Hallo allerseits! Mein Name ist Denis Oleynik, ich arbeite als technischer Direktor bei 1Service.
In unserem Unternehmen widmen wir viel Zeit der Bearbeitung von Anforderungen. Als wir Erfahrungen gesammelt haben, stellten wir fest, dass die Tools, die üblicherweise für die Entwicklung von Softwareprodukten verwendet werden, dazu führen, dass wir nicht sagen können, dass wir genau das umgesetzt haben, was der Kunde von uns wollte. Gerade weil es irgendwann eine Lücke zu den anfänglich gesammelten Anforderungen aus deren Softwareimplementierung und nachfolgenden Tests gibt.
Diese Linie liegt irgendwo zwischen den in Confluence erfassten Anforderungen und den Aufgaben für deren Implementierung in Jira. Eine weitere Linie führt zwischen den Testfällen im Testtool und den gleichen Anforderungen in Confluence, wobei der mit den Aufgaben in Jira verbundene Code im Auge behalten wird. Das Fehlen klarer Antworten auf die Fragen: „Warum / warum haben wir das so umgesetzt?“ Oder „Haben wir alles getan, was der Kunde von uns wollte?“ - hat uns sehr beschäftigt.
Und irgendwann schien es uns, dass das Konzept „Dokumentation ist Code“ (Dokumentation als Code) uns erlauben wird, Antworten auf diese Fragen zu finden. Das Konzept „Dokumentation ist Code“ setzt voraus, dass wir Anforderungen, Architekturlösungen und Benutzeranweisungen in Form von einfachen Textdateien speichern, die mithilfe von
(D) VCS- Klassensystemen versioniert werden können.
Idealerweise sollten die Eingabe- / Ausgabedatenmodelle auch in einer Ebene gespeichert werden Textform. Echte „lesbare“ Dokumente (sowie ausführbare Module) werden als Ergebnis der Zusammenstellung des Projekts angezeigt. In diesem Fall wird die technische Dokumentation zusammen mit der Entwicklung des gesamten Projekts nach denselben Prinzipien der Codeversionierung erstellt, wodurch die Kriterien der durchgängigen Rückverfolgbarkeit, Verifizierung und Relevanz erfüllt werden. Dieser Ansatz löst auch das Problem der Organisation der sogenannten "Basisversion von Anforderungen" (Baselines), die für viele Anforderungsmanagementsysteme zu einem echten Problem wird. Insbesondere in Confluence wird empfohlen, dieses Problem zu lösen, indem eine Kopie des ursprünglichen Bereichs erstellt wird, in dem die Anforderungen erstellt wurden, während jegliche Verbindung und Vererbung der Anforderungen verloren geht. Eigentlich ist dieser Artikel der Feldforschung dieses Konzepts in unserem Unternehmen gewidmet.
Hintergrund
Was unserer Meinung nach die breite Anwendung dieses Konzepts in der Masse aufhält, ist das Elend der Werkzeuge zur visuellen Darstellung und Verwaltung von Anforderungen in einer flachen Textform. Dies bedeutet, dass Sie keine einfachen Textdateien für den Product Owner anzeigen, damit er Project Scope in ihnen sieht. Sie können keine Textdateien auf der Präsentationsseite für die Stakeholder anzeigen, sie haben keine Grafiken, Diagramme und Bilder in der Bearbeitungsphase - und dies mag Business-Analysten bereits nicht was im Wesentlichen Inhalte generieren sollte. Und nur die Entwickler sind glücklich und rufen: „Cool! nur hardcore! mehr Verpflichtungen! “und andere Häresien.
