 Quelle
QuelleHallo habr Mein Name ist Maxim Pchelin und ich leite die Entwicklung von BI-DWH bei MyGames (Gaming Division der Mail.ru Group). In diesem Artikel werde ich darüber sprechen, wie und warum wir einen kundenorientierten DataLake-Speicher erstellt haben.
Der Artikel besteht aus drei Teilen. Zunächst erkläre ich, warum wir uns für die Implementierung von DataLake entschieden haben. Im zweiten Teil werde ich beschreiben, welche Technologien und Lösungen wir verwenden, damit der Speicher funktionieren und mit Daten gefüllt werden kann. Und im dritten Teil beschreibe ich, was wir tun, um die Qualität unserer Dienstleistungen zu verbessern.
Was hat uns zu DataLake gebracht?
Wir bei
MyGames arbeiten in der BI-DWH-Abteilung und bieten Dienstleistungen in zwei Kategorien an: ein Repository für Datenanalysten und regelmäßige Berichterstellungsdienste für Geschäftsanwender (Manager, Vermarkter, Spieleentwickler und andere).
Warum so ein nicht standardmäßiger Speicher?
In der Regel impliziert BI-DWH nicht die Implementierung von DataLake-Speicher, dies kann nicht als typische Lösung bezeichnet werden. Und wie werden dann solche Dienste aufgebaut?
Normalerweise hat ein Unternehmen ein Projekt - in unserem Fall ist dies ein Spiel. Das Projekt verfügt über ein Protokollierungssystem, das am häufigsten Daten in die Datenbank schreibt. Darüber hinaus werden Storefronts für Aggregate, Metriken und andere Entitäten für zukünftige Analysen erstellt. Die regelmäßige Berichterstellung basiert auf Storefronts mit einem geeigneten BI-Tool sowie Ad-Hoc-Analysesystemen, angefangen bei einfachen SQL-Abfragen und Excel-Tabellen bis hin zum Jupyter Notebook für DS und ML. Das gesamte System wird von einem Entwicklungsteam unterstützt.
Angenommen, eine andere Firma wird in einer Firma geboren. Ein anderes Entwicklungsteam und eine andere Infrastruktur zu haben, ist attraktiv, aber teuer. Das Projekt muss also "angeschlossen" werden. Dies kann auf verschiedene Arten geschehen: auf Datenbankebene, auf Storefront-Ebene oder zumindest auf Anzeigeebene - das Problem ist behoben.
Und wenn das Unternehmen ein drittes Projekt hat? Das „Teilen“ kann bereits zu einem schlechten Ende führen: Möglicherweise treten Probleme bei der Zuweisung von Ressourcen oder Zugriffsrechten auf. Zum Beispiel wird eines der Projekte von einem externen Team durchgeführt, das nichts über die ersten beiden Projekte wissen muss. Die Situation wird riskanter.
Stellen Sie sich vor, es gibt nicht drei Projekte, sondern viel mehr. Und so geschah es, dass genau dies unser Fall ist.
MyGames ist einer der größten Geschäftsbereiche der Mail.ru Group. Wir haben 150 Projekte in unserem Portfolio. Darüber hinaus sind sie alle sehr unterschiedlich: ihre eigene Entwicklung und für Operationen in Russland gekauft. Sie arbeiten auf verschiedenen Plattformen: PC, Xbox, Playstation, iOS und Android. Diese Projekte werden in zehn Büros auf der ganzen Welt mit Hunderten von Entscheidungsträgern entwickelt.

Für Unternehmen ist dies eine großartige Sache, erschwert jedoch die Aufgabe für das BI-DWH-Team.
In unseren Spielen werden viele Spieleraktionen protokolliert: Als er das Spiel betrat, wo und wie er die Level bekam, mit wem und wie erfolgreich er gekämpft hat, was und für welche Währung er gekauft hat. Wir müssen all diese Daten für jedes Spiel sammeln.
Wir brauchen dies, damit das Unternehmen Antworten auf seine Fragen zu den Projekten erhält. Was ist letzte Woche nach dem Start der Aktion passiert? Wie sehen unsere Prognosen für den Umsatz oder die Auslastung der Spieleserverkapazitäten für den nächsten Monat aus? Was kann getan werden, um diese Prognosen zu beeinflussen?
Es ist wichtig, dass MyGames den Projekten kein Entwicklungsparadigma auferlegt. Jedes Spielstudio zeichnet Daten auf, da es dies für effizienter hält. Einige Projekte generieren Protokolle auf der Clientseite, andere auf der Serverseite. Einige Projekte verwenden RDBMS, um sie zu sammeln, während andere völlig andere Tools verwenden: Kafka, Elasticsearch, Hadoop, Tarantool oder Redis. Und wir greifen auf diese Datenquellen zurück, um sie in das Repository hochzuladen.
Was möchten Sie von unserem BI-DWH?
Zunächst möchten sie von der BI-DWH-Abteilung Daten zu allen unseren Spielen erhalten, um sowohl tägliche als auch strategische Aufgaben zu lösen. Beginnend damit, wie viele Leben ein schreckliches Monster am Ende des Levels beschert und wie die Ressourcen im Unternehmen richtig verteilt werden: Welche Projekte sollten mehr Entwickler bescheren oder wer sollte ein Marketingbudget zuweisen?
Zuverlässigkeit wird auch von uns erwartet. Wir arbeiten in einem großen Unternehmen und können nicht nach dem Prinzip „Gestern haben wir gearbeitet, aber heute ist das System vorhanden, und es wird sich erst in einer Woche entwickeln, wenn wir uns etwas einfallen lassen.“
Sie wollen Ersparnisse von uns. Gerne lösen wir alle Probleme, indem wir Eisen kaufen oder Leute einstellen. Aber wir sind eine kommerzielle Organisation und können es uns nicht leisten. Wir versuchen, dem Unternehmen Gewinn zu bringen.
Wichtig ist, dass sie Kundenorientierung von uns wollen. Kunden sind in diesem Fall unsere Verbraucher, Kunden: Manager, Analysten usw. Wir müssen uns an unsere Spiele anpassen und so arbeiten, dass es für Kunden bequem ist, mit uns zusammenzuarbeiten. Zum Beispiel können wir in einigen Fällen, wenn wir Projekte auf dem asiatischen Markt für Operationen kaufen, zusammen mit dem Spiel Basen mit Namen auf Chinesisch erhalten. Und die Dokumentation für diese Grundlagen auf Chinesisch. Wir könnten nach einem ETL-Entwickler mit Chinesischkenntnissen suchen oder das Herunterladen von Spieldaten verweigern. Stattdessen schließen wir uns in den Besprechungsraum ein, nehmen die Uhr und fangen an zu spielen. Das Spiel betreten und verlassen, kaufen, schießen, sterben. Und wir schauen, was und wann in dieser oder jener Tabelle erscheint. Dann schreiben wir die Dokumentation und bauen auf deren Basis ETL.
In diesem Fall ist es wichtig, die Kante zu fühlen. Es ist ein unzulässiger Luxus, sich in die einzigartige Protokollierung eines Spiels mit einer DAU von 50 Personen zu vertiefen, wenn Sie einem Projekt mit einer DAU von 500.000 in der Nähe helfen müssen. Wir können uns also natürlich sehr viel Mühe geben, um eine maßgeschneiderte Lösung zu entwickeln, aber nur, wenn das Geschäft dies wirklich benötigt.
Sobald Entwickler, insbesondere Anfänger, jedoch hören, dass sie sich auf diese Weise anpassen müssen, haben sie den Wunsch, dies niemals zu tun. Jeder Entwickler möchte eine ideale Architektur erstellen, diese niemals ändern und Artikel darüber auf Habr schreiben.
Aber was passiert, wenn wir aufhören, uns an unsere Spiele anzupassen? Angenommen, wir fordern sie auf, Daten an eine einzelne Eingabe-API zu senden. Das Ergebnis wird eins sein - jeder wird anfangen sich zu zerstreuen.
- Einige Projekte werden anfangen, ihre BI-DWH-Lösungen mit Vorliebe und Dichterinnen zu kürzen. Dies führt zu doppelten Ressourcen und Schwierigkeiten beim Datenaustausch zwischen Systemen.
- Andere Projekte werden die Erstellung ihres BI-DWH nicht beeinflussen, aber sie werden sich auch nicht an unsere anpassen wollen. Und wieder andere verwenden keine Daten mehr, was noch schlimmer ist.
- Nun, und was am wichtigsten ist, das Management wird keine aktuellen systematischen Informationen darüber haben, was in den Projekten vor sich geht.
Können wir Speicher auf einfache Weise implementieren?
150 Projekte sind viel. Die Lösung sofort für alle umzusetzen ist zu lang. Das Geschäft wird nicht ein Jahr auf die ersten Ergebnisse warten. Aus diesem Grund haben wir drei Projekte mit maximalem Umsatz ausgewählt und den ersten Prototyp für sie implementiert. Wir wollten wichtige Daten daraus sammeln und Basis-Dashboards mit den beliebtesten Messwerten erstellen - DAU, MAU, Umsatz, Registrierungen, Aufbewahrung sowie ein bisschen Wirtschaftlichkeit und Prognosen.
Wir konnten die Spielebasen der Projekte selbst dafür nicht nutzen. Erstens würde dies die designübergreifende Analyse erschweren, da Daten aus mehreren Datenbanken aggregiert werden müssen. Zweitens arbeiten die Spiele selbst auf diesen Datenbanken, was wichtig ist, damit die Master und Repliken nicht überlastet werden. Schließlich löschen alle Spiele zu einem bestimmten Zeitpunkt den gesamten Datenverlauf, den sie nicht benötigen, in ihren Datenbanken, was für die Analyse nicht akzeptabel ist.
Daher besteht die einzige Möglichkeit darin, alles, was Sie für die Analyse benötigen, an einem einzigen Ort zu sammeln. Zu diesem Zeitpunkt passte jede relationale Datenbank oder jedes Klartext-Repository zu uns. Wir würden BI schrauben und Dashboards bauen. Es gibt viele Möglichkeiten für Kombinationen solcher Lösungen:

Aber wir haben verstanden, dass wir später alle anderen 150 Spiele abdecken müssen. Möglicherweise kann eine relationale Clusterdatenbank die generierte Datenmenge verarbeiten. Die Quellen befinden sich aber nicht nur in völlig unterschiedlichen Systemen, sondern haben auch sehr unterschiedliche Datenstrukturen. Wir treffen relationale Strukturen, Data Vault und andere. Es wird nicht funktionieren, all dies in einer Datenbank ohne komplexe und mühsame Tricks unterzubringen.
All dies führte uns zu dem Verständnis, dass wir einen DataLake erstellen müssen.
Implementierung von DataLake
Erstens ist DataLake Storage für unsere Bedingungen geeignet, da es uns ermöglicht, unstrukturierte Daten zu speichern. DataLake kann zu einem zentralen Einstiegspunkt für alle Quellen werden, angefangen bei Tabellen aus RDBMS bis hin zu JSON, das wir von Kafka oder Mongo aus versenden. Infolgedessen kann DataLake die Grundlage für designübergreifende Analysen werden, die auf der Grundlage von Schnittstellen für verschiedene Benutzer implementiert werden: SQL, Python, R, Spark usw.
Wechseln Sie zu Hadoop
Für DataLake haben wir die naheliegende Lösung gewählt - Hadoop. Insbesondere seine Montage aus Cloudera. Mit Hadoop können Sie mit unstrukturierten Daten arbeiten. Durch Hinzufügen von Datenknoten können Sie diese problemlos skalieren. Darüber hinaus wurde dieses Produkt gut untersucht, sodass die Antwort auf jede Frage im Bereich Stackoverflow zu finden ist und keine Ressourcen für Forschung und Entwicklung aufgewendet werden müssen.
Nach der Implementierung von Hadoop haben wir das folgende Diagramm unseres ersten Unified Storage erhalten:

Daten wurden aus einer kleinen Anzahl von Quellen in Hadoop gesammelt und anschließend mit mehreren Schnittstellen versehen: BI-Tools und -Services für Ad-Hoc-Analysen.
Weitere Ereignisse entwickelten sich unerwartet: Unser Hadoop startete perfekt, und Kunden, für die Daten in den Laden flossen, gaben alte Analysesysteme auf und nutzten das neue Produkt täglich für ihre Arbeit.
Aber es entstand ein Problem: Je mehr Sie tun, desto mehr wollen sie von Ihnen. Sehr schnell forderten Projekte, die bereits in Hadoop integriert waren, mehr Daten an. Und diejenigen Projekte, die noch nicht hinzugefügt wurden, begannen danach zu fragen. Die Anforderungen an die Stabilität begannen stark zuzunehmen.
Gleichzeitig ist es nicht sinnvoll, das Team linear zu vergrößern. Wenn zwei DWH-Entwickler mit zwei Projekten fertig werden, können wir für vier Projekte keine weiteren Entwickler einstellen. Deshalb sind wir erstmal den anderen Weg gegangen.
Prozesseinrichtung
Bei begrenzten Ressourcen ist die kostengünstigste Lösung die Optimierung von Prozessen. Darüber hinaus ist es in einem großen Unternehmen unmöglich, einfach eine Speicherarchitektur zu entwickeln und diese zu implementieren. Müssen mit einer großen Anzahl von Menschen verhandeln.
- Zuallererst mit Geschäftsvertretern, die Ressourcen für die Analyse bereitstellen. Sie müssen nachweisen, dass Sie nur die Aufgaben Ihrer Kunden ausführen müssen, die dem Unternehmen zugute kommen.
- Sie müssen auch mit Analysten verhandeln, damit diese Ihnen eine Gegenleistung für die von Ihnen angebotenen Services bieten - Systemanalyse, Geschäftsanalyse, Testen. Zum Beispiel gaben wir die Systemanalyse unserer Datenquellen an Analysten weiter. Natürlich sind sie nicht glücklich, aber sonst wird es einfach niemanden geben, der das tut.
- Zu guter Letzt müssen Sie mit den Spielentwicklern verhandeln: Installieren Sie SLAs und einigen Sie sich auf eine Datenstruktur. Wenn die Felder ständig verschwinden, angezeigt und umbenannt werden, werden Sie unabhängig von der Größe des Teams immer Ihre Hände vermissen.
- Sie müssen auch mit Ihrem eigenen Team verhandeln: Suchen Sie einen Kompromiss zwischen idealen Lösungen, die alle Entwickler erstellen möchten, und Standardlösungen, die nicht so interessant sind, die sich aber billig und schnell nieten lassen.
- Es wird notwendig sein, sich mit den Administratoren über die Überwachung der Infrastruktur abzustimmen. Sobald Sie über zusätzliche Ressourcen verfügen, ist es jedoch besser, einen eigenen DevOps-Spezialisten im Speicherteam zu beauftragen.
An dieser Stelle könnte ich den Artikel beenden, wenn eine solche Variante des Repository alle dafür festgelegten Ziele erfüllen würde. Aber das ist nicht so. Warum?
Vor Hadoop konnten wir Daten und Statistiken für fünf Projekte bereitstellen. Mit der Implementierung von Hadoop und ohne Verstärkung des Teams konnten wir 10 Projekte abdecken. Nach der Festlegung der Prozesse hat unser Team bereits 15 Projekte betreut. Das ist cool, aber wir haben 150 Projekte, wir brauchten etwas Neues.
Airflow-Implementierung
Zunächst haben wir mit Cron Daten aus Quellen gesammelt. Zwei Projekte sind normal. 10 - es tut weh, aber ok. Mittlerweile werden jedoch täglich ca. 12.000 Prozesse geladen, um 150 Projekte in DataLake zu laden. Cron ist nicht mehr geeignet. Dazu benötigen wir ein leistungsstarkes Tool zum Verwalten von Daten-Download-Streams.
Wir haben uns für den Open Source Airflow Task Manager entschieden. Er wurde in den Eingeweiden von Airbnb geboren und danach nach Apache versetzt. Dies ist ein Tool für codegesteuertes ETL. Das heißt, Sie schreiben ein Skript in Python und es wird in eine DAG (Directed Acyclic Graph) konvertiert. DAGs eignen sich hervorragend zur Aufrechterhaltung von Abhängigkeiten zwischen Tasks. Sie können keine Storefront mit noch nicht geladenen Daten erstellen.
Airflow hat einen großartigen Fehlerbehandler. Wenn ein Prozess abstürzt oder ein Problem mit dem Netzwerk vorliegt, startet der Dispatcher den Prozess so oft neu, wie Sie dies angegeben haben. Wenn beispielsweise viele Fehler aufgetreten sind und sich die Tabelle in der Quelle geändert hat, wird eine Benachrichtigung angezeigt.
Airflow hat eine großartige Benutzeroberfläche: Sie zeigt bequem an, welche Prozesse ausgeführt werden, welche erfolgreich abgeschlossen wurden oder einen Fehler aufweisen. Wenn Aufgaben mit Fehlern gestürzt sind, können Sie sie über die Schnittstelle neu starten und den Prozess durch Überwachung steuern, ohne in den Code zu gelangen.
Airflow ist anpassbar und basiert auf Operatoren. Dies sind Plugins für die Arbeit mit bestimmten Quellen. Einige Betreiber sind sofort einsatzbereit, viele haben die Airflow-Community angeschrieben. Wenn Sie möchten, können Sie Ihren eigenen Operator erstellen, die Oberfläche hierfür ist sehr einfach.
Wie verwenden wir den Luftstrom?
Zum Beispiel müssen wir eine Tabelle aus PostgreSQL in Hadoop laden. Die Task
sql_sensor_battle_log prüft, ob die Quelle die Daten enthält, die wir für gestern benötigen. In diesem
load_stg_data_from_battle_log Task
load_stg_data_from_battle_log Daten aus dem PG und fügt sie Hadoop hinzu. Schließlich führt
load_oda_data_from_battle_log die anfängliche Verarbeitung durch, beispielsweise die Konvertierung von der Unix-Zeit in die vom Menschen lesbare Zeit.
In einer solchen Aufgabenkette werden Daten von einer Entität in einer Quelle abgerufen:

Und so - von allen Entitäten, die wir brauchen, aus einer Hand:
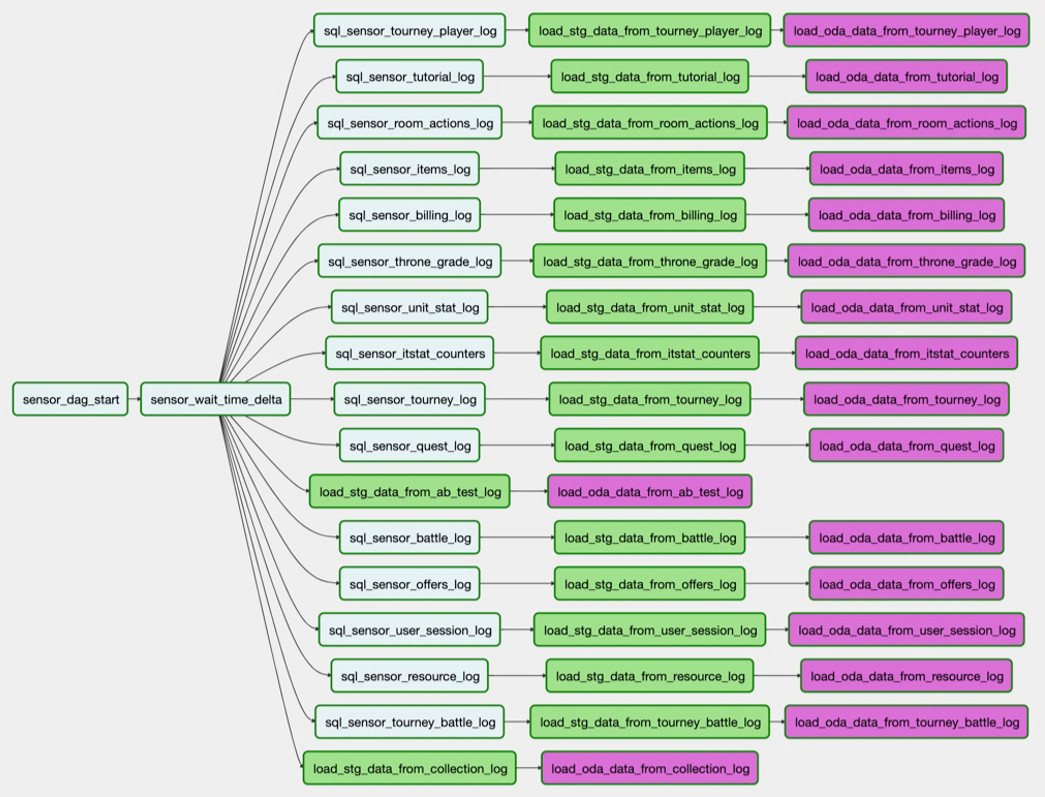
Diese Gruppe von Downloads ist die DAG. Derzeit verfügen wir über 250 solcher DAGs, mit denen Rohdaten geladen, verarbeitet, transformiert und Storefronts erstellt werden können.
Das aktualisierte Unified Storage-Schema sieht wie folgt aus:
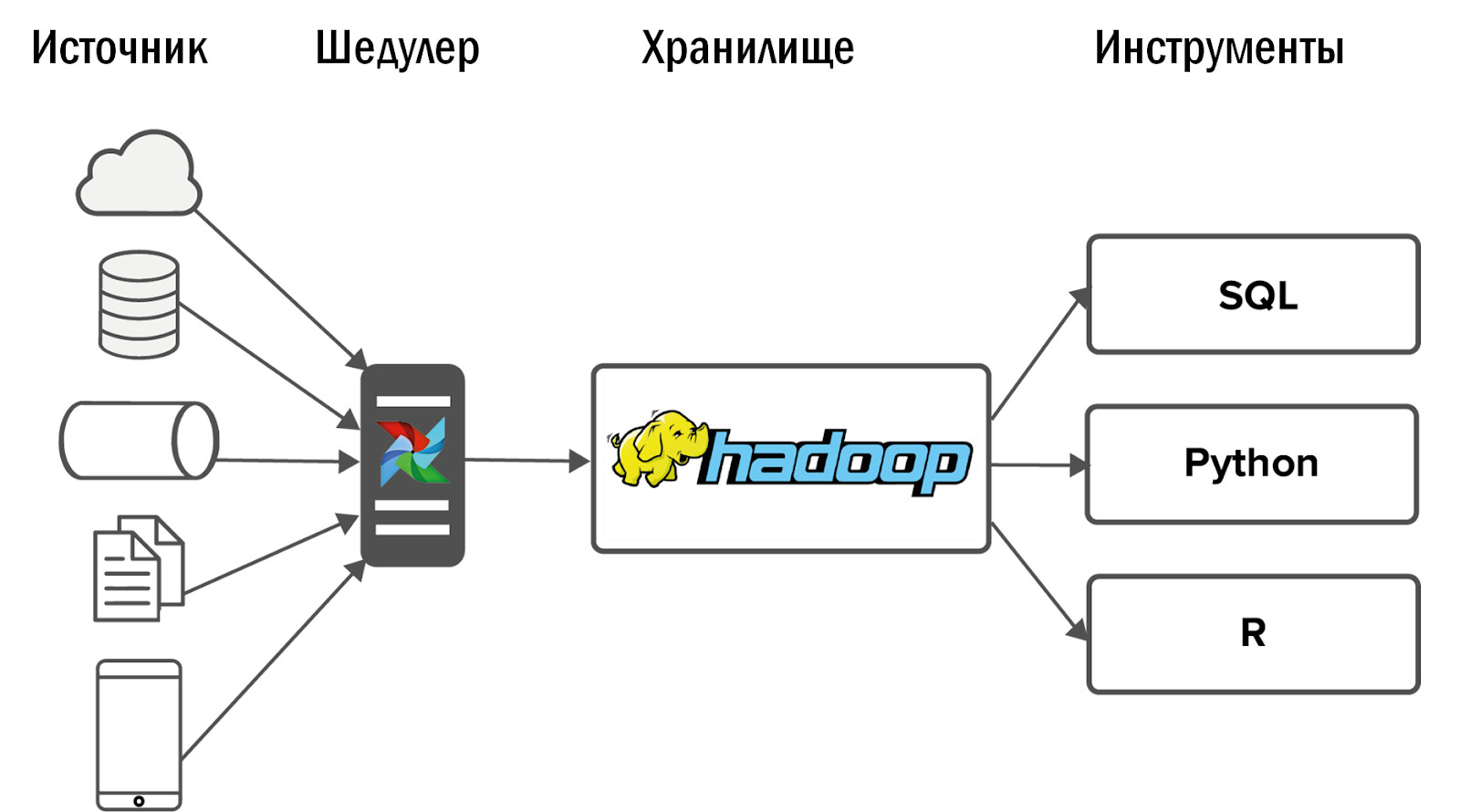
- Nach der Einführung von Airflow konnten wir die Anzahl der Bezugsquellen deutlich steigern - bis zu 400 Stück. Datenquellen sind sowohl interne (aus unseren Spielen) als auch externe: gekaufte Statistiksysteme, heterogene APIs. Mit Airflow können wir täglich 12.000 Prozesse ausführen und steuern, die Daten aus all unseren 150 Spielen verarbeiten.
- Ausführlicher über unseren Luftstrom schrieb Dean Safina in ihrem Artikel ( https://habr.com/ru/company/mailru/blog/344398/ ). Treten Sie auch der Airflow-Community über Telegram ( https://t.me/ruairflow ) bei. Viele Fragen zu Airflow können mithilfe der Dokumentation gelöst werden. Manchmal werden jedoch weitere benutzerdefinierte Anforderungen angezeigt: Wie kann ich Airflow in Docker packen, warum funktioniert das nicht am dritten Tag und so weiter? Dies kann in dieser Community beantwortet werden.
Was in DataLake zu verbessern
Zu diesem Zeitpunkt sind die DWH-Entwickler zuversichtlich, dass alles bereit ist und Sie sich jetzt beruhigen können. Leider oder zum Glück gibt es in DataLake noch etwas zu verbessern.
Datenqualität
Bei einer großen Anzahl von Tabellen in DataLake leidet zuerst die Datenqualität. Nehmen Sie zum Beispiel einen Tisch mit Zahlungen. Es enthält user_id, Betrag, Datum und Uhrzeit der Zahlung:
Täglich werden ungefähr 10 Tausend Zahlungen getätigt:

Einmal in der Tabelle für den Tag kamen nur 28 Einträge. Ja, und user_id ist alles leer:
Wenn plötzlich etwas in unserer Quelle kaputt geht, werden wir dank Airflow sofort davon erfahren. Aber wenn es formal Daten gibt und auch im richtigen Format, dann erfahren wir nicht sofort von der Aufschlüsselung und schon von den Datenkonsumenten. Es ist nicht realistisch, unsere 5000 Tische mit eigenen Händen zu überprüfen.
Um dies zu verhindern, haben wir ein eigenes Datenqualitätskontrollsystem (DQ) entwickelt. Täglich überwacht es die wichtigsten Downloads in unser Repository: Es verfolgt plötzliche Änderungen in der Anzahl der Zeilen, sucht nach leeren Feldern und prüft, ob Daten dupliziert wurden. Das System wendet auch benutzerdefinierte Prüfungen von Analysten an. Darauf aufbauend benachrichtigt sie die Mail darüber, was wo schief gelaufen ist. Analysten gehen zu Projekten und finden heraus, warum beispielsweise zu wenig Daten vorhanden sind, beseitigen die Gründe und laden die Daten erneut.
Priorisieren Sie Downloads
Mit der zunehmenden Anzahl von Aufgaben zum Laden von Daten in DataLake entsteht schnell ein Prioritätskonflikt. Die übliche Situation: Einige nicht so wichtige Projekte haben nachts alle Ressourcen mit ihren Downloads in Anspruch genommen, und die Tabellen, die zur Berechnung der Kennzahlen für das Top-Management benötigt werden, haben zu Beginn des Arbeitstages keine Zeit zum Laden. Wir gehen auf verschiedene Arten damit um.
- Überwachen von Schlüsseldownloads. Airflow verfügt über ein eigenes SLA-System, mit dem Sie feststellen können, ob alle Schlüssel rechtzeitig eingegangen sind. Wenn einige Daten nicht geladen sind, werden wir dies einige Stunden früher als die Benutzer herausfinden und Zeit haben, dies zu beheben.
- Priorität einstellen. Dazu verwenden wir das Airflow-Warteschlangen- und Prioritätssystem. Es ermöglicht uns, die Ladereihenfolge von DAGs und die Anzahl der parallelen Prozesse in ihnen zu bestimmen. Es ist nicht sinnvoll, Protokolle hochzuladen, die vierteljährlich analysiert werden, bevor Daten für Kennzahlen des Top-Managements heruntergeladen werden.
Überwachung der Dauer der Nachtreihe
Wir haben ein Sammellager. Nachts bauen wir gerade daran, und es ist wichtig, dass genügend Nacht zur Verfügung steht, um die tägliche Charge zu verarbeiten. Ansonsten stehen den Analysten während der Arbeitszeit nicht genügend Speicherressourcen zur Verfügung, um zu arbeiten. Wir lösen dieses Problem regelmäßig auf verschiedene Arten:
- Umgekehrte Skalierung. Wir versenden nicht alle Daten, sondern nur das, was die Analysten benötigen. Wir überwachen alle geladenen Tabellen, und wenn eine davon sechs Monate lang nicht verwendet wird, schalten wir das Laden ab.
- Kapazitätsaufbau. Wenn wir verstehen, dass wir durch die Netzwerkfähigkeiten, die Anzahl der Kerne oder die Festplattenkapazität begrenzt sind, fügen wir Hadoop Datenknoten hinzu.
- Optimierung des Luftstroms der Arbeiter. Wir tun alles, damit jeder Teil unseres Systems zu jedem Zeitpunkt der Speicherbauzeit optimal genutzt wird.
- Refactoring nicht optimaler Prozesse. Zum Beispiel betrachten wir die Wirtschaftlichkeit eines frischen Spiels und es dauert 5 Minuten. Aber nach einem Jahr wachsen die Daten und die gleiche Anfrage wird 2 Stunden lang bearbeitet. Irgendwann müssen wir uns auf eine inkrementelle Neuberechnung einstellen, obwohl dies zu Beginn als unnötige Komplikation erscheinen könnte.
Ressourcensteuerung
Es ist wichtig, nicht nur Zeit zu haben, um das Repository für den Beginn des Arbeitstages fertig vorzubereiten, sondern auch, um danach die Verfügbarkeit seiner Ressourcen zu überwachen. Damit können sich im Laufe der Zeit Schwierigkeiten ergeben. Der Grund dafür ist, dass Analysten suboptimale Abfragen schreiben. Auch hier werden die Analysten selbst immer mehr. In diesem Fall ist es am einfachsten, die Hardwarekapazität zu erhöhen. Eine nicht optimale Anforderung beansprucht jedoch immer noch alle verfügbaren Ressourcen. Das heißt, früher oder später werden Sie ohne nennenswerten Nutzen Geld für Eisen ausgeben. Aus diesem Grund verwenden wir mehrere andere Ansätze.
- Zitat: Wir überlassen den Nutzern zumindest ein wenig Ressourcen. Ja, Anforderungen werden langsam ausgeführt, aber zumindest werden sie ausgeführt.
- Überwachung der verbrauchten Ressourcen: Wie viele Kerne werden von Benutzeranforderungen verwendet, die die Verwendung von Partitionen in Hadoop vergessen haben und den gesamten Arbeitsspeicher in Anspruch genommen haben usw. Außerdem sind diese Überwachungen für die Analysten selbst sichtbar, und wenn bei ihnen etwas nicht funktioniert, finden sie selbst den Schuldigen und lösen sie ihn. Wenn wir nur wenige Projekte hätten, würden wir den Ressourcenverbrauch selbst verfolgen. Aber bei so vielen müssten wir ein separates, ständig wachsendes Überwachungsteam einstellen. Und auf lange Sicht ist das unvernünftig.
- Freiwillige Benutzerschulung. Analysten schreiben keine Qualitätsabfragen in Ihr Repository. Ihre Aufgabe ist es, geschäftliche Fragen zu beantworten. Und außer uns - dem Repository-Team - kümmert sich niemand um die Qualität der Analystenanfragen. Aus diesem Grund erstellen wir häufig gestellte Fragen und Präsentationen, halten Vorlesungen für unsere Analysten und erklären, wie wir mit unserem DataLake arbeiten können und wie nicht.
In der Tat ist es viel wichtiger, Zeit für die Bereitstellung von Daten zu investieren, als sie auszufüllen. Wenn sich Daten im Speicher befinden, diese jedoch nicht verfügbar sind, sind sie aus geschäftlicher Sicht immer noch vorhanden, und Sie haben sich bereits um das Herunterladen bemüht.
Flexibilität in der Architektur
Es ist wichtig, die Flexibilität des gebauten DataLake nicht zu vergessen und keine Angst zu haben, die Architektur zu ändern, wenn die Eingabefaktoren geändert werden: Welche Daten müssen in den Speicher hochgeladen werden, wer verwendet sie und wie. Wir glauben nicht, dass unsere Architektur immer unverändert bleibt.
Zum Beispiel haben wir ein neues Handyspiel gestartet. Sie schreibt JSON von Clients an Nginx, Nginx wirft Daten an Kafka, wir analysieren sie mit Spark und fügen sie in Hadoop ein. Alles funktioniert, die Aufgabe ist erledigt.
