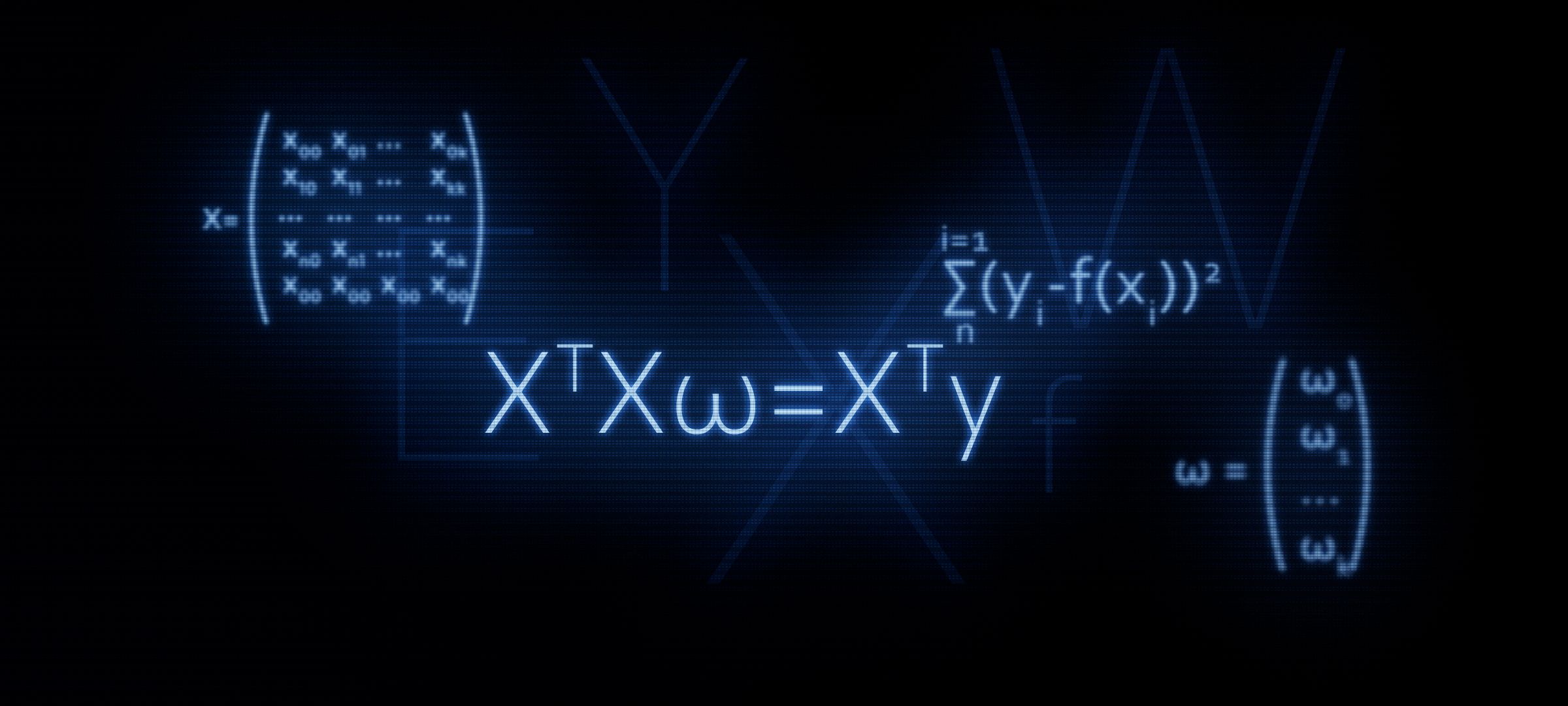
Der Zweck dieses Artikels ist es, unerfahrenen Datenschreibern Unterstützung zu bieten. Im
vorherigen Artikel haben wir drei Methoden zur Lösung der linearen Regressionsgleichung an den Fingern untersucht: analytische Lösung, Gradientenabstieg, stochastischer Gradientenabstieg. Dann haben wir für die analytische Lösung die Formel angewendet
XTX vecw=XT vecy . In diesem Artikel werden wir, wie aus dem Titel hervorgeht, die Verwendung dieser Formel begründen, oder mit anderen Worten, wir werden sie unabhängig ableiten.
