Mein Kollege Rafael Grigoryan eegdude schrieb kürzlich einen Artikel darüber, warum die Menschheit ein EEG benötigt und welche signifikanten Phänomene darin aufgezeichnet werden können. In Fortsetzung des Themas der neuronalen Schnittstellen verwenden wir heute einen der offenen Datensätze, die in einem Spiel mithilfe der P300-Mechanik aufgezeichnet wurden, um das EEG-Signal zu visualisieren, die Struktur der aufgerufenen Potentiale zu sehen, die Hauptklassifikatoren zu konstruieren und die Qualität zu bewerten, mit der wir das Vorhandensein eines solchen aufgerufenen Potentials vorhersagen können.
Lassen Sie mich daran erinnern, dass P300 ein sogenanntes Potential (VP) ist, eine spezifische Reaktion des Gehirns, die mit der Entscheidungsfindung und der Unterscheidung von Reizen verbunden ist (die wir unten sehen werden). Es wird normalerweise verwendet, um modernes BCI zu bauen.
Um die EEG-Klassifizierung durchzuführen, können Sie Freunde anrufen, ein Spiel über Waschbären und Dämonen in VR schreiben, Ihre eigenen Reaktionen aufschreiben und einen wissenschaftlichen Artikel schreiben (darüber werde ich ein andermal sprechen), aber glücklicherweise Wissenschaftler aus der ganzen Welt einige Experimente für uns durchgeführt und es bleibt nur die Daten herunterzuladen.
Eine Analyse zum Erstellen einer neuronalen Schnittstelle auf dem P300 mit schrittweisen Codes und Visualisierungen sowie einem Link zum Repository finden Sie unter der Katze.
Der Artikel zeigt nur die wichtigsten Punkte aus dem Code, die voll reproduzierbare Version in Jupyter Notebook , um hier zu suchen
Aus Sicht eines EEG ist der P300 in bestimmten Kanälen nur ein Burst zu einer bestimmten Zeit. Es gibt viele Möglichkeiten, es aufzurufen, zum Beispiel, wenn Sie sich auf ein Objekt konzentrieren und es zu einem zufälligen Zeitpunkt aktiviert wird (Form, Farbe, Helligkeit ändern oder irgendwo abspringen). So wurde es in der Antike implementiert.
Im Allgemeinen lautet das Schema wie folgt: Es gibt mehrere (normalerweise 3 bis 7) Reize im Gesichtsfeld einer Person. Eine Person wählt eine davon aus und konzentriert sich darauf (eine gute Methode ist es, die Anzahl der Aktivierungen zu zählen). Dann blinkt jedes Objekt in zufälliger Reihenfolge. Wenn wir die Aktivierungszeit jedes Stimulus kennen, können wir jetzt das nächste EEG betrachten und feststellen, ob es einen charakteristischen Peak enthält (wir werden ihn in den folgenden Visualisierungen sehen). Da sich die Person nur auf einen Stimulus konzentriert hat, sollte der Peak einer sein. Daher wird in diesen neuronalen Schnittstellen eine von mehreren Optionen ausgewählt (Buchstaben zum Schreiben, Aktionen im Spiel und Gott weiß, was sonst noch). Wenn es mehr als sieben Optionen gibt, können Sie sie in das Raster einfügen und die Aufgabe auf die Auswahl einer Zeile + Spalte reduzieren. So sieht der oben gezeigte klassische Matrix-P300-Speller aus.
Im Falle des heute betrachteten Datensatzes wurde der visuelle Teil (sowie der Name) von den berühmten Game Space Invidern ausgeliehen . Es sah ungefähr so aus

In der Tat ist dies der gleiche Buchstabierer, nur die Buchstaben werden durch Außerirdische ersetzt.
Das Video des Spielprozesses und die technischen Berichte wurden ebenfalls beibehalten.
Auf die eine oder andere Weise sind die mit diesem Spiel gesammelten Daten im Internet erschienen und wir können auf sie zugreifen. Die Daten bestehen aus 16 EEG-Kanälen und einem Ereigniskanal, die anzeigen, zu welchem Zeitpunkt das (vom Spieler erstellte) Ziel und die nicht zum Ziel gehörenden Anreize aktiviert wurden. Wir werden mit ihnen arbeiten.
