
Es war 2019, und wir haben immer noch keine Standardlösung für die Protokollaggregation in Kubernetes. In diesem Artikel möchten wir anhand von Beispielen aus der Praxis unsere Suche, die aufgetretenen Probleme und deren Lösungen mitteilen.
Zunächst mache ich jedoch eine Reservierung, bei der verschiedene Kunden sehr unterschiedliche Dinge verstehen, indem sie Protokolle sammeln:
- jemand möchte Sicherheits- und Überwachungsprotokolle sehen;
- jemand - zentralisierte Protokollierung der gesamten Infrastruktur;
- und für jemanden ist es ausreichend, nur die Anwendungsprotokolle zu sammeln, beispielsweise mit Ausnahme von Balancern.
Wie wir verschiedene "Wishlist" implementiert haben und auf welche Schwierigkeiten wir bei der Kürzung gestoßen sind.
Theorie: Über Protokollierungswerkzeuge
Hintergrundinformationen zu den Komponenten des Protokollierungssystems
Die Protokollierung hat einen langen Weg zurückgelegt, weshalb wir Methoden zum Sammeln und Analysieren von Protokollen entwickelt haben, die wir heute verwenden. In den 1950er Jahren führte Fortran ein Analogon von Standard-I / O-Streams ein, das dem Programmierer beim Debuggen seines Programms half. Dies waren die ersten Computerprotokolle, die den Programmierern dieser Zeit das Leben leichter machten. Heute sehen wir in ihnen die erste Komponente des Protokollierungssystems - die
Quelle oder der „Produzent“ der Protokolle .
Die Informatik stand nicht still: Computernetzwerke erschienen, die ersten Cluster ... Komplexe Systeme, die aus mehreren Computern bestanden, begannen zu funktionieren. Jetzt mussten Systemadministratoren Protokolle von mehreren Computern sammeln und in besonderen Fällen Betriebssystemkernel-Meldungen hinzufügen, falls ein Systemfehler untersucht werden musste.
RFC 3164 wurde in den frühen 2000er Jahren herausgegeben und standardisierte remote_syslog, um zentralisierte Protokollsammlungssysteme zu beschreiben. So erschien eine weitere wichtige Komponente: der
Sammler (Collector) von Protokollen und deren Speicherung.
Mit der Zunahme des Protokollvolumens und der weit verbreiteten Einführung von Webtechnologien stellte sich die Frage, welche Protokolle den Benutzern bequem angezeigt werden sollten. Einfache Konsolen-Tools (awk / sed / grep) wurden durch erweiterte
Protokoll-Viewer ersetzt - die dritte Komponente.
Im Zusammenhang mit der Zunahme des Protokollvolumens wurde eines klar: Es werden Protokolle benötigt, aber nicht alle. Unterschiedliche Protokolle erfordern unterschiedliche Sicherheitsstufen: Einige gehen jeden zweiten Tag verloren, andere müssen fünf Jahre lang aufbewahrt werden. Daher wurde dem Protokollierungssystem eine Filter- und Routing-Komponente für Datenströme hinzugefügt - nennen wir es einen
Filter .
Repositorys machten ebenfalls einen großen Sprung: Sie wechselten von regulären Dateien zu relationalen Datenbanken und dann zu dokumentenorientierten Repositorys (z. B. Elasticsearch). So wurde der Speicher vom Kollektor getrennt.
Am Ende hat sich das Konzept des Protokolls zu einem abstrakten Strom von Ereignissen erweitert, den wir für die Geschichte aufbewahren möchten. Genauer gesagt, wenn eine Untersuchung durchgeführt oder ein Analysebericht erstellt werden muss ...
Infolgedessen hat sich die Sammlung von Protokollen in relativ kurzer Zeit zu einem wichtigen Subsystem entwickelt, das zu Recht als einer der Unterabschnitte von Big Data bezeichnet werden kann.
 Wenn einmal normale Ausdrucke für ein „Protokollierungssystem“ ausreichen könnten, hat sich die Situation jetzt sehr verändert.
Wenn einmal normale Ausdrucke für ein „Protokollierungssystem“ ausreichen könnten, hat sich die Situation jetzt sehr verändert.Kubernetes und Logs
Als Kubernetes in die Infrastruktur kam, ging das bestehende Problem des Sammelns von Protokollen nicht an ihm vorbei. In gewisser Hinsicht ist es noch schmerzhafter geworden: Die Verwaltung der Infrastrukturplattform wurde nicht nur vereinfacht, sondern auch kompliziert. Viele alte Dienste begannen, auf Microservice-Tracks zu migrieren. Im Zusammenhang mit Protokollen führte dies zu einer wachsenden Anzahl von Protokollquellen, ihrem speziellen Lebenszyklus und der Notwendigkeit, die Verbindungen aller Systemkomponenten durch die Protokolle zu verfolgen ...
Mit Blick auf die Zukunft kann ich sagen, dass es derzeit leider keine standardisierte Protokollierungsoption für Kubernetes gibt, die sich positiv von allen anderen unterscheiden würde. Die beliebtesten Programme in der Community sind:
- Jemand stellt einen EFK- Stack bereit (Elasticsearch, Fluentd, Kibana).
- Jemand versucht es mit dem kürzlich veröffentlichten Loki oder verwendet den Protokollierungsoperator .
- wir (und vielleicht nicht nur wir? ..) sind mit unserer eigenen entwicklung weitgehend zufrieden - loghouse ...
In der Regel verwenden wir solche Bundles in K8-Clustern (für selbst gehostete Lösungen):
Ich werde mich jedoch nicht mit den Anweisungen für deren Installation und Konfiguration befassen. Stattdessen werde ich mich auf ihre Mängel und allgemeineren Schlussfolgerungen zur Situation mit Protokollen im Allgemeinen konzentrieren.
Übe mit Logs in K8s

"Alltagsprotokolle", wie viele von Ihnen? ..
Die zentrale Erfassung von Protokollen mit einer ausreichend großen Infrastruktur erfordert erhebliche Ressourcen für die Erfassung, Speicherung und Verarbeitung von Protokollen. Während des Betriebs verschiedener Projekte waren wir mit unterschiedlichen Anforderungen und den daraus resultierenden betrieblichen Problemen konfrontiert.
Versuchen wir es mit ClickHouse
Schauen wir uns ein zentrales Repository für ein Projekt mit einer Anwendung an, die eine ganze Reihe von Protokollen generiert: mehr als 5000 Zeilen pro Sekunde. Beginnen wir mit seinen Protokollen und fügen sie zu ClickHouse hinzu.
Sobald die maximale Echtzeit erforderlich ist, ist der 4-Kern-ClickHouse-Server auf dem Festplattensubsystem bereits überlastet:

Diese Art des Downloads ist darauf zurückzuführen, dass wir versuchen, so schnell wie möglich an ClickHouse zu schreiben. Darauf reagiert die Datenbank mit einer erhöhten Festplattenlast, die folgende Fehler verursachen kann:
DB::Exception: Too many parts (300). Merges are processing significantly slower than insertsTatsache ist, dass
MergeTree-Tabellen in ClickHouse (sie enthalten Protokolldaten) ihre eigenen Schwierigkeiten beim Schreiben haben. Die darin eingefügten Daten erzeugen eine temporäre Partition, die dann mit der Haupttabelle zusammengeführt wird. Infolgedessen ist die Aufzeichnung auf der Festplatte sehr anspruchsvoll, und es gilt die Einschränkung, deren Benachrichtigung wir oben erhalten haben: In einer Sekunde können nicht mehr als 300 Unterpartitionen zusammengeführt werden (das sind 300 Einfügungen pro Sekunde).
Um dieses Verhalten zu vermeiden,
sollten Sie
in ClickHouse in möglichst großen
Blöcken und nicht öfter als einmal in 2 Sekunden
schreiben . Wenn Sie jedoch in großen Stapeln schreiben, sollten Sie weniger häufig in ClickHouse schreiben. Dies kann wiederum zu Pufferüberläufen und zum Verlust von Protokollen führen. Die Lösung besteht darin, den Fluentd-Puffer zu vergrößern, aber dann steigt der Speicherverbrauch.