Warum es sinnvoll ist, der Formel mehr Aufmerksamkeit zu schenken
XTX vecw=XT vecy ?
Mit der Matrixgleichung beginnt in den meisten Fällen die Bekanntschaft mit der linearen Regression. Gleichzeitig sind detaillierte Berechnungen, wie die Formel abgeleitet wurde, selten.
In Yandex-Kursen für maschinelles Lernen empfehlen die Schüler beispielsweise, wenn sie in die Regularisierung eingeführt werden, die Funktionen aus der
sklearn- Bibliothek zu verwenden, während kein Wort über die Matrixdarstellung des Algorithmus erwähnt wird. In diesem Moment möchten einige Hörer dieses Problem möglicherweise genauer verstehen - schreiben Sie Code, ohne fertige Funktionen zu verwenden. Dazu müssen wir zunächst die Gleichung mit dem Regularisierer in Matrixform darstellen. Dieser Artikel ermöglicht es denen, die solche Fähigkeiten beherrschen möchten. Fangen wir an.
Grundlinie
Ziele
Wir haben eine Reihe von Zielwerten. Das Ziel kann beispielsweise der Preis eines Vermögenswerts sein: Öl, Gold, Weizen, Dollar usw. Gleichzeitig meinen wir mit einer Anzahl von Werten des Zielindikators die Anzahl von Beobachtungen. Solche Beobachtungen können zum Beispiel die monatlichen Ölpreise für das Jahr sein, dh wir werden 12 Zielwerte haben. Wir beginnen die Notation einzuführen. Wir bezeichnen jeden Zielwert als
yi . Insgesamt haben wir
n Beobachtungen, das heißt, wir können uns unsere Beobachtungen als vorstellen
y1,y2,y3...yn .
Regressoren
Wir gehen davon aus, dass es Faktoren gibt, die die Werte des Zielindikators zum Teil erklären. Zum Beispiel wird der Wechselkurs des Dollar / Rubel-Paares stark vom Ölpreis, dem Fed-Kurs usw. beeinflusst. Solche Faktoren werden als Regressoren bezeichnet. Gleichzeitig muss jeder Wert des Zielindikators dem Wert des Regressors entsprechen, dh wenn wir 2018 für jeden Monat 12 Ziele haben, müssen wir auch 12 Regressoren für denselben Zeitraum haben. Bezeichnen Sie die Werte jedes Regressors mit
xi:x1,x2,x3...xn . Lassen Sie in unserem Fall gibt es
k Regressoren (d. h.
k Faktoren, die den Wert des Ziels beeinflussen). So können unsere Regressoren wie folgt dargestellt werden: für den 1. Regressor (zum Beispiel den Ölpreis):
x11,x12,x13...x1n , für den 2. Regressor (zum Beispiel die Fed-Rate):
x21,x22,x23...x2n für
k der "Regressor:
xk1,xk2,xk3...xknAbhängigkeit der Ziele von Regressoren
Zielabhängigkeit annehmen
yi von Regressoren "
i -th "Beobachtung kann durch die lineare Regressionsgleichung der Form ausgedrückt werden:
f(w,xi)=w0+w1x1i+...+wkxki
wo
xi - "
i "Regressorwert von 1 bis
n ,
k - die Anzahl der Regressoren von 1 bis
kw - Winkelkoeffizienten, die den Betrag darstellen, um den sich der berechnete Zielindikator im Durchschnitt ändert, wenn sich der Regressor ändert.
Mit anderen Worten, wir sind für alle da (außer
w0 ) des Regressors bestimmen wir "unseren" Koeffizienten
w , dann multiplizieren Sie die Koeffizienten mit den Werten der Regressoren "
i -th "Beobachtung, als Ergebnis bekommen wir eine gewisse Annäherung"
i das "Ziel.
Daher müssen wir solche Koeffizienten auswählen
w für die die Werte unserer Näherungsfunktion
f(w,xi) wird so nahe wie möglich an den Werten der Ziele liegen.
Abschätzung der Qualität der Approximationsfunktion
Wir werden die Qualitätsschätzung der Approximationsfunktion nach der Methode der kleinsten Quadrate bestimmen. Die Qualitätsbewertungsfunktion hat in diesem Fall die folgende Form:
Err= sum limitsni=1(yi−f(xi))2 rightarrowmin
Wir müssen solche Werte der Koeffizienten $ w $ wählen, für die der Wert gilt
Err wird der kleinste sein.
Wir übersetzen die Gleichung in Matrixform
Vektoransicht
Um Ihnen das Leben zu erleichtern, sollten Sie zunächst die lineare Regressionsgleichung und den ersten Koeffizienten beachten
w0 nicht mit einem Regressor multipliziert. Wenn wir die Daten in Matrixform übersetzen, wird der obige Umstand die Berechnungen außerdem ernsthaft erschweren. In diesem Zusammenhang wird vorgeschlagen, einen weiteren Regressor für den ersten Koeffizienten einzuführen
w0 und gleich eins. Oder vielmehr jeder "
i Der "Wert" dieses Regressors ist gleichbedeutend mit der Einheit - denn wenn er mit der Einheit multipliziert wird, ändert sich nichts im Hinblick auf das Ergebnis der Berechnungen und im Hinblick auf die Regeln für das Produkt der Matrizen, wird unsere Qual erheblich verringert.
Nehmen wir nun für eine Weile an, wir hätten nur eine, um das Material zu vereinfachen. "
i th "Beobachtung. Dann stellen Sie sich die Werte der Regressoren"
i Beobachtung als Vektor
vecxi . Vektor
vecxi hat Dimension
(k times1) , also
k Zeilen und 1 Spalte:
vecxi= beginpmatrixx0ix1i...xki endpmatrix qquad
Die gewünschten Koeffizienten können als Vektor dargestellt werden
vecw Dimension haben
(k times1) :
vecw= beginpmatrixw0w1...wk endpmatrix qquad
Die lineare Regressionsgleichung für
i -th "Beobachtung wird die Form annehmen:
f(w,xi)= vecxiT vecw
Die Qualitätsbewertungsfunktion des linearen Modells hat folgende Form:
Err= sum limitsni=1(yi− vecxiT vecw)2 rightarrowmin
Beachten Sie, dass wir gemäß den Regeln der Matrixmultiplikation den Vektor transponieren mussten
vecxi .
Matrixdarstellung
Als Ergebnis der Multiplikation von Vektoren erhalten wir die Zahl:
(1 timesk) centerdot(k times1)=1 times1 wie erwartet. Diese Zahl ist die Annäherung "
i -th "Ziel. Aber wir müssen nicht einen Wert des Ziels approximieren, sondern alle. Dazu schreiben wir alles"
i Matrix-Regressoren
X . Die resultierende Matrix hat die Dimension
(n timesk) :
$$ display $$ X = \ begin {pmatrix} x_ {00} & x_ {01} & ... & x_ {0k} \\ x_ {10} & x_ {11} & ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $$ display $$
Nun hat die lineare Regressionsgleichung die Form:
f(w,X)=X vecw
Bezeichnen Sie die Werte der Zielindikatoren (alle
yi ) pro Vektor
vecy Dimension
(n times1) :
vecy= beginpmatrixy0y1...yn endpmatrix qquad
Nun können wir im Matrixformat die Gleichung zur Beurteilung der Qualität eines linearen Modells schreiben:
Err=(X vecw− vecy)2 rightarrowmin
Tatsächlich erhalten wir aus dieser Formel weiterhin die uns bekannte Formel
XTXw=XTyWie geht das? Die Klammern werden geöffnet, die Differenzierung wird durchgeführt, die resultierenden Ausdrücke werden transformiert usw. Und genau das werden wir jetzt tun.
