
Seien Sie einfach nicht überrascht, aber die zweite Überschrift dieses Beitrags erzeugte ein neuronales Netzwerk, oder vielmehr den Algorithmus der Sammarisierung. Und was ist Sammarisierung?
Dies ist eine der zentralen und klassischen
Herausforderungen der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) . Es besteht darin, einen Algorithmus zu erstellen, der Text als Eingabe verwendet und eine gekürzte Version davon ausgibt. Darüber hinaus bleibt die korrekte Struktur (entsprechend den Normen der Sprache) erhalten und die Hauptidee des Textes wird korrekt übermittelt.
Solche Algorithmen sind in der Industrie weit verbreitet. Beispielsweise sind sie für Suchmaschinen nützlich: Mithilfe der Textreduzierung können Sie leicht nachvollziehen, ob die Hauptidee einer Site oder eines Dokuments mit einer Suchanfrage korreliert. Sie werden verwendet, um in einem großen Strom von Mediendaten nach relevanten Informationen zu suchen und Informationsmüll herauszufiltern. Textreduktion hilft bei der Finanzanalyse, bei der Analyse von Rechtsverträgen, der Kommentierung von wissenschaftlichen Arbeiten und vielem mehr. Übrigens, der Sammarisierungsalgorithmus hat alle Unterüberschriften für diesen Beitrag generiert.
Zu meiner Überraschung gab es auf Habré nur sehr wenige Artikel zum Thema Sammarisierung. Ich beschloss, meine Forschungen und Ergebnisse in diese Richtung zu teilen. Dieses Jahr nahm ich an der Rennstrecke der
Dialogkonferenz teil und experimentierte mit Überschriftengeneratoren für Nachrichten und Gedichte, die neuronale Netze verwendeten. In diesem Beitrag werde ich zunächst kurz auf den theoretischen Teil der Sammarisierung eingehen und anschließend Beispiele für die Generierung von Überschriften geben. Ich werde Ihnen erläutern, welche Schwierigkeiten Modelle beim Kürzen des Texts haben und wie diese Modelle verbessert werden können, um bessere Überschriften zu erzielen.
Unten finden Sie ein Beispiel für eine Nachricht und ihre ursprüngliche Referenzüberschrift. Die Modelle, über die ich sprechen werde, werden anhand des folgenden Beispiels so trainiert, dass sie Header generieren:

Geheimnisse zum Schneiden von Text seq2seq Architektur
Es gibt zwei Arten von Textreduzierungsmethoden:
- Extraktiv . Es besteht darin, die informativsten Teile des Textes zu finden und daraus die für die jeweilige Sprache richtige Anmerkung zu erstellen. Diese Gruppe von Methoden verwendet nur die Wörter, die sich im Quelltext befinden.
- Auszug Es besteht darin, semantische Verknüpfungen aus dem Text zu extrahieren und dabei Sprachabhängigkeiten zu berücksichtigen. Bei der abstrakten Zusammenstellung werden Anmerkungswörter nicht aus dem abgekürzten Text, sondern aus dem Wörterbuch (der Liste der Wörter für eine bestimmte Sprache) ausgewählt, wodurch die Hauptidee umformuliert wird.
Der zweite Ansatz impliziert, dass der Algorithmus Sprachabhängigkeiten berücksichtigen, neu formulieren und verallgemeinern sollte. Er möchte auch etwas über die reale Welt wissen, um sachliche Fehler zu vermeiden. Lange galt dies als schwierige Aufgabe, und die Forscher konnten keine qualitativ hochwertige Lösung finden - einen grammatikalisch korrekten Text unter Beibehaltung der Grundidee. Aus diesem Grund basierten die meisten Algorithmen in der Vergangenheit auf einem Extraktionsansatz, da Sie durch die Auswahl ganzer Textteile und deren Übertragung auf das Ergebnis den Grad der Alphabetisierung wie bei der Quelle beibehalten können.