Hinweis : Eine weitere problematische Seite unserer ClickHouse-Lösung war, dass die Partitionierung in unserem Fall (Loghouse) über externe Tabellen implementiert wurde, die durch eine Merge-Tabelle verknüpft sind. Dies führt dazu, dass beim Abtasten großer Zeitintervalle übermäßiger RAM-Speicher erforderlich ist, da der Metatable alle Partitionen durchläuft - auch diejenigen, die offensichtlich nicht die erforderlichen Daten enthalten. Jetzt kann dieser Ansatz jedoch für aktuelle Versionen von ClickHouse (seit 18.16 ) sicher für veraltet erklärt werden.Infolgedessen wird deutlich, dass ClickHouse nicht über genügend Ressourcen für jedes Projekt verfügt, um Protokolle in Echtzeit zu erfassen (genauer gesagt, ihre Verteilung ist nicht sinnvoll). Außerdem benötigen Sie einen
Akku , zu dem wir zurückkehren. Der oben beschriebene Fall ist real. Und zu diesem Zeitpunkt konnten wir keine zuverlässige und stabile Lösung anbieten, die den Kunden zufrieden stellt und es ermöglicht, Protokolle mit einer minimalen Verzögerung zu sammeln ...
Was ist mit Elasticsearch?
Elasticsearch ist dafür bekannt, schwere Lasten zu bewältigen. Versuchen wir es im selben Projekt. Jetzt ist die Ladung wie folgt:
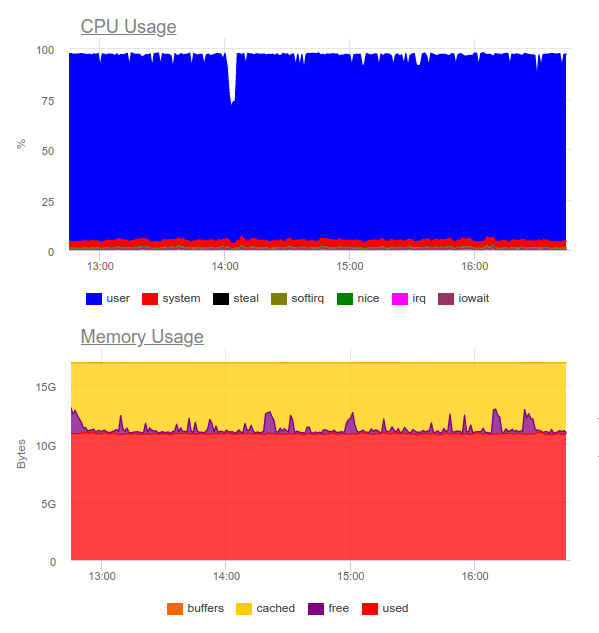
Elasticsearch war in der Lage, den Datenstrom zu verarbeiten. Das Schreiben derartiger Volumes nutzt jedoch die CPU in hohem Maße. Dies wird von der Organisation des Clusters entschieden. Rein technisch ist dies kein Problem, aber es stellt sich heraus, dass wir nur für den Betrieb des Log-Collection-Systems bereits ca. 8 Kerne verwenden und eine zusätzliche hoch belastete Komponente im System haben ...
Fazit: Diese Option kann gerechtfertigt sein, aber nur, wenn das Projekt umfangreich ist und die Verwaltung bereit ist, erhebliche Ressourcen für ein zentrales Protokollierungssystem aufzuwenden.
Dann stellt sich eine logische Frage:
Welche Protokolle werden wirklich benötigt?

Versuchen wir, den Ansatz selbst zu ändern: Die Protokolle sollten gleichzeitig informativ sein und nicht
jedes Ereignis im System abdecken.
Nehmen wir an, wir haben einen florierenden Online-Shop. Welche Protokolle sind wichtig? Es ist eine gute Idee, so viele Informationen wie möglich von einem Zahlungsgateway aus zu sammeln. Vom Image-Slicing-Service im Produktkatalog sind jedoch nicht alle Protokolle für uns kritisch: Nur Fehler und erweiterte Überwachung sind ausreichend (z. B. der Prozentsatz von 500 Fehlern, die diese Komponente generiert).
