Letztes Schuljahr, April. Die Studenten beginnen immer öfter, sich mit dem Gedanken zu befassen, dass es notwendig wäre, eine Abschlussarbeit zu machen. Dies zu tun, bedeutet in gewissem Sinne, herauszufinden, wie schnell etwas zubereitet werden kann, das zumindest mit dem Thema übereinstimmt, das anscheinend vom Vorgesetzten gebilligt wurde. Und ja, Sie benötigen mindestens 80 Seiten, Sie müssen auch alle Arten von GOSTs einhalten ... Es ist klar, dass Sie keine Zeit haben, so viel zusammenhängenden Text selbst zu schreiben (und sie können sogar in die Essenz der Arbeit einfließen, na ja!). Offensichtlich müssen Sie die bereits verteidigten, geprüften und genehmigten Arbeiten von hoher Qualität übernehmen. Die Situation ist uns allen bekannt. Die einzige Frage, die offen bleibt, ist, wie sichergestellt werden kann, dass die Arbeit auf Ausleihe getestet wird ... Internetrecherchen und Kommunikation mit unglücklichen Kollegen führen den Schüler zu den folgenden Optionen zur Lösung des Problems:
Schreiben Sie die Arbeit selbst;- Umformulieren des Textes (teuer und schwierig);
- Überlisten Sie das System mit "technischen Problemumgehungen".