Die meisten Datensätze für BCI wurden von Neurophysiologen aufgezeichnet, und das sind Leute, die sich nicht wirklich für Kompatibilität interessieren, daher sind die Datenformate sehr unterschiedlich: von verschiedenen Versionen der .mat Dateien bis zu den "Standard" -Formaten .edf und .gdf .
Das Wichtigste, was Sie über diese Formate wissen müssen, ist, dass Sie sie nicht analysieren oder direkt damit arbeiten möchten.
Glücklicherweise hat eine Gruppe von Enthusiasten von NeuroTechX Downloader für einige Datensätze direkt in Zahlen geschrieben.
Diese Bootloader sind Teil des moabb- Projekts, das behauptet, eine universelle Lösung für BCI zu sein.
Rohdatensatz herunterladen
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
Zu diesem Zeitpunkt haben wir eine RawEDF- Struktur erhalten, die EEG-Aufzeichnungen enthält. Dies ist eine Struktur aus dem mne Paket, die Biologen normalerweise zur Interaktion mit Signalen verwenden: Diese Struktur verfügt über integrierte Methoden zum Filtern, Visualisieren und Speichern von Etiketten, und Sie wissen es nie. Aber wir werden diesen Weg seitdem nicht mehr gehen Die Paketschnittstelle ist in der Regel instabil (die aktuelle Version ist 0.19 , wir verwenden jedoch 0.17 da der Datensatz von der neuen Version nicht mehr gelesen wird) und schlecht dokumentiert. Dadurch können unsere Ergebnisse möglicherweise nicht mehr reproduzierbar werden.
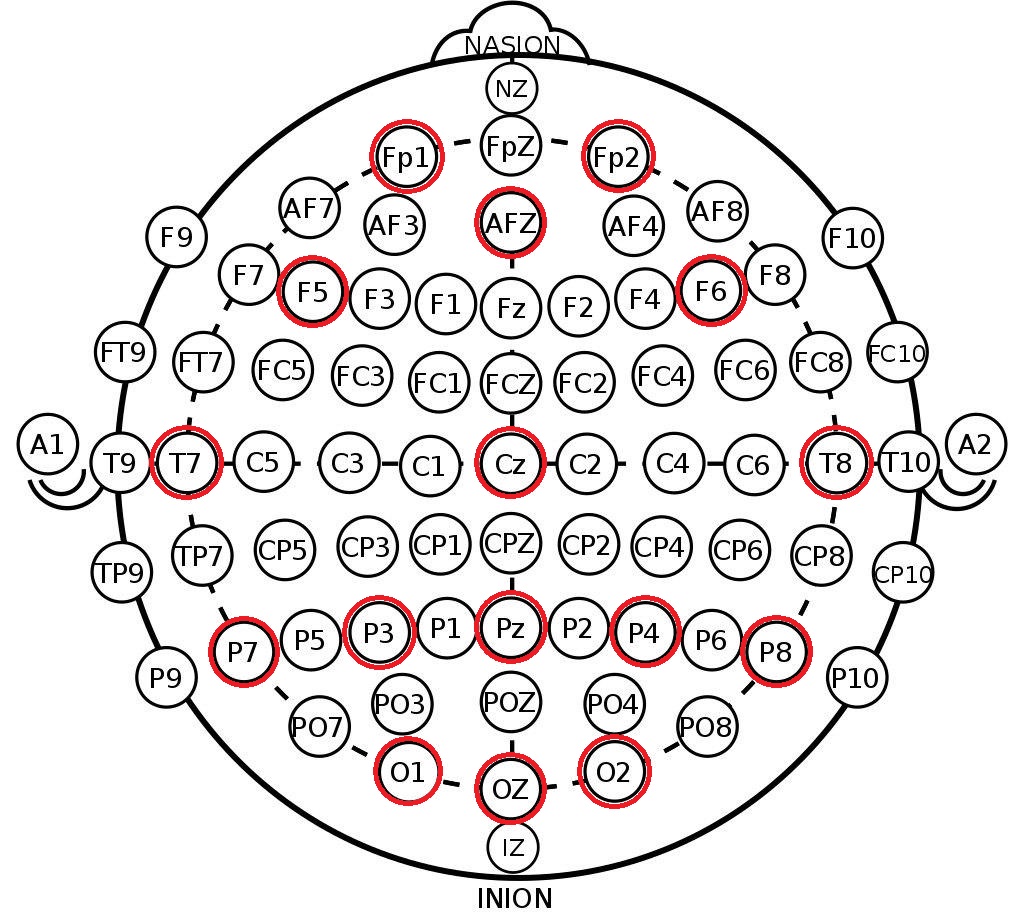
Was wir aus der resultierenden Struktur entnehmen, sind die Kanalbezeichnungen im 10-20-System . Hierbei handelt es sich um eine internationale Anordnung von Elektroden am Kopf einer Person, mit deren Hilfe Wissenschaftler Gehirnzonen und EEG-Kanalpositionen korrelieren können. Unten sehen Sie die Anordnung der Elektroden im 10-10-System (unterscheidet sich von 10-20 durch die doppelte Markierungsdichte) und die Kanäle, die in diesem Datensatz aufgezeichnet wurden, sind rot markiert.
print(m_data[1]['session_1']['run_1'])
Zunächst ordnen wir aus den heruntergeladenen Daten für jedes Subjekt 16 Sekunden lang Arrays mit kontinuierlichem EEG und alle Labels für dieses Intervall zu (in den Daten ist dies nur ein weiterer Kanal, in dem der Beginn der für uns interessanten Ereignisse vermerkt ist).
In diesem Stadium behalten wir die maximale Länge des kontinuierlichen EEG bei, um Kanteneffekte bei der weiteren Filterung zu vermeiden.
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
Filterung und Trennung
Generell kann ich zur Überprüfung der Methoden der Vorverarbeitung und Klassifizierung des EEG einen hervorragenden Überblick von den Meistern der Neurocomputer-Interfaces empfehlen. Ebenfalls vor nicht allzu langer Zeit wurde eine neuere Übersicht über neuronale Netzwerktests veröffentlicht.
Die minimale Vorverarbeitung des EEG-Signals zur Klassifizierung umfasst 3 Schritte:
- Dezimation
- Filterung
- Skalierung
Um diese Schritte zu implementieren, werden wir das gute alte sklearn und sein Paradigma für Transformatoren und Pipelines verwenden, damit unsere Vorverarbeitung leicht erweiterbar ist.
Der Code des Transformers wird in einer separaten Datei abgelegt. Nachfolgend werden einige Details beschrieben.
Dezimation
Aus irgendeinem Grund habe ich in einigen Artikeln und Verarbeitungsbeispielen eine Abnahme der Signalfrequenz eeg = eeg[:, ::10] indem ich einfach Samples im Stil eeg = eeg[:, ::10] . Dies ist völlig falsch (warum - siehe ein Buch über Signalverarbeitung). Wir verwenden die Standardimplementierung scipy .
Filtern
Hier verlassen wir uns auch auf scipy Filter, indem wir ein Butterworth-Bandpassfilter 4-Ordnung auswählen und es in Vorwärts- und Rückwärtsrichtung ( filtfilt ) filtfilt , um die Phase aufrechtzuerhalten. Grenzfrequenzen - von 0,5 bis 20 Hz, das ist der Standardbereich für unsere Aufgabe.
Skalierung
Wir haben einen StandardScaler pro Kanal verwendet (subtrahiert den Durchschnitt, dividiert durch die Standardabweichung), der alle Signale aus dem Sample anzeigt. In der Tat wird an dieser Stelle ein kleines Datenleck eingeführt. Formal sieht der Scaler auch Daten aus der Testprobe, aber bei ausreichend großen Datenmengen sind der Mittelwert und die Abweichung gleich.
Die Masturbation wird kanalweise durchgeführt, sodass es möglich ist, Daten von verschiedenen Sensoren mit unterschiedlichen Größenordnungen und Eigenschaften (z. B. hautgalvanische Reaktion (RAG) ) innerhalb desselben Datensatzes zu aggregieren.
