Es ist bekannt, dass die CTO-Kompetenz erst zum zweiten Mal getestet wird, wenn diese Rolle gespielt wird. Weil es eine Sache ist, mehrere Jahre in einem Unternehmen zu arbeiten, sich mit ihm zu entwickeln und im gleichen kulturellen Kontext nach und nach mehr Verantwortung zu übernehmen. Und es ist eine ganz andere Sache - sofort den Posten eines technischen Direktors in einem Unternehmen mit Altgepäck und einer Reihe von Problemen zu übernehmen, die ordentlich unter dem Teppich aufgefallen sind.
In diesem Sinne ist die Erfahrung von Leon Fayer, die er auf
DevOpsConf teilte, nicht nur direkt einzigartig, sondern multipliziert mit der Erfahrung und der Anzahl der verschiedenen Rollen, die er über 20 Jahre für sich selbst ausprobiert hat, sehr nützlich. Unter dem Strich eine Chronologie von Ereignissen über 90 Tage und viele Geschichten, über die man gerne lachen kann, wenn sie jemand anderem passieren, die aber nicht so lustig sind, wenn man sie persönlich sieht.
Leon ist auf Russisch sehr farbenfroh. Wenn Sie also 35-40 Minuten Zeit haben, empfehle ich, das Video anzuschauen. Textversion, um Zeit zu sparen.
Die erste Version des Berichts enthielt eine gut strukturierte Beschreibung der Arbeit mit Menschen und Prozessen sowie nützliche Empfehlungen. Aber sie übermittelte nicht alle Überraschungen, die sich auf dem Weg ergaben. Aus diesem Grund habe ich das Format geändert und die Probleme beschrieben, die die neue Firma aus einer Schnupftabakdose vor mir aufgetaucht ist, sowie die Methoden, um sie in chronologischer Reihenfolge zu lösen.
Einen Monat zuvor
Wie viele gute Geschichten begann auch diese mit Alkohol. Wir saßen mit Freunden in der Bar, und wie es sich für IT-Leute gehört, weinten alle über ihre Probleme. Einer von ihnen wechselte nur den Job und sprach über seine Probleme mit der Technologie, mit Menschen und mit dem Team. Je länger ich zuhörte, desto mehr wurde mir klar, dass er mich nur einstellen musste, weil es genau solche Probleme waren, die ich in den letzten 15 Jahren gelöst hatte. Ich sagte es ihm und am nächsten Tag trafen wir uns bereits in einer Arbeitsumgebung. Die Firma hieß Lehrstrategien.
Teaching Strategies ist führend auf dem Markt für Bildungsprogramme für Kleinkinder - von der Geburt bis zu drei Jahren. Das traditionelle Papierunternehmen ist bereits 40 Jahre alt und die digitale SaaS-Version der Plattform 10. Vor relativ kurzer Zeit hat der Prozess der Anpassung der digitalen Technologie an Unternehmensstandards begonnen. Die "neue" Version wurde im Jahr 2017 eingeführt und war fast wie die alte, nur hat es noch schlimmer geklappt.
Das Interessanteste ist, dass der Verkehr in diesem Unternehmen sehr vorhersehbar ist - Sie können von Tag zu Tag, von Jahr zu Jahr sehr genau vorhersagen, wie viele Menschen wann kommen werden. Beispielsweise gehen alle Kinder in Kindergärten zwischen 13.00 und 15.00 Uhr in den Schlaf, und die Lehrer beginnen, Informationen einzugeben. Und das jeden Tag außer am Wochenende, denn am Wochenende arbeitet fast niemand.
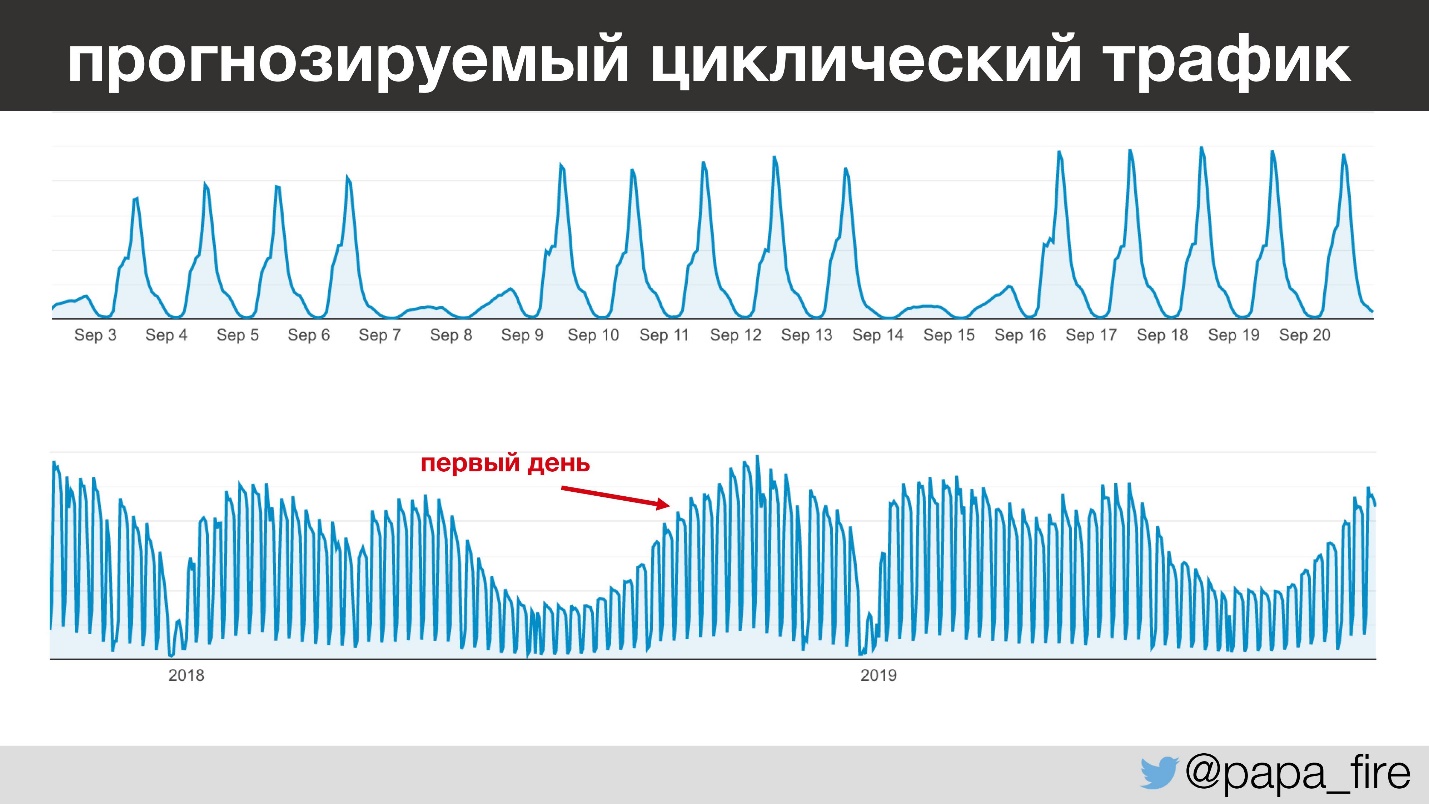
Mit Blick auf die Zukunft habe ich meine Arbeit in der Zeit des größten jährlichen Verkehrs aufgenommen, was aus verschiedenen Gründen interessant ist.
Die Plattform, die nur 2 Jahre alt zu sein schien, hatte einen besonderen Stack: ColdFusion & SQL Server 2008. ColdFusion ist, wenn Sie es nicht wissen, aber höchstwahrscheinlich nicht wissen, ein solches Unternehmens-PHP, das Mitte der 90er Jahre herauskam, und seitdem habe ich noch nicht einmal davon gehört. Es gab auch: Ruby, MySQL, PostgreSQL, Java, Go, Python. Der Hauptmonolith funktionierte jedoch mit ColdFusion und SQL Server.
Die Probleme
Je mehr ich mit den Mitarbeitern des Unternehmens über die Arbeit sprach und auf welche Probleme gestoßen wurde, desto mehr wurde mir klar, dass die Probleme nicht nur technischer Natur sind. Okay, die Technologie ist alt - und daran haben sie nicht gearbeitet, aber es gab Probleme mit dem Team und den Prozessen, und das Unternehmen begann dies zu verstehen.
Traditionell saßen Technikfreaks in der Ecke und erledigten einen Teil ihrer Arbeit. Aber immer mehr Geschäfte gingen über die digitale Version. Daher sind im Unternehmen im letzten Jahr vor Beginn meiner Arbeit neue hinzugekommen: der Verwaltungsrat, CTO, CPO und QA-Direktor. Das heißt, das Unternehmen begann, in den technologischen Bereich zu investieren.