Mal sehen, was technische Runden sind, wie wir sie fangen und warum ihre Verwendung keine gute Idee ist ...
Durch eine Neuformulierung können Sie den Text einer anderen Person als Ihren eigenen Text weitergeben, wenn dies gut gemacht wird. Hochwertige Umformulierungen an sich sind jedoch ein sehr mühsamer Prozess, für den der Student höchstwahrscheinlich nicht die Zeit und das Geld hat. Einfache Umformulierungen (z. B. Synonymisierung) führen zu einem Ergebnis, das nicht nur vom Anti-Plagiat-System erkannt wird, sondern höchstwahrscheinlich auch den Vorgesetzten und das Zertifizierungskomitee amüsiert.
Auf diese Weise kommen wir zu dem kreativsten und beliebtesten Tool unter Studenten - technischen Problemumgehungen - Dokumenttransformationen, die, ohne die Anzeige des Originaldokuments zu ändern, den vom Überprüfungssystem extrahierten Text ändern.
Unter dem Gesichtspunkt der Arbeit mit technischen Runden (im Folgenden werden wir sie einfach "Runden" nennen) hat das Antiplagiatsystem zwei Aufgaben:
- Erkennen möglicher Bypässe und Benachrichtigung des Benutzers darüber;
- Überprüften Text aus Crawls entfernen.
Das allgemeine Schema der Verarbeitungsrunden kann wie folgt beschrieben werden:
- Erkennung von Bypässen, Speicherung von Informationen über diese;
- Löschen des extrahierten Texts von Crawls;
- Die Definition von "Verdächtigkeit" des Dokuments auf der Grundlage der Umwege;
- Anzeige von Informationen über den Verdacht gegenüber dem Benutzer, Anzeige der gefundenen Umwege.
So sieht es in der Praxis aus.
Dokument im docx-Format:
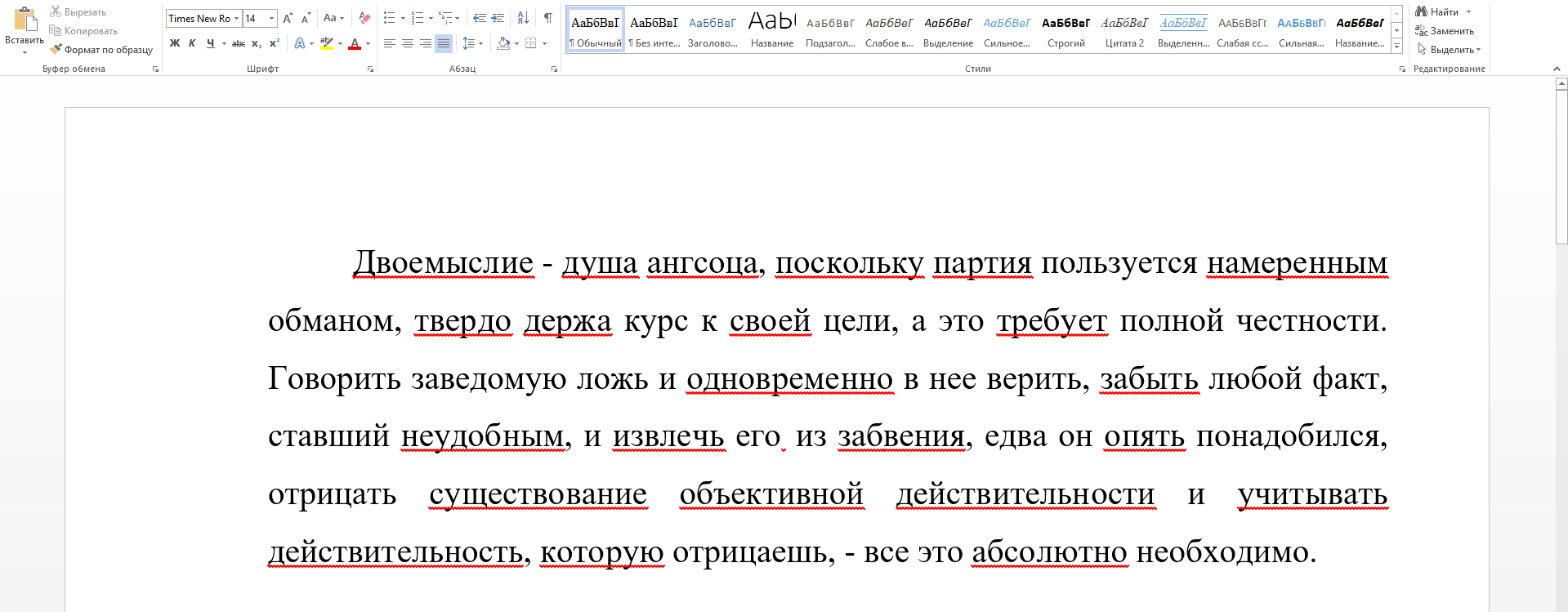
Überprüfen eines Dokuments ohne Funktion zur Durchforstungserkennung:
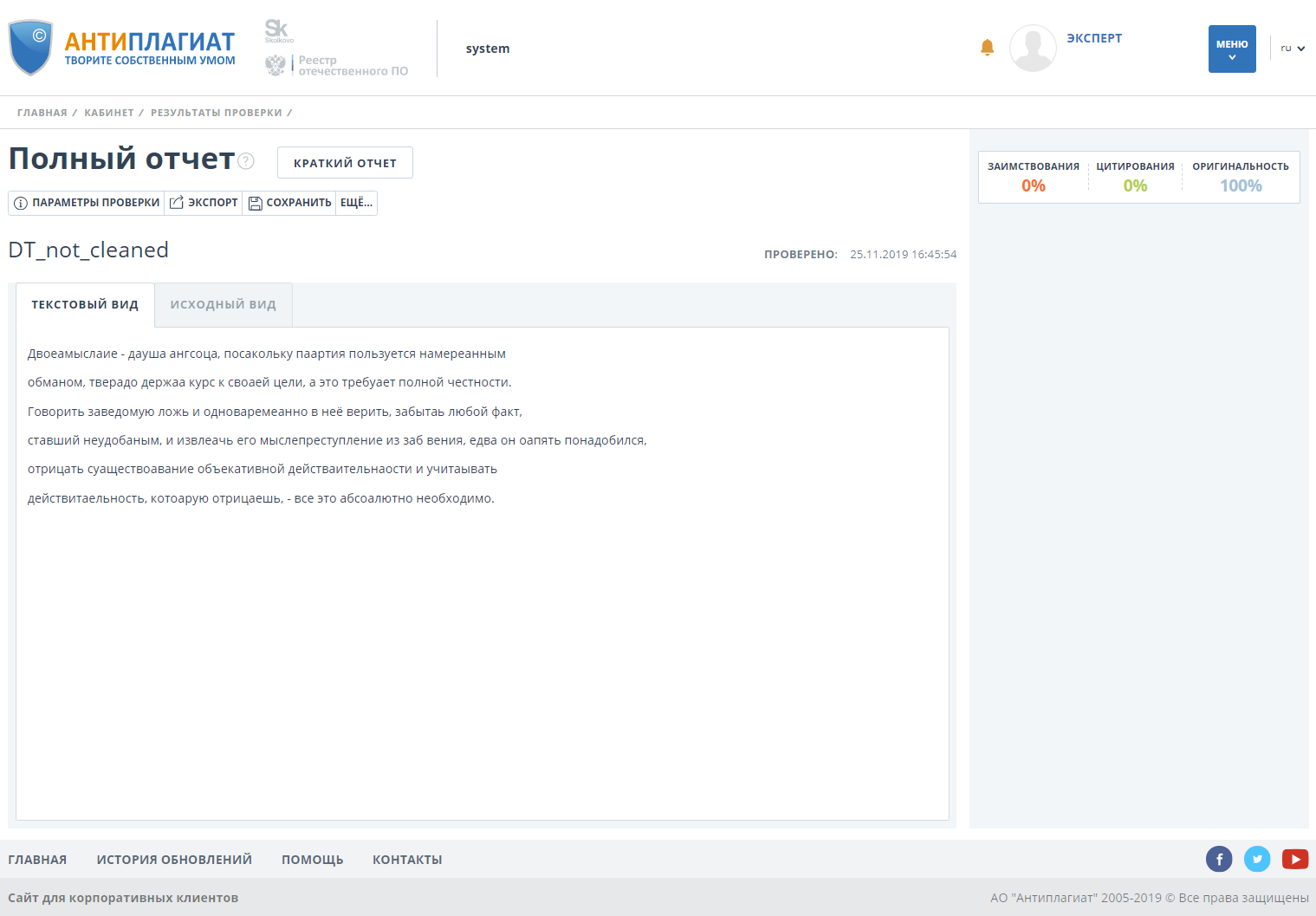
Das Dokument hat hundertprozentige Originalität.
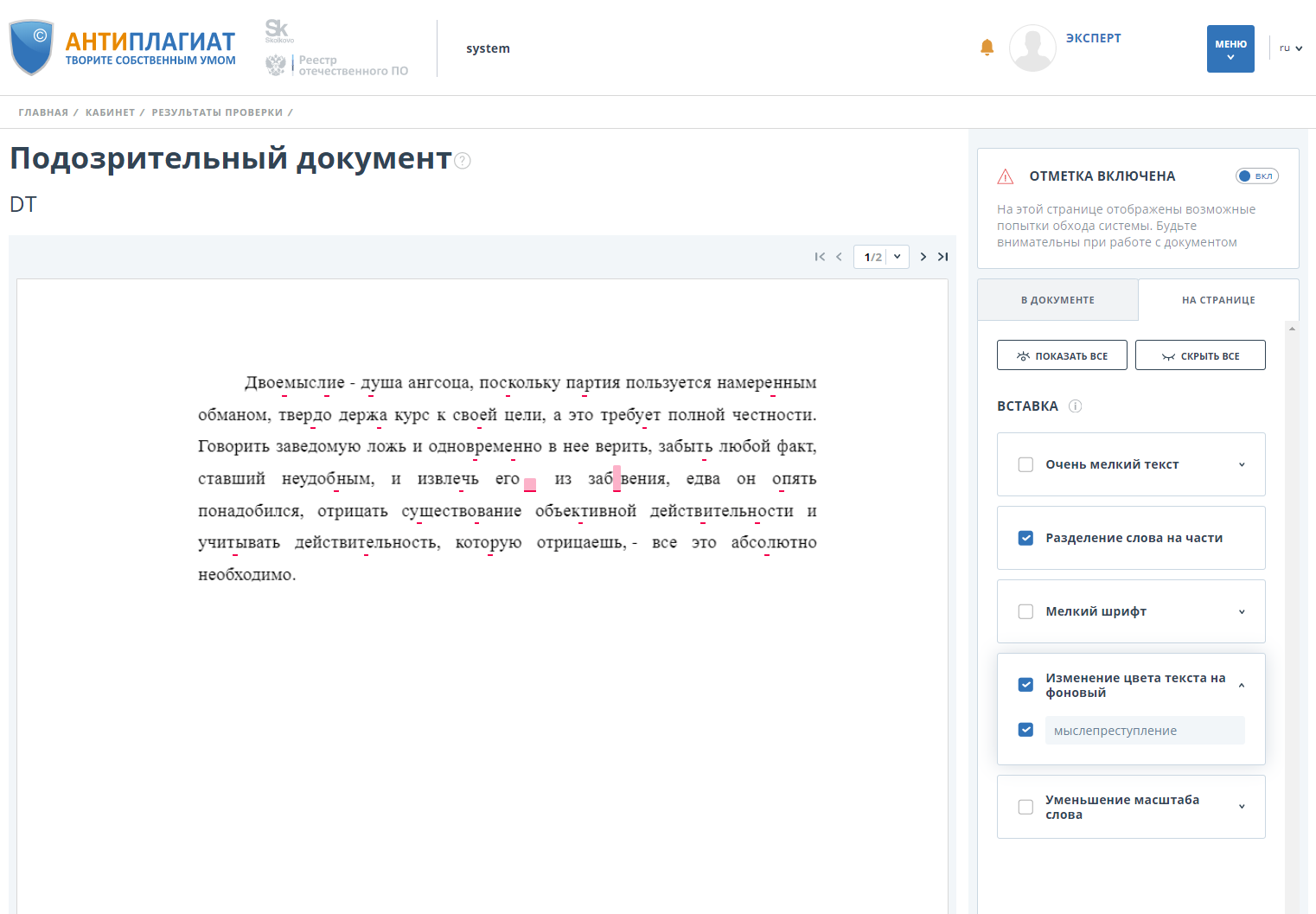
Wir überprüfen das Dokument mit aktivierter Bypass-Erkennung und stellen fest, dass die Originalität auf 0 abfällt.

Außerdem markiert das System das Dokument als "Verdächtig" und zeigt dem Benutzer an, wo und welche Umgehungen erkannt wurden:
Da technische Problemumgehungen dazu dienen, die Originalität eines Dokuments zu verbessern, ist es interessant, sie danach zu klassifizieren, wie sie sich auf die Dokumentüberprüfung auswirken. Basierend auf der Tatsache, dass das Hauptelement der Prüfung eines Dokuments auf Ausleihe die Wörter des Dokuments sind, können Problemumgehungen entsprechend ihrer Auswirkung auf die extrahierten Dokumentwörter in die folgenden Typen unterteilt werden:
- Ändern Sie das Wort (das Wort im extrahierten Text unterscheidet sich von dem im Quelldokument angezeigten Wort).
- Hinzufügen eines Wortes (das Wort ist im Quelldokument nicht sichtbar und wird im extrahierten Text des Dokuments angezeigt);
- Löschen eines Wortes (das Wort ist im Quelldokument sichtbar, nicht im extrahierten Text des Dokuments)
- Wortumbruch (im Originaldokument wird das Wort normal angezeigt, im ausgehärteten Text ist es in zwei oder mehr Teile unterteilt);
- Zusammenführen von Wörtern (mehrere Wörter werden im Quelldokument angezeigt, sie werden im extrahierten Text zu einem Wort zusammengeführt).
Mal sehen, mit welchen Problemumgehungen wir konfrontiert sind. Beginnen wir mit den einfachen und gehen wir zu den interessantesten.
Text-Crawls
Umgehungen dieses Typs sind in keiner Weise an das Format des Dokuments gebunden, sondern ändern den Zeichenfolgenwert der Wörter, sodass sie weiterhin identisch mit den ursprünglichen Wörtern aussehen.
Omoglyphen
Eine der ersten Problemumgehungen, die wir aufgezeichnet haben, war das Ersetzen von Buchstaben durch Omoglyphen - Zeichen, die den Originalbuchstaben optisch ähnlich sind und unterschiedliche Bedeutungen haben. Omoglyphia wird seit den frühesten Tagen des Bestehens des Anti-Plagiat-Systems verwendet , und trotz der Tatsache, dass es seit langer Zeit von uns gefangen wurde, stoßen wir immer noch auf ähnliche Umwege bei der studentischen Arbeit.
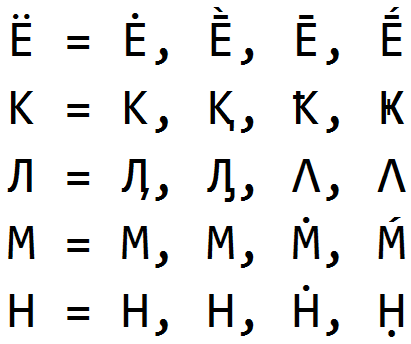
Omoglyphen sind leicht zu finden und zu säubern, wenn die Sprache jedes Wortes bekannt ist. Wir können die Sprache jedes Worts des Textes qualitativ bestimmen, selbst wenn der Text mehrere Sprachen und eine große Menge von "Müll" (Homoglyphen und andere zusätzliche Zeichen) enthält. Wie ist ein Thema für einen separaten Artikel. Mit der Wortsprache und einer Liste möglicher Homoglyphen für die Sprache stellen wir die Buchstaben der Originalsprache wieder her und speichern Informationen über die gefundenen Homoglyphen.
Nicht druckbare Zeichen
Eine andere Möglichkeit, den Zeichenfolgenwert von Wörtern zu ändern, ohne ihre Anzeige wesentlich zu verändern, besteht darin, unsichtbare oder schwach sichtbare Unicode-Zeichen zu verwenden. Das Einfügen solcher Zeichen in ein Wort ändert die Zeichenfolgenbedeutung des Wortes, während die Anzeige praktisch unverändert bleibt.
Viele dieser Zeichen gehören zu den Unicode-Kategorien "Sonstige, Steuerung" und "Markieren, Nicht-Leerzeichen".
Das System löscht diese Zeichen einfach und benachrichtigt den Benutzer bei einer großen Anzahl von Zeichen über den Verdacht des Dokuments und zeigt die gelöschten nicht druckbaren Zeichen im Bericht an.
PDF-Problemumgehungen
Wie bereits erwähnt , ist das Schlüsselformat für die Verarbeitung von Dokumenten pdf. Wir konvertieren alle anderen Dokumenttypen in PDF-Dateien, sodass die grundlegende Logik der Dokumentverarbeitung für alle unterstützten Formate vereinheitlicht wird. Daher sind die Problemumgehungen, die in PDF-Dokumenten implementiert werden können, für uns von besonderem Interesse.
Kleiner Text
Ein Workaround, an den man als erstes denkt, ist, etwas Kleines und Unsichtbares zu machen. Der so erhaltene Text ist beim Anzeigen des Originaldokuments nicht sichtbar, wird jedoch vom System abgerufen. Die Implementierung ist sehr einfach - stellen Sie die minimale Schriftgröße für den Text ein, ändern Sie die Farbe des Texts. Das Auffinden derartiger Bypässe ist ebenso einfach: Prüfen Sie einfach die Schriftgröße des Texts und die geometrischen Abmessungen der einzelnen Wörter. Aufgrund ihrer geringen Größe fügen die Schüler der Seite häufig ganze Absätze eines solchen verborgenen Textes hinzu:

Anzeige eines erkannten Crawl-Versuchs:

Ändern Sie die Textfarbe in den Hintergrund
Trotz der Tatsache, dass diese Methode häufig in Kombination mit der vorherigen verwendet wird, ist ihre unabhängige Anwendung interessanter. Tatsache ist, dass es für uns zum Erkennen und Löschen des Bypasses ausreicht, zu bestimmen, dass mindestens ein Parameter des Wortes / Symbols einen „verdächtigen“ Wert hat. Und wenn die Definition kleiner Wortgrößen trivial ist, ist die Definition von Text, dessen Farbe dem Hintergrund entspricht, ein komplizierteres Verfahren.
Das Erkennen eines unsichtbaren Texts wird durch die folgenden Umstände erschwert:
- Es ist nicht immer möglich, die Farbe eines bestimmten Zeichens aus dem PDF-Format abzurufen.
- Der Hintergrund des Wortes ist möglicherweise nicht weiß. Darüber hinaus befindet sich das Wort möglicherweise auf dem Hintergrund des Bildes.
- Wörter und Symbole können ineinander laufen.
Um die ersten beiden Schwierigkeiten zu beseitigen, wird die "Unsichtbarkeit" des Texts durch Analyse des gerenderten Bildes der Dokumentseite ermittelt:
- Bestimmen Sie den Bereich der Seite, der das Wort enthält.
- Wir berechnen die Varianz der erhaltenen Region. Liegt die Varianz unter einem bestimmten Schwellenwert - im analysierten Bereich haben wir eine einheitliche Farbe, es sind keine Buchstaben sichtbar. Daher wird versucht, das System zu umgehen.
Wörter und Symbole nacheinander versteckt
Unsichtbare Zeichen können nicht durch Analysieren des Bereichs, in dem sie sich befinden, erkannt werden, wenn diese Zeichen hinter anderen „sichtbaren“ Zeichen versteckt sind. Um solche „verborgenen“ Zeichen zu erkennen, haben wir ein separates Verfahren, das die Schnittmenge von Symbolbereichen analysiert und die Zeichen markiert, die von anderen Zeichen weitgehend überlappt werden.

Erkannter Bypass:
Text als Bilder
Was passiert, wenn wir einen Teil des Textes durch Bilder ersetzen, die diesen Text enthalten? Bei richtiger Genauigkeit sieht alles so aus, als hätte sich im Dokument nichts geändert. Wenn Sie jedoch eine Textebene extrahieren, werden natürlich keine Wörter aus Bildern extrahiert. Um diese Lücke zu schließen, verwenden wir die optische Texterkennung.
Problemumgehungen mit Funktionen zur Konvertierung von DocX in PDF
Das Konvertieren von Dokumenten in PDF ist keine einfache Aufgabe. Lesen Sie hier, wie wir die für uns am besten geeignete Lösung ausgewählt haben . Leider konvertiert auch die beste der von uns analysierten Optionen Dokumente unvollständig in PDF. Einige "Funktionen" der Konvertierung werden aktiv verwendet, wenn versucht wird, das System zu umgehen.
Formeln
Formeln und eine Reihe anderer Objekte, die Text enthalten, gehen nach der Konvertierung in PDF „verloren“. Sie können also versuchen, den gesamten Textabschnitt oder beispielsweise jedes zweite Wort im Text auszublenden:

Bei der Konvertierung nach pdf erhalten wir folgendes Ergebnis:

Um diese und andere Problemumgehungen zu erkennen und zu bereinigen, die durch die Konvertierungsfunktionen von docx in pdf verbessert wurden, analysieren und bereinigen wir die Quell-docx-Datei. Insbesondere wenn in einem Dokument eine erhebliche Anzahl von Formeln gefunden wird, ersetzen wir diese durch einfachen Text, der gespeichert wird, wenn das Dokument in PDF konvertiert wird. Darüber hinaus merken wir uns die Positionen der von uns verarbeiteten Formeln und informieren den Benutzer gegebenenfalls über den Verdacht, dass das Dokument geprüft wurde, und markieren den Text, den wir aus den Formeln wiederhergestellt haben.
Maßstab, kleiner Abstand zwischen Symbolen und Linien
Bei der Konvertierung in PDF werden einige Texteigenschaften nicht berücksichtigt: Maßstab, Intersymbol und Zeilenabstand. Auf diese Weise können Sie Text hinzufügen, der im Quelldokument unsichtbar ist (z. B. in sehr kleinem Maßstab), was in PDF zu einem normalen Text wird, der nicht auffällt. Implementierung umgehen (docx):

Das Ergebnis der Konvertierung nach pdf (wir haben die Farbe selbst geändert):

Der einzige Weg, um diesen Text abzufangen, besteht darin, ihn in docx zu finden und Informationen darüber zu speichern. Wenn das Dokument viele solcher Texte enthält, markieren wir das Dokument als verdächtig und zeigen dem Benutzer, wo wir im Dokument Text mit verdächtigen Attributen gefunden haben.
Ein Wort in Stücke brechen
Ein interessanter Sonderfall beim Anwenden der im vorherigen Absatz beschriebenen Eigenschaften besteht darin, dem Wort ein Leerzeichen hinzuzufügen und es auszublenden. Im Originaldokument sieht das Wort normal aus, wird zusammengeführt und nach dem Konvertieren des Dokuments in ein PDF-Dokument in zwei Teile geteilt, sobald der Speicherplatz in voller Größe angezeigt wird. Wir fangen eine ähnliche Finte mit unseren Ohren in etwa der gleichen Weise wie im vorherigen Absatz. Implementierung umgehen (docx):

Das Ergebnis der Konvertierung nach pdf:

Anzeige einer Umleitung:

Unter dem alten Kastanienbaum, im Licht des Tages, habe ich dich betrogen, und du mich ...
Wir haben über die grundlegenden, aber keineswegs alle technischen Möglichkeiten zur Implementierung von Problemumgehungen gesprochen. Natürlich ist es unwahrscheinlich, dass wir jemals in der Lage sein werden, die Verteidigung absolut zu machen. Trotzdem verbessern wir unser System ständig und lassen immer weniger Möglichkeiten, es zu „täuschen“. In der Sitzung versuchen wir, erkennbare Lücken besonders schnell zu schließen - oft vergehen nur wenige Tage, wenn eine Lücke entdeckt wird, bis sie am Produkt geschlossen wird. Das ist der Grund, warum es ein bisschen lächerlich und gleichzeitig traurig ist, die Werbeversprechen von Unternehmen zu lesen, die bereit sind, Studenten dabei zu helfen, die Originalität ihrer Arbeit zu steigern und eine Garantie für ihre Arbeit zu geben, die manchmal 30 Tage erreicht. Student, du wirst verraten! Im besten Fall kann diese „Garantie“ die Kosten für die Dienste der Crawler-Firma an Sie zurückzahlen, aber sie hilft in keiner Weise bei einem fehlgeschlagenen Diplom und einem möglichen Ausschluss von der Universität ...
Kreieren Sie mit Ihrem eigenen Verstand!