Dies war jedoch vor dem Boom der neuronalen Netze und dem bevorstehenden Eindringen in das NLP. 2014 wurde die
seq2seq- Architektur
mit einem Aufmerksamkeitsmechanismus eingeführt, mit dem einige Textsequenzen gelesen und andere generiert werden können (abhängig davon, was das Modell für die Ausgabe gelernt hat) (
Artikel von Sutskever et al.). 2016 wurde eine solche Architektur direkt auf die Lösung des Sammarisierungsproblems angewendet, wodurch ein abstrakter Ansatz implementiert und ein Ergebnis erzielt wurde, das mit dem vergleichbar war, was eine kompetente Person schreiben konnte (
Artikel von Nallapati et al., 2016;
Artikel von Rush et al., 2015; ) Wie funktioniert diese Architektur?
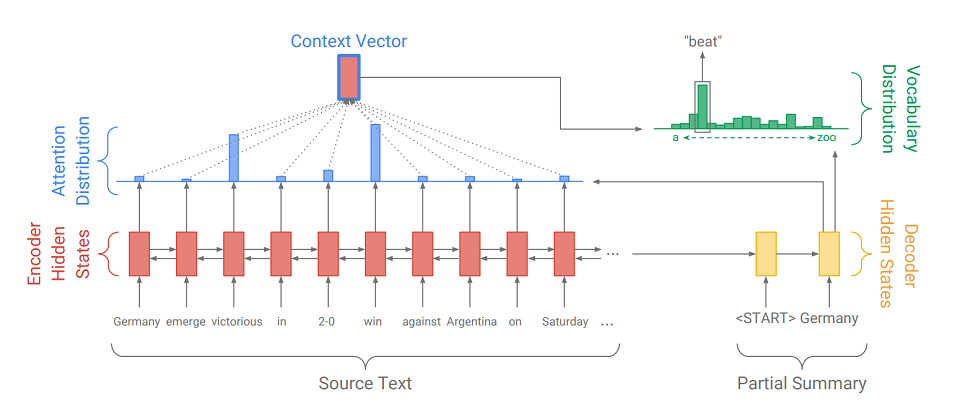
Seq2Seq besteht aus zwei Teilen:
- Encoder (Encoder) - Ein Zwei-Wege-RNN, mit dem die Eingabesequenz gelesen wird, dh die Eingabeelemente werden nacheinander gleichzeitig von links nach rechts und von rechts nach links verarbeitet, um den Kontext besser zu berücksichtigen.
- Decoder (Decoder) - Einweg-RNN, der sequentiell und elementweise eine Ausgangssequenz erzeugt.
Zunächst wird die Eingabesequenz in eine Einbettungssequenz übersetzt (kurz gesagt, die Einbettung ist eine prägnante Darstellung eines Wortes als Vektor). Die Einbettungen durchlaufen dann das rekursive Netzwerk des Encoders. Daher erhalten wir für jedes Wort die verborgenen Zustände des Encoders (
angezeigt durch rote Rechtecke im Diagramm ) und sie enthalten Informationen über das Token selbst und seinen Kontext, sodass wir die Sprachverbindungen zwischen den Wörtern berücksichtigen können.
Nachdem der Encoder die Eingabe verarbeitet hat, überträgt er seinen letzten verborgenen Zustand (der komprimierte Informationen über den gesamten Text enthält) an den Decoder, der ein spezielles Token empfängt

und erstellt das erste Wort der Ausgabesequenz (
im Bild ist es „Deutschland“ ). Dann nimmt er zyklisch seine vorherige Ausgabe, gibt sie an sich selbst weiter und zeigt wieder das nächste Ausgabeelement an (
also kommt nach "Deutschland" "Schlag" und nach "Schlag" das nächste Wort usw. ). Dies wird solange wiederholt, bis ein spezieller Token ausgegeben wird
. Dies bedeutet das Ende der Generation.