Spuren von schwerem Erbe befanden sich nicht nur in den Systemen. Das Unternehmen hatte Legacy-Prozesse, Legacy-Leute und Legacy-Kultur. All dies musste geändert werden. Ich dachte, dass es definitiv nicht langweilig sein würde, und beschloss, es zu versuchen.
Zwei Tage zuvor
Zwei Tage vor Beginn eines neuen Jobs kam ich ins Büro, füllte die letzten Papiere aus, lernte das Team kennen und stellte fest, dass das Team zu diesem Zeitpunkt mit dem Problem zu kämpfen hatte. Es bestand in der Tatsache, dass die durchschnittliche Ladezeit der Seite auf 4 s sprang, dh 2 mal.
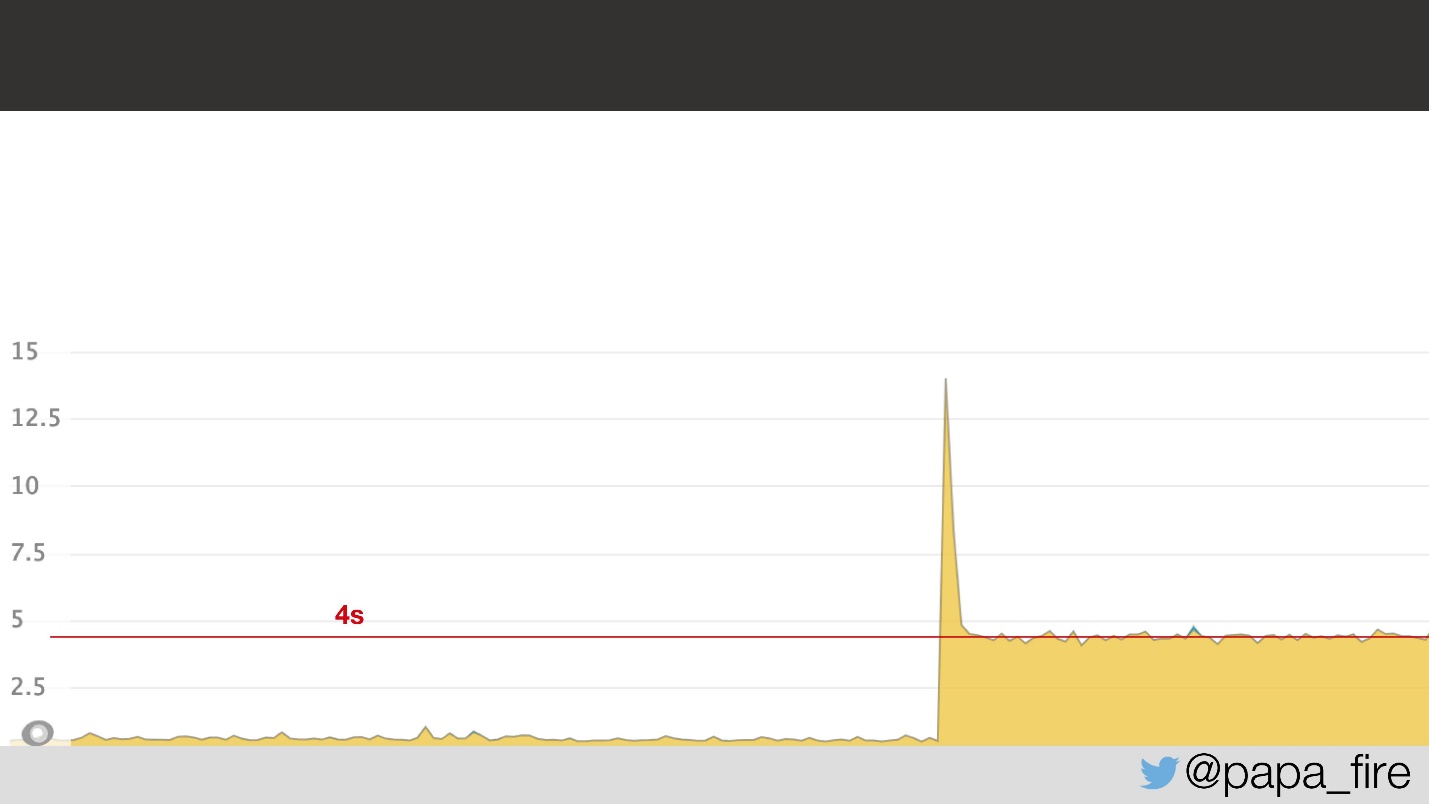
Nach dem Zeitplan zu urteilen, ist offensichtlich etwas passiert, und es ist nicht klar, was. Es stellte sich heraus, dass das Problem in der Netzwerklatenz im Rechenzentrum lag: 5 ms Latenz im Rechenzentrum wurden für Benutzer auf 2 s konvertiert. Warum dies geschah, wusste ich nicht, aber auf jeden Fall wurde bekannt, dass das Problem im Rechenzentrum liegt.
Erster Tag
Zwei Tage vergingen und an meinem ersten Arbeitstag stellte ich fest, dass das Problem nicht behoben war.
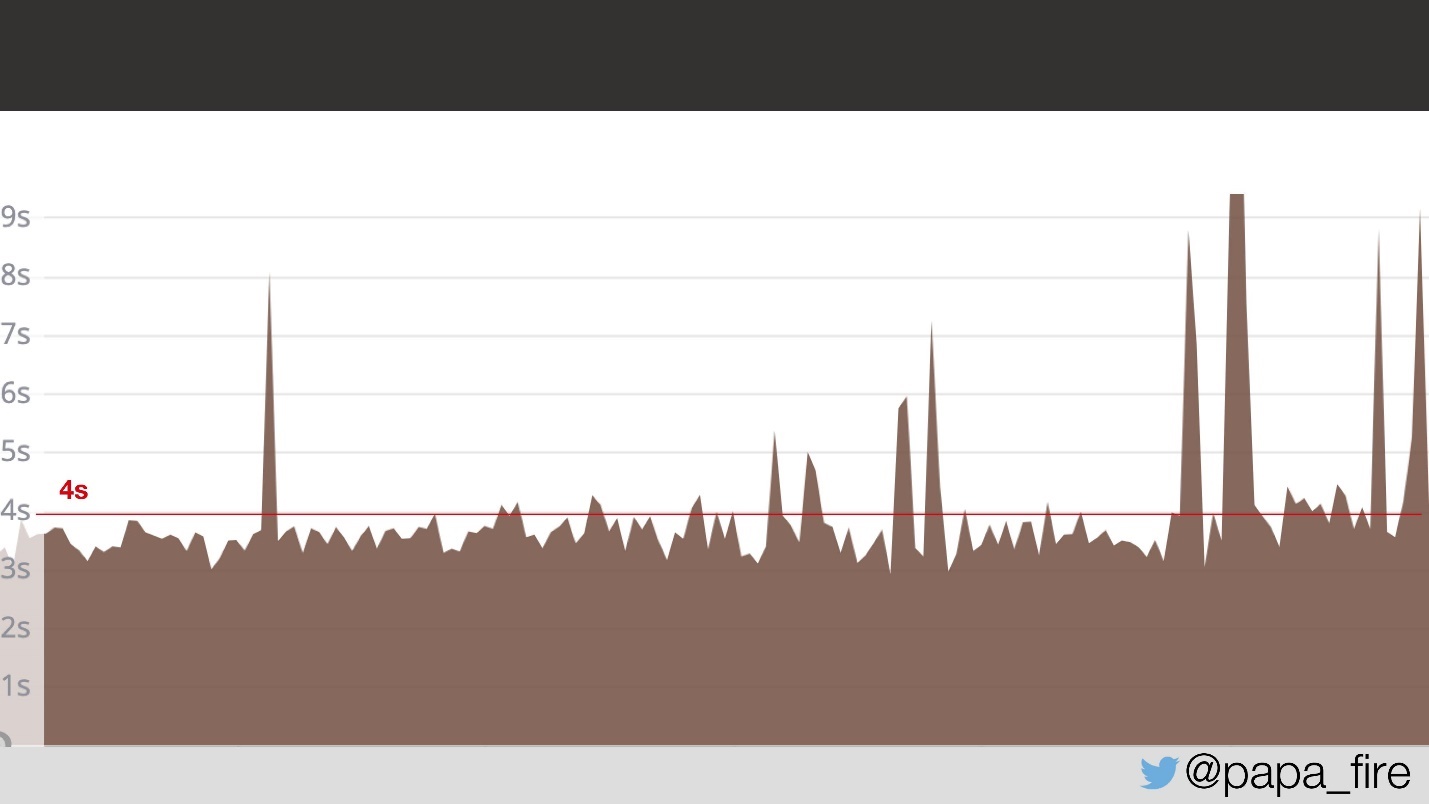
Zwei Tage lang luden Benutzer der Seite durchschnittlich 4 Sekunden. Ich frage, ob sie das Problem gefunden haben.
