 Was denn
Was denn Ein Video-Codec ist eine Software / Hardware, die digitales Video komprimiert und / oder dekomprimiert.
Wofür? Trotz einiger Einschränkungen in Bezug auf die Bandbreite,
Und was den Speicherplatz angeht, verlangt der Markt immer mehr qualitativ hochwertige Videos. Erinnern Sie sich, wie wir im letzten Beitrag das erforderliche Minimum für 30 Bilder pro Sekunde, 24 Bit pro Pixel, mit einer Auflösung von 480 x 240 berechnet haben? Empfing 82.944 Mbit / s ohne Komprimierung. Die Komprimierung ist die einzige Möglichkeit, HD / FullHD / 4K auf Fernsehbildschirme und das Internet zu übertragen. Wie wird das erreicht? Jetzt werden wir kurz die Hauptmethoden betrachten.

Die Übersetzung wurde mit Unterstützung von EDISON Software erstellt.
Wir beschäftigen uns mit der Integration von Videoüberwachungssystemen und der Entwicklung eines Mikrotomographen .
Codec gegen Container
Ein häufiger Anfängerfehler besteht darin, einen digitalen Videocodec und einen digitalen Videocontainer zu verwechseln. Ein Container hat ein bestimmtes Format. Ein Wrapper mit Video-Metadaten (und möglicherweise Audio). Komprimiertes Video kann als Container-Nutzlast betrachtet werden.
In der Regel gibt eine Videodateierweiterung einen Containertyp an. Beispielsweise ist die Datei video.mp4 höchstwahrscheinlich ein
MPEG-4 Part 14- Container, und die Datei video.mkv ist höchstwahrscheinlich eine russische
Puppe . Sie können
FFmpeg oder
MediaInfo verwenden, um sich im
Codec- und Container-Format voll und ganz sicher zu
fühlen .
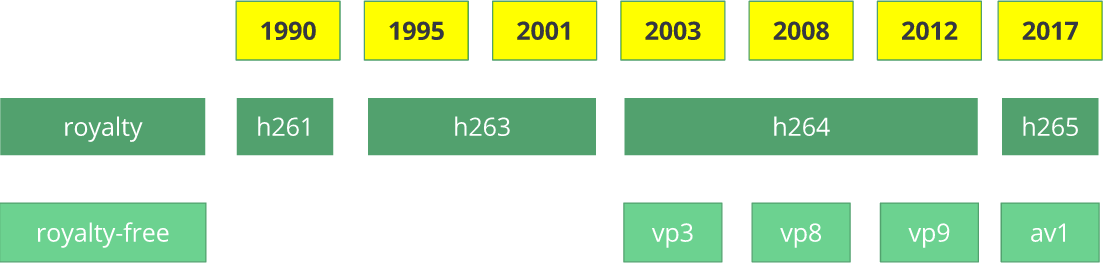
Ein bisschen Geschichte
Bevor wir zu
Wie kommen? Tauchen wir ein bisschen in die Geschichte ein, um ein bisschen mehr über einige alte Codecs zu erfahren.
Der
H.261 -Videocodec erschien 1990 (technisch gesehen 1988) und wurde für eine Datenübertragungsrate von 64 Kbit / s entwickelt. Es wurden bereits Ideen wie Farbunterabtastung, Makroblöcke usw. verwendet. 1995 wurde der Video-Codec-Standard
H.263 veröffentlicht, der sich bis 2001 entwickelte.
Im Jahr 2003 wurde die erste Version von
H.264 / AVC fertiggestellt. Im selben Jahr veröffentlichte TrueMotion seinen kostenlosen Video-Codec, der verlustbehaftetes Video mit dem Namen
VP3 komprimiert. 2008 kaufte Google diese Firma und brachte im selben Jahr
VP8 heraus . Im Dezember 2012 veröffentlichte Google
VP9 und es wird in etwa ¾ des Browsermarktes (einschließlich mobiler Geräte) unterstützt.
AV1 ist ein neuer kostenloser Open-Source-Videocodec, der
von der Open Media Alliance (
AOMedia ) entwickelt wurde und zu dem bekannte Unternehmen wie Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel und Cisco gehören . Die erste Version des Codec 0.1.0 wurde am 7. April 2016 veröffentlicht.
Geburt von AV1
Anfang 2015 arbeitete Google an
VP10 , Xiph (das zu Mozilla gehört) arbeitete an
Daala und Cisco erstellte seinen kostenlosen Video-Codec namens
Thor .
Dann kündigte
MPEG LA zunächst jährliche Grenzwerte für
HEVC (
H.265 ) und eine 8-fach höhere Gebühr als für H.264 an, änderte jedoch bald die Regeln erneut:
kein Jahreslimit,
Inhaltsgebühr (0,5% des Umsatzes) und
Die Stückkosten sind etwa zehnmal höher als bei H.264.
Die Open Media Alliance wurde von Unternehmen aus verschiedenen Bereichen gegründet: Geräteherstellern (Intel, AMD, ARM, Nvidia, Cisco), Inhaltsanbietern (Google, Netflix, Amazon), Browsern (Google, Mozilla) und anderen.
Die Unternehmen hatten ein gemeinsames Ziel - einen Videocodec ohne Lizenzgebühren. Dann kommt
AV1 mit einer wesentlich einfacheren Patentlizenz. Timothy B. Terriberry hielt eine beeindruckende Präsentation ab, aus der das aktuelle Konzept von AV1 und seines Lizenzmodells hervorging.
