Ich werde die Implementierung der Grundtypen in CPython ohne Eile weiter analysieren. Zuvor wurden
Wörterbücher und
ganze Zahlen in Betracht gezogen. Diejenigen, die der Meinung sind, dass ihre Implementierung nichts Interessantes und Listiges enthalten kann, werden aufgefordert, diesen Artikeln beizutreten. Diejenigen, die sie bereits gelesen haben, wissen, dass CPython viele interessante Funktionen und Implementierungsfunktionen hat. Sie können hilfreich sein, wenn Sie Ihre eigenen Skripte schreiben, oder als Leitfaden für Architektur- und Algorithmuslösungen. Die Zeichenfolgen sind hier keine Ausnahme.
Beginnen wir mit einem kurzen Exkurs in die Geschichte. Python erschien 1990-91. Anfänglich gab es bei der Entwicklung der Basiscodierung in Python ein gutes altes Einzelbyte-ASCII. Ungefähr zur gleichen Zeit (etwas später) hatte die Menschheit es satt, sich mit dem „Zoo“ der Kodierungen zu befassen, und 1991 wurde der Unicode-Standard vorgeschlagen. Aber auch beim ersten Mal hat es nicht funktioniert. Die Einführung von Zwei-Byte-Codierungen begann, aber bald wurde klar, dass zwei Byte nicht für alle ausreichen würden. Es wurde eine 4-Byte-Codierung vorgeschlagen. Leider schien die Zuweisung von 4 Byte für jedes Zeichen eine Verschwendung von Speicherplatz und Arbeitsspeicher zu sein, insbesondere in den Ländern, in denen zuvor ein Einzelbyte-ASCII-Wert ausreichte. Mehrere Krücken wurden in eine 2-Byte-Codierung gesägt, um mehr Zeichen zu unterstützen, und all dies ähnelte der vorherigen Situation mit dem „Zoo“ der Codierungen.
1993 wurde utf-8 eingeführt. Was ein Kompromiss war: ASCII war eine gültige Teilmenge von UTF-8, alle anderen Zeichen haben es erweitert. Um diese Möglichkeit zu unterstützen, mussten wir uns jedoch von einer festen Länge jedes Zeichens trennen. Aber er war dazu bestimmt,
alle zu
regieren , um genau Unicode zu werden, dh eine einzelne Codierung, die von den meisten Programmen unterstützt wird, in denen die meisten Dateien gespeichert sind. Dies wurde insbesondere durch die Entwicklung des Internets beeinflusst, da Webseiten normalerweise nur utf-8 verwenden.
Die Unterstützung für diese Codierung wurde schrittweise in Programmiersprachen eingeführt, die wie Python vor utf-8 entwickelt wurden und daher andere Codierungen verwendeten. Es gibt
PEP mit einer netten Nummer 100, die die Unicode-Unterstützung behandelt. In
PEP-0263 wurde es möglich, die Kodierung der Quelldateien zu deklarieren. Die Ascodierung war immer noch die Basiscodierung, das Präfix "u" wurde verwendet, um Unicode-Zeichenfolgen zu deklarieren, die Arbeit mit ihnen war immer noch nicht praktisch und natürlich genug. Es bestand jedoch die Möglichkeit, die folgende Häresie zu erstellen:
class 비빔밥: _ = 2 א = 비빔밥() print(א)
Am 3. Dezember 2008 fand ein historisches Ereignis für die gesamte Python-Community statt (und angesichts der Verbreitung dieser Sprache, vielleicht auch für die ganze Welt) - Python 3. Es wurde beschlossen, die Probleme ein für alle Mal zu beenden, weil viele Codierungen, und daher ist Unicode die Basiscodierung geworden. Wir erinnern uns jedoch, dass die Codierung kompliziert ist und beim ersten Mal nicht funktioniert. Diesmal hat es auch nicht geklappt.
Der große Nachteil von utf-8 ist, dass die Länge des Zeichens nicht festgelegt ist, was dazu führt, dass eine so einfache Operation wie der Zugriff auf den Index die Komplexität O (N) hat, da der Versatz des Elements nicht im Voraus bekannt ist. Zum Speichern eines Strings zugewiesen, können Sie dessen Länge nicht in Zeichen berechnen.
Um all diese Probleme in Python zu vermeiden, wurde entschieden, 2- und 4-Byte-Codierungen (je nach Plattform) zu verwenden. Die Indexbehandlung wurde vereinfacht - der Index musste nur mit 2 oder 4 multipliziert werden. Dies brachte jedoch die folgenden Probleme mit sich:
- Jede Plattform hatte ihre eigene Codierung, was zu Problemen mit der Code-Portabilität führen konnte
- Erhöhter Speicherverbrauch und / oder Codierungsprobleme für schwierige Zeichen, die nicht in zwei Bytes passen
Eine Lösung für diese Probleme wurde in
PEP-393 vorgeschlagen , und wir werden darüber sprechen.
Es wurde beschlossen, die Zeilen als Array von Zeichen zu belassen, um den Zugriff durch Index- und andere Operationen zu erleichtern. Die Länge der Zeichen begann jedoch zu variieren. Beim Erstellen einer Zeichenfolge durchsucht der Interpreter alle Zeichen und weist jedem Byte die Anzahl der zum Speichern der „größten“ erforderlichen Bytes zu. Wenn Sie also eine ASCII-Zeichenfolge deklarieren, sind alle Zeichen ein Byte, wenn Sie der Zeichenfolge jedoch ein Zeichen hinzufügen möchten Aus der kyrillischen Sprache werden alle Zeichen bereits aus zwei Bytes bestehen. Es gibt drei mögliche Optionen: 1, 2 und 4 Bytes pro Zeichen.
Der Zeichenfolgentyp (PyUnicodeObject) wird
wie folgt deklariert:
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
PyCompactUnicodeObject stellt wiederum die
folgende Struktur dar (mit einigen Vereinfachungen und meinen Kommentaren):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
Somit sind 4 Zeilendarstellungen möglich:
- Legacy-String, fertig
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- Legacy-String, nicht fertig
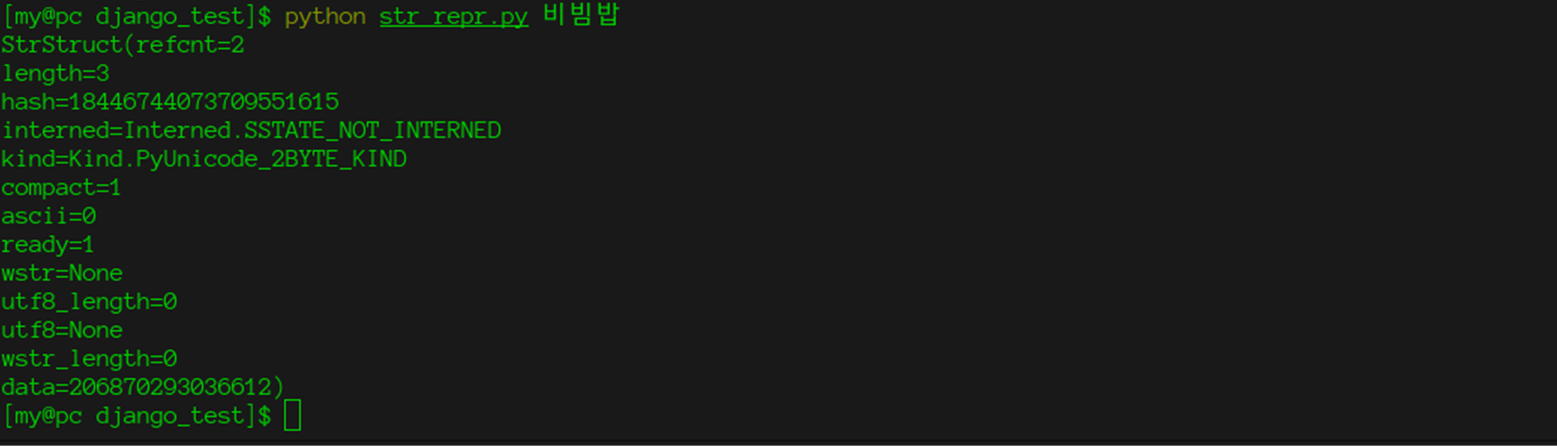
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- kompakte Ascii
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- kompakt
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
Es ist zu beachten, dass Python 3 auch die Syntax zum Deklarieren von Unicode-Strings über das Präfix "u" unterstützt.
>>> b = u"" >>> b ''
Diese Funktion wurde hinzugefügt, um die Portierung von Code von der zweiten auf die dritte Version in
PEP-414 in Python 3.3 erst im Februar 2012 zu vereinfachen. Ich möchte Sie daran erinnern, dass Python 3 im Dezember 2008 veröffentlicht wurde, aber niemand hatte es eilig mit dem Übergang.
Mit diesem Wissen und dem Standardmodul ctypes können wir auf die internen Felder des Strings zugreifen.
import ctypes import enum import sys class Interned(enum.Enum):
Und brechen Sie sogar den Interpreter, wie Sie es im
vorherigen Teil getan haben.
HAFTUNGSAUSSCHLUSS: Der folgende Code wird so wie er ist geliefert, der Autor übernimmt keine Verantwortung und kann den Zustand des Dolmetschers sowie die geistige Gesundheit von Ihnen und Ihren Kollegen nach der Ausführung dieses Codes nicht garantieren. Der Code wurde auf cpython Version 3.7 getestet und funktioniert leider nicht mit ASCII-Strings.
Ändern Sie dazu den oben beschriebenen Code in:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
In diesen Beispielen wird die in
Python 3.6 hinzugefügte Zeichenfolgeninterpolation verwendet. Python kam nicht sofort zu dieser Methode, um Zeichenfolgen auszugeben:% syntax, format, so etwas
wie perl wurden ausprobiert (eine ausführlichere Beschreibung mit Beispielen finden Sie
hier ).
Vielleicht war diese Änderung für seine Zeit (vor Python 3.8 mit seinem `: =` Operator) die umstrittenste. Die Diskussion (und Verurteilung) wurde sowohl über
reddit als auch in Form von
PEP geführt . Verbesserungs- / Korrekturideen wurden in Form von
i-lines ausgedrückt
, für die Benutzer ihre Parser schreiben konnten, um die Kontrolle zu verbessern und SQL-Injections und andere Probleme zu vermeiden. Diese Änderung wurde jedoch verschoben, damit sich die Leute an die F-Linien gewöhnen und etwaige Probleme erkennen.
F-Linien haben eine Besonderheit (Nachteil): Sie können keine Sonderzeichen mit Schrägstrichen angeben, z. B. '\ n' '\ t'. Dies kann jedoch leicht umgangen werden, indem eine separate Zeile mit Sonderzeichen deklariert und an die f-Zeile übergeben wird, wie im obigen Beispiel beschrieben. Sie können jedoch geschachtelte Klammern verwenden.
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
Wie Sie sehen, speichern Strings ihren Hash, und es gab einen
Vorschlag, diesen Wert zum Vergleichen von Strings zu verwenden, basierend auf einer einfachen Regel: Wenn die Strings identisch sind, haben sie denselben Hash, und daraus folgt, dass die Strings mit unterschiedlichen Hashes nicht identisch sind. Es blieb jedoch unerfüllt.
Beim Vergleich zweier Zeichenketten wird geprüft, ob sich die Zeiger auf die Zeichenketten auf dieselbe Adresse beziehen. Wenn nicht, wird ein zeichenweiser Vergleich oder ein memcmp gestartet, wenn dies zulässig ist.
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
Der Hash-Wert wirkt sich jedoch indirekt auf den Vergleich aus. Tatsache ist, dass in cpython Zeichenfolgen interniert, d. H. In einem einzelnen Wörterbuch gespeichert werden. Dies gilt nicht für alle Zeilen, alle Konstanten, Wörterbuchschlüssel, Felder und Variablen sowie ASCII-Zeilen mit einer Länge von weniger als 20 werden interniert.
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
Und die leere Zeichenfolge ist in der Regel Singleton
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
Wie wir sehen können, war cpython in der Lage, eine einfache, aber gleichzeitig effiziente Implementierung des Zeichenfolgentyps zu erstellen. In einigen Fällen war es dank der memcmp- und memcpy-Funktionen möglich, den verwendeten Speicher zu reduzieren und Vorgänge zu beschleunigen, anstatt zeichenweise. Wie Sie sehen, ist der String-Typ überhaupt nicht so einfach zu implementieren, wie es beim ersten Mal scheinen mag. Aber die Entwickler von cpython sind sehr geschickt mit ihrem Geschäft umgegangen und deshalb können wir es nutzen und nicht einmal darüber nachdenken, was sich unter der Haube verbirgt.