Hallo Habr!
Home Credit ist ein großes und sehr dynamisches System, das manchmal schwer im Auge zu behalten ist. Um die Mitarbeiter über alle Neuigkeiten und Änderungen auf dem Laufenden zu halten und überall auf dem Laufenden zu bleiben, führen wir aktiv Algorithmen für maschinelles Lernen ein. In unserer Bank übernehmen Chat-Bots bereits einen Teil der Arbeit von Betreibern, Kundenbewertungen werden nicht nur von Experten, sondern auch von intelligenten Algorithmen zur Verarbeitung natürlicher Sprache analysiert.
Heute werde ich Ihnen erzählen, wie wir den Spezialisten für Bankdienstleistungen geholfen haben, die Notwendigkeit zu beseitigen, ständig auf die Dashboards von Überwachungssystemen zu schauen. Sie forderten nämlich maschinelles Lernen, um zu helfen. Das haben wir.

Wie funktioniert die manuelle Überwachung?
Ein typischer Arbeitsplatz eines Bedienungsfachmanns sieht wie im obigen Bild aus und er verbringt die meiste Zeit damit, sich mit Dashboards zu befassen. Jede verdächtige Aktivität im System, zum Beispiel wenn das Netzwerk ausgefallen ist oder eine NullPointerException ausfällt, wird sofort auffallen - eine Untersuchung wird sofort gestartet.
Der Mensch ist keine Maschine. Er kann abgelenkt sein, zum Abendessen gehen, ans Telefon gehen. Und wenn die Anzahl der Graphen mehr als einhundert beträgt, wird es schwierig, sie alle zusammenzufügen und der Essenz auf den Grund zu gehen.
Ein weiteres Problem ist, dass es eine Reihe von Fehlern gibt, die ständig auftreten, das Verhalten des Systems jedoch nicht ernsthaft beeinträchtigen. Beispielsweise fiel ein Mikroservice eines Drittanbieters aus, und die Dashboards wurden merklich erschüttert. Tatsächlich ist das System jedoch außer Gefahr. Auf den ersten Blick ist nicht immer klar, wie anormales Verhalten kritisch ist und was dahinter steckt. Um die Gründe im Detail zu ermitteln, müssen Sie zum Server gehen und sich eingehend mit den Protokollen befassen. Eine solche Operation muss Dutzende Male am Tag durchgeführt werden. Vertrauen wir sie zumindest teilweise dem Auto an.
Maschinelles Lernen als kluger Assistent
Es gibt drei Hauptdatenquellen: Zabbix, ElasticSearch und ein internes System zur Überwachung von Geschäftskennzahlen. Wir verwenden Zabbix, um die Hardware, das Netzwerk und die Verfügbarkeit verschiedener Einstiegspunkte in die Systeme zu überwachen. Analysieren und extrahieren Sie das Nachrichtenprotokoll mit ElasticSearch. Verschiedene Fehler, Ausführungen und Abfragen werden als Metriken verwendet. Geschäftsanalysten überwachen jedoch die Leistung der Benutzer: Anzahl der Übertragungen, Verkäufe und andere Geschäftsaktivitäten. Die Daten werden einmal pro Minute erfasst und der Datenbank hinzugefügt. Nun, die Daten werden gesammelt, es ist Zeit, eine Reihe von Fragen zu schreiben, um maschinelles Lernen in den Kampf zu ziehen.
Wir formulieren das Problem wie folgt: Wenn wir die Systemmetriken am Eingang haben, klassifizieren wir den Endzustand des Systems: regulär oder abnormal. In dieser Situation passt das Problem perfekt zum Paradigma des Lernens mit einem Lehrer. Dies bedeutet, dass unser gesamter Trainingsdatensatz gekennzeichnet werden muss. Mit anderen Worten, jede Minute der Systemoperation sollte mit 0 (normales Verhalten) oder -1 (anomales Verhalten) gekennzeichnet sein.
Im Leben stellt sich heraus, dass nicht alles so rosig ist, wie wir möchten. In der Regel werden nicht alle Vorfälle in JIRA aufgezeichnet, vieles verbleibt in der Post und geht nicht darüber hinaus, und manchmal sind die Fristen der Anomalie verschwommen oder ungenau. Es stellt sich heraus, dass die Erstellung eines qualitativ hochwertigen Datensatzes im Bereich der historischen Daten keine triviale Aufgabe ist.