- Ja, wir haben ein Ticket geöffnet.
- Und?
"Nun, sie haben uns noch nicht geantwortet."Dann wurde mir klar, dass alles, worüber ich zuvor erzählt worden war, nur die kleine Spitze des Eisbergs war, mit der ich kämpfen musste.
Es gibt ein gutes Zitat, das für diesen Fall sehr gut geeignet ist:
"Manchmal muss man die Organisation ändern, um die Technologie zu ändern."
Da ich jedoch in der arbeitsreichsten Zeit des Jahres zu arbeiten begann, musste ich beide Optionen zur Lösung des Problems in Betracht ziehen: sowohl schnell als auch langfristig. Und fangen Sie mit dem an, was gerade wichtig ist.
Tag drei
Das Laden dauert also 4 Sekunden und von 13 bis 15 die größten Spitzen.
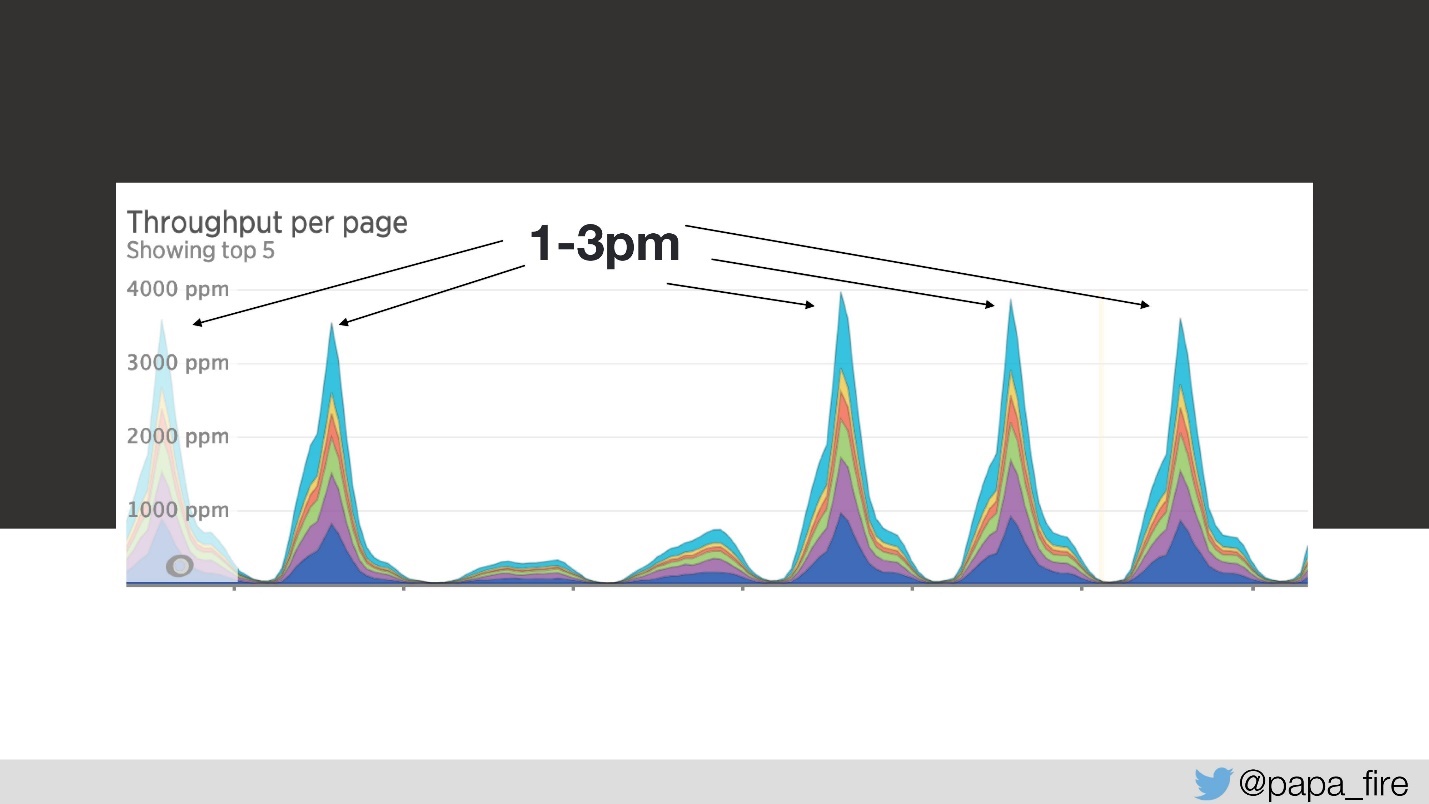
Am dritten Tag in diesem Zeitintervall sah die Download-Geschwindigkeit folgendermaßen aus:
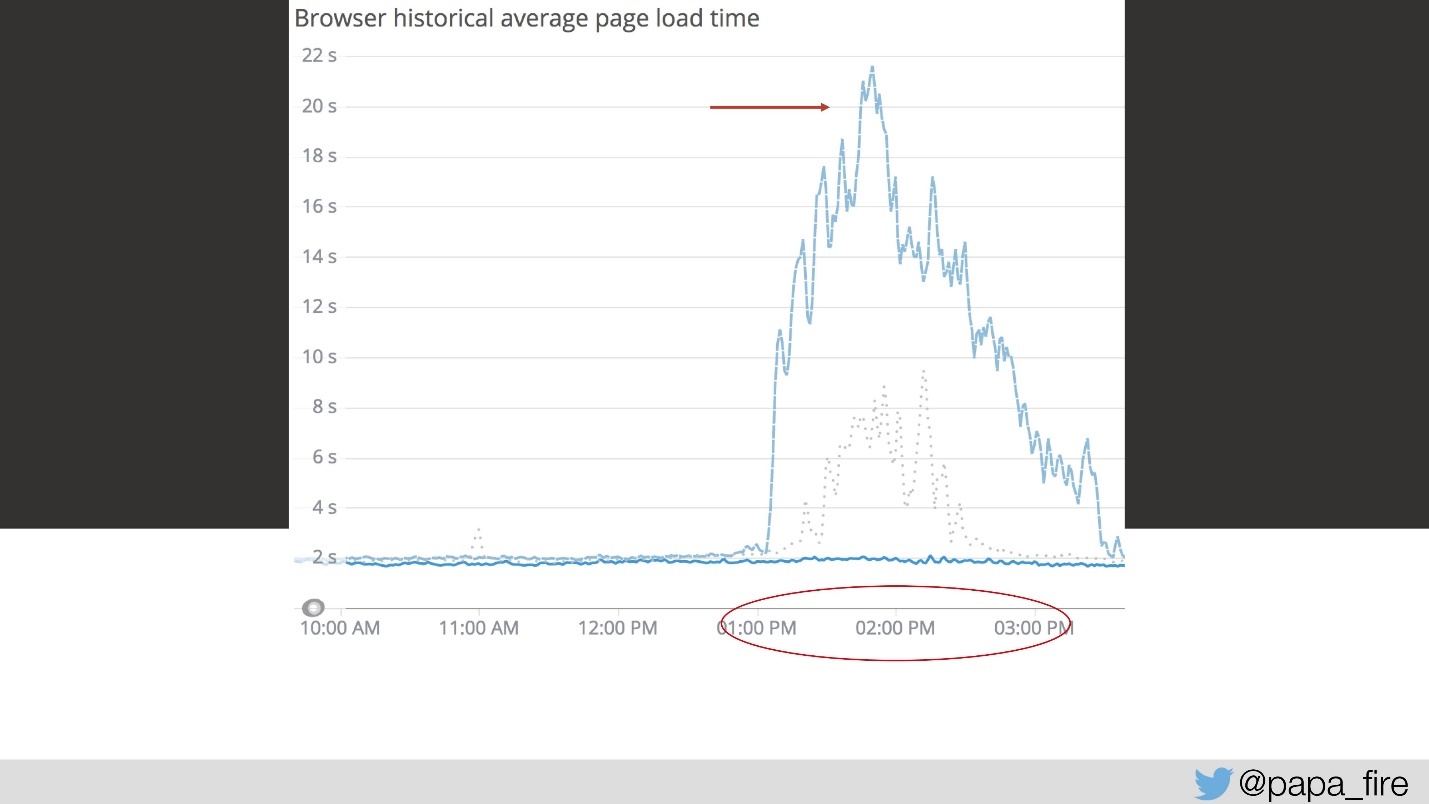
Aus meiner Sicht hat gar nichts funktioniert. Aus der Sicht aller anderen ging es etwas langsamer als sonst. Aber das passiert einfach nicht so - das ist ein ernstes Problem.
Ich habe versucht, das Team zu überzeugen, dem sie geantwortet haben, dass sie nur mehr Server brauchen. Dies ist natürlich die Lösung des Problems, aber keineswegs immer die einzige und effektivste. Ich habe gefragt, warum es nicht genug Server gibt, wie viel Verkehr. Ich habe die Daten hochgerechnet und festgestellt, dass wir ungefähr 150 Anfragen pro Sekunde haben, was im Grunde genommen in vernünftige Grenzen passt.
Aber wir dürfen nicht vergessen, dass Sie die richtige Frage stellen müssen, bevor Sie die richtige Antwort erhalten. Meine nächste Frage war: Wie viele Frontend-Server haben wir? Die Antwort "verwirrt mich" - wir hatten 17 Frontend-Server!
- Es ist mir peinlich zu fragen, 150 geteilt durch 17, wird es ungefähr 8 sein? Sie möchten sagen, dass jeder Server 8 Anfragen pro Sekunde überspringt und wenn es morgen 160 Anfragen pro Sekunde gibt, brauchen wir 2 weitere Server?Natürlich brauchten wir keine zusätzlichen Server. Die Lösung lag im Code selbst und auf der Oberfläche:
var currentClass = classes.getCurrentClass(); return currentClass;
Es gab eine
getCurrentClass() Funktion, weil alles auf der Site im Kontext der Klasse funktioniert - richtig. Und für diese eine Funktion auf jeder Seite gab es mehr als
200 Anfragen .
Die Lösung auf diese Weise war sehr einfach, es war nicht erforderlich, etwas neu zu schreiben: fordern Sie einfach nicht die gleichen Informationen erneut an.
if ( !isDefined("REQUEST.currentClass") ) { var classes = new api.private.classes.base(); REQUEST.currentClass = classes.getCurrentClass(); } return REQUEST.currentClass;
Ich war sehr glücklich, denn ich entschied, dass ich erst am dritten Tag das Hauptproblem fand. Da ich naiv war, war dies nur eines von vielen Problemen.
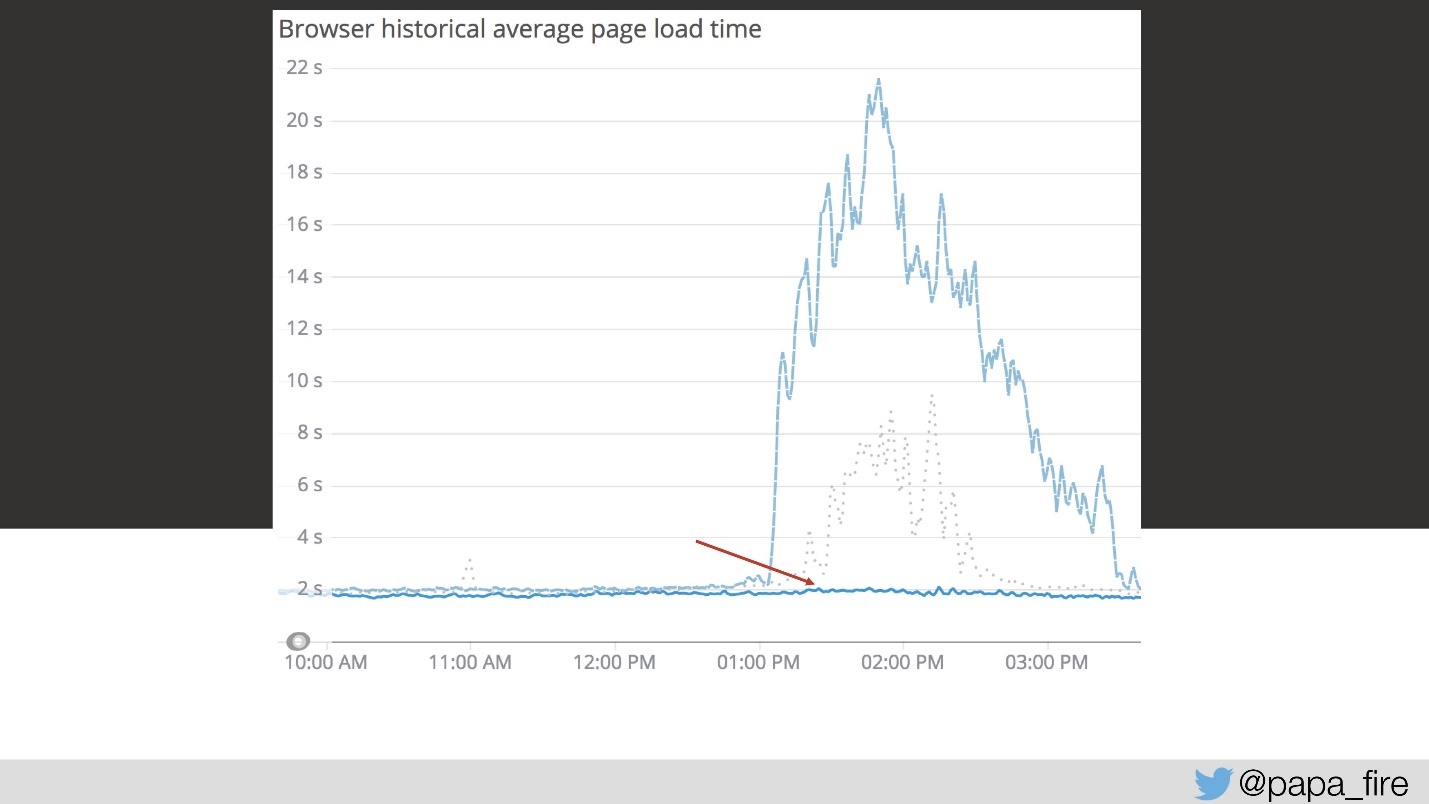
Die Lösung dieses ersten Problems senkte den Zeitplan jedoch erheblich.
Gleichzeitig haben wir weitere Optimierungen vorgenommen. In Sichtweite war eine Menge von allem, was repariert werden kann. Am selben dritten Tag stellte ich beispielsweise fest, dass sich noch ein Cache im System befindet (zunächst dachte ich, dass alle Anforderungen direkt aus der Datenbank stammen). Wenn ich an einen Cache denke, stelle ich den Standard Redis oder Memcached vor. Das habe ich aber nur gedacht, weil für das Caching auf diesem System MongoDB und SQL Server verwendet wurden - derselbe, von dem die Daten gerade gelesen wurden.
Tag zehn
In der ersten Woche hatte ich es mit Problemen zu tun, die gerade gelöst werden mussten. Irgendwann in der zweiten Woche bin ich zum ersten Mal aufgestanden, um mit dem Team zu sprechen und zu sehen, was passiert und wie der gesamte Prozess abläuft.
Wieder wurde eine interessante Sache entdeckt. Das Team bestand aus: 18 Entwicklern; 8 Tester; 3 Manager; 2 Architekten. Und alle nahmen an gemeinsamen Ritualen teil, das heißt, mehr als 30 Menschen kamen jeden Morgen zum Aufstehen und erzählten, was sie taten. Es ist klar, dass das Meeting nicht 5 oder 15 Minuten gedauert hat. Niemand hat jemandem zugehört, weil jeder auf verschiedenen Systemen arbeitet. In dieser Form waren bereits 2-3 Tickets pro Stunde beim Putzen ein gutes Ergebnis.
Als erstes haben wir das Team entlang der Produktlinie in mehrere aufgeteilt. Für verschiedene Bereiche und Systeme haben wir separate Teams ermittelt, zu denen Entwickler, Tester, Produktmanager und Geschäftsanalysten gehörten.
Als Ergebnis erhielten wir:
- Reduzierung von Stand-Ups und Rallyes.
- Produktwissen.
- Ein Gefühl der Eigenverantwortung. Bevor die Leute immer über Systeme sprachen, wussten sie, dass wahrscheinlich jemand anderes mit ihren Fehlern arbeiten musste, aber nicht sich selbst.
- Zusammenarbeit zwischen Gruppen. Man kann nicht sagen, dass die Qualitätssicherung vorher nicht viel mit Programmierern kommuniziert hat, das Produkt hat sein eigenes Ding gemacht usw. Jetzt haben sie einen gemeinsamen Verantwortungsbereich.
Wir haben uns hauptsächlich auf Effizienz, Produktivität und Qualität konzentriert - das sind die Probleme, die wir durch Teamtransformation lösen wollten.
Elfter Tag
Während ich die Struktur des Teams änderte, entdeckte ich, wie
Story Points gezählt werden. 1 SP entsprach einem Tag, und jedes Ticket enthielt sowohl SP für die Entwicklung als auch für die Qualitätssicherung, dh mindestens 2 SP.
Wie habe ich das gefunden?
Fehler gefunden: In einem der Berichte, in dem das Start- und Enddatum des Zeitraums eingegeben wird, für den der Bericht benötigt wird, wird der letzte Tag nicht berücksichtigt. Das heißt, irgendwo in der Anfrage war nicht <=, sondern einfach <. Mir wurde gesagt, dass dies drei Story Points sind, das heißt
3 Tage .
Danach haben wir:
- Das Story Points-Bewertungssystem wurde überarbeitet. Das Beheben kleinerer Fehler, die schnell durch das System geleitet werden können, erreicht den Benutzer jetzt schnell.
- Wir fingen an, verwandte Tickets für Entwicklung und Test zu kombinieren. Bisher war jedes Ticket, jeder Fehler ein geschlossenes Ökosystem, das mit nichts anderem verbunden war. Das Ändern von drei Schaltflächen auf einer Seite kann drei verschiedene Tickets mit drei verschiedenen QA-Prozessen anstelle eines automatischen Tests auf einer Seite sein.
- Sie begannen mit Entwicklern an einem Ansatz zur Bewertung der Arbeitskosten zu arbeiten. Drei Tage, um eine Taste zu ändern, ist nicht lustig.
Zwanzigster Tag
Irgendwann Mitte des ersten Monats hatte sich die Situation ein wenig stabilisiert, ich fand heraus, was hauptsächlich geschah, und begann bereits, in die Zukunft zu schauen und über langfristige Lösungen nachzudenken.
Langfristige Ziele:
- Verwaltete Plattform Hunderte von Anfragen auf jeder Seite - das ist nicht ernst.
- Vorhersehbare Trends. Es gab periodische Verkehrsspitzen, die auf den ersten Blick nicht mit anderen Metriken korrelierten. Man musste verstehen, warum dies geschieht, und lernen, Vorhersagen zu treffen.
- Plattformerweiterung. Das Geschäft wächst stetig, es kommen immer mehr Nutzer, der Verkehr nimmt zu.
In der Vergangenheit wurde oft gesagt: "Lasst uns alles in [Sprache / Framework] umschreiben, alles wird besser funktionieren!"
In den meisten Fällen funktioniert dies nicht, wenn die neu geschriebene überhaupt funktioniert. Daher mussten wir eine Roadmap erstellen - eine konkrete Strategie, die Schritt für Schritt veranschaulicht, wie die Geschäftsziele erreicht werden (was wir tun und warum), die:
- spiegelt die Mission und Ziele des Projekts wider;
- priorisiert wichtige Ziele;
- enthält einen Zeitplan für ihre Leistung.
Zuvor hatte niemand mit dem Team darüber gesprochen, zu welchem Zweck Änderungen vorgenommen wurden. Dies setzt die richtigen Erfolgsquoten voraus. Zum ersten Mal in der Unternehmensgeschichte haben wir einen KPI für eine technische Gruppe festgelegt, und diese Indikatoren waren an organisatorische gebunden.
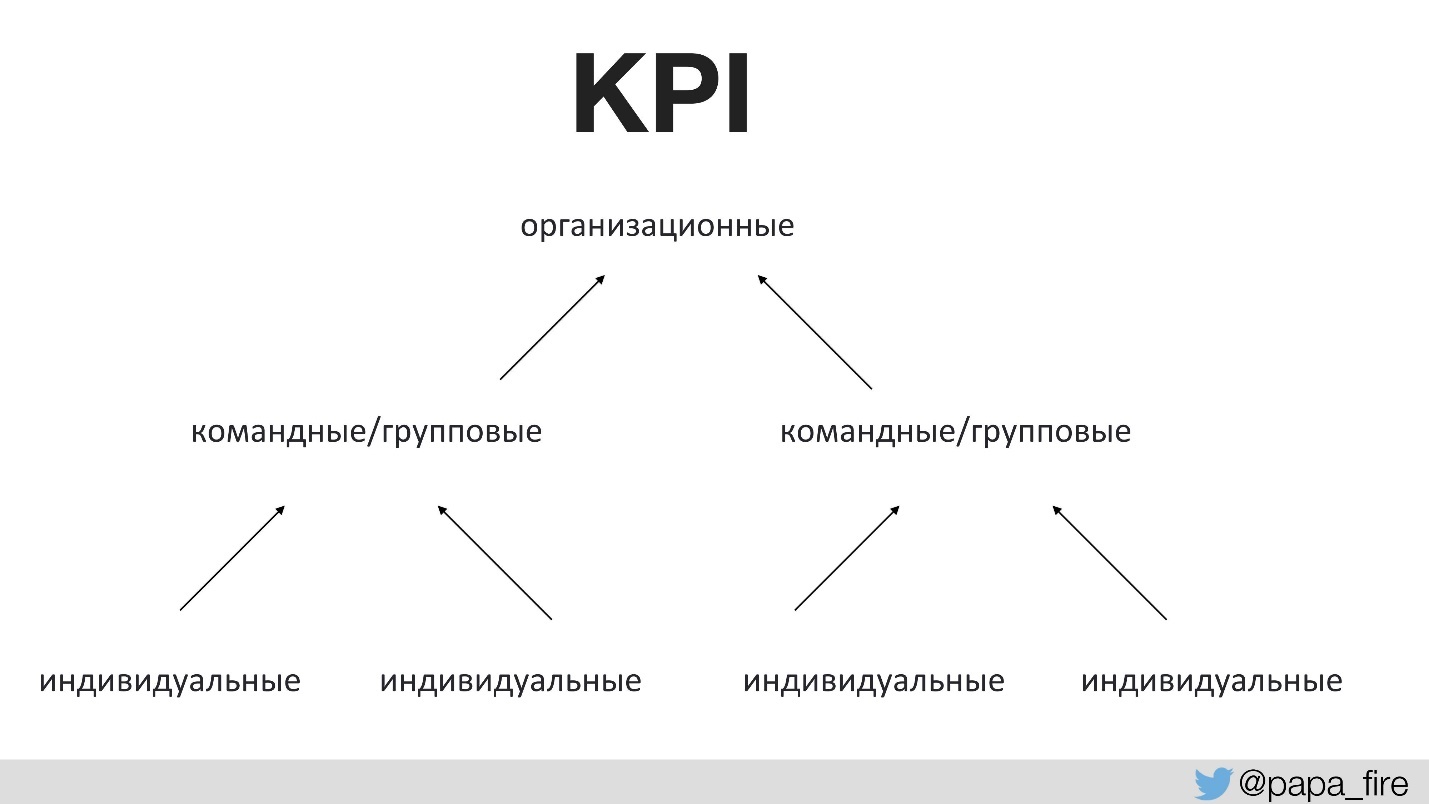
Das heißt, Organisations-KPIs werden von Teams unterstützt, und Team-KPIs werden bereits von einzelnen unterstützt. Ansonsten, wenn die technologischen KPIs nicht mit den organisatorischen übereinstimmen, zieht jeder die Decke über sich.
Eine der organisatorischen Kennzahlen ist beispielsweise die Steigerung des Marktanteils durch neue Produkte.
Wie können Sie das Ziel unterstützen, mehr neue Produkte zu haben?
- Erstens möchten wir mehr Zeit mit der Entwicklung neuer Produkte verbringen, anstatt Fehler zu beheben. Dies ist eine logische Lösung, die einfach zu messen ist.
- Zum anderen wollen wir eine Steigerung des Transaktionsvolumens unterstützen, denn je größer der Marktanteil, desto mehr Nutzer und dementsprechend mehr Verkehr.
