
Kürzlich fand in der Abteilung Yandex.Money Operations ein bedeutendes Ereignis statt. Unser Unternehmen wächst rasant und es stellte sich heraus, dass sich nicht nur unsere Herzen, sondern auch die Anforderungen des Rechenzentrums ändern. Genauer gesagt muss sich der Ort ändern. Und jetzt, seit drei Monaten, lebt eines der Rechenzentren an einem neuen Ort.
Über den Umzug von Yandex.Money in ein neues Rechenzentrum werde ich Ihnen, dem Leiter der Betriebsabteilung, und Ivan, dem Leiter der Abteilung für IT-Infrastruktur und interne Systeme, berichten.
Unter dem Strich - eine Chronologie der Ereignisse, wichtige Meilensteine des Umzugs, unerwartete Wendungen und Nachbesprechungen. Wir teilen mit, wie wir das überstanden haben.
Voraussetzungen für den Umzug
Zuvor befand sich eines der Rechenzentren von Yandex.Money in einem Vorort von Moskau. Die Realität ist, dass nicht alle Anbieter von optischen Kommunikationskanälen außerhalb der Stadt die Möglichkeit haben, Kabelstrecken unabhängig zu verlegen - das ist teuer. Der erste Grund für unsere Entscheidung für den Umzug war die Tatsache, dass die Kommunikationskanäle im alten Rechenzentrum auf denselben Wegen verliefen, was mit zusätzlichen Risiken verbunden war.
Innerhalb der Moskauer Ringstraße gibt es viele Anbieter, und das Kabelsystem ist gut entwickelt. Sie können Kanäle von verschiedenen Anbietern kaufen, die unterschiedliche Vorgehensweisen aufweisen und sich nicht überschneiden. In der Region besteht ein erhöhtes Risiko - zum Beispiel wird ein Bagger kommen und alle Gleise auf einmal ausheben.
Zweitens hatte das vorherige Rechenzentrum technologische Einschränkungen, einschließlich periodisch auftretender Probleme mit der Stromversorgung.
Aber der Hauptgrund (= Schmerz) ist die Unfähigkeit zu expandieren. Dies bedeutete, dass das Gebäude keinen Platz mehr für zusätzliche Gestelle hatte, in denen neue Geräte untergebracht werden konnten. Dies steht in direktem Zusammenhang mit unserer produktiven Umgebung, da Yandex.Money über zwei Rechenzentren verfügt und diese in Bezug auf die Kapazitäten symmetrisch sein müssen.
Planung
Die Vorbereitung für den Umzug war in Phasen unterteilt:
- Wettbewerbe: Gleichstrom, Kanäle, Netzwerke, Racks, PDUs, Kabel;
- Übertragen Sie Anwendungen und Datenbanken auf den 2. DC;
- Lehren - DC deaktivieren;
- Neue Architektur von Kernnetzen, IX;
- Einrichten eines neuen Netzwerkkerns im DC.
Lieferantenauswahl
Das erste Yandex.Money-Rechenzentrum befindet sich in Moskau. Um große Netzwerkverzögerungen zu vermeiden, haben wir beschlossen, das zweite Rechenzentrum in der Nähe des ersten zu platzieren.
Innerhalb des MKAD sollen Netzwerkverzögerungen minimiert und nicht näher als 20 km zur ersten Einrichtung sichergestellt werden, um die Unabhängigkeit beider Rechenzentren von der gleichen städtischen Infrastruktur und möglichen technologischen oder Naturkatastrophen sicherzustellen.
Bei der Analyse des Marktes haben wir uns von einem so wichtigen Kriterium wie der Zertifizierung von Rechenzentren hinsichtlich Verfügbarkeit und Zuverlässigkeit leiten lassen. Der in Russland und der Welt am weitesten verbreitete Standard ist der vom Uptime Institute entwickelte Standard, der Rechenzentren auf der ganzen Welt überprüft. Es ist anzumerken, dass es viele Rechenzentren gibt, die nur die Projektdokumentation zertifiziert haben. Dies bedeutet jedoch nicht, dass das Rechenzentrum selbst gemäß Standards gebaut, getestet und betrieben wird.
Ein Fall aus unserer Praxis: Ein Anbieter von Rechenzentrumsdiensten in Moskau gab uns bekannt, dass das Rechenzentrumsprojekt den Tier III-Standard erfüllt, und bot an, eine Vereinbarung mit dem Versprechen einer 100% igen Verfügbarkeit, dh 0 Minuten Ausfallzeit pro Jahr, abzuschließen! Bei einem persönlichen Besuch der Website haben wir festgestellt, dass es keine offiziellen Zertifizierungen gibt, die das Qualitätsniveau garantieren, und die Infrastruktur greift eindeutig nicht auf Tier III zurück. Das Rechenzentrum befand sich im Erdgeschoss eines Wohngebäudes, und der einzige Generatoranhänger stand ohne physischen Schutz auf der Straße.
Daher haben wir in die Wettbewerbsanforderungen nicht nur die Zertifizierung des Projekts, sondern auch die Zertifizierung der Implementierungs- und Managementprozesse aufgenommen.
Des Weiteren haben wir mit Lieferanten von optischen Kommunikationskanälen zwischen unseren DCs und Kanälen Verkehrsknotenpunkte (IX) festgelegt, an denen wir Schnittstellen mit Anbietern oder unseren Partnern einrichten. Das Hauptkriterium war, dass die optischen Kommunikationskanäle unabhängig sein sollten und unterschiedliche Wege gehen sollten.
Natürlich gab es auch andere Anschaffungen - hauptsächlich Netzwerkgeräte, Racks (Spezialschränke für die Installation von Servern), Stromverteiler (intelligente Stromverteiler) sowie Kabel und Patchkabel.
Es ist erwähnenswert, dass wir den Lieferanten, der das Gerät transportiert, besonders sorgfältig ausgewählt haben. Es ist wichtig, dass das Unternehmen Erfahrung im Transport von Servern hat und die Umzugsunternehmen verstehen, dass dies nicht Möbel und Lasten sind. Sie sollten auch beim Fahren besonders vorsichtig sein. Zusätzlich versicherten wir die transportierten Geräte bei Transportschäden.
Upgrade der Netzwerkinfrastruktur
In Bezug auf die Netzwerkinfrastruktur hatten wir zwei Möglichkeiten. Die erste besteht darin, alte Netzwerkgeräte so zu transportieren, wie sie sind. Die zweite besteht darin, zunächst eine neue Netzwerkinfrastruktur in einem neuen Rechenzentrum aufzubauen und erst dann die Serverausrüstung zu transportieren.
Da wir verstanden haben, dass wir bereits auf die Netzwerkbandbreite im alten Rechenzentrum „gestoßen“ sind und die Reserve und die Skalierbarkeit für mindestens die nächsten 3-5 Jahre benötigen, wurde beschlossen, die Netzwerkinfrastruktur im neuen Rechenzentrum von Grund auf neu aufzubauen und auf eine neue Gerätegeneration aufzurüsten .
Beim Aufbau eines Netzwerks in einem neuen Rechenzentrum haben wir uns an das klassische Modell gehalten. In jedem Rack sind die Server mit zwei Zugriffsschaltern verbunden, die wiederum mit den zentralen Aggregationsschaltern verbunden sind (sie sind auch der Kern des Netzwerks).
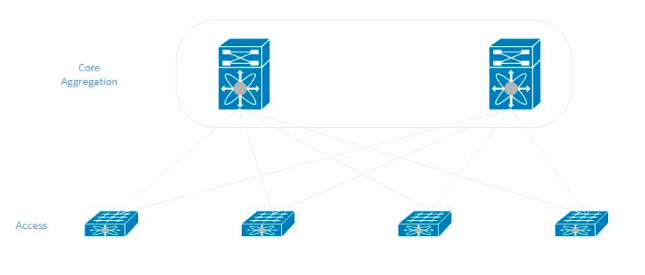
Lehren
Beim Umzug haben wir beschlossen, das Rechenzentrum vollständig auszuschalten, um alles auf einmal zu transportieren und an einem neuen Ort einzuschalten. Dazu musste das Unternehmen lernen, auf eines der beiden Rechenzentren zu verzichten. Es erforderte die Teilnahme fast aller unserer Administratoren, damit Informationssysteme auf verschiedenen Plattformen, auf verschiedenen Betriebssystemen und mit verschiedenen Datenbanken auf der verbleibenden Site ununterbrochen funktionieren.
Für die kritischsten Dienste wurde eine Reserve bereitgestellt, die auch bei ausgeschaltetem Rechenzentrum verfügbar blieb.
Nach der Durchführung der Reservierungsarbeiten begannen die Übungen. Zuerst haben wir einzelne Netzwerke, Segmente und erst dann das Rechenzentrum vollständig getrennt. 2019 haben wir das Rechenzentrum zehnmal testweise heruntergefahren - wir haben beobachtet, wie sich unsere 300 Informationssysteme verhalten. Wir haben die Autonomie wiederholt überprüft und waren überzeugt, dass wir die Verbindung leicht trennen können.
Und weiter…
Woche X
An einem der Freitage sollte die gesamte Ausrüstung im Rechenzentrum abgeschaltet werden. Die neuesten Versionen wurden am Morgen herausgebracht, und dann wurde ein Moratorium für sie angekündigt.
Yandex.Money kann 60 oder mehr Releases pro Tag haben, und alle werden an beide Rechenzentren weitergeleitet.
Wir haben die Releases gestoppt, um sicherzustellen, dass das System stabil funktioniert und keine Korrekturen in unseren Komponenten erforderlich sind. Ab 15:00 Uhr löschten sie allmählich alle Anwendungen, Datenbanken und Server aus. In der Nacht von Freitag auf Samstag warteten wir auf die Zeit, wir waren überzeugt, dass nichts Schlimmes passierte, was bedeutet, dass wir gehen können. Am Samstagmorgen begann ein 15-köpfiges Team, die Geräte zu demontieren und in das neue Rechenzentrum zu transportieren.

Wir haben den ganzen Samstag gebraucht, um die Ausrüstung zu zerlegen und zu transportieren. Als nächstes begann der Prozess der Installation, des Umschaltens und des Anschlusses an die Stromversorgung.

Am Samstagabend haben wir den ersten Stapel Server montiert und verbunden. Die Hauptarbeit begann am Sonntag - am Abend des Wochenendes war fast die gesamte Ausrüstung installiert. Und wir haben die Kommutierung erst am Montagabend beendet.

Am Dienstagmorgen haben wir die letzten Tests von Netzwerken und Kommunikationskanälen durchgeführt und waren bereit, unsere Systeme zu verbessern. Sie haben angefangen, die ersten Server zu erhöhen, aber etwas ist schief gelaufen ...
Von Administratoren erhielten wir Massenbeschwerden, dass das Netzwerk auf den Servern nicht funktionierte: entweder vollständig oder eine von zwei Schnittstellen. Sie begannen, nach Problemen auf der Seite von Netzwerkgeräten, in Betriebssystemen und in den Einstellungen von Betriebssystemen zu suchen.
Die Symptome waren ähnlich - sie begannen zu untersuchen, was der Grund sein könnte. Wir haben festgestellt, dass es sich lohnt, die Patchkabel neben den Switch-Ports stärker zu verschieben, und einige der funktionierenden Verbindungen erlöschen.

Als wir dies entdeckten, stellten wir fest, dass ein erheblicher Teil dieser Patchkabel (etwa 40% von 2000 Stück) defekt war. Wir verlegten alle verfügbaren Patchkabel eines anderen vertrauenswürdigen Herstellers in ein neues Rechenzentrum und begannen dringend, die kritischsten Server erneut zu verbinden. Es dauerte noch einen Tag.
Ab Mittwochabend am Donnerstagmorgen begann das Team, den Hauptblock der Informationssysteme zu heben.
Nachdem wir wichtige Services erhöht und die Reserve des Zahlungssystems eingerichtet hatten, haben wir einen Teil der Teststände des neuen Rechenzentrums und die Reserve der Backoffice-Systeme einbezogen, sodass alle unsere internen Systeme mit zwei Rechenzentren arbeiten. Ende der Woche wurde nahezu die gesamte IT-Infrastruktur des transportierten Rechenzentrums in Betrieb genommen.
Ursprünglich gab es einen Plan für 5 Tage, aber mit einer Notfallsituation im Zusammenhang mit defekten Patchkabeln stellte sich heraus, dass es eine Woche war. Im Folgenden haben wir die Zeitachse unserer Aktionen klar umrissen.
Umzugsplan - ausstehend:- Freitag - wir löschen Netzwerke und Anwendungen;
- Samstag - wir tragen und beginnen die Montage;
- Sonntag - Installation von Servern, Start von Netzwerken;
- Montag - wir beenden das Netzwerk, starten Anwendungen;
- Dienstag - alles einschalten.
Realität:- Freitag - wir löschen Netzwerke und Anwendungen;
- Samstag - wir tragen und beginnen die Montage;
- Sonntag - Installation von Servern, Start von Netzwerken;
- Montag - Verkabelung, Netzwerkstart;
- Dienstag - Server einschalten, 100+ funktioniert nicht;
- Mittwoch - Hochzeit in Drähten, Ersatz , Einführung von App und DB;
- Donnerstag - beendet den Ersatz für PS, starten Sie die App.
Das Leben nach dem Umzug
Was haben wir vom Umzug mitbekommen?Erstens haben beide Rechenzentren jetzt die Stufe III des Uptime Institute. Lieferanten von Rechenzentren garantieren uns eine Verfügbarkeit von 99,982%, was 1,6 Stunden Ausfallzeit pro Jahr entspricht. Wir sind von der Zuverlässigkeit der Kommunikationskanäle zwischen unseren Standorten überzeugt. Auch jetzt gibt es keine Einschränkungen beim Ausbau unserer IT-Infrastruktur.
Die Idee des Umzugs gab uns eine großartige Gelegenheit, die Netzwerkausrüstung in Bezug auf die Bandbreite zu verbessern. Wir haben auch Stromversorgungen in Racks überarbeitet - installierte „Smart PDUs“, reservierte Stromserver.
Und als wir umgezogen sind, konnten wir die Umschaltung „kämmen“, und jetzt sieht es ordentlicher aus.

Daher begann das System im Allgemeinen stabiler zu arbeiten, und unsere Kunden erhalten einen besseren Service.
Welche Schlussfolgerungen haben Sie für sich gezogen?Wenn Sie große Projekte durchführen, müssen Sie über die Risiken nachdenken und sich vorstellen, welche Fallstricke auftreten können. Unser Beispiel mit Ethernet-Kabeln hat gezeigt, dass es nicht ausreicht, einen Testkauf zu tätigen und die Kabelprodukte des ausgewählten Herstellers zu testen. Um die Risiken zu verringern, war es erforderlich, eine Charge von 2000 Kabeln stichprobenartig zu testen.
Es ist auch zu bedenken, dass einige Server den Umzug möglicherweise nicht überleben und sich aus verschiedenen Gründen einfach nicht einschalten lassen. Auf die eine oder andere Weise wackelt die Straße und ist mechanisch belastet. Von den 600 transportierten Geräten brachen 6 Blöcke. Von einer ausreichend großen Anzahl von Servern hat nur 1% gelitten, keine einzige Festplatte ist abgestürzt - wir glauben, dass dies ein hervorragendes Ergebnis ist.
So zog das Rechenzentrum von Yandex.Money an einen neuen Ort. Wir hoffen, dass unsere Erfahrung Ihnen hilft, mögliche Fehler zu vermeiden und Sie möglicherweise zu anderen interessanten Lösungen führt.