Wir bei
People & Screens arbeiten seit vielen Jahren als Werbepartner mit Online-Unternehmen zusammen. Als wir die Idee hatten, den Beitrag von Display-Werbung zum Verkauf von Online-Shops zu bewerten, schien dies nicht realisierbar und sogar verrückt. Sobald wir feststellten, dass alle Elemente des Mosaiks gefunden und zusammengefügt werden können, beschlossen wir, es zu versuchen. Die ersten Hypothesen wurden zusammen mit
Data Insight bestätigt. Wir
haben uns mit dieser Geschichte befasst und in einigen Monaten sorgfältiger Arbeit eine solche Studie erstellt, die tatsächlich ein angewandtes Arbeitsinstrument ist - ein Modell zur Bewertung der Wirksamkeit von Werbung in 12 E-Commerce-Produktkategorien. In diesem Artikel werden wir über die Ergebnisse und die verwendeten Analysemethoden sprechen.
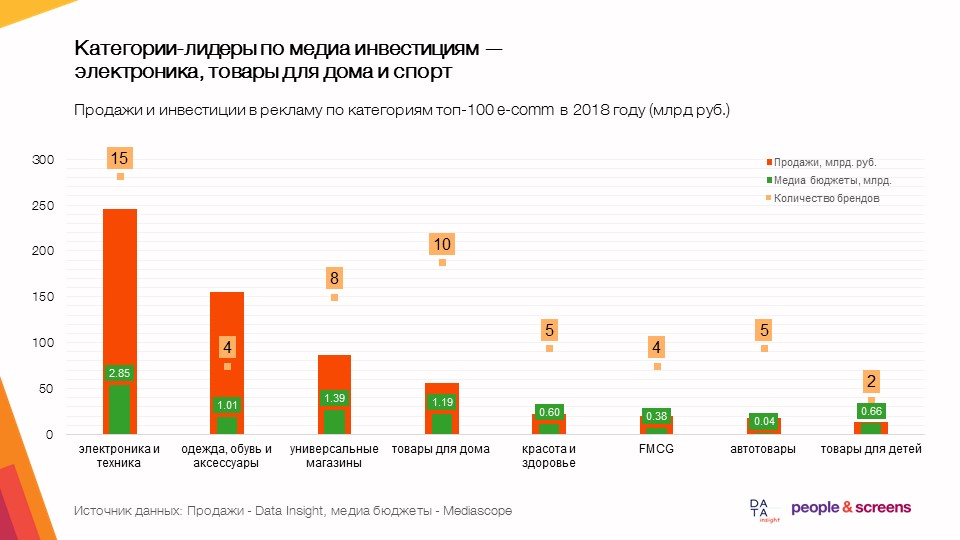
Forschungsziele und -ergebnisse
Die Schlüsselhypothese unserer Studie: Display-Werbung, die Entwicklung der Marke eines Online-Shops, steigert den Umsatz im gesamten Verkaufstrichter. Bei der Analyse von Verkaufsdaten, Werbung und externen Daten in den letzten vier Jahren wurde die Hypothese bestätigt. Infolgedessen haben wir ökonometrische Verkaufsmodelle für 60 Online-Shops in 12 Produktkategorien erstellt.
- Lediglich der kurzfristige Beitrag der Display-Werbung betrug 39% des Wachstums von Online-Shops mit einer durchschnittlichen Marktdynamik von 50-60%.