So kamen wir zu dem
Schluss, dass eine
zentrale Protokollierung keineswegs immer gerechtfertigt ist . Sehr oft möchte der Client alle Protokolle an einem Ort sammeln, obwohl tatsächlich nur 5% der geschäftskritischen Nachrichten aus dem gesamten Protokoll benötigt werden:
- Manchmal reicht es beispielsweise aus, nur die Größe des Containerprotokolls und des Fehlersammlers (z. B. Sentry) zu konfigurieren.
- Zur Untersuchung von Vorfällen reichen häufig Fehlermeldungen und ein umfangreiches lokales Protokoll aus.
- Wir hatten Projekte, die nur Funktionstests und Fehlersammelsysteme kosteten. Der Entwickler brauchte die Protokolle nicht als solche - sie sahen alles auf Fehlerspuren.
Leben Illustration
Ein gutes Beispiel ist eine andere Geschichte. Wir erhielten eine Anfrage des Sicherheitsteams eines Kunden, der bereits eine kommerzielle Lösung hatte, die lange vor der Implementierung von Kubernetes entwickelt wurde.
Es dauerte, bis sich ein zentrales Protokollsammelsystem mit einem Unternehmenssensor zur Erkennung von Problemen - QRadar - „angefreundet“ hatte. Dieses System ist in der Lage, Protokolle über das Syslog-Protokoll zu empfangen, um sie über FTP abzurufen. Die Integration in das remote_syslog-Plugin für fluentd funktionierte jedoch nicht sofort
(wie sich herausstellte, sind wir nicht die einzigen ) . Probleme bei der Konfiguration von QRadar hatte das Sicherheitsteam des Kunden.
Infolgedessen wurde ein Teil der geschäftskritischen Protokolle auf FTP QRadar hochgeladen, und der andere Teil wurde über Remote-Syslog direkt von den Knoten umgeleitet. Dazu haben wir sogar ein
einfaches Diagramm geschrieben - vielleicht hilft es jemandem, ein ähnliches Problem zu lösen ... Dank des resultierenden Schemas hat der Kunde selbst kritische Protokolle empfangen und analysiert (unter Verwendung seiner bevorzugten Tools), und wir konnten die Kosten für das Protokollierungssystem senken und nur die letzten aufbewahren Monat.
Ein anderes Beispiel zeigt, wie man es nicht macht. Einer unserer Kunden, der
jedes vom Benutzer ausgehende Ereignis handhabte, gab die Informationen mehrzeilig und
unstrukturiert in das Protokoll aus. Wie Sie vielleicht erraten haben, war das Lesen und Speichern solcher Protokolle äußerst unpraktisch.
Kriterien für Protokolle
Solche Beispiele führen zu der Schlussfolgerung, dass Sie nicht nur ein System zum Sammeln von Protokollen auswählen, sondern auch
die Protokolle selbst entwerfen müssen ! Was sind die Anforderungen hier?
- Protokolle müssen in einem maschinenlesbaren Format vorliegen (z. B. JSON).
- Protokolle sollten kompakt sein und den Protokollierungsgrad ändern können, um mögliche Probleme zu beheben. Gleichzeitig sollten Sie in Produktionsumgebungen Systeme mit einer Protokollierungsstufe wie Warnung oder Fehler ausführen.
- Protokolle müssen normalisiert sein, dh im Protokollobjekt müssen alle Zeilen den gleichen Feldtyp haben.
Unstrukturierte Protokolle können zu Problemen beim Laden von Protokollen in das Repository und beim vollständigen Stoppen ihrer Verarbeitung führen. Zur Veranschaulichung hier ein Beispiel mit einem 400-Fehler, auf den sicherlich viele in fließenden Protokollen gestoßen sind:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"Ein Fehler bedeutet, dass Sie ein Feld, dessen Typ instabil ist, mit einer fertigen Zuordnung an den Index senden. Das einfachste Beispiel ist ein Feld im Nginx-Protokoll mit der Variablen
$upstream_status . Es kann entweder eine Zahl oder eine Zeichenfolge sein. Zum Beispiel:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}Die Protokolle zeigen, dass der Server 10.100.0.10 mit dem Fehler 404 geantwortet hat und die Anforderung an einen anderen Content Store gesendet wurde. In den Protokollen hat sich die Bedeutung folgendermaßen geändert:
"upstream_response_time": "0.001, 0.007"Diese Situation ist so weit verbreitet, dass sie
in der Dokumentation sogar gesondert
erwähnt wurde .
Und was ist mit Zuverlässigkeit?
Es gibt Zeiten, in denen alle Protokolle ausnahmslos wichtig sind. Und damit haben die oben vorgeschlagenen / diskutierten typischen Protokollsammlungsschemata für K8 Probleme.
Beispielsweise kann fluentd keine Protokolle aus kurzlebigen Containern sammeln. In einem unserer Projekte hat der Container mit der Datenbankmigration weniger als 4 Sekunden gelebt und wurde dann gelöscht - entsprechend der entsprechenden Anmerkung:
"helm.sh/hook-delete-policy": hook-succeededAus diesem Grund wurde das Migrationsprotokoll nicht in das Repository übernommen. In diesem Fall kann die
before-hook-creation Abhilfe schaffen.
Ein weiteres Beispiel ist die Rotation von Docker-Protokollen. Angenommen, es gibt eine Anwendung, die aktiv in die Protokolle schreibt. Unter normalen Umständen können wir alle Protokolle verarbeiten. Sobald jedoch ein Problem auftritt, beispielsweise wie oben beschrieben mit dem falschen Format, wird die Verarbeitung gestoppt und Docker dreht die Datei. Fazit: Geschäftskritische Protokolle können verloren gehen.
Aus diesem Grund ist
es wichtig, den Protokollfluss zu trennen und das Senden des Wertvollsten direkt in die Anwendung einzubetten, um deren Sicherheit zu gewährleisten. Darüber hinaus ist es nicht überflüssig, eine Art
„Akkumulator“ von Protokollen zu erstellen, die die kurze Nichtverfügbarkeit des Speichers überstehen und gleichzeitig wichtige Nachrichten verwalten können.
Vergessen
Sie nicht, dass
es wichtig ist, jedes Subsystem auf eine qualitative Weise zu überwachen . Andernfalls kann es leicht vorkommen, dass sich fluentd im
CrashLoopBackOff Status befindet und nichts sendet, was den Verlust wichtiger Informationen verspricht.
Schlussfolgerungen
In diesem Artikel werden SaaS-Lösungen wie Datadog nicht berücksichtigt. Viele der hier beschriebenen Probleme wurden bereits auf die eine oder andere Weise von kommerziellen Unternehmen gelöst, die auf das Sammeln von Protokollen spezialisiert sind, aber nicht jeder kann SaaS aus verschiedenen Gründen verwenden
(die wichtigsten sind die Kosten und die Einhaltung von 152-) .
Die zentralisierte Sammlung von Protokollen sieht zunächst nach einer einfachen Aufgabe aus, ist es aber überhaupt nicht. Es ist wichtig sich daran zu erinnern, dass:
- Die detaillierte Anmeldung ist nur eine wichtige Komponente. Für andere Systeme können Sie die Überwachung und die Fehlererfassung konfigurieren.
- Protokolle in der Produktion sollten minimiert werden, um eine zusätzliche Belastung zu vermeiden.
- Protokolle müssen maschinenlesbar, normalisiert und in einem strengen Format vorliegen.
- Wirklich kritische Protokolle sollten in einem separaten Stream gesendet werden, der von den Hauptprotokollen getrennt werden sollte.
- Es lohnt sich, eine Protokollbatterie in Betracht zu ziehen, die hohe Belastungsspitzen abfängt und die Belastung des Speichers vergleichmäßigt.

Diese einfachen Regeln würden, wenn sie überall angewendet würden, die oben beschriebenen Schaltkreise funktionieren lassen - obwohl ihnen wichtige Komponenten (Batterie) fehlen. Wenn Sie sich nicht an diese Grundsätze halten, führt die Aufgabe Sie und die Infrastruktur leicht zu einer anderen hoch belasteten (und gleichzeitig ineffektiven) Komponente des Systems.
PS
Lesen Sie auch in unserem Blog: