Jedes Rasterbild kann als
zweidimensionale Matrix dargestellt werden . Wenn es um Farben geht, kann die Idee entwickelt werden, indem das Bild in Form einer
dreidimensionalen Matrix betrachtet wird , in der zusätzliche Messungen zum Speichern von Daten für jede der Farben verwendet werden.
Betrachten wir die endgültige Farbe als eine Kombination der sogenannten Primärfarben (rot, grün und blau) bestimmen wir in unserer dreidimensionalen Matrix drei Ebenen: die erste für rot, die zweite für grün und die letzte für blau.
Wir werden jeden Punkt in dieser Matrix als Pixel (Bildelement) bezeichnen. Jedes Pixel enthält Intensitätsinformationen (normalerweise in Form eines numerischen Werts) jeder Farbe. Zum Beispiel bedeutet ein
rotes Pixel , dass es 0 Grün, 0 Blau und maximal Rot hat.
Ein rosa Pixel kann unter Verwendung einer Kombination von drei Farben gebildet werden. Unter Verwendung eines Zahlenbereichs von 0 bis 255 wird das rosa Pixel als
Rot = 255 ,
Grün = 192 und
Blau = 203 definiert .

Dieser Artikel wurde mit der Unterstützung von EDISON veröffentlicht.
Wir entwickeln Anwendungen für die Videoüberwachung, das Streaming von Videos sowie die Videoaufzeichnung im Operationssaal .
Alternative Farbcodierungstechniken
Um die Farben darzustellen, aus denen das Bild besteht, gibt es viele andere Modelle. Beispielsweise können Sie eine indizierte Palette verwenden, in der nur ein Byte für jedes Pixel erforderlich ist, anstatt der drei, die bei Verwendung des RGB-Modells erforderlich sind. In einem solchen Modell können Sie eine 2D-Matrix anstelle einer 3D-Matrix verwenden, um jede Farbe darzustellen. Das spart Speicherplatz, gibt aber weniger Farbe.

RGB
Schauen Sie sich zum Beispiel das folgende Bild an. Das erste Gesicht ist komplett bemalt. Andere sind die roten, grünen und blauen Ebenen (die Intensität der entsprechenden Farben wird in Graustufen angezeigt).

Wir sehen, dass sich die Rottöne im Original an denselben Stellen befinden, an denen die hellsten Stellen der zweiten Person beobachtet werden. Während der Beitrag von Blau ist hauptsächlich nur in den Augen von Mario (dem letzten Gesicht) und den Elementen seiner Kleidung zu sehen. Beachten Sie, wo alle drei Farbebenen den geringsten Beitrag leisten (die dunkelsten Teile der Bilder) - das ist Marios Schnurrbart.
Um die Intensität jeder Farbe zu speichern, ist eine bestimmte Anzahl von Bits erforderlich - dieser Wert wird als
Bittiefe bezeichnet . Angenommen, es werden 8 Bits (basierend auf einem Wert von 0 bis 255) auf einer Farbebene ausgegeben. Dann haben wir eine Farbtiefe von 24 Bit (8 Bit * 3 R / G / B-Ebene).
Eine weitere Eigenschaft des Bildes ist die
Auflösung , dh die Anzahl der Pixel in einer Dimension. Es wird oft als
Breite × Höhe bezeichnet , wie im folgenden Beispiel 4 mal 4.

Eine weitere Eigenschaft, mit der wir uns bei der Arbeit mit Bildern / Videos befassen, ist das
Seitenverhältnis , das das übliche proportionale Verhältnis zwischen Breite und Höhe eines Bildes oder Pixels beschreibt.
Wenn sie sagen, dass ein Film oder ein Bild 16 mal 9 groß ist, bezieht sich dies normalerweise auf das
Seitenverhältnis der Anzeige (
DAR - from
Display Aspect Ratio ). Manchmal kann es jedoch zu unterschiedlichen Formen einzelner Pixel kommen - in diesem Fall handelt es sich um das
Pixelverhältnis (
PAR - from
Pixel Aspect Ratio ).


Hinweis an die Gastgeberin: DVD entspricht DAR 4 mal 3
Obwohl die tatsächliche Auflösung der DVD 704 x 480 beträgt, bleibt das Seitenverhältnis 4: 3 erhalten, da der PAR auf 10:11 (704 x 10/480 x 11) eingestellt ist.
Und schließlich können wir ein
Video als Folge von
n Bildern über einen bestimmten Zeitraum definieren, was als zusätzliche Dimension betrachtet werden kann. Und
n ist dann die Bildrate oder die Anzahl der Bilder pro Sekunde (
FPS - from
Frames per Second ).

Die Anzahl der Bits pro Sekunde, die zum Anzeigen eines Videos erforderlich sind, ist die
Bitrate .
Bitrate = Breite * Höhe * Bittiefe * Frames pro Sekunde
Beispiel: Für Videos mit 30 Bildern pro Sekunde, 24 Bit pro Pixel, 480 x 240 Auflösung, 82.944.000 Bit pro Sekunde oder 82.944 Mbit / s (30 x 480 x 240 x 24) ist dies erforderlich, wenn Sie keine der Komprimierungsmethoden verwenden.
Ist die Bitrate
nahezu konstant , spricht man von einer
konstanten Bitrate (
CBR - from
constant bit rate ). Es kann aber auch variieren, in diesem Fall spricht man von einer
variablen Bitrate (
VBR - from
variable bit rate ).
Dieser Graph zeigt eine begrenzte VBR, wenn im Falle eines vollständig dunklen Rahmens nicht zu viele Bits ausgegeben werden.

Zunächst entwickelten die Ingenieure eine Methode, um die wahrgenommene Bildrate einer Videoanzeige zu verdoppeln, ohne zusätzliche Bandbreite zu verbrauchen. Diese Methode wird als
Interlaced-Video bezeichnet . Grundsätzlich wird die Hälfte des Bildschirms im ersten "Frame" und die andere Hälfte im nächsten "Frame" gesendet.
Derzeit wird die Szenenvisualisierung hauptsächlich mit der
Progressive-Scan-Technologie durchgeführt . Dies ist eine Methode zum Anzeigen, Speichern oder Übertragen von Bewegtbildern, bei der alle Zeilen jedes Einzelbilds nacheinander gezeichnet werden.

Na dann! Jetzt wissen wir, wie das Bild in digitaler Form dargestellt wird, wie die Farben angeordnet sind, wie viele Bits pro Sekunde wir verwenden, um das Video anzuzeigen, wenn die Übertragungsgeschwindigkeit konstant (CBR) oder variabel (VBR) ist. Wir kennen eine bestimmte Auflösung mit einer bestimmten Bildrate, kennen viele andere Begriffe wie Interlaced-Video, PAR und einige andere.
Redundanzentfernung
Es ist bekannt, dass Videos ohne Komprimierung nicht normal verwendet werden können. Ein stündliches Video mit einer Auflösung von 720p und einer Frequenz von 30 Bildern pro Sekunde würde 278 GB belegen. Diesen Wert erhalten wir durch Multiplikation von 1280 x 720 x 24 x 30 x 3600 (Breite, Höhe, Bits pro Pixel, FPS und Zeit in Sekunden).
Mit
verlustfreien Komprimierungsalgorithmen wie DEFLATE (in PKZIP, Gzip und PNG verwendet) wird die erforderliche Bandbreite nicht ausreichend reduziert. Sie müssen nach anderen Möglichkeiten suchen, um Videos zu komprimieren.
Hierfür können Sie die Merkmale unserer Vision nutzen. Wir unterscheiden bessere Helligkeit als Farben. Ein Video ist eine Reihe von aufeinanderfolgenden Bildern, die sich im Laufe der Zeit wiederholen. Es gibt kleine Unterschiede zwischen benachbarten Bildern derselben Szene. Darüber hinaus enthält jeder Rahmen viele Bereiche, die dieselbe (oder eine ähnliche) Farbe verwenden.
Farbe, Helligkeit und unsere Augen
Unsere Augen reagieren empfindlicher auf Helligkeit als auf Farbe. Sie können sich von diesem Bild überzeugen.
Wenn Sie in der linken Bildhälfte nicht sehen, dass die Farben der Quadrate
A und
B tatsächlich gleich sind, ist dies normal. Unser Gehirn lässt uns mehr auf Hell-Dunkel als auf Farbe achten. Auf der rechten Seite zwischen den markierten Quadraten befindet sich ein Jumper der gleichen Farbe - daher können wir (d. H. Unser Gehirn) leicht feststellen, dass tatsächlich die gleiche Farbe vorhanden ist.
Schauen wir uns (vereinfacht) an, wie unsere Augen funktionieren. Das Auge ist ein komplexes Organ, das aus vielen Teilen besteht. Am meisten interessieren uns jedoch Zapfen und Stäbchen. Das Auge enthält etwa 120 Millionen Stäbchen und 6 Millionen Zapfen.
Betrachten Sie die Wahrnehmung von Farbe und Helligkeit als separate Funktionen bestimmter Teile des Auges (in der Tat ist alles etwas komplizierter, aber wir werden es vereinfachen). Stabzellen sind hauptsächlich für die Helligkeit verantwortlich, während Zapfenzellen für die Farbe verantwortlich sind. Je nach enthaltenem Pigment werden die Zapfen in drei Typen unterteilt: S-Zapfen (blau), M-Zapfen (grün) und L-Zapfen (rot).
Da wir viel mehr Stäbchen (Helligkeit) als Zapfen (Farbe) haben, können wir schließen, dass wir die Übergänge zwischen Dunkelheit und Licht besser unterscheiden können als Farben.

Kontrastempfindlichkeitsfunktionen
Forscher der experimentellen Psychologie und vieler anderer Gebiete haben viele Theorien des menschlichen Sehens entwickelt. Und eine von ihnen heißt Kontrastempfindlichkeitsfunktionen . Sie sind mit räumlicher und zeitlicher Beleuchtung verbunden. Kurz gesagt, es geht darum, wie viele Änderungen erforderlich sind, bevor der Beobachter sie sieht. Beachten Sie den Plural des Wortes "Funktion". Dies liegt an der Tatsache, dass wir die Empfindlichkeitsfunktionen messen können, um nicht nur Schwarzweißbilder, sondern auch Farbkontraste zu erzeugen. Die Ergebnisse dieser Experimente zeigen, dass unsere Augen in den meisten Fällen empfindlicher auf Helligkeit als auf Farbe reagieren.
Da bekannt ist, dass wir empfindlicher auf die Bildhelligkeit reagieren, können Sie versuchen, diese Tatsache zu nutzen.
Farbmodell
Wir haben ein bisschen herausgefunden, wie man mit Farbbildern unter Verwendung des RGB-Schemas arbeitet. Es gibt noch andere Modelle. Es gibt ein Modell, das Luminanz von Farbe trennt und als
YCbCr bekannt ist . Übrigens gibt es andere Modelle, die eine ähnliche Trennung vornehmen, aber wir werden nur dieses betrachten.
In diesem Farbmodell ