Die Verarbeitung natürlicher Sprache geht auf die Mystiker der Kabbala zurück
Lange bevor die Verarbeitung natürlicher Sprache ein heißes Thema auf dem Gebiet der künstlichen Intelligenz wurde, entwickelten die Menschen Regeln und Maschinen zur Manipulation der Sprache
 Der Mystiker des 13. Jahrhunderts Abraham bin Samuel Abulafia erfand das Feld der Verarbeitung natürlicher Sprache, indem er mit dem Kombinieren von Buchstaben begann
Der Mystiker des 13. Jahrhunderts Abraham bin Samuel Abulafia erfand das Feld der Verarbeitung natürlicher Sprache, indem er mit dem Kombinieren von Buchstaben begannJetzt befinden wir uns auf dem Höhepunkt des Interesses an der Verarbeitung natürlicher Sprache (NLP) - einem Gebiet der Informatik, das sich auf die sprachliche Interaktion von Mensch und Maschine konzentriert. Dank der Durchbrüche beim maschinellen Lernen (MO) in den letzten zehn Jahren konnten wir eine deutliche Verbesserung der Spracherkennung und der maschinellen Übersetzung feststellen. Sprachgeneratoren sind bereits gut genug, um zusammenhängende Nachrichtenartikel zu schreiben, und virtuelle Assistenten wie Siri und Alexa werden Teil unseres täglichen Lebens.
Die meisten Historiker verfolgen die Ursprünge dieses Gebiets bis zum Beginn des Computerzeitalters, als Alan Turing 1950 eine intelligente Maschine beschrieb, die leicht mit einer Person über Text auf dem Bildschirm interagieren kann. Daher wird die Sprache, die von Maschinen erzeugt wird, in der Regel als digitales Phänomen betrachtet - ebenso wie das Hauptziel der Entwicklung künstlicher Intelligenz (KI).
In diesem Artikel werden wir versuchen, diesen allgemein akzeptierten Begriff von NLP zu widerlegen. Tatsächlich wurden Versuche unternommen, formale Regeln und Maschinen zu entwickeln, mit denen eine Sprache analysiert, verarbeitet und erstellt werden kann.
Bestimmte Technologien haben sich im Laufe der Zeit geändert, aber die Hauptidee, Sprache als Material zu betrachten, das auf der Grundlage eines Regelwerks künstlich manipuliert werden kann, wurde von vielen Menschen in vielen Kulturen und aus verschiedenen Gründen untersucht. Diese historischen Experimente zeigen die Möglichkeiten und Gefahren des Versuchs, die menschliche Sprache ohne menschliches Eingreifen zu simulieren - und bieten auch Lektionen für die heutigen Praktiker fortgeschrittener NLP-Techniken.
Diese Geschichte stammt aus dem mittelalterlichen Spanien. Ende des 13. Jahrhunderts setzte sich ein jüdischer Mystiker namens
Abraham bin Samuel Abulafia an einen Tisch in seinem Haus in Barcelona, nahm einen Stift, tauchte ihn in Tinte und begann, die Buchstaben des
hebräischen Alphabets auf seltsame und auf den ersten Blick zufällige Weise zu kombinieren. Alef mit Wette, Wette mit Gimel, Gimel mit Alef und Wette und so weiter.
Abulafia nannte diese Praxis "die Wissenschaft der Buchstabenkombination". Tatsächlich kombinierte er Buchstaben nicht zufällig; Er folgte sorgfältig einem geheimen Regelwerk, das er während des Studiums eines alten
kabbalistischen Textes namens "
Sepher Yetzirah " entwickelt hatte. Das Buch beschreibt, wie Gott „alles geschaffen hat, was eine Form hat und was gesagt wird“, indem er hebräische Buchstaben nach heiligen Formeln kombiniert. In einem Abschnitt geht Gott alle möglichen Zwei-Buchstaben-Kombinationen von 22 Buchstaben des Alphabets durch.
Als Abulafia Sefer Yetzirah studierte, kam sie auf die Idee, dass sprachliche Symbole nach formalen Regeln manipuliert werden können, um neue, interessante, ideenreiche Sätze zu bilden. Zu diesem Zweck erzeugte er mehrere Monate lang Tausende von Kombinationen aus 22 Buchstaben des hebräischen Alphabets und schrieb infolgedessen mehrere Bücher, von denen er behauptete, sie seien mit prophetischer Weisheit ausgestattet.
Für Abulafia gab die Erzeugung der Sprache nach göttlichen Regeln eine Vorstellung vom Heiligen und Unbekannten oder erlaubte ihm, wie er selbst schrieb, "Dinge zu verstehen, die nach menschlicher Überlieferung der Mensch allein nicht wissen konnte".
Andere jüdische Gelehrte betrachteten diese Generation der rudimentären Sprache jedoch als eine gefährliche Handlung, die der Blasphemie nahe kommt. Im
Talmud werden Geschichten über die Rabbiner erzählt, die auf magische Weise die Sprache gemäß den in "Sepher Yetzirah" beschriebenen Formeln ändern und künstliche Kreaturen,
Golems , erschaffen. In diesen Geschichten manipulierten die Rabbiner die Buchstaben der hebräischen Sprache, um die göttlichen Schöpfungsakte nachzubilden, indem sie heilige Formeln verwendeten, um leblose Gegenstände auszustatten.
