Fear Operations-Puffer bringen ...
Betrachten Sie am Beispiel einer kleinen Abfrage einige universelle Ansätze zur Optimierung von Abfragen unter PostgreSQL. Es liegt an Ihnen, ob Sie sie verwenden oder nicht, aber es lohnt sich, sie kennenzulernen.
In einigen zukünftigen Versionen von PG kann sich die Situation mit der "Weisheit" des Schedulers ändern, aber für 9.4 / 9.6 sieht es in etwa genauso aus, wie hier als Beispiele.
Ich nehme eine sehr reale Anfrage an:
SELECT TRUE FROM "" d INNER JOIN "" doc_ex USING("@") INNER JOIN "" t_doc ON t_doc."@" = d."" WHERE (d."3" = 19091 or d."" = 19091) AND d."$" IS NULL AND d."" IS NOT TRUE AND doc_ex.""[1] IS TRUE AND t_doc."" = '' LIMIT 1;
über die Namen von Tabellen und FeldernDie „russischen“ Namen von Feldern und Tabellen können unterschiedlich behandelt werden, dies ist jedoch Geschmackssache. Da
wir in „Tensor“ keine ausländischen Entwickler haben und PostgreSQL es uns erlaubt, Namen auch mit Hieroglyphen zu vergeben, wenn sie
in Anführungszeichen gesetzt sind , bevorzugen wir es, Objekte eindeutig und klar zu benennen, damit es nicht zu Missverständnissen kommt.
Schauen wir uns den resultierenden Plan an:
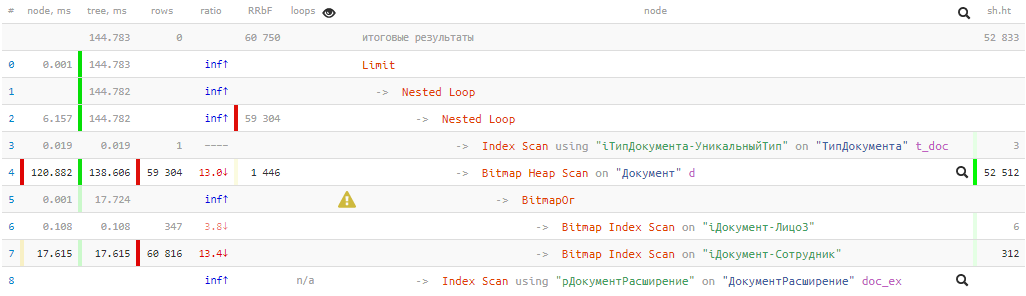 [siehe EXPLAIN.TENSOR.RU]144 ms und fast 53 KB Puffer
[siehe EXPLAIN.TENSOR.RU]144 ms und fast 53 KB Puffer - das sind mehr als 400 MB Daten! Und wir haben Glück, dass sich alle zum Zeitpunkt unserer Anfrage im Cache befinden, da sie sonst um ein Vielfaches länger sind, wenn sie von der Festplatte abgezogen werden.
Der Algorithmus ist am wichtigsten!
Um eine Anfrage irgendwie zu optimieren, müssen Sie zuerst verstehen, was sie überhaupt tun soll.
Im Moment überlassen wir die Entwicklung der Datenbankstruktur dem Geltungsbereich dieses Artikels und sind uns einig, dass wir
die Abfrage relativ „billig“
umschreiben und / oder alle benötigten
Indizes in die Datenbank übernehmen können.
Die Anfrage lautet also:
- prüft, ob mindestens ein Dokument vorhanden ist
- In dem Zustand, den wir brauchen und von einem bestimmten Typ
- wo der Autor oder Vollstrecker der Mitarbeiter ist, den wir brauchen
JOIN + LIMIT 1
Sehr oft ist es für einen Entwickler einfacher, eine Abfrage zu schreiben, bei der zunächst eine große Anzahl von Tabellen verknüpft wird, und dann gibt es von diesem gesamten Satz nur einen Datensatz. Aber einfacher für den Entwickler - bedeutet nicht effizienter für die Datenbank.
In unserem Fall gab es nur 3 Tische - und welche Wirkung ...
Lassen Sie uns zuerst die Verbindung zur Tabelle "TypeDocument" aufheben und gleichzeitig der Datenbank mitteilen, dass unser Typdatensatz
eindeutig ist (wir wissen das, aber der Scheduler hat keine Ahnung):
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' LIMIT 1 ) ... WHERE d."" = (TABLE T) ...
Ja, wenn die Tabelle / CTE aus einem einzelnen Feld eines einzelnen Datensatzes besteht, können Sie in PG stattdessen auch so schreiben
d."" = (SELECT "@" FROM T LIMIT 1)
Lazy Computing in PostgreSQL-Abfragen
BitmapOr vs UNION
In einigen Fällen kostet uns der Bitmap-Heap-Scan eine Menge Geld - zum Beispiel in unserer Situation, wenn genügend Datensätze unter die erforderliche Bedingung fallen. Wir haben es aufgrund der
OR-Bedingung erhalten, die sich im Plan
in eine BitmapOr- Operation
verwandelt hat .
Kehren wir zur ursprünglichen Aufgabe zurück: Sie müssen einen Datensatz finden, der einer der Bedingungen entspricht. Das heißt, Sie müssen nicht alle 59.000 Datensätze nach beiden Bedingungen durchsuchen. Es gibt eine Möglichkeit, eine Bedingung zu ermitteln und erst
dann zur zweiten zu wechseln, wenn bei der ersten keine Bedingung
gefunden wurde . Dieses Design wird uns helfen:
( SELECT ... LIMIT 1 ) UNION ALL ( SELECT ... LIMIT 1 ) LIMIT 1
"External" LIMIT 1 stellt sicher, dass die Suche endet, wenn der erste Datensatz gefunden wird. Und wenn es sich bereits im ersten Block befindet, wird der zweite nicht
ausgeführt (
nie im Plan ausgeführt).
Unter schwierigen Bedingungen „verstecken“
Es gibt einen äußerst unangenehmen Moment in der ersten Anforderung - Überprüfen des Status mithilfe der verknüpften Tabelle "Dokumenterweiterung". Unabhängig von der Wahrheit der übrigen Bedingungen im Ausdruck (z. B.
"Gelöscht" IST NICHT WAHR ) wird diese Verbindung immer hergestellt und ist "die Ressourcen wert". Mehr oder weniger davon werden ausgegeben - hängt von der Größe dieses Tisches ab.
Sie können die Anforderung jedoch so ändern, dass die Suche nach dem zugehörigen Datensatz nur dann erfolgt, wenn dies wirklich erforderlich ist:
SELECT ... FROM "" d WHERE ... AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END
Da wir
für das Ergebnis der verknüpften Tabelle
keine Felder benötigen , können wir den JOIN in eine Bedingung für eine Unterabfrage verwandeln.
Wir lassen die indizierten Felder "außerhalb der Klammern" von CASE, fügen einfache Bedingungen aus dem Datensatz zum WHEN-Block hinzu - und jetzt wird die "schwere" Abfrage nur ausgeführt, wenn zu THEN gewechselt wird.
Mein Nachname ist "Total"
Wir sammeln die resultierende Abfrage mit allen oben beschriebenen Mechanismen:
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' ) ( SELECT TRUE FROM "" d WHERE ("3", "") = (19091, (TABLE T)) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) UNION ALL ( SELECT TRUE FROM "" d WHERE ("", "") = ((TABLE T), 19091) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) LIMIT 1;
Passen Sie die [Unter] -Indizes an
Das geschulte Auge bemerkte, dass die indizierten Bedingungen in den UNION-Untereinheiten geringfügig abweichen - dies liegt daran, dass wir bereits die entsprechenden Indizes auf dem Tisch haben. Und wenn sie nicht da wären, lohnt es sich,
Folgendes zu erstellen:
Dokument (Person3, Dokumenttyp) und
Dokument (Dokumenttyp, Mitarbeiter) .
über die Reihenfolge der Felder in ROW-BedingungenAus Sicht des Planers können Sie natürlich sowohl (A, B) = (constA, constB) als auch (B, A) = (constB, constA) schreiben . Wenn Sie jedoch in der Reihenfolge der Felder im Index schreiben, ist es einfacher, eine solche Anforderung später zu debuggen.
Was ist der Plan?
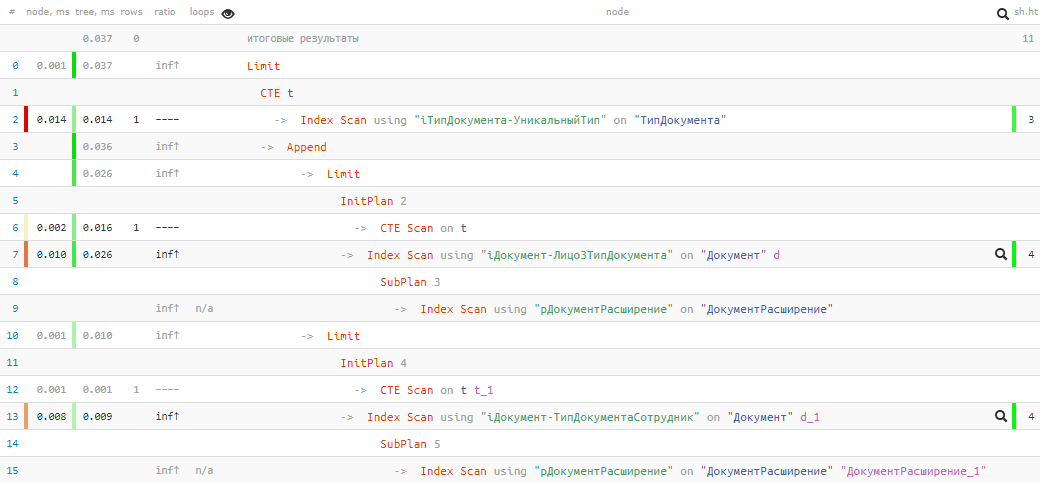 [siehe EXPLAIN.TENSOR.RU]
[siehe EXPLAIN.TENSOR.RU]Leider hatten wir kein Glück und im ersten UNION-Block wurde nichts gefunden, so dass der zweite trotzdem zur Hinrichtung ging. Aber
trotzdem - nur
0.037ms und 11 Puffer !
Wir haben die Anforderung beschleunigt und das "Pumpen" von Daten im Speicher mit relativ einfachen Methoden um
mehrere tausend Mal reduziert - ein gutes Ergebnis mit einem kleinen Einfügevorgang. :)