Früher oder später muss jeder wachsende Dienst seine technischen Fähigkeiten bewerten. Wie viele Besucher können wir bedienen? Was ist die Kapazität des Systems? Haben wir das Limit erreicht und werden nicht fallen, wenn wir mehrere tausend weitere Nutzer anziehen? Wie viele zusätzliche Rechenressourcen sind für das nächste Jahr vorgesehen, um die Wachstumspläne zu erfüllen?
Antworten erhalten Sie analytisch, indem Sie Fragen an einen erfahrenen Entwickler / DevOps / SRE / admin richten. Die Zuverlässigkeit der Bewertung hängt von einer Vielzahl von Faktoren ab: angefangen von der Geschwindigkeit der Füllung des Systems mit Funktionen und der grafischen Darstellung der Beziehungen zwischen den Komponenten bis hin zur Zeit, die der Experte den Morgen im Verkehr verbracht hat. Je komplexer das System ist, desto mehr Zweifel bestehen an der Angemessenheit der analytischen Bewertung.
Mein Name ist Maxim Kupriyanov, seit fünf Jahren arbeite ich bei Yandex.Market. Heute werde ich den Lesern von Habr erzählen, wie wir gelernt haben, die Leistungsfähigkeit unserer Dienste zu bewerten und was daraus geworden ist.
Wir gehen zu der Position
Die Struktur der Market-Komponenten ist ziemlich kompliziert, daher haben wir beschlossen, die Kapazität nur der größten und teuersten Services in Bezug auf die Skalierung zu bewerten. Darüber hinaus sollte die tägliche Anzahl der Anfragen eindeutig von der Größe des täglichen Marktpublikums abhängen (Daily Active Users, DAU). Warum genau von DAU? Denn Analysten, die Prognosen für Monate und Jahre abgeben, berechnen immer die zukünftige Größe des Publikums, und wir werden diesen angenehmen Umstand ausnutzen.
Lassen Sie uns nun darüber sprechen, ohne die es unmöglich ist, objektive Bewertungen zu erstellen: über die Metriken des Dienstes. Wenn die Anzahl der Dienstanforderungen von der DAU abhängt, benötigen wir definitiv die Metrik "Anforderungen pro Sekunde" (Anforderungen pro Sekunde, RPS). Um die Qualität des Dienstes beurteilen zu können, müssen Sie außerdem den Prozentsatz der Fehler und die Antwortzeiten (Anforderungszeitpunkte) kennen. Der Fehler wird als Antwort mit einem HTTP-Code von 500 oder höher betrachtet. Fehler aus dem 4xx-Bereich sind clientseitig und sagen in einem normal funktionierenden System normalerweise nichts über Serviceprobleme aus. In Bezug auf die Zeitangaben ist es für uns üblich, das 80., 95., 99. und 99.9. Perzentil der Antwortzeiten zu berechnen und zu speichern. Ein bestimmter Satz kann sich jedoch von Service zu Service geringfügig unterscheiden.
Wir haben also Metriken für die Anforderungshäufigkeit, den Prozentsatz der Fehler und eine Reihe von Perzentilen der Antwortzeit. Außerdem kennen wir den DAU-Service für jeden Tag und für zukünftige Perioden (in Form einer Prognose). Angesichts der Tatsache, dass sich die durchschnittlichen Benutzerverhaltensmuster von Tag zu Tag nicht zu stark ändern, können wir bei Kenntnis des RPS in der aktivsten Phase des Arbeitstages (Peak-RPS) den Peak-RPS für zukünftige Perioden vorhersagen, vorausgesetzt, wir haben eine DAU-Prognose. Und umgekehrt: Wenn wir wissen, wie viele Anfragen pro Sekunde das System bestehen kann, ohne die Vereinbarung über die Antwortzeit und den Prozentsatz der Fehler zu verletzen, können wir abschätzen, wie viel Publikum wir bedienen können, das heißt, wir kennen die Kapazität des Systems.
Nun, wir haben uns für die Aufgabe entschieden: Die Antwortzeiten und den Prozentsatz der Fehler in Form von Vereinbarungen festzulegen und den maximalen RPS zu ermitteln, den das System unter diesen Bedingungen aushält. Wie werden wir uns entscheiden?