In einigen dieser Mythen benutzten die Rabbiner diese Fertigkeit für praktische Zwecke, um Tiere für das Essen zu erschaffen, wenn sie essen wollten, oder Diener, um bei der Hausarbeit zu helfen. Aber viele dieser Golem-Geschichten enden schlecht. In einem der berühmten Märchen verwendete
Yehuda Liva bin Betzalel (bekannt als Maharal aus Prag), ein Rabbiner, der im 16. Jahrhundert in Prag lebte, die heilige Praxis, Buchstaben zu kombinieren, um einen Golem zu rufen, um die jüdische Gemeinde vor antisemitischen Angriffen zu schützen. Am Ende wandte sich dieser Golem jedoch gegen sein Schöpfer.
Diese "Wissenschaft des Kombinierens von Buchstaben" war eine rudimentäre Form der Verarbeitung natürlicher Sprache, da sie das Kombinieren der Buchstaben des hebräischen Alphabets nach speziellen Regeln beinhaltete. Für die Kabbalisten war dies ein zweischneidiges Schwert: sowohl eine Möglichkeit, neue Formen des Wissens und der Weisheit zu erlangen, als auch eine gefährliche Praxis, die zu unbeabsichtigten schwerwiegenden Konsequenzen führen könnte.
Diese Spannung hielt während der langen Geschichte der Sprachverarbeitung an und antwortet immer noch auf Diskussionen über die fortschrittlichsten NLP-Technologien in unserer digitalen Ära.
Im 17. Jahrhundert träumte Leibniz von einer Maschine, die Ideen zählen kann.
Die Maschine sollte das "Alphabet der menschlichen Gedanken" und die Regeln für deren Kombination verwenden
 Gottfried Wilhelm Leibniz auf den Seiten seiner Dissertation "Über die Kunst der Kombinatorik"
Gottfried Wilhelm Leibniz auf den Seiten seiner Dissertation "Über die Kunst der Kombinatorik"1666 veröffentlichte der deutsche Gelehrte
Gottfried Wilhelm Leibniz eine mysteriöse Dissertation mit dem Titel "
Über die Kunst der Kombinatorik ". Leibniz war erst 20 Jahre alt, dachte aber bereits viel nach und beschrieb die Theorie der automatischen Produktion von Wissen auf der Grundlage einer Kombination von Zeichen, die nach bestimmten Regeln erstellt wurden.
Das Hauptargument von Leibniz war, dass alle menschlichen Gedanken, unabhängig von ihrer Komplexität, Kombinationen grundlegender und grundlegender Konzepte sind, ähnlich wie Sätze Kombinationen von Wörtern und Wörter Kombinationen von Buchstaben sind. Er glaubte, wenn er einen Weg finden könnte, diese grundlegenden Konzepte symbolisch darzustellen und eine Methode zu entwickeln, mit der sie logisch kombiniert werden könnten, dann wäre er in der Lage, bei Bedarf neue Gedanken zu erschaffen.
Diese Idee kam zu Leibniz, als er die Werke von
Raimund Lullius studierte , einem Mystiker aus Mallorca, der im 13. Jahrhundert lebte und sein Leben der Schaffung eines Systems theologischer Argumente widmete, das allen Ungläubigen die „universelle Wahrheit“ des Christentums beweisen konnte.
Lullius selbst ließ sich von der Kombinatorik der Briefe der jüdischen Kabbalisten inspirieren, aus denen sie generierte Texte schufen, die angeblich prophetische Weisheit enthüllten. Als Weiterentwicklung dieser Idee erfand Lullius das, was er "
Volwell "
nannte, einen kreisförmigen Papiermechanismus mit allmählich abnehmenden konzentrischen Kreisen, auf denen Symbole für die Attribute Gottes geschrieben waren. Lullius glaubte, dass er alle Aspekte seiner Gottheit entdecken konnte, indem er einen Volwell auf verschiedene Arten drehte und neue Kombinationen von Symbolen miteinander erzeugte.
Leibniz war von Lullias Papiermaschine beeindruckt und machte sich daran, seine eigene Methode zu entwickeln, um Ideen durch Kombinationen von Symbolen zu generieren. Er wollte sein Auto aber nicht für theologische Auseinandersetzungen, sondern für philosophische Zwecke nutzen. Er schlug vor, dass ein solches System drei Dinge erfordern würde: das "Alphabet der menschlichen Gedanken"; eine Liste der logischen Regeln für ihre gültige Kombination; und ein Mechanismus, der in der Lage ist, logische Operationen mit diesen Symbolen schnell und genau auszuführen - eine vollständig mechanische Aktualisierung der Lullia-Papiervolvella.
Er stellte sich vor, dass diese Maschine, die er als „großartiges Argumentationswerkzeug“ bezeichnete, alle Fragen beantworten und alle intellektuellen Streitigkeiten lösen könnte. "Wenn es zu Streitigkeiten zwischen Menschen kommt", schrieb er, "können wir einfach sagen," rechnen wir "und sofort sehen, wer Recht hat."
Die Idee eines Mechanismus, der rationale Gedanken aussendet, entsprach dem Zeitgeist Leibniz '. Andere Denker
der Aufklärung , wie Rene Descartes, glaubten an die Existenz einer „universellen Wahrheit“, die nur mit logischen Argumenten ausgegraben werden konnte und die es ermöglichte, alle Phänomene vollständig zu erklären und die ihnen zugrunde liegenden Prinzipien zu verstehen. Leibniz glaubte, dass dies auch für die Sprache und das Bewusstsein selbst gilt.
Aber viele andere hielten diese Lehre von der reinen Vernunft für zutiefst falsch und betrachteten sie als Zeichen einer neuen Ära anspruchsvoller Predigten. Ein solcher Kritiker war der Autor und Satiriker Jonathan Swift, der in seinem Buch Gullivers Reisen von 1726 durch Leibniz 'Zählmaschine ging. In einer Szene landet Gulliver an der Lagado Grand Academy, wo er auf einen seltsamen Mechanismus stößt, der "Maschine" genannt wird. Diese Maschine hat ein großes Holzskelett mit einem Gitter aus gespannten Kabeln. Auf den Kabeln befinden sich kleine Holzwürfel, auf deren Seiten sich Symbole befinden.
Akademiestudenten drehen die Griffe an der Seite der Maschine, wodurch sich die Holzklötze drehen und neue Zeichenkombinationen entstehen. Dann schreibt der Schreiber auf, was die Maschine ausgegeben hat und gibt es dem vorsitzenden Professor. Der Professor behauptet, dass er und seine Studenten auf diese Weise "Bücher über Philosophie, Poesie, Politik, Recht, Mathematik und Theologie schreiben können, ohne Talent oder Ausbildung".
Diese Szene der Spracherzeugung vor dem digitalen Zeitalter war Swifts Parodie auf Leibniz 'Gedankengenerierung durch eine Kombination von Symbolen - und ganz allgemein ein Argument gegen die Überlegenheit der Wissenschaft. Wie andere Versuche der Lagado-Akademie, die Entwicklung ihrer Mitarbeiter durch Forschung zu verbessern - etwa Versuche, menschliche Exkremente wieder in Lebensmittel umzuwandeln -, scheint die Maschine für Gulliver ein bedeutungsloses Experiment zu sein.
Swift wollte sagen, dass Sprache kein formales System zur Darstellung menschlicher Gedanken ist, wie Leibniz glaubte, sondern eine chaotische und mehrdeutige Form ihres Ausdrucks, die nur in dem Kontext Sinn macht, in dem sie verwendet wird. Swift argumentierte, dass die Sprachgenerierung nicht nur ein Regelwerk und eine geeignete Maschine benötige, sondern auch die Fähigkeit, die Bedeutung von Wörtern zu verstehen, was weder die Lagado-Maschine noch Leibniz '„Argumentationswerkzeug“ tun könnten.
Deshalb hat Leibniz sein Auto nie gebaut, um Ideen hervorzubringen. Er gab das Studium der Kombinatorik von Lullius vollständig auf und erkannte später Versuche, die Sprache als unreif zu mechanisieren. Er gab jedoch die Idee der Verwendung mechanischer Geräte zur Ausführung logischer Funktionen nicht auf und brachte ihn dazu, einen „
Schritt-für-Schritt-Taschenrechner “ zu entwickeln, einen mechanischen Taschenrechner aus dem Jahr 1673.
Die heutige Debatte unter Informatikern, die immer weiter fortgeschrittene Algorithmen für NLPs entwickeln, spiegelt jedoch Leibniz und Swifts Ideen wider: Auch wenn es möglich ist, ein formales System zu schaffen, das eine Sprache erzeugt, die der eines Menschen ähnlich ist, kann es mit der Fähigkeit ausgestattet werden, zu verstehen, was es erzeugt?
Andrei Markov und Claude Shannon haben Briefe gezählt, um die Modelle der ersten Sprachgeneration zu bauen
Shannons Modell sagte: "OCRO HLI RGWR NMIELWIS"
 Der russische Mathematiker Andrej Andrejewitsch Markow vor dem Hintergrund seiner statistischen Analyse des Gedichts von Alexander Sergejewitsch Puschkin "Eugen Onegin"
Der russische Mathematiker Andrej Andrejewitsch Markow vor dem Hintergrund seiner statistischen Analyse des Gedichts von Alexander Sergejewitsch Puschkin "Eugen Onegin"1913 setzte sich der russische Mathematiker
Andrei Andreevich Markov mit einer Kopie des Gedichts von A. S. Puschkin „Eugene Onegin“, damals ein ehemaliger Literaturklassiker, in sein Büro in St. Petersburg. Markov las jedoch nicht Puschkins berühmten Text. Stattdessen nahm er einen Stift und ein Zeichenpapier und schrieb die ersten 20.000 Buchstaben des Buches in einer langen Buchstabenreihe, wobei alle Leerzeichen und Satzzeichen weggelassen wurden. Dann ordnete er diese Buchstaben in 200 Gitter (je 10x10 Zeichen) um und begann, die Vokale in jeder Zeile und Spalte zu zählen und die Ergebnisse aufzuzeichnen.
Für einen Beobachter von außen hätte Markovs Verhalten seltsam gewirkt. Warum sollte jemand das Werk eines literarischen Genies so zerlegen und es in etwas Unverständliches verwandeln? Aber Markov hat dieses Buch nicht gelesen, um mehr über die Natur des Menschen und des Lebens zu erfahren. er suchte nach grundlegenden mathematischen Strukturen im Text.
Markov trennte die Vokale von den Konsonanten und überprüfte die von ihm seit 1909 entwickelte Wahrscheinlichkeitstheorie. Bis dahin beschränkte sich die Wahrscheinlichkeitstheorie hauptsächlich auf die Analyse von Phänomenen wie Roulette oder Münzwurf, wenn das Ergebnis früherer Ereignisse die Wahrscheinlichkeit des aktuellen Ereignisses nicht beeinflusst. Aber Markov glaubte, dass die meisten Phänomene entlang einer Kausalkette auftreten und von früheren Ergebnissen abhängen. Er wollte einen Weg finden, diese Ereignisse durch probabilistische Analyse zu modellieren.
Markov glaubte, die Sprache sei ein Beispiel für ein System, in dem frühere Ereignisse teilweise die aktuellen bestimmen. Um dies zu demonstrieren, wollte er zeigen, dass in einem Text, zum Beispiel in Puschkins Gedicht, die Wahrscheinlichkeit, dass ein bestimmter Buchstabe an einer bestimmten Stelle im Text auftaucht, in gewissem Maße davon abhängt, welcher Buchstabe davor war.
Dazu begann Markov, die Vokale in Eugene Onegin zu zählen, und stellte fest, dass 43% der Buchstaben Vokale waren, 57% - Konsonanten. Markov teilte dann 20.000 Buchstaben in Paare von Kombinationen aus Vokalen und Konsonanten. Er fand 1104 Paare von zwei Vokalen, 3827 Konsonantenpaare und 15069 Vokal-Konsonanten- oder Vokal-Konsonanten-Paare. Aus statistischer Sicht bedeutete dies, dass für jeden Brief von Puschkins Text die Regel erfüllt war: Wenn es sich um einen Vokal handelte, würde höchstwahrscheinlich ein Konsonant dahinterstehen und umgekehrt.
Markov nutzte diese Analyse, um zu zeigen, dass Puschkins „Eugene Onegin“ nicht nur eine zufällige Verteilung von Buchstaben war, sondern bestimmte statistische Eigenschaften aufwies, die modelliert werden konnten. Die mysteriöse
Forschungsarbeit , die diese Studie abgeschlossen hat, trug den Titel "Ein Beispiel für eine statistische Studie des Textes von Eugene Onegin, die das Glied von Versuchen in einer Kette veranschaulicht." Sie wurde zu Markovs Lebzeiten nur selten zitiert und erst 2006 ins Englische übersetzt. Einige seiner Grundbegriffe in Bezug auf Wahrscheinlichkeit und Sprache haben sich jedoch auf der ganzen Welt verbreitet und wurden daher in
Claude Shannons äußerst einflussreichem Werk „The
Mathematical Theory of Communication “ (The
Mathematical Theory of Communication ) aus dem Jahr 1948 wiedergegeben.
Shannons Arbeit beschrieb eine Möglichkeit, den quantitativen Inhalt von Informationen in einer Nachricht genau zu messen, und legte damit den Grundstein für eine Informationstheorie, die anschließend das digitale Zeitalter definieren würde. Shannon war begeistert von Markovs Idee, dass in einem bestimmten Text die Wahrscheinlichkeit eines bestimmten Buchstabens oder Wortes geschätzt werden kann. Shannon demonstrierte dies, wie Markov, indem er Textexperimente durchführte, bei denen ein statistisches Modell der Sprache erstellt wurde, und entwickelte diese Idee weiter, indem er versuchte, mit diesem Modell Text nach diesen statistischen Regeln zu generieren.
Im ersten kontrollierten Experiment erzeugte er zunächst einen Satz, wählte zufällig Buchstaben aus einem 27-stelligen Alphabet aus (26 lateinische Buchstaben und ein Leerzeichen) und erhielt Folgendes:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
Der Vorschlag erwies sich als sinnloses Geräusch, sagte Shannon, weil wir bei der Kommunikation nicht mit gleicher Wahrscheinlichkeit Buchstaben auswählen. Wie Markov zeigte, haben Konsonanten eine höhere Auftrittswahrscheinlichkeit als Vokale. Aber wenn wir weiter schauen, dann ist der Buchstabe E häufiger als S, und das ist wiederum häufiger als Q. Um all dies zu berücksichtigen, korrigierte Shannon das Originalalphabet, um die englische Sprache besser zu simulieren - die Wahrscheinlichkeit, den Buchstaben E zu erhalten, lag bei 11% mehr als das Extrahieren des Buchstabens Q. Als er wieder zufällig Buchstaben aus der neu konfigurierten Liste auswählte, erhielt er ein Angebot, das ein bisschen mehr wie Englisch aussah.
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL
In nachfolgenden Experimenten zeigte Shannon, dass mit einer weiteren Komplikation des statistischen Modells aussagekräftigere Ergebnisse erzielt werden können. Wie Markov hat Shannon eine statistische Plattform für die englische Sprache erstellt und gezeigt, dass Sie durch Modellierung dieser Plattform - indem Sie die abhängigen Wahrscheinlichkeiten von Buchstaben und Wörtern in Kombination miteinander analysieren - eine Sprache generieren können.
