
Auf einer Konferenz der Entwickler von System- und Werkzeugsoftware - OS DAY 2016, die am 9. und 10. Juni 2016 in Innopolis (Kasan) stattfand, als ein Bericht über die vielzellige Architektur erörtert wurde, wurde der Gedanke geäußert, dass dies zur Lösung von Problemen der künstlichen Intelligenz am effektivsten ist. Die Bedingungen für die Entwicklung eines neuen Allzweckprozessors für KI-Aufgaben haben sich in diesem Jahr entwickelt.
Der Neuroprozessor S2 Multiclet, dessen Projekt erstmals auf dem Huawei Innovation Forum 2019 vorgestellt wurde, ist eine Weiterentwicklung der Multicell-Architektur. Es unterscheidet sich von zuvor erstellten Mehrfachzellen mit einem Befehlssystem, nämlich der Einführung neuer Typen von kleinen Daten (mit Fest- und Gleitkommazahlen) und Operationen mit diesen. Die Anzahl der Zellen wurde erhöht - 256 und die Frequenz - 2,5 GHz, was eine Spitzenleistung von 81,9 TFlops bei 16F liefern und dementsprechend im Hinblick auf neuronale Berechnungen mit den Fähigkeiten moderner spezialisierter ASIC - TPUs (TPU - 3: 90 TFlops bei 16F) vergleichbar machen sollte 16F).
Da die Effizienz der Verwendung von Prozessoren in hohem Maße von der Optimalität des Compilers abhängt, wurde ein Schema zur Codeoptimierung entwickelt.
Lassen Sie es uns genauer betrachten.
Der
vorherige Artikel erwähnte Compiler-Optimierungen, die es wert sind, implementiert zu werden. Dort finden Sie Materialien zur vielzelligen Architektur, wenn Sie nicht bereits damit vertraut sind.
Befehle mit zwei Argumenten mit zwei Konstanten generieren
Mit dem Prozessor S1 wurde ein neues Befehlsformat eingeführt, mit dem beide Argumente als konstanter Wert angegeben werden können. Auf diese Weise können Sie die Anzahl der Befehle im Code verringern und unnötige Befehle wie Laden, um Konstanten in den Switch zu laden, entfernen.
Zum Beispiel:
load_l func wr_l @1, #SP
kann ersetzt werden durch:
wr_l func, #SP
Oder sogar zwei Teams gleichzeitig:
load_l [foo] load_l [bar] add_l @1, @2
Es gibt zwei konstante Adressen, und das Lesen daraus kann auch direkt in die Argumente des Befehls eingesetzt werden:
add_l [foo], [bar]
Diese Optimierung wurde für alle implementiert, die dieses Format unterstützen. Leider hat es sich aus zwei Gründen als sehr unwirksam erwiesen:
- Die Anzahl der Situationen, in denen eine solche Optimierung durchgeführt werden kann, ist sehr gering. Im Arbitrierungscode treten selten Situationen auf, in denen Sie zwei im Voraus bekannte Werte irgendwie verarbeiten müssen. Meistens werden solche Dinge in der Kompilierungsphase entschieden, und es bleibt nur noch wenig zur Laufzeit zu tun. Normalerweise sind dies einige Operationen an Adressen, die wiederum konstant sind.
- Das Entfernen des Ladebefehls befreit den Prozessor nicht vom Prozess des Erzeugens der Konstante, sondern nur vom Abrufen eines separaten Ladebefehls, der nur eine schwache Beschleunigung ergibt, und selbst dann nicht immer.
Optimierung der Übertragung von virtuellen Registern zwischen Basiseinheiten
In LLVM sind Basisblöcke lineare Abschnitte, in denen Code ohne Verzweigung ausgeführt wird. Absätze in einer mehrzelligen Architektur erfüllen genau die gleiche Funktion. Daher spiegelt ein Absatz beim Generieren eines Codes in den meisten Fällen einen Basisblock wider. In Prozessor R1 wurde jede Übertragung von virtuellen Registern zwischen Absätzen durch den Speicher ausgeführt, indem der Wert des gewünschten Registers in den Stapel geschrieben und in den Absatz zurückgelesen wurde, der dieses Register benötigt. Dieser Mechanismus ist in zwei Teile unterteilt: Übertragung des virtuellen Registers in einen anderen Absatz zur direkten Verwendung und Übertragung des virtuellen Registers als Parameter für den Phi-Knoten.
