PostgreSQL verwendet akkumulierte Statistiken zur Verteilung der Datenwerte in den Zieltabellen, um den effizientesten Abfrageausführungsplan auszuwählen.
Die Aktualisierung erfolgt durch explizite Ausführung der Befehle
ANALYZE und
VACUUM ANALYZE oder im Hintergrund durch die
automatische Vakuum- / Autoanalyse . Wenn die Statistiken jedoch nicht aktualisiert werden können, kann dies zu Problemen führen.
Wie kann man ein solches Problem erkennen und beheben?
Die Hauptoption, wenn eine solche Situation überhaupt eintreten kann, ist, wenn sich der Datensatz in der Tabelle dramatisch geändert hat. Das heißt, es wurde
eine große Anzahl von INSERT / UPDATE / DELETE-Vorgängen ausgeführt oder die Daten einfach in eine leere Tabelle
"gegossen" - beispielsweise
beim Wiederherstellen von einer Sicherung .
In der Hilfe zum Standard-
Wiederherstellungsdienstprogramm pg_restore heißt es sogar explizit:
Nach der Wiederherstellung ist es sinnvoll, ANALYZE für jede wiederhergestellte Tabelle auszuführen, damit der Optimierer aktuelle Statistiken erhält.
Wenn Sie also etwas Ähnliches mit der Datenbank tun - seien Sie nicht faul, führen Sie
ANALYZE sofort für die "
fettesten " Tabellen oder für die gesamte Datenbank aus.
Wir stellen fest, ob ein Problem vorliegt
Wodurch sieht die "alles schlechte" Situation genau aus? Normalerweise ungefähr so:
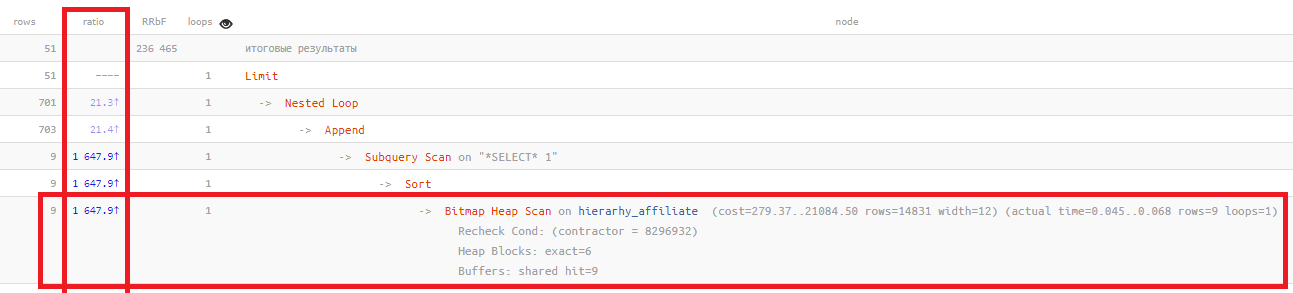
Die
Verhältnisspalte zeigt nur die Beziehung "zu Zeiten" zwischen der Anzahl der auf der Grundlage von Statistiken geplanten Datensätze und der tatsächlich gelesenen Anzahl:
Bitmap Heap Scan on ... (... rows=14831 ...) (actual ... rows=9 ...)
Je höher dieser Wert, desto schlechter spiegeln die Statistiken die tatsächliche Situation in Ihrer Tabelle wider. Normalerweise
überschreitet es Hunderte nicht , in diesem Beispiel
eineinhalbtausend Mal .
Dies führt zur Wahl eines ineffektiven Plans und damit zur
wildesten Belastung der Basis . Um es schnell zu entfernen, müssen Sie sich nur die Empfehlungen des Handbuchs anhören und
ANALYZE in den
Haupttabellen durchgehen.
Hier ist die CPU-Last auf dem Datenbankserver vor und nach dieser Operation für das obige Beispiel:
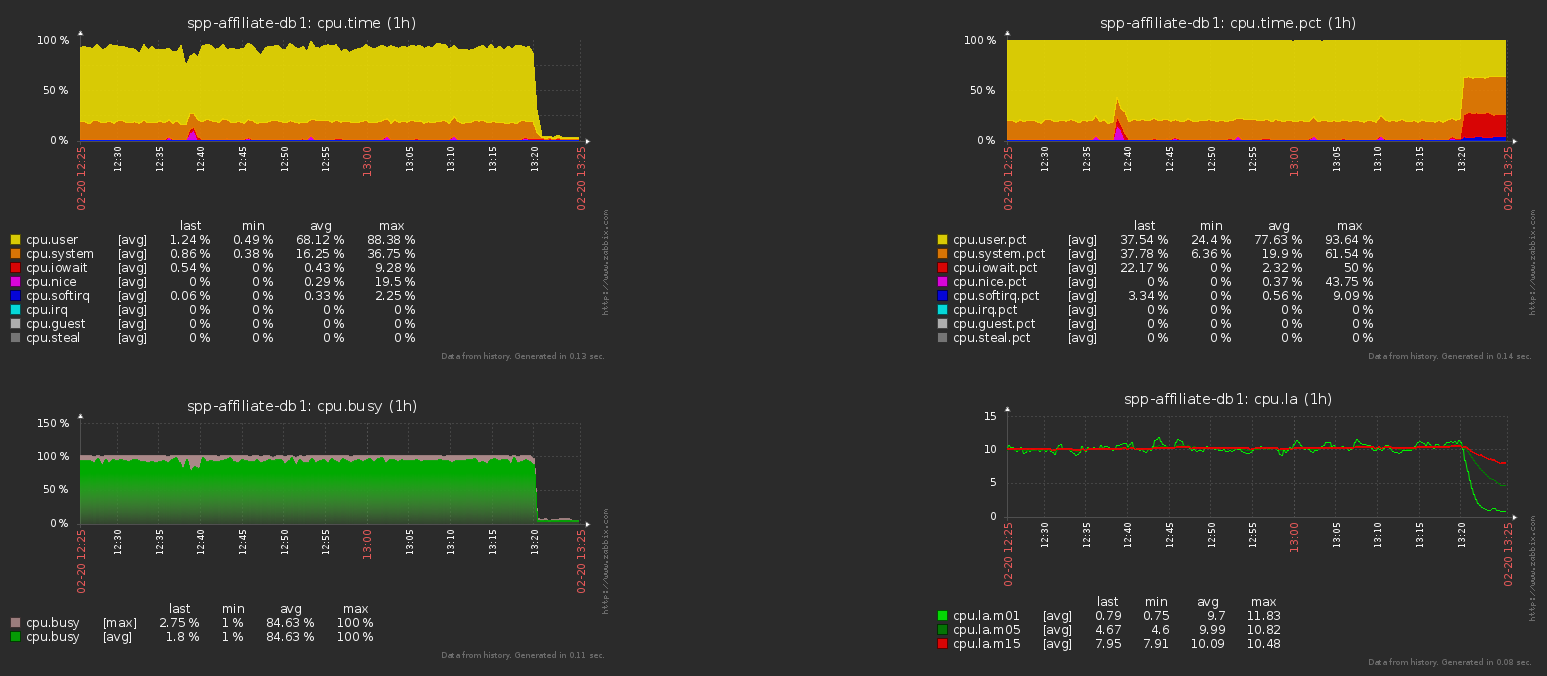
Häufig aktualisierte Tabelle
Aber was ist, wenn die Tabelle wirklich eine große Anzahl von Datensätzen ändert? Dies ist beispielsweise eine Art Puffer oder Verarbeitungswarteschlange, in der ständig neue Datensätze hinzugefügt und alte gelöscht werden.
In diesem Fall helfen uns die folgenden
Konfigurationsparameter :
autovacuum_naptime (integer)
Legt die Mindestverzögerung zwischen zwei automatischen Bereinigungsläufen für eine einzelne Datenbank fest. Der Daemon für die automatische Bereinigung durchsucht die Datenbank in dem angegebenen Zeitintervall und gibt die Befehle VACUUM und ANALYZE aus, wenn dies für die Tabellen in dieser Datenbank erforderlich ist. Wenn dieser Wert ohne Einheiten angegeben wird, wird er als in Sekunden festgelegt betrachtet. Standardmäßig beträgt die Verzögerung eine Minute (1 Minute). Dieser Parameter kann nur in postgresql.conf oder in der Befehlszeile festgelegt werden, wenn der Server gestartet wird.
autovacuum_analyze_threshold (integer)
Legt die minimale Anzahl von hinzugefügten, geänderten oder gelöschten Tupeln fest, bei denen ANALYZE für eine einzelne Tabelle ausgeführt wird. Der Standardwert ist 50 Tupel. Dieser Parameter kann nur in postgresql.conf oder in der Befehlszeile festgelegt werden, wenn der Server gestartet wird. Dieser Wert kann jedoch für ausgewählte Tabellen überschrieben werden, indem deren Speichereinstellungen geändert werden.
autovacuum_analyze_scale_factor (Gleitkomma)
Gibt den Prozentsatz der Tabellengröße an, der zu autovacuum_analyze_threshold hinzugefügt wird, wenn der Befehlsschwellenwert ANALYZE ausgewählt wird. Der Standardwert ist 0.1 (10% der Tabellengröße). Sie können diesen Parameter nur in postgresql.conf oder in der Befehlszeile festlegen, wenn der Server gestartet wird. Dieser Wert kann jedoch für ausgewählte Tabellen überschrieben werden, indem deren Speichereinstellungen geändert werden.
SWSS
Manchmal wird
autovacuum_naptime beim Einrichten eines Servers auf "einmal pro Tag" (1d) "
komprimiert ", sodass
autoVACUUMs seltener in der Datenbank unterwegs sind und weniger Ressourcen
verbrauchen .
Manchmal, wenn auch sehr selten, kann dies sogar gerechtfertigt sein - zum Beispiel, wenn Sie
Tausende von Tabellen / Abschnitten in einer Datenbank haben (auch wenn sie in unterschiedlichen Mustern angeordnet sind).
Da bei der Initialisierung des automatischen Vakuumprozesses genau festgelegt wird, welche bestimmten Tabellen aus der gesamten Liste verarbeitet werden müssen,
kann dies einen erheblichen Teil der Ressourcen in Anspruch
nehmen und den Server verlangsamen .
In diesem Fall haben Sie Probleme mit einer häufig geänderten Tabelle.
Hier - entweder ein angemesseneres Startintervall einstellen oder ANALYZE anhand einer solchen Tabelle im manuellen Modus aus bestimmten Gründen (z. B. einem externen Timer oder nach dem Ende der nächsten Stufe der Warteschlangenverarbeitung) ausführen.
Genosse, halten Sie die Statistiken auf dem neuesten Stand!