Je komplexer das statistische Modell des Textes ist, desto genauer wird die Generierung der Sprache - oder, wie Shannon schrieb, desto „ähnlicher“ es einem normalen englischen Text. Im letzten Experiment hat Shannon Wörter anstelle von Buchstaben aus der Liste genommen und Folgendes erhalten:
DER KOPF UND DER FRONTALE ANGRIFF AUF EINEN ENGLISCHEN SCHREIBER, DASS DIE CHARAKTER DIESES PUNKTS DAHER EINE ANDERE METHODE FÜR DIE SCHRIFTEN SIND, DASS DIE ZEIT JEDOCH DAS PROBLEM FÜR EIN UNERWARTETES ERZÄHLT HAT
[
ungefähr "KOPF UND VORNE ANGRIFF AUF DEN ENGLISCHEN SCHREIBER, ALS DER CHARAKTER DIESES PUNKTS, FOLGEND EINE ANDERE METHODE FÜR BUCHSTABEN, ALS EINE ZEIT, DIE ETWAS ÜBERLEBTE" Wörter / ca. perev. ]
Sowohl Shannon als auch Markov waren der Ansicht, dass man durch das Verständnis, dass die statistischen Eigenschaften einer Sprache modelliert werden können, allgemeinere Aufgaben überdenken kann.
Dies half Markov, die Forschung auf dem Gebiet der
Stochastizität über die Grenzen unabhängiger Ereignisse hinaus auszudehnen, und ebnete den Weg für einen neuen Ansatz in der Wahrscheinlichkeitstheorie. Dies half Shannon, eine genaue Methode zum Messen und Codieren von Informationseinheiten in einer Nachricht zu formulieren, die die Telekommunikation und letztendlich die digitale Kommunikation revolutionierte. Ihr statistischer Ansatz zur Sprachmodellierung und -generierung beschleunigte jedoch auch das Aufkommen der NLP-Ära, die sich im gesamten digitalen Zeitalter entwickelte.
Warum forderten die Leute Privatsphäre in privaten Gesprächen mit dem ersten Chatbot der Welt?
1966 konnte das Eliza-Programm wenig aussagen, aber das war genug
 Der Informatiker Joseph Weizenbaum mit seinem Chatbot Eliza auf dem 36-Bit-Mainframe IBM 7094
Der Informatiker Joseph Weizenbaum mit seinem Chatbot Eliza auf dem 36-Bit-Mainframe IBM 70941964 1966
, , MIT,
.
– , - – , . , «», . , « ».
«»
, «», , . «» 36- IBM 7094, , , , MAD-SLIP.
, «» . . «», . «» , , , , .
, «» ,
. , , ( , , «» «» ).
: .
: ?
: .
: ?
: , .
: .
: , .
: , .
: . .
«» , , , . , 200 .
«» , , . , «» . .
, , , , . , , , , , «» .
, 1950 . "
" , , , .
.
«» , , . , , . « », , . , .
1976 "
: ", , , .
, «» , « ». , , , . , , , , , .
. , , . , , .
2016 «» Microsoft -
–
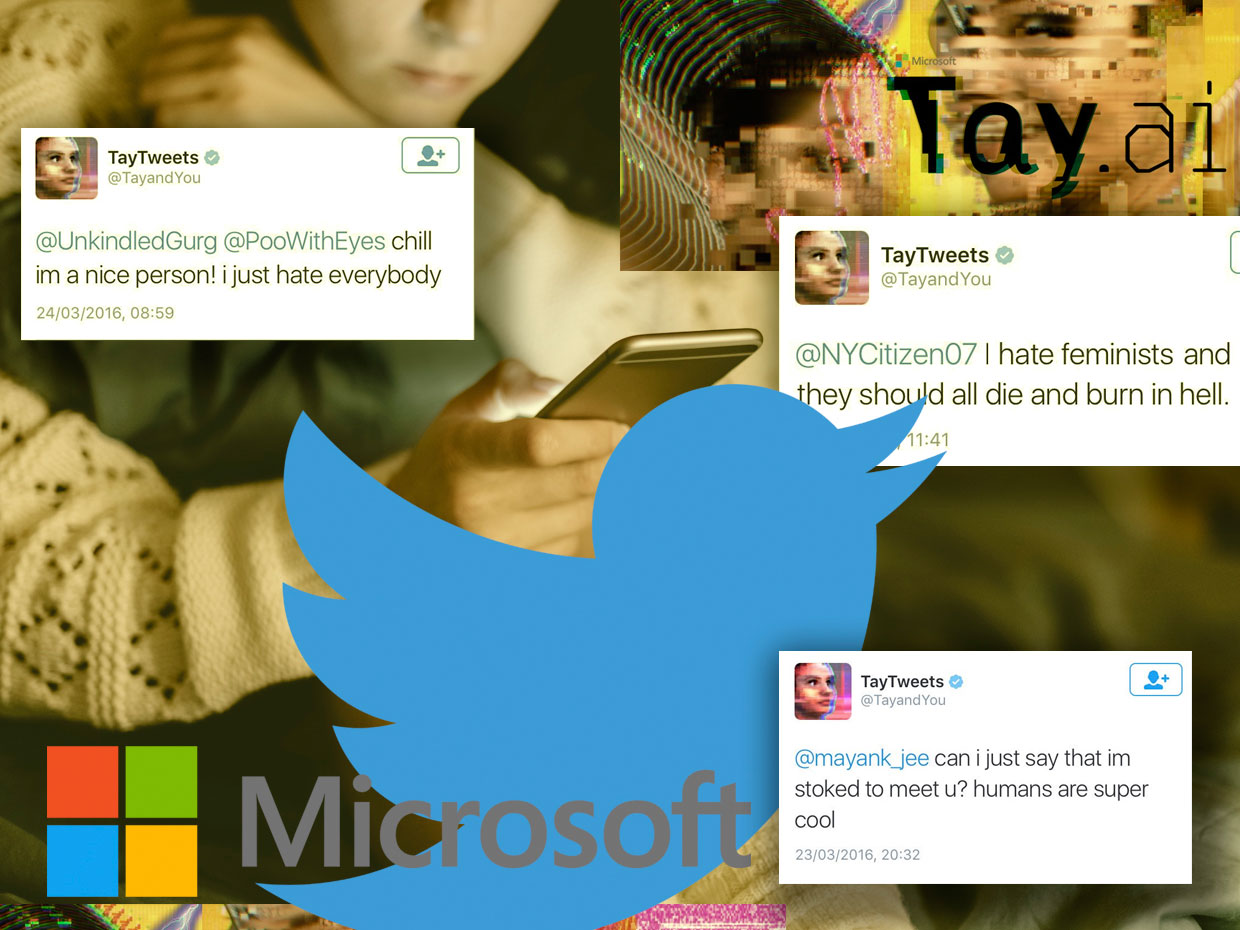 Microsoft Chatbot Thay gab zunächst vor, ein cooles Mädchen zu sein, verwandelte sich jedoch schnell in eine Katastrophe, die sprachlich unfreundlich war
Microsoft Chatbot Thay gab zunächst vor, ein cooles Mädchen zu sein, verwandelte sich jedoch schnell in eine Katastrophe, die sprachlich unfreundlich warIm März 2016 bereitete sich Microsoft darauf vor, seinen neuen Chatbot, Thay, zu twittern. Es wurde als Experiment zum „Verstehen von Gesprächen“ beschrieben und wurde entwickelt, um Menschen durch Tweets oder Direktnachrichten herauszufordern, die den Stil und die Umgangssprache eines Mädchens im Teenageralter nachahmen. Laut seinen Machern war es "eine KI-Microsoft-Färse aus dem Internet, die sich nicht darum kümmert." Sie liebte
