Wir nutzen Cloud-Dienste seit langem: E-Mail, Speicher, soziale Netzwerke, Instant Messenger. Sie arbeiten alle remote - wir senden Nachrichten und Dateien und sie werden auf Remote-Servern gespeichert und verarbeitet. Cloud-Spiele funktionieren auch: Der Benutzer stellt eine Verbindung zum Dienst her, wählt das Spiel aus und startet. Dies ist praktisch für den Spieler, da die Spiele fast sofort starten, keinen Speicher belegen und keinen leistungsstarken Spielecomputer benötigen.

Bei einem Cloud-Dienst ist alles anders - er hat Probleme mit der Datenspeicherung. Jedes Spiel kann Dutzende oder Hunderte von Gigabyte wiegen, zum Beispiel "The Witcher 3" benötigt 50 GB und "Call of Duty: Black Ops III" - 113. Gleichzeitig wird der Dienst bei 2-3 Spielen nicht genutzt, es werden mindestens mehrere Dutzend benötigt . Zusätzlich zum Speichern von Hunderten von Spielen muss der Dienst entscheiden, wie viel Speicher pro Spieler zugewiesen werden soll, und bei Tausenden von Spielen skalieren.
Sollte dies alles auf ihren Servern gespeichert werden: Wie viele benötigen sie, wo können Rechenzentren platziert werden, wie können Daten zwischen mehreren Rechenzentren im laufenden Betrieb synchronisiert werden? "Wolken" kaufen? Verwenden Sie virtuelle Maschinen? Ist es möglich, Benutzerdaten fünfmal mit Komprimierung zu speichern und in Echtzeit bereitzustellen? Wie kann ein gegenseitiger Einfluss von Benutzern bei der konsistenten Verwendung derselben virtuellen Maschine ausgeschlossen werden?
All diese Aufgaben wurden in Playkey.net - einer Cloud-basierten Spieleplattform - erfolgreich gelöst.
Vladimir Ryabov (
Graymansama ) - Leiter der Systemadministrationsabteilung - wird ausführlich über die ZFS-Technologie für FreeBSD, die dabei geholfen hat, und die neue ZOL-Version (ZFS unter Linux) sprechen.
Tausend Server des Unternehmens befinden sich in entfernten Rechenzentren in Moskau, London und Frankfurt. Es gibt mehr als 250 Spiele im Service, die von 100.000 Spielern pro Monat gespielt werden.
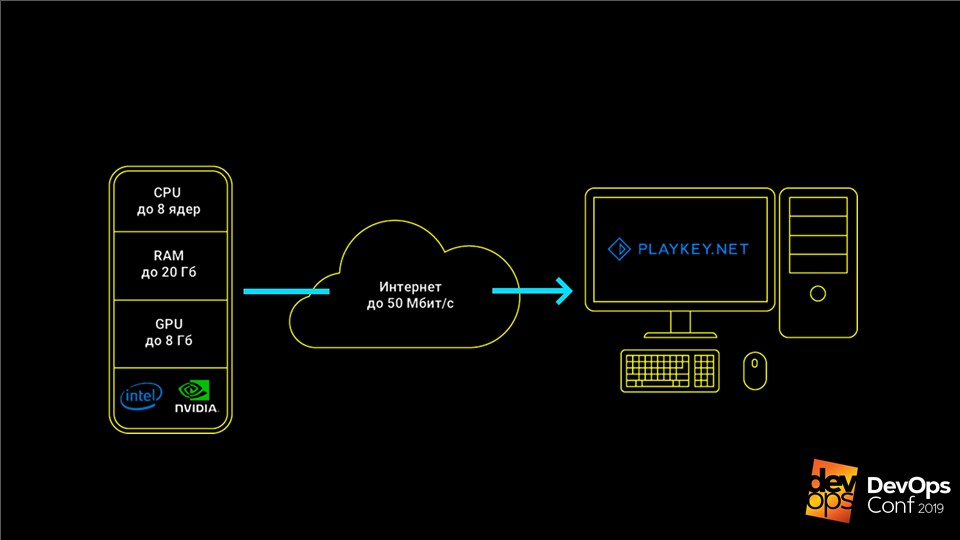
Der Dienst funktioniert folgendermaßen: Das Spiel wird auf den Servern des Unternehmens ausgeführt, der Benutzer erhält eine Reihe von Steuerelementen über Tastatur, Maus oder Gamepad, und als Antwort wird ein Videostream gesendet. Auf diese Weise können Sie moderne Top-End-Spiele auf Computern mit schwacher Hardware, Laptops mit integriertem Video oder auf Macs spielen, für die diese Spiele überhaupt nicht freigegeben sind.
Spiele müssen gespeichert und aktualisiert werden
Die Hauptdaten für den Cloud-Gaming-Dienst sind die Spieldistributionen, die Hunderte von GB überschreiten können, und das Speichern durch Benutzer.
Als wir klein waren, hatten wir nur ein Dutzend Server und einen bescheidenen Katalog von 50 Spielen. Wir haben alle Daten lokal auf den Servern gespeichert, manuell aktualisiert, alles war in Ordnung. Aber die Zeit ist reif und wir machen uns auf den Weg
zu den AWS-Wolken .
Mit AWS haben wir mehrere hundert Server, aber die Architektur hat sich nicht geändert. Sie waren auch Server, aber jetzt virtuell, mit lokalen Festplatten, auf denen die Spieldistributionen lagen. Die manuelle Aktualisierung von 100 Servern schlägt jedoch fehl.
Wir suchten nach einer Lösung. Zuerst haben wir versucht, über
rsync zu aktualisieren. Es stellte sich jedoch heraus, dass dies extrem langsam ist und die Belastung des Hauptknotens zu hoch ist. Dies ist jedoch noch nicht einmal das Schlimmste: Als wir nur wenig online waren, haben wir einige der virtuellen Maschinen ausgeschaltet, um nicht dafür zu zahlen, und beim Aktualisieren wurden die Daten nicht auf die deaktivierten Server übertragen. Alle von ihnen wurden ohne Updates gelassen.
Die Lösung waren Torrents - das
BTSync- Programm. Sie können einen Ordner auf einer großen Anzahl von Knoten synchronisieren, ohne explizit einen zentralen Knoten anzugeben.
Wachstumsprobleme
Für eine Weile hat das alles wunderbar funktioniert. Aber der Dienst entwickelte sich, es gab mehr Spiele und Server. Die Anzahl der lokalen Speicher nahm ebenfalls zu, wir mussten immer mehr bezahlen. In den Wolken ist es teuer, vor allem für SSDs. Zu einem bestimmten Zeitpunkt dauerte sogar die übliche Indizierung eines Ordners zum Starten der Synchronisierung mehr als eine Stunde, und alle Server konnten mehrere Tage lang aktualisiert werden.
BTSync hat ein weiteres Problem mit übermäßigem Netzwerkverkehr verursacht. Damals wurde es bei Amazon sogar zwischen internen Virtuals bezahlt. Wenn der klassische Game Launcher kleine Änderungen an großen Dateien vornimmt, glaubt BTSync sofort, dass sich die gesamte Datei geändert hat, und beginnt, sie vollständig auf alle Knoten zu übertragen. Selbst ein Upgrade von 15 MB kann daher zig GB Synchronisationsdatenverkehr generieren.
Die Situation wurde kritisch, als der Speicher auf 1 TB anstieg. Habe gerade ein neues Spiel World of Warships veröffentlicht. Ihre Distribution hatte mehrere hunderttausend kleine Dateien. BTSync konnte es nicht verdauen und an alle anderen Server verteilen - dies verlangsamte die Verteilung anderer Spiele.
All diese Faktoren verursachten zwei Probleme:
- Die lokale Lagerhaltung ist teuer, unpraktisch und schwierig zu aktualisieren.
- Die Wolken waren sehr teuer.
Wir haben uns entschlossen, zum Konzept unserer physischen Server zurückzukehren.
Eigenes Speichersystem
Bevor wir auf physische Server wechseln, müssen wir den lokalen Speicher entfernen. Dies erfordert ein eigenes
Speichersystem - Speicher . Dies ist ein System, das alle Distributionen speichert und zentral an alle Server verteilt.
Es scheint, dass die Aufgabe einfach ist - sie wurde bereits wiederholt gelöst. Aber bei Spielen gibt es Nuancen. Beispielsweise lehnen die meisten Spiele die Arbeit ab, wenn sie nur über Lesezugriff verfügen. Selbst beim normalen Start schreiben sie gerne etwas in ihre Dateien, ohne dass sie sich weigern zu arbeiten. Im Gegenteil, wenn einer großen Anzahl von Benutzern Zugriff auf einen Satz von Distributionen gewährt wird, beginnen sie, die Dateien des anderen mit wettbewerbsfähigem Zugriff zu schlagen.
Wir haben über das Problem nachgedacht, verschiedene mögliche Lösungen geprüft und sind zu
ZFS - Zettabyte File System auf FreeBSD gekommen .
ZFS unter FreeBSD
Dies ist kein gewöhnliches Dateisystem. Klassische Systeme werden zunächst auf einem Gerät installiert und erfordern für das Arbeiten mit mehreren Festplatten bereits einen Volume Manager.
ZFS wurde ursprünglich auf virtuellen Pools erstellt.
Sie heißen
zpool und bestehen aus Plattengruppen oder RAID-Arrays. Das gesamte Volumen dieser Festplatten steht für jedes Dateisystem innerhalb von zpool zur Verfügung. Das liegt daran, dass ZFS ursprünglich als System entwickelt wurde, das mit großen Datenmengen arbeitet.
Wie ZFS zur Lösung unserer Probleme beitrug
Dieses System verfügt über einen wunderbaren
Mechanismus zum Erstellen von Schnappschüssen und Klonen . Sie werden
sofort erstellt und wiegen nur wenige KB. Wenn wir Änderungen an einem der Klone vornehmen, erhöht sich das Volumen dieser Änderungen. Gleichzeitig ändern sich die Daten in den verbleibenden Klonen nicht und bleiben eindeutig. Auf diese Weise können Sie eine
10-TB- Festplatte mit exklusivem Zugriff für den Endbenutzer mit nur wenigen KB verteilen.
Werden Klone, die während einer Spielsitzung Änderungen vornehmen, nicht so viel Platz beanspruchen wie alle Spiele? Nein, wir haben festgestellt, dass selbst in längeren Spielsitzungen die Anzahl der Änderungen selten 100-200 MB überschreitet - dies ist nicht kritisch. Aus diesem Grund können wir mehreren hundert Benutzern gleichzeitig vollen Zugriff auf eine vollwertige Festplatte mit hoher Kapazität gewähren, wobei wir nur 10 TB mit einem Tail ausgeben.
So funktioniert ZFS
Die Beschreibung scheint kompliziert, aber ZFS funktioniert ganz einfach. Lassen Sie uns seine Arbeit
zpool data eines einfachen Beispiels analysieren: Erstellen Sie
zpool data von den verfügbaren
zpool create data /dev/da /dev/db /dev/dc Datenträgern.
zpool create data /dev/da /dev/db /dev/dc .
Hinweis Dies ist für die Produktion nicht erforderlich, da bei Ausfall mindestens einer Festplatte der gesamte Pool in Vergessenheit gerät. Verwenden Sie besser RAID-Gruppen.Wir erstellen das Dateisystem
zfs create data/games und darin ein Blockgerät mit dem Namen
data/games/disk von 10 TB. Das Gerät ist unter
/dev/zvol/data/games/disk als normale Festplatte verfügbar - Sie können die gleichen Manipulationen damit durchführen.
Dann beginnt der Spaß. Wir geben diese Festplatte über
iSCSI an unseren Update-Assistenten weiter - eine normale virtuelle Maschine, auf der Windows ausgeführt wird. Wir verbinden die Festplatte und legen die Spiele einfach über Steam darauf, wie auf einem normalen Heimcomputer.
Fülle die Scheibe mit Spielen. Jetzt müssen diese Daten für Endbenutzer auf
200 Server verteilt werden.
- Erstellen Sie einen Snapshot dieser Festplatte und nennen Sie ihn die erste Version -
zfs snapshot data/games/disk@ver1 . Erstellen Sie den Klon zfs clone data/games/disk@ver1 data/games/disk-vm1 , der zur ersten virtuellen Maschine geleitet wird. - Wir geben den Klon über iSCSI und KVM startet eine virtuelle Maschine mit dieser Festplatte . Es wird geladen, geht in einen Pool von zugänglichen Servern für Benutzer und erwartet einen Spieler.
- Nach Abschluss der Benutzersitzung werden alle von diesem virtuellen Computer gespeicherten Benutzer auf einem separaten Server abgelegt . Wir schalten die virtuelle Maschine aus und zerstören den Klon -
zfs destroy data/games/disk-vm1 . - Wir kehren zum ersten Schritt zurück, erstellen erneut einen Klon und starten die virtuelle Maschine.
Dies ermöglicht es uns, jedem nächsten Benutzer einen
immer sauberen Computer zur Verfügung zu stellen, auf dem keine Änderungen gegenüber dem vorherigen Spieler vorgenommen wurden. Die Festplatte wird nach jeder Benutzersitzung gelöscht, und der auf dem Speichersystem belegte Speicherplatz wird freigegeben. Wir führen ähnliche Vorgänge auch mit der Systemfestplatte und mit allen unseren virtuellen Maschinen durch.
Kürzlich stieß ich auf YouTube auf ein Video, in dem ein zufriedener Benutzer während einer Spielsitzung unsere Festplatten auf Servern formatierte und sich sehr darüber freute, dass er alles kaputt gemacht hatte. Ja, bitte, nur um zu bezahlen - er kann spielen und sich verwöhnen lassen. In jedem Fall erhält der nächste Benutzer immer eine saubere, funktionsfähige virtuelle Maschine, egal was der vorherige tut.
Nach diesem Schema werden Spiele auf nur 200 Server verteilt. Wir haben die Zahl 200 experimentell berechnet: Dies ist die Anzahl der Server, auf denen keine kritischen Belastungen der Speicherlaufwerke auftreten. Dies liegt daran, dass
Spiele ein ziemlich spezifisches Belastungsprofil haben : Sie lesen viel in der Startphase oder in der Level-Ladephase und verwenden während des Spiels im Gegenteil praktisch keine Diskette. Wenn Ihr Lastprofil unterschiedlich ist, ist die Abbildung unterschiedlich.
Nach dem alten Schema benötigen wir für die gleichzeitige Wartung von 200 Benutzern 2.000 TB lokalen Speicher. Jetzt können wir etwas mehr als 10 TB für den Hauptdatensatz ausgeben, und es sind noch 0,5 TB für Benutzerwechsel verfügbar. Obwohl ZFS es liebt, wenn mindestens 15% des freien Speicherplatzes in seinem Pool vorhanden sind, scheint es mir, dass wir erheblich gespart haben.
Was ist, wenn wir mehrere Rechenzentren haben?
Dieser Mechanismus funktioniert nur in einem Rechenzentrum, in dem Server mit einem Speichersystem über mindestens 10-Gigabit-Schnittstellen verbunden sind. Was tun bei mehreren DCs? Wie aktualisiere ich die Hauptdiskette mit Spielen (Datensatz) zwischen ihnen?
Dafür hat ZFS eine eigene Lösung -
den Send / Receive-Mechanismus . Der Ausführungsbefehl ist sehr einfach:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
Mit diesem Mechanismus können Sie einen Snapshot vom Hauptsystem von einem Speichersystem auf ein anderes übertragen. Zum ersten Mal müssen Sie alle 10 Terabyte an Daten, die auf den Masterknoten geschrieben wurden, an ein leeres Speichersystem senden. Bei den nächsten Aktualisierungen werden Änderungen jedoch erst ab dem Zeitpunkt gesendet, an dem die vorherige Momentaufnahme erstellt wurde.
Als Ergebnis erhalten wir:
- Alle Änderungen werden zentral auf einem Speichersystem vorgenommen . Dann verteilen sie sich auf alle anderen Rechenzentren in beliebiger Menge, und die Daten auf allen Knoten sind immer identisch.
- Der Sende- / Empfangsmechanismus hat keine Angst vor einer Unterbrechung . Daten werden erst dann auf den Hauptdatensatz angewendet, wenn sie vollständig an den Slave-Knoten übertragen wurden. Wenn die Verbindung unterbrochen wird, können die Daten nicht beschädigt werden. Wiederholen Sie einfach den Sendevorgang.
- Jeder Knoten kann während eines Unfalls in wenigen Minuten leicht zum Masterknoten werden, da die Daten auf allen Knoten immer identisch sind.
Deduplizierung und Backups
ZFS bietet eine weitere nützliche Funktion - die
Deduplizierung . Diese Funktion hilft
, zwei identische Datenblöcke nicht zu speichern . Stattdessen wird nur der erste Block gespeichert, und anstelle des zweiten wird eine Verknüpfung zum ersten gespeichert. Zwei identische Dateien belegen einen Speicherplatz und füllen 110% des ursprünglichen Volumens aus, wenn sie zu 90% übereinstimmen.
Die Funktion hat uns sehr beim Speichern von Benutzern geholfen. In einem Spiel haben verschiedene Benutzer eine ähnliche Speicherung, viele Dateien sind gleich. Durch die Verwendung der Deduplizierung können wir fünfmal so viele Daten speichern. Unser Deduplizierungsverhältnis beträgt 5,22. Physikalisch haben wir 4,43 Terabyte, multiplizieren mit einem Faktor und erhalten fast 23 Terabyte echte Daten. Dies spart Platz, indem doppelte Speicherung vermieden wird.
Snapshots eignen sich gut für Backups . Wir verwenden diese Technologie für unsere Dateispeicher. Wenn Sie beispielsweise einen Monat lang jeden Tag ein Bild speichern, können Sie jederzeit an jedem Tag des Monats einen Klon bereitstellen und verlorene oder beschädigte Dateien abrufen. Dadurch entfällt die Notwendigkeit, den gesamten Speicher zurückzusetzen oder eine vollständige Kopie davon bereitzustellen.
Wir verwenden Klone, um unseren Entwicklern zu helfen . Zum Beispiel möchten sie eine potenziell gefährliche Migration auf einer Kampfbasis erleben. Es ist nicht schnell, eine klassische Sicherung einer Datenbank bereitzustellen, die sich 1 TB nähert. Daher entfernen wir einfach den Klon von der Basisfestplatte und fügen ihn sofort der neuen Instanz hinzu. Jetzt können Entwickler dort alles sicher testen.
ZFS-API
All dies muss natürlich automatisiert werden. Warum auf Server klettern, mit den Händen arbeiten, Skripte schreiben, wenn dies Programmierern gegeben werden kann? Deshalb haben wir unsere einfache
Web-API geschrieben .
Wir haben alle Standard-ZFS-Funktionen darin eingeschlossen, den Zugriff auf potenziell gefährliche Funktionen unterbrochen, die das gesamte Speichersystem beschädigen könnten, und all dies den Programmierern zur Verfügung gestellt. Jetzt werden
alle Festplattenvorgänge streng zentralisiert und durch Code ausgeführt, und wir
kennen immer den Status jeder Festplatte . Alles funktioniert super.
ZoL - ZFS unter Linux
Wir haben das System zentralisiert und dachten, ist es so gut? Tatsächlich müssen wir jetzt für jede Erweiterung sofort mehrere Server-Racks kaufen: Sie sind an Speichersysteme gebunden, und es ist irrational, das System zu teilen. Was tun, wenn wir beschließen, einen kleinen Demo-Stand bereitzustellen, um Partnern in anderen Ländern die Technologie zu zeigen?
Nachdenklich kamen wir zu der alten Idee,
lokale Laufwerke zu verwenden , aber nur mit all den Erfahrungen und Kenntnissen, die wir erhalten haben. Wenn Sie die Idee globaler ausbauen, können Sie unseren Benutzern dann nicht nur die Möglichkeit geben, unsere Server zu nutzen, sondern auch ihre Computer zu mieten.
Die relativ neue
Version von
ZFS unter Linux - ZoL hat uns dabei sehr geholfen.
Jetzt hat jeder Server seinen eigenen Speicher.
Nur werden nicht 10 Terabyte Daten gespeichert, wie bei einer zentralen Installation, sondern nur 1-2 Distributionen der Spiele, für die es bereitgestellt wird. Eine SSD reicht dafür aus. All dies funktioniert einwandfrei: Jeder nächste Benutzer erhält immer eine saubere virtuelle Maschine sowie eine Kampfinstallation.
Hier sind wir jedoch auf zwei Probleme gestoßen.
Wie aktualisiere ich?
Update zentral über SSH, wie wir es in den Rechenzentren tun, wird nicht funktionieren . Benutzer können im Gegensatz zu Speichersystemen mit dem lokalen Netzwerk verbunden oder einfach ausgeschaltet werden, und Sie möchten nicht so viele SSH-Verbindungen herstellen.
Wir hatten die gleichen Probleme wie bei der Verwendung von rsync. Torrents auf ZFS können jedoch nicht mehr bezogen werden. Wir haben uns genau überlegt, wie der Sendemechanismus funktioniert: Er sendet alle geänderten Datenblöcke an den endgültigen Speicher, und Receive wendet sie auf den aktuellen Datensatz an. Warum nicht die Daten in eine Datei schreiben, anstatt sie an den Endbenutzer zu senden?
Das Ergebnis nennen wir
diff . Dies ist eine Datei, in die alle zwischen den letzten beiden Snapshots geänderten Blöcke nacheinander geschrieben werden. Wir haben diesen Diff auf einen CDN gelegt und ihn per HTTP an alle unsere Benutzer gesendet: Er hat den Computer eingeschaltet, festgestellt, dass Aktualisierungen vorgenommen wurden, die Luft abgelassen und ihn mit Receive auf den lokalen Datensatz angewendet.
Was tun mit Fahrern?
Zentralisierte Server haben dieselbe Konfiguration, und
Endbenutzer haben immer unterschiedliche Computer und Grafikkarten . Selbst wenn wir die Betriebssystemverteilung so weit wie möglich mit allen möglichen Treibern füllen, wird sie beim ersten Start diese Treiber trotzdem installieren wollen, dann wird sie neu gestartet und dann möglicherweise erneut. Da jedes Mal, wenn wir einen sauberen Klon bereitstellen, alle diese Karussells nach jeder Benutzersitzung auftreten - das ist schlecht.
Wir wollten einen Initialisierungslauf durchführen: Warten Sie, bis Windows hochfährt, alle Treiber installiert, alles tut, was sie will, und erst dann auf diesem Laufwerk arbeiten. Das Problem ist jedoch, dass die Aktualisierungen unterbrochen werden, wenn Sie Änderungen am Hauptdatensatz vornehmen, da die Daten auf der Quelle und auf dem Empfänger unterschiedlich sind und diff einfach nicht angewendet werden.
ZFS ist jedoch ein flexibles System, mit dem wir eine kleine Krücke bauen konnten.
- Erstellen Sie wie gewohnt einen Snapshot:
zfs snapshot data/games/os@init . - Erstellen Sie den Klon -
zfs clone data/games/os@init data/games/os-init - und führen Sie ihn im Initialisierungsmodus aus. - Wir warten darauf, dass alle Treiber installiert werden und alles neu gestartet wird.
- Schalten Sie die virtuelle Maschine aus und machen Sie erneut einen Schnappschuss. Diesmal jedoch nicht aus dem ursprünglichen Datensatz, sondern aus dem Initialisierungsklon:
zfs snapshot data/games/os-init@ver1 . - Wir erstellen einen Klon des Schnappschusses mit allen installierten Treibern. Es wird nicht mehr neu gestartet:
zfs clone data/games/os-init@ver1 data/games/os-vm1 . - Dann arbeiten wir am klassischen Haufen.
Jetzt befindet sich dieses System in der Alpha-Testphase. Wir testen es an echten Benutzern ohne Linux-Kenntnisse, aber sie schaffen es, alles zu Hause bereitzustellen. Unser oberstes Ziel ist es, dass jeder Benutzer einfach ein bootfähiges USB-Flash-Laufwerk an seinen Computer anschließt, ein zusätzliches SSD-Laufwerk anschließt und es auf unserer Cloud-Plattform ausleiht.
Wir haben nur einen kleinen Teil der ZFS-Funktionalität besprochen. Dieses System kann viel interessanter und unterschiedlicher sein, aber nur wenige kennen sich mit ZFS aus - Benutzer möchten nicht darüber sprechen. Ich hoffe, dass nach diesem Artikel neue Benutzer in der ZFS-Community auftauchen.
Abonnieren Sie einen Telegrammkanal oder Newsletter , um mehr über neue Artikel und Videos von der DevOpsConf- Konferenz zu erfahren. Neben dem Newsletter sammeln wir Neuigkeiten von bevorstehenden Konferenzen und berichten beispielsweise, was für DevOps-Fans auf der Saint HighLoad ++ interessant sein wird.