Phi-Knoten sind eine Folge der
SSA-Form (Static Single Assignment), in der die LLVM-Präsentationssprache dargestellt wird. In dieser Form kann eine Variable (oder, wie bei LLVM IR - Virtual Registers) nur einmal geschrieben werden. Zum Beispiel dieser Pseudocode:
a = 1; if (v < 10) a = 2; else a = 3; b = a;
Wird nicht in SSA-Form dargestellt, da der Wert der Variablen
a überschrieben werden kann. Der Code kann in dieser Form umgeschrieben werden, wenn Sie den Phi-Knoten verwenden:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
Der Phi-Knoten wählt a2 oder a3 aus, je nachdem, woher der Kontrollfluss stammt:
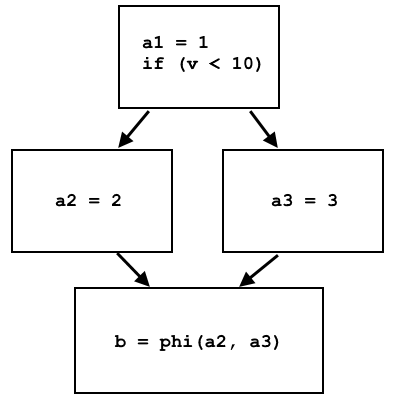
In LLVM IR phi werden Knoten als separate Anweisung implementiert, die unterschiedliche virtuelle Register auswählt, abhängig davon, von welcher Basiseinheit die Steuerung stammt. Die Implementierung dieses Befehls durch den Speicher auf dem Prozessor ist recht einfach: Verschiedene Basisblöcke schreiben verschiedene Daten in dieselbe Speicherzelle, und am Standort-Phi-Knoten wird diese Speicherzelle gelesen, und die Daten sind abhängig vom vorherigen Basisblock unterschiedlich.
Das SSA-Formular impliziert, dass der Wert dort beim Initialisieren des Registers immer der gleiche ist. Wenn die direkte Übertragung von virtuellen Registern ausgeführt wird und der Wert jedes virtuellen Registers in eine separate Speicherzelle geschrieben wird, ist die SSA-Bedingung problemlos erfüllt: Die Daten befinden sich im Speicher, bis sie überschrieben werden. Wenn wir das Register jedoch über den Switch übertragen möchten, müssen wir uns daran erinnern, dass seine Größe nur 63 Zellen beträgt und jeder Wert verschwindet, wenn 63 Befehle ausgeführt werden. Daher ist es unmöglich, das virtuelle Register durch den Schalter zu übertragen, wenn es in einem ersten Absatz geschrieben und nach dem Abschluss von Hunderten anderer verwendet wird. es bleibt nur die Erinnerung.
Die Implementierung dieser Optimierung wurde genau mit der Optimierung von Phi-Knoten begonnen, da im Gegensatz zur direkten Übertragung von virtuellen Registern die Parameterwerte für den Phi-Knoten immer direkt in den vorherigen Absätzen (Basisblöcken) initialisiert werden, sodass Sie nicht viel darüber nachdenken können, ob der Schalter groß genug ist wenn wir diese Parameter durchlaufen wollen.
Mit Multicellular Assembler können Sie den Ergebnissen von Befehlen Namen zuweisen und deren Ergebnisse anhand dieses Namens verwenden. Anstatt dass jeder Programmierer berechnen muss, wie viele Befehle dieses Ergebnis zurückerhalten hat, berechnet der Assembler dies selbst:
result := add_l [A], [B] ; ; ; wr_l @result, C
Dieser Mechanismus funktioniert perfekt im aktuellen Absatz, da es sich um einen linearen Abschnitt handelt und die Reihenfolge der Befehle dort bekannt ist. Dies wird aktiv verwendet, wenn der Compiler Code generiert: Allen Befehlen werden Namen zugewiesen, und der Compiler muss sich nicht um die Nummerierung der Befehle kümmern. Genauer gesagt, es war nicht notwendig, denn wenn wir das Ergebnis eines Befehls in einem anderen Absatz ausführen lassen möchten, funktioniert der Mechanismus nicht: In der Assembler-Phase ist es unmöglich herauszufinden, welcher Absatz vom vorherigen tatsächlich ausgeführt wurde, wenn der aktuelle mehrere Eingaben enthält. Daher besteht die einzige Möglichkeit darin, über die Nummer auf die Ergebnisse der Mannschaften zuzugreifen. Aus diesem Grund können Sie nicht einfach zusätzliche Datensätze / Lesungen aus dem Speicher in benachbarten Absätzen entfernen und die Registerverweise aus dem Lesebefehl durch den Befehl im vorherigen Absatz ersetzen.