Es gibt noch einen anderen subtilen Punkt. Aus irgendeinem Grund sind sich Apologeten des Konzepts "Dokumentation ist Code" sicher, dass, sobald die Dokumentation neben dem Code im Repository liegt, dies zu einer obligatorischen Anpassung und Synchronisierung mit Änderungen des Codes führt, wodurch dieser auf dem neuesten Stand gehalten werden kann (
Abschnitt 1.2.1 ) Aber unserer Meinung nach wird dieser Moment eine Frage der Disziplin bleiben, da niemand die Mühe macht, den Code zu ändern, und die Dokumentation sich nicht ändert. Das heißt, die Relevanz der Dokumentation bei einer solchen Implementierung des Konzepts bleibt der Verwaltung des Entwicklungsprozesses überlassen, wobei der obligatorische Schritt vor der Freigabe darin besteht, "die Relevanz der Dokumentation zu überprüfen". In diesem Fall ist „Dokumentation ist ein Code“ nicht weit von Word-Dateien entfernt, wenn Sie beim Kompilieren der resultierenden Dokumente einige Automatisierungsschritte nicht berücksichtigen.
Ja, erstens ist es "unbequem, geliebt, trocken", und zweitens decken technische Chips das Problem der Aktualisierung der Dokumentation mit einem Tuch ab. Es gibt ein allgemeines Stereotyp: "Wir sind im Gefängnis - aber wir brauchen keine Dokumentation im Gefängnis!" Um es milde auszudrücken, das ist nicht ganz richtig. Ich möchte diesen Fehler durch einen Vergleich der Use-Case- und User-Story-Ansätze aus Karl Wigers exzellentem Buch „Software Requirements Development“ [4] widerlegen. Wenn wir Entwicklungsansätze, die auf User Stories basieren, mit der Agile-Methodik in Beziehung setzen, formuliert Wigers die Entwicklung von Anforderungen, die auf User Stories basieren, folgendermaßen:
Benutzerhistorie → (Diskussionen) → Aktualisierte Benutzerhistorie (mit Akzeptanzkriterien) → (Diskussionen) → Akzeptanztests
(S. 169, Abb. 8-1). Daher ist die Ausgabedokumentation als Ergebnis der Entwicklung der anfänglichen Anforderungen in agilen Entwicklungsprojekten Abnahmetests. Heutzutage sind Testskripte, die in der Sprache
Gherkin [5] geschrieben sind und in sogenannten Feature-Dateien (einfach, Text) gespeichert sind, eine weit verbreitete Methode zum Organisieren von Abnahmetests.
Um
die Umsetzung des Konzepts „Dokumentation ist Code“ in agilen Entwicklungsprojekten zu unterstützen, benötigen wir daher ein Tool, das die Entwicklung der Anforderungen vom User Story-Format bis zu Abnahmetests begleitet und aufgrund ihrer erfolgreichen Ausführung relevante Dokumentationen generiert. Leider gibt es bis heute kein Tool, das diesen Prozess vollständig unterstützt (oder zumindest den Wunsch postuliert, ihn zu unterstützen).
Architektur der Forschungswerkzeuge
Es gibt also kein Werkzeug, aber ich möchte das Konzept untersuchen. Aus Hoffnungslosigkeit mussten wir es entwickeln. Wenn es ein solches Tool (nennen wir es StoryMapper) bereits gab, welche Architektur hätte es, um sich mit minimalem Stress unauffällig in ein vorhandenes Ökosystem des Entwicklungsprozesses zu integrieren? Wenn dies bereits ein aufgebauter Entwicklungsprozess ist, wird die
CI / CD- Schleife wahrscheinlich bereits ausgeführt, und das Versionskontrollsystem, das höchstwahrscheinlich auf Git basiert, wird zweifellos verwendet. In diesem Fall zeigt das folgende Diagramm die Position von StoryMapper während des Entwicklungsprozesses:
Abb. 1 Platzieren Sie das StoryMapper-Tool in der Struktur des EntwicklungsprozessesSomit interagiert StoryMapper direkt mit den Hosting-Diensten von Git-Repositories und mit der
CI / CD- Schleife. Die Integration mit Git-Hosting-Diensten ist erforderlich, um die aktuelle Sammlung von Feature-Dateien (falls vorhanden) abzurufen sowie die Ergebnisse von Änderungen an Feature-Dateien, Service-Dateien im Zusammenhang mit der Strukturierung der Dokumentation, Beispiele für Eingabe- und Ausgabedaten in das Repository usw. zu übertragen. .
CD usw. die Interaktion mit der Kontur
CI / notwendig , um die Montage Szenariotests (manuell oder geplant) und für nachfolgende Testergebnisse in der Lage sein zu laufen - sie mit einem entsprechenden Merkmal-Dateien entsprechen (wie Obra th wird die Überprüfung und die Überprüfung der Dokumentation Relevanz).
Man muss verstehen, dass StoryMapper kaum den Titel eines „weiteren Gherkin-Editors“ beanspruchen muss. Ja, die grundlegenden Funktionen zum Bearbeiten von Feature-Dateien sollten festgelegt werden. Wir sind uns jedoch darüber im Klaren, dass
BA oder
QA , wenn sie sich für VSC, Sublime, Notepad ++ oder sogar vi entschieden haben (warum nicht?), Sie davon überzeugen, nur mit Anforderungen in StoryMapper zu arbeiten die aufgabe ist nicht so undankbar, sondern falsch. Daher gehen wir davon aus, dass die Möglichkeit einer vielfältigen Verwendung von StoryMapper festgelegt werden sollte, insbesondere: Die Entwicklung von Features in Ihrem bevorzugten Editor, und StoryMapper wird zum Strukturieren von vorgefertigten Feature-Dateien verwendet. Mehr dazu im Abschnitt Forschungsrichtungen.
Erforderliche Mindestfunktionalität
Da sich StoryMapper derzeit im MVP-Status befindet, sind dies die Mindestanforderungen, die wir an StoryMapper gestellt haben, damit wir es wirklich verwenden können:
- Git-basiertes Story-Mapping;
- Gurken-Editor;
- Starten der Zusammenstellung von Szenariotests (manuell und gemäß Zeitplan);
- Reflexion der Ergebnisse von Szenariotests auf der Karte von User Stories.
Ich werde nicht auf die Funktionalität des Werkzeugs eingehen, da das Thema dieses Artikels der Operationsverlauf und nicht das Skalpell des Chirurgen ist.
Forschungsbereiche
Die Hauptidee ist folgende:
Wenn Sie bei der Verwendung des Konzepts "Dokumentation ist Code" nicht die Anforderungen des Kunden erfüllen und beim Schreiben des Codes eine beliebige Dokumentation erstellen, wird diese Dokumentation so schnell ungültig wie die Version mit Dateien im MS-Format Wort Aus diesem Grund wollten wir überlegen und untersuchen, ob das Konzept für den gesamten Entwicklungszyklus verwendet werden kann. Andererseits interessierten wir uns auch für den Übergangszeitpunkt, in dem das Team nicht das Konzept „Dokumentation ist ein Code“ verwendet, sondern es anwenden möchte - wie soll man in diesem Fall vorgehen?
StoryMapper ist also ein Tool, das nicht den einzig wahren Anwendungsfall regelt. Im Gegenteil, jeder potenzielle Benutzer kann seine Optionen für die Verwendung des Tools sehen. Wir haben uns auf drei Hauptbereiche konzentriert:
- Flexible Entwicklung: von einer Story Map bis zu Akzeptanztests;
- Strukturieren und Visualisieren einer Sammlung von Feature-Dateien;
- Produktivitätsüberwachung.
Im Folgenden werde ich detailliert beschreiben, welche Ergebnisse wir in jeder Richtung erzielt haben.
Flexible Entwicklung: von Story Cards bis zu Abnahmetests
Diese Richtung beinhaltet die Entwicklung eines neuen Produkts oder die Verfeinerung eines bestehenden. Die Arbeit in dieser Richtung erfolgte unter dem Codenamen "BDDSM": als Kombination der Story-Mapping-Technik und der
BDD- Entwicklungsmethodik. Und es hat Wurzeln geschlagen.
Für den Anfang wird ein Git-Repository für Feature-Dateien erstellt, in dem ein Zweig für die Interaktion mit StoryMapper zugeordnet ist. In StoryMapper wird ein Projekt erstellt, das mit Geschäftsanalysten verbunden ist, die an dem Projekt arbeiten. In der Kommunikation mit Stakeholdern beginnen Business Analysten, eine gemeinsame Vision des Produkts zu formulieren und diese in Form eines Skeletts einer User Story Map [1,2] zu fixieren, zunächst eine Skizze der ersten Ebene von
UF :
 Abb. 6 Oberes Skelett der Karte der User Stories (anklickbar)
Abb. 6 Oberes Skelett der Karte der User Stories (anklickbar)Und dann schrittweise die zweite Ebene der Benutzeraktivitäten ausfüllen:
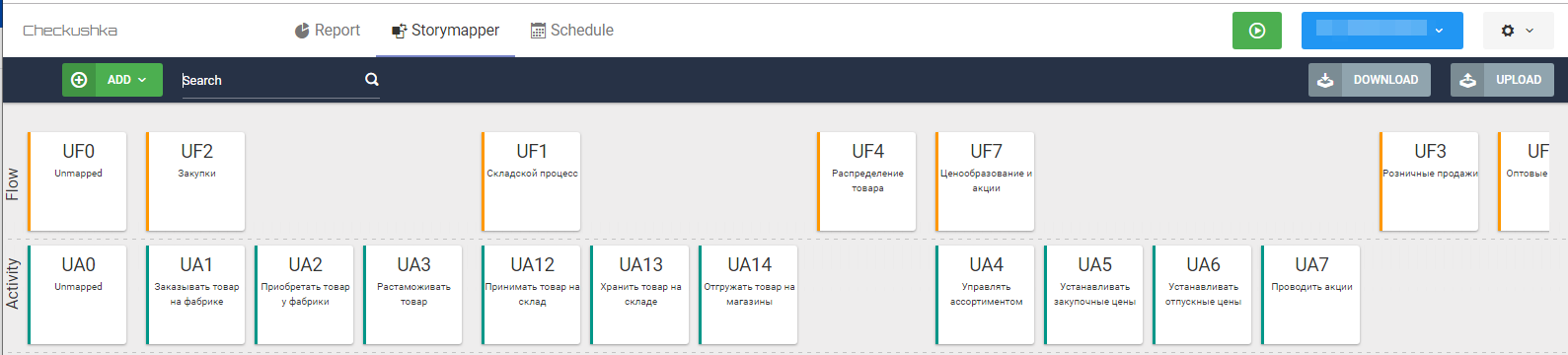 Abb. 7 Gerüst der zweiten Ebene der Karte mit User Stories
Abb. 7 Gerüst der zweiten Ebene der Karte mit User StoriesDa es sich bei jeder Karte um eine Textdatei handelt, entweder in der Phase des Sammelns von Anforderungen (wenn die Karte im Zuge der Kommunikation mit dem Benutzer zusammengestellt wird) oder in der Phase der Nachbearbeitung der Interviews, werden die Kommunikationsergebnisse direkt an die
UF- und
UA- Karten übertragen. Dies ist die Grundlage für eine weitere Zerlegung der Anforderungen auf die Ebene der User Stories.
