Erster Teil, ergänzt.
Cotans, hallo.
Ich bin Sasha und ich gönne mir Neuronen.
Auf Wunsch der Arbeiter sammelte ich endlich meine Gedanken und beschloss, eine Reihe von kurzen und fast schrittweisen Anweisungen zu unterbrechen.
Anweisungen, wie Sie Ihr neuronales Netzwerk von Grund auf trainieren und bereitstellen und sich gleichzeitig mit dem Telegramm-Bot anfreunden.
Anleitung für Dummies wie mich.
Heute werden wir die Architektur unseres neuronalen Netzwerks auswählen, testen und unseren ersten Trainingsdatensatz sammeln.
Wahl der Architektur
Nach dem relativ erfolgreichen Start des
selfie2anime- Bots (unter Verwendung des vorgefertigten
UGATIT- Modells) wollte ich dasselbe tun, aber
meines . Zum Beispiel ein Modell, das Ihre Fotos in Comics verwandelt.
Hier sind einige Beispiele aus meinem
photo2comicsbot , und wir werden etwas Ähnliches tun.



Da das
UGATIT- Modell für meine Grafikkarte zu schwer war, machte ich auf eine ältere, aber weniger unersättliche Analogie aufmerksam -
CycleGANIn dieser Implementierung gibt es mehrere Modellarchitekturen und eine komfortable visuelle Darstellung des Lernprozesses im Browser.
CycleGAN erfordert wie
Architekturen zum Übertragen von Stilen über ein einzelnes Bild keine gepaarten Bilder für das Training. Dies ist wichtig, da wir sonst alle Fotos selbst in Comics neu zeichnen müssten, um ein Trainingsset zu erstellen.
Die Aufgabe, die wir für unseren Algorithmus festlegen, besteht aus zwei Teilen.
Am Ausgang sollten wir ein Bild bekommen, das:
a) ähnlich einem Comic
b) ähnlich dem Originalbild
Punkt "a" kann mit der üblichen GAN implementiert werden, wobei der geschulte Kritiker für "Comicähnlichkeit" verantwortlich sein wird.
Mehr zu GAN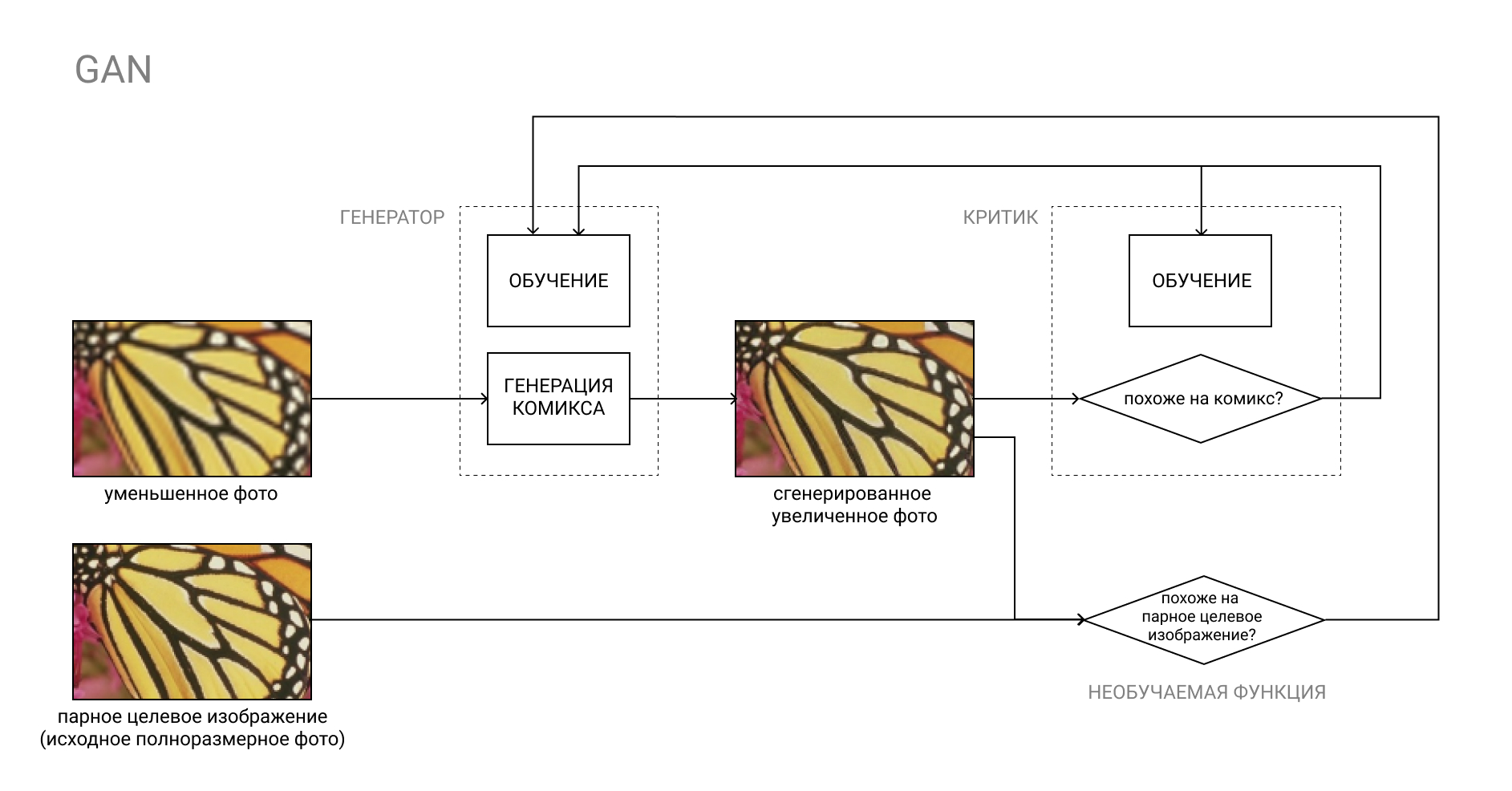
Das GAN (Generative Adversarial Network) ist ein Paar von zwei neuronalen Netzwerken: Generator und Critic.
Der Generator wandelt die Eingabe beispielsweise von einem Foto in ein Comic-Buch um, und der Kritiker vergleicht das resultierende "falsche" Ergebnis mit einem echten Comic-Buch. Der Generator hat die Aufgabe, die Kritiker auszutricksen und umgekehrt.
Während des Lernprozesses lernt der Generator, Comics zu erstellen, die den realen Comics immer ähnlicher werden, und der Kritiker lernt, sie besser voneinander zu unterscheiden.
Der zweite Teil ist etwas komplizierter. Wenn wir Bilder gepaart hätten, bei denen es Fotos in Satz „A“ und in Satz „B“ geben würde, die aber in Comics neu gezeichnet werden (das ist, was wir vom Modell erhalten möchten), könnten wir Nur um das vom Generator erzeugte Ergebnis mit dem gepaarten Bild aus Satz „B“ unseres Trainingssatzes zu vergleichen.
In unserem Fall sind die Mengen "A" und "B" in keiner Weise miteinander verbunden. In Set "A" - zufällige Fotos, in Set "B" - zufällige Comics.
Es ist sinnlos, einen gefälschten Comic mit einem zufälligen Comic aus der Menge „B“ zu vergleichen, da dies zumindest die Funktion des Kritikers dupliziert, ganz zu schweigen von dem unvorhersehbaren Ergebnis.
Hier hilft die CycleGAN-Architektur.
Kurz gesagt, dies ist ein GAN-Paar, bei dem das erste Bild von Kategorie "A" (zum Beispiel ein Foto) in Kategorie "B" (zum Beispiel ein Comic) und das zweite zurück von Kategorie "B" in Kategorie "A" konvertiert wird.
