In den letzten Jahren habe ich eine Maschine entwickelt und hergestellt, mit der LEGO Teile erkannt und sortiert werden können. Der wichtigste Teil der Maschine ist die
Erfassungseinheit , ein kleines, fast vollständig geschlossenes Fach, in dem sich ein Förderband, eine Beleuchtung und eine Kamera befinden.
Die Beleuchtung sehen Sie etwas tiefer.Die Kamera nimmt Fotos der LEGO-Teile auf, die durch den Förderer kommen, und überträgt die Bilder dann drahtlos an einen Server, auf dem ein Algorithmus für künstliche Intelligenz ausgeführt wird, um das Teil unter Tausenden von möglichen LEGO-Elementen zu erkennen. In zukünftigen Artikeln werde ich Ihnen mehr über den AI-Algorithmus erzählen. Dieser Artikel wird sich auf die Verarbeitung konzentrieren, die zwischen der Rohausgabe der Videokamera und der Eingabe in das neuronale Netzwerk durchgeführt wird.
Das Hauptproblem, das ich lösen musste, bestand darin, den Videostream vom Förderer in separate Bilder von Teilen zu konvertieren, die ein neuronales Netzwerk verwenden konnte.
Das ultimative Ziel: Wechseln Sie von einem Rohvideo (links) zu einer Reihe von Bildern derselben Größe (rechts), um sie in ein neuronales Netzwerk zu übertragen. (im vergleich zur realen arbeit ist gif etwa halb so langsam)Dies ist ein großartiges Beispiel für eine Aufgabe, die oberflächlich betrachtet einfach zu sein scheint, aber tatsächlich viele einzigartige und interessante Hindernisse aufwirft, von denen viele für Bildverarbeitungsplattformen einzigartig sind.
Das Abrufen der richtigen Teile eines Bildes auf diese Weise wird häufig als Objekterkennung bezeichnet. Genau das muss ich tun: um das Vorhandensein von Objekten, deren Position und Größe zu erkennen, damit Sie für jedes Teil in jedem Frame
Begrenzungsrechtecke erstellen können.
Das Wichtigste ist, gute Begrenzungsrahmen zu finden (oben in Grün dargestellt)Ich werde drei Aspekte bei der Lösung des Problems berücksichtigen:
- Vorbereiten, um unnötige Variablen zu entfernen
- Erstellen eines Prozesses aus einfachen Bildverarbeitungsvorgängen
- Aufrechterhaltung einer ausreichenden Leistung auf einer Raspberry Pi-Plattform mit begrenzten Ressourcen
Eliminierung unnötiger Variablen
Bei solchen Aufgaben ist es am besten, so viele Variablen wie möglich zu entfernen, bevor Sie Bildverarbeitungstechniken anwenden. Zum Beispiel sollte ich mir keine Gedanken über Umgebungsbedingungen, unterschiedliche Kamerapositionen und Informationsverlust machen, da einige Teile von anderen überlappen. Natürlich ist es möglich (wenn auch sehr schwierig), alle diese Variablen programmgesteuert aufzulösen, aber zum Glück wurde diese Maschine von Grund auf neu erstellt. Ich selbst kann mich auf eine erfolgreiche Lösung vorbereiten und alle Störungen beseitigen, noch bevor ich anfing, Code zu schreiben.
Der erste Schritt besteht darin, die Position, den Winkel und den Fokus der Kamera fest festzulegen. Damit ist alles einfach - im System ist die Kamera über dem Förderer montiert. Ich muss mich nicht um Störungen durch andere Teile kümmern. Unerwünschte Objekte haben fast keine Chance, in die Erfassungseinheit zu gelangen. Ein bisschen komplizierter, aber es ist sehr wichtig,
konstante Lichtverhältnisse zu gewährleisten. Ich brauche den Objekterkenner nicht, um den Schatten eines sich bewegenden Teils auf dem Band fälschlicherweise als ein physisches Objekt zu interpretieren. Glücklicherweise ist die Erfassungseinheit sehr klein (das gesamte Sichtfeld der Kamera ist kleiner als ein Laib Brot), sodass ich mehr als genug Kontrolle über die Umgebungsbedingungen hatte.
Aufnahmeeinheit, Innenansicht. Die Kamera befindet sich im oberen Drittel des Rahmens.Eine Lösung besteht darin, das Fach vollständig geschlossen zu halten, damit keine Außenbeleuchtung eintritt. Ich habe diesen Ansatz mit LED-Streifen als Lichtquelle ausprobiert. Leider hat sich das System als sehr launisch herausgestellt - nur ein kleines Loch im Gehäuse reicht aus, und das Licht dringt in das Fach ein, sodass Objekte nicht erkannt werden können.
Am Ende bestand die beste Lösung darin, alle anderen Lichtquellen zu „verstopfen“, indem das kleine Fach mit starkem Licht gefüllt wurde. Es hat sich herausgestellt, dass die Lichtquellen, mit denen Wohnräume beleuchtet werden können, sehr billig und einfach zu handhaben sind.
Holen Sie sich die Schatten!Wenn die Quelle in das winzige Fach gerichtet ist, werden alle potenziellen externen Lichtstörungen vollständig blockiert. Ein solches System hat auch einen praktischen Nebeneffekt: Aufgrund der großen Lichtmenge in der Kamera können Sie eine sehr hohe Verschlusszeit verwenden, um perfekte Bilder von Teilen zu erhalten, selbst wenn Sie sich schnell auf dem Förderband bewegen.
Objekterkennung
Wie habe ich es geschafft, dieses schöne Video mit gleichmäßiger Beleuchtung in die Bounding-Boxen zu verwandeln, die ich brauchte? Wenn Sie mit AI arbeiten, können Sie mir vorschlagen, ein neuronales Netzwerk zur Objekterkennung wie
YOLO oder
Faster R-CNN zu implementieren. Diese neuronalen Netze können die Aufgabe leicht bewältigen. Leider führe ich Objekterkennungscode auf
Raspberry Pi aus . Sogar ein leistungsfähiger Computer würde Probleme haben, diese Faltungs-Neuronalen Netze mit der Frequenz auszuführen, die ich etwa 90 FPS benötigte. Und Raspberry pi, das keine AI-kompatible GPU hat, könnte mit einer sehr reduzierten Version eines solchen AI-Algorithmus nicht fertig werden. Ich kann Videos von einem Pi auf einen anderen Computer streamen, aber die Echtzeit-Videoübertragung ist ein sehr launischer Prozess. Verzögerungen und Bandbreitenbeschränkungen verursachen schwerwiegende Probleme, insbesondere, wenn Sie eine hohe Datenübertragungsgeschwindigkeit benötigen.
YOLO ist sehr cool! Aber ich brauche nicht alle Funktionen.Glücklicherweise konnte ich eine schwierige AI-basierte Lösung vermeiden, indem ich die Bildverarbeitungstechniken der „alten Schule“ verwendete. Die erste Technik ist die
Hintergrundsubtraktion , bei der versucht wird, alle veränderten Teile des Bildes zu isolieren. In meinem Fall sind die LEGO-Details das einzige, was sich im Sichtfeld der Kamera bewegt. (Natürlich bewegt sich das Band auch, aber da es eine einheitliche Farbe hat, scheint es stationär zur Kamera zu sein). Trenne diese LEGO-Details vom Hintergrund und die Hälfte des Problems ist gelöst.
Damit die Hintergrundsubtraktion funktioniert, müssen sich die Vordergrundobjekte erheblich vom Hintergrund unterscheiden. LEGO-Details haben eine große Auswahl an Farben, daher musste ich die Hintergrundfarbe sehr sorgfältig auswählen, damit sie so weit wie möglich von LEGO-Farben entfernt war. Deshalb besteht das Klebeband unter der Kamera aus Papier - es muss nicht nur sehr homogen sein, sondern kann auch nicht aus LEGO bestehen, sonst hat es die Farbe eines der Teile, die ich erkennen muss! Ich habe mich für Hellrosa entschieden, aber jede andere Pastellfarbe, im Gegensatz zu normalen LEGO-Farben, reicht aus.
Die wunderbare OpenCV-Bibliothek verfügt bereits über mehrere Algorithmen zur Hintergrundsubtraktion. Der MOG2 Background Subtractor ist der komplexeste von ihnen und arbeitet gleichzeitig unglaublich schnell, sogar auf Himbeer-Pi. Das direkte Zuführen von Videobildern zu MOG2 funktioniert jedoch nicht sehr gut. Hellgraue und weiße Figuren kommen der Helligkeit eines blassen Hintergrunds zu nahe und gehen darauf verloren. Ich musste einen Weg finden, um das Klebeband klarer von den darauf befindlichen Teilen zu trennen, und dem Hintergrund-Subtrahierer befehlen, die
Farbe und nicht die
Helligkeit genauer zu betrachten. Dazu hat es mir gereicht, die Bildsättigung zu erhöhen, bevor ich sie auf einen Hintergrund-Subtrahierer übertrug. Die Ergebnisse haben sich deutlich verbessert.
Nachdem ich den Hintergrund subtrahiert hatte, musste ich morphologische Operationen anwenden, um so viel Rauschen wie möglich zu beseitigen. Um die Konturen von weißen Bereichen zu finden, können Sie die Funktion findContours () der OpenCV-Bibliothek verwenden. Indem Sie verschiedene Heuristiken anwenden, um rauschhaltige Schleifen abzulenken, können Sie diese Schleifen einfach in vordefinierte Begrenzungsrahmen konvertieren.
Leistung
Ein neuronales Netzwerk ist eine gefräßige Kreatur. Für beste Ergebnisse bei der Klassifizierung benötigt sie Bilder mit maximaler Auflösung und in möglichst großen Mengen. Dies bedeutet, dass ich sie mit einer sehr hohen Bildrate aufnehmen muss, während die Bildqualität und Auflösung erhalten bleiben. Ich muss das Maximum aus der Kamera und der GPU Raspberry PI herausholen.
Eine sehr ausführliche
Dokumentation für Picamera besagt, dass der V2-
Kamerachip Bilder mit einer Größe von 1280
x 720 Pixeln mit einer maximalen Frequenz von 90 Bildern pro Sekunde erzeugen kann. Dies ist eine unglaubliche Datenmenge, und obwohl die Kamera sie erzeugen kann, bedeutet dies nicht, dass ein Computer damit umgehen kann. Wenn ich rohe 24-Bit-RGB-Bilder verarbeiten würde, müsste ich Daten mit einer Geschwindigkeit von ungefähr 237 MB / s übertragen, was für die schlechte GPU des Pi-Computers und für SDRAM zu viel ist. Selbst wenn die GPU-beschleunigte Komprimierung in JPEG verwendet wird, können 90 fps nicht erreicht werden.
Der Raspberry Pi kann rohe, ungefilterte YUV-Bilder anzeigen. Obwohl es schwieriger ist, mit RGB zu arbeiten als mit RGB, verfügt YUV tatsächlich über viele praktische Eigenschaften. Das wichtigste ist, dass nur 12 Bit pro Pixel gespeichert werden (für RGB sind es 24 Bit).
Alle vier Bytes von Y haben ein Byte U und ein Byte V, dh 1,5 Bytes pro Pixel.Dies bedeutet, dass ich im Vergleich zu RGB-Frames
doppelt so viele YUV-Frames verarbeiten kann, und dies zählt nicht die zusätzliche Zeit, die die GPU beim Konvertieren in ein RGB-Bild einspart.
Dieser Ansatz führt jedoch zu eindeutigen Einschränkungen des Verarbeitungsprozesses. Die meisten Vorgänge mit einem Videobild in voller Größe verbrauchen extrem viel Speicher und CPU-Ressourcen. Innerhalb meiner strengen Fristen ist es nicht einmal möglich, ein YUV-Vollbild zu dekodieren.
Zum Glück muss ich nicht den gesamten Frame verarbeiten! Für die Erkennung von Objekten müssen Begrenzungsrechtecke nicht genau sein. Die ungefähre Genauigkeit ist ausreichend, sodass der gesamte Prozess der Erkennung von Objekten mit einem viel kleineren Rahmen ausgeführt werden kann. Beim Verkleinern müssen nicht alle Pixel eines Vollbilds berücksichtigt werden, sodass Bilder sehr schnell und kostenlos verkleinert werden können. Dann vergrößert sich der Maßstab der resultierenden Begrenzungsrechtecke erneut und wird zum Ausschneiden von Objekten aus einem YUV-Frame in voller Größe verwendet. Dank dessen muss ich nicht den gesamten hochauflösenden Frame dekodieren oder anderweitig verarbeiten.
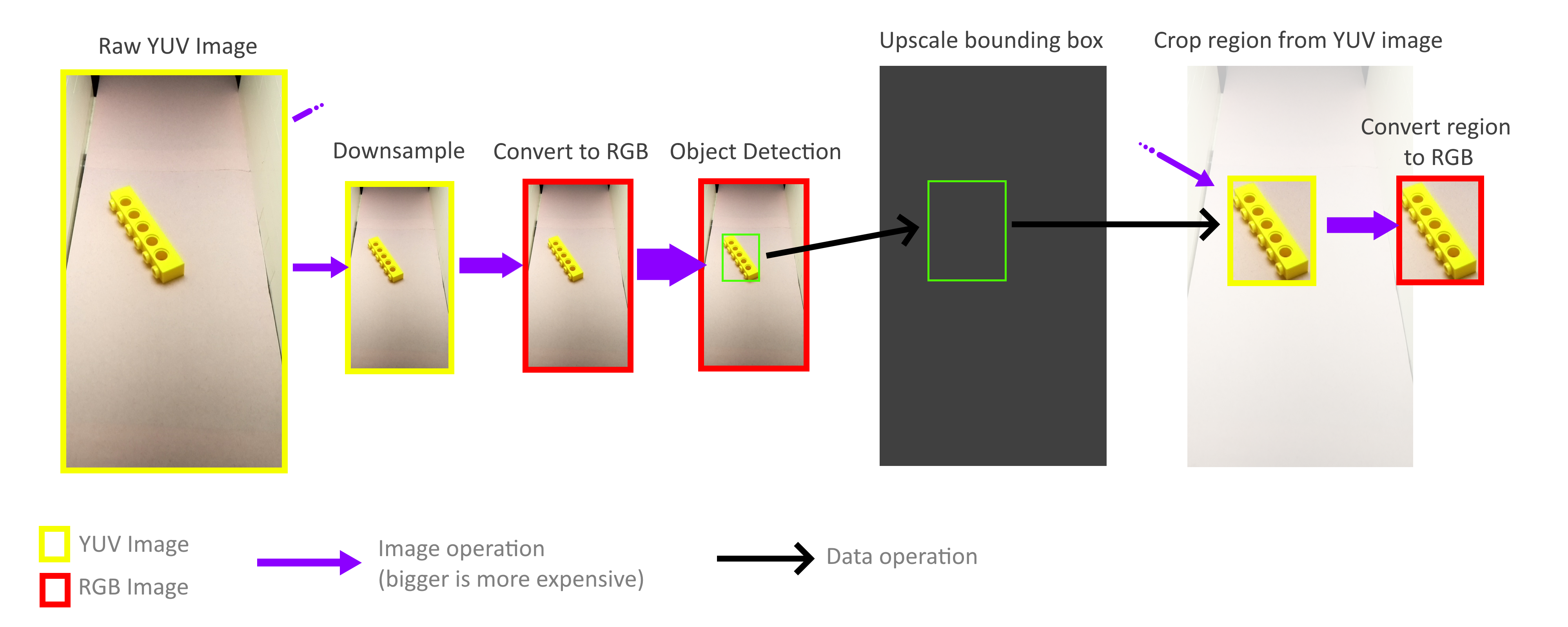
Glücklicherweise ist es dank der Speichermethode dieses YUV-Formats (siehe oben) sehr einfach, schnelle Beschneidungs- und Zoomvorgänge zu implementieren, die direkt mit dem YUV-Format arbeiten. Darüber hinaus kann der gesamte Prozess problemlos auf vier Pi-Kerne parallelisiert werden. Ich habe jedoch herausgefunden, dass nicht alle Kerne ihr volles Potenzial ausschöpfen, und dies zeigt, dass die Speicherbandbreite immer noch der Engpass ist. Trotzdem schaffte ich es, in der Praxis 70-80 FPS zu erreichen. Eine genauere Analyse der Speichernutzung kann dazu beitragen, die Dinge noch weiter zu beschleunigen.
Wenn Sie mehr über das Projekt erfahren möchten, lesen Sie meinen vorherigen Artikel:
„Wie ich mehr als 100.000 LEGO-Bilder zum Lernen erstellt habe .
“Video der Bedienung der gesamten Sortiermaschine: