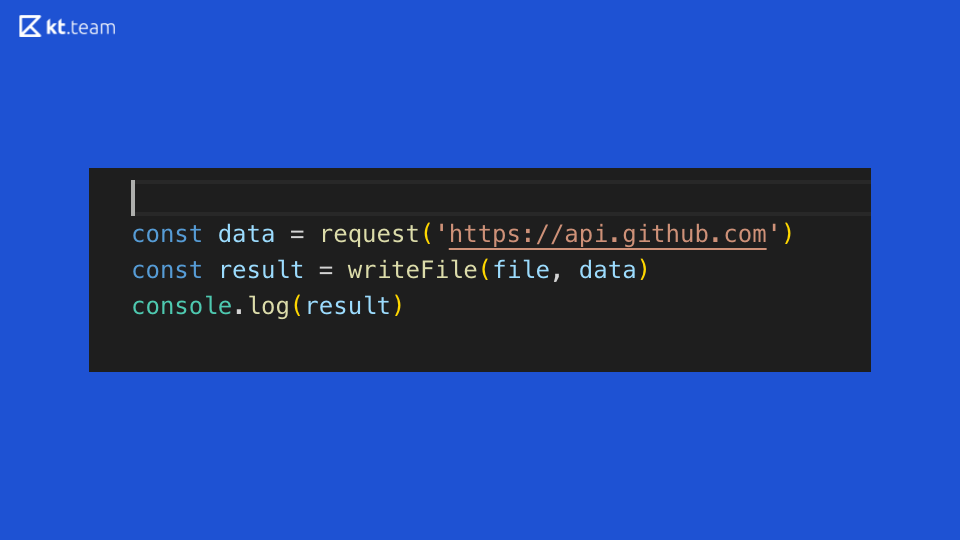
Angenommen, dies ist ein abstrakter Webserver, der Vorgänge auf einem Router ausführt. Wenn auf diesem Router eine eingehende Anfrage eingeht, stellen wir eine weitere Anfrage, lesen die Datei und drucken sie an die Konsole. In der Zeit, die für das Anfordern und Lesen einer Datei aufgewendet wird, wird der Server blockiert, er kann keine anderen eingehenden Anforderungen verarbeiten und führt keine anderen Vorgänge aus.
Welche Möglichkeiten gibt es, um dieses Problem zu lösen?
- Multithreading
- Nicht blockierende E / A
Für die erste Option (Multithreading) gibt es ein gutes Beispiel für den Webserver Apache vs Nginx.
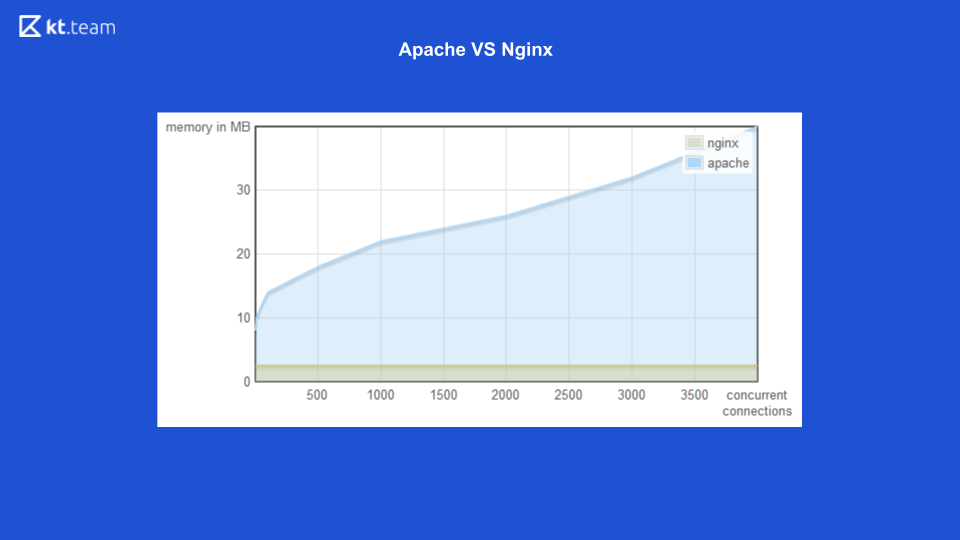
Bisher hat Apache für jede eingehende Anfrage einen Stream ausgelöst: Wie viele Anfragen gab es, die gleiche Anzahl von Threads. Zu diesem Zeitpunkt hatte Nginx den Vorteil, nicht blockierende E / A zu verwenden. Hier können Sie sehen, dass mit zunehmender Anzahl eingehender Anforderungen der von Apache belegte Speicherplatz zunimmt und auf der nächsten Folie die Anzahl der pro Sekunde verarbeiteten Anforderungen mit der Anzahl der Verbindungen für Nginx höher ist.
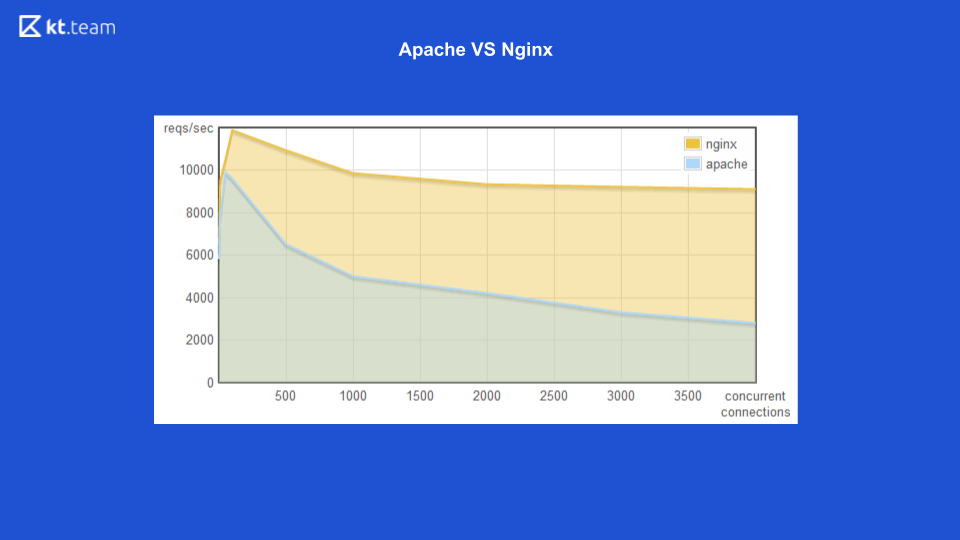
Es wird deutlich, dass nicht blockierende Ein- / Ausgänge effizienter sind.