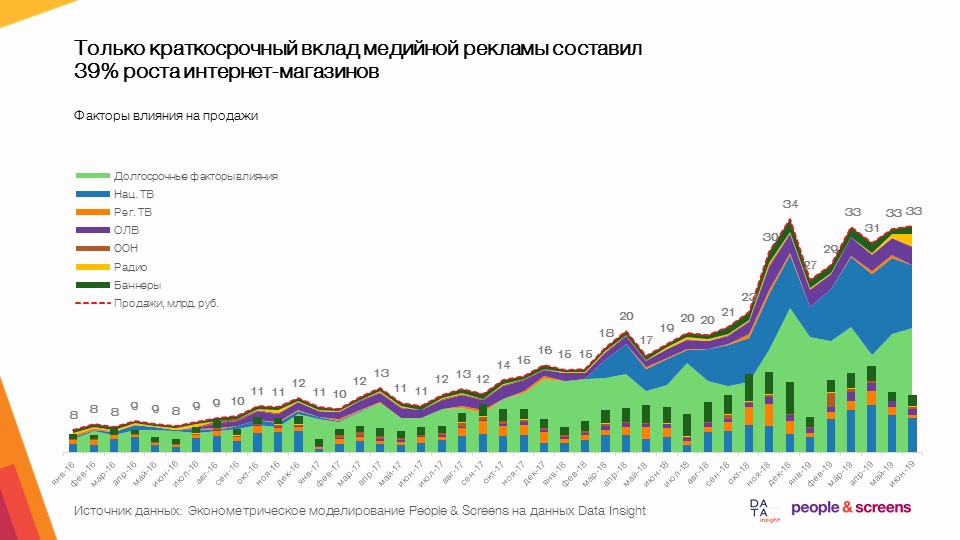
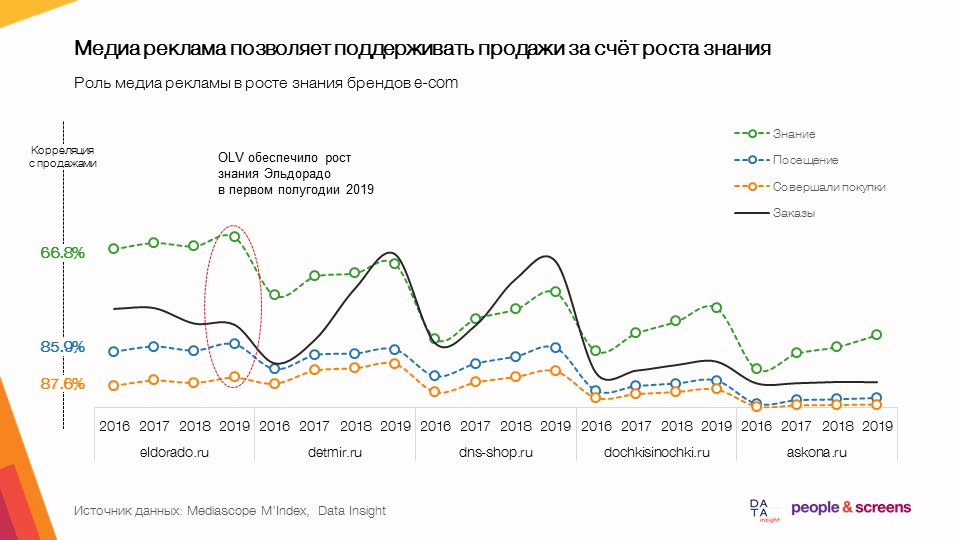
- Mit Display-Werbung können Sie den Verkauf durch mehr Wissen unterstützen.
- Die größte Gesamtrendite im E-Commerce wird durch Online-Videowerbung erzielt.
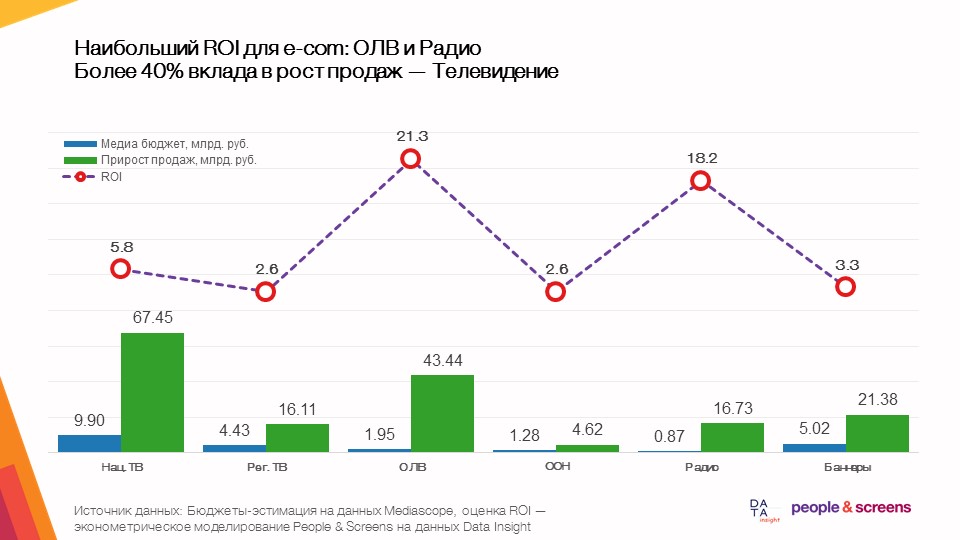
- Die Effizienz der Medien hängt stark von der Kategorie ab: In den Kategorien Bekleidung und Online-Verbrauchermärkte zeigte das Fernsehen eine hohe Effizienz, bei Elektronik und Autoprodukten - Online-Videowerbung.