Sie werden überrascht sein zu erfahren, dass Sie den AV1-Codec über einen Browser analysieren können (Interessenten können zu
aomanalyzer.org gehen).

Universeller Codec
Analysieren wir die grundlegenden Mechanismen, die dem universellen Videocodec zugrunde liegen. Die meisten dieser Konzepte sind nützlich und werden in modernen Codecs wie
VP9 ,
AV1 und
HEVC verwendet . Ich warne Sie, dass vieles, was erklärt wird, vereinfacht wird. Gelegentlich werden reale Beispiele verwendet (wie dies bei H.264 der Fall ist), um Technologie zu demonstrieren.
1. Schritt - Aufteilen des Bildes
Der erste Schritt besteht darin, den Frame in mehrere Abschnitte, Unterabschnitte und mehr zu unterteilen.

Wofür? Gründe gibt es viele. Wenn wir das Bild teilen, können wir den Bewegungsvektor mit kleinen Abschnitten für kleine bewegliche Teile genauer vorhersagen. Bei einem statischen Hintergrund können Sie sich auf größere Abschnitte beschränken.
In der Regel organisieren Codecs diese Abschnitte in Abschnitte (oder Fragmente), Makroblöcke (oder Blöcke eines Codierungsbaums) und viele Unterabschnitte. Die maximale Größe dieser Partitionen variiert, HEVC legt 64 x 64 fest, während AVC 16 x 16 verwendet und Unterabschnitte bis zu 4x4 aufgeteilt werden können.
Erinnern Sie sich an die Rahmenvarianten aus dem letzten Artikel ?! Dasselbe kann auf Blöcke angewendet werden, also können wir ein I-Fragment, einen B-Block, einen P-Makroblock usw. haben.
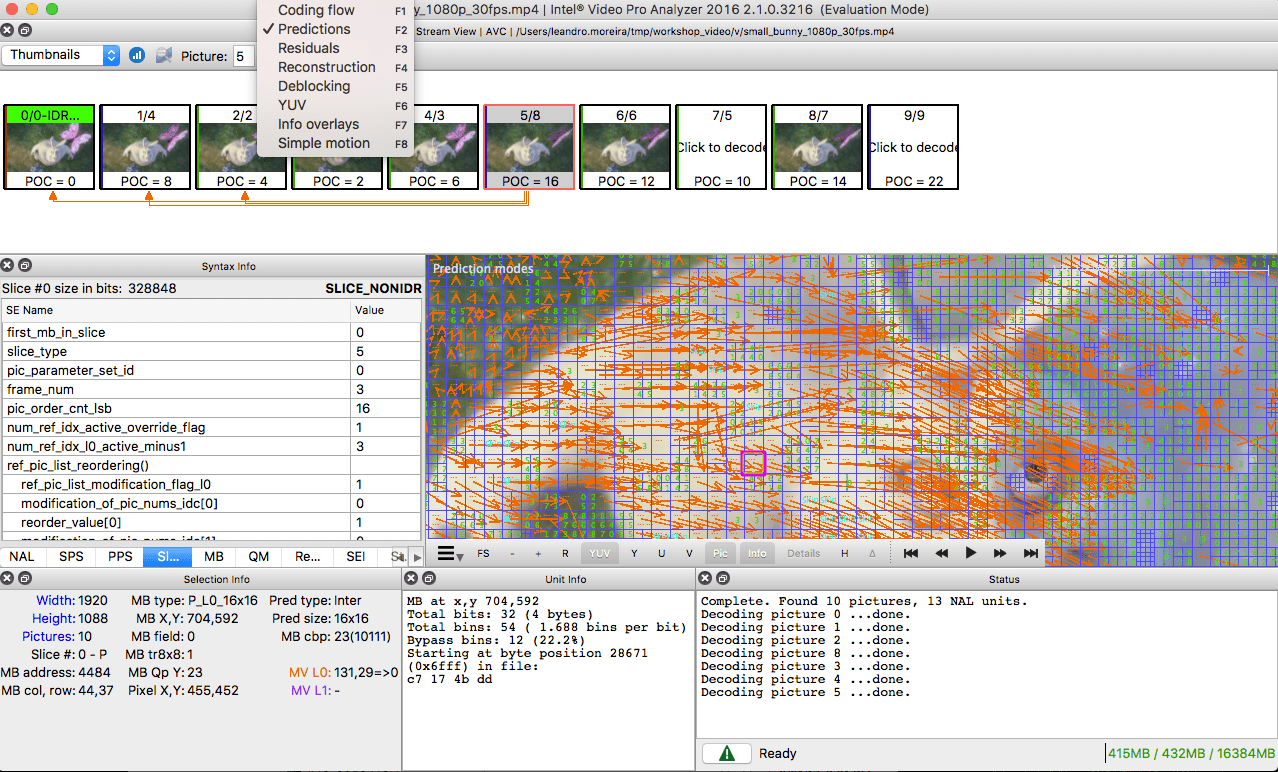
Sehen Sie für diejenigen, die üben möchten, wie das Bild in Abschnitte und Unterabschnitte unterteilt wird. Zu diesem Zweck können Sie den
Intel Video Pro Analyzer verwenden, der bereits in einem früheren Artikel erwähnt wurde (der kostenpflichtig ist, aber eine kostenlose Testversion enthält, die auf die ersten 10 Bilder beschränkt ist). Die Abschnitte von
VP9 werden hier analysiert:

2. Schritt - Prognose
Sobald wir Abschnitte haben, können wir
astrologische Vorhersagen darüber machen. Für die
INTER-Vorhersage ist es notwendig,
Bewegungsvektoren und den Rest zu übertragen, und für die INTRA-Vorhersage werden die
Richtung der Vorhersage und der Rest übertragen.
3. Schritt - Konvertierung
Nachdem wir den Restblock erhalten haben (den vorhergesagten Abschnitt → den realen Abschnitt), ist es möglich, ihn so zu transformieren, dass wir wissen, welche Pixel verworfen werden können, während die Gesamtqualität erhalten bleibt. Es gibt einige Transformationen, die genaues Verhalten liefern.
Obwohl es andere Methoden gibt, wollen wir die
diskrete Cosinustransformation (
DCT - from
discrete cosine transform ) genauer betrachten. Hauptmerkmale von DCT:
- Konvertiert Pixelblöcke in gleich große Frequenzkoeffizientenblöcke.
- Versiegelt die Stromversorgung und hilft, räumliche Redundanzen zu beseitigen.
- Bietet Reversibilität.
2. Februar 2017 Sintra R.J. (Cintra, RJ) und Bayer F.M. (Bayer FM) veröffentlichte einen Artikel zur DCT-ähnlichen Konvertierung für die Bildkomprimierung, der nur 14 Zusätze erfordert.
Machen Sie sich keine Sorgen, wenn Sie die Vorteile der einzelnen Artikel nicht verstehen. Anhand konkreter Beispiele werden wir nun ihren wahren Wert überprüfen.
Nehmen wir einen 8x8 Pixel Block wie folgt:
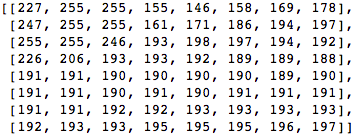
Dieser Block wird 8 mal 8 Pixel in das folgende Bild gerendert:
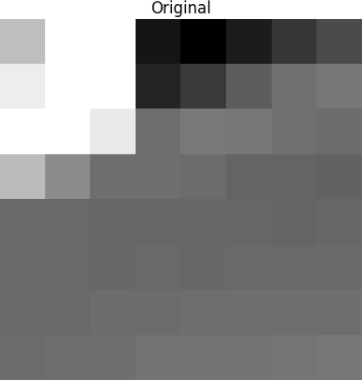
Wenden Sie DCT auf diesen Pixelblock an und erhalten Sie einen Koeffizientenblock der Größe 8x8:
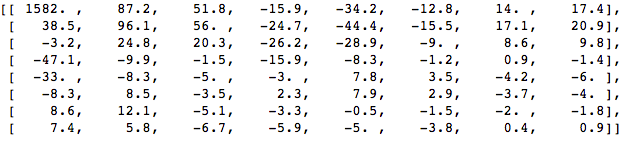
Und wenn wir diesen Koeffizientenblock rendern, erhalten wir das folgende Bild:
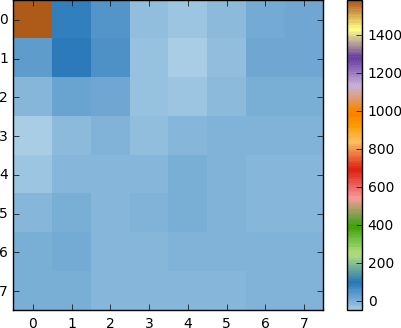
Wie Sie sehen können, entspricht dies nicht dem Originalbild. Möglicherweise stellen Sie fest, dass sich der erste Koeffizient von allen anderen stark unterscheidet. Dieser erste Koeffizient ist als DC-Koeffizient bekannt, der alle Abtastwerte in der Eingabematrix darstellt, ähnlich wie der Durchschnittswert.
Dieser Koeffizientenblock hat eine interessante Eigenschaft: Er trennt hochfrequente von niederfrequenten Komponenten.
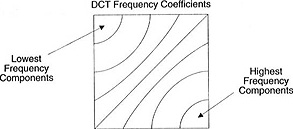
Im Bild ist der größte Teil der Leistung auf niedrigere Frequenzen konzentriert. Wenn Sie daher das Bild in seine Frequenzkomponenten umwandeln und die höheren Frequenzkoeffizienten verwerfen, können Sie die zur Beschreibung des Bildes erforderliche Datenmenge reduzieren, ohne die Bildqualität zu stark zu beeinträchtigen.
Frequenz bedeutet, wie schnell sich das Signal ändert.
Versuchen wir, die im Testbeispiel gewonnenen Erkenntnisse anzuwenden, indem wir das Originalbild mit DCT in seine Frequenz (Koeffizientenblock) umwandeln und dann einige der unwichtigsten Koeffizienten verwerfen.
Konvertieren Sie es zunächst in den Frequenzbereich.
Als nächstes verwerfen wir einen Teil (67%) der Koeffizienten, hauptsächlich die untere rechte Seite.
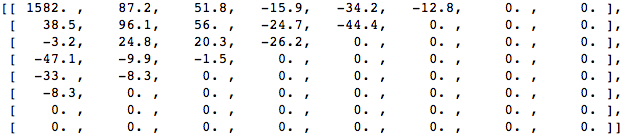
Schließlich stellen wir das Bild aus diesem verworfenen Koeffizientenblock wieder her (denken Sie daran, es muss umkehrbar sein) und vergleichen es mit dem Original.
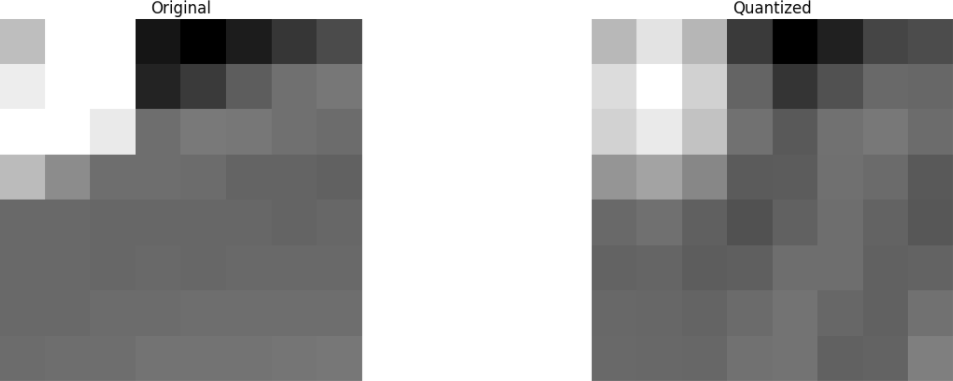
Wir sehen, dass es dem Originalbild ähnelt, aber es gibt viele Unterschiede zum Original. Wir haben 67,1875% und haben immer noch etwas, das der ursprünglichen Quelle ähnelt. Sie können die Koeffizienten bewusster verwerfen, um ein noch besseres Bild zu erhalten. Dies ist jedoch das nächste Thema.
Jeder Koeffizient wird mit allen Pixeln erzeugt.
Wichtig: Jeder Koeffizient wird nicht direkt auf einem Pixel angezeigt, sondern ist eine gewichtete Summe aller Pixel. Diese erstaunliche Grafik zeigt, wie der erste und der zweite Koeffizient unter Verwendung von Gewichten berechnet werden, die für jeden Index eindeutig sind.
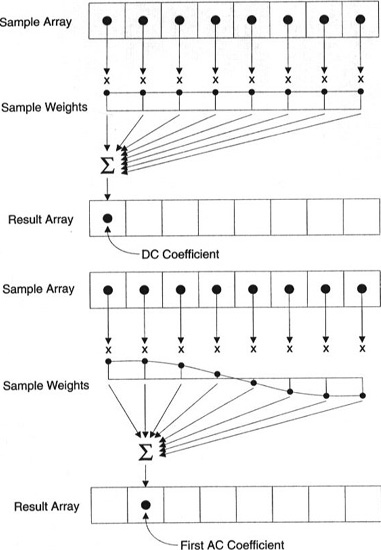
Sie können auch versuchen, DCT zu visualisieren, indem Sie eine einfache darauf basierende Bildgebung betrachten. Zum Beispiel ist hier das Symbol A, das mit jedem Koeffizientengewicht erzeugt wird:

4. Schritt - Quantisierung
Nachdem wir im vorherigen Schritt einige Koeffizienten weggeworfen haben, erstellen wir im letzten Schritt (Transformation) eine spezielle Quantisierungsform. Zu diesem Zeitpunkt ist es zulässig, Informationen zu verlieren. Oder einfacher gesagt, wir werden die Koeffizienten quantisieren, um eine Komprimierung zu erreichen.
Wie kann ein Koeffizientenblock quantisiert werden? Eine der einfachsten Methoden wird die einheitliche Quantisierung sein, wenn wir einen Block nehmen, durch einen Wert (durch 10) teilen und abrunden, was passiert ist.
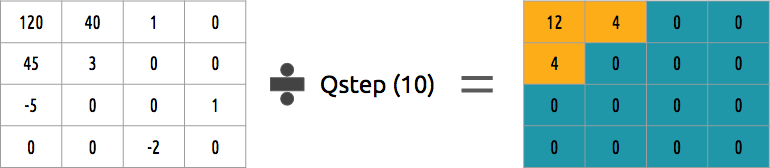
Können wir diesen Koeffizientenblock umkehren? Ja, wir können, indem wir mit demselben Wert multiplizieren, durch den wir dividiert haben.
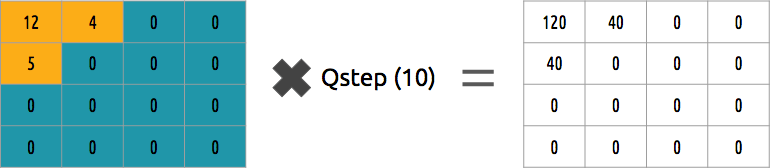
Dieser Ansatz ist nicht der beste, da er nicht die Bedeutung jedes Koeffizienten berücksichtigt. Man könnte die Quantisierermatrix anstelle eines einzelnen Werts verwenden, und diese Matrix könnte die DCT-Eigenschaft verwenden, um die Mehrheit der unteren rechten und die Minderheit der oberen linken zu quantisieren.
5-Stufen-Entropie-Codierung
Nachdem wir die Daten (Bildblöcke, Fragmente, Rahmen) quantisiert haben, können wir sie immer noch ohne Verlust komprimieren. Es gibt viele algorithmische Möglichkeiten, Daten zu komprimieren. Wir werden einige von ihnen kurz kennenlernen. Zum besseren Verständnis lesen Sie das Buch „
Komprimierung verstehen: Datenkomprimierung für moderne Entwickler “ („
Komprimierung verstehen: Datenkomprimierung für moderne Entwickler “).
Videokodierung mit VLC
Angenommen, wir haben einen Zeichenstrom:
a ,
e ,
r und
t . Die Wahrscheinlichkeit (im Bereich von 0 bis 1), wie oft jedes Symbol im Stream vorkommt, ist in dieser Tabelle dargestellt.
Wir können eindeutige Binärcodes (vorzugsweise kleine) den wahrscheinlichsten und größere Codes den unwahrscheinlichsten zuordnen.
Wir komprimieren den Stream unter der Annahme, dass wir am Ende 8 Bits für jedes Zeichen ausgeben. Ohne Komprimierung eines Zeichens wären 24 Bits erforderlich. Wenn jedes Zeichen durch seinen Code ersetzt wird, erhalten wir Einsparungen!
Der erste Schritt ist das Codieren des Zeichens
e , das 10 ist, und des zweiten Zeichens
a , das (nicht mathematisch) hinzugefügt wird: [10] [0] und schließlich des dritten Zeichens
t , das unseren endgültigen komprimierten Bitstrom gleich macht [10] [0] [1110] oder
1001110 , für die nur 7 Bits erforderlich sind (3,4-mal weniger Speicherplatz als im Original).
Bitte beachten Sie, dass jeder Code ein eindeutiger Code mit einem Präfix sein muss.
Der Huffman-Algorithmus hilft beim Auffinden dieser Zahlen. Obwohl diese Methode nicht fehlerfrei ist, gibt es Videocodecs, die diese algorithmische Methode zur Komprimierung anbieten.
Sowohl der Codierer als auch der Decodierer müssen Zugriff auf die Symboltabelle mit ihren Binärcodes haben. Daher ist es auch notwendig, eine Tabelle in der Eingabe zu senden.
Arithmetische Codierung
Angenommen, wir haben einen Strom von Zeichen:
a ,
e ,
r ,
s und
t , und ihre Wahrscheinlichkeit wird durch diese Tabelle dargestellt.
Mit dieser Tabelle erstellen wir Bereiche, die alle möglichen Zeichen enthalten, sortiert nach der größten Zahl.

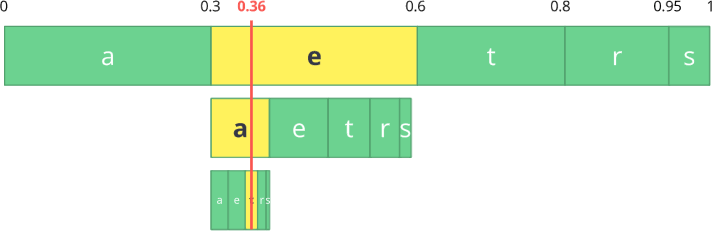
Codieren wir nun einen Stream mit drei Zeichen:
eat .
Wählen Sie zunächst das erste Zeichen
e aus , das sich im Unterbereich von 0,3 bis 0,6 (ohne) befindet. Wir nehmen diesen Unterbereich und teilen ihn wieder in die gleichen Proportionen wie zuvor, jedoch bereits für diesen neuen Bereich.

Lassen Sie uns unseren
Eat- Stream weiter codieren. Nun nehmen wir das zweite Zeichen
a , das sich in dem neuen Unterbereich von 0,3 bis 0,39 befindet, und dann nehmen wir unser letztes Zeichen
t und wiederholen denselben Vorgang erneut, um das letzte Unterband von 0,354 bis 0,372 zu erhalten.
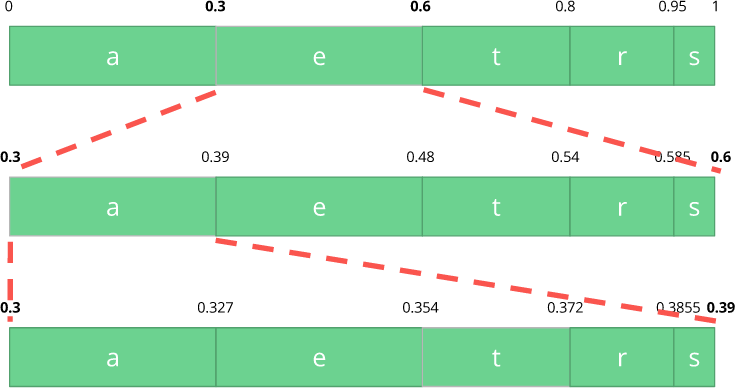
Wir müssen nur eine Zahl im letzten Unterbereich von 0,354 bis 0,372 auswählen. Lassen Sie uns 0,36 wählen (aber Sie können jede andere Zahl in diesem Unterbereich wählen). Nur mit dieser Nummer können wir unseren ursprünglichen Fluss wiederherstellen. Es ist, als würden wir eine Linie innerhalb von Bereichen zeichnen, um unseren Stream zu kodieren.
Der umgekehrte Vorgang (also das
Dekodieren ) ist genauso einfach: Mit unserer Zahl 0.36 und unserem Anfangsbereich können wir den gleichen Vorgang starten. Aber jetzt zeigen wir unter Verwendung dieser Nummer den Stream, der unter Verwendung dieser Nummer codiert wurde.
Beim ersten Bereich stellen wir fest, dass unsere Nummer einem Slice entspricht, daher ist dies unser erstes Zeichen. Jetzt teilen wir uns wieder dieses Teilband und führen den gleichen Vorgang wie zuvor durch. Hier sehen Sie, dass 0,36 dem Zeichen
a entspricht , und nach Wiederholung des Vorgangs gelangen wir zum letzten Zeichen
t (das unseren ursprünglich codierten Stream
eat bildet ).
Sowohl der Codierer als auch der Decodierer müssen eine Tabelle mit Symbolwahrscheinlichkeiten haben, daher ist es erforderlich, diese in den Eingabedaten zu senden.
Ziemlich elegant, nicht wahr? Jemand, der sich diese Lösung ausgedacht hat, war verdammt schlau. Einige Video-Codecs verwenden diese Technik (oder bieten sie auf jeden Fall als Option an).
Die Idee ist, einen verlustfreien quantisierten Bitstrom zu komprimieren. Sicherlich gibt es in diesem Artikel nicht jede Menge Details, Gründe, Kompromisse usw. Wenn Sie jedoch Entwickler sind, sollten Sie mehr wissen. Neue Codecs versuchen, andere Entropiecodierungsalgorithmen wie
ANS zu verwenden .
6-stufiges Bitstream-Format
Nach alledem müssen die komprimierten Frames im Rahmen der durchgeführten Schritte entpackt werden. Der Decoder muss ausdrücklich über die vom Encoder getroffenen Entscheidungen informiert werden. Dem Decoder sollten alle erforderlichen Informationen zur Verfügung gestellt werden: Bittiefe, Farbraum, Auflösung, Vorhersageinformationen (Bewegungsvektoren, Richtungs-INTER-Vorhersage), Profil, Pegel, Bildrate, Bildtyp, Bildnummer und vieles mehr.
Wir werden uns den
H.264- Bitstream ansehen. Unser erster Schritt besteht darin, einen minimalen H.264-Bitstream zu erstellen (FFmpeg fügt standardmäßig alle Codierungsparameter wie
SEI NAL hinzu - etwas weiter werden wir herausfinden, was es ist). Wir können dies mit unserem eigenen Repository und FFmpeg tun.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264Dieser Befehl generiert einen unformatierten
H.264- Bitstream mit einem Frame und einer Auflösung von 64 x 64 mit dem Farbraum
YUV420 . Das folgende Bild wird als Rahmen verwendet.

H.264-Bitstream
Der
AVC-Standard (
H.264 ) definiert, dass Informationen in Makrorahmen (im Verständnis des Netzwerks) gesendet werden, die als
NAL bezeichnet werden (dies ist eine solche Ebene der Netzwerkabstraktion). Das Hauptziel von NAL ist die Bereitstellung einer "netzwerkfreundlichen" Videopräsentation. Dieser Standard sollte auf Fernsehgeräten (basierend auf Streams) und im Internet (basierend auf Paketen) funktionieren.

Es gibt eine Synchronisationsmarke zum Definieren der Grenzen von NAL-Elementen. Jeder Synchronisationsmarker enthält den Wert
0x00 0x00 0x01 mit Ausnahme des allerersten, nämlich
0x00 0x00 0x00 0x01. Wenn wir
Hexdump für den generierten H.264-Bitstream ausführen, identifizieren wir mindestens drei NAL-Muster am Anfang der Datei.
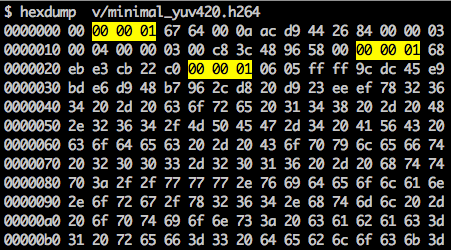
Wie bereits erwähnt, muss der Decoder nicht nur die Bilddaten kennen, sondern auch die Details des Videos, des Rahmens, der Farbe, der verwendeten Parameter und vieles mehr. Das erste Byte jeder NAL definiert ihre Kategorie und ihren Typ.
Normalerweise ist der erste NAL-Bitstrom
SPS . Diese Art von NAL ist für das Melden allgemeiner Codierungsvariablen wie Profil, Ebene, Auflösung und mehr verantwortlich.
Wenn wir das erste Synchronisationstoken überspringen, können wir das erste Byte dekodieren, um herauszufinden, welcher NAL-Typ der erste ist.
Das erste Byte nach der Synchronisationsmarke ist beispielsweise
01100111 , wobei sich das erste Bit (
0 ) im Feld f
orbidden_zero_bit befindet. Die nächsten 2 Bits (
11 )
teilen uns das Feld
nal_ref_idc mit, das angibt, ob dieses NAL ein Referenzfeld ist oder nicht. Die verbleibenden 5 Bits (
00111 )
teilen uns das Feld
nal_unit_type mit. In diesem Fall handelt es sich um einen SPS (
7 ) -NAL-Block.
Das zweite Byte (
binär =
01100100 ,
hex =
0x64 ,
dez =
100 ) in der SPS-NAL ist das Feld
profile_idc, das das vom Encoder verwendete Profil anzeigt. In diesem Fall wurde ein begrenztes hohes Profil verwendet (d. H. Ein hohes Profil ohne Unterstützung für ein bidirektionales B-Segment).

Wenn wir uns mit der Spezifikation des
H.264- Bitstroms für SPS NAL vertraut machen, finden wir viele Werte für den Parameternamen, die Kategorie und die Beschreibung. Schauen
wir uns beispielsweise die Felder pic_width_in_mbs_minus_1 und
pic_height_in_map_units_minus_1 an .
Wenn wir mit den Werten dieser Felder einige mathematische Operationen durchführen, erhalten wir die Erlaubnis. Sie können sich
1920 x 1080 vorstellen,
wenn Sie
pic_width_in_mbs_minus_1 mit einem Wert von
119 ((119 + 1) * macroblock_size = 120 * 16 = 1920) verwenden . Auch hier wurde Platz gespart, anstatt 1920 mit 119 zu programmieren.
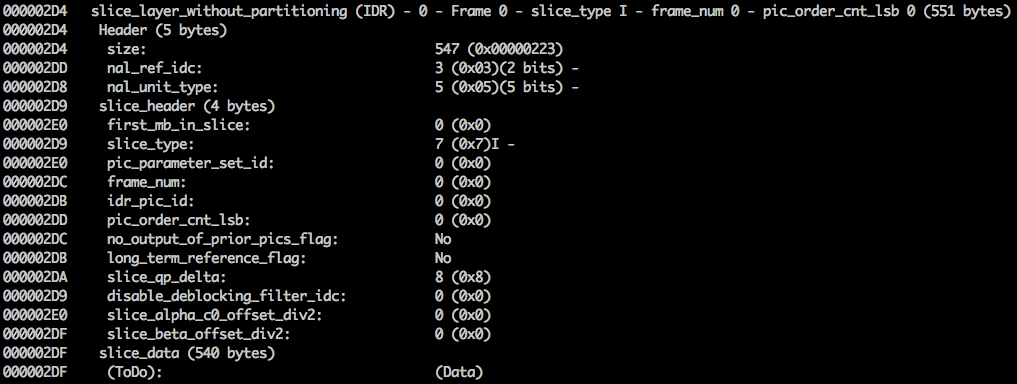
Wenn Sie unser erstelltes Video weiterhin in binärer Form überprüfen (zum Beispiel:
xxd -b -c 11 v / minimal_yuv420.h264 ), können Sie zur letzten NAL gehen, die das Frame selbst ist.

Hier sehen wir die ersten 6-Byte-Werte:
01100101 10001000 10000100 00000000 00100001 11111111 . Da bekannt ist, dass das erste Byte den Typ der NAL angibt, handelt es sich in diesem Fall (
00101 ) um ein IDR-Fragment (5), das dann weiter untersucht werden kann:

Unter Verwendung der Spezifikationsinformationen ist es möglich, den Fragmenttyp (
slice_type ) und die
Bildnummer (
frame_num ) unter anderen wichtigen Feldern zu decodieren.
Um die Werte einiger Felder (
ue (
v ),
me (
v ),
se (
v ) oder
te (
v )) zu erhalten, müssen wir das Fragment mit einem speziellen Decoder decodieren, der auf
dem Golomb-Exponentialcode basiert. Diese Methode ist sehr effektiv für die Codierung variabler Werte, insbesondere wenn viele Standardwerte vorhanden sind.
Die Werte für
slice_type und
frame_num in diesem Video sind 7 (I-Fragment) und 0 (erstes Bild).
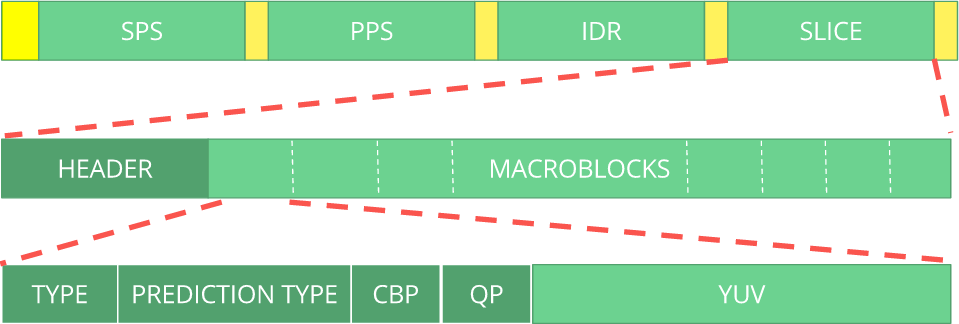
Bitstream kann als Protokoll betrachtet werden. Wenn Sie mehr über den Bitstream erfahren möchten, lesen Sie die
ITU H.264- Spezifikation. Hier ist ein Makro, das zeigt, wo sich die Bilddaten befinden (
YUV in komprimierter Form).
Sie können andere Bitstreams wie
VP9 ,
H.265 (
HEVC ) oder sogar unseren neuen besten
AV1- Bitstream erkunden. Sind sie alle gleich? Nein, aber es ist viel einfacher, den Rest zu verstehen, wenn man sich mit mindestens einem befasst hat.
Willst du üben? Entdecken Sie den H.264-Bitstream
Sie können Einzelbildvideos generieren und mithilfe von MediaInfo den H.264- Bitstream untersuchen. Tatsächlich hindert Sie nichts daran, sich den Quellcode anzusehen, der den H.264 ( AVC ) -Bitstream analysiert.
Zum Üben können Sie Intel Video Pro Analyzer verwenden (ich habe bereits gesagt, dass das Programm kostenpflichtig ist, aber gibt es eine kostenlose Testversion mit einem Limit von 10 Bildern?).
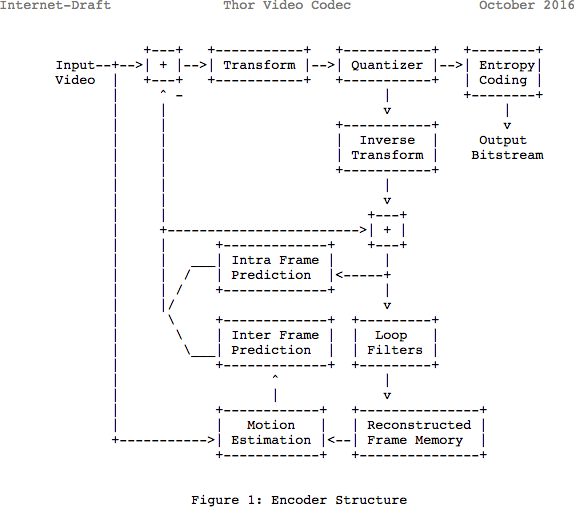
Rückblick
Beachten Sie, dass viele moderne Codecs dasselbe Modell verwenden, das sie gerade gelernt haben. Schauen wir uns hier das Blockdiagramm des
Thor- Video-Codecs an. Es enthält alle Schritte, die wir unternommen haben. In diesem Beitrag geht es darum, die Neuerungen und Dokumentationen in diesem Bereich zumindest besser zu verstehen.
Bisher wurde geschätzt, dass 139 GB Festplattenspeicher erforderlich sind, um eine einstündige Videodatei mit 720p und 30 fps Qualität zu speichern. Wenn Sie die in diesem Artikel beschriebenen Methoden verwenden (Inter-Frame- und interne Vorhersagen, Konvertierung, Quantisierung, Entropie-Codierung usw.), können Sie erreichen (vorausgesetzt, wir geben 0,031 Bit pro Pixel aus), dass das Video eine recht zufriedenstellende Qualität aufweist, die es in Anspruch nimmt Nur 367,82 MB, nicht 139 GB Arbeitsspeicher.
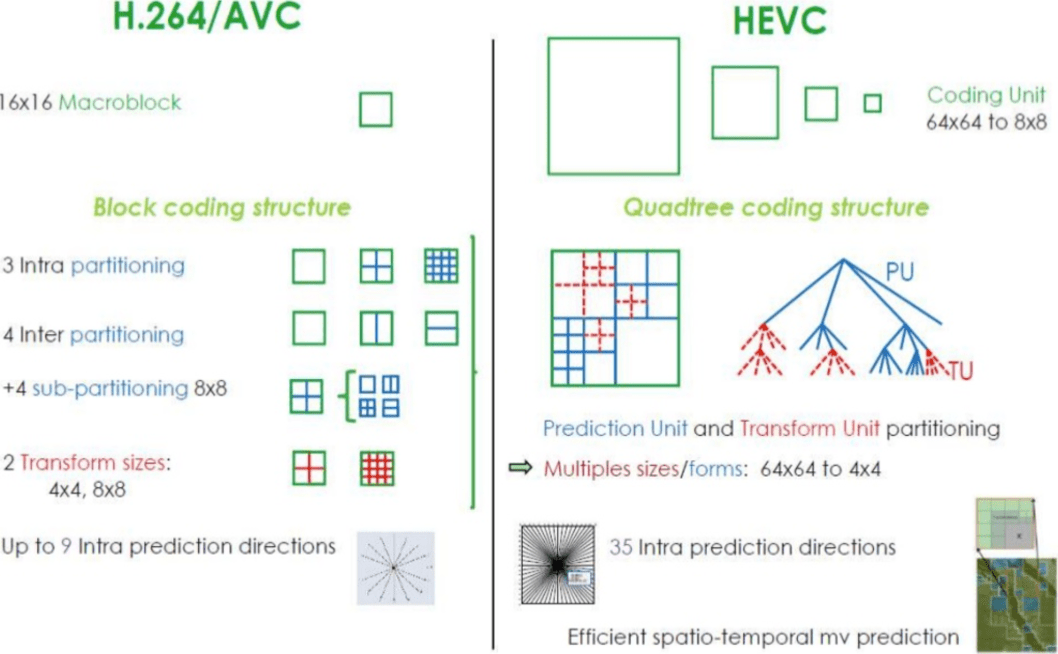
Wie erreicht H.265 ein besseres Kompressionsverhältnis als H.264?
Da Sie nun mehr über die Funktionsweise von Codecs wissen, ist es einfacher zu verstehen, wie neue Codecs mit weniger Bits eine höhere Auflösung bieten können.
Wenn Sie
AVC und
HEVC vergleichen , sollten Sie nicht vergessen, dass dies fast immer eine Wahl zwischen einer höheren CPU-Last und einem höheren Komprimierungsverhältnis ist.
HEVC bietet mehr Optionen für Abschnitte (und Unterabschnitte) als
AVC , mehr Anweisungen für interne Vorhersagen, verbesserte Entropiecodierung und vieles mehr. All diese Verbesserungen machten
H.265 in der Lage, 50% mehr als
H.264 zu komprimieren.

Lesen Sie auch den Blog
EDISON Unternehmen:
20 Bibliotheken für
spektakuläre iOS-Anwendung