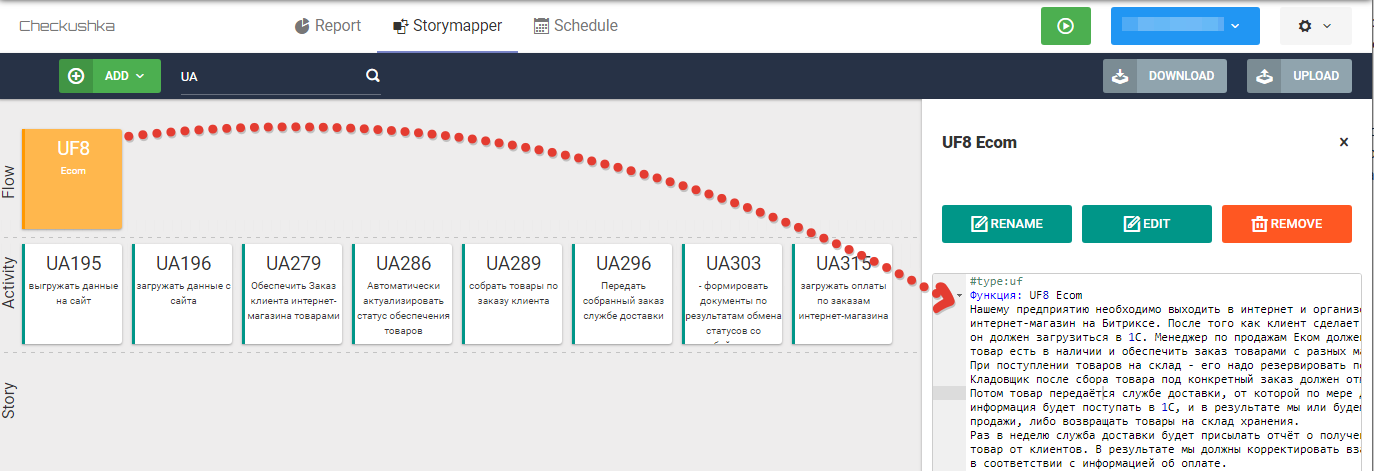 Abb. 8 Anforderungenstext ohne Gherkin-Syntax auf UF- Ebene
Abb. 8 Anforderungenstext ohne Gherkin-Syntax auf UF- EbeneAls Nächstes lernen Business-Analysten, wie Benutzeraktivitäten in User Stories zerlegt werden, und bilden im StoryMapper -
US eine dritte Kartenebene. Die Isolation der
USA ist mit der Formulierung von Akzeptanzkriterien verbunden, dh wenn Sie als jemand etwas wollen, werden wir überprüfen, ob Sie es erhalten haben [3]. Akzeptanzkriterien für Starter können in den
USA auch als Flachtext festgelegt werden.
Nachdem die Akzeptanzkriterien festgelegt und mit den Stakeholdern abgestimmt wurden, setzen sie die Geschäftsanalysten in Form von Skripten in der Sprache Gherkin ein. Tatsächlich wird an jedes Akzeptanzkriterium der Text „Szenario: KP-Nr.“ Angehängt, der die bisher abstrakte User Story in eine Feature-Datei verwandelt.
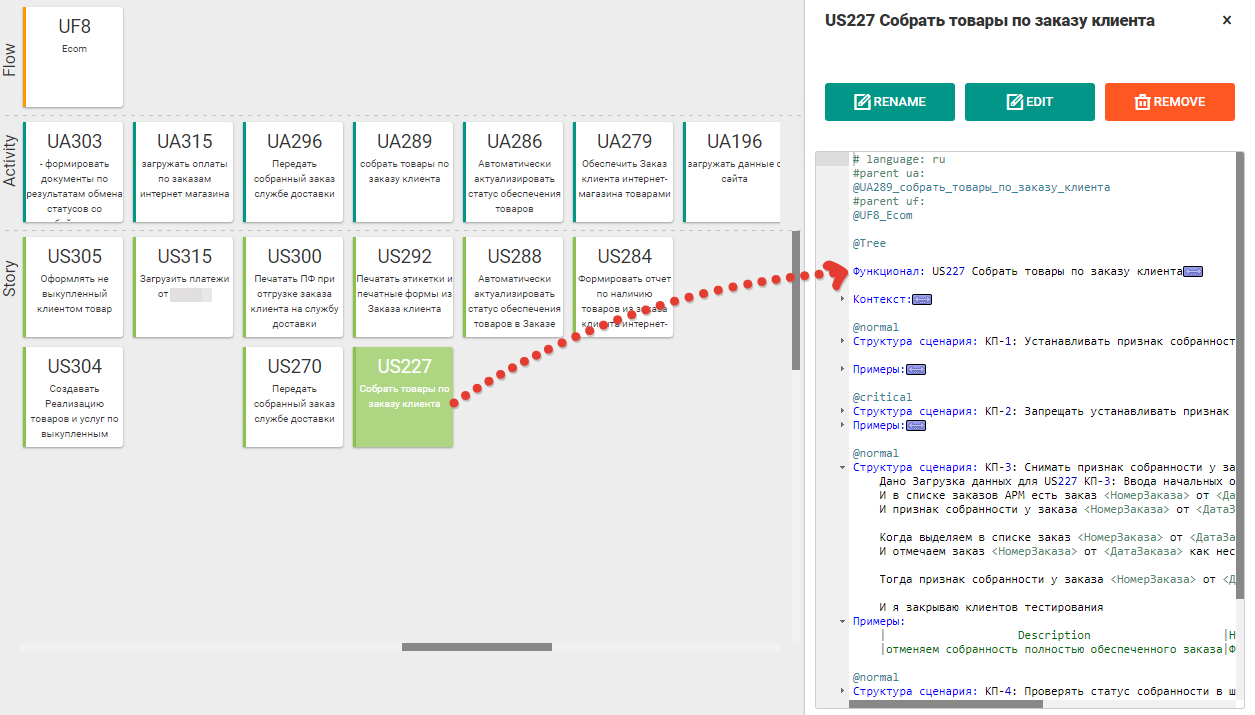 Abb. 8.1 Akzeptanzkriterien für User Stories als Skripte auf Gherkin
Abb. 8.1 Akzeptanzkriterien für User Stories als Skripte auf GherkinDanach wird jedes Szenario durch mehrere vergrößerte Schritte entschlüsselt, aus denen hervorgeht, wie genau ein bestimmtes Akzeptanzkriterium überprüft wird. Ferner werden diese Schritte entweder von den Entwicklern programmiert oder aus der Bibliothek der Schritte des verwendeten Gherkin-Frameworks eingegeben und zum Exportieren von Skripten exportiert.
Parallel dazu wird ein Prüfstand eingerichtet, auf dem der Assembly-Server Funktionstests durchführt und wartet, bis die
USA mit Skripten fertig sind. Sobald das Produkt und die Szenarien, in denen die Akzeptanzkriterien implementiert sind, fertig sind, gibt der Assembly-Server Berichte in den Formaten Allure und Cucumber aus und sendet sie an StoryMapper. Dadurch wird das Assembly-Ergebnis im Format Cucumber auf die User Story Map projiziert:
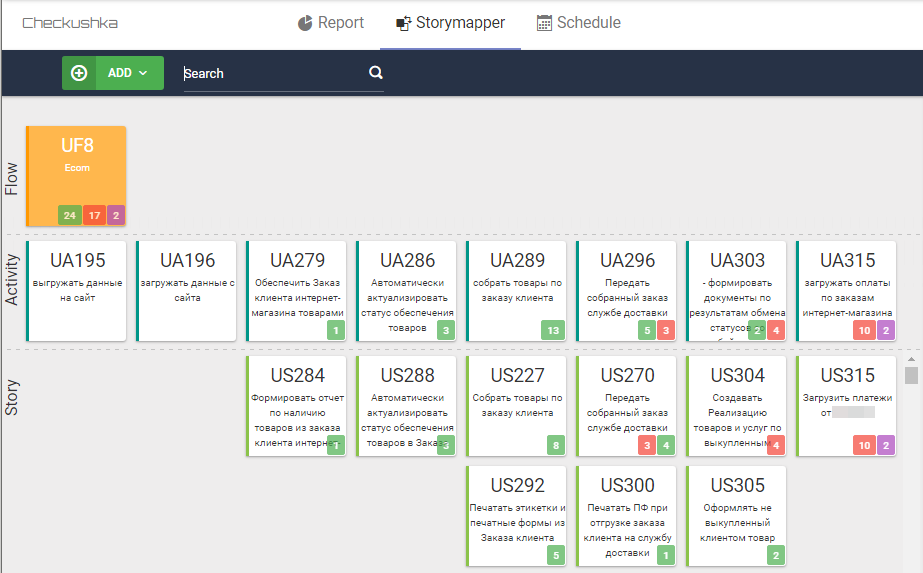 Abb. 9 Karte mit User Stories mit Skriptergebnissen
Abb. 9 Karte mit User Stories mit SkriptergebnissenGleichzeitig bietet StoryMapper drei Ebenen für das Verständnis der Produktbereitschaft: UF ist die oberste Ebene, auf der die Anzahl der ordnungsgemäß funktionierenden Skripte (die die Akzeptanzkriterien erfüllen) angezeigt wird, die fehlerhaft arbeiten und noch nicht bereit sind. Das heißt, die oberste Ebene ist ein Indikator für die Produktbereitschaft und ein Indikator dafür, wie viel noch zu tun ist (dies ist die Ebene des Product Owner). In den unteren Ebenen können Sie genau herausfinden, welche Art von Benutzeraktivitäten es gibt und wo Sie Anstrengungen unternehmen müssen, um das Produkt fertigzustellen (dies ist die Ebene der Scrum Master in größerem Umfang und der Product Owner in geringerem Umfang). Die niedrigere Ebene in den
USA ist die Ebene, auf der Geschäftsanalysten, Entwickler und Qualitätssicherung interagieren und gemeinsam genau das Produkt entwickeln, das die Stakeholder von ihnen erwarten.
Außerdem wird in einem der letzten Schritte der Fertigungslinie eine automatische Dokumentation erstellt. Mehr dazu können Sie mit
Kollegen lesen. Dies ist nicht die einzige Option. Wir planen, das
Pickles- Paket in unser Tool aufzunehmen - den De-facto-Standard in der Welt der „Live-Dokumentation“.
Strukturieren und Visualisieren einer Sammlung von Feature-Dateien
Bei unserer Arbeit in diese Richtung haben wir uns einen solchen Fall angesehen. Das Entwicklungsteam hat sich nach dem Hype um das Thema BDD, Funktionstests und Branchenentwicklungsstandards vorgenommen, Feature-Dateien zu schreiben. Und die Dornen durchbrechen, hat eine ziemlich große Sammlung im Repository angesammelt. Wenn Sie jedoch 10 Dateien in Ihrer Sammlung haben, gibt der Bericht im Allure-Format immer noch ein zuverlässiges Bild des Produktzustands. Aber wenn die Anzahl der Feature-Dateien in Dutzenden und manchmal Hunderten gemessen wird, werden Sie sie früher oder später irgendwie strukturieren wollen. Das erste, was mir einfällt, ist, sie in thematische Ordner zu sortieren. Und wofür? Von Stakeholdern, von Metadaten, von Subsystemen? Dies sind alles andere als leere Fragen. Und wenn sich später herausstellt, dass Feature-Dateien ursprünglich so geschrieben wurden, wie Gott es der Seele vorschreibt, und es Skripte gibt, die sich auf mehrere Ordner gleichzeitig beziehen, wie dann?
