
Wir werden was wir sehen. Zuerst formen wir die Werkzeuge, dann formen uns die Werkzeuge.
- Marschall McLuhan
Ich möchte meinem guten Freund Ricardo Sueiras für seine Rezension, seinen Beitrag und dafür, dass ich diesen Artikel nicht unvollendet lassen durfte, aufrichtig danken und meinen Dank aussprechen . Ricardo, du bist nur eine Legende!
Es ist wichtig, sich daran zu erinnern, dass Chaos Engineering nicht stattfindet, wenn Sie Affen freigeben und willkürlich Fehler eingeben. Chaos Engineering ist eine gut definierte, formalisierte Experimentiertechnik.
"Chaos Engineering beinhaltet sorgfältige Beobachtung, strenge Skepsis in Bezug auf den Beobachtungsgegenstand, weil kognitive Annahmen die Interpretation der Ergebnisse verzerren. Diese Technik beinhaltet die Formulierung von Hypothesen durch Induktion basierend auf ähnlichen Beobachtungen; experimentelle und messungsbasierte Prüfung von Schlussfolgerungen aus ähnlichen Hypothesen; Anpassung." oder Ablehnung von Hypothesen basierend auf experimentellen Ergebnissen
- Wikipedia
Das Chaos Engineering beginnt mit dem Verständnis des stabilen Zustands des Systems, mit dem Sie sich befassen, und formuliert dann eine Hypothese und schließlich ein Experiment, das dies bestätigt und dabei hilft, den Sicherheitsspielraum des Systems zu erhöhen.
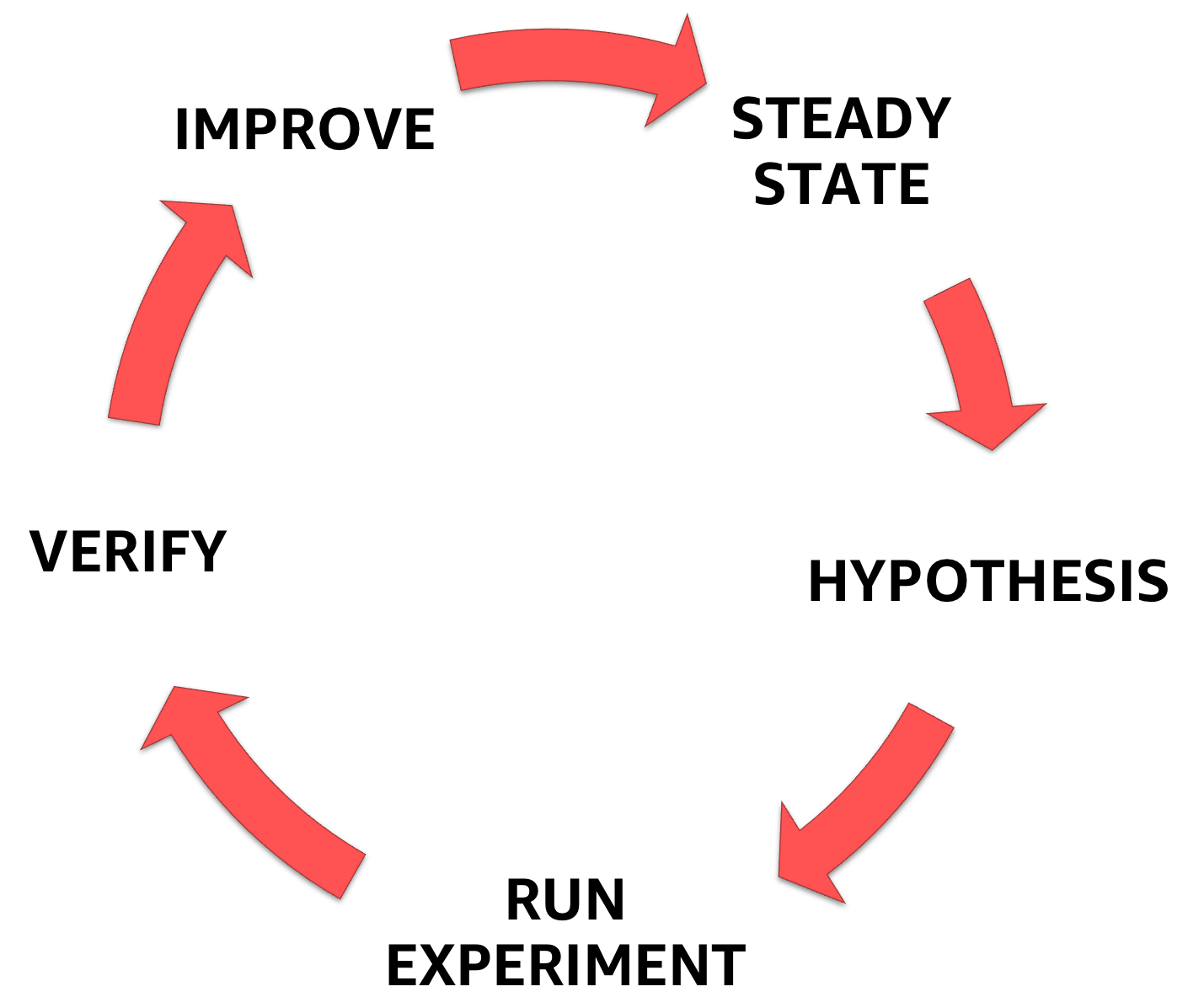
Chaos Engineering-Phasen
Im ersten Teil einer Artikelserie habe ich das Chaos Engineering vorgestellt und jeden Schritt der oben beschriebenen Methodik besprochen.
Im zweiten Teil habe ich die Bereiche untersucht, in die Sie investieren müssen, wenn Sie Experimente zur Chaostechnik entwerfen, und wie Sie die richtigen Hypothesen auswählen.
In diesem dritten Teil werde ich mich auf das Experiment selbst konzentrieren und eine Auswahl von Werkzeugen und Methoden vorstellen, die ein breites Spektrum von Fehlern abdecken.
Die Liste ist nicht erschöpfend, aber zunächst einmal sollte es genug sein, um zum Nachdenken anzuregen.
Einführung des Scheiterns - was ist es und wofür ist es?
Mit Failure wird überprüft, ob das Systemverhalten unter normalen Lastbedingungen den Spezifikationen entspricht. Zum ersten Mal wurde diese Technik angewendet, wenn Fehler auf der Ebene des Eisens - auf der Ebene der Kontakte - durch Ändern der elektrischen Signale an den Geräten verursacht wurden.