Zusätzlich zu den oben genannten Operationen konnten auch Artefakte im EEG (Blinken, Kauen, Kopfbewegungen) unterschieden werden. Dieser Datensatz ist jedoch bereits sehr sauber. Lassen Sie ihn also bis zum nächsten Mal.
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
Als nächstes werden wir die Vorverarbeitungs-Pipeline auf unsere Daten anwenden und das kontinuierliche EEG-Signal in Epochen aufteilen. Wir bezeichnen die Epoche als die Zeitspanne unmittelbar nach der Aktivierung des Stimulus mit einer charakteristischen Dauer von 0,5 bis 1 Sekunde, in unserem Fall beträgt die Dauer 900 ms, obwohl sie verkürzt werden kann.
In unserem Datensatz gibt es 16 EEG-Kanäle. Nachdem die Dezimierung angewendet wurde, fällt die Frequenz auf 50 Hz ab, sodass eine Epoche durch eine Matrix (16, 45) 900 ms bei 50 Hz sind 45 Zeitabtastwerte.
Die Tags in diesem Datensatz sind nur Binärdateien - sie markieren die Signale des Ziels (vom Player ausgeblendet, aktiv, 1) und des Nichtziels (leer, 0).
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
Wir haben also einen Pytorch im Pytorch-Stil, in dem der erste Index verschiedene Personen zählt. Mit dieser Struktur können wir beide eine Kreuzvalidierung innerhalb der Daten einer Person durchführen und die Toleranz des Klassifikators zwischen verschiedenen Personen testen (sogenanntes Transferlernen, kalibrierungslose Vorhersage). Die Daten einer Person bestehen aus einer Reihe von Epochen und Klassenbezeichnungen. Die Anzahl der Epochen für jede Person variiert geringfügig aufgrund der Eigenschaften der Aufnahme.
Datenrecherche und Visualisierung
Schauen Sie sich zunächst eines der kontinuierlichen Signale an, bevor Sie in Epochen aufteilen.
Trotz der Tatsache, dass es bereits herausgefiltert wurde, zeigt es keine Aktivierungen am Auge und sieht eher wie eine Art Geräusch aus.
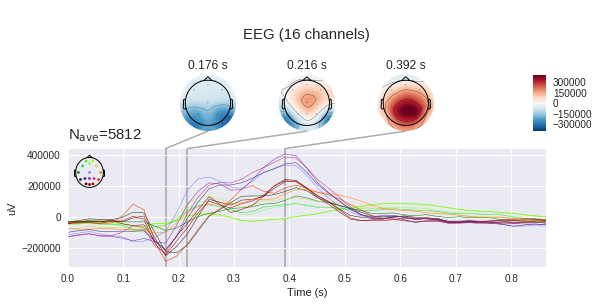
Wenn wir nur eine Zielepoche aus unserem Datensatz betrachten, sehen wir einen charakteristischen Anstieg im Intervall von 400 bis 600 ms. Dies ist unser gesuchtes Potenzial P300.
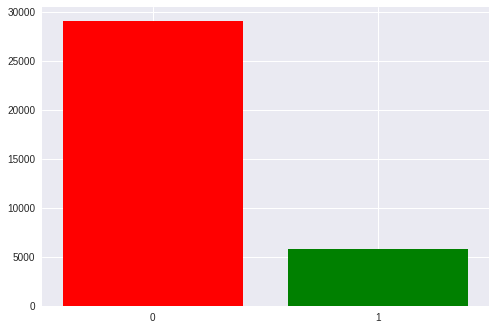
Insgesamt gibt es in unserem Datensatz ungefähr 35.000 Epochen, dh Stimulusaktivierung. Jede Person hat ungefähr 1300 bis 1750 (dies liegt an der Tatsache, dass jemand Aliens schneller und jemand langsamer abgeschossen hat).
Es gibt auch ein merkliches Ungleichgewicht in den Klassen: 1 bis 5 zugunsten leerer Reize. Wir haben 6 Zeilen und Spalten in der Matrix und nur eine davon ist das Ziel. Wir werden später darauf zurückkommen, wenn wir die erhaltenen Metriken diskutieren.
Jetzt ist es Zeit, den Unterschied zwischen dem Zielsignal und dem Nichtziel zu untersuchen
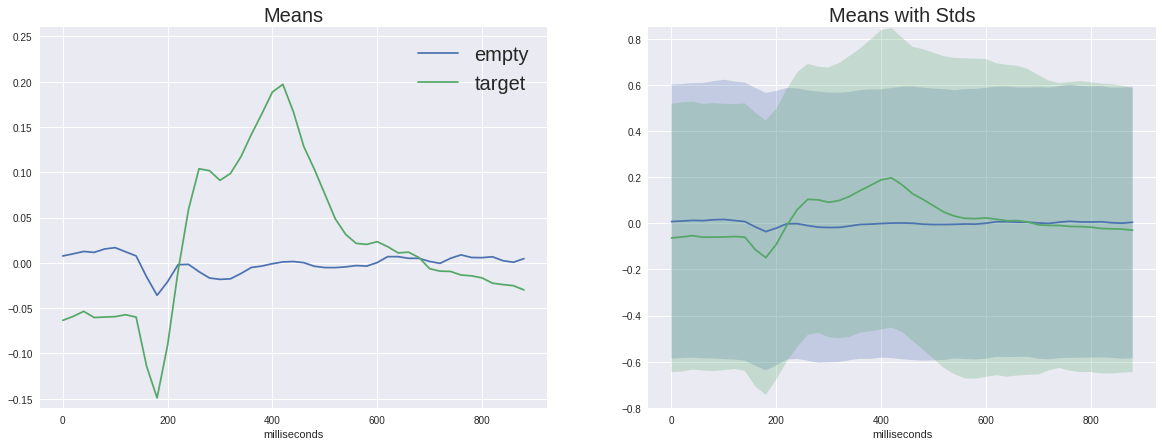
In der linken Grafik können Sie sehen, dass die durchschnittlichen Signale sehr unterschiedlich sind und beide eine unspezifische Reaktion im Bereich von 180 ms haben, aber die Zielamplitude ist viel größer, das Ziel hat auch einen charakteristischen Buckel von 250 bis 500 ms - dies ist der berüchtigte P300.
Bei einem solchen Unterschied im Signal mag unsere Aufgabe wie eine Kleinigkeit erscheinen, aber wenn wir die Standardabweichung an jedem Punkt zur Grafik hinzufügen, werden wir sehen, dass das Bild nicht so rosig ist - das Signal ist ziemlich verrauscht. Und dies trotz der Tatsache, dass das Signal-Rausch-Verhältnis für den P300 als eines der höchsten in der Neurophysiologie gilt.
(Tatsächlich sind diese Graphen nicht ganz ehrlich aufgebaut, da das Leersignal über fünfmal so viele verschiedene Abtastwerte gemittelt wird, sodass zufällige Abweichungen stärker gedrosselt werden. Wie wir jedoch an der Streuung derselben Reihenfolge erkennen können, hilft dies nicht allzu viel.)

Es ist auch nützlich, die durchschnittlichen Signale einer Person zu betrachten.
Hier findet sich die bisherige Bemerkung zur „unehrlichen“ Mittelung - das Leersignal ist spürbar amplitudenstärker als bei der Mittelung über alles. Außerdem ist der Peak von P300 bei einer Person höher, da weniger gemittelt wird.
Es ist wichtig, ein anderes Merkmal des Signals einer Person zu beachten - es hat eine etwas andere Form als das generalisierte. Die zwischenmenschliche Variabilität der neurophysiologischen Reaktionen ist recht hoch, wir werden den Einfluss dieses Faktors in der Arbeit der Klassifikatoren noch sehen. Intrapersonale Unterschiede (eine Person in einer anderen Stimmung, Stresslevel, Müdigkeit) sind jedoch auch ziemlich groß.

Als nächstes sehen wir den kanalweisen Sweep der Signale. Die Sichtweise hier stimmt mit dem obigen Bild überein, das die Position der Elektroden zeigt - Nase oben usw.
Die Reaktion jedes Teils des Kopfes ist unterschiedlich. Bei Fp1,2 sind zwei negative Peaks vor dem positiven Peak ausgeprägt. Außerdem gibt es in einigen Kanälen zwei positive Peaks und in einigen einen oder einen Übergang zwischen diesen.
Verschiedene Kanäle sind für die Bestimmung des Vorhandenseins von P300 von unterschiedlicher Bedeutung. Sie können mithilfe verschiedener Methoden geschätzt werden - Berechnung der gegenseitigen Information (gegenseitige Information) oder Add-Delete-Methode (auch bekannt als schrittweise Regression). Die Anwendung dieser Methoden werden wir zu einem anderen Zeitpunkt behandeln.
Es sei daran erinnert, dass wir die Potentialdifferenz zwischen den Elektroden mit Elektroden messen, was bedeutet, dass wir zu bestimmten Zeitpunkten Spannungskarten für den gesamten Kopf unter Verwendung von Spannungsänderungen an einzelnen Punkten erstellen können. Es ist klar, dass, wenn es 16 Elektroden gibt, die Genauigkeit einer solchen Karte sehr zu wünschen übrig lässt, aber ein gewisses Verständnis sollte hergestellt werden. ( mne erwartet standardmäßig Mikrovolt, aber die Skalierung wurde bereits angewendet, sodass die absoluten Werte nicht korrekt sind.)

Klassifizierung
Schließlich ist es Zeit, maschinelle Lernmethoden auf unsere Stichprobe anzuwenden.
Mehrere grundlegende wurden als Klassifikatoren ausgewählt - ein Protokoll. Regression, die Support-Vektor-Methode (SVM) und mehrere Methoden unter Verwendung der Korrelationsanalyse aus dem pyriemann Paket (Details zu den einzelnen Methoden finden Sie in der Dokumentation). Es ist anzumerken, dass diese Methoden speziell für die Anwendung im EEG entwickelt wurden und mit ihrer Hilfe mehrere Wettbewerbe gewonnen wurden kaggle.
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

Das gebräuchlichste Schema neuronaler Schnittstellen ist "Kalibrierung + Arbeit", d.h. Zunächst ist es notwendig, dass sich eine Person für einige Zeit auf die zuvor angegebenen Reize konzentriert, und erst danach sagen wir ihre Wahl voraus. Dieser Ansatz hat den offensichtlichen Nachteil eines langweiligen Anfangsstadiums.
Um die Leistung unserer Methoden in diesem Modus zu bewerten, führen wir eine Kreuzvalidierung innerhalb einer Person durch.
Die Genauigkeitsmetrik ist in diesem Fall aufgrund des Ungleichgewichts des Datensatzes nicht relevant (die Grundlinie hier ist 5/6 ~ 83%), daher ziehe ich es vor, die Genauigkeits-Rückruf-f1 drei zu betrachten.
Um den gesamten Datensatz zu überprüfen, werden die Ergebnisse einer solchen Kreuzvalidierung über alle Personen gemittelt. Im Allgemeinen ist die Leistung der besten Modelle ziemlich hoch im Vergleich zu dem, was wir bei Neiry unter den "Feldbedingungen" eines Vergnügungsparks haben (ich erinnere mich, dass dieser Datensatz im Labor aufgezeichnet wurde).
In diesem Datensatz gibt es nur binäre Bezeichnungen für die Daten. Im Allgemeinen müssen wir das Mehrklassenproblem der Auswahl eines der Stimuli lösen (übrigens ist es ausgeglichen, da jeder Stimulus gleich oft aktiviert wird). Um dies zu lösen, wird normalerweise die Anzahl der Aktivierungen jedes Stimulus festgelegt (z. B. 6 Stimuli mit jeweils 5 Aktivierungen), und alle Stimuli werden zufällig aktiviert (30-mal), 30 Epochen werden erhalten und die Wahrscheinlichkeiten seiner Aktivierungen werden addiert, um gezielt zu sein, wonach der Stimulus das Maximum erreicht hat der betrag wird als ziel anerkannt. Wir werden die Umsetzung dieses Ansatzes in einem zukünftigen Beitrag an einem geeigneten Datensatz demonstrieren.

Das zweite Schema nennt sich Transferlernen - also die Übertragung des Klassifikators zwischen Personen. Tatsache ist, dass wir bei der Kalibrierung tatsächlich zur Peakform einer Person zurückkehren, sodass wir dies in nachfolgenden Tests gut vorhersagen können. Ohne Kalibrierung sollte ein vorab geschulter Klassifikator in der Lage sein, das P300-Konzept zu isolieren, ohne die Wellenform einer bestimmten Person im Voraus zu kennen.
Wir werden zwei Experimente durchführen - wir werden den Klassifikator auf eine Person trainieren, und wir werden fünf vorhersagen, und dann werden wir die Trainingsstichprobe auf 10 Personen erhöhen und die Ergebnisse vergleichen, um sicherzustellen, dass die Modelle in der Lage sind, ihre Verallgemeinerungsfähigkeit zu erhöhen
Training für 1 Person

Training für 10 Personen
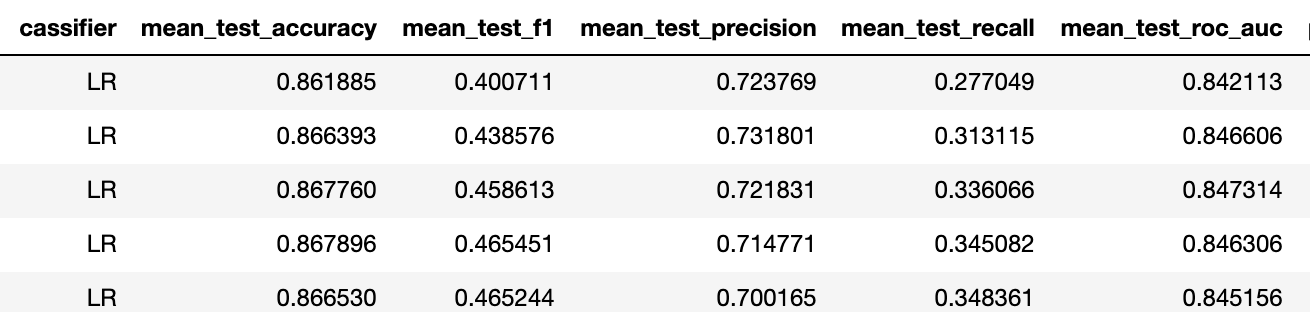
Also stieg f1 für einen besseren Klassifikator von 0,23 auf 0,4 (in beiden Fällen handelt es sich um eine logarithmische Regression mit derselben Regularisierung).
Dies bedeutet, dass die Vorhersagefähigkeit von "nein" auf "akzeptabel" angestiegen ist. Basierend auf unserer Erfahrung reichen mit solchen binären Aufgabenmetriken 5 Aktivierungen jedes Stimulus aus, um die Genauigkeit eines Mehrklassenproblems von etwa 75% zu erreichen.
Abschließend möchte ich darauf hinweisen, dass die obige Methode ziemlich primitiv ist, was zum Beispiel am hohen Grad der Regularisierung der logarithmischen Regression zu erkennen ist - die Kanäle in den Daten sind ziemlich stark korreliert und es gibt verschiedene Ansätze, um diesen Umstand zu lösen.
Fazit
Heute haben wir uns mit dem hervorgerufenen Potenzial des P300 vertraut gemacht und eine einfache Pipeline für die neuronale Schnittstelle erstellt. Ich empfehle Interessenten, einen eigenen Laptop (im Repository ) zu öffnen und mit Visualisierungsoptionen und Klassifikatoren zu experimentieren.
Mit einem grundlegenden Verständnis der Arbeitsweise mit dem EEG-Signal können wir dieses Thema vertiefen - um fortgeschrittene Vorverarbeitungsmethoden sowie neuronale Netze anzuwenden und die Probleme beim Aufbau neuronaler Schnittstellen zu lösen. Fortsetzung folgt...