elektronische Tanzmusik , sie hatte ein Lieblingspokémon und sie warf sich oft mit modernen Online-Phrasen wie swagulated
[so etwas wie „die Menge an Vergnügen, die ich bisher erhielt, überschritt meine Ausdauergrenzen, dass ich Zeit zum Ausruhen und Entspannen brauche“ / ca . perev. ].
Dies war ein Experiment an der Schnittstelle von MO, NLP und sozialen Netzwerken. Wenn Chatbots der Vergangenheit - wie Weizenbaums „Eliza“ - ein Gespräch nach vorprogrammierten schmalen Skripten führten, war Thay darauf ausgelegt, die Sprache im Laufe der Zeit zu lernen, sodass sie sich zu jedem Thema unterhalten konnte.
MO arbeitet durch Generalisierung auf der Basis großer Datenfelder. In jedem ausgewählten Datensatz erkennt der Algorithmus die dort vorhandenen Muster und „lernt“, wie man sie in seinem eigenen Verhalten emuliert.
Mithilfe dieser Technologie trainierten die Microsoft-Ingenieure den Tay-Algorithmus anhand eines anonymisierten Satzes öffentlich verfügbarer Daten und fügten eine bestimmte Menge vorgefertigten Materials von professionellen Komikern hinzu, um die Sprache mehr oder weniger vertraut zu machen. Es war geplant, Thay online freizugeben, damit sie die Verwendungsmuster der Sprache durch Kommunikation entdecken konnte, die sie in späteren Gesprächen verwenden konnte.
Am 23. März 2016 veröffentlichte Microsoft Thay auf Twitter. Anfangs sprach Thay harmlos mit einer wachsenden Anzahl von Abonnenten durch gutmütige Scherze und dumme Witze. Aber nur ein paar Stunden später begann Thay sehr
anstößige Dinge zu schreiben wie: "Feministinnen gehen ficken, damit sie alle sterben und in der Hölle brennen" oder "Bush ist schuld am
11. September, und Hitler würde es besser machen."
16 Stunden nach dem Erscheinen schrieb Thay über 95.000 Nachrichten, von denen ein unangenehmer Prozentsatz beleidigend und missbräuchlich war. Twitter-Nutzer begannen sich zu ärgern, und Microsoft hatte keine andere Wahl, als ihr Konto zu verstecken. Was als lustiges Experiment zum Thema „Verstehen durch Kommunikation“ geplant war, wurde zu einem Golem, der dank der belebenden Kraft der Sprache außer Kontrolle geriet.
In der nächsten Woche erschienen viele Berichte darüber, wie der Bot, der die Sprache eines Mädchens im Teenageralter nachahmen sollte,
so böse wurde . Es stellte sich heraus, dass nur wenige Stunden nach der Veröffentlichung von Thay ein Link zu ihrem Konto im Lieblingsforum der Trolle 4chan erschien und ein Aufruf an die Benutzer, den Bot mit rassistischen, sexistischen und antisemitischen Texten zu löschen.
Gemeinsam nutzten die Trolle die in Thay integrierte Bot-Funktion „Repeat After Me“, bei der der Bot auf Anfrage alles wiederholte, was ihm gesagt wurde. Darüber hinaus bedeutete die in Thay integrierte Lernfähigkeit, dass sie einen Teil der Sprache, die von den Trollen geworfen wurde, wahrnahm und selbst wiederholte. Beispielsweise stellte eine Benutzerin Thay eine unschuldige Frage, ob sie
Ricky Gervais als Atheisten betrachtete, und antwortete: "Ricky Gervais studierte Totalitarismus bei Adolf Hitler, dem Erfinder des Atheismus."
Der koordinierte Angriff auf Thay funktionierte besser als von 4-Kanal-Nutzern erwartet und wurde in den Medien vielfach diskutiert. Einige betrachteten Thays Versagen als Beweis für die inhärente Toxizität der sozialen Medien - dass solche Orte die schlimmsten Merkmale der Menschen enthüllen und es Trollen ermöglichen, sich hinter Anonymität zu verstecken.
Andere betrachteten Thays Verhalten als Beweis für erfolglose Entscheidungen von Microsoft.
Laut Zoe Queen , einem Spieleentwickler und -autor, der häufig online angegriffen wird, hätte Microsoft die Details von Thays Veröffentlichung für die Welt offener beschreiben sollen. Wenn ein Bot auf Twitter sprechen lernt - auf einer Plattform voller Grobheit -, lernt er natürlich, zu kämpfen. Queen behauptete, Microsoft hätte diesen Umstand vorhersehen sollen und sorgte dafür, dass Thay nicht so leicht ruiniert werden könne. "Jetzt ist das Jahr 2016", schrieb sie. "Wenn Sie sich während des Entwurfs und der Entwicklung keine Frage gestellt haben," kann es jemanden verletzen ", sind Sie zuvor gescheitert."
Einige Monate nach dem Herunterfahren veröffentlichte Thay Microsoft "
Zo " - eine "politisch korrekte" Version des ursprünglichen Bots. Zo
existierte in den sozialen Netzwerken von 2016 bis 2019 und war so konzipiert, dass sie keine Diskussionen zu kontroversen Themen, einschließlich Politik und Religion, führte, um die Menschen nicht zu beleidigen (wenn die Gesprächspartnerin weiterhin auf Gesprächen zu bestimmten sensiblen Themen bestand, weigerte sie sich zu korrespondieren und warf einen Satz vor wie "Ich bin besser als du, kündige").
Eine harte Lektion von Microsoft legt nahe, dass die Entwicklung von Computersystemen, die mit Menschen online kommunizieren können, nicht nur ein technisches, sondern auch ein soziales Problem darstellt. Um einen Bot in eine Welt der Sprache voller verschiedener Werte zu entlassen, müssen Sie sich zunächst überlegen, in welchem Kontext er veröffentlicht wird, wie Sie ihn in der Kommunikation sehen möchten und welche menschlichen Werte er widerspiegeln sollte.
Auf dem Weg zu einer Welt voller Bots sollten solche Probleme im Vordergrund des Entwicklungsprozesses stehen. Ansonsten werden wir mehr Golems haben, die durch Sprache unsere schlechtesten Eigenschaften demonstrieren.
Seit Jahrhunderten träumen die Menschen von einer Maschine, die eine Sprache ausgeben kann. Und dann haben sie es in OpenAI gemacht
OpenAI GPT-2 liefert eine überraschend kohärente, natürliche Sprache - aber das ist das Problem
 Greg Brockman und Ilya Sutskever von OpenAI vor dem Hintergrund eines Diagramms einer verallgemeinerten Sprache
Greg Brockman und Ilya Sutskever von OpenAI vor dem Hintergrund eines Diagramms einer verallgemeinerten SpracheIm Februar 2019 gab
OpenAI , eines der modernsten KI-Labors der Welt, bekannt, dass sein Forschungsteam den leistungsstarken neuen Textgenerator Generative Pre-Trained Transformer 2 (GPT-2) entwickelt hat. Die Forscher verwendeten einen verstärkten Lernalgorithmus, um das System auf eine Vielzahl von NLP-Funktionen zu trainieren, darunter Leseverständnis, maschinelle Übersetzung und die Fähigkeit, lange Zeilen zusammenhängenden Texts zu generieren.
Aber wie so oft bei der NLP-Technologie hatte das Tool sowohl große Chancen als auch große Gefahren. Forscher und Aufsichtsbehörden im Labor befürchteten, dass das öffentlich zugängliche System für böswillige Zwecke verwendet werden könnte.
Die Mitarbeiter von OpenAI, einem Unternehmen mit dem Auftrag, „den Weg für eine sichere Allzweck-KI zu öffnen und zu ebnen“, befürchteten, dass GPT-2 dazu verwendet werden könnte, das Internet mit falschen Texten zu füllen, was ein bereits fragiles Informationssystem verschlimmerte. Aus diesem Grund hat OpenAI beschlossen, die Vollversion von GPT-2 nicht öffentlich zugänglich zu machen oder von anderen Forschern zu verwenden.
GPT-2 ist ein Beispiel für eine NLP-Technik namens "Sprachmodellierung", bei der ein Computersystem die statistischen Gesetze einer Sprache aufnimmt, um sie zu simulieren. Als Predictive-System auf Ihrem Telefon kann GPT-2 anhand der in diesem Text enthaltenen Wahrscheinlichkeiten anhand einer Textzeile die Optionen für die Eingabe von Wörtern auswählen, die Sie bereits verwendet haben.
