
Ich saß friedlich auf einem Seminar, hörte mir den Bericht eines Studenten über einen Artikel aus dem vergangenen
CVPR an und googelte gleichzeitig das Thema.
- Zu den Vorteilen des Artikels gehört die Verfügbarkeit von Quellcode ....
Ich musste eingreifen:
- Die Anwesenheit von was, entschuldigen Sie mich?
- Ähh ... Quellcode ...
"Hast du es gesehen?"
- Nein, aber der Artikel besagt ...
(Mutter-Mutter-Mutter ... hallte gewohnheitsmäßig)ㅡ Sind Sie dem Link gefolgt?
Der Artikel ist in der Tat sehr ermutigend geschrieben: "Der Code und das Modell sind auf der Projektseite öffentlich verfügbar ... / imtqy.com / ...". In dem Commit vor zwei Jahren wurde jedoch der inspirierende Link "Code und Modell werden in Kürze veröffentlicht" :
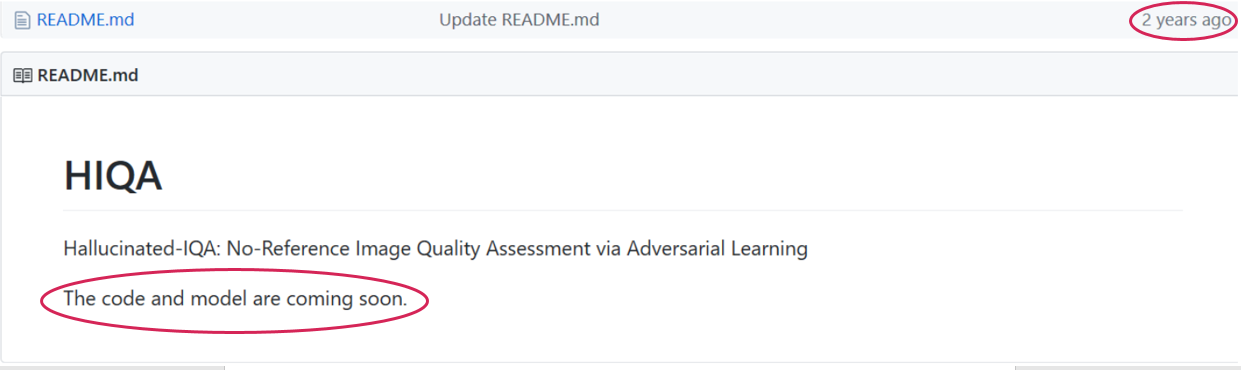
Suchen und finden, klopfen und öffnen ... Vielleicht ... Oder vielleicht auch nicht. Aufgrund meiner traurigen Erfahrung würde ich es auf die zweite setzen, da sich die Situation in letzter Zeit wiederholt hat, oh, oh, sehr oft. Auch bei CVPR. Und das ist nur ein Teil des Problems! Quellen können verfügbar sein, aber zum Beispiel nur ein Modell, ohne Trainingsskripte. Und es mag Lernskripte geben, aber für mehrere Monate mit Briefen an die Autoren ist es unmöglich, dasselbe Ergebnis zu erzielen. Oder für ein Jahr in einem anderen Datensatz mit regelmäßigen Skype-Anrufen ist ein Autor in den USA nicht in der Lage, sein Ergebnis zu reproduzieren, das er im bekanntesten Labor der Branche zu diesem Thema erhalten hat ... Eine Art von Tryndets.
Und anscheinend sehen wir bisher nur Blumen. In naher Zukunft wird sich die Situation dramatisch verschlechtern.
Wen kümmert es,
was mit dem Studenten passiert ist, in dessen Richtung sich die wissenschaftliche Welt bewegt?
Reproduzierbarkeitskrise
GIBT ES 2016
EINE REPRODUZIERBARKEITSKRISE? (Gibt es jetzt eine Reproduzierbarkeitskrise)? , die die Ergebnisse einer Umfrage unter 1576 Forschern zitierten:
 Quelle: Diese und die folgenden Grafiken in diesem Abschnitt sind ein Artikel in Nature.