Hier ist eine sehr wichtige Konsequenz zu beachten: Wenn ein Absatz mehrere Eingaben hat, kann sich
@ 1 im ersten Befehl dieses Abschnitts auf ganz unterschiedliche Ergebnisse beziehen, je nachdem, welcher Absatz der vorherige war. Phi Node ist so eine Situation. Zuvor wurden in allen Basisblöcken, die den Phi-Knoten initialisierten, Daten in dieselbe Speicherzelle geschrieben, und anstelle des Phi-Knotens wurde ein Lesevorgang aus dieser Zelle durchgeführt. Daher war es absolut unwichtig, an welcher Stelle sich in den vorhergehenden Absätzen in dieser Zelle ein Datensatz befand, ebenso wie an welcher Stelle diese Zelle gelesen wurde. Wenn Sie die Verwendung von Speicher loswerden - es ändert sich.
Damit Phi-Hosts einen Switch anstelle des Speichers verwenden können, wurde Folgendes ausgeführt:
- Alle Phi-Knoten in der aktuellen Basiseinheit werden gezählt (und es können auch mehrere vorhanden sein), sind mit einer Seriennummer gekennzeichnet und in dieser Reihenfolge angeordnet
- Für jeden Phi-Knoten werden die ihn initialisierenden Basisblöcke umgangen und mit Befehlen zum Laden der Werte in den Switch ( loadu_q ) versehen, die durch die Seriennummer des entsprechenden Phi-Knotens gekennzeichnet sind
- Der phi-Befehl des Knotens selbst wird ebenfalls durch loadu_q mit seiner Seriennummer ersetzt
- Alle hinzugefügten Befehle werden in der angegebenen Reihenfolge neu angeordnet
Der vierte Punkt ist aus dem bereits angegebenen Grund erforderlich: Wenn der Befehl
loadu_q @ 3 speziell für seinen Phi-Knoten auf das Ergebnis zugreifen soll, sollten alle initialisierenden Absätze des Befehls, die Daten in den Switch laden, in genau derselben Reihenfolge sein. Lassen Sie uns ein Beispiel für das tatsächliche Ergebnis des Kompilierens von Code geben, in dem sich zwei Phi-Knoten in einer Basiseinheit befinden.
Absätze mit Initialisierern für Phi-Knoten:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
Ein Absatz mit zwei Phi-Knoten:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
Zuvor gab es anstelle von
loadu_q- Befehlen
Schreib- und
Lesezugriffe in den Speicher.
Bei der Implementierung dieser Optimierung gab es auch einige Probleme, die nicht im Voraus vorhergesehen wurden:
- Bei einigen vorhandenen Codeoptimierungen werden Befehle an bestimmten Stellen neu angeordnet, z. B. indem die Adresse des nächsten Absatzes an den Anfang des aktuellen Absatzes gesetzt wird oder die Position der Lese- / Schreibbefehle im Speicher am Anfang bzw. Ende des Absatzes. Diese Optimierungen treten nach Operationen mit Phi-Knoten auf (den sogenannten LLVM-Anweisungen vor Prozessoranweisungen), sodass sie häufig die erstellte Reihenfolge von loadu_q- Befehlen stören. Um die Arbeit dieser Optimierungen nicht zu stören, musste ich einen separaten LLVM-Durchlauf erstellen, der die Befehle für Phi-Knoten nach allen anderen Manipulationen mit den Befehlen in der richtigen Reihenfolge anordnet.
- Es stellte sich heraus, dass eine Situation auftreten kann, in der eine Basiseinheit Phi-Knoten für zwei verschiedene Basiseinheiten initialisiert. Das heißt, nach dem angegebenen Algorithmus werden diese Basisblöcke zu dem loadu_q- Initialisierungsbefehl für jeden Phi-Knoten hinzugefügt. In diesem Fall gibt es, selbst wenn sie nur einen Phi-Knoten haben, im Initialisierungsabschnitt zwei loadu_q-Befehle , die logischerweise beide an letzter Stelle stehen sollten, was natürlich unmöglich ist. Glücklicherweise sind solche Situationen recht selten. Wenn es also eine solche Basiseinheit gibt, in der Phi-Knoten für mehr als eine andere Basiseinheit initialisiert sind, verwendet im übrigen nur die erste den Schalter gemäß dem Algorithmus - wie zuvor - über den Speicher.
All diese Optimierungen von Phi-Knoten können noch etwas ergänzt werden. Wenn Sie sich
beispielsweise den obigen Absatz
LBB1_30 ansehen , können Sie feststellen, dass mit
loadu_q-Befehlen Werte geladen werden, die an keiner anderen Stelle verwendet werden. Wenn Sie also
loadu_q entfernen und die Befehle, mit denen diese Werte erstellt werden, in derselben Reihenfolge
festlegen, werden mit den Befehlen
loadu_q @ 2 im nächsten Abschnitt auch die richtigen Werte geladen.
Benchmarks
Die aktuellen Optimierungsergebnisse wurden an den Benchmarks CoreMark und WhetStone getestet. Eine Beschreibung hierzu finden Sie im
vorherigen Artikel . Beginnen wir mit den CoreMark-Ergebnissen auf dem S2-Core im Vergleich zu den alten Ergebnissen (frühere Version des Compilers auf dem S1-Core).
Die relativen CoreMark / MHz-Werte werden im Histogramm angezeigt:

Um eine Schätzung der Beschleunigung nur aufgrund der Optimierung von Phi-Knoten zu erhalten, können Sie den CoreMark-Indikator auf einer Mehrfachzelle auf S1- und S2-Kernen für eine Frequenz von 1600 MHz neu berechnen: Sie betragen 1147 bzw. 1224, was einer Steigerung von 6,7% entspricht.
Bei WhetStone ist die Situation etwas anders. Änderungen im Kernel haben hier das Ergebnis beeinflusst, außerdem läuft dieser Benchmark auf einem Kern (Multicell) und wird in Megahertz berechnet, so dass die Prozessorfrequenz keine Rolle spielt.
Whetstone Scorecard:
Jetzt ist klar, dass selbst bei Verwendung der vorherigen Version des Compilers auf dem S1-Kernel der Gesamtindex höher ist, was hauptsächlich auf die MFLOPS1-3-Gleitkommatests zurückzuführen ist. Dieser Nachteil wurde beim Testen bemerkt und wird durch die Tatsache verursacht, dass der interne Förderer des Gleitkomma-Blocks in S2 im Vergleich zu S1 einen Schritt mehr ist. Infolgedessen verloren aufeinanderfolgende Ketten datenbezogener Befehle einen Takt für jeden Befehl. Die Notwendigkeit für diesen Schritt wurde durch eine Verringerung der Dauer des Taktzyklus (eine Erhöhung der Frequenz des Prozessors von 1,6 GHz auf 2,5 GHz und eine Erhöhung der Nomenklatur von Befehlen, beispielsweise das Auftreten des Multiplikationsbefehls mit der Akkumulation von MAC) verursacht. Diese Entscheidung ist vorübergehend. Die Arbeiten zur Verkürzung der Pipeline sind im Gange und werden in Zukunft behoben, es wurden jedoch Tests mit der aktuellen Version von S2 durchgeführt.
Um die Beschleunigung der Compileroptimierung zu bewerten, wurde WhetStone auch in einer früheren Version kompiliert und in der aktuellen Version von S2 gestartet. Der Gesamtindikator betrug 0,3068 MWIPS / MHz gegenüber 0,3267 MWIPS / MHz beim neuen Compiler, d. H. Dies zeigt eine Beschleunigung von 6,5% aufgrund der obigen Optimierungen.
Mit dem entwickelten und getesteten Optimierungssystem können Sie in Zukunft das nächste Optimierungsschema implementieren, nämlich die direkte Übertragung virtueller Register über den Switch. Wie bereits erwähnt, kann nicht jede Kopie des virtuellen Registers über den Switch erstellt werden. Aufgrund der begrenzten Größe des Schalters und der Unfähigkeit, korrekt auf die Ergebnisse der vorherigen Absätze zuzugreifen, wenn es mehrere Einstiegspunkte für den aktuellen gibt (dies wird teilweise durch Phi-Knoten gelöst), besteht die einzige mögliche Option darin, virtuelle Register von einem Absatz direkt in den nächsten zu kopieren, es gibt jedoch nur einen vorherigen . In der Tat sind solche Fälle nicht so selten. Oft ist es notwendig, Daten so direkt zu übertragen, obwohl es natürlich schwierig ist, vorab mitzuteilen, wie viel Codebeschleunigung sie bewirken wird.