Dank moderner Betriebssysteme, die diesen Mechanismus bereitstellen - einen Ereignis-Demultiplexer - wird eine nicht blockierende Eingabe / Ausgabe ermöglicht.
Ein Demultiplexer ist ein Mechanismus, der eine Anforderung von einer Anwendung empfängt, registriert und ausführt.
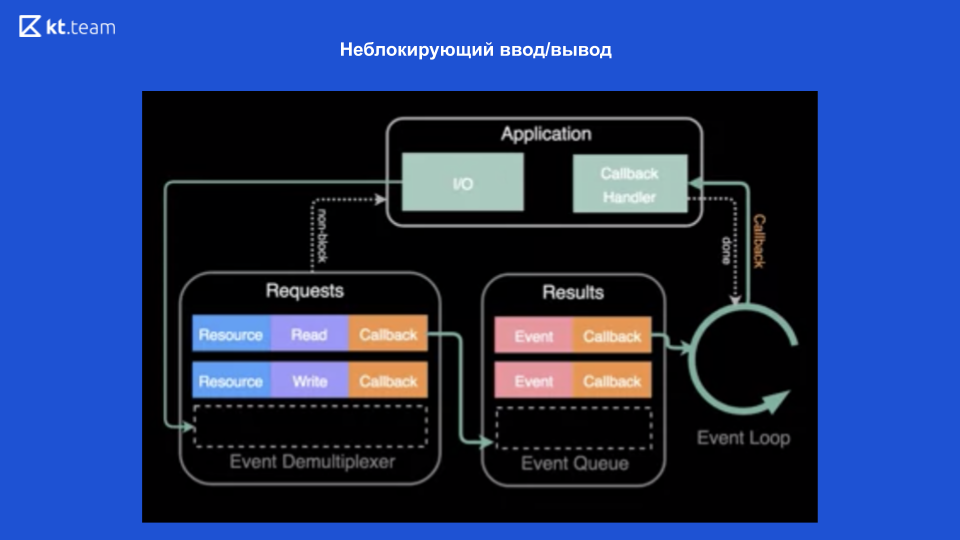
Im oberen Teil des Diagramms ist zu sehen, dass wir eine Anwendung haben und Operationen darin ausgeführt werden (lass es eine Datei lesen). Dazu wird eine Anfrage an den Event-Demultiplexer gestellt, hier wird eine Ressource gesendet (Link zur Datei), die gewünschte Operation und der Rückruf. Der Ereignisdemultiplexer registriert diese Anforderung und gibt die Steuerung direkt an die Anwendung zurück - sie wird also nicht blockiert. Anschließend werden Operationen für die Datei ausgeführt. Anschließend wird beim Lesen der Datei der Rückruf in der Ausführungswarteschlange registriert. Dann verarbeitet die Ereignisschleife nach und nach synchron jeden Rückruf aus dieser Warteschlange. Und gibt dementsprechend das Ergebnis an die Anwendung zurück. Weiter wird (falls nötig) alles nochmal gemacht.
Dank dieser nicht blockierenden E / A kann Node.js also asynchron sein.
Ich werde klarstellen, dass in diesem Fall das Betriebssystem uns nicht blockierende Ein- / Ausgaben zur Verfügung stellt. Zur nicht blockierenden Eingabe / Ausgabe (im Allgemeinen zu Eingabe / Ausgabe-Operationen) schließen wir Netzwerkanforderungen ein und arbeiten mit Dateien.
Dies ist das allgemeine Konzept der nicht blockierenden E / A. Als sich die Gelegenheit ergab, ließ sich Ryan Dahl, ein Entwickler von Node.js, von der Nginx-Erfahrung inspirieren, bei der nicht blockierende E / A verwendet wurden, und beschloss, eine Plattform speziell für Entwickler zu erstellen. Das erste, was er tun musste, war, seine Plattform mit einem Event-Demultiplexer „anzufreunden“. Das Problem war, dass der Demultiplexer in jedem Betriebssystem anders implementiert war und er einen Wrapper schreiben musste, der später als libuv bekannt wurde. Dies ist eine in C geschriebene Bibliothek. Sie bietet eine einzige Schnittstelle für die Arbeit mit diesen Ereignisdemultiplexern.
Funktionen der Libuv-Bibliothek
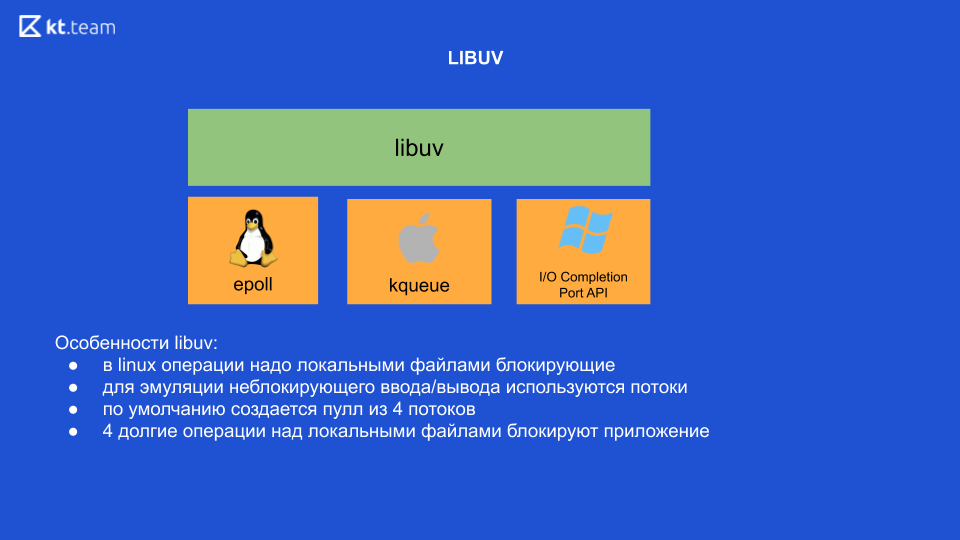
Im Prinzip blockieren momentan unter Linux alle Operationen mit lokalen Dateien. Das heißt, es scheint nicht blockierende Ein- / Ausgaben zu geben, aber genau bei der Arbeit mit lokalen Dateien blockiert der Vorgang immer noch. Deshalb verwendet libuv intern Threads, um nicht blockierende E / A zu emulieren. 4 Threads steigen aus dem Kasten heraus, und hier müssen wir die wichtigste Schlussfolgerung ziehen: Wenn wir 4 schwere Operationen an lokalen Dateien ausführen, werden wir dementsprechend unsere gesamte Anwendung blockieren (es ist unter Linux, andere Betriebssysteme nicht).