Quelle: Diese und die folgenden Grafiken in diesem Abschnitt sind ein Artikel in Nature.Nach den Ergebnissen der Umfrage glauben 52% der Forscher, dass es eine signifikante Krise gibt, 38% - eine milde Krise (insgesamt 90%!), 3% - dass es keine Krise gibt und 7% - wurden nicht ermittelt.
Die verschwörerische Version des Autors - angesichts des Ausmaßes der Katastrophe wollen letztere einfach keine "übermäßige" Aufmerksamkeit auf die Frage lenken:

Wenn man sich die Disziplinen ansieht, stellt sich heraus, dass die Chemie an erster Stelle steht, die Biologie an zweiter Stelle und die Physik an dritter Stelle:
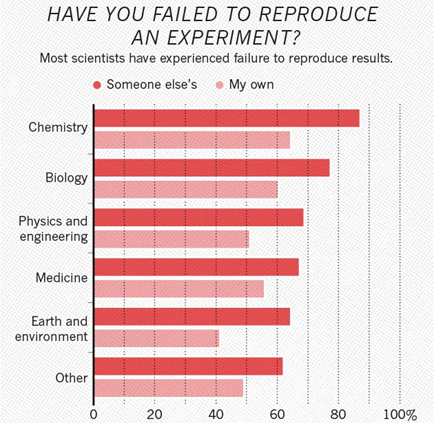
Interessanterweise fanden es zum Beispiel in der Chemie mehr als 60% der Forscher unmöglich, ihre eigene Forschung zu reproduzieren. In der Physik sind dies ebenfalls mehr als 50%.
Sehr interessant ist auch,
was genau aus Sicht der Forscher den größten Beitrag zur Krise der Irreproduzierbarkeit leistet:

An erster Stelle steht „Selektive Berichterstattung“. Für die Informatik ist dies eine Situation, in der der Autor beispielsweise die besten Beispiele für Veröffentlichungen auswählt, an denen der Algorithmus arbeitet, und nicht detailliert beschreibt, wo und was nicht funktioniert.
Interessanterweise ist die zweite "Druck zu veröffentlichen." Dies ist ein sehr bekanntes Prinzip von „Publish or Perish“.
Ein Artikel in der englischsprachigen Wikipedia beschreibt das Problem gut. Es gibt in der russischen Wikipedia keinen Artikel zu diesem Thema, obwohl das Problem an Orten mit einer hohen Bezahlung für wissenschaftliche Arbeit relevant wird. Beispielsweise sind an einer Top-Universität mit einem guten Gehalt (ich spreche leider nicht von meiner Heimatuniversität Moskau) hohe Publikationsergebnisse für die Rezertifizierung von entscheidender Bedeutung. Wenn Sie weiterarbeiten möchten, veröffentlichen Sie diese bitte. Ein Kadaver, eine Vogelscheuche, was auch immer, aber so, dass die Punkte waren.
Beachten Sie auch, dass "Methoden, Code nicht verfügbar" in 45% der Fälle und manchmal in 82% der Fälle häufig vorkommt. Nun, in 40% der Fälle wird direkt Betrug als Grund angegeben, d. H. ziemlich oft. Ich habe kürzlich mit einem chinesischen Professor gesprochen, der auf dem Gebiet der Videokomprimierungsalgorithmen arbeitet. Er sagte, dass es in China viele Artikel mit bewusstem Betrug gebe, sie seien einfach eine Geißel geworden. Bei betrügerischen externen Veröffentlichungen werden sie dort schnell entlassen, und sie versuchen, die Anforderungen zu erfüllen. Im Inneren entsteht jedoch ein Albtraum (siehe z. B. den Artikel
„In China veröffentlichen oder untergehen“ in Nature). Ein Albtraum, auch aus folgendem Grund in der Liste „Unzureichende Begutachtung“ - es gibt nicht genug Kraft für eine qualitativ hochwertige Begutachtung.
Ein besonderes großes Problem, das ich nur kurz erwähnen möchte: Konnte das Ergebnis nicht reproduziert werden, ist es fast unmöglich, einen Artikel darüber zu veröffentlichen ...

Jeder ist an neuen Errungenschaften, neuen Beiträgen und neuen Ideen interessiert und was alt ist, funktioniert nicht - welchen Unterschied macht es? Dies erhöht natürlich den Anteil nicht reproduzierbarer Ergebnisse, einschließlich vorsätzlichen Betrugs. Höchstwahrscheinlich wird niemand verstehen, dass dies nicht akzeptiert wird. Es ist offensichtlich, dass, wenn andere auf einem falschen Ergebnis basieren, das gesamte System instabil wird, was letztendlich alle betrifft:
 Ihre Wetten
Ihre Wetten - haben Sie
Zeit, ihm auszuweichen oder ihn zu vernichten?Gesamt:
- Laut einer Umfrage unter 1.576 in Nature veröffentlichten Forschern glauben 52%, dass es derzeit eine erhebliche Krise der Reproduzierbarkeit gibt, und 90% stimmen zu, dass es eine solche Krise gibt.
- Darüber hinaus blüht die derzeitige Situation immer noch und bald wird sich alles verschlechtern, insbesondere in der Informatik. Warum? Finde es jetzt heraus.
Reproduzierbarkeit in der Informatik
An der Arizona State University (die in Bezug auf die Anzahl der Studenten übrigens doppelt so groß ist wie die Moskauer State University)
wurde in der Abteilung des Programmierers eine spezielle Website eingerichtet, die sich der Untersuchung der Reproduzierbarkeit ihrer Ergebnisse in 601 Artikeln aus Zeitschriften widmet und
ACM- Konferenzen. Das Ergebnis war das folgende Bild:

 Quelle: Wiederholbarkeit in der Informatik
Quelle: Wiederholbarkeit in der InformatikSie haben 106 Artikel nicht überprüft, weil sie die Reinheit des Experiments nicht verletzen wollten (sie haben an die Autoren geschrieben und den Code angefordert).
- In 93 Artikeln (19%) gibt es keinen Code oder es gab Hardware, mit der sie nicht verglichen werden konnten.
- in 176 Artikeln (35%) gaben die Autoren keinen Code an,
- in 226 Artikeln (46%) war der Code, in 9 (2%) war das Sammeln nicht möglich und in 87 (64 + 23) Artikeln (18%) dauerte es mehr als eine halbe Stunde, um die Probleme bei der Zusammenstellung des Projekts zu lösen (in 23 Fällen wurden die Probleme beseitigt) gescheitert, aber der Autor versichert, dass "mehr Anstrengungen" alles gesammelt hätte).
Ich muss sagen, dass nach unserer Erfahrung nach der Versammlung das Interessanteste erst am Anfang steht, aber in der Studie haben sie beschlossen, in diesem Stadium aufzuhören, und bei so vielen von ihnen können Sie verstehen. In jedem Fall sind die Statistiken sehr aufschlussreich, und 35% der Ablehnungen, den Code bereitzustellen, entsprechen in etwa der Zeile „Methoden, Code nicht verfügbar“ der vorherigen Studie (drittes Diagramm).
Im Allgemeinen ist das Thema ziemlich gut ausgegraben. Insbesondere ist der „Gold Standard“ die Verfügbarkeit von Code und Daten, mit denen das Ergebnis leicht vollständig wiederholt werden kann, und der schlechteste Ansatz ist die Einreichung nur von Artikeln:
 Quelle: Konzeptualisierung, Messung und Untersuchung der Reproduzierbarkeit
Quelle: Konzeptualisierung, Messung und Untersuchung der ReproduzierbarkeitWarum passiert das?
Wie bei jedem komplexen Phänomen gibt es mehrere Gründe:
- Im Westen ist das bereits erwähnte "Publish or Perish" sehr einflussreich. In Seminaren und Workshops werden junge grüne Doktoranden absolut ernst genommen und unmissverständlich angeleitet - „Eine Idee ist gekommen, veröffentlichen Sie sie zuerst! Und erst dann nachschauen! “(Wer hat Wildheit gesagt? Harte Realität, meine Herren!) Priorität in der Wissenschaft ist wirklich wichtig (auch für das berüchtigte Zitat), daher wird eine interessante Idee zuerst veröffentlicht (manchmal mit gefälschten Daten). , manchmal nicht) und erst dann fangen sie an, lange Zeit schmerzhaft etwas zu programmieren und ziehen oft eine Eule auf den Globus. Der am Anfang dieses Textes als erstes Beispiel aufgeführte Artikel scheint nur einer davon zu sein (halluzinogene neuronale Netze ... Ich frage mich, was sie geraucht haben? Aber es kam zu CVPR!). Das Ergebnis ist ein übergewichtiges weißes Pelztier, da sich die Situation weiter verschlechtert:

- Üblicherweise gibt der Staat die Hälfte des Forschungsgeldes (irgendwo mehr, irgendwo weniger). Und Regierungsgeld provoziert Publikationswahnsinn (wenn es veröffentlicht wird, nur um es zu veröffentlichen). Die andere Hälfte des Geldes kommt von Unternehmen, und die Unternehmen sprechen eindeutig von Veröffentlichungsbeschränkungen. Ein beliebtes koreanisches Unternehmen, das russischen Wissenschaftlern die Möglichkeit bot, nach dem treffenden Ausdruck eines Kollegen „für Perlen“ zu arbeiten, war vor allem für seine
Negerbedingungen für Institute und Universitäten bekannt. Ja, jetzt haben sie im Lohnwettlauf sogar den Markt für neuronale Netze durchbrochen, aber im Allgemeinen ist das erste, was einen schrecklichen Vertrag anbietet, die Corporate Identity solcher asiatischen Unternehmen. Und wenn ein gut geschriebener Artikel nicht veröffentlicht werden darf, und dann ein anderer und mehr - dann demotiviert er natürlich stark. Dies wird auch nach einigen Jahren nicht vergessen.
Infolgedessen geht das Ergebnis an Patente mit einem Minimum an Artikeln. Es ist interessant, dass ich mit Kollegen aus Finnland, den USA, Frankreich usw. gesprochen habe. Dort sitzen viele Leute fest auf Zuschüssen, aber diejenigen mit vielen Unternehmen veröffentlichen nicht alle Ergebnisse, und wenn sie veröffentlichen, reduzieren sie (kulturell gesehen) auf irgendeine Weise die Beschreibung des Ansatzes, was natürlich die Reproduktion kompliziert. Dafür wurde bereits bezahlt.
Gesamt:
- Auch nach dringenden Anfragen wird der Code in maximal 46% der Fälle verschickt (übrigens, lest die Studie , es gibt interessante Beispiele für "Ausreden", die nach unserer Erfahrung genau diese grundsätzlich verschicken).
- Das Wissenschaftsfinanzierungssystem selbst motiviert entweder dazu, nicht überprüfte Ergebnisse so schnell wie möglich zu veröffentlichen, oder schränkt Veröffentlichungen ein, auch im Hinblick auf die vollständige Offenlegung. In beiden Fällen nimmt die Reproduzierbarkeit ab.
Warum maschinelles Lernen alles noch schlimmer macht
Das ist aber noch nicht alles! In letzter Zeit hat sich das maschinelle Lernen im Allgemeinen und neuronale Netze im Besonderen rasch verbreitet. Das ist cool. Es funktioniert großartig. Das völlig Unmögliche von gestern wird heute möglich! Nur eine Art Urlaub! Also?
Nein. Neuronale Netze haben der Informatik eine neue Runde des Eintauchens in den Abgrund der Irreproduzierbarkeit hinzugefügt.