Bei der Programmierung trägt die Einführung von Fehlern dazu bei, die Stabilität des Softwaresystems zu verbessern, und ermöglicht es Ihnen, Mängel in der Beständigkeit gegen potenzielle Fehler im System zu korrigieren. Dies wird als Fehlerbehebung bezeichnet. Dies hilft auch bei der Beurteilung des Schadens durch einen Ausfall - d. H. Schadensradius, noch bevor ein Ausfall in der Produktionsumgebung eintritt. Dies wird als Fehlervorhersage bezeichnet.
Die Einführung von Fehlern hat mehrere wichtige Vorteile:
- Verstehen und üben Sie Reaktionen auf Unfälle und Zwischenfälle.
- Verstehen Sie die Auswirkungen von echten Fehlern.
- die Wirksamkeit und die Grenzen von Fehlertoleranzmechanismen verstehen.
- Beseitigen Sie Konstruktionsfehler und erkennen Sie häufige Fehlerquellen.
- Systembeobachtbarkeit verstehen und verbessern.
- Verstehen Sie den Radius des Scheiterns und schränken Sie ihn ein.
- die Ausbreitung von Fehlern zwischen Systemkomponenten verstehen.
Fehlerkategorien
Es gibt 5 Kategorien für die Einführung von Fehlern: auf der Ebene von (1) Ressourcen; (2) Netzwerk und Abhängigkeiten; (3) Anwendung, Prozess und Service; (4) Infrastruktur; und (5) die menschliche Ebene **.
Als nächstes werde ich jede der Kategorien untersuchen und ein Beispiel für die Einführung von Fehlern für jede von ihnen geben. Ich werde auch ein Beispiel für die Einführung von Ausfällen und All-in-One-Orchestrierungsinstrumenten betrachten.
** Wichtig! In diesem Beitrag werde ich nicht auf die Einführung von Fehlern auf menschlicher Ebene eingehen, sondern im Folgenden darauf eingehen.
1 - Einführung von Fehlern auf Ressourcenebene, auch bekannt als Mangel an Ressourcen.
Ja, Cloud-Technologien haben uns gelehrt, dass die Ressourcen nahezu unbegrenzt sind, aber ich beeile mich, Sie zu enttäuschen: Sie sind nicht unendlich. Instanz, Container, Funktion usw. - Unabhängig von der Abstraktion enden die Ressourcen schließlich. Ein Überschreiten der zulässigen maximalen Ressourcenausschöpfung wird als Erschöpfung bezeichnet.

Ein Mangel an Ressourcen imitiert einen Denial-of-Service- Angriff, jedoch nicht den üblichen, um den beabsichtigten Server zu infiltrieren. Diese Einführung von Fehlern ist wahrscheinlich weit verbreitet, da es wahrscheinlich nicht schwierig ist, sie zu verwenden.
Verbrauchen von CPU-, Speicher- und E / A-Ressourcen
Eines meiner Lieblingswerkzeuge ist Stress-ng, die Entsprechung zum ursprünglichen Stresstest-Tool von Amos Waterland .
Mit Stress-ng können Fehler durch Laden verschiedener physischer Subsysteme des Computers sowie durch Steuern der Schnittstellen des Systemkerns mithilfe von Stresstests eingegeben werden. Die folgenden Belastungstests sind verfügbar: CPU, CPU-Cache, Gerät, E / A, Interrupt, Dateisystem, Speicher, Netzwerk, Betriebssystem, Pipeline, Scheduler und VM. Die Manpages enthalten eine vollständige Beschreibung aller verfügbaren Stresstests, von denen es nur 220 gibt!
Im Folgenden finden Sie einige praktische Beispiele für die Verwendung von Stress:
Die Last auf dem CPU- matrixprod bietet die richtige Mischung aus Operationen mit Speicher, Cache und Gleitkomma. Das vielleicht. Der beste Weg, um die CPU gut aufzuwärmen.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s
Die iomix-bytes Last schreibt N-Bytes für jeden iomix Handler- iomix . Die Standardeinstellung ist 1 GB und eignet sich ideal für die Durchführung eines E / A-Belastungstests. In diesem Beispiel lege ich 80% des freien Speicherplatzes im Dateisystem fest.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s
vm-bytes hervorragend für Speicher-Stresstests. In diesem Beispiel führt stress-ng 9 Stresstests des virtuellen Speichers durch, die zusammen 90% des verfügbaren Speichers pro Stunde verbrauchen. Somit verbraucht jeder Stresstest 10% des verfügbaren Speichers.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
Nicht genügend Speicherplatz auf den Festplatten
dd ist ein Befehlszeilenprogramm, das zum Konvertieren und Kopieren von Dateien kompiliert wurde. dd kann jedoch aus Dateien von speziellen Geräten wie /dev/zero und /dev/random lesen und / oder schreiben, um beispielsweise den Bootsektor einer Festplatte zu sichern und eine feste Menge zufälliger Daten abzurufen. Auf diese Weise können Fehler auf dem Server verursacht und ein Festplattenüberlauf simuliert werden. Haben Ihre Protokolldateien den Server überlaufen und die Anwendung gelöscht? Also, dd wird helfen - und es wird weh tun!
Gehen Sie mit dd sehr vorsichtig um. Geben Sie den falschen Befehl ein - und die Daten auf der Festplatte werden gelöscht, zerstört oder überschrieben!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
Anwendungs-API-Verlangsamung
Die Leistung, Ausfallsicherheit und Skalierbarkeit der API sind wichtig. APIs sind für die Erstellung von Anwendungen und das Wachstum Ihres Unternehmens von entscheidender Bedeutung.
Das Testen der Auslastung ist eine hervorragende Möglichkeit, um Ihre Anwendung zu testen, bevor sie in Produktion geht. Dies ist auch eine coole Methode zum Laden von Stress, da sie häufig Ausnahmen und Einschränkungen aufdeckt, die unter anderen Umständen unsichtbar geblieben wären, bevor sie auf echten Verkehr gestoßen wären.
wrk ist ein HTTP-Benchmarking-Tool, das die Systeme erheblich belastet. Ich teste API-Zugänglichkeitsüberprüfungen besonders gerne, insbesondere bei Leistungsüberprüfungen , da sie viele Aspekte in Bezug auf Entwurfsentscheidungen auf Entwicklercode-Ebene offenbaren: Wie ist der Cache konfiguriert? Wie wird das Tempolimit umgesetzt? Priorisiert das System Integritätsprüfungen in Bezug auf Load Balancer?