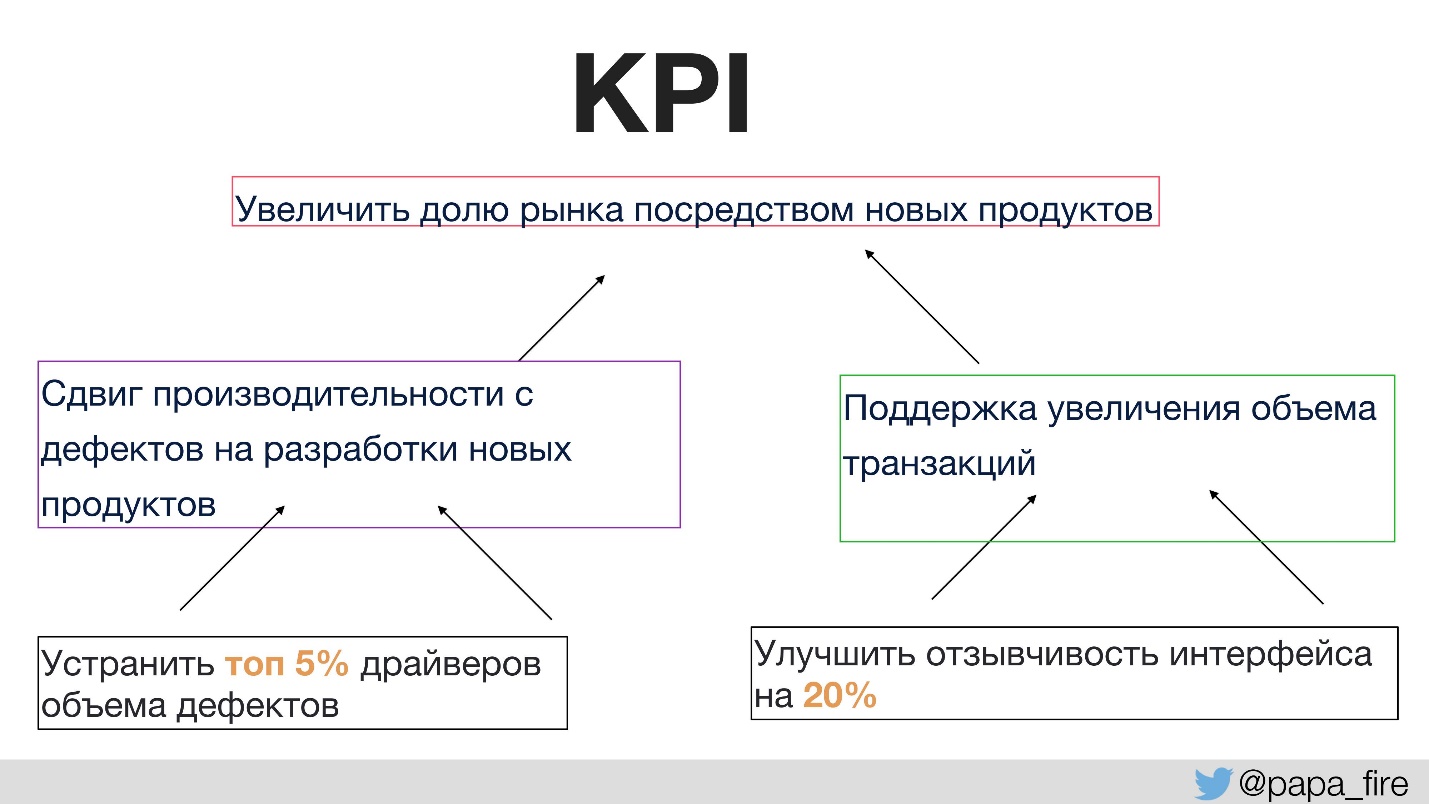
Dann befinden sich die einzelnen KPIs, die innerhalb der Gruppe ausgeführt werden können, beispielsweise dort, wo die Hauptmängel herkommen. Wenn Sie sich auf diesen bestimmten Abschnitt konzentrieren, können Sie die Anzahl der Fehler erheblich verringern und dann die Zeit für die Entwicklung neuer Produkte und die Unterstützung von Unternehmens-KPIs verlängern.
Daher sollte jede Entscheidung, einschließlich der Neufassung des Codes, die spezifischen Ziele unterstützen, die sich das Unternehmen für uns gesetzt hat (Wachstum der Organisation, neue Funktionen, Rekrutierung).
Während dieses Prozesses entstand eine interessante Sache, die nicht nur für Technikfreaks, sondern allgemein für das Unternehmen zu einer Neuigkeit wurde: Alle Tickets sollten sich auf mindestens einen KPI konzentrieren. Das heißt, wenn das Produkt angibt, dass es eine neue Funktion erstellen möchte, sollte die erste Frage gestellt werden: "Welchen KPI unterstützt diese Funktion?"
Dreißigster Tag
Ende des Monats entdeckte ich eine weitere Nuance, die keiner meiner Ops-Mitarbeiter jemals mit den Verträgen gesehen hatte, die wir mit Kunden abschließen. Möglicherweise fragen Sie, warum Kontakte angezeigt werden sollen.
- Erstens, weil SLAs in Verträgen registriert sind.
- Zweitens sind SLAs alle unterschiedlich. Jeder Kunde kam mit seinen Anforderungen und die Verkaufsabteilung unterschrieb ohne hinzusehen.
Eine weitere interessante Nuance: Im Vertrag mit einem der größten Kunden steht, dass alle von der Plattform unterstützten Softwareversionen n-1 sein müssen, dh nicht die neueste, sondern die vorletzte Version.
Es ist klar, wie weit wir von n-1 entfernt waren, wenn die Plattform auf ColdFusion und SQL Server 2008 war, die im Juli überhaupt nicht mehr unterstützt wurden.
Fünfundvierzigster Tag
Irgendwann in der Mitte des zweiten Monats hatte ich genug Zeit, um mich hinzusetzen und ein
Wertstrom- Mapping für den gesamten Prozess durchzuführen. Dies sind die notwendigen Schritte, von der Erstellung des Produkts bis zur Auslieferung an den Verbraucher, und Sie müssen sie so detailliert wie möglich bemalen.
Sie zerlegen den Prozess in kleine Stücke und sehen, was zu viel Zeit in Anspruch nimmt, was optimiert, verbessert usw. werden kann. Zum Beispiel, wie lange dauert es, bis die Anfrage vom Produkt, die die Pflege durchläuft, das Ticket erreicht, das der Entwickler in Anspruch nehmen kann, die Qualitätssicherung usw. Sie betrachten jeden einzelnen Schritt im Detail und glauben, dass Sie optimieren können.
Dabei sind mir zwei Dinge aufgefallen:
- Hoher Prozentsatz von Rückflugtickets von der Qualitätssicherung zurück an Entwickler;
- Die Überprüfung der Pull-Anforderung hat zu lange gedauert.
Das Problem war, dass dies Schlussfolgerungen waren wie: Es scheint viel Zeit in Anspruch zu nehmen, aber wir sind uns nicht sicher, wie viel.
"Es ist unmöglich zu verbessern, was nicht gemessen werden kann."
Wie kann man belegen, wie ernst das Problem ist? Verbringt es Tage oder Stunden?
Um dies zu messen, haben wir dem Jira-Prozess ein paar Schritte hinzugefügt: "Bereit für Entwickler" und "Bereit für Qualitätssicherung", um zu messen, wie lange jedes Ticket wartet und wie oft es zu einem bestimmten Schritt zurückkehrt.
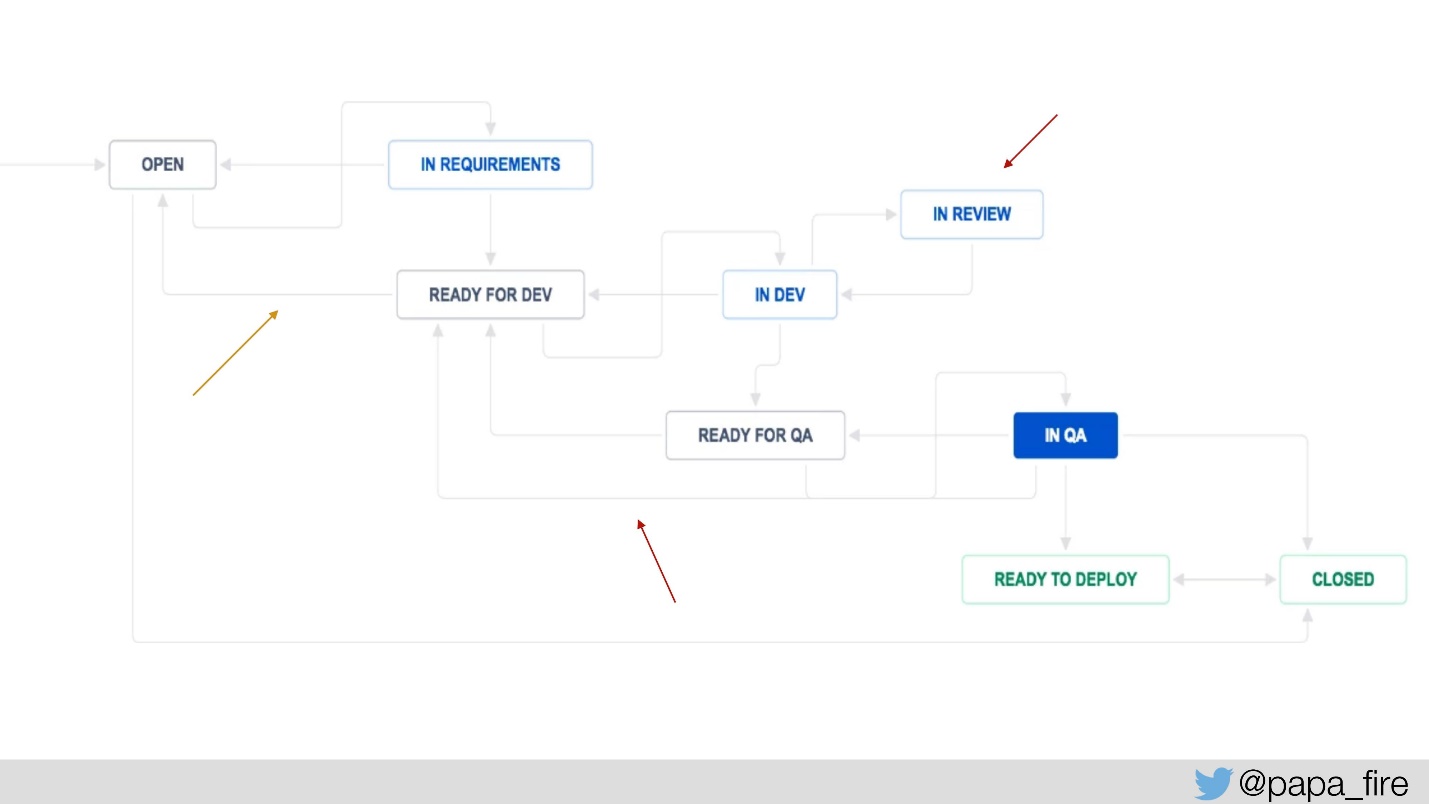
Wir haben auch "In Review" hinzugefügt, um zu erfahren, wie viele Tickets im Durchschnitt geprüft werden. Deshalb tanzen sie bereits. Wir hatten Systemmetriken, jetzt fügten wir neue Metriken hinzu und begannen zu messen:
- Prozesseffizienz: Leistung und geplant / geliefert.
- Prozessqualität: Anzahl der Mängel, Mängel aus der Qualitätssicherung .
Es hilft wirklich zu verstehen, was gut läuft und was schlecht ist.
Fünfzigster Tag
Das ist natürlich alles gut und interessant, aber gegen Ende des zweiten Monats passierte etwas, das im Prinzip vorhersehbar war, obwohl ich nicht mit einem solchen Ausmaß gerechnet hatte. Die Leute begannen zu gehen, weil sich die Spitze geändert hat. Es kamen neue Leute zur Führung, die begannen, alles zu ändern, und die alten gaben auf. Und normalerweise kennen sich in einer Firma, die mehrere Jahre alt ist, alle Freunde und alle.
Dies wurde erwartet, aber das Ausmaß der Entlassungen war unerwartet. Zum Beispiel haben in einer Woche zwei Teamleiter gleichzeitig ihre Entlassung beantragt. Deshalb musste ich andere Probleme nicht vergessen, sondern mich darauf konzentrieren
, ein Team zu bilden . Dies ist ein langwieriges und schwieriges Problem, aber sie musste sich damit befassen, weil sie die Menschen retten wollte, die geblieben waren (oder die meisten von ihnen). Man musste irgendwie auf die Tatsache reagieren, dass Leute gegangen sind, um die Moral im Team aufrechtzuerhalten.
Theoretisch ist das gut so: Es kommt eine neue Person mit einer vollständigen Carte Blanche, die die Teamfähigkeit beurteilen und das Personal ersetzen kann. Tatsächlich kann man aus so vielen Gründen nicht einfach neue Leute mitbringen.
Benötigen Sie immer ein Gleichgewicht.- Alt und neu. Wir müssen alte Menschen behalten, die sich verändern und die Mission unterstützen können. Gleichzeitig müssen wir aber neues Blut einbringen, worüber wir später sprechen werden.
- Erfahrung Ich habe viel mit guten Jugendlichen gesprochen, die verbrannt waren und für uns arbeiten wollten. Aber ich konnte sie nicht ertragen, weil es nicht genug Herren gab, die die Junioren unterstützen und für sie Mentoren sein würden. Zuerst war es notwendig, die Spitze und erst dann die Jugend zu gewinnen.
- Karotte und Peitsche.
Ich habe keine gute Antwort auf die Frage, was für ein Gleichgewicht richtig ist, wie man es aufrechterhält, wie viele Menschen abreisen und wie viel man drängt. Dies ist ein rein individueller Prozess.
Erster Tag fünfzig
Ich sah mir das Team genau an, um zu verstehen, wen ich habe, und erinnerte mich noch einmal:
"Die meisten Probleme sind Probleme mit Menschen."
Ich habe festgestellt, dass das Team als solches - sowohl die Entwickler als auch Ops - drei große Probleme hat:
- Zufriedenheit mit dem aktuellen Stand der Dinge.
- Mangel an Verantwortung - weil noch nie jemand die Ergebnisse der Arbeit der ausübenden Künstler eingebracht hat, um das Geschäft zu beeinflussen.
- Angst vor Veränderung.

Veränderungen bringen Sie immer aus Ihrer Komfortzone heraus, und je jünger die Menschen sind, desto weniger mögen sie Veränderungen, weil sie nicht verstehen, warum und wie. Die häufigste Antwort, die ich hörte, war: "Das haben wir nie gemacht." Und es kam zum Punkt der völligen Absurdität - die kleinsten Veränderungen gingen nicht vorüber, ohne dass jemand empört war. Und es spielt keine Rolle, wie sehr die Veränderungen ihre Arbeit betrafen, sagten die Leute: "Nein, warum? Es wird nicht funktionieren. "
Aber Sie können nicht besser werden, ohne etwas zu ändern.
Ich hatte ein absolut absurdes Gespräch mit einem Mitarbeiter, ich erzählte ihm meine Optimierungsideen, zu denen er mir sagte:
- Ah, du hast nicht gesehen, was wir letztes Jahr hatten!
- Na und?
"Jetzt viel besser als es war."
"Also könnte es nicht besser sein?"
- Und warum?Gute Frage - warum? Als ob, wenn es jetzt besser ist als früher, dann ist alles gut genug. Dies führt zu einer grundsätzlichen Verantwortungslosigkeit. Wie gesagt, das technische Team war etwas distanziert. Das Unternehmen war der Meinung, dass dies der Fall sein sollte, aber
niemand hat jemals Maßstäbe gesetzt . Sie haben SLA nie im technischen Support gesehen, daher war es für die Gruppe ziemlich "akzeptabel" (und es hat mich am meisten beeindruckt):
- 12 Sekunden herunterladen;
- 5-10 Minuten Ausfallzeit pro Release;
- Kritische Fehlerbehebung dauert Tage und Wochen.
- Dienstausfall 24x7 / Rufbereitschaft.
Niemand hat jemals versucht zu fragen, warum wir es nicht besser machen sollten, und niemand hat jemals gemerkt, dass es nicht sein sollte.
Als Bonus gab es ein weiteres Problem:
mangelnde Erfahrung . Die Senioren gingen, und die verbleibende junge Mannschaft wuchs unter dem vorherigen Regime und wurde dadurch vergiftet.
Zu alledem hatten die Menschen auch Angst zu versagen, inkompetent zu wirken. Dies drückt sich darin aus, dass sie erstens
unter keinen Umständen um Hilfe gebeten haben . Wie oft haben wir in einer Gruppe und einzeln gesprochen und ich sagte: "Stellen Sie eine Frage, wenn Sie nicht wissen, wie Sie etwas tun sollen." Ich bin zuversichtlich und weiß, dass ich jedes Problem lösen kann, aber es wird einige Zeit dauern. Wenn Sie jemanden fragen können, der weiß, wie man es in 10 Minuten löst, werde ich Sie darum bitten. Je weniger Erfahrung Sie haben, desto mehr haben Sie Angst, Fragen zu stellen, weil Sie denken, dass Sie als inkompetent gelten.
Diese Angst, eine Frage zu stellen, manifestiert sich in interessanten Formen. Zum Beispiel fragen Sie: "Wie geht es Ihnen mit dieser Aufgabe?" - "Es sind noch ein paar Stunden, ich bin bereits fertig." Wenn Sie am nächsten Tag noch einmal nachfragen, erhalten Sie die Antwort, dass alles in Ordnung ist, aber es gab ein Problem, es wird am Ende des Tages fertig sein. Ein weiterer Tag vergeht, und bis Sie sich gegen die Wand drücken und jemanden zum Reden zwingen, geht alles weiter. Eine Person möchte das Problem selbst lösen und glaubt, dass es ein großer Misserfolg sein wird, wenn sie es nicht löst.
Deshalb haben die
Entwickler überbewertet . Es war dieser Witz, als sie über eine bestimmte Aufgabe diskutierten, sie gaben mir eine solche Zahl, dass ich sehr überrascht war. Zu der mir gesagt wurde, dass der Entwickler in Schätzungen die Zeit angibt, zu der das Ticket von der Qualitätssicherung zurückgegeben wird, weil sie dort Fehler finden, und die Zeit, die PR benötigt, und die Zeit, die Leute, die es anzeigen müssen, beschäftigt sind - das ist alles das ist nur möglich.
Zweitens
analysieren Menschen, die Angst haben, inkompetent zu sein,
unnötigerweise . Wenn Sie sagen, was genau getan werden muss, beginnt es: „Nein, aber was ist, wenn wir hier nachdenken?“ In diesem Sinne ist unser Unternehmen nicht einzigartig, es ist ein Standardproblem für Jugendliche.
Als Antwort habe ich die folgenden Praktiken eingeführt:
- Die Regel ist 30 Minuten. Wenn Sie das Problem in einer halben Stunde nicht lösen können, bitten Sie jemanden um Hilfe. Dies funktioniert mit unterschiedlichem Erfolg, weil die Leute immer noch nicht fragen, aber zumindest der Prozess hat begonnen.
- Schließen Sie alles außer der Essenz aus , um die Dauer der Aufgabe abzuschätzen. Berücksichtigen Sie also nur, wie lange es dauert, den Code zu schreiben.
- Weiterbildung für all jene, die übermäßig analysieren. Es ist nur eine ständige Arbeit mit Menschen.
Sechzigster Tag
Während ich das alles tat, ist es Zeit, das Budget herauszufinden. Natürlich habe ich viele interessante Dinge gefunden, in denen wir das Geld ausgegeben haben. Zum Beispiel hatten wir ein ganzes Rack in einem separaten Rechenzentrum, auf dem sich ein FTP-Server befand, der von einem Client verwendet wurde. Es stellte sich heraus, dass "... wir umgezogen sind, aber er blieb, wir haben ihn nicht geändert." Das war vor 2 Jahren.
Von besonderem Interesse war die Cloud-Service-Rechnung. Ich bin sicher, dass der Hauptgrund für die hohe Rechnung für Cloud-Dienste Entwickler sind, die zum ersten Mal in ihrem Leben uneingeschränkten Zugriff auf Server haben. Sie müssen nicht fragen: "Bitte gib mir einen Testserver", können sie nehmen. Außerdem wollen Entwickler immer ein so cooles System bauen, dass Facebook mit Netflix beneidet.
Die Entwickler haben jedoch keine Erfahrung mit dem Kauf von Servern und der Möglichkeit, die richtige Servergröße zu ermitteln, da sie diese zuvor nicht benötigt haben. Und normalerweise verstehen sie den Unterschied zwischen Skalierbarkeit und Leistung nicht vollständig.
Inventar-Ergebnisse:
- Wir haben ein Rechenzentrum verlassen.
- Kündigte den Vertrag mit 3 Protokolldiensten. Weil wir fünf hatten - jeder Entwickler, der anfing, mit etwas zu spielen, nahm einen neuen.
- 7 AWS-Systeme ausgeschaltet. Wieder stoppte niemand die toten Projekte, sie alle arbeiteten weiter.
- Reduzierte Softwarekosten um das 6-fache.
Fünfundsiebzigster Tag
Die Zeit verging und nach zweieinhalb Monaten musste ich mich mit dem Vorstand treffen. Unser Verwaltungsrat ist nicht besser und nicht schlechter als andere, er will wie alle Verwaltungsräte alles wissen. Die Leute investieren Geld und wollen verstehen, wie viel unsere Arbeit in die festgelegten KPIs passt.
Das Board erhält jeden Monat viele Informationen: die Anzahl der Benutzer, deren Wachstum, welche Dienste sie wie nutzen, Produktivität und Produktivität und schließlich die durchschnittliche Seitenladegeschwindigkeit.
Das einzige Problem ist, dass ich glaube, dass der Durchschnittswert rein böse ist. Aber der Verwaltungsrat ist sehr schwer zu erklären. Sie sind es gewohnt, mit aggregierten Zahlen zu arbeiten, und nicht zum Beispiel durch die Streuung der Ladezeit pro Sekunde.
In dieser Hinsicht gab es interessante Punkte. Ich habe zum Beispiel gesagt, dass Sie den Datenverkehr je nach Art des Inhalts auf einzelne Webserver aufteilen müssen.

Das heißt, ColdFusion durchsucht Jetty und Nginx und startet Seiten. Und Bilder, JS und CSS durchlaufen eine separate Nginx mit ihren eigenen Konfigurationen. Dies ist eine ziemlich übliche Praxis, die ich
vor ein paar Jahren geschrieben habe. , … 200 .
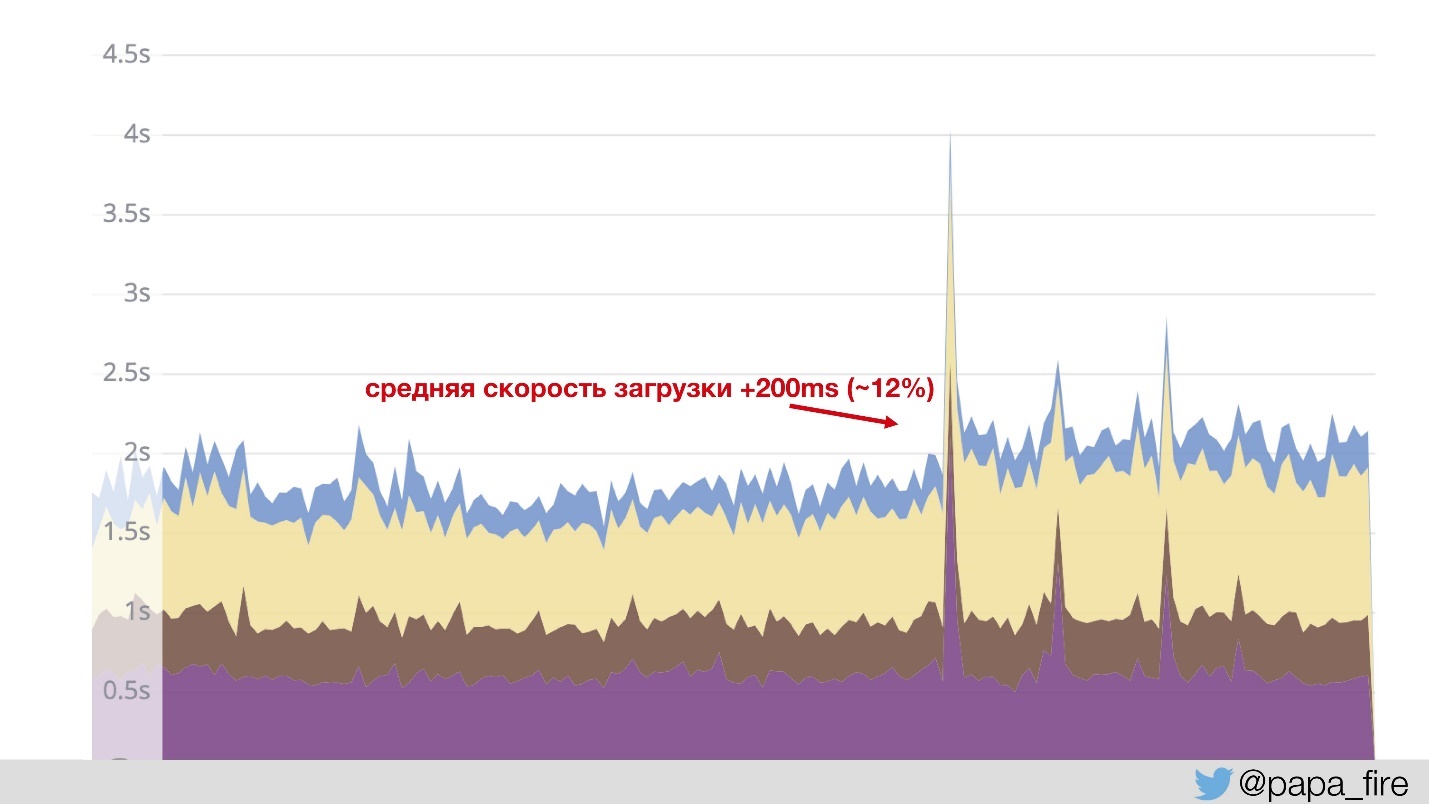
, , Jetty. — . , , , - 12%?
, — . , , .

— , . . - , .
Fazit
. , , , . , ,
SEQUENCE .
nextID , .
, . , , — .

. , :
.
twitter ,
facebook medium .
legacy : , . c DevOpsConf , . youtube , , DevOps.