Dieser Anwendungsfall impliziert also den Wunsch, Ihre Dokumentation zu bereinigen, um von „Funktionen separat, Dokumentation separat“ zu „Dokumentation ist ein Code“ zu wechseln. Wenn ein solches Repository mit StoryMapper verbunden ist, fallen alle Feature-Dateien in die erste Spalte unter UF0 und UA0. Der nächste Schritt bei der Strukturierung besteht darin, das Gerüst der Struktur zusammenzusetzen. In StoryMapper sind dies alle
UF und
UA gleich , aber niemand besteht darauf, sie nur aus diesem Blickwinkel zu betrachten. Sie können einfach als zwei Hierarchieebenen betrachtet werden, unter denen zuvor unstrukturierte Feature-Dateien abgelegt werden können. Nachdem die Struktur festgelegt wurde, werden Feature-Dateien aus der ersten Spalte unter der entsprechenden
UA auseinandergezogen . Zweifellos verursacht dieser Prozess einen Angriff der Reflexion und Umgestaltung von Features, da beim Ziehen die gesamte Tiefe des Chaos deutlich wird, das sich während des anfänglichen Schreibens ereignet hat. Manchmal reicht es aus, das Skript von einer Datei in eine andere zu übertragen, manchmal eine große Datei in mehrere zu teilen, um die semantische Konnektivität wiederherzustellen, und manchmal es einfach in den Papierkorb zu werfen, da alte, nicht ausführbare Manuskripte im Repository lagen.
Wenn die Assembly-Linie bereits konfiguriert wurde (da es ein Feature-File-Repository gibt, müssen sie irgendwo gesammelt werden), müssen Sie einen Schritt hinzufügen, um die Assembly-Ergebnisse an StoryMapper zu senden. Das Endergebnis ist das letzte Bild aus dem vorherigen Abschnitt (Abb. 9): Strukturierte Feature-Dateien mit Markierungen auf den Ergebnissen ihrer Skripte.
Wie benutzt man ein solches Bild? Es kann dem Managementteam gezeigt werden, um über die Ergebnisse des Teams zu berichten und den Grad der Bereitschaft / Qualität des Produkts nachzuweisen. Es kann vom Team bei der Durchführung einer Retrospektive verwendet werden, um
DoD zu korrigieren oder den Prozess irgendwie zu korrigieren. Es kann für die Rückstandsbereinigung verwendet werden, dies erfordert jedoch bereits Arbeiten gemäß dem im vorherigen Abschnitt beschriebenen Szenario, wenn nach der anfänglichen Strukturierung der Anforderungen die weitere Entwicklung in einem vollständigen Zyklus durch StoryMapper (oder zumindest unter Berücksichtigung von StoryMapper) ausgeführt wird.
Produktüberwachung
Ein weiterer Nebenanwendungsfall, der in unserer Praxis Fuß gefasst hat. Tatsächlich ist es ein modernes und modisches Thema - warum nicht direkt im Produkt testen. Immerhin gibt es keinen Fehler, nein, und ja, sie werden es schaffen. Dies ist insbesondere dann relevant, wenn die IT-Aktivität nicht für das Unternehmen relevant ist und die Entwicklung auslagert, insbesondere wenn es sich um kleine und mittlere Online-Shops handelt.
Wie wir es sehen. Eine einfache Option: Aus der Reihe der Funktionstests wird eine bestimmte Teilmenge nicht modifizierender Datenbanktests ausgewählt, die das Front-End überprüfen. : , -, , , -, , . , . StoryMapper Allure, , — , , , IT- .
, , . , , , , - .
, , :
- , ;
- , , ;
- StoryMapper ;
- StoryMapper .
Entwicklungsrichtungen
, StoryMapper MVP. , « », , , , . , , « ». , :
- « », « — »;
- (, etc. );
- / / Excel;
- - Jira ( , ).
, , , . , .
( ), , ( !) —
telegram , .
- , . , ., , 2017.
- , . , .-.-, , 2012.
- Gojko Adjic, Specification by Example, NY, Manning Publication, 2011.
- , , , .: ; .: -, 2014.
- BDD «What's in a story»
- « — » «Write the docs»
- « — » " docToolchain "