Hier ist, wo Sie anfangen sollen:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Dieser Befehl startet 12 Threads und hält 400 HTTP-Verbindungen 20 Sekunden lang offen.
2 - Einführung in Fehler und Abhängigkeiten auf Netzwerkebene
Peter Deutschs Buch The Eight Fallacies of Distributed Computing ist eine Sammlung von Annahmen, die Entwickler beim Entwurf verteilter Systeme treffen. Und dann fliegt die Antwort in Form von Unzugänglichkeit, und Sie müssen alles wiederholen. Diese falschen Annahmen sind:
- Das Netzwerk ist zuverlässig.
- Die Verzögerung ist 0.
- Die Bandbreite ist endlos.
- Das Netzwerk ist sicher.
- Die Topologie ändert sich nicht.
- Es gibt nur einen Administrator.
- Überweisungskosten 0.
- Das Netzwerk ist homogen.
Diese Liste ist ein guter Ausgangspunkt für die Auswahl eines Failovers, wenn Sie testen, ob Ihr verteiltes System mit Netzwerkfehlern umgehen kann.
Einführung von Netzwerklatenz, -verlust und -ausfall
Einführen von Netzwerklatenz, -verlust oder -unterbrechung
tc ( Traffic Control ) ist ein Linux-Befehlszeilentool, mit dem der Linux-Kernel-Batch-Scheduler konfiguriert wird. Es definiert, wie Pakete zum Senden und Empfangen in der Netzwerkschnittstelle in die Warteschlange gestellt werden. Zu den Vorgängen gehören das Einreihen in die Warteschlange, das Definieren von Richtlinien, das Klassifizieren, das Planen, das Formen und der Verlust.
tc kann verwendet werden, um Verzögerungen und Paketverluste für UDP- oder TCP-Anwendungen zu simulieren oder die Nutzung der Bandbreite eines bestimmten Dienstes zu begrenzen - um die Bedingungen des Internetverkehrs zu simulieren.
- Einführung einer Verzögerung von 100 ms
#Start ❯ tc qdisc add dev etho root netem delay 100ms #Stop ❯ tc qdisc del dev etho root netem delay 100ms
- Einführung einer Verzögerung von 100 ms mit einem Delta von 50 ms
#Start ❯ tc qdisc add dev eth0 root netem delay 100ms 50ms #Stop ❯ tc qdisc del dev eth0 root netem delay 100ms 50ms
- Beschädigung von 5% der Netzwerkpakete
#Start ❯ tc qdisc add dev eth0 root netem corrupt 5% #Stop ❯ tc qdisc del dev eth0 root netem corrupt 5%
- 7% Paketverlust bei einer Korrelation von 25%
#Start ❯ tc qdisc add dev eth0 root netem loss 7% 25% #Stop ❯ tc qdisc del dev eth0 root netem loss 7% 25%
Wichtig! 7% reichen aus, damit die TCP-Anwendung nicht gelöscht wird.
Spielen mit "/ etc / hosts" - eine statische Nachschlagetabelle für Hostnamen
/etc/hosts ist eine einfache Textdatei, die zeilenweise IP-Adressen mit Hostnamen verknüpft. Jeder Knoten benötigt eine Zeile mit folgenden Informationen:
IP_address canonical_hostname [aliases...]
Die Hosts-Datei ist eines von mehreren Systemen, die auf Netzwerkknoten in einem Computernetzwerk zugreifen und von Benutzern verstandene Hostnamen in IP-Adressen umwandeln. Und ja, Sie haben es erraten: Dank dessen ist es bequem, Computer zu betrügen. Hier einige Beispiele:
- Blockieren Sie den Zugriff auf die DynamoDB-API für die EC2-Instanz
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
- Blockieren Sie den Zugriff auf die EC2-API von einer EC2-Instanz
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
Live ec2 describe-instances : Erstens ist die EC2-API verfügbar und ec2 describe-instances erfolgreich zurückgegeben.
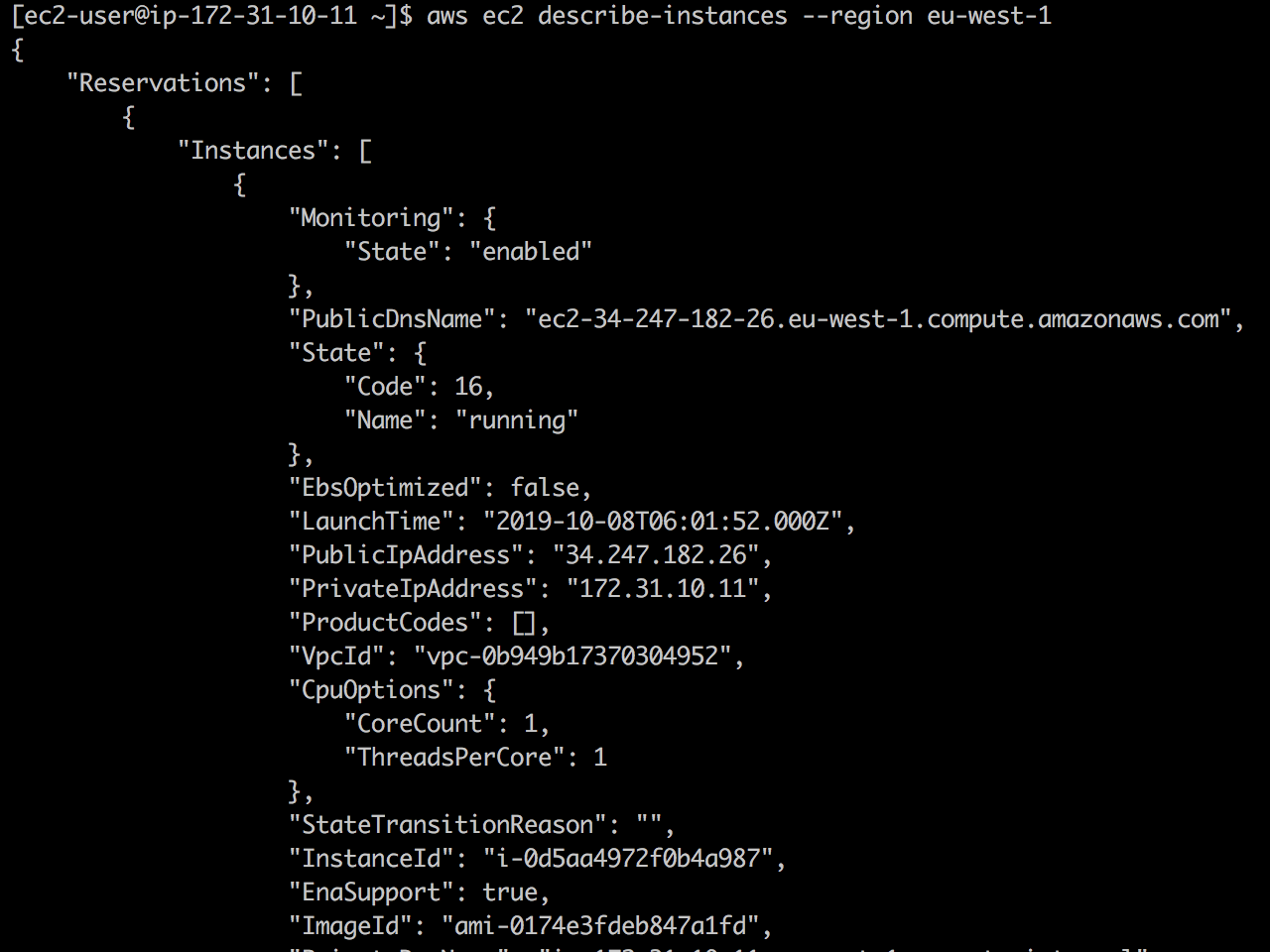
Sobald ich 127.0.01 ec2.eu-west-1.amazonaws.com zu /etc/hosts hinzugefügt 127.0.01 ec2.eu-west-1.amazonaws.com , wird der EC2-API-Aufruf beendet.

Dies funktioniert natürlich für alle AWS-APIs.
Ich würde dir einen Witz über DNS erzählen ...

... aber ich fürchte, es wird dich erst am zweiten Tag erreichen. Ich meine nach 24 Stunden.
Am 21. Oktober 2016 war aufgrund des DDoS-Dyn-Angriffs eine angemessene Anzahl von Plattformen und Diensten in Europa und Nordamerika nicht verfügbar. Laut dem ThousandEyes-Bericht zur weltweiten DNS-Leistung für 2018 verlassen sich 60% der Unternehmen und SaaS-Anbieter immer noch auf einen DNS-Anbieter aus einer Hand und sind daher anfällig für DNS-Ausfälle. Und da es ohne DNS kein Internet gibt, ist es großartig, einen DNS-Fehler zu simulieren, um Ihre Ausfallsicherheit für den nächsten DNS-Fehler zu bewerten.
Blackholing ist eine Methode, mit der sie traditionell den Schaden eines DDoS-Angriffs reduzieren. Schlechter Netzwerkverkehr wird zum Schwarzen Loch geleitet und für ungültig erklärt. Die Version von /dev/null für die Arbeit im Netzwerk :-) Mit ihr können Sie beispielsweise den Verlust des Netzwerkverkehrs oder das Protokoll desselben DNS simulieren.
Für diese Aufgabe benötigen Sie das Tool iptables , mit dem Sie das IP-Paket im Linux-Kernel konfigurieren, verwalten und überprüfen können.
Versuchen Sie Folgendes, um DNS-Datenverkehr über blackhole zu erhalten:
#Start ❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP #Stop ❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROP
Einführung von Fehlern mit Toxiproxy.
Linux-Tools wie tc und iptables ein - aber nicht das einzige - ernstes Problem. Sie benötigen Root-Berechtigungen, um ausgeführt zu werden. Dies führt bei einigen Organisationen und Umgebungen zu Problemen. Bitte Liebe und Gunst - Toxiproxy !
Toxiproxy ist ein Open-Source-TCP-Proxy, der vom Shopify- Entwicklerteam entwickelt wurde . Es hilft, chaotische Netzwerk- und Systembedingungen oder reale Systeme zu simulieren. Platzieren Sie es wie unten gezeigt zwischen den verschiedenen Komponenten der Architektur.
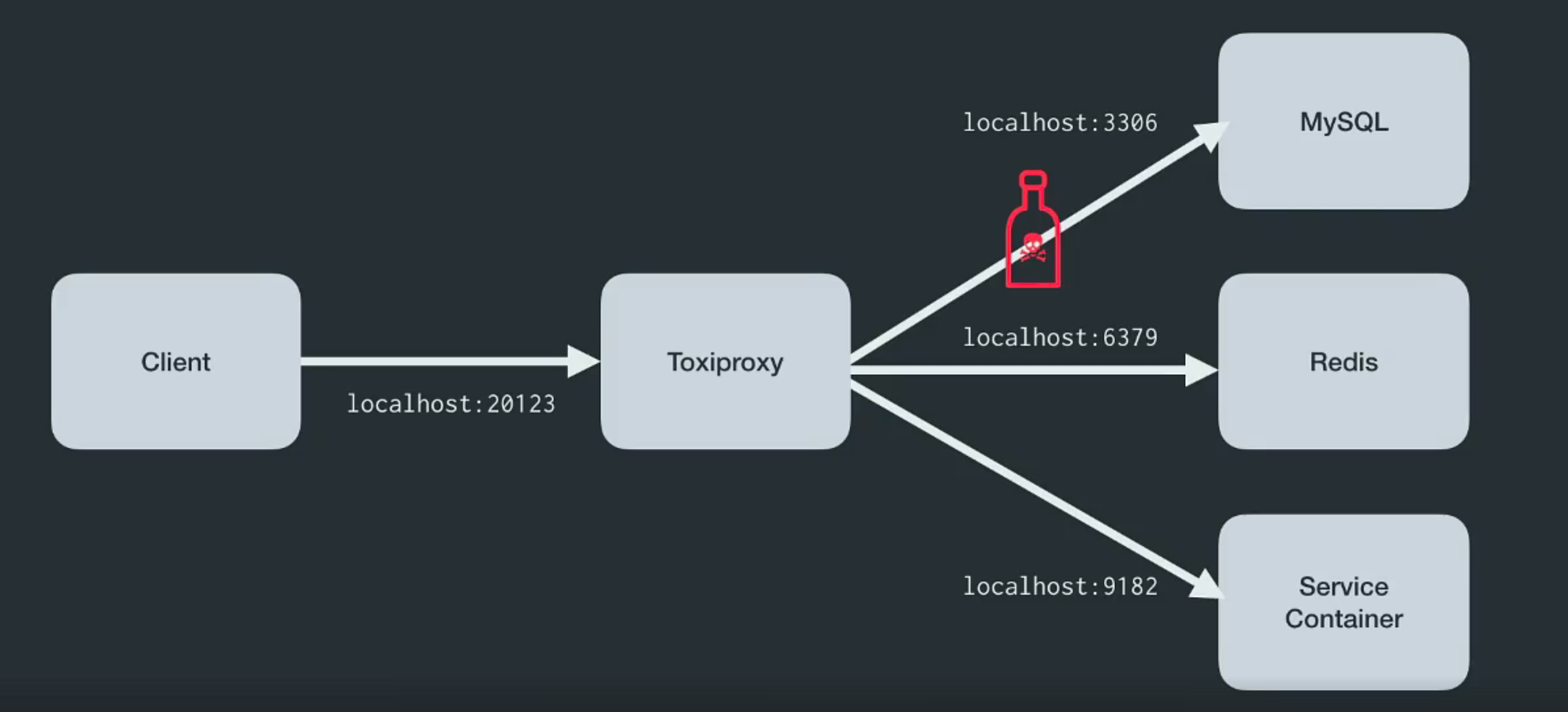
Es wurde speziell für Test-, CI- und Entwicklungsumgebungen entwickelt und führt eine vordefinierte oder zufällige Verwirrung ein, die durch Einstellungen gesteuert wird. Toxiproxy manipuliert mithilfe von Toxics die Beziehung zwischen dem Client und dem Entwicklercode und kann über die HTTP-API konfiguriert werden. Und für ihn im Kit gibt es genug Giftstoffe, um loszulegen.
Das folgende Beispiel zeigt, wie Toxiproxy mit Toxics-Client-Code arbeitet, indem die Kommunikation zwischen meinem Redis-Client, redis-cli und Redis selbst um 1000 ms verzögert wird.
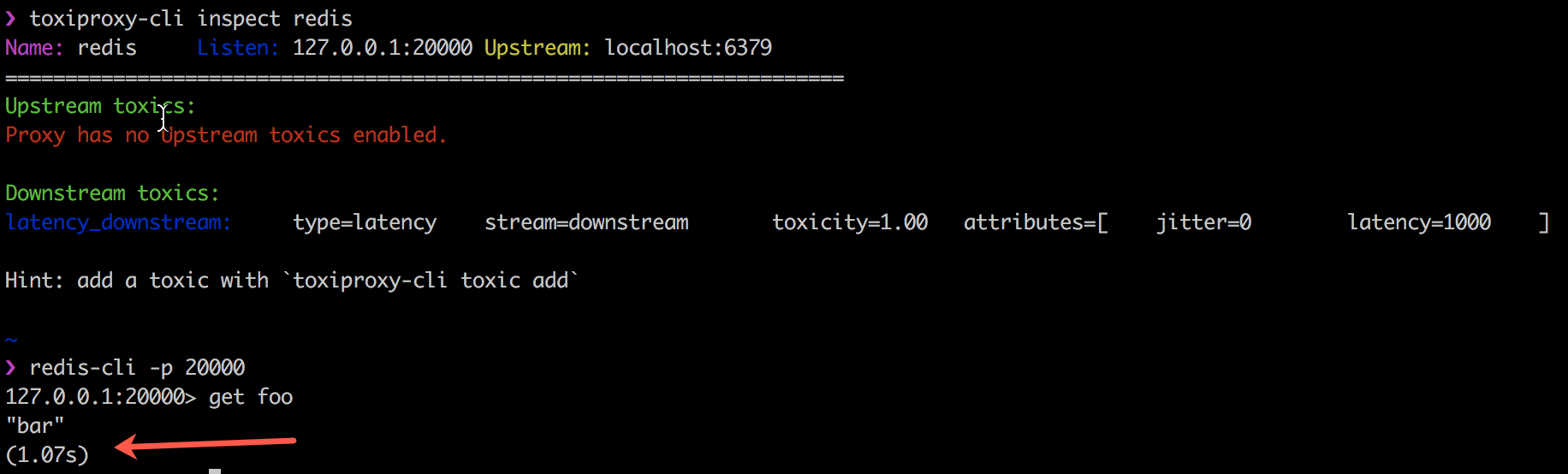
Toxiproxy wird von Shopify seit Oktober 2014 erfolgreich in allen Produktions- und Entwicklungsumgebungen eingesetzt. Weitere Informationen finden Sie auf ihrem Blog .
3 - Einführung von Fehlern auf Anwendungs-, Prozess- und Serviceebene
Die Software fällt. Das ist eine Tatsache. Und was machst du? Soll ich mich über SSH am Server anmelden und den fehlgeschlagenen Prozess neu starten? Prozessleitsysteme bieten Zustandssteuerungs- oder Zustandsänderungsfunktionen vom Typ Start, Stopp, Neustart. Kontrollsysteme werden normalerweise verwendet, um eine stabile Prozesskontrolle zu gewährleisten. systemd ist ein solches Tool, das die grundlegenden Prozesssteuerungsbausteine für Linux bereitstellt. Supervisord bietet die Steuerung mehrerer Prozesse auf Betriebssystemen wie UNIX.
Wenn Sie die Anwendung bereitstellen, sollten Sie diese Tools verwenden. Es ist sicherlich eine gute Praxis, den Schaden durch das Beenden kritischer Prozesse zu testen. Stellen Sie sicher, dass Sie Benachrichtigungen erhalten und der Prozess automatisch neu gestartet wird.
- Java-Prozesse beenden
❯ pkill -KILL -f java #Alternative ❯ pkill -f 'java -jar'
- Python-Prozesse beenden
❯ pkill -KILL -f python
Natürlich können Sie den Befehl pkill , um einige andere auf dem System ausgeführte Prozesse pkill .
Einführung in Datenbankfehler
Wenn es Fehlermeldungen gibt, die Operatoren nicht gern erhalten, dann sind dies diejenigen, die mit Datenbankfehlern zusammenhängen. Da Daten Gold wert sind, steigt bei jedem Absturz einer Datenbank das Risiko, Kundendaten zu verlieren.

Es wird nur eine einfache Wartung sein. Und-und-und-und-so ... alles fiel
Manchmal entscheidet die Fähigkeit, Daten wiederherzustellen und die Datenbank so schnell wie möglich in einen betriebsbereiten Zustand zu versetzen, über die Zukunft des Unternehmens. Leider ist es auch nicht immer einfach, sich auf verschiedene Arten von Datenbankfehlern vorzubereiten - und viele davon werden nur in der Produktionsumgebung angezeigt.
Wenn Sie jedoch Amazon Aurora verwenden , können Sie die Ausfallsicherheit des Amazon Aurora-Datenbankclusters bei Fehlern mithilfe von Failover-Anforderungen testen.
Amazon Aurora Crash Einführung
Fehleranforderungen werden als SQL-Befehle an eine Amazon Aurora-Instanz ausgegeben und ermöglichen es Ihnen, eine Simulation eines der folgenden Ereignisse zu planen:
- Fehler einer schreibenden DB-Instanz.
- Ausfall der Aurora-Replik.
- Festplattenfehler.
- Festplattenüberlastung.
Wenn Sie eine Anforderung für einen Fehler senden, müssen Sie auch die Zeitspanne angeben, in der das Fehlerereignis simuliert wird.
- Verursacht einen Fehler in der Amazon Aurora-Instanz:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];
- simulieren Sie den Ausfall von Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE [ TO ALL | TO "replica name" ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- Simulieren Sie einen Festplattenfehler für den Aurora-Datenbankcluster:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- Simulieren Sie einen Festplattenfehler für den Aurora-Datenbankcluster:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION BETWEEN minimum AND maximum MILLISECONDS [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
Absturz in der Welt der serverlosen Anwendungen
Ein Ausfall kann eine echte Herausforderung sein, wenn Sie serverlose Komponenten verwenden, da serverlose Dienste wie AWS Lambda das Failover nicht von Haus aus unterstützen.
Einführung in Lambda-Fehler
Um dieses Problem zu verstehen, habe ich eine kleine Python-Bibliothek und eine Lambda-Ebene geschrieben , um Fehler in AWS Lambda einzuführen. Derzeit unterstützen sowohl Verzögerung, Fehler, Ausnahmen als auch die Einführung eines HTTP-Fehlercodes. Ein Fehler wird durch folgende Konfiguration des AWS SSM-Parameterspeichers erreicht :
{ "isEnabled": true, "delay": 400, "error_code": 404, "exception_msg": "I really failed seriously", "rate": 1 }
Sie können der Handler-Funktion einen Python-Dekorator hinzufügen, um einen Fehler einzuführen.
- eine Ausnahme auslösen:
@inject_exception def handler_with_exception(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_exception('foo', 'bar') Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1 corrupting now Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../chaos_lambda.py", line 316, in wrapper raise _exception_type(_exception_msg) Exception: I really failed seriously
- Geben Sie den Fehlercode "ungültiges HTTP" ein:
@inject_statuscode def handler_with_statuscode(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_statuscode('foo', 'bar') Injecting Error 404 at a rate of 1 corrupting now {'statusCode': 404, 'body': 'Hello from Lambda!'}
- Geben Sie eine Verzögerung ein:
@inject_delay def handler_with_delay(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_delay('foo', 'bar') Injecting 400 of delay with a rate of 1 Added 402.20ms to handler_with_delay {'statusCode': 200, 'body': 'Hello from Lambda!'}
Klicken Sie hier , um mehr über diese Python-Bibliothek zu erfahren.
Einführung des Lambda-Fehlers durch Parallelitätsbeschränkung
Aus Sicherheitsgründen passt Lambda standardmäßig die parallele Ausführung aller Funktionen in einer bestimmten Region pro Konto an. Parallele Ausführungen beziehen sich auf mehrere Ausführungen eines Funktionscodes, die zu einem bestimmten Zeitpunkt ausgeführt werden. Sie werden verwendet, um einen Funktionsaufruf auf eine eingehende Anforderung zu skalieren. Aber es kann dem entgegengesetzten Zweck dienen: die Hinrichtung von Lambda zu stoppen.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0
Dieser Befehl reduziert die Nebenläufigkeit auf Null und führt zu Abfrageausfällen mit einem Fehler wie "Bremsen" - DTC 429 .
Thundra - Serverlose Übertragungsverfolgung
Thundra ist ein Überwachungstool für serverlose Anwendungen, das Fehler in serverlose Anwendungen einschleusen kann. Er erstellt Wrapper-Handler, um Fehler einzuführen, wie z. B. "Kein Fehlerhandler" für Vorgänge mit DynamoDB, "Keine Fehlerneutralisierung" für die Datenquelle oder "Keine Zeitüberschreitung bei ausgehenden HTTP-Anforderungen". Ich habe es nicht selbst ausprobiert, aber in diesem Beitrag für die Autorenschaft von Yan Chui und in diesem großartigen Video von Marsha Villalba ist der Prozess gut beschrieben. Es sieht vielversprechend aus.
Und zum Abschluss des Abschnitts über serverlose Anwendungen möchte ich sagen, dass Yan Chui einen hervorragenden Artikel über die Schwierigkeiten des Chaos Engineering in Bezug auf serverlose Anwendungen verfasst hat. Ich empfehle jedem, es zu lesen.
4 - Einführung von Ausfällen auf Infrastrukturebene
Alles begann mit der Einführung von Fehlern auf Infrastrukturebene - sowohl für Amazon als auch für Netflix. Die Einführung von Fehlern auf Infrastrukturebene - vom Trennen eines gesamten Rechenzentrums bis zum zufälligen Stoppen von Instanzen - ist wahrscheinlich die einfachste Implementierung.
Und natürlich fällt mir zuerst das Beispiel des „ Affen des Chaos “ ein.
Stoppen von EC2-Instanzen, die zufällig in einer bestimmten Verfügbarkeitszone ausgewählt wurden.
Netflix wollte in seinen Kinderschuhen strenge architektonische Regeln einführen. Er setzte seinen "Monkey of Chaos" als eine der ersten AWS-Anwendungen ein, um automatisch skalierbare zustandslose Microservices zu installieren - in dem Sinne, dass jede Instanz automatisch zerstört oder ersetzt werden kann, ohne dass es zu einem Zustandsverlust kommt. Der Chaos-Affe sorgte dafür, dass niemand gegen diese Regel verstieß.
Das nächste Szenario - ähnlich dem „Affen des Chaos“ - besteht darin, eine beliebige Instanz in einer bestimmten Verfügbarkeitszone innerhalb derselben Region zu stoppen.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")
import boto3 import random REGION = 'eu-west-1' def stop_random_instance(az, tag_name, tag_value, region=REGION): ''' >>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1') ['i-0ddce3c81bc836560'] ''' ec2 = boto3.client("ec2", region_name=region) paginator = ec2.get_paginator('describe_instances') pages = paginator.paginate( Filters=[ { "Name": "availability-zone", "Values": [ az ] }, { "Name": "tag:" + tag_name, "Values": [ tag_value ] } ] ) instance_list = [] for page in pages: for reservation in page['Reservations']: for instance in reservation['Instances']: instance_list.append(instance['InstanceId']) print("Going to stop any of these instances", instance_list) selected_instance = random.choice(instance_list) print("Randomly selected", selected_instance) response = ec2.stop_instances(InstanceIds=[selected_instance]) return response
Haben Sie tag_name tag_value tag_name und tag_value ? Solche kleinen Dinge verhindern den Ausfall der falschen Instanzen. #lessonlearned

Und ja ... starte die Datenbank neu - gut gemacht
5 - Fehlereinführung und All-in-One-Orchestrierungs-Tools
Es ist wahrscheinlich, dass Sie in so vielen Werkzeugen verloren sind. Glücklicherweise gibt es einige Tools für die Einführung von Ablehnungen und die Orchestrierung, die die meisten enthalten und einfach zu bedienen sind.
Eines meiner Lieblingswerkzeuge ist das Chaos Toolkit , eine Open-Source-Chaos-Engineering-Plattform, die vom großen ChaosIQ- Team kommerziell unterstützt wird. Hier nur einige davon: Russ Miles , Sylvain Helleguarch und Marc Parrien .
Das Chaos Toolkit definiert eine deklarative und erweiterbare API für die bequeme Durchführung eines Chaos Engineering-Experiments. Es enthält Treiber für AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus und Gremlin.
Erweiterungen sind eine Reihe von Prüfungen und Aktionen, die für Experimente wie folgt verwendet werden: Wir stoppen eine zufällig ausgewählte Instanz in einer bestimmten Verfügbarkeitszone, wenn der tag-key einen chaos-ready Wert enthält.
{ "version": "1.0.0", "title": "What is the impact of randomly terminating an instance in an AZ", "description": "terminating EC2 instance at random should not impact my app from running", "tags": ["ec2"], "configuration": { "aws_region": "eu-west-1" }, "steady-state-hypothesis": { "title": "more than 0 instance in region", "probes": [ { "provider": { "module": "chaosaws.ec2.probes", "type": "python", "func": "count_instances", "arguments": { "filters": [ { "Name": "availability-zone", "Values": ["eu-west-1c"] } ] } }, "type": "probe", "name": "count-instances", "tolerance": [0, 1] } ] }, "method": [ { "type": "action", "name": "stop-random-instance", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "stop_instance", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] }, "pauses": { "after": 60 } } ], "rollbacks": [ { "type": "action", "name": "start-all-instances", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "start_instances", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] } } ] }
Die Durchführung des obigen Experiments ist einfach:
❯ chaos run experiment_aws_random_instance.json
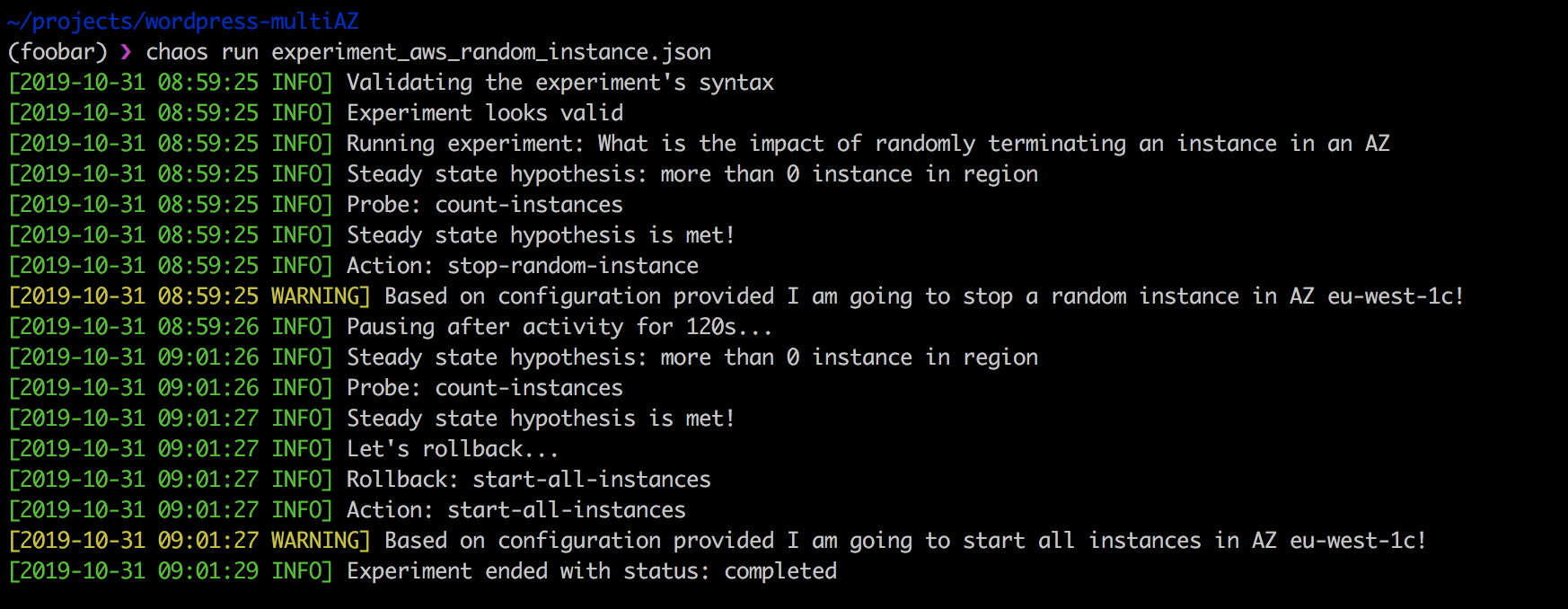
Die Stärke des Chaos Toolkits besteht darin, dass es zum einen Open Source ist und auf Ihre Bedürfnisse zugeschnitten werden kann. Zweitens passt es perfekt in die CI / CD-Pipeline und unterstützt kontinuierliche Chaos-Tests.