Um das nächste Element anzuzeigen, konvertiert der Decoder genau wie der Encoder das Eingabe-Token in Einbettung, geht einen Schritt des rekursiven Netzwerks und empfängt den nächsten verborgenen Zustand des Decoders (
gelbe Rechtecke im Diagramm ). Dann wird unter Verwendung einer vollständig verbundenen Schicht eine Wahrscheinlichkeitsverteilung für alle Wörter aus einem vorkompilierten Modellwörterbuch erhalten. Die wahrscheinlichsten Wörter werden vom Modell abgeleitet.
Das Hinzufügen
eines Aufmerksamkeitsmechanismus hilft dem Decoder, die eingegebenen Informationen besser zu nutzen. Der Mechanismus bei jedem Erzeugungsschritt bestimmt die sogenannte
Aufmerksamkeitsverteilung (die
blauen Rechtecke in der Figur sind die Menge von Gewichten, die den Elementen der ursprünglichen Sequenz entsprechen, die Summe der Gewichte ist 1, alle Gewichte> = 0 ) und daraus wird die gewichtete Summe aller verborgenen Codiererzustände erhalten, wodurch gebildet wird Kontextvektor (
das Diagramm zeigt ein rotes Rechteck mit einem blauen Strich ). Dieser Vektor verkettet sich mit dem Einbetten des Decodierereingangsworts im Stadium der Berechnung des latenten Zustands und mit dem latenten Zustand selbst im Stadium der Bestimmung des nächsten Wortes. So kann das Modell bei jedem Schritt der Ausgabe ermitteln, welche Geberzustände für das Modell momentan am wichtigsten sind. Mit anderen Worten, es entscheidet über den Kontext, in dem die Eingabewörter am meisten berücksichtigt werden sollten (z. B. zeigt das Bild das Wort „Schlag“ an, der Aufmerksamkeitsmechanismus gewichtet die Sieger- und Gewinnmarker stark, und der Rest ist nahe Null).
Da die Generierung von Headern auch eine der Aufgaben der Sammarisierung ist, nur mit der minimal möglichen Ausgabe (1-12 Wörter), habe ich mich entschlossen,
seq2seq mit dem Aufmerksamkeitsmechanismus für unseren Fall anzuwenden. Wir trainieren ein solches System für Texte mit Überschriften, zum Beispiel in den Nachrichten. Darüber hinaus ist es ratsam, dem Decoder in der Ausbildungsphase nicht seine eigene Ausgabe, sondern die Worte der tatsächlichen Überschrift (Lehrerzwang) vorzulegen, um sich und dem Modell das Leben zu erleichtern. Als Fehlerfunktion verwenden wir die Standardfunktion für den Verlust durch Kreuzentropie, die zeigt, wie nahe die Wahrscheinlichkeitsverteilungen des Ausgangsworts und des Wortes aus dem realen Header sind:
Bei Verwendung des trainierten Modells verwenden wir die Strahlensuche, um eine wahrscheinlichere Folge von Wörtern zu finden als bei Verwendung des Greedy-Algorithmus. Dazu leiten wir bei jedem Schritt der Generierung nicht das wahrscheinlichste Wort ab, sondern betrachten gleichzeitig beam_size der wahrscheinlichsten Wortfolgen. Wenn sie enden, endet jeder am
) leiten wir die wahrscheinlichste Sequenz ab.
Modellentwicklung
Eines der Probleme des Modells in seq2seq ist die Unfähigkeit, Wörter zu zitieren, die nicht im Wörterbuch enthalten sind. Zum Beispiel hat das Modell keine Chance, "obamacare" aus dem obigen Artikel abzuleiten. Gleiches gilt für:
- seltene Familiennamen und Namen
- neue Begriffe
- wörter in anderen sprachen,
- verschiedene Wortpaare, die durch einen Bindestrich verbunden sind (als "Republikanischer Senator")
- und andere Designs.
Natürlich können Sie das Wörterbuch erweitern, dies erhöht jedoch die Anzahl der trainierten Parameter erheblich. Darüber hinaus ist es erforderlich, eine große Anzahl von Dokumenten bereitzustellen, in denen diese seltenen Wörter vorkommen, damit der Generator lernt, sie qualitativ zu verwenden.
Eine andere und elegantere Lösung für dieses Problem wurde 2017 in einem Artikel vorgestellt - „
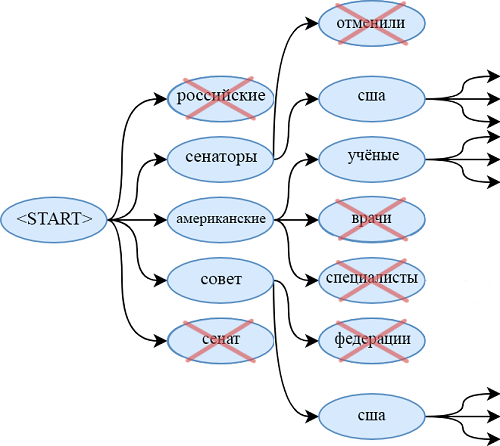
Auf den Punkt gebracht: Zusammenfassung mit Pointer-Generator-Netzwerken “ (Abigail See et al.). Sie fügt unserem Modell einen neuen Mechanismus hinzu -
einen Zeigermechanismus, mit dem Wörter aus dem Quelltext ausgewählt und direkt in die generierte Sequenz eingefügt werden können. Wenn der Text eine OOV enthält (
kein Wortschatz - ein Wort, das nicht im Wörterbuch enthalten ist ), kann das Modell die OOV isolieren und an der Ausgabe einfügen, wenn es dies für erforderlich hält. Ein solches System wird als
" Pointer-Generator" (Pointer-Generator oder pg) bezeichnet und ist eine Synthese von zwei Ansätzen zur Sammarisierung. Sie kann selbst entscheiden, in welchem Schritt sie abstrakt sein soll und in welchem Schritt - extrahieren. Wie sie es macht, werden wir jetzt herausfinden.
Der Hauptunterschied zum üblichen seq2seq-Modell ist die zusätzliche Aktion, für die p
gen berechnet wird - die Erzeugungswahrscheinlichkeit. Dies erfolgt unter Verwendung des verborgenen Zustands des Decoders und des Kontextvektors. Die Bedeutung der zusätzlichen Aktion ist einfach. Je näher p
gen an 1 liegt, desto wahrscheinlicher ist es, dass das Modell mithilfe der abstrakten Generierung ein Wort aus seinem Wörterbuch ausgibt. Je näher
pgen an 0 liegt, desto wahrscheinlicher ist es, dass der Generator das Wort aus dem Text extrahiert, der von der zuvor erhaltenen Aufmerksamkeitsverteilung geleitet wird. Die endgültige Wahrscheinlichkeitsverteilung der Wortergebnisse ist die Summe der erzeugten Wahrscheinlichkeitsverteilung mit Wörtern (in denen es keine OOV gibt) multipliziert mit
pgen und der Aufmerksamkeitsverteilung (in der OOV zum Beispiel "2-0" im Bild ist) multipliziert mit (1 - p
gen ).

Zusätzlich zum Zeigemechanismus wird im Artikel
ein Coverage-Mechanismus eingeführt , mit dem sich wiederholende Wörter vermeiden lassen. Ich habe auch damit experimentiert, aber keine signifikanten Verbesserungen in der Qualität der Überschriften festgestellt - es ist nicht wirklich notwendig. Dies liegt höchstwahrscheinlich an den Besonderheiten der Aufgabe: Da nur wenige Wörter ausgegeben werden müssen, hat der Generator einfach keine Zeit, sich zu wiederholen. Für andere Aufgaben der Sammarisierung, zum Beispiel Annotation, kann es sich als nützlich erweisen. Bei Interesse können Sie im Originalartikel darüber nachlesen.

Große Auswahl an russischen Wörtern
Eine andere Möglichkeit, die Qualität der Ausgabe-Header zu verbessern, besteht darin, die Eingabesequenz ordnungsgemäß vorzuverarbeiten. Neben der offensichtlichen Beseitigung von Großbuchstaben habe ich auch versucht, Wörter aus dem Quelltext in Stil- und Beugungspaare (d. H. Grundlagen und Endungen) umzuwandeln. Verwenden Sie zum Teilen den Porter Stemmer.
Wir markieren alle Beugungen am Anfang mit dem „+“ - Symbol, um sie von anderen Token zu unterscheiden. Wir betrachten jedes Thema und jede Wendung als ein separates Wort und lernen auf dieselbe Weise wie in Worten daraus. Das heißt, wir erhalten Einbettungen von ihnen und leiten eine Sequenz ab (die auch in Grundlagen und Enden unterteilt ist), die leicht in Wörter umgewandelt werden kann.
Eine solche Konvertierung ist sehr nützlich, wenn Sie mit morphologisch reichen Sprachen wie Russisch arbeiten. Anstatt große Wörterbücher mit einer Vielzahl russischer Wortformen zu kompilieren, können Sie sich auf eine große Anzahl von Wortstämmen (die um ein Vielfaches kleiner sind als die Anzahl der Wortformen) und eine sehr kleine Anzahl von Endungen (ich habe viele 450 Beugungen) beschränken. Auf diese Weise erleichtern wir dem Modell die Arbeit mit diesem „Reichtum“ und erhöhen gleichzeitig nicht die Komplexität der Architektur und die Anzahl der Parameter.

Ich habe auch versucht, die Lemma + Gramm-Transformation zu verwenden. Das heißt, aus jedem Wort vor der Verarbeitung können Sie mithilfe des Pymorphie-Pakets (z. B. "was") seine ursprüngliche Form und grammatische Bedeutung abrufen.
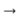
"Sein" und "VERB | impf | past | sing | femn"). So erhielt ich ein Paar paralleler Sequenzen (in der einen - den Anfangsformen, in der anderen - grammatikalischen Werten). Für jeden Sequenztyp habe ich meine Einbettungen zusammengestellt, die ich dann verkettet und an die zuvor beschriebene Pipeline gesendet habe. Darin lernte der Decoder nicht, ein Wort, sondern ein Lemma und Grammatiken auszusprechen. Ein solches System brachte jedoch keine sichtbaren Verbesserungen im Vergleich zu pg zum Thema. Vielleicht war es eine zu einfache Architektur für die Arbeit mit grammatischen Werten, und es hat sich gelohnt, für jede grammatische Kategorie in der Ausgabe einen eigenen Klassifikator zu erstellen. Aber ich habe nicht mit solchen oder komplexeren Modellen experimentiert.
Ich habe mit einem anderen Zusatz zur ursprünglichen Architektur des Zeigergenerators experimentiert, der sich jedoch nicht auf die Vorverarbeitung bezieht. Dies ist eine Erhöhung der Anzahl von Schichten (bis zu 3) der rekursiven Netzwerke des Codierers und Decodierers. Das Erhöhen der Tiefe des wiederkehrenden Netzwerks kann die Qualität der Ausgabe verbessern, da der verborgene Zustand der letzten Schichten Informationen über eine viel längere Eingabesubsequenz enthalten kann als der verborgene Zustand eines einschichtigen RNN. Dies hilft, komplexe erweiterte semantische Verbindungen zwischen Elementen der Eingabesequenz zu berücksichtigen. Dies kostet zwar eine erhebliche Erhöhung der Anzahl der Modellparameter und erschwert das Lernen.

Header Generator Experimente
Alle meine Experimente mit Überschriftengeneratoren lassen sich in zwei Typen unterteilen: Experimente mit Nachrichtenartikeln und Versen. Ich werde Sie in der Reihenfolge erzählen.
Nachrichten Experimente
Bei der Arbeit mit Nachrichten verwendete ich Modelle wie seq2seq, pg, pg mit Stielen und Flexionen - einschichtig und dreischichtig. Ich habe auch Modelle in Betracht gezogen, die mit Gramm arbeiten, aber alles, was ich über sie erzählen wollte, habe ich bereits oben beschrieben. Ich muss gleich sagen, dass alle in diesem Abschnitt beschriebenen pg den Beschichtungsmechanismus verwendeten, obwohl sein Einfluss auf das Ergebnis zweifelhaft ist (da es ohne ihn nicht viel schlimmer war).
Ich habe den RIA Novosti-Datensatz, der von der Nachrichtenagentur Rossiya Segodnya zur Verfügung gestellt wurde, geschult, um auf der Dialog-Konferenz einen Track zur Erstellung von Schlagzeilen zu erstellen. Der Datensatz enthält 1.003.869 Nachrichtenartikel, die von Januar 2010 bis Dezember 2014 veröffentlicht wurden.
Alle untersuchten Modelle verwendeten dieselben Einbettungen (128), denselben Wortschatz (100.000) und dieselben latenten Zustände (256) und trainierten für dieselbe Anzahl von Epochen. Daher können sich nur qualitative Änderungen in der Architektur oder in der Vorverarbeitung auf das Ergebnis auswirken.
Modelle, die an vorverarbeiteten Text angepasst sind, liefern bessere Ergebnisse als Modelle, die mit Wörtern arbeiten. Eine dreischichtige Seite, die Informationen zu Themen und Wendungen verwendet, funktioniert am besten. Bei Verwendung von pg wird auch die erwartete Verbesserung der Qualität der Header im Vergleich zu seq2seq angezeigt, was auf die bevorzugte Verwendung des Zeigers beim Generieren von Headern hinweist. Hier ist ein Beispiel für die Funktionsweise aller Modelle:
Wenn wir uns die generierten Header ansehen, können wir die folgenden Probleme von den untersuchten Modellen unterscheiden:
- Models verwenden oft unregelmäßige Formen von Wörtern. Modelle mit Stielen (wie im obigen Beispiel) sind von diesem Nachteil mehr befreit;
- Alle Modelle mit Ausnahme derer, die mit Themen arbeiten, können unvollständig erscheinende Kopfzeilen oder seltsame Designs erzeugen, die nicht in der Sprache vorliegen (wie im obigen Beispiel).
- Alle untersuchten Modelle verwechseln häufig die beschriebenen Personen, ersetzen falsche Daten oder verwenden nicht ganz passende Wörter.


Versuche mit Versen
Da die dreischichtige Seite mit den Themen die geringsten Ungenauigkeiten in den generierten Überschriften aufweist, ist dies das Modell, das ich für Versuche mit Versen gewählt habe. Ich brachte ihr den Fall bei, der aus 6 Millionen russischen Gedichten von der Site "stihi.ru" bestand. Dazu gehören Liebe (etwa die Hälfte der Verse widmet sich diesem Thema), bürgerliche (etwa ein Viertel), Stadt- und Landschaftspoesie. Schreibzeitraum: Januar 2014 - Mai 2019. Ich werde Beispiele für generierte Überschriften für Verse geben:
Das Modell erwies sich als größtenteils extrahierend: Fast alle Überschriften bestehen aus einer einzelnen Zeile, die häufig aus der ersten oder letzten Zeilengruppe extrahiert wird. In Ausnahmefällen kann das Modell Wörter generieren, die nicht im Gedicht enthalten sind. Dies ist darauf zurückzuführen, dass eine sehr große Anzahl von Texten in dem Fall tatsächlich eine der Zeilen als Namen hat.
Abschließend möchte ich sagen, dass der Indexgenerator, der an den Stielen arbeitete und einen einschichtigen Decoder und Encoder verwendete, auf der
Wettbewerbsstrecke für die Generierung von Überschriften für Nachrichtenartikel auf der wissenschaftlichen Dialogkonferenz zur Computerlinguistik "Dialogue" den zweiten Platz belegte. Hauptorganisator dieser Konferenz ist ABBYY, das Unternehmen forscht in nahezu allen modernen Bereichen der Verarbeitung natürlicher Sprache.
Abschließend schlage ich Ihnen ein wenig interaktiv vor: Senden Sie Nachrichten in den Kommentaren und sehen Sie, welche Header das neuronale Netzwerk für sie generiert.
Matvey, Entwickler bei NLP Group bei ABBYY