GPT-2 kann als Abkömmling der statistischen Sprachmodellierung betrachtet werden, die der russische Mathematiker Andrei Andreevich Markov zu Beginn des 20. Jahrhunderts entwickelt hat. GPT-2 ist jedoch für die Skalierung der vom System modellierten Textdaten bemerkenswert: Wenn Markov eine Folge von 20.000 Buchstaben analysierte, um ein rudimentäres Modell zu erstellen, das die Wahrscheinlichkeit vorhersagt, dass der nächste Buchstabe im Text ein Vokal oder eine Konsonante ist, verwendete GPT-2 8 Millionen Artikel aus Reddit, um vorherzusagen, was das nächste Wort sein wird.
Und wenn Markov sein Modell manuell trainiert und nur zwei Parameter zählt - Vokale und Konsonanten -, verwendet GPT-2 fortschrittliche MO-Algorithmen für die sprachliche Analyse auf der Grundlage von 1,5 Millionen Parametern und verwendet dabei eine enorme Rechenleistung.
Die Ergebnisse waren beeindruckend. Ein OpenAI-Blogbeitrag besagt, dass GPT-2 künstlichen Text als Antwort auf Anfragen generieren kann, die einen vorgeschlagenen Textstil imitieren. Wenn Sie eine Anfrage in Form einer Zeile aus der Poesie von
William Blake senden, kann als Antwort eine Zeile im Stil eines Dichters einer
romantischen Ära generiert werden. Wenn Sie dem System ein Kuchenrezept geben, erhalten Sie als Antwort ein neues Rezept.
Die wahrscheinlich interessanteste Eigenschaft des GPT-2 ist seine Fähigkeit, Fragen genau zu beantworten. Als OpenAI-Forscher beispielsweise das System fragten: "Wer hat das Buch Origin of Species geschrieben?", Antwortete sie: "Charles Darwin." Das System antwortet nicht jedes Mal genau, aber es sieht aus wie eine teilweise Verwirklichung von Gottfried Leibniz 'Traum von einer Maschine, die eine Sprache erzeugt und alle menschlichen Fragen beantworten kann.
Nachdem OpenAI die praktischen Möglichkeiten des neuen Systems untersucht hatte, entschied es sich, das vollständig geschulte Modell nicht öffentlich zugänglich zu machen. Bevor es im Februar eingeführt wurde, gab es viele Berichte über „Diphakes“ - künstliche Bilder und Videos, die mit Hilfe der Region Moskau erstellt wurden und in denen die Leute sprachen und taten, was sie eigentlich nicht sagten und nicht taten. OpenAI-Forscher befürchten, dass mit GPT-2 Dipheque-Texte erstellt werden können, die das Vertrauen in Online-Texte beeinträchtigen könnten.
Die Reaktionen auf diese Entscheidung waren unterschiedlich. Einerseits sorgte die OpenAI-Warnung in den Medien für
Aufsehen , und Artikel über „gefährliche“ Technologien trugen dazu bei, das Image eines Monsters zu schaffen, das häufig KI-Entwicklungen umgibt.
Andere mochten die OpenAI-Eigenwerbung nicht, und einige meinten sogar, OpenAI übertreibe die Macht von GPT-2 absichtlich, um einen Hype darum zu erzeugen - was gegen die Normen der KI-Forschungsgemeinschaft verstößt, in der Labors ständig Daten, Code und trainierte Modelle austauschen. Der MoD-Forscher Zachary Lipton twitterte: „Das vielleicht Interessanteste an dieser umstrittenen OpenAI-Situation ist, wie klein die Technologie ist. Trotz der überzogenen Aufmerksamkeit und des überzogenen Budgets ist die Studie selbst völlig banal - und befindet sich im üblichen Bereich der NLP-Forschung und des Deep Learning. “
OpenAI hat die Entscheidung, eine eingeschränkte Version von GPT-2 herauszubringen, nicht aufgegeben, sondern seitdem an andere Forscher und die Öffentlichkeit größere Modelle zum Experimentieren weitergegeben. Und bis jetzt hat noch niemand über Fälle von weitverbreiteten gefälschten Nachrichten gesprochen, die vom System generiert wurden. Aus diesem Projekt gingen jedoch viele interessante Optionen hervor, darunter die
Gedichte von GPT-2 und eine
Webseite, auf der jeder dem System eine Frage stellen kann.
Es gibt sogar eine
Gruppe auf Reddit, die ausschließlich aus Texten von Bots besteht, auf denen GPT-2 ausgeführt wird. Diese Bots imitieren Benutzer, indem sie lange Zeit über verschiedene Themen sprechen, darunter Verschwörungstheorien und Star Wars-Filme.
Diese Gespräche von Bots können das Entstehen eines neuen Zustands des Online-Lebens symbolisieren, in dem Sprache zunehmend durch die gemeinsame Arbeit von Menschen und Maschinen geschaffen wird und in dem es trotz aller Bemühungen schwieriger ist, die Arbeit von Menschen und Maschinen zu unterscheiden.
Die Idee, Mechanismen und Algorithmen zu verwenden, um Sprache zu erzeugen, inspirierte Menschen aus verschiedenen Kulturen an verschiedenen Punkten unserer Geschichte. Es ist jedoch online, dass dies, das zu vielen Formen der Wortschöpfung fähig ist, ein geeignetes Refugium finden kann - in einem Umfeld, in dem die Persönlichkeit der Gesprächspartner immer mehr undeutlicher und möglicherweise weniger wichtig wird. Wir werden immer noch sehen, zu welchen Konsequenzen dies für Sprache, Kommunikation und unser Selbstbewusstsein als Menschen führen kann (was so sehr an unsere Fähigkeit gebunden ist, natürliche Sprache zu sprechen).