Der Nachteil des Chaos Toolkits ist, dass es Zeit braucht, um es zu meistern. Darüber hinaus gibt es keine vorgefertigten Experimente, sodass Sie diese selbst schreiben müssen. Ich bin jedoch mit dem Team von ChaosIQ vertraut, das unermüdlich arbeitet und diese Aufgabe versteht.
Gremlin
Ein weiterer Favorit von mir ist der Gremlin. Es enthält eine umfassende Reihe von Modi zum Einführen von Fehlern in ein einfaches Tool mit einer intuitiven Benutzeroberfläche. So ein Chaos-as-a-Service.
Gremlin unterstützt die Einführung von Fehlern auf Ressourcen-, Netzwerk- und Abfrageebene , sodass Sie schnell mit dem gesamten System experimentieren können, einschließlich mit Hardware, verschiedenen Cloud-Anbietern, containerisierten Umgebungen, einschließlich Kubernetes, Anwendungen und in gewissem Maße serverlosen Anwendungen.
Plus ein Bonus - die Jungs von Gremlin sind großartige Kollegen, die großartige Inhalte für den Blog schreiben und immer bereit sind zu helfen! Hier sind einige von ihnen: Matthew , Colton , Tammy , Rich , Ana und HML .
Der Gremlin kann nirgendwo eingesetzt werden:
Rufe zuerst die Gremlin App auf und wähle "Create Attack".
Weisen Sie eine Zielinstanz zu.
Wählen Sie die Art des Fehlers, den Sie einführen möchten, und das Chaos kann beginnen!
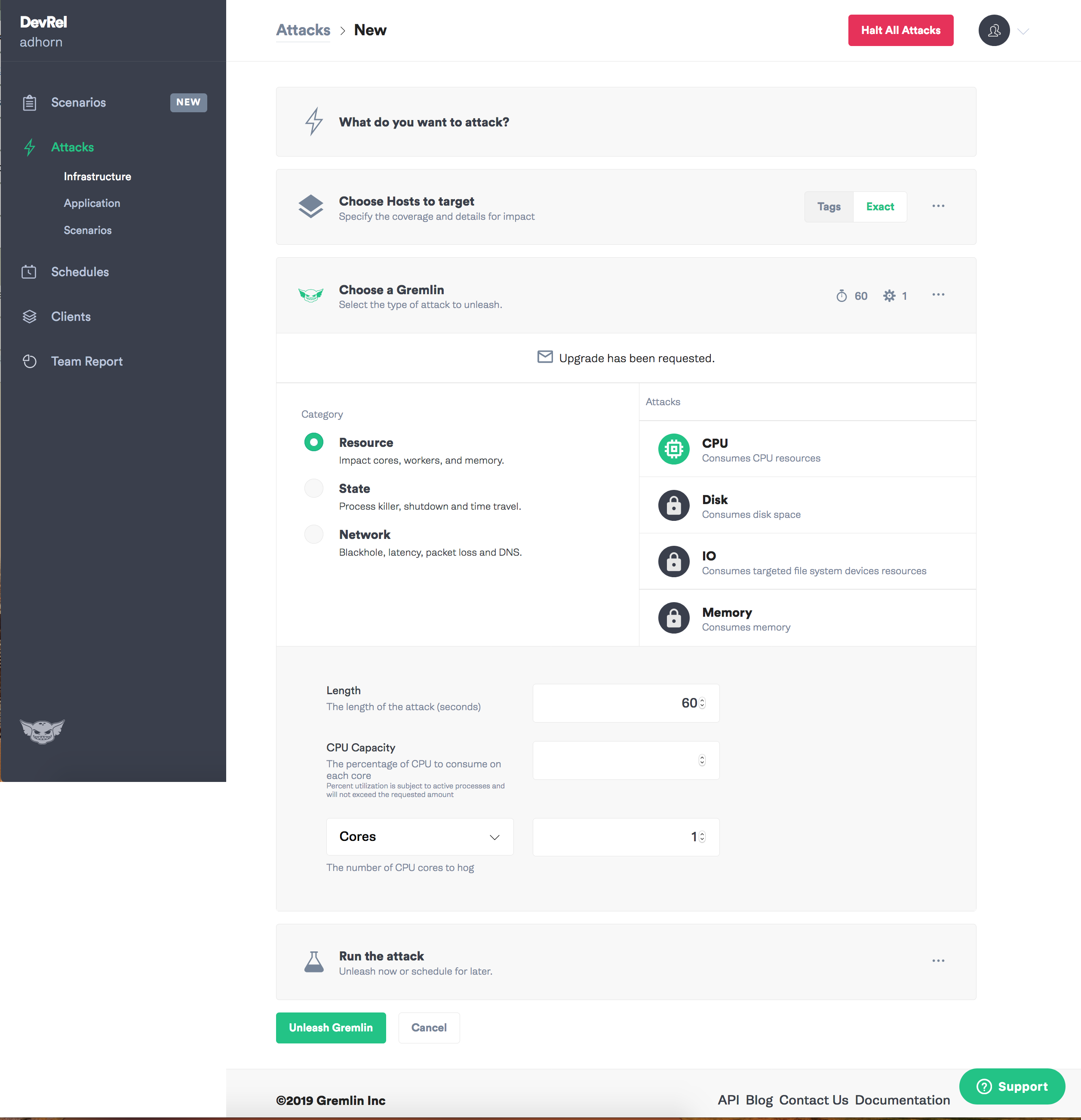
Ich muss zugeben, dass ich Gremlin immer gemocht habe: Experimente zur Chaostechnik sind damit intuitiv einfach.
— , . . , Gremlin- daemon , , .
Run Command AWS System Manager
Run command EC2 , 2015 , . — 2, . , , Systems Manager.
Run Command DevOps ad-hoc , .
, Run Command , Windows, -.
AWS System Manager . — !
!
, .
1 — - — , - . . — , — , , . , ! :
" . ".
— , - Amazon Prime Video
2 — , , . , -.
3 — , , .
4 — , , , . , - — , .
, , , . , . , , :-)
—