Matrixtransformationen
Klappen Sie die Klammern auf
(X vecw− vecy)2=(X vecw− vecy)T(X vecw− vecy)=(X vecw)TX vecw− vecyTX vecw−(X vecw)T vecy+ vecyT vecyBereiten Sie eine Gleichung zur Differenzierung vor
Dazu führen wir einige Transformationen durch. In nachfolgenden Berechnungen wird es für uns praktischer sein, wenn der Vektor
vecwT wird zu Beginn jeder Arbeit in der Gleichung vorgestellt.
Umwandlung 1
vecyTX vecw=(X vecw)T vecy= vecwTXT vecyWie ist es dazu gekommen? Um diese Frage zu beantworten, schauen Sie sich einfach die Größen der multiplizierten Matrizen an und sehen Sie, dass wir am Ausgang eine Zahl oder etwas anderes erhalten
const .
Wir schreiben die Dimensionen der Matrixausdrücke.
vecyTX vecw:(1 timesn) centerdot(n timesk) centerdot(k times1)=(1 times1)=const(X vecw)T vecy:((n timesk) centerdot(k times1))T centerdot(n times1)=(1 timesn) centerdot(n times1)=(1 times1)=const vecwTXT vecy:(1 malk) centerdot(k maln) centerdot(n mal1)=(1 mal1)=constUmwandlung 2
(X vecw)TX vecw= vecwTXTX vecwWir schreiben ähnlich wie Transformation 1
(X vecw)TX vecw:((n malk) centerdot(k mal1))T centerdot(n malk) centerdot(k mal1)=(1 mal1)=const vecwTXTX vecw:(1 malk) centerdot(k maln) centerdot(n malk) centerdot(k mal1)=(1 mal1)=constAm Ausgang erhalten wir eine Gleichung, die wir unterscheiden müssen:
Err= vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyWir unterscheiden die Funktion der Bewertung der Qualität des Modells
Unterscheiden nach Vektor
vecw :
fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw
( vecwTXTX vecw)′−(2 vecwTXT vecy)′+( vecyT vecy)′=02XTX vecw−2XT vecy+0=0XTX vecw=XT vecyFragen warum
( vecyT vecy)′=0 Sollte dies nicht der Fall sein, aber die Operationen zur Bestimmung der Ableitungen in den beiden anderen Ausdrücken werden wir genauer analysieren.
Differenzierung 1
Wir zeigen die Unterscheidung:
fracd( vecwTXTX vecw)d vecw=2XTX vecwUm die Ableitung einer Matrix oder eines Vektors zu bestimmen, müssen Sie sehen, was sie enthalten. Wir schauen:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
vecw= beginpmatrixw0w1...wk endpmatrix qquad$ inline $ X ^ T = \ begin {pmatrix} x_ {00} & x_ {10} & ... & x_ {n0} \\ x_ {01} & x_ {11} & ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} & x_ {1k} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
$ inline $ X = \ begin {pmatrix} x_ {00} & x_ {01} & ... & x_ {0k} \\ x_ {10} & x_ {11} & ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
Bezeichnen Sie das Produkt von Matrizen
XTX durch die Matrix
A . Matrix
A quadratisch und darüber hinaus ist es symmetrisch. Diese Eigenschaften werden uns weiterhin nützlich sein, merken Sie sich diese. Matrix
A hat Dimension
(k timesk) :
$ inline $ A = \ begin {pmatrix} a_ {00} & a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad $ inline $
Jetzt ist es unsere Aufgabe, die Vektoren korrekt mit der Matrix zu multiplizieren und nicht "zweimal zwei fünf" zu erhalten, also werden wir uns konzentrieren und äußerst vorsichtig sein.