Was wir analysiert haben
Die Datenerhebung für die Studie wurde von beiden an der Studie beteiligten Unternehmen durchgeführt. Die folgenden Daten wurden von People & Screens gesammelt:
- Anzeigenausgänge anzeigen. Wir haben Downloads aus den Mediascope- Datenbanken verwendet, auf die alle Anzeigengruppen zugreifen können. Wir haben die Werbekosten für alle Medien und Werbekontakte für den Zeitraum ab Januar 2016 tagesgenau (für Werbung im Fernsehen, Radio, in der Presse, im Internet) und monatlich (für Außenwerbung) einer breiten Zielgruppe (alle 18+) entnommen bis Juni 2019. Um die Arbeitsgeschwindigkeit zu diesem Zeitpunkt zu maximieren, haben wir die interne Entwicklung von Dentsu Aegis Network Russia genutzt, um mit Industriedaten, insbesondere der Atomizer-Plattform, zu arbeiten.
- Tägliches Entladen von Daten aus SimilarWeb in den letzten 18 Monaten. Wir haben uns die Dynamik nach Tagen der Besuche auf Desktop / Mobile, die Dynamik nach Tagen des Desktop-Datenverkehrs nach Quelle (Kanal) und die Dynamik von Installationen auf Android angesehen.
- Dynamik des Wissens / Besuche / Käufe aus der TGI / Marketing Index-Datenbank für 2016-2019 nach Quartalen. Dies ist ein Download der Mediascope-Industriesoftware Gallileo.
- Google Trends- Suchanfragen für Januar 2016 bis Juli 2019 in ganz Russland.
Auf der Data Insight-Seite wurden die folgenden Daten gesammelt und bereitgestellt:
- Die Dynamik der Bestellungen für 72 Online-Shops aus dem TOP-100- Ranking nach Monaten für den Zeitraum Januar 2016 bis August 2019.
- Die li.ru-Zählerdaten für den Zeitraum von Januar 2018 bis August 2019 (Verkehr zur Site, getrennt insgesamt, nur in Russland und nur mobil) für TOP-11-Sites.
- Die mail.ru-Zählerdaten für den Zeitraum von Juni 2017 bis September 2019 für 53 Websites.
- Rambler- Zählerdaten für den Zeitraum von Juni 2017 bis September 2019 für 38 Standorte.
- Yandex Wordstat- Suchanfragedaten für 24 Monate von Oktober 2017 bis September 2019.
- Auswertung der durchschnittlichen Checks der TOP-100-Onlineshops ab 2018.
Datenalgorithmus
Die Datenerfassung für die Studie erfolgte in mehreren Phasen. Wir werden die Arbeit, die unsere Kollegen von Data Insight zur Generierung der für die Studie erforderlichen Daten geleistet haben, außerhalb des Artikels belassen, aber wir werden Ihnen mitteilen, welche Arbeit auf der Seite von People & Screens geleistet wurde:
- Suchen Sie in den uns zur Verfügung stehenden Industriedatenbanken nach allen Online-Shops des TOP-100- Ratings und stellen Sie passende Wörterbücher zusammen. Hierfür haben wir die semantische Suchmaschine Elasticsearch verwendet .
- Erstellung von Vorlagen und Hochladen von Daten darauf. In dieser Phase war es am wichtigsten, die Architektur der Datentabellen vorauszudenken.
- Zusammenführen von Daten aus allen Quellen in einem einzigen Datensatz (Datensatz).