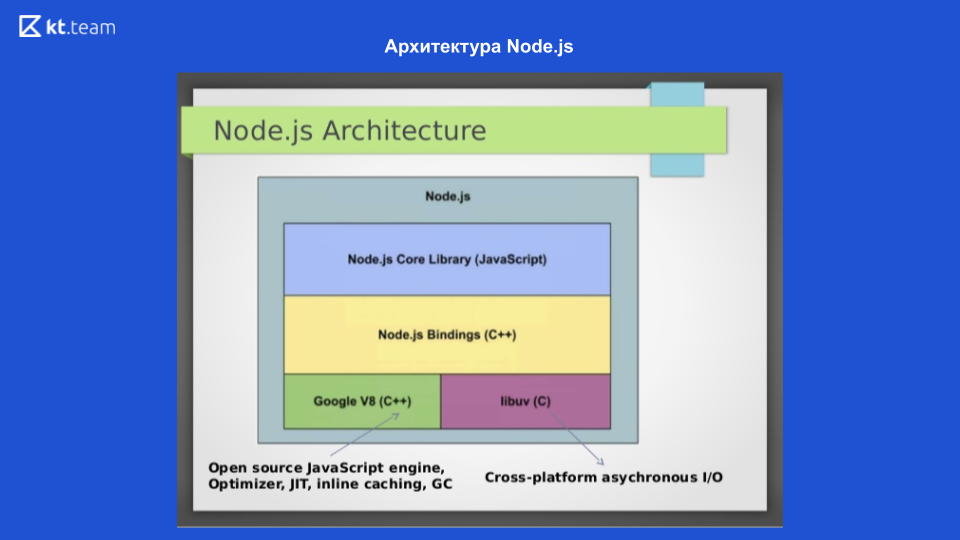
Auf dieser Folie sehen wir die Architektur von Node.js. Für die Interaktion mit dem Betriebssystem wird die in C geschriebene libuv-Bibliothek verwendet. Um JavaScript-Code in Maschinencode zu kompilieren, wird die Google V8-Engine verwendet. Außerdem gibt es eine Node.js-Core-Bibliothek, die Module für die Arbeit mit Netzwerkanforderungen, ein Dateisystem und ein Modul für die Protokollierung enthält. Da dies alles miteinander interagierte, werden Node.js Bindings geschrieben. Diese 4 Komponenten bilden die Struktur von Node.js. Der Event-Loop-Mechanismus selbst befindet sich in libuv.
Ereignisschleife
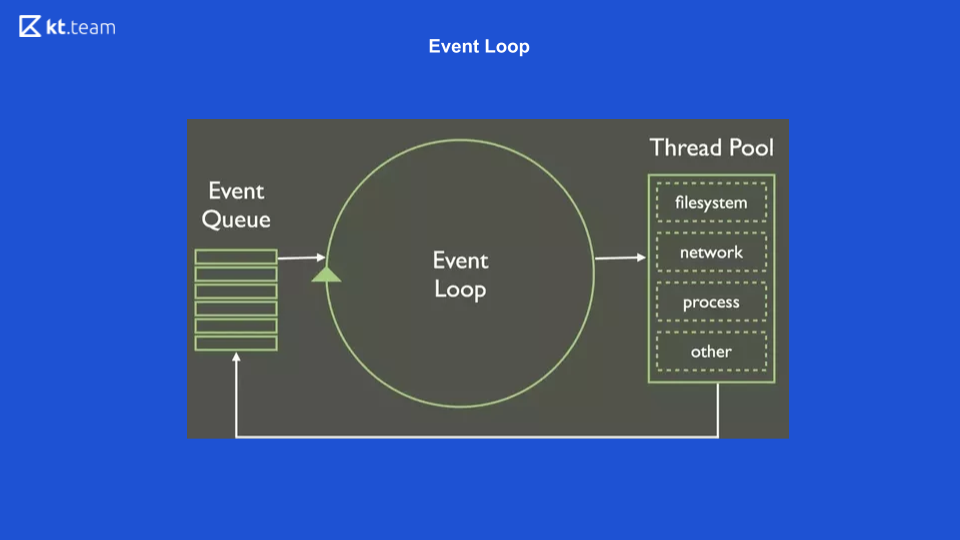
Dies ist die einfachste Darstellung von Event Loop. Es gibt eine bestimmte Warteschlange von Ereignissen, es gibt einen endlosen Zyklus von Ereignissen, die Operationen aus der Warteschlange synchron ausführen und sie weiter verteilen.
Diese Folie zeigt, wie die Ereignisschleife direkt in Node.js aussieht.
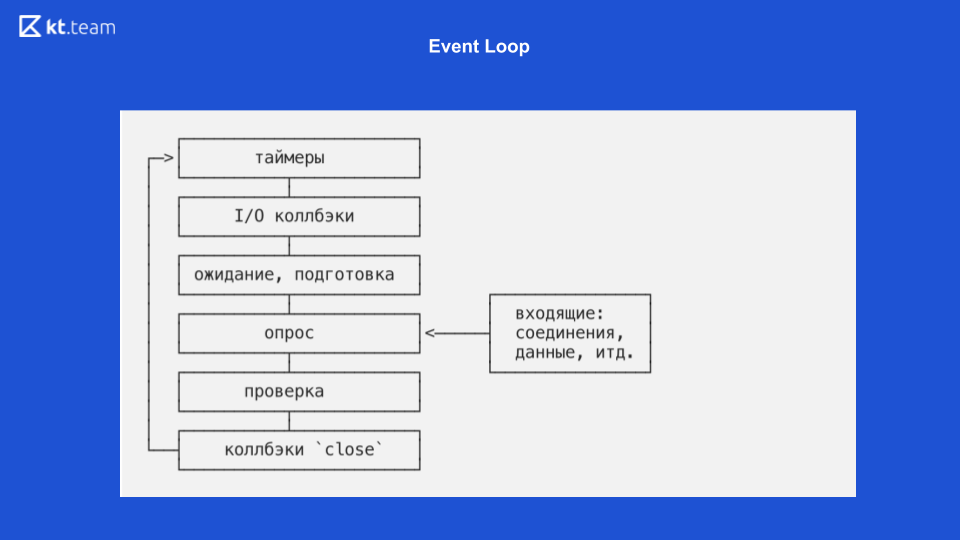
Dort ist die Implementierung interessanter und komplizierter. Im Grunde ist eine Ereignisschleife eine Ereignisschleife und unendlich, solange etwas zu tun ist. Die Ereignisschleife in Node.js ist in mehrere Phasen unterteilt. (Die Phasen von Folie 8 müssen mit dem Quellcode auf Folie 9 verglichen werden.)