Während die neuen Daten gerade erst angelegt werden, versuchen wir, den Nutzen aus dem herauszuholen, was wir bereits haben. In Fällen, in denen die Daten kein Markup haben, werden Lernalgorithmen ohne Lehrer verwendet. Wir gehen davon aus, dass das System die meiste Zeit korrekt funktioniert, aber gelegentlich unvorhergesehene Ereignisse eintreten: Fehler (wo ohne sie), die Basis fielen ab oder zum Beispiel der Bagger Petr traf das Kabel des Rechenzentrums. Daher reduzieren wir unsere Aufgabe auf die Suche nach Anomalien, nämlich die Suche nach einem neuen Systemverhalten (Novelty Detection).
Verwenden Sie dazu den Isolated Forest-Algorithmus. Es ist bereits in der sklearn-Bibliothek implementiert. Wir werden Metriken von Überwachungssystemen als Merkmale verwenden.
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
Wir werden den isolierten Wald anhand historischer Daten trainieren und die neuen Daten, die wir bereits zur Kennzeichnung herangezogen haben, zur Bewertung der Qualität verwenden. Es bleibt also die Wahl der Modell-Hyperparameter und der Datensatzgröße für das Training.
Jetzt werden die Statusdaten, die jede Minute gesammelt werden, in das trainierte Modell eingegeben und erhalten die Bezeichnung 0 oder -1.
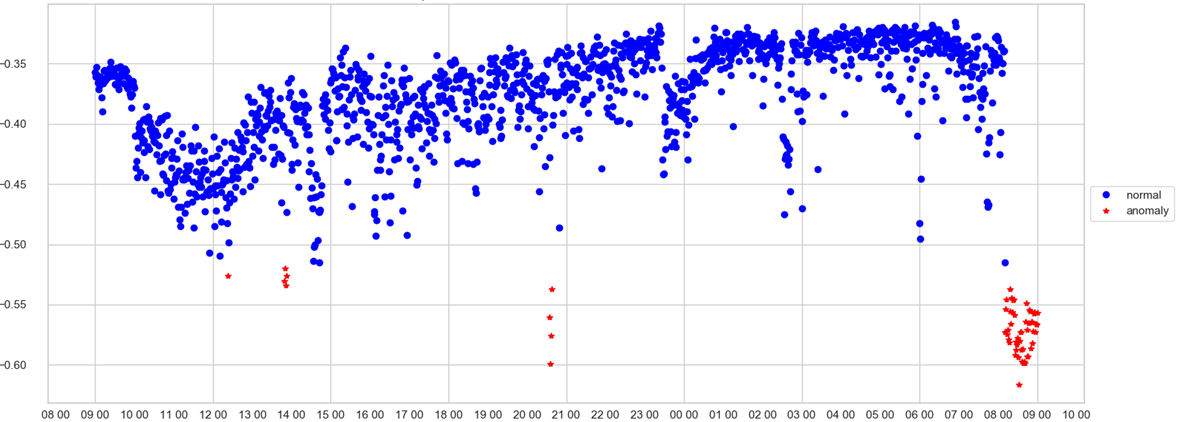
Ein Bediener kann nur einen Zeitplan verfolgen. Auf der X - Achse - Zeit, auf der Y - Anomalie - Punktzahl, das heißt, wie stark das Modell den Zustand des Systems in dieser Minute als abnormal betrachtete. Wenn der Geschwindigkeitswert den Papierkorb passiert hat (den das Modell selbst auswählt), wird der Punkt rot getönt und eine Anomalie aufgezeichnet.
Jetzt erfahren wir, dass das System in einem ungewöhnlichen Modus arbeitet oder dass eine Notfallsituation in nahezu Echtzeit eingetreten ist. Das ist sehr schön, aber was ist mit dem Bediener zum Zeitpunkt des Empfangs des Signals über die Anomalie? Welches Dashboard soll man anschauen? Lassen Sie uns versuchen, die „Black Box“ unseres Modells zu öffnen und zu verstehen, wie es Entscheidungen trifft.
Interpretation eines Modells mit LIME
Es gibt verschiedene Ansätze, um die Black Box eines trainierten Modells zu öffnen und zu verstehen, was die Maschine beschäftigt. Mit einer logistischen Regression oder einem Entscheidungsbaum ist alles klar, es ist nicht schwer zu verstehen, auf deren Grundlage die Entscheidung getroffen wurde. Mit Isolated Forest sind die Dinge komplizierter. Erstens gibt es einen Unfall im Algorithmus, und zweitens handelt es sich um einen Lernalgorithmus ohne Lehrer.