Wir schießen auf das Ziel
Hier ist ein klassischer Ansatz zur Lösung des Problems: Wir erfassen einen Teststandort, nehmen die Systemzugriffsprotokolle aus der Produktionsumgebung, fertigen Kassetten davon und feuern das System, wodurch die Häufigkeit von Anforderungen erhöht wird, bis der Standort eine erhebliche Verschlechterung der Antwortzeiten und / oder Fehler aufweist. An diesem Punkt stoppen wir und legen die Häufigkeit der Anfragen fest (genau das gleiche RPS). Sieg Egal wie. Und hier ist warum:
- Der Teststandort ist in der Regel nicht identisch mit der Plattform unter dem Service in der Produktionsumgebung.
- Der Service-Code ändert sich täglich oder sogar noch häufiger.
- Versuche können die Belastung beeinflussen;
- Der Schweregrad der Benutzeranforderungen hängt von der Tageszeit und anderen Bedingungen ab.
- Moderne Dienste arbeiten selten isoliert, sie stellen häufiger Unterabfragen an andere Dienste, und dies muss irgendwie berücksichtigt werden.
Verbesserung: Wir werden den Dienst jeden Tag automatisch auslösen und zu Stoßzeiten Kassetten aus Magazinen abholen. Und um auf einem Testgelände keine Ressourcen zu verschwenden, werden wir abwechselnd auf dem gleichen Stand Komponenten schälen, die für uns von Interesse sind. Es klingt kompliziert und löst nicht alle Probleme. Aber welche anderen Möglichkeiten gibt es?
Realität simulieren
Die allgemeine Idee ist folgende: Wir kopieren einen Teil des Datenverkehrs von den Balancern zur Site, wo wir die vollständige Analogie der Produktionsumgebung in Miniaturform erfassen und, indem wir das Volumen des kopierten Datenverkehrs anpassen, nach dem Punkt der Verschlechterung suchen. Die Idee ist schön, und wir auf dem Markt tun dies, um neue Funktionen zu testen und das Verhalten neuer Versionen mit alten zu vergleichen. Mein Kollege Eugene hat
darüber ausführlich gesprochen - siehe Abschnitt über den Schattenhaufen. Aber es gibt auch offensichtliche Schwierigkeiten:
- Das Problem der Interaktion mit externen Komponenten ist nicht gelöst, da es sehr teuer ist, eine Kopie der gesamten Produktionsumgebung zu erstellen.
- Anforderungsprotokolle vom Spiegelsystem können sich versehentlich mit den Protokollen aus der Produktionsumgebung vermischen. Dies bedeutet, dass ein System mit einer Markierung des Spiegelverkehrs erstellt werden muss, damit es gefunden und bereinigt werden kann.
- Anfragen werden normalerweise entweder vollständig oder als Prozentsatz der Gesamtsumme gespiegelt, und eine solche Genauigkeit passt nicht zu uns (aber dies kann gelöst werden, wir arbeiten in diese Richtung).
Im Allgemeinen ist die Nachahmung der Produktion ein sehr guter und vielversprechender Ansatz, jedoch sehr teuer und mit erheblichen Einschränkungen.
Testen direkt in der Produktion
Und dann sind wir endlich zum leckeren gekommen. Für jede getestete Komponente wird eine separate Instanz in der Produktion ausgelöst, deren Häufigkeit von der Auswuchtmaschine mit hoher Genauigkeit geregelt wird. Beim letzten Mal
fragten uns die Leser : „Ist HAProxy genug für Sie? Gab es ein Bedürfnis, etwas Eigenes zu schreiben? " Das ist also der sehr seltene Fall, in dem es nicht genug war und ich schreiben musste.
Gleichzeitig gibt es einen separaten Dienst, der die Metriken der geladenen Instanz genau überwacht und, wenn sich die Indikatoren kritischen Werten nähern, das Ventil am Balancer schließt, wodurch die Häufigkeit von Anforderungen verringert wird. Wenn der Service innerhalb akzeptabler Grenzen arbeitet, öffnet das Ventil im Gegenteil. Natürlich sind die Schwellenwerte für Timings und Fehler beim Laden eines Live-Dienstes merklich konservativer (in der Regel um 5–10%) als auf dem Trainingsgelände, da wir die Interaktion mit den Benutzern nicht verschlechtern möchten. Somit arbeitet die geladene Instanz immer bis zum Limit. Wir korrigieren diese Indikatoren. Und dann haben wir Arithmetik: Wir kennen die Anzahl der Servicekerne, die gerade unter Last sind, wir kennen die DAU gestern. Daher berücksichtigen wir Recycling-, Kapazitätsreserve- und Systemverhaltensoptionen beim Deaktivieren des einen oder anderen Standorts. All dies liegt in der Basis, aus der wunderschöne Grafiken erstellt werden. Basierend auf diesen Daten werden Warnungen ausgelöst, wenn die Kapazität unter den Schwellenwert fällt.
Schauen wir uns die Grafiken an
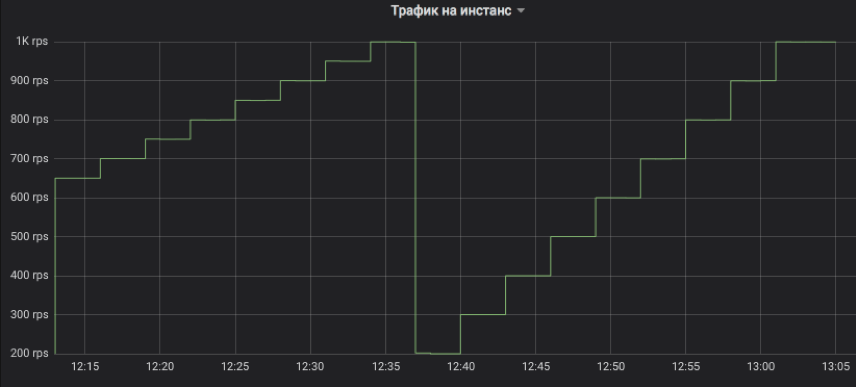
Auf diese Weise steuern wir den Verkehrsfluss zur getesteten Instanz. Der Schritt kann ein Vielfaches von 1 RPS sein. In der Grafik haben wir zur Veranschaulichung einen Anstieg mit einem Drei-Minuten-Intervall modelliert: Zuerst von 650 auf 1 km / h in Schritten von 50 und dann von 200 auf 1 km / h in Schritten von 100. Lassen Sie mich daran erinnern, dass dies echter Nutzerverkehr ist, auf den Kunden Antworten erhalten haben.
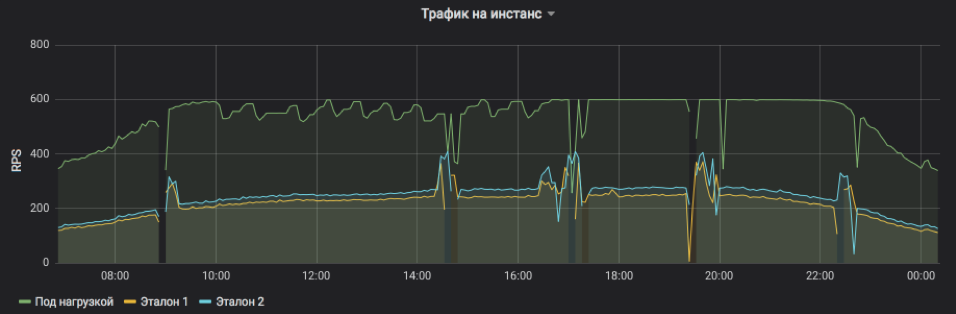
Dies zeigt RPS für drei Instanzen: eine unter Last und zwei unter Kontrolle. Dem Probanden wurde künstlich eine Obergrenze von 600 RPS gesetzt. Der Service kann mehr sein, aber es wird zu instabil und abhängig von äußeren Einflüssen. Es ist deutlich zu sehen, dass in der ersten Hälfte des Tages Serviceanfragen im Durchschnitt schwerer sind und die Instanz unter akzeptablen Bedingungen nicht ihre maximale Kapazität erreichen kann, aber gegen Abend wird alles wieder normal. Bursts und Auslassungen in der Tabelle sind Instanzneustarts zum Auslegen von Releases und anderen Updates (sie sind alle im Gleichgewicht, niemand wurde verletzt). Und schrittweise RPS-Anpassungen am Testobjekt sind nur die Arbeit eines Algorithmus, der die Grenzen der Möglichkeiten auslotet.

Die Häufigkeit von Serviceanfragen und die Belastung, der eine Instanz standhalten kann, sind deutlich sichtbar.
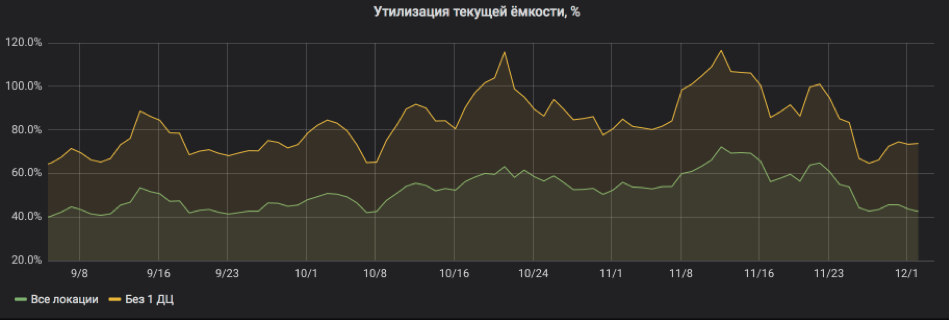
Und hier berechnen wir alles in Prozent der Auslastung neu. Die Grafik zeigt, dass der Service ziemlich stark ausgelastet war und dass bei Deaktivierung eines der Standorte die Gefahr bestand, dass der Service für SLA freigegeben wurde. Aber jetzt ist alles in Ordnung: Ressourcen wurden dem Service hinzugefügt, das Recycling ist wieder in akzeptablen Grenzen.
So können Sie mithilfe von Auslastungstests in der Produktion schnell die Kapazität des Systems bewerten und den Ressourcenverbrauch für zukünftige Perioden vorhersagen. Gleichzeitig verursacht das System keine nennenswerten Kosten, und Sie können sicher mit Stateful Services arbeiten, da wir keinen neuen Datenverkehr generieren, sondern nur den aktuellen Datenverkehr präzise umverteilen. Und schließlich: Um zu funktionieren, ist es in der Regel nicht erforderlich, den Code des experimentellen Systems selbst zu ändern, wodurch auch ältere Anwendungen getestet werden können.
Nachdenken
Diese Methode funktioniert seit mehr als einem Jahr nicht mehr auf dem Markt, und wir können Beobachtungen und Empfehlungen austauschen:
- Neben der geladenen Instanz muss eine gewöhnliche Einzelsteuerung und vorzugsweise Dampf vorhanden sein, da eine Verschlechterung häufig nicht aufgrund einer Überlastung der Instanz, sondern aufgrund allgemeiner Probleme mit dem gesamten Dienst auftritt.
- Die Technik funktioniert nur mit Komponenten, bei denen die Auslastung Hunderte von Anforderungen pro Sekunde für einen Standort übersteigt. Der Grund ist ganz einfach: Wir müssen sowohl die getestete Instanz als auch eine oder zwei Kontrollinstanzen laden. Wenn es nicht genug Verkehr gibt, werden wir nicht die Sättigung erreichen, oder wir werden nicht in der Lage sein, ehrlich zu vergleichen. Und wenn die RPS-Grenze pro Instanz sehr klein ist, ist der Mindestschritt zum Ändern der Anforderungsfrequenz auf 1 RPS möglicherweise zu grob.
- Es ist besser, Fronts und Backends an verschiedenen Orten zu testen, damit Artefakte beim Testen von Backends die Einschätzung der Frontkapazität nicht beeinträchtigen.
- Wenn wir die Reaktionszeiten analysieren und nach Anzeichen für eine Verschlechterung suchen, nehmen wir normalerweise fünfminütige Aggregate und zählen den Median, um nicht auf zufällige Bursts zu reagieren.
- Der Hauptgrund, warum die geladene Instanz des Dienstes abstürzt, ist der Speicherplatz für Protokolldateien (Protokolle). Sie vergessen ihn immer.
- Die Protokollierung auf I / O-geladenen Datenträgern von Webservern ist ein sehr häufiger Grund für eine Verschlechterung der Timings, selbst auf SSDs. Aktivieren Sie immer die Pufferung, die asynchrone Aufzeichnung und alles andere, um nicht zu warten, bis die Aufzeichnung beendet ist.
- Die Nachtlast ist nicht indikativ, da die Anforderungen aufgrund des größeren Roboteranteils im Durchschnitt höher sind. Um die Kapazität abzuschätzen, ist es daher besser, den Bereich von der üblichen hellen Tageszeit bis zur Nacht festzulegen und den Anforderungsfluss nur dann zu verringern, wenn Anzeichen einer Verschlechterung auftreten.
- Das 99,9-Perzentil der Antwortzeiten ist für die Kapazitätsschätzung unbrauchbar, da die Netzwerkverfügbarkeitsgarantien selten 99% überschreiten.
- Starten Sie eine Zeitleiste, und zeichnen Sie Service Releases und andere wichtige Ereignisse auf. Es hilft herauszufinden, was zu einer Verringerung der Kapazität geführt hat.
- Bei einer detaillierten Analyse der Ursachen für die Beeinträchtigung ist auch die Nachverfolgung hilfreich: Jeder Serviceanforderung wird ein Markierungsheader hinzugefügt, der vom vorderen bis zum letzten Backend alle Protokolle eingibt. Auf diese Weise können Sie den gesamten Anforderungspfad verfolgen und die Ursachen für Verzögerungen nachvollziehen.