Je nach Art der Aktivität muss man sich mit Situationen auseinandersetzen, in denen ein Entwickler eine Anfrage schreibt und denkt, "die
Basis ist intelligent, sie kann alles verarbeiten! "
In einigen Fällen (teils aus Unkenntnis der Datenbankfunktionen, teils aus vorzeitigen Optimierungen) führt dieser Ansatz zum Auftreten von „Frankenstein“.
Zuerst werde ich ein Beispiel für eine solche Abfrage geben:
Um die Qualität der Anfrage objektiv zu bewerten, erstellen wir einen beliebigen Datensatz:
CREATE TABLE tbl AS SELECT (random() * 1000)::integer key_a , (random() * 1000)::integer key_b , (random() * 10000)::integer fld1 , (random() * 10000)::integer fld2 FROM generate_series(1, 10000); CREATE INDEX ON tbl(key_a, key_b);
Es stellt sich heraus, dass das
Lesen der Daten selbst
weniger als ein Viertel der gesamten Ausführungszeit für Abfragen in Anspruch genommen
hat :
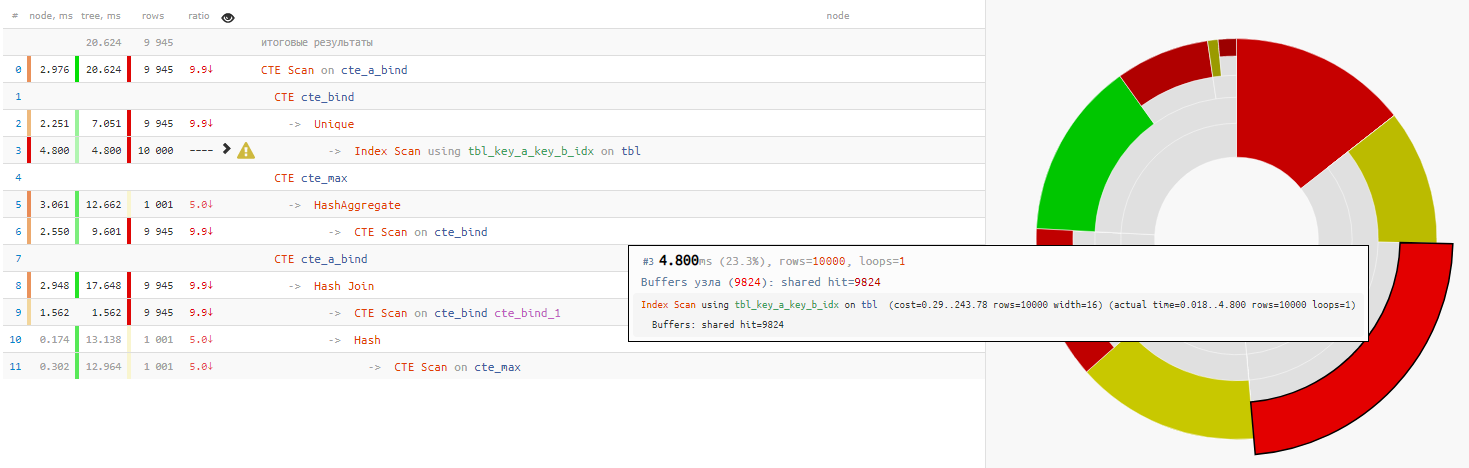 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Mit Knochen zerlegen
Wir werden uns die Anfrage genau ansehen und uns wundern:
- Warum ist WITH RECURSIVE hier, wenn es keine rekursiven CTEs gibt?
- Warum Min / Max-Werte in einem separaten CTE gruppieren, wenn sie dann trotzdem der Originalprobe zugeordnet sind?
+ 25% der Zeit - Warum verwenden Sie am Ende die Wiederholungsablesungen vom vorherigen CTE durch das bedingungslose 'SELECT * FROM'?
+ 14% der Zeit
In diesem Fall hatten wir das große Glück, dass für die Verbindung Hash Join und nicht Nested Loop ausgewählt wurde, da wir dann keinen einzigen CTE-Scan-Pass, sondern 10K erhalten würden!
ein bisschen über CTE ScanHier müssen wir daran erinnern, dass der CTE-Scan ein Analogon zum Seq-Scan ist - das heißt, keine Indizierung, sondern nur eine erschöpfende Suche, die 10K x 0,3 ms = 3000 ms für cte_max- Zyklen oder 1K x 1,5 ms = 1500 ms für cte_bind- Zyklen erfordert !
Was wollten Sie eigentlich als Ergebnis haben?
Ja, normalerweise ist es diese Art von Frage, die er in der 5. Minute der Analyse von "dreistöckigen" Anfragen aufruft.Wir wollten, dass für jedes eindeutige Schlüsselpaar
min / max von key_a aus der Gruppe entfernt wird .
Also werden wir die
Fensterfunktionen dafür verwenden:
SELECT DISTINCT ON(key_a, key_b) key_a a , key_b b , max(fld1) OVER(w) bind_fld1 , min(fld2) OVER(w) bind_fld2 FROM tbl WINDOW w AS (PARTITION BY key_a);
 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Da das Lesen von Daten in beiden Versionen ungefähr 4 bis 5 ms dauert, ist unser gesamter Zeitgewinn von
-32% in seiner reinen Form die
Last, die von der Basis-CPU entfernt wird , wenn eine solche Anforderung ziemlich oft ausgeführt wird.
Im Allgemeinen sollten Sie die Basis nicht zwingen, "rund zu tragen, quadratisch zu rollen".