Dies ist wahrscheinlich kein Artikel, sondern eine kurze Anmerkung zu einigen Funktionen der Arbeit mit großen Tabellen in MySQL.
Der Grund für das Schreiben war das scheinbar alltägliche Hinzufügen einer neuen Spalte zur Tabelle. Aber es stellte sich heraus, dass nicht alles so einfach war wie erwartet.
Also, eines Abends, um unsere lieben Kunden nicht zu stören, mussten wir dem Tisch eine Spalte hinzufügen.
Um es klarer zu machen, die Eigenschaften der Tabelle und Basis:
- Tischgröße 110 GB
- Anzahl der Zeilen: 7,5 Millionen
- Speicher-Engine: InnoDB
- Es gibt zwei SQL-Server, die gemäß dem Master-Slave-Schema verbunden sind, während sich der Master auf der SSD und der Slave auf der Festplatte befindet
Es scheint eine naheliegende Lösung für das Hinzufügen einer Spalte zu sein - Alter Table.
alter table table_name add source varchar(32)
Wir haben es benutzt (ja, wir haben verstanden, dass es schlecht war, aber in diesem speziellen Fall waren die Risiken minimal).
Die Ergebnisse waren ziemlich unangenehm:
- Auf dem Assistenten dauerte der Prozess des Hinzufügens einer Spalte ungefähr eine Stunde (!)
- auf dem sklaven begann es nach abschluss des prozesses auf dem master und dauerte ca. 8 stunden (!!)
- Während der Änderungstabelle wurde die Datenreplikation (!!!) auf dem Slave vollständig gestoppt
Aber es gibt einen Silberstreifen: Ein kleiner Bonus war, dass nach dem Hinzufügen einer Spalte die Größe des Tisches um 10% abnahm.
In den folgenden Grafiken ist es deutlich sichtbar.
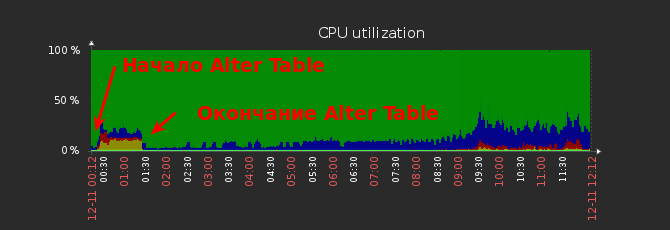 Grafik zur CPU-Auslastung im Assistenten.
Grafik zur CPU-Auslastung im Assistenten. CPU-Lastdiagramm auf dem Slave.
CPU-Lastdiagramm auf dem Slave. Replikationsverzögerung.
Replikationsverzögerung.Welche Probleme erwarten diejenigen, die dies an Schlachttischen tun?
Erstens können Sie für die Dauer der Änderungstabelle keine Daten in die Tabelle schreiben (aber Sie können sie lesen). Tatsächlich hängt es von der Version von MySQL ab, in letzterer ist es nicht der Fall, aber Sie müssen trotzdem verstehen, wozu Ihre Version in der Lage ist, um Probleme zu vermeiden.
Wenn die Tabelle also groß ist, ist die Nichtverfügbarkeitszeit erheblich (wie bei uns bei Verwendung einer SSD eine Stunde und bei einer regulären Festplatte 8 Stunden), was Ihre Kunden wahrscheinlich nicht erwarten werden.
Zweitens wurde, wie in unserem Fall, während der Ausführung der Alter-Tabelle die
Synchronisation aller Tabellen , nicht nur der von uns geänderten, auf dem Slave
vollständig gestoppt . Wenn Ihre Daten auf dem zweiten Server kritisch sind und aktuell sein sollten, besteht daher die Gefahr, dass Sie keine Aktualisierungen mit allen daraus resultierenden Konsequenzen vornehmen.
Ein weiterer nicht offensichtlicher Punkt, auf den wir beim Hinzufügen einer Spalte gestoßen sind (dies war jedoch ein anderes Mal) -
zusätzlicher Speicherplatz wird benötigt .
Tatsache ist, dass einige Änderungen an den Tabellen die Tabelle von Grund auf neu erstellen, sodass Sie nicht weniger Platz benötigen als eine vorhandene Tabelle. Für große Tische wird, gelinde gesagt, viel Platz benötigt. Gemäß der Dokumentation wird eine temporäre Tabelle im selben Verzeichnis wie das Original erstellt.
Darüber hinaus werden während der Ausführung aller Arten von Alter Table alle Änderungen in die Protokolldatei geschrieben, sodass nach den Änderungen ein Rollover der Daten über den Zeitraum durchgeführt werden kann, in dem der Vorgang ausgeführt wurde. Auch hier kann eine unangenehme Überraschung auf Sie warten: Wenn sich die Tabelle über einen längeren Zeitraum ändert und das Betriebsvolumen groß ist, endet möglicherweise nicht nur der Speicherplatz, sondern auch die in den SQL-Einstellungen angegebene Dateigrößenbeschränkung wird möglicherweise überschritten. In jedem Fall erwartet Sie „der Online-DDL-Vorgang schlägt fehl und nicht festgeschriebene gleichzeitige DML-Vorgänge werden zurückgesetzt“.
Wir waren mit der Tatsache konfrontiert, dass das Verzeichnis für temporäre Dateien klein war,
weshalb wir
innodb_tmpdir neu definieren
mussten .
So können Sie feststellen, wohin die Variable gerade zeigt:
select @@GLOBAL.innodb_tmpdir;
Denken Sie daran, dass die Größe des temporären Verzeichnisses möglicherweise auch die Größe einer Tabelle + Indizes benötigt. Im Allgemeinen sollten Sie sich mit Platz eindecken.
Um die Dokumentation nicht zu wiederholen, lesen Sie ausführlicher unter
https://dev.mysql.com/doc/refman/5.7/de/innodb-online-ddl-space-requirements.htmlAber wie geht das? Tatsächlich gibt es kein einziges Rezept für alle Gelegenheiten.
Eine der möglichen Optionen, wie wir es für Tabellen tun, die für die Aktualisierung nicht kritisch sind:
- Erstellen Sie eine neue Tabelle mit der gewünschten Struktur
- Füllen Sie die Felder aus der alten Tabelle aus
- Löschen Sie eine alte Tabelle oder benennen Sie sie um
- Benenne das neue um
Ich wiederhole, dass dies für nicht kritische Aktualisierungstabellen funktioniert. Gleichzeitig wird das Blockieren der Replikation vermieden. Es ist zu beachten, dass das Ausfüllen einer neuen Tabelle so erfolgen muss, dass die Replikation fortgesetzt werden kann. Da sie sequentiell ausgeführt wird, können Sie nicht mit einem einzelnen SQL-Ausdruck arbeiten, sondern müssen ihn in mehrere kleine Abfragen aufteilen, zwischen denen die Replikation anderer Daten stattfindet. In anderen Fällen sind andere Optionen möglich, möglicherweise teilt jemand die Kommentare mit.
UPD
Syavadee schlug vor, das Percona Online-Schema zu ändern. Tatsächlich implementiert es den oben beschriebenen Algorithmus mit zusätzlichen Extras.
UPD
Arheops empfiehlt, die parallele Replikation / gtid zu aktivieren, um Replikationsprobleme zu lösen.
Um zu verstehen, wie groß die Tabelle ist und wie viele Zeilen sie enthält, müssen Sie im Übrigen manchmal lernen
select count(*) from table_name
Bei großen und geladenen Tabellen ist dies jedoch auch nicht die schnellste Operation, insbesondere wenn Sie über eine halbe Million Zeilen oder mehr verfügen.
Daher können Sie für eine ungefähre Schätzung des Volumens die folgende Methode verwenden:
SHOW TABLE STATUS FROM express where name='table_name'
Leider kann die resultierende Größe der InnoDB-Engine um 50 Prozent abweichen (in unserem Fall liegt die tatsächliche Anzahl der Datensätze in der obigen Tabelle bei etwa 7,5 Millionen, und diese Methode ergab nur 5 Millionen), dies ist jedoch durchaus für eine indikative Schätzung geeignet.
Das ist alles, ich hoffe, dieser Hinweis hilft jemandem, große Probleme mit vermeintlich harmlosen SQL-Befehlen zu vermeiden.