Der erste Kandidat war die LIME-Bibliothek, die den modellunabhängigen Ansatz verwendet, der bei der Interpretation von Modellen hilft. Die Hauptsache ist, dass die Ausgabe des Modells eine Wahrscheinlichkeitsverteilung zwischen Klassen aufweist. Okay, natürlich ist das Ergebnis nicht die Wahrscheinlichkeit, aber bald, aber versuchen wir, sie im Bereich von 0 bis 1 zu normalisieren und sie als Wahrscheinlichkeit zu behandeln. So konnten wir ein mit LIME kompatibles Eingabeformat bereitstellen.
Die Interpretation der Ergebnisse durch LIME war enttäuschend. Erstens gab es als Interpretation mehrere wichtige Anzeichen am Ausgang, und in den meisten Fällen spiegelte nur eines die Essenz der Entscheidung wirklich angemessen wider, während der Rest Rauschen hinzufügte. Der zweite Nachteil bestand darin, dass die Interpretation instabil war und häufig von Lauf zu Lauf unterschiedliche Anzeichenlisten hervorbrachte. Um stabilere Ergebnisse zu erzielen, mussten Sie die Interpretation mehrmals ausführen und die Ergebnisse irgendwie mitteln. Das wollte ich eigentlich nicht.
SHAP - Brücke von Person zu Auto
Danach fiel unser Blick auf eine andere Bibliothek zur Interpretation von Modellen - SHAP. Die Idee hinter der Bibliothek kam aus der Spieltheorie. Die Bibliothek hat auch eine schöne Visualisierung. Nachdem wir uns die Beispiele angesehen hatten, stellten wir frustriert fest, dass SHAP den isolierten Wald nicht interpretieren konnte und wir wollten es wirklich! Andererseits kann SHAP XGBoost sicher sezieren. Wir dachten uns, was ist, wenn wir lernen, XGBoost genau so zu machen, wie es Isolated Forest kann? Dazu haben wir unseren gesamten Datensatz genommen und ihn mit Isolated Forest markiert. Außerdem nahmen sie als Ziel keine Klasse, sondern eine Wertung, die dem Isolierten Wald zugeteilt wurde. Wir werden anhand aller Messdaten die Geschwindigkeit vorhersagen, die Isolated Forest bieten würde, aber nur mit XGBoot! Gesagt, getan. Wir werden unseren mit Tags versehenen Datensatz über XGBoost ausführen. Und jetzt, jetzt weiß er, wie man Geschwindigkeit vorhersagt, genau wie bei Isolated Forest. Hurra, jetzt können wir SHAP benutzen!
Der erste Schritt besteht darin, ein TreeExplainer-Objekt zu erstellen und das Modell selbst als Parameter zu übergeben. Als nächstes werden die Shap-Werte berechnet, anhand derer wir erklären können, wie das Modell diese oder jene Entscheidung getroffen hat.
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
Mit SHAP können Sie sowohl das gesamte Modell als auch die Ergebnisse für bestimmte Beispiele interpretieren. Beispielsweise können Sie mithilfe der force_plot () -Methode, die die Eingabewerte und die Werte des Beispiels selbst empfängt, eine Erklärung für ein bestimmtes Beispiel abrufen.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
Das folgende Diagramm zeigt, welche Funktionen des Modells und wie stark die Entscheidung beeinflusst haben.

Wir helfen dem Geschäft
Wenn nun bekannt ist, welche Metriken einen signifikanten Beitrag zur Gesamtanormalitätsrate geleistet haben, kann festgestellt werden, auf welcher Ebene das Problem aufgetreten ist und vor allem, ob es sich auf die Endbenutzer des Systems ausgewirkt hat.

Jedes Mal, wenn eine Anomalie erkannt wird, wird eine Liste von Metriken erstellt, die den größten Einfluss auf die Entscheidung haben. Wenn die Liste Metriken enthält, mit denen geschäftsbezogene Indikatoren direkt verfolgt werden, wird dies in der Warnung in besonderer Weise erwähnt, wodurch die Priorität der Anomalie automatisch erhöht wird.
Dies ist nur der erste, aber wichtige Schritt zur Stärkung und Automatisierung des Überwachungssystems mithilfe von maschinellem Lernen, wodurch die Ermittlung der Ursachen und des Einflusses von abnormalem Systemverhalten erheblich beschleunigt werden kann.
Referenzen:scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap