Hallo habr Mein Name ist Roman und ich möchte heute darüber sprechen, wie wir an der Innopolis University einen Prüfstand und einen Service für das Acronis Active Restore-System entwickelt haben, das bald Teil der Produktlinie des Unternehmens werden sollte. Alle, die daran interessiert sind, wie die Universität Beziehungen zu Industriepartnern aufbaut, lade ich ein, unter cat weiterzumachen.

Die Entwicklung von Active Restore begann innerhalb von Acronis, aber wir als Studenten der Innopolis University haben an diesem Prozess im Rahmen eines industriellen Schulungsprojekts teilgenommen. Mein Kurator (und jetzt Kollege) Daulet Tumbaev schrieb bereits
in seinem Beitrag über die Idee und die Architektur. Heute werde ich darüber sprechen, wie wir den Service von Innopolis vorbereitet haben.
Alles begann im Sommer, als uns mitgeteilt wurde, dass im ersten Semester IT-Unternehmen zu uns kommen und ihre Ideen für die praktische Arbeit anbieten würden. Und so wurden uns im Dezember 2018 15 verschiedene Projekte vorgestellt, und am Ende des Monats setzten wir Prioritäten, um herauszufinden, wem es am besten gefällt.
Alle Studenten füllten ein Formular aus, in dem vier Projekte ausgewählt werden mussten, an denen wir teilnehmen wollten. Es war notwendig zu motivieren, warum ich und warum genau diese Projekte. Ich habe zum Beispiel darauf hingewiesen, dass ich bereits Erfahrung in der Systemprogrammierung und -entwicklung in C / C ++ habe. Vor allem aber ermöglichte mir das Projekt, meine Fähigkeiten zu entwickeln und weiter zu wachsen.
Zwei Wochen später wurden wir beauftragt und ab Beginn des zweiten Semesters begannen die Arbeiten an Projekten. Das Team wurde gebildet, beim ersten Treffen haben wir die Stärken und Schwächen des anderen bewertet und Rollen zugewiesen.
- Roman Rybkin ist ein Python / C ++ - Entwickler.
- Eugene Ishutin - Python / C ++ - Entwickler, verantwortlich für die Interaktion mit dem Unternehmen.
- Anastasia Rodionova ist ein Python / C ++ - Entwickler, der für das Verfassen der Dokumentation verantwortlich ist.
- Brandon Acosta - die Umgebung einrichten, den Stand für Experimente und Tests vorbereiten.
Die ersten zwei Wochen mussten wir den Prozess starten. Wir haben Kontakte zum Kunden geknüpft, die Anforderungen für das Projekt formalisiert, einen iterativen Prozess gestartet und die Arbeitsumgebung eingerichtet.
Übrigens begann unsere Arbeit mit dem Kunden wirklich zu kochen, als wir die Wahlfächer begannen. Tatsache ist, dass Acronis an der Innopolis University (und nicht nur) Fächer der Wahl führt. Alexey Kostyushko, ein führender Entwickler des Kernel-Teams, unterrichtet fortlaufend zwei Kurse: Reverse Engineering und Windows Kernel Architecture and Drivers. Soweit ich weiß, ist in Zukunft auch ein Kurs über Systemprogrammierung und Multi-Threaded-Computing geplant. Das Wichtigste ist jedoch, dass alle diese Kurse so konzipiert sind, dass sie den Studenten helfen, mit Industrieprojekten fertig zu werden. Sie sind sehr bemüht, das Fachgebiet zu verstehen und vereinfachen so die Arbeit am Projekt.
Aus diesem Grund haben wir energischer als andere Teams begonnen und die Interaktion mit Acronis selbst wurde dichter. Alexey Kostyushko war für uns als Product Owner tätig, von ihm erhielten wir die notwendigen Kenntnisse im Fachgebiet. Dank seiner Wahlfächer wurden unsere harten Fähigkeiten und Kompetenzen sehr stark gepumpt und wir wurden wirklich bereit, die Aufgabe zu erfüllen, vor der wir standen.
Vom Gedanken zum Projekt
Der erste Monat für alle Teams war so schwierig wie möglich. Jeder war verloren, wusste nicht, wo er anfangen sollte - vielleicht mit Dokumenten oder umgekehrt, mit Code. Zunächst kamen widersprüchliche Kommentare von Kuratoren und Mentoren der Hochschul- und Unternehmensvertreter.
Als alles stimmte (zumindest in meinem Kopf), wurde klar, dass die Mentoren der Universität uns halfen, interne Beziehungen im Team aufzubauen und Dokumente vorzubereiten. Der eigentliche Durchbruch war jedoch die Ankunft von Daulet im März. Wir haben uns einfach hingesetzt und das ganze Wochenende an dem Projekt gearbeitet. Dann haben wir das Wesentliche des Projekts überarbeitet, neu gestartet, die Prioritäten der Aufgaben neu verteilt und sind schnell vorwärts geflogen. Wir haben verstanden, was zu tun ist, um das Experiment zu starten (etwas später) und den Service zu entwickeln. Von diesem Moment an wurde die allgemeine Idee zu einem klaren Plan. Die eigentliche Entwicklung des Codes begann und in 2 Wochen entwickelten wir die erste Version des Prüfstands, einschließlich virtueller Maschinen, der erforderlichen Dienste und des Codes für die Automatisierung des Experiments und das Sammeln von Daten.
Es ist erwähnenswert, dass es parallel zum Industrieprojekt Schulungen gab, die uns geholfen haben, eine kompetente Architektur für unsere Projekte zu entwickeln und das Qualitätsmanagement zu organisieren. Anfangs nahmen diese Aufgaben 70-90% der Zeit pro Woche in Anspruch, aber es stellte sich heraus, dass Zeit benötigt wurde, um Probleme im Entwicklungsprozess zu vermeiden. Das Ziel der Universität war es, dass wir lernen, den Entwicklungsprozess kompetent zu gestalten, und Unternehmen als Kunden interessierten sich mehr für das Ergebnis. Dies brachte natürlich viel Verwirrung mit sich, half jedoch dabei, theoretische und praktische Fähigkeiten zu kombinieren. Ausreichende Komplexität und Belastung sorgten für das Vorhandensein von Motivation, was zu einem erfolgreichen Projekt führte.
Zu Beginn waren zwei Mitarbeiter in unserem Team mit der reinen Entwicklung beschäftigt, ein Mitarbeiter übernahm die Dokumente und ein anderer war mit der Einrichtung der Umgebung befasst. Später schlossen sich uns jedoch drei weitere Junggesellen an, mit denen wir ein einziges Team bildeten. Die Universität hat beschlossen, ein industrielles Testprojekt für Studenten des dritten Studienjahres zu starten. Die Erweiterung des Teams von 4 auf 7 Personen beschleunigte den Prozess erheblich, da unsere Junggesellen problemlos Aufgaben im Zusammenhang mit der Entwicklung ausführen konnten. Ekaterina Levchenko half beim Schreiben von Python-Code und Batch-Skripten für den Prüfstand. Ansat Abirov und Ruslan Kim waren als Entwickler an der Auswahl und Optimierung von Algorithmen beteiligt.
Wir haben in diesem Format bis Ende Mai gearbeitet, als das Experiment gestartet wurde. In diesem Moment endete das Industrieprojekt für Junggesellen. Zwei von ihnen absolvierten ein Acronis-Praktikum und arbeiteten weiterhin bei uns. Deshalb haben wir nach Mai bereits als ein Team von 6 Personen gearbeitet.
Vor uns lag das dritte Semester, das in Innopolis frei von akademischen Aktivitäten ist. Wir hatten nur 2 Wahlfächer, und der Rest der Zeit wurde für ein Industrieprojekt ausgegeben. Im dritten Semester wurde intensiv am Service gearbeitet. Der Entwicklungsprozess war voll im Gange, Demos und Berichte wurden regelmäßig. In diesem Format haben wir 1,5 Monate gearbeitet und Ende Juli den Entwicklungsteil der Arbeit fast abgeschlossen.
Technische Details
Zunächst wurden die Anforderungen für einen Dienst formuliert, der mit dem Dateisystem-Minifiltertreiber (den Sie
hier lesen können) adäquat interagieren sollte, und seine Architektur wurde durchdacht. Mit Blick auf die Einfachheit der weiteren Codeunterstützung haben wir sofort einen modularen Ansatz bereitgestellt. Unser Service umfasst mehrere Manager, Agenten und Bearbeiter, und bereits vor dem Beginn der Codierung wurde die Fähigkeit zum parallelen Arbeiten festgelegt.
Nach einer Besprechung der Architektur bei einem Treffen mit Acronis-Mitarbeitern wurde jedoch beschlossen, zuerst ein Experiment durchzuführen und dann den Dienst selbst in Anspruch zu nehmen. Infolgedessen dauerte die Entwicklung nur 2,5 Monate. In der restlichen Zeit haben wir ein Experiment durchgeführt, um die Liste der Dateien zu ermitteln, auf denen mindestens Windows ausgeführt werden kann. In einem realen System wird diese Gruppe von Dateien mithilfe des Treibers generiert. Wir haben uns jedoch entschlossen, diese Gruppe heuristisch mithilfe der Halbdivisionsmethode zu ermitteln, um den Betrieb des Treibers zu überprüfen.
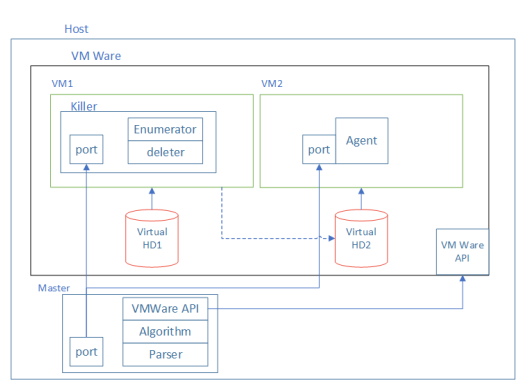 Der Stand des Experiments.
Der Stand des Experiments.
Dazu stellen wir in Python einen Stand aus zwei virtuellen Maschinen zusammen. Einer von ihnen arbeitete unter Linux und der zweite lud Windows. Für sie wurden zwei Festplatten konfiguriert: Virtual HD1 und Virtual HD2. Beide Laufwerke waren mit VM1 verbunden, auf dem Linux installiert war. Auf dieser virtuellen Maschine auf HD1 wurde die Killer-Anwendung installiert, die HD2 „beschädigte“. Schaden bezieht sich auf das Löschen einiger Dateien von der Festplatte. HD2 war eine Bootdiskette für VM2, die unter Windows funktioniert. Nachdem die Festplatte „beschädigt“ war, haben wir versucht, VM2 zu starten. Wenn dies möglich war, wurden die von der Festplatte gelöschten Dateien als nicht erforderlich angesehen.
Um diesen Prozess zu automatisieren, haben wir versucht, Dateien nicht nach dem Zufallsprinzip zu löschen, sondern im Rahmen eines vorgedachten Ansatzes. Der Algorithmus bestand aus 3 Schritten:
- Teilen Sie die Dateiliste in zwei Hälften.
- Löschen Sie eine der halben Dateien.
- Versuchen Sie, das System zu starten. Wenn das System gestartet wurde, fügen Sie die gelöschten Dateien zur Liste der nicht benötigten hinzu. Ansonsten kehren wir zu Schritt 1 zurück.
Zuerst beschlossen wir, den Algorithmus zu simulieren. Angenommen, das Dateisystem enthält 1.000.000 Dateien. In diesem Fall wurde die effektivste Suche nach kritischen Dateien in Fällen durchgeführt, in denen kritische Dateien etwa 15% der Gesamtmenge ausmachten.
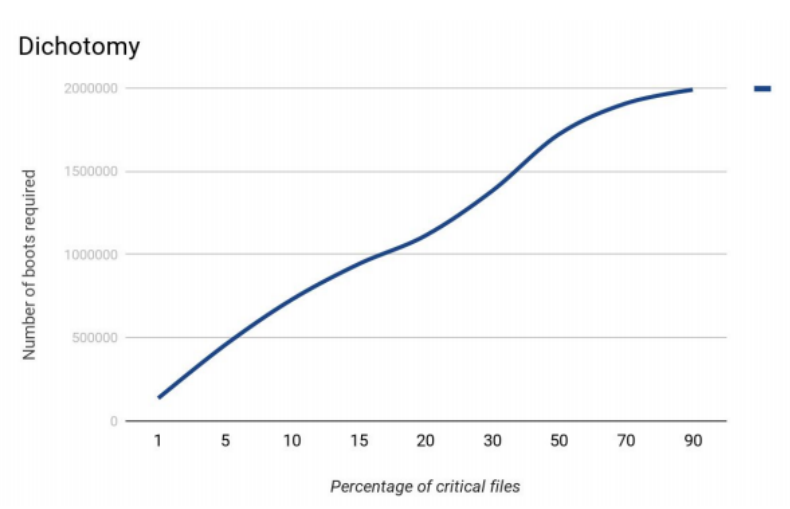 Halbteilungsmethode.
Halbteilungsmethode.Anfangs gab es viele Probleme mit dem Experiment. Für 2-3 Wochen stand ein Prüfstand bereit. Und weitere 1-1,5 Monate musste ich Fehler finden, den Code hinzufügen und verschiedene Tricks anwenden, um den Stand zum Laufen zu bringen.
Am schwierigsten war es, einen Fehler zu finden, der mit dem Zwischenspeichern von Datenträgeroperationen verbunden war. Das Experiment dauerte 2 Tage und lieferte sehr optimistische Ergebnisse, die um ein Vielfaches schneller waren als die Simulationen. Der Test kritischer Dateien ist jedoch fehlgeschlagen, das System wurde nicht gestartet. Es stellte sich heraus, dass während des erzwungenen Herunterfahrens der virtuellen Maschine die vom Dateisystem zwischengespeicherten Löschvorgänge nicht ausgeführt wurden und die Festplatte daher nicht vollständig gelöscht wurde. Infolgedessen hat der Algorithmus falsche Ergebnisse erhalten, und wir haben einige Tage lang alle unsere Windungen auf die Probe gestellt, um alles herauszufinden.
Zu einem bestimmten Zeitpunkt stellten wir fest, dass der Algorithmus im Dauerbetrieb in einem der Segmente des Dateisystems vergraben war und versuchte, dieselben Dateien zu löschen (in der Hoffnung auf ein neues Ergebnis). Dies geschah zu Zeiten, in denen sich der Algorithmus in Regionen befand, in denen die meisten erforderlich waren, während das falsche Intervall zum Löschen ausgewählt wurde. Zu diesem Zeitpunkt haben wir beschlossen, eine Liste mit Umordnungsdateien hinzuzufügen. Das heißt, nach einigen Iterationen wurde die Liste der Dateien gemischt. Dies half, den Algorithmus aus solchen Stöcken herauszuschlagen.
Als alles fertig war, haben wir diese beiden VMs 3 Tage lang gestartet. Insgesamt wurden etwa 600 Iterationen durchgeführt, darunter mehr als 20 erfolgreiche Starts. Es stellte sich heraus, dass dieses Experiment sowohl für längere Zeit als auch auf leistungsstärkeren Computern ausgeführt werden kann, um die optimale Dateigröße für die Ausführung von Windows zu ermitteln. Der Algorithmus kann auch auf mehrere Maschinen verteilt werden, um diesen Prozess weiter zu beschleunigen
In unserem Fall befanden sich neben Windows nur Python und unser Dienst auf der Festplatte. In drei Tagen ist es uns gelungen, die Anzahl der Akten von 70.000 auf 50.000 zu reduzieren. Die Liste der Dateien wurde nur um 28% reduziert, aber es wurde klar, dass dieser Ansatz funktioniert und Sie können die minimale Menge an Dateien bestimmen, die zum Laden des Betriebssystems erforderlich sind.
Servicestruktur
Lassen Sie uns auf eine kleine Servicestruktur eingehen. Das Hauptservicemodul ist ein Warteschlangenmanager. Da wir eine Liste der Dateien vom Treiber erhalten, müssen wir Dateien von dieser Liste wiederherstellen. Zu diesem Zweck haben wir eine Wendung mit Prioritäten erstellt.
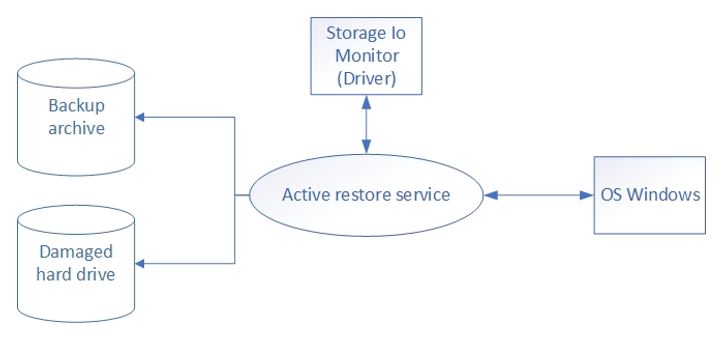
Wir haben eine Liste von Dateien, die nacheinander wiederhergestellt werden. Wenn neue Zugriffsanforderungen angezeigt werden, werden dringend benötigte Dateien vorrangig wiederhergestellt. Aus diesem Grund befinden sich am Anfang der Warteschlange die Dateien, die der Benutzer jetzt wirklich benötigt, und am Ende der Zeile die Dateien, die möglicherweise in Zukunft benötigt werden. Bei aktiver Arbeit des Benutzers können sich jedoch eine „Warteschlange außergewöhnlicher Objekte“ sowie eine Liste der Dateien bilden, die gerade wiederhergestellt werden. Außerdem sollte die Suchoperation auf alle diese Warteschlangen gleichzeitig angewendet worden sein. Leider haben wir keine Implementierung der Warteschlange gefunden, die mehrere Dateiprioritäten festlegen und gleichzeitig die Suche unterstützen und die Prioritäten im laufenden Betrieb ändern könnte. Wir wollten uns nicht an vorhandene Datenstrukturen anpassen und mussten daher unsere eigenen schreiben und die Fähigkeit einrichten, damit zu arbeiten.
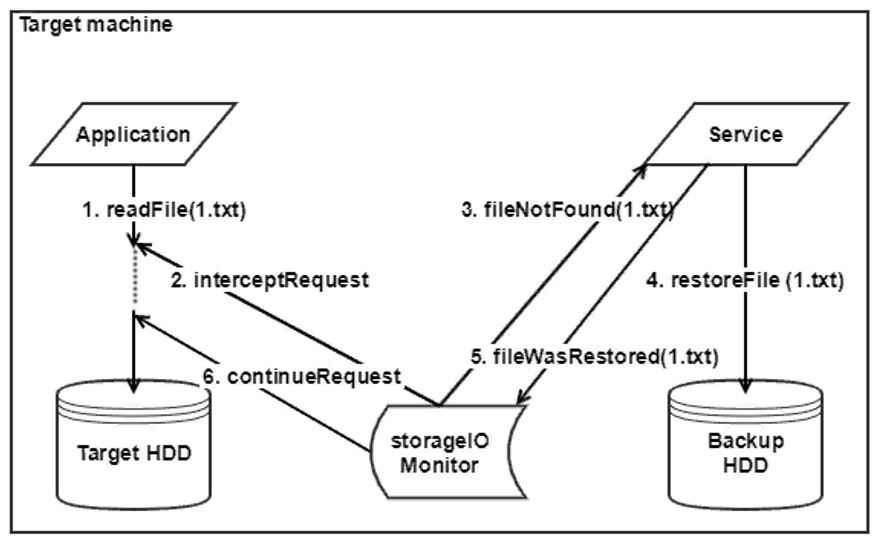
Unser Dienst muss zuerst mit dem Treiber kommunizieren, an dem Daulet gearbeitet hat, und danach mit den Komponenten, die für die Wiederherstellung der Dateien verantwortlich sind. Daher haben wir uns für den Anfang entschieden, einen eigenen kleinen Emulator für das Wiederherstellungssystem zu erstellen, der Dateien von einem externen Laufwerk ausgeben kann, damit diese wiederhergestellt werden können Stellen Sie den Dienst wieder her und testen Sie ihn.
Insgesamt wurden zwei Betriebsmodi bereitgestellt - Normal- und Wiederherstellungsmodus. Im normalen Modus sendet uns der Treiber eine Liste der Dateien, die vom Start des Betriebssystems betroffen sind. Während das System ausgeführt wird, überwacht der Treiber alle Dateivorgänge, sendet Benachrichtigungen an unseren Dienst und ändert die Liste der Dateien. Im Wiederherstellungsmodus benachrichtigt der Treiber den Dienst, dass eine Systemwiederherstellung erforderlich ist. Der Dienst stellt Dateien in die Warteschlange, führt Software-Agenten aus, die Dateien von der Sicherung anfordern, und startet den Wiederherstellungsprozess.
Diplom, Berufseinladung und neue Projekte
Als der Service fertig und getestet war, hatten wir die letzte Aktivität im Projekt. Es war notwendig, alle von uns gesammelten Artefakte zu aktualisieren und zu strukturieren sowie dem Kunden und der Universität unsere Ergebnisse zu präsentieren. Für das Unternehmen war dies ein weiterer Schritt zur Umsetzung des Projekts, für die Universität mit unserer Abschlussarbeit.
Im Anschluss an die Präsentation wurde den Studierenden ein Vorschlag unterbreitet. Und nach ein paar Wochen gehe ich zu Acronis. Die Ergebnisse des Projekts veranlassten die Entwickler zu der Annahme, dass es möglich ist, den Dienst effizienter zu gestalten, indem er auf die Ebene der nativen Windows-Anwendung gesenkt wird. Aber mehr dazu im nächsten Artikel.