Dazu haben wir die hochgeladene Datenverarbeitung in Python mit den Paketen pandas und sqlalchemy verwendet . Das Set von Life-Hacks ist hier ganz normal:
Bei der Verarbeitung von Rohdaten aus CSV-Tabellen mit mehr als 1 Million Zeilen haben wir zuerst die Tabellenspaltennamen mit einer Abfrage des Formulars hochgeladen:
col_names = pd.read_csv(FILE_PATH,sep=';', nrows=0).columns
Dann wurden die Datentypen über das Wörterbuch hinzugefügt:
types_dict = {'Cost RUB' : int } types_dict.update({col: str for col in col_names if col not in types_dict})
und die Daten selbst geladen Funktion
pd.read_csv(FILE_PATH, sep=';', usecols=col_names, dtype=types_dict, chunksize=chunksize)
Die Konvertierungsergebnisse wurden nach PostgreSQL hochgeladen. - Quervalidierung der Auftragsdynamik auf Basis einer Analyse der Verkehrsdynamik, der Suchanfragen und des tatsächlichen Umsatzes im Kundenpool der Agentur People & Screens. Hier haben wir Korrelationsmatrizen mit df.corr () auf verschiedenen Datensätzen innerhalb einer festen Site erstellt und dann die „verdächtigen“ Reihen mit Ausreißern detailliert analysiert. Dies ist eine der Schlüsselphasen der Studie, in der wir die Zuverlässigkeit der Dynamik der untersuchten Indikatoren überprüft haben.
- Konstruktion ökonometrischer Modelle anhand validierter Daten. Hier verwendeten wir die direkten und inversen Fourier-Transformationen aus dem Numpy- Paket ( np.fft.fft- und np.fft.ifft-Funktionen ), um die Saisonalität zu extrahieren, eine stückweise glatte Näherung zur Schätzung des Trends und das lineare Regressionsmodell ( linear_model ) des sklearn- Pakets, um den Beitrag der Werbung zu schätzen. Bei der Auswahl einer Modellklasse für diese Aufgabe gingen wir davon aus, dass das Simulationsergebnis einfach interpretiert und zur numerischen Bewertung der Werbewirksamkeit unter Berücksichtigung der Datenqualität verwendet werden sollte. Wir untersuchten die Zuverlässigkeit von Modellen, indem wir die Daten in Trainings- und Testproben mit variablem Zeitintervall aufteilten. Das heißt Wir haben das Verhalten des auf Daten von Januar 2016 bis Dezember 2018 trainierten Modells im Testzeitintervall von Januar bis August 2019 verglichen, dann das Modell im Zeitintervall von Januar 2016 bis Januar 2019 trainiert und das Verhalten des Modells auf Daten von Februar bis Januar 2019 untersucht August 2019. Die Qualität der Modelle wurde anhand der Stabilität des Beitrags von Werbefaktoren in verschiedenen Trainingsstichproben als Prognose für die Teststichprobe untersucht
- Der letzte Schritt bestand darin, eine Präsentation auf der Grundlage der Ergebnisse vorzubereiten. Hier haben wir eine Brücke zwischen mathematischen Modellen und praktischen betriebswirtschaftlichen Schlussfolgerungen geschlagen und die Modelle erneut unter dem Gesichtspunkt des gesunden Menschenverstands der Ergebnisse getestet.
Die Besonderheiten der Analyse des E-Commerce und die dabei auftretenden Schwierigkeiten
- Bei der Datenerfassung traten Schwierigkeiten bei der richtigen Einschätzung des Suchinteresses an der Ressource auf. In Google Trends gibt es keine Möglichkeit, Suchanfragen zu gruppieren und ausschließende Keywords wie in Yandex Wordstat zu verwenden. Es war wichtig, den semantischen Kern jedes Onlineshops zu studieren und die zentrale Anfrage hochzuladen. Zum Beispiel muss M.Video in Russisch geschrieben sein - dies ist die zentrale Anforderung für diese Site.
Für Geschäfte, die Waren sowohl online als auch offline verkaufen, verfolgten Kollegen von Data Insight in Yandex wordstat-Daten den folgenden Ansatz:
Stellen Sie sicher, dass es keine irrelevanten Fragen gibt (Hauptsache, Sie schätzen nicht das Nachfragevolumen, sondern verfolgen Änderungen in der Dynamik). Wir sind stark genug, um Suchbegriffe zu filtern. Wo das Risiko bestand, dass der Markenname unangemessene Anfragen entgegennimmt, haben wir Statistiken zu Schlüsselkombinationen erstellt. Beispiel: "Ozonspeicher" anstelle von "Ozon" - bei diesem Ansatz wird die Beliebtheit der Suche des Einzelhändlers unterschätzt, aber die Nachfragedynamik wird zuverlässiger gemessen und von "Lärm" befreit. In Bezug auf Suchstatistiken gibt es ein methodologisches Problem, das anscheinend nicht zuverlässig gelöst werden kann. Für viele Einzelhändler werden diese Statistiken durch SEO-Tools verzerrt, die die Suchergebnisse durch Verhaltensfaktoren optimieren, aber die Statistiken zur tatsächlichen Nachfrage verzerren. - Beim Zusammenführen von Daten aus verschiedenen Quellen wurde es erforderlich, die Daten auf eine Granularität zu bringen: Daten zu TV-Werbung und Verkehr von SimilarWeb wurden täglich, Daten zu Suchanfragen wurden wöchentlich und Daten zu Bestellungen und Zählerdaten wurden monatlich übermittelt. Als Ergebnis haben wir eine separate Datenbank mit Datumsfeldern erstellt, mit denen Sie Daten auf der erforderlichen Ebene aggregieren können, sowie eine zwischengespeicherte monatliche Aggregationsdatenbank für die weitere Arbeit mit allen Details der Verkaufsdaten.
- In der Phase der Quervalidierung der Daten stellten wir fest, dass die Umsatzdynamik von unseren eigenen Daten abweicht. Dies erforderte eine Erörterung der Situation mit Kollegen von Data Insight. Dank eines genauen Verständnisses der Monate, in denen die größten Fehler auftreten, haben Analysten zwei Fehler identifiziert, die tief im Algorithmus zur Bewertung der monatlichen Umsatzdynamik liegen.
- Im Stadium der Modellentwicklung traten mehrere Schwierigkeiten auf. Um die Wirkung von Werbung richtig einschätzen zu können, mussten externe Faktoren isoliert werden. Jede Verkaufsdynamik (und E-Commerce ist keine Ausnahme) ist nicht nur mit Werbung verbunden, sondern auch mit vielen anderen Faktoren: UX / UI-Änderungen auf der Website, Preise, Sortiment, Wettbewerb, Währungsschwankungen usw.
Um dieses Problem zu lösen, haben wir einen Ansatz verwendet, der auf einer Regressionsanalyse von Daten für einen langen Zeitraum basiert - von Januar 2016 bis August 2019. Im Rahmen dieses Ansatzes haben wir Veränderungen (Stöße) in der Dynamik von Aufträgen analysiert, die der Werbung in diesem Zeitraum zugeschrieben werden können.
Es ist wichtig zu verstehen, dass, wenn irgendwann eine Werbung gestartet wurde, der erwartete Umsatzwert laut Modell jedoch nicht höher war als der tatsächliche, das Modell anzeigt, dass diese Werbung in diesem Zeitraum nicht funktioniert hat. Natürlich kann ein solches Verkaufsverhalten eine Überlagerung mehrerer Faktoren sein (z. B. Preiserhöhungen / Markteinführung von Wettbewerbern zum gleichen Zeitpunkt wie die Werbekampagne oder die Website "fiel" durch den Zustrom von Kunden).
Da wir Effekte über einen langen Zeitraum über eine große Anzahl von Marken hinweg mitteln, sollte der Effekt solcher zufälligen Zufälle über eine große Stichprobe ausgeglichen werden, obwohl dies zu überschätzten oder unterschätzten Effekten für einzelne Marken führen kann. Auf diese Weise konnten wir allgemeine Regeln und Muster für die gesamte E-Commerce-Kategorie festlegen. Gleichzeitig muss für eine detaillierte Analyse des Einflusses von Werbung innerhalb einzelner Marken natürlich noch der gesamte Satz von Einflussfaktoren untersucht werden.
Fazit
Im Rahmen dieser Studie haben wir uns zum Ziel gesetzt, auf der Grundlage von Daten aus heterogenen Quellen die verlässlichsten Ergebnisse zu erzielen. Diese Daten sind für sich genommen keine exakten Werte, sondern lediglich eine Bewertung dieser Werte durch Fremdüberwachung (Überwachung der Werbeleistungen, der Verkehrsdynamik, des Suchinteresses und schließlich der Bestellungen).
Jeder Link hat Einschränkungen in Bezug auf die Qualität der Daten, und dies ist ein Problem, mit dem Analysten und Forscher jeden Tag in der einen oder anderen Größenordnung konfrontiert sind. Wir hoffen, dass wir im Rahmen dieses Artikels zeigen konnten, welche Methoden die Zuverlässigkeit der Schlussfolgerungen einer analytischen Studie gewährleisten und gleichzeitig die Aussagekraft der Ergebnisse bewahren können.