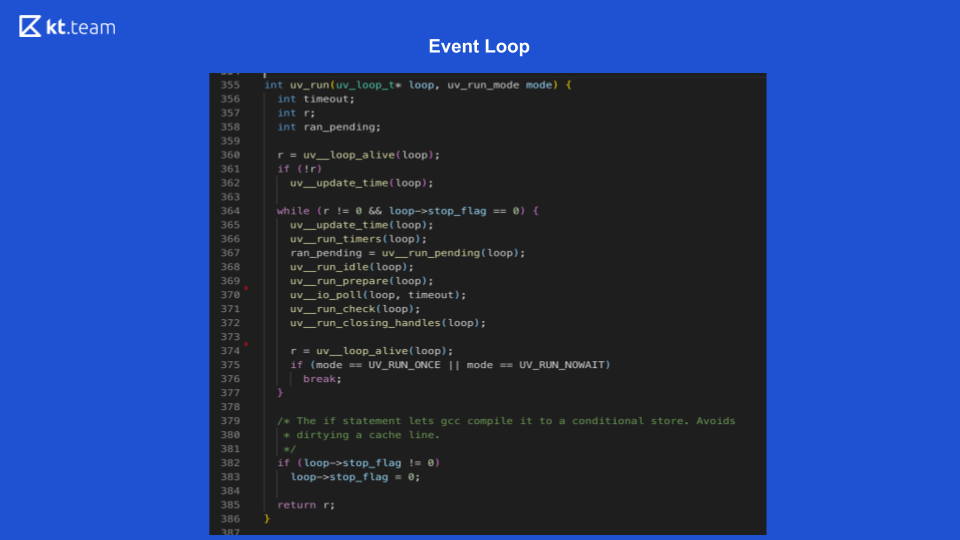
Phase 1 - Timer
Diese Phase wird direkt von Event Loop ausgeführt. (Code-Snippet mit uv_update_time) - hier wird die Zeit, zu der die Event-Schleife zu arbeiten begann, einfach aktualisiert.
uv_run_timers - Bei dieser Methode wird die nächste Timer-Aktion ausgeführt. Es gibt einen bestimmten Stapel, genauer gesagt, eine Reihe von Timern. Dies ist im Wesentlichen dasselbe wie die Warteschlange, in der sich die Timer befinden. Der Timer mit der kürzesten Zeit wird verglichen mit der aktuellen Zeit der Ereignisschleife verwendet, und wenn es Zeit ist, diesen Timer auszuführen, wird sein Rückruf ausgeführt. Es ist erwähnenswert, dass Node.js eine Implementierung von setTimeout hat und es setInterval gibt. Für libuv ist dies im Wesentlichen dasselbe, nur setInterval hat noch ein Wiederholungsflag.
Wenn dieser Timer ein Wiederholungsflag hat, wird er dementsprechend erneut in die Ereigniswarteschlange gestellt und dann auf die gleiche Weise verarbeitet.
Phase 2 - E / A-Rückrufe
Hier müssen wir zum Diagramm über nicht blockierende Ein- / Ausgänge zurückkehren.
Wenn der Ereignisdemultiplexer eine Datei liest und den Rückruf in die Warteschlange stellt, entspricht dies nur der E / A-Rückrufstufe. Hier werden Callbacks für nicht blockierende Ein- / Ausgaben durchgeführt, das sind genau die Funktionen, die nach einer Anforderung an eine Datenbank oder eine andere Ressource oder zum Lesen / Schreiben einer Datei verwendet werden. Sie werden genau in dieser Phase durchgeführt.
In Folie 9 startet die Ausführung der E / A-Rückruffunktion Zeile 367: ran_pending = uv_run_pending (Schleife).
3 Phasen - Warten, Vorbereiten
Dies sind interne Vorgänge für Rückrufe. Tatsächlich können wir die Phase nicht nur indirekt beeinflussen. Es gibt einen process.nextTick, dessen Rückruf möglicherweise versehentlich in der Wartephase der Vorbereitung ausgeführt wird. process.nextTick wird in der aktuellen Phase ausgeführt, d. h., process.nextTick kann in absolut jeder Phase ausgeführt werden. Es gibt kein fertiges Tool, um den Code in der Phase "Warten, Vorbereiten" in Node.js auszuführen.
Auf Folie 9 entsprechen die Zeilen 368, 369 dieser Phase:
uv_run_idle (Schleife) - warte;
uv_run_prepare (loop) - Vorbereitung.
4 Phasen - Übersicht
Hier wird unser gesamter Code ausgeführt, den wir in JS schreiben. Zunächst werden alle von uns gestellten Anforderungen hier abgerufen, und hier kann Node.js blockiert werden. Wenn eine schwere Rechenoperation hier eintrifft, friert unsere Anwendung zu diesem Zeitpunkt möglicherweise ein und wartet, bis diese Operation abgeschlossen ist.
Auf Folie 9 befindet sich die Abfragefunktion in Zeile 370: uv_io_poll (Schleife, Zeitüberschreitung).
5 Phasen - Check
In Node.js gibt es einen setImmediate-Timer, dessen Rückrufe in dieser Phase ausgeführt werden.
Im Quellcode ist dies Zeile 371: uv_run_check (Schleife).
6 phase (last) - Rückrufereignisse werden geschlossen
Beispielsweise muss ein Web-Socket die Verbindung trennen, in dieser Phase wird ein Rückruf dieses Ereignisses aufgerufen.
Im Quellcode ist dies Zeile 372: uv_run_closing_handless (loop).
Und am Ende ist Event Loop Node.js wie folgt
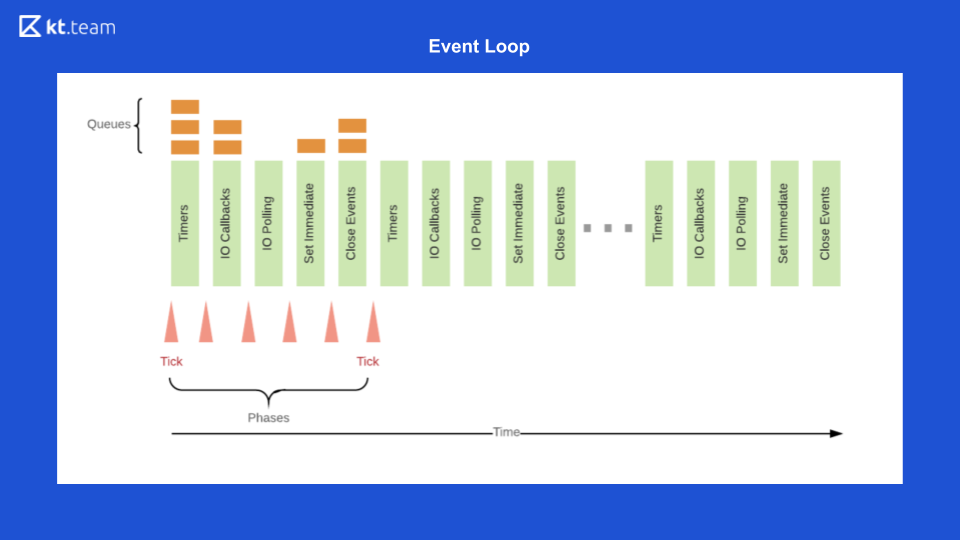
Zuerst wird in der Zeitgeberwarteschlange der Zeitgeber ausgeführt, dessen Periode sich nähert.
Dann werden I / O-Callbacks ausgeführt.
Dann ist der Code die Basis, dann setImmediate und die Close-Ereignisse.
Danach wiederholt sich alles im Kreis. Um dies zu demonstrieren, öffne ich den Code. Wie wird es aufgeführt?
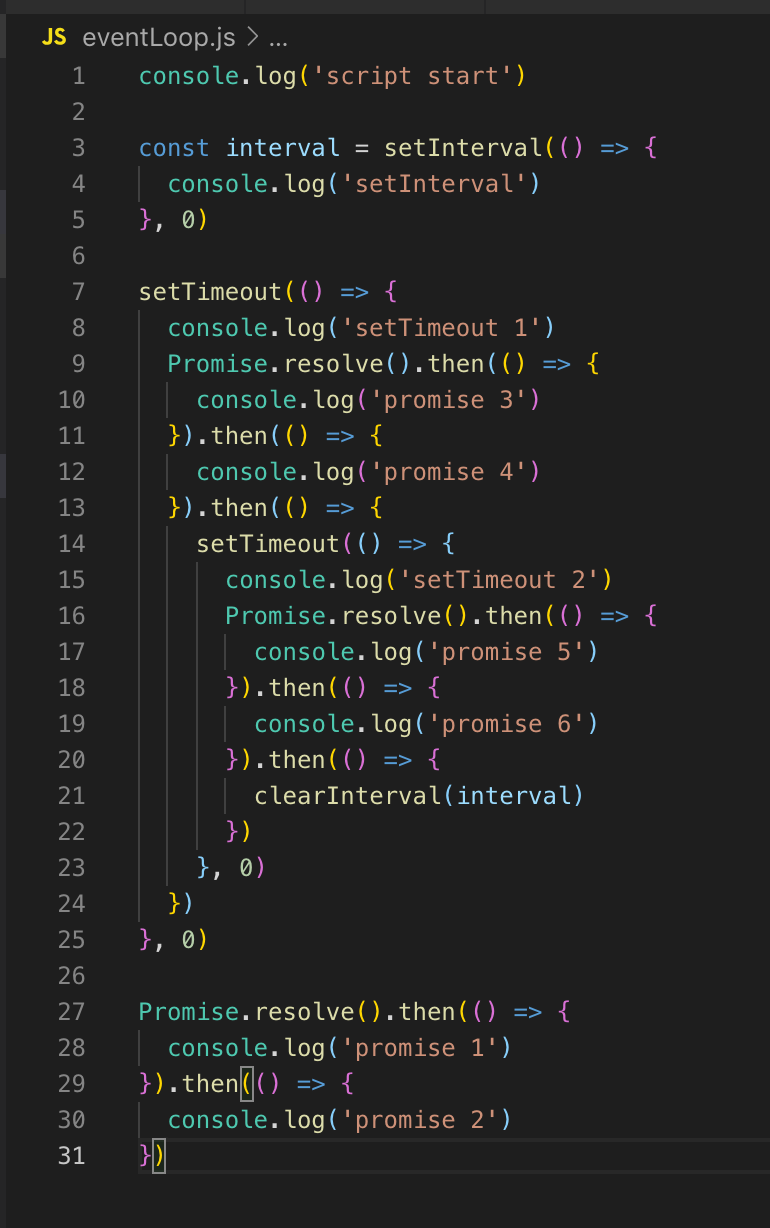
Wir haben keine Timer in der Schlange, daher wird die Event-Schleife fortgesetzt. Da es auch keine I / O-Rückrufe gibt, gehen wir sofort in die Polling-Phase. Der gesamte Code, der sich hier befindet, wird anfänglich in der Abfragephase ausgeführt. Deshalb drucken wir zuerst script_start, setInterval wird in die Timer-Warteschlange gestellt (nicht ausgeführt, nur platziert). setTimeout wird ebenfalls in die Timer-Warteschlange gestellt, und dann werden die Versprechen ausgeführt: Zuerst Versprechen 1 und dann Versprechen 2.
Im nächsten Tick (Event-Loop) kehren wir zur Timer-Stufe zurück, hier in der Queue befinden sich bereits 2 Timer: setInterval und setTimeout. Sie haben beide eine Verzögerung von 0 bzw. sind zur Ausführung bereit.
SetInterval wird ausgeführt (Ausgabe an die Konsole), dann setTimeout 1. Es gibt keine nicht blockierenden E / A-Rückrufe, dann wird eine Abfragephase durchgeführt, Versprechen 3 und Versprechen 4 werden in der Konsole angezeigt.
Als nächstes wird der setTimeout-Timer protokolliert. Dies beendet den Tick, gehe zum nächsten Tick. Es gibt wieder Timer, die Ausgabe an die Konsole lautet setInterval und setTimeout 2, dann werden Versprechen 5 und Versprechen 6 angezeigt.
Wir haben Event Loop überprüft und können nun detaillierter auf Multithreading eingehen.
Threading - worker_threads-Modul
Threading ist in Node.js dank des Moduls worker_threads in Version 10.5 erschienen. Und in der 10. Version wurde es ausschließlich mit dem - experimental-worker-Schlüssel gestartet, und ab der 11. Version war es möglich, ohne diesen zu starten.
Node.js hat auch ein Cluster-Modul, aber es löst keine Threads aus - es löst mehrere weitere Prozesse aus. Die Skalierbarkeit von Anwendungen ist das Hauptziel.
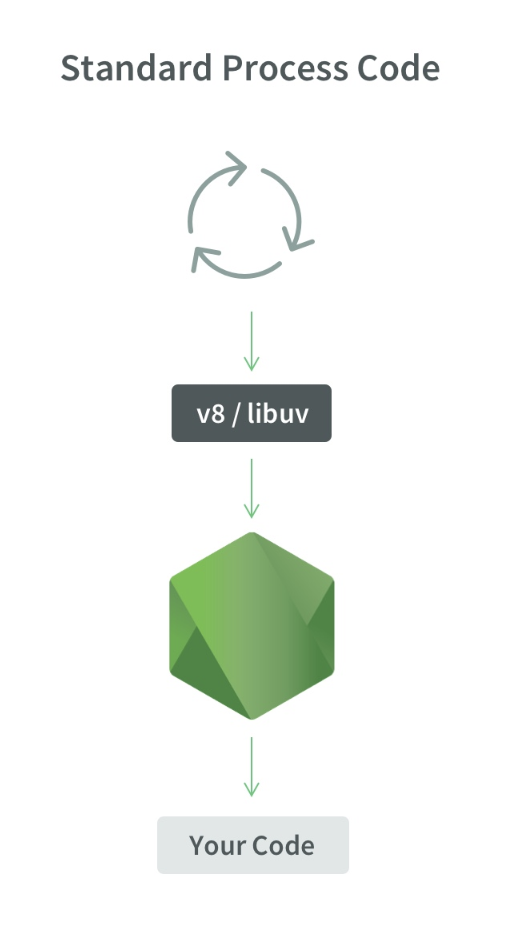
Wie sieht ein Prozess aus:
1 Node.js-Prozess, 1 Thread, 1 Ereignisschleife, 1 V8-Engine und libuv.
Wenn wir X-Threads starten, sieht das so aus:
1 Node.js-Prozess, X Threads, X Event Loops, X V8-Engines und X libuv.
Schematisch sieht es so aus
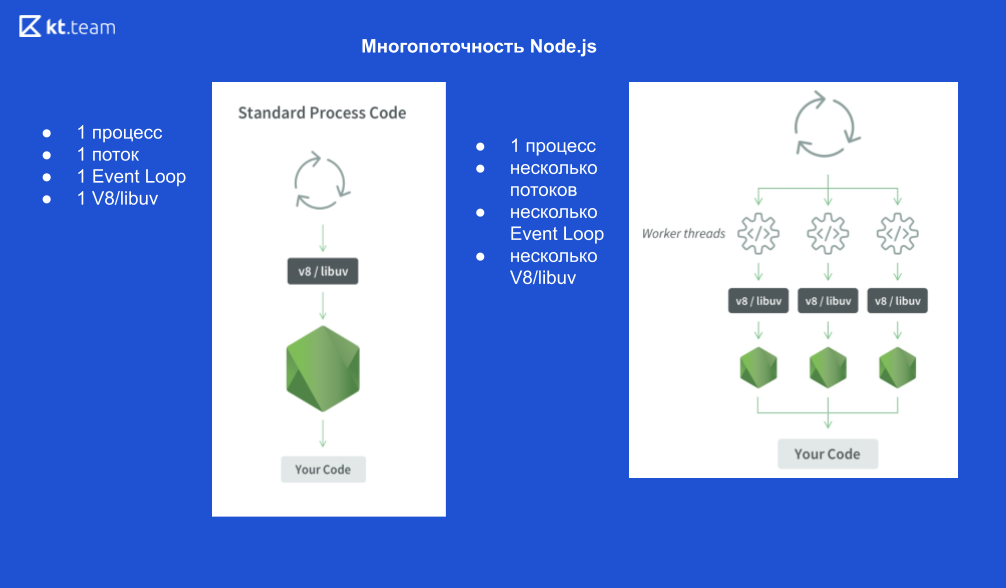
Nehmen wir ein Beispiel.
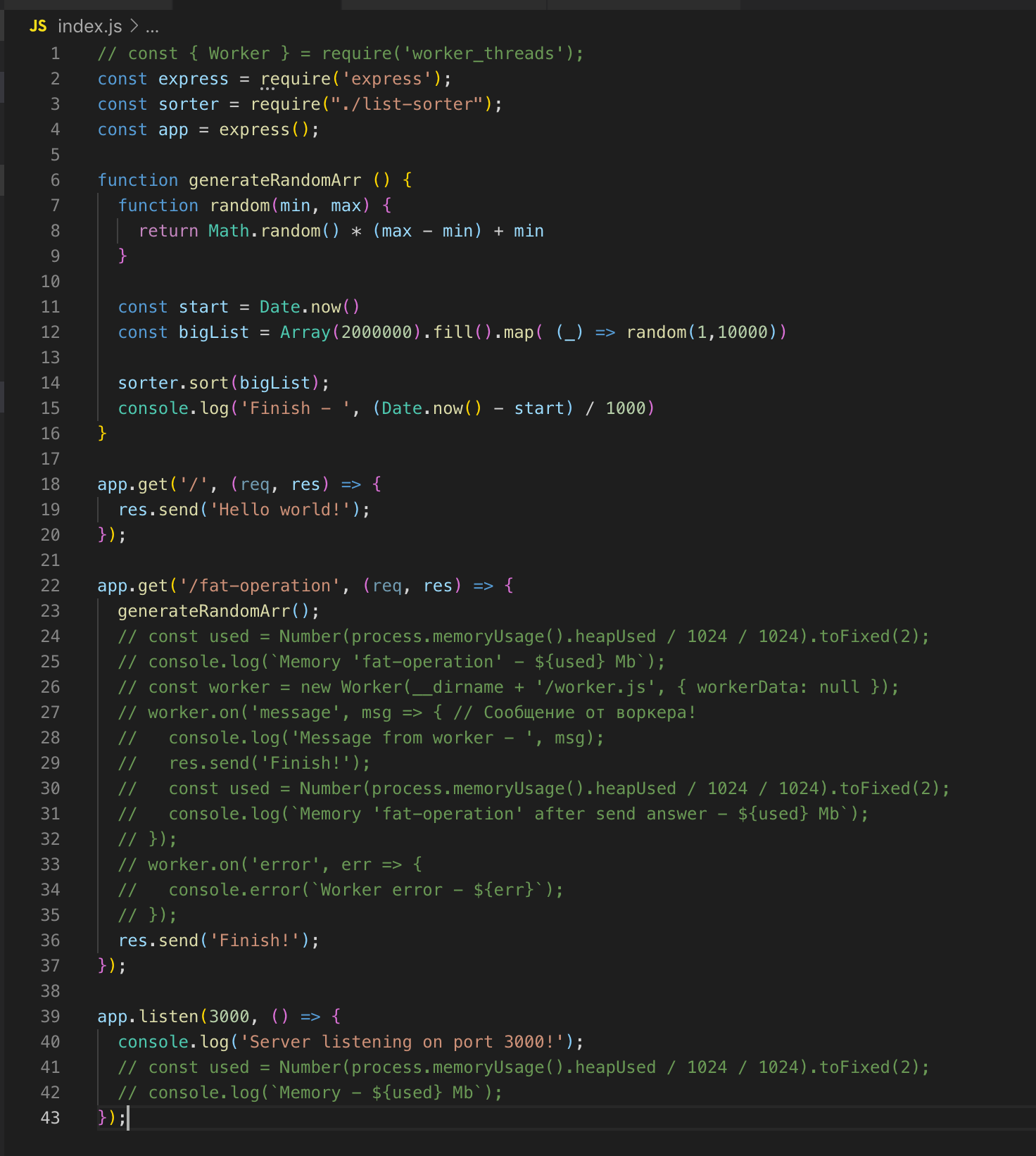
Der einfachste Webserver unter Express. Es gibt 2 Wege - / und / Fettoperation.
Es gibt auch eine generateRandomArr () - Funktion. Sie füllt das Array mit zwei Millionen Datensätzen und sortiert es. Starten wir den Server.
Wir bitten um / Fettoperation. Und in dem Moment, in dem die Sortierung des Arrays ausgeführt wird, senden wir eine weitere Anfrage an route /, aber um die Antwort zu erhalten, müssen wir warten, bis das Array sortiert ist. Dies ist eine klassische Single-Thread-Implementierung. Jetzt verbinden wir das worker_threads-Modul.
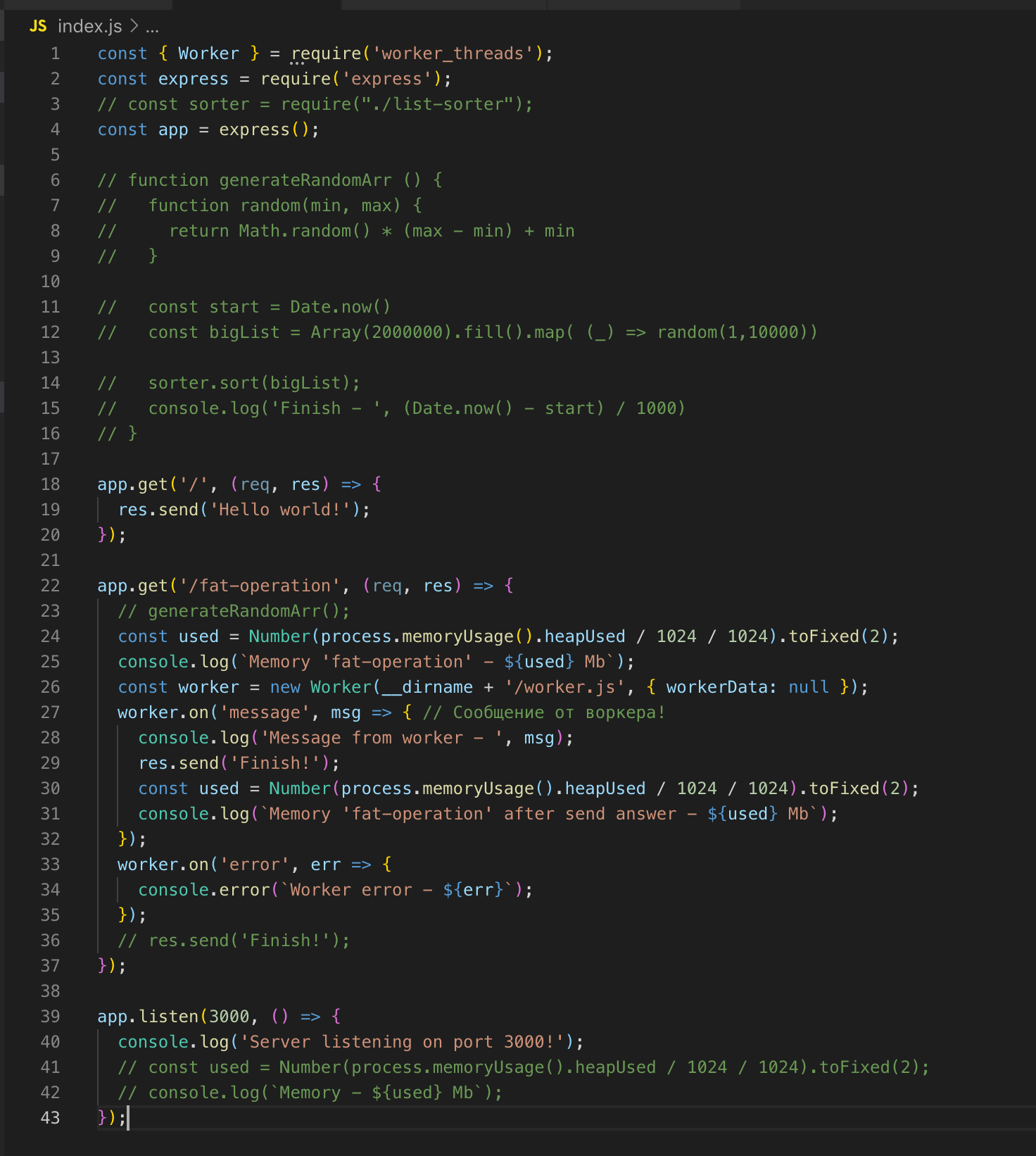
Wir stellen eine Anfrage an / fat-operation und dann - an /, worauf wir sofort die Antwort bekommen - Hallo Welt!
Für die Sortierung des Arrays haben wir einen separaten Thread mit einer eigenen Instanz von Event Loop ausgelöst, der die Ausführung des Codes im Hauptthread nicht beeinflusst.
Ein Thread wird "zerstört", wenn keine Operationen ausgeführt werden müssen.
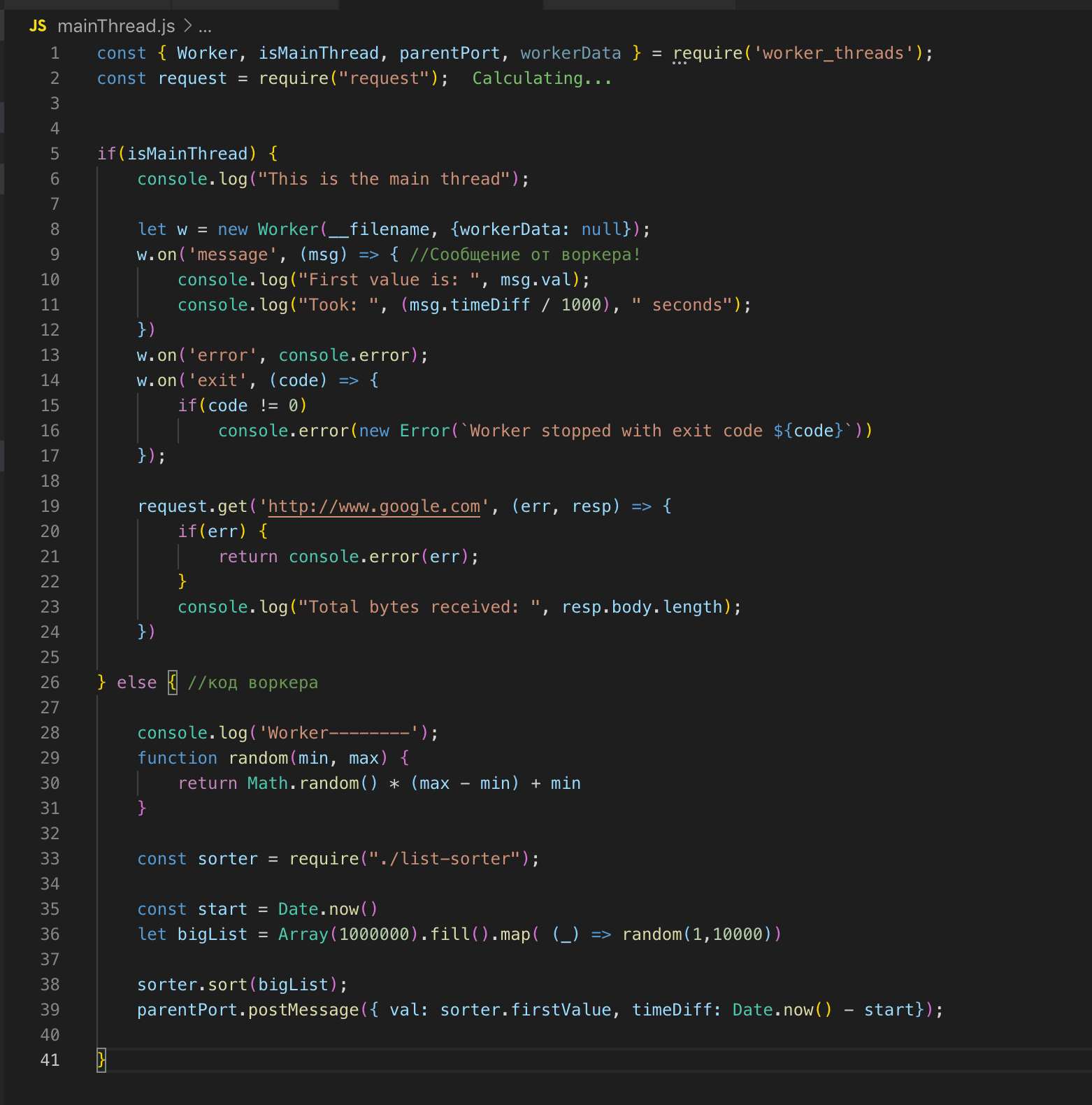
Wir schauen uns den Quellcode an. Wir registrieren den Arbeiter in Zeile 26 und leiten die Daten bei Bedarf an ihn weiter. In diesem Fall sende ich nichts. Und dann abonnieren wir Ereignisse: einen Fehler und eine Meldung. Im Worker wird die Funktion aufgerufen, ein Array von zwei Millionen Datensätzen wird sortiert. Sobald es sortiert ist, senden wir das Ergebnis über post_message an den Hauptstream ok.
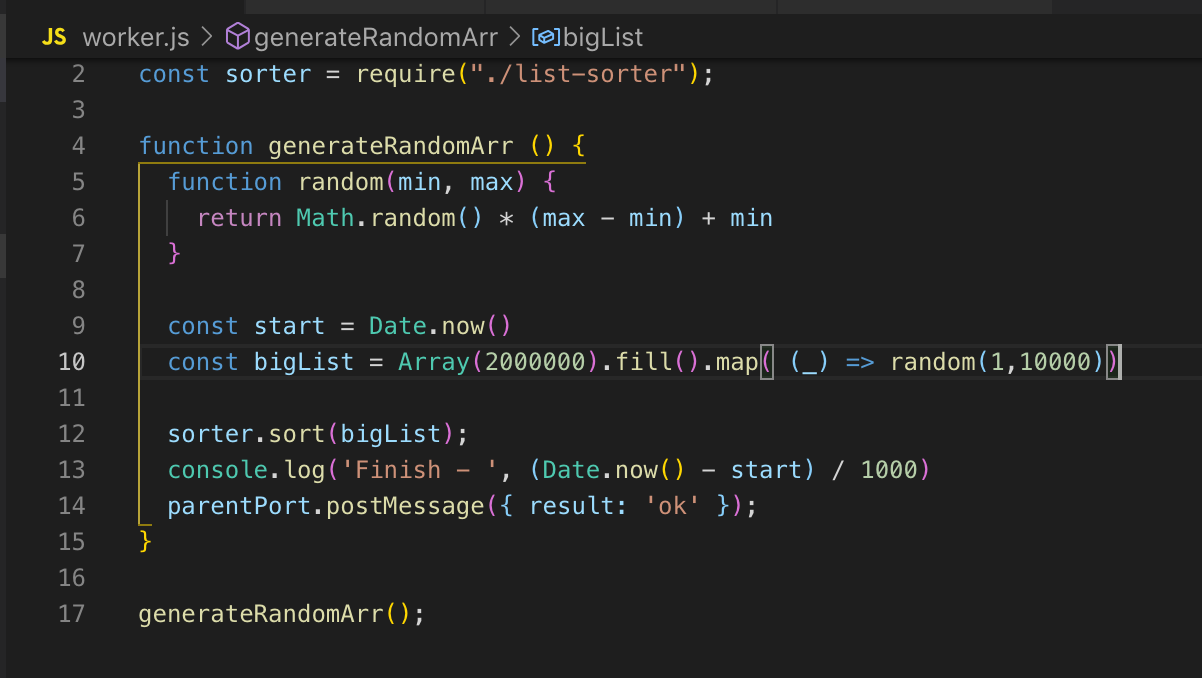
Im Haupt-Thread fangen wir diese Nachricht ab und senden das Ergebnis zum Abschluss. Der Worker und der Haupt-Thread haben einen gemeinsamen Speicher, sodass wir Zugriff auf globale Variablen des gesamten Prozesses haben. Wenn wir Daten vom Hauptstream an den Worker übertragen, erhält der Worker nur eine Kopie.
Wir können den Haupt- und den Worker-Stream in einer Datei beschreiben. Das worker_threads-Modul bietet eine API, über die wir bestimmen können, in welchem Thread der Code gerade ausgeführt wird.
Ich teile Links zu nützlichen Ressourcen und einen Link zur Präsentation von Ryan Dahl, als er den Event Loop präsentierte (interessant zu sehen).
Ereignisschleife
- Übersetzung eines Artikels aus der Dokumentation von Node.js
- https://blog.risingstack.com/node-js-at-scale-understanding-node-js-event-loop/
- https://habr.com/de/post/336498/
Worker_threads
- https://nodejs.org/api/worker_threads.html#worker_threads_worker_workerdata - API
- https://habr.com/ru/company/ruvds/blog/415659/
- https://nodesource.com/blog/worker-threads-nodejs/
- Originalfolien aus Ryan Dahls Präsentation (über VPN)