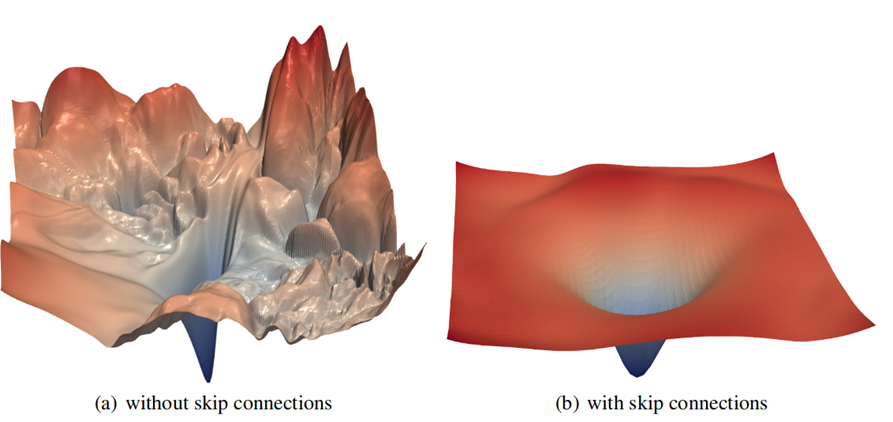
Hier ist ein einfaches Beispiel: Es sieht aus wie die Verlustfunktion für
ResNet-56 ohne Überspringen von Verbindungen (Visualisierung einiger Parameter aus mehreren zehn Millionen). Unsere Aufgabe für eine angemessene Anzahl von Iterationen (Epochen) ist es, den tiefsten Punkt zu finden:
 Quelle: Visualisierung der Verlustlandschaft neuronaler Netze
Quelle: Visualisierung der Verlustlandschaft neuronaler NetzeSie können deutlich das Meer der lokalen Minima sehen, in das unser Gefälle freudig „fällt“ und „nicht raus kann“. Ja, es ist klar, dass dieses Beispiel für ResNet als hervorragende Illustration dient, die durch das
Überspringen von Verbindungen bereitgestellt wird (nach der Einführung wird das Lernen im Netzwerk dramatisch verbessert):
Denn es ist eine Sache, ein Minimum in einer komplexen Landschaft zu finden (und nur die unerschwingliche Gesamtdimension des Suchraums hilft), und es ist eine ganz andere Sache, ein globales Minimum zu sehen, das mit Verläufen relativ leicht zu finden ist.
Die Geschichte ist schön, aber in unserer harten Realität mit einer großen Anzahl von Schichten müssen wir uns immer wieder der Tatsache stellen, dass das Netzwerk nicht lernt. Im Allgemeinen.
Und was noch interessanter ist - irgendwann ist es möglich, es zu trainieren (der Fehler sinkt stark), aber nach einiger Zeit, wenn versucht wird, das Ergebnis von Grund auf neu zu reproduzieren (zum Beispiel, wenn diese Koeffizienten verloren gehen), ist es nicht möglich, den Fokus zu wiederholen, und es gibt eine offensichtliche schmerzhafte Reise des Netzwerks in der Ferne von einem Minimum. Hunderte von
Epochen folgen aufeinander, und der Wagen bleibt an Ort und Stelle. Die Steinblume kommt nicht von Danila, dem Meister.
Es war ziemlich schwierig, sich eine Situation vorzustellen, in der ein Forscher seine eigenen Ergebnisse in der Informatik nicht reproduzieren kann. Heute ist es alltäglich geworden, wie es lange Zeit in der Physik, Chemie, Biologie und auf der Liste stand.
Mit neuronalen Netzen wurde die Informatik plötzlich zu einer experimentellen Wissenschaft! Willkommen in dieser wundervollen Welt. Jetzt werden Sie zunehmend mit der Unfähigkeit konfrontiert sein, Ihr
eigenes Ergebnis zu reproduzieren (wie 64% der Chemiker, 60% der Biologen, siehe die zweite Grafik dieses Artikels).
Das sind aber nicht alle Freuden. Mehr wird mehr Spaß machen!
Im Allgemeinen war ich ziemlich lange skeptisch gegenüber neuronalen Netzen, da die darauf basierenden Algorithmen nicht funktionierten. Na ja ... Sie haben natürlich irgendwie funktioniert, aber bei großen Samples verloren sie gegenüber den "klassischen" Algorithmen der neuesten Generation (was sie nicht davon abhielt, in der Masse veröffentlicht zu werden). Dies geschah, weil die neuronalen Netze für alle Arten von Betrug äußerst praktisch sind. Die Hauptsache ist, ein Trainingsmuster für Beispiele richtig auszuwählen und Sie können natürlich Wunder demonstrieren. Es entstehen schöne Bilder (und manchmal auch schöne Grafiken), und der Artikel passt gut. Sie können sogar den Code auslegen (es scheint in Mode gekommen zu sein), dies ändert nichts an der Essenz. Es funktioniert nicht Aber wenn der große rote
PoP- Hahn mit einem riesigen scharfen Schnabel dahintersteht ... ist der Artikel eine Feige und geht zum Drucken.

Ein separates Hauptproblem sind Bereiche, in denen es keine großen Trainingsmuster gibt. Kollegen aus der Medizin beschweren sich - ein kompletter Albtraum passiert. Sie sammeln seit Jahren Datensätze. Und es gibt sogar Zehntausende von Beispielen. Aber Doktoranden mit tiefen neuronalen Netzen kommen. Figak-figak und überholte alle ... Schön! Die Giganten der Wissenschaft! Und mit fröhlichen hellen Gesichtern berichten die Ergebnisse. Sie werden gefragt:
- Was hast du getan, um eine Überanpassung zu verhindern?
- Entschuldigung?
- Warum hast du keine Umschulung?
Und ein Mann erzählt absolut ernsthaft, wie er das richtige Netzwerk genommen und streng nach dem Trainingshandbuch trainiert hat, und daher ist alles in Ordnung mit ihm. Das heißt Jugendliche (massiv!) verstehen nicht, was Umschulung ist! Nicht einer, nicht zwei, sondern nur ein beachtlicher Anteil von Postgraduiertenberichten. Hier ist es, eine neue Welle junger Revolutionäre des neuronalen Netzes. Wir erinnern uns an
Professor Preobraschenski und seufzen heftig über den Analphabetismus, der für junge Revolutionäre traditionell ist. Wir ziehen Schlussfolgerungen.
Aber das ist in Ordnung. Auf der jüngsten
ITIS 2019 hat Mikhail Belyaev wundervolle Beispiele gegeben, wie dieser Ansatz für die medizinische Produktion recht gut funktioniert! In realen Unternehmen, die Analysen mit neuronalen Netzen anbieten, haben sie Kontrolltests bestanden und unerwartet traurige Ergebnisse erhalten. Der Grund dafür ist, dass Investoren auch eine Revolution gespürt haben und wenn jemand neue Horizonte verspricht, die auf neuronalen Netzen basieren, dann gibt er ihm Geld (der aufschlussreiche Anatoly Levenchuk
warnte davor bereits 2015, ein halbes Jahr nach der Erfindung der
Benchmark , und ein halbes Jahr vor ResNet, wann viele Schichten sind noch schlecht ausgebildet). Und zahlen Sie dafür, liebe Herren! Und ja, es wäre besser, zuerst mit Mäusen zu experimentieren, aber Mäuse haben, wie ein bekannter Zyniker sagte, keine Brieftaschen! Aus diesem Grund werden Daten für das Training jetzt mit Verbrauchergeldern gesammelt (kulturell ausgedrückt), d. H. auf dein geld. Leute, seid wachsam!
Es ist klar, dass nicht die neuronalen Netze schuld sind. Die große Frage ist, wie Sie eine ausreichende Menge benachbarter Daten erhalten, sie auf eine kleine Stichprobe anpassen, ein
katastrophales Vergessen vermeiden und das ist alles. Aber selbst wenn Sie kompetente Forscher haben, wird es einige Zeit dauern. Und der Investor will
hier und gestern ein Ergebnis. Freut man sich also über die Erfolgswelle der neuronalen Netze?
Wir erhalten einen großen
Schaum einer großen
Welle , wenn inoperative Methoden tatsächlich die Brandung großer Wellen zur realen Verwendung schleppten. Zahlen Sie bitte die Rechnung!
Insgesamt: Neuronale Netze verschlechtern die Situation in der Informatik in drei Bereichen:
- Mit dem Training neuronaler Netze wird CS der ersteren zu einer experimentellen Wissenschaft mit allen daraus resultierenden Nachteilen.
- Wenn Sie das Trainingsmuster an das Testmuster anpassen, können Sie ein beliebig schönes Ergebnis nachweisen (was den Hauptgrund für die Nichtreproduzierbarkeit verschärft - selektives Berichten).
- Und schließlich ist es in Bereichen, in denen die Trainingsstichproben klein sind, äußerst schwierig, eine Umschulung zu vermeiden, mit der viele nicht umgehen und arbeiten können (formal ist das Ergebnis im Datensatz hervorragend, aber tatsächlich funktioniert der Algorithmus nicht).
Was kann getan werden?
Wenn Sie (eine glückliche Person!) In gut ausgegrabenen Gebieten arbeiten, müssen Sie häufig nur Datensätze vorbereiten und sie an Netzwerke weiterleiten. Es sei denn, es lohnt sich, Architekturen zu betrachten. In diesem Fall macht es keinen Sinn, Artikel ohne Code anzusehen. Und das ist ein echter Urlaub! Fühle dein Glück, nicht jeder hat so viel Glück!
Es gibt sogar eine solche Site
PapersWithCode.com , die im Bereich des maschinellen Lernens gezielt Artikel sammelt, die Bewertung ihrer Repositorys von GitHub automatisch analysiert, alles nach Kategorien auflistet und Benchmarks und Datensätze hinzufügt. Im Allgemeinen - alles ist für Menschen! Übrigens ist der Code ihren Berechnungen zufolge nur noch für 17-19% der Artikel verfügbar:
 Quelle: Prozentsatz der veröffentlichten Artikel mit mindestens einer Code-Implementierung
Quelle: Prozentsatz der veröffentlichten Artikel mit mindestens einer Code-ImplementierungAber wenn wir uns für eine Sekunde ablenken lassen (und trotzdem für die richtigen Leute werben), gibt es einen sehr interessanten Zeitplan, um die Popularität von ML / DL-Frameworks in den letzten 4 Jahren zu ändern:
 Quelle: Papierimplementierungen gruppiert nach Framework
Quelle: Papierimplementierungen gruppiert nach FrameworkFackel auf dem Pferd, TF (wer hätte das gedacht!) Verliert an Boden. Dies ist jedoch eine andere Geschichte ...
Aus Erfahrung ist klar, dass diese 17-20% der Artikel mit Code auch (aus den beschriebenen Gründen) nicht alles magisch sind, aber man kann zumindest ihre Arbeit um eine Größenordnung schneller überprüfen. Und das ist großartig.
Ein weiteres wirklich funktionierendes Rezept ist die Erstellung relativ großer Datensätze und Benchmarks. Der Aufstieg neuronaler Netze begann vergebens mit
ImageNet mit 14 Millionen Bildern, die in über 20.000 Klassen unterteilt waren. Ja, es ist schwierig, aber mit Deep Learning können Sie nur mit
sehr großen Sets arbeiten. Auch wenn ihre Erschaffung schmerzhaft und schwierig ist.
Zum Beispiel haben wir vor einiger Zeit einen
Maßstab für die Hervorhebung von durchscheinenden Objekten in einem Video erstellt (Wolle, Haare, Stoffe, Rauch und andere nicht triviale Lebensfreuden). Ursprünglich war geplant, innerhalb von 3 Monaten zu bleiben, wenn es erstellt wurde. Es wurden Servoantriebe gefunden, ein Bildschirm, eine gute Kamera
, ein blaues elektrisches Klebeband gekauft , von allen Mädchen, die sie kannten, eine Million Plüschtiere beschlagnahmt, eine Schaufensterpuppe mit Echthaar gefunden, auf der Friseure das Haarstyling trainieren. Und ...
 Quelle: Materialien des Autors ... Wie deutlich zu sehen ist, spielt das blaue Isolierband eine wichtige Rolle
Quelle: Materialien des Autors ... Wie deutlich zu sehen ist, spielt das blaue Isolierband eine wichtige RolleAlles (nein, nicht so ... ALLES!) Ist falsch gelaufen. , ( ), ( ), ( , ). Usw. usw.
( ), , . , ! , - , , .
— . , . , , , (. ,
25 Kaggle).
Gesamt:
, , , … . , , ,
.
, , .
Replication crisis ( , , ) , — , :
 : The Reproducibility Crisis in Psychological Science: One Year Later , , , , , … , Computer Science ...
: The Reproducibility Crisis in Psychological Science: One Year Later , , , , , … , Computer Science ...! 20 ,
Computer Science , (
), - . — , .

Und der letzte. , . , . !
!Lesen Sie auch:
Danksagung
The replication crisis Science for Sale: The Other Problem With Corporate Money .
, :
- Labor für Computergrafik und Multimedia VMK Moscow State University .. ,
- , , , , ,
- persönlich Konstantin Kozhemyakov und Dmitry Konovalchuk, die viel getan haben, um diesen Artikel besser und visueller zu machen,
- , , , , , , , , , , !