$ inline $ \ vec {w} ^ TA \ vec {w} = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad \ times \ begin {pmatrix} a_ {00} & a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \ \ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
$ inline $ = \ begin {pmatrix} w_0a_ {00} + w_1a_ {10} + ... + w_ka_ {k0} & ... & w_0a_ {0k} + w_1a_ {1k} + ... + w_ka_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
= beginpmatrix(w0a00+w1a10+...+wkak0)w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10mu(w0a0k+w1a1k+...+wkakk)wk endpmatrix==w20a00+w1a10w0+wkak0w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10muw0a0kwk+w1a1kwk+...+w2kakkWir haben jedoch einen komplizierten Ausdruck! Tatsächlich haben wir eine Zahl - einen Skalar. Und jetzt gehen wir schon wirklich zur Differenzierung über. Es ist notwendig, die Ableitung des erhaltenen Ausdrucks für jeden Koeffizienten zu finden
w0w1...wk und den Dimensionsvektor am Ausgang erhalten
(k times1) . Nur für den Fall werde ich die Vorgehensweisen für die Aktionen beschreiben:
1) differenzieren durch
wo wir bekommen:
2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwk2) differenzieren durch
w1 wir bekommen:
w0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk3) differenzieren durch
wk wir bekommen:
w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakkAm Ausgang der versprochene Größenvektor
(k times1) :
beginpmatrix2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwkw0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk.........w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakk endpmatrix
Wenn Sie sich den Vektor genauer ansehen, werden Sie feststellen, dass das linke und das entsprechende rechte Element des Vektors so gruppiert werden können, dass der Vektor vom dargestellten Vektor unterschieden werden kann
vecw die Größe
(k times1) . Zum Beispiel
w1a10 (linkes Element der obersten Zeile des Vektors)
+a01w1 (das rechte Element der obersten Zeile des Vektors) kann als dargestellt werden
w1(a10+a01) und
w2a20+a02w2 - wie
w2(a20+a02) usw. in jeder Zeile. Gruppe:
beginpmatrix2w0a00+w1(a10+a01)+w2(a20+a02)+...+wk(ak0+a0k)w0(a01+a10)+2w1a11+w2(a21+a12)+...+wk(ak1+a1k).........w0(a0k+ak0)+w1(a1k+ak1)+w2(a2k+ak2)+...+2wkakk endpmatrix
Nehmen Sie den Vektor heraus
vecw und am Ausgang erhalten wir:
$$ display $$ \ begin {pmatrix} 2a_ {00} & a_ {10} + a_ {01} & a_ {20} + a_ {02} & ... & a_ {k0} + a_ {0k} \\ a_ {01} + a_ {10} & 2a_ {11} & a_ {21} + a_ {12} & ... & a_ {k1} + a_ {1k} \\ ... & ... & .. . & ... & ... \\ ... & ... & ... & ... & ... \\ ... & ... & ... & ... & .. . \\ a_ {0k} + a_ {k0} & a_ {1k} + a_ {k1} & a_ {2k} + a_ {k2} & ... & 2a_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ ... \\ ... \\ w_k \ end {pmatrix} \ qquad $$ display $$
Schauen wir uns nun die resultierende Matrix an. Eine Matrix ist die Summe zweier Matrizen
A+AT :
$$ display $$ \ begin {pmatrix} a_ {00} & a_ {01} & a_ {02} & ... & a_ {0k} \\ a_ {10} & a_ {11} & a_ {12} & ... & a_ {1k} \\ ... & ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & a_ {k2} & ... & a_ {kk} \ end {pmatrix} + \ begin {pmatrix} a_ {00} & a_ {10} & a_ {20} & ... & a_ {k0} \\ a_ {01} & a_ {11} & a_ {21} & ... & a_ {k1} \\ ... & ... & ... & ... & ... \\ a_ {0k} & a_ {1k} & a_ {2k} & ... & a_ {kk} \ end {pmatrix} \ qquad $$ display $$
Denken Sie daran, dass wir vorhin eine wichtige Eigenschaft der Matrix festgestellt haben
A - Es ist symmetrisch. Anhand dieser Eigenschaft können wir sicher den Ausdruck angeben
A+AT gleich
2A . Dies lässt sich leicht überprüfen, indem das Produkt Matrix für Element angezeigt wird
XTX . Wir werden dies hier nicht tun, wer möchte, kann die Überprüfung selbst durchführen.
Kommen wir zu unserem Ausdruck zurück. Nach unseren Transformationen stellte sich heraus, wie wir es sehen wollten:
(A+AT) times beginpmatrixw0w1...wk endpmatrix qquad=2A vecw=2XTX vecw
Also haben wir die erste Differenzierung gemeistert. Wir kommen zum zweiten Ausdruck.
Differenzierung 2
fracd(2 vecwTXT vecy)d vecw=2XT vecyGehen wir den ausgetretenen Pfaden entlang. Es wird viel kürzer als das vorherige sein, gehen Sie also nicht weit vom Bildschirm weg.
Wir decken die elementweisen Vektoren und die Matrix auf:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
$ inline $ X ^ T = \ begin {pmatrix} x_ {00} & x_ {10} & ... & x_ {n0} \\ x_ {01} & x_ {11} & ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} & x_ {1k} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
vecy= beginpmatrixy0y1...yn endpmatrix qquadFür eine Weile entfernen wir die Zwei aus den Berechnungen - es spielt keine große Rolle, dann werden wir es an seinen Platz zurückbringen. Multiplizieren Sie die Vektoren mit der Matrix. Zunächst multiplizieren wir die Matrix
XT auf vektor
vecy Hier haben wir keine Einschränkungen. Holen Sie sich den Größenvektor
(k times1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Führen Sie die folgende Aktion aus - multiplizieren Sie den Vektor
vecw zu dem resultierenden Vektor. Am Ausgang wartet eine Nummer auf uns:
beginpmatrixw0(x00y0+x10y1+...+xn0yn)+w1(x01y0+x11y1+...+xn1yn) mkern10mu+ mkern10mu... mkern10mu+ mkern10muwk(x0ky0+x1ky1+...+xnkyn) endpmatrix qquad
Wir unterscheiden es dann. Am Ausgang erhalten wir einen Dimensionsvektor
(k times1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Ähnelt es etwas? Alles ist richtig! Dies ist das Produkt der Matrix.
XT auf vektor
vecy .
Damit wurde die zweite Unterscheidung erfolgreich abgeschlossen.
Anstelle einer Schlussfolgerung
Jetzt wissen wir, wie es zur Gleichstellung kam.
XTX vecw=XT vecy .
Schließlich beschreiben wir einen schnellen Weg, um die Hauptformeln zu transformieren.
Schätzen Sie die Qualität des Modells nach der Methode der kleinsten Quadrate: sum limitsni=1(yi−f(xi))2 mkern20mu= mkern20mu sum limitsni=1(yi− vecxiT vecw)2==(X vecw− vecy)2 mkern20mu= mkern20mu(X vecw− vecy)T(X vecw− vecy) mkern20mu= mkern20mu vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyWir differenzieren den resultierenden Ausdruck: fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw=2XTX vecw−2XT vecy=0XTX vecw=XT vecy leftarrow Frühere Arbeiten des Autors - „Wir lösen die Gleichung der einfachen linearen Regression“ rightarrow Die nächste Arbeit des Autors - "Chewing Logistic Regression"Literatur
Internetquellen:1)
habr.com/de/post/2785132)
habr.com/ru/company/ods/blog/3220763)
habr.com/de/post/3070044)
nabatchikov.com/blog/view/matrix_derLehrbücher, Aufgabensammlungen:1) Vorlesungsskript über höhere Mathematik: volle Lehrveranstaltung / D.T. Geschrieben - 4. Aufl. - M .: Iris Press, 2006
2) Angewandte Regressionsanalyse / N. Draper, G. Smith - 2. Aufl. - M .: Finanzen und Statistik, 1986
3) Aufgaben zum Lösen von Matrixgleichungen:
function-x.ru/matrix_equations.html
mathprofi.ru/deistviya_s_matricami.html