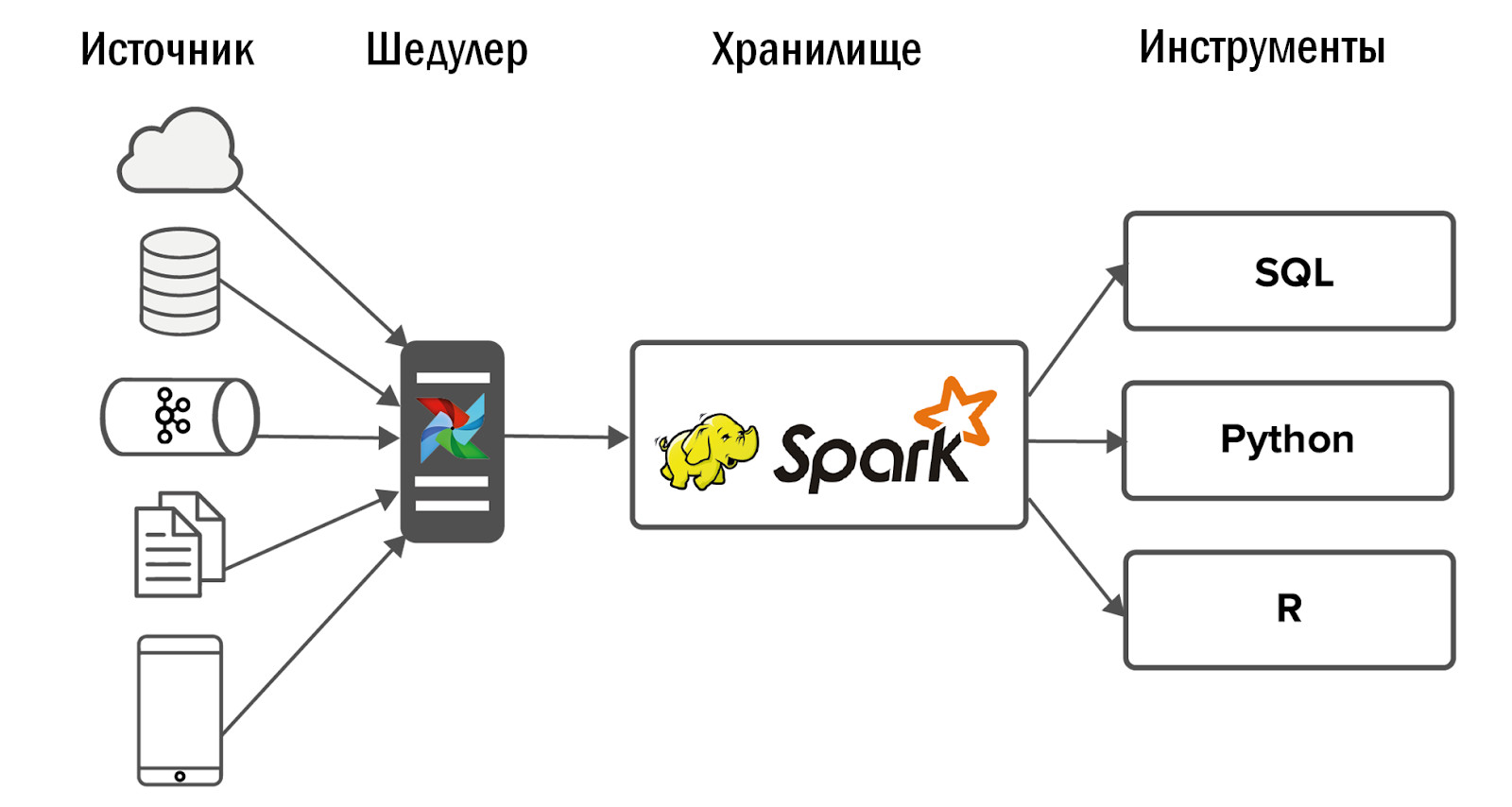
Ein paar Monate vergingen, und in der Lagerung begannen alle Prozesse der Nachtcharge länger zu laufen. Wir fangen an herauszufinden, was los ist: Es hat sich herausgestellt, dass beim Spielstart 50-mal mehr Daten generiert wurden und Spark die JSON-Analyse nicht bewältigen konnte, wodurch die Hälfte der Speicherressourcen aufgebraucht wurde. Zu Beginn wurden alle Daten an ein Kafka-Thema gesendet und Spark sortierte sie in verschiedene Entitäten. Wir haben Spieleentwickler gebeten, Daten über Kunden mit verschiedenen Entitäten zu teilen und sie in separate Kafka-Themen zu unterteilen. Es wurde einfacher, aber nicht lange. Dann haben wir beschlossen, von der täglichen JSON-Analyse auf die stündliche umzustellen. Der Bau des Lagers begann jedoch nicht nur nachts, sondern rund um die Uhr, was für uns nicht wünschenswert war. Nach solchen Versuchen, dieses Problem zu lösen, haben wir Spark aufgegeben und ClickHouse implementiert.

Es hat eine großartige JSON-Parsing-Engine, die Daten sofort in Tabellen zerlegt. Wir senden zuerst Informationen von Kafka an ClickHouse und holen sie von dort in Hadoop ab. Dies hat unser Problem vollständig gelöst.
Natürlich versuchen wir, keine Zoosysteme in unserem DataLake-Speicher zu züchten, aber wir versuchen, die am besten geeigneten Technologien für bestimmte Aufgaben auszuwählen.
War es das wert?
Hat es sich gelohnt, Hadoop, ein Qualitätskontrollsystem, einzusetzen, sich mit Airflow zu befassen und Geschäftsprozesse einzurichten? Natürlich hat es sich gelohnt:
- Das Unternehmen verfügt über aktuelle Informationen zu allen Projekten, die in einzelnen Services verfügbar sind.
- Benutzer unseres Systems, von Spieledesignern bis hin zu Managern, hörten auf, Entscheidungen nur auf der Grundlage von Intuition zu treffen, und wechselten zu datengetriebenen Ansätzen.
- Wir haben den Analysten die Werkzeuge an die Hand gegeben, um ihre eigene Raketenwissenschaft zu entwickeln. Jetzt beantworten sie komplexe Geschäftsanfragen, erstellen Prognosemodelle, empfehlen Systeme und verbessern Spiele. Eigentlich arbeiten wir dafür in BI-DWH.