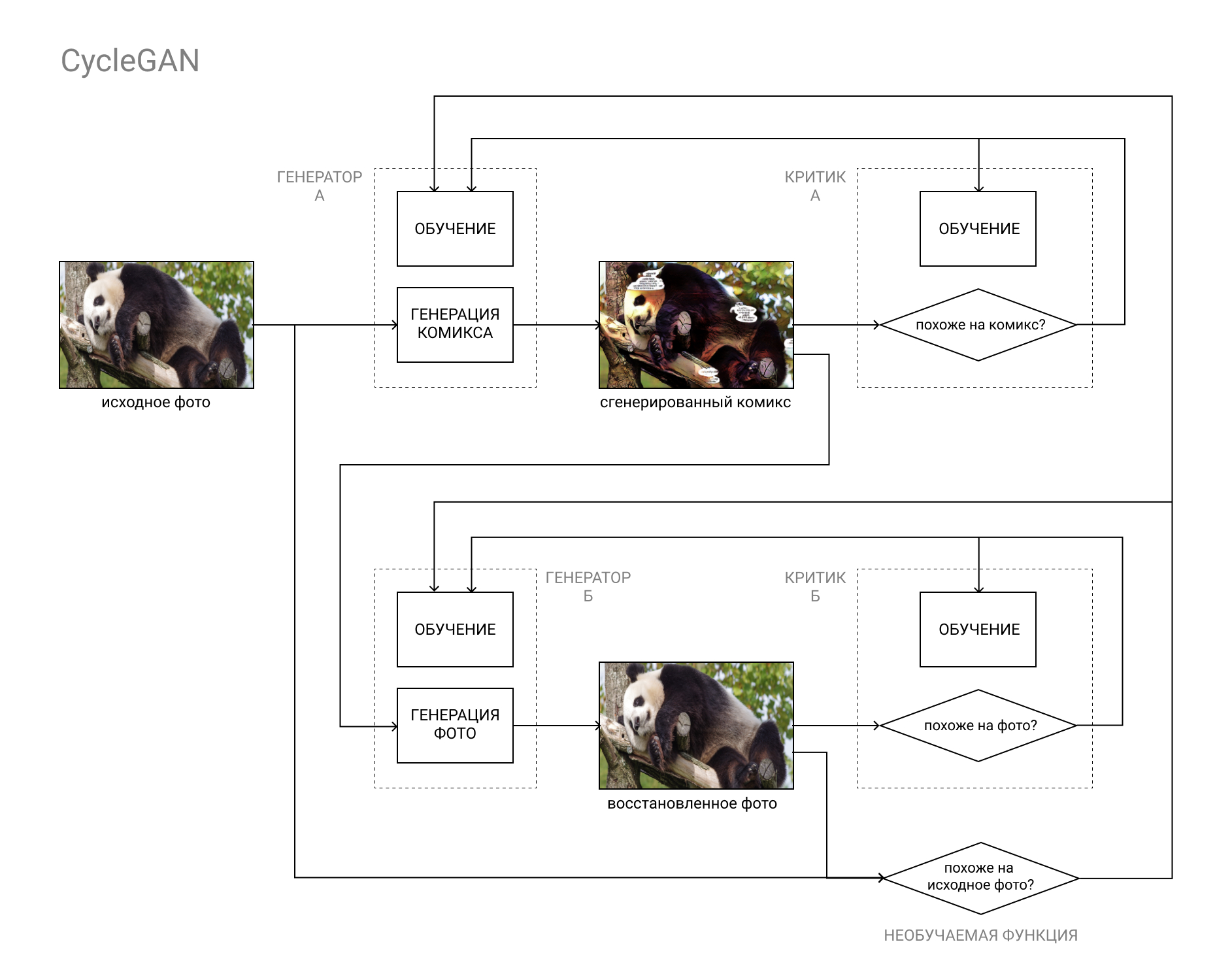
Die Modelle werden sowohl auf der Grundlage des Vergleichs des Originalfotos mit dem wiederhergestellten (als Ergebnis des Zyklus „A“ - „B“ - „A“, „Foto-Comic-Foto“) als auch auf der Grundlage der Daten der Kritiker wie bei einer regulären GAN trainiert.
Dies ermöglicht es, beide Teile unserer Aufgabe zu erfüllen: ein Comic-Buch zu erstellen, das sich nicht von anderen Comics unterscheidet und gleichzeitig dem Originalfoto ähnelt.
Modellinstallation und -überprüfung
Um unseren Listplan umzusetzen, brauchen wir:
- CUDA-fähige Grafikkarte mit 8 GB RAM
- Linux-Betriebssystem
- Miniconda / Anaconda mit Python 3.5+
Grafikkarten mit weniger als 8 GB RAM können auch funktionieren, wenn Sie mit den Einstellungen zaubern. Es wird auch unter Windows funktionieren, aber langsamer hatte ich einen Unterschied von mindestens 1,5-2 mal.
Wenn Sie keine GPU mit CUDA-Unterstützung haben oder zu faul sind, um alles einzurichten, können Sie immer Google Colab verwenden. Wenn es eine ausreichende Anzahl von Personen gibt, die dies möchten, fülle ich das Lernprogramm aus und erkläre, wie die folgenden Schritte in einer Google-Cloud ausgeführt werden.Miniconda kann hier genommen werdenInstallationsanleitungErstellen Sie nach der Installation von Anaconda / Miniconda (im Folgenden als conda bezeichnet) eine neue Umgebung für unsere Experimente und aktivieren Sie diese:
(Windows-Benutzer müssen Anaconda Prompt zuerst über das Startmenü starten.)conda create --name cyclegan conda activate cyclegan
Jetzt werden alle Pakete in der aktiven Umgebung installiert, ohne den Rest der Umgebung zu beeinträchtigen. Dies ist praktisch, wenn Sie bestimmte Kombinationen von Versionen verschiedener Pakete benötigen, z. B. wenn Sie den alten Code einer anderen Person verwenden und veraltete Pakete installieren müssen, ohne Ihr Leben und Ihre Hauptarbeitsumgebung zu beeinträchtigen.
Folgen Sie dann einfach den README.MD-Anweisungen der Distribution:
Speichern Sie die CycleGAN-Distribution:
(oder einfach das Archiv von GitHub herunterladen) git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-and-pix2pix
Installieren Sie die erforderlichen Pakete:
conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing conda install pytorch torchvision -c pytorch conda install visdom dominate -c conda-forge
Laden Sie den fertigen Datensatz und das entsprechende Modell herunter:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra bash ./scripts/download_cyclegan_model.sh horse2zebra
Achten Sie darauf, welche Fotos im heruntergeladenen Datensatz enthalten sind.
Wenn Sie die Skriptdateien aus dem vorherigen Absatz öffnen, können Sie feststellen, dass andere vorgefertigte Datensätze und Modelle für diese vorhanden sind.
Testen Sie abschließend das Modell anhand des heruntergeladenen Datensatzes:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
Die Ergebnisse werden im Ordner / results / horse2zebra_pretrained / gespeichert
Trainingsset erstellen
Ein ebenso wichtiger Schritt nach der Auswahl der Architektur des zukünftigen Modells (und der Suche nach einer fertigen Implementierung auf github) ist die Kompilierung eines Datensatzes oder eines Datensatzes, auf dem wir unser Modell trainieren und testen werden.
Fast alles hängt davon ab, welche Daten wir verwenden. Zum Beispiel wurde UGATIT für den selfie2anime- Bot auf weibliche Selfies und weibliche Gesichter von Anime trainiert. Daher benimmt sie sich auf männlichen Fotos zumindest lustig und ersetzt brutale bärtige Männer durch kleine Mädchen mit hohem Kragen. Auf dem Foto hat dein bescheidener Diener erfahren, dass er sich einen Anime ansieht.

Wie Sie bereits verstanden haben, lohnt es sich, die Fotos / Comics auszuwählen, die Sie am Eingang verwenden möchten, und am Ausgang zu erhalten. Planen Sie Selfies zu verarbeiten? Fügen Sie Selfies und Nahaufnahmen von Gesichtern aus Comics, Fotos von Gebäuden hinzu? Fügen Sie Fotos von Gebäuden und Seiten aus Comics mit Gebäuden hinzu.
Als Beispielfotos habe ich
DIV2K und
Urban100 verwendet , die mit Fotos von Google-Stars gewürzt wurden, um die Vielfalt zu verbessern.
Ich nahm Comics aus dem Marvel-Universum, der gesamten Seite, und warf Anzeigen und Ankündigungen aus, bei denen das Bild nicht wie ein Comic aussieht. Ich kann den Link aus offensichtlichen Gründen nicht anhängen, aber auf Anfrage von Marvel Comics können Sie gescannte Optionen auf Ihren Lieblingsseiten mit Comics leicht finden, wenn Sie wissen, was ich meine.
Es ist wichtig, auf die Zeichnung zu achten, sie unterscheidet sich in verschiedenen Serien und in der Farbgebung.

Ich hatte eine Menge Deadpool und Spiderman, so dass die Haut sehr rot wird.
Eine unvollständige Liste anderer öffentlicher Datensätze finden Sie
hier .
Die Ordnerstruktur in unserem Datensatz sollte wie folgt aussehen:
selfie2comics
├── trainA
├── trainB
├── testA
└── testB
trainA - unsere Fotos (ca. 1000 Stück)
testA - einige Fotos für Modelltests (30 Stück reichen aus)
trainB - unsere Comics (ca. 1000 Stück)
testB - comics für tests (30 stück)
Es wird empfohlen, den Datensatz möglichst auf einer SSD abzulegen.
Das ist alles für heute, in der nächsten Ausgabe werden wir damit beginnen, das Modell zu trainieren und die ersten Ergebnisse zu erzielen!
Stellen Sie sicher, dass Sie schreiben, wenn bei Ihnen ein Fehler aufgetreten ist. Dies wird dazu beitragen, die Führung zu verbessern und das Leiden der nachfolgenden Leser zu lindern.
Wenn Sie bereits versucht haben, das Modell zu trainieren, teilen Sie die Ergebnisse in den Kommentaren mit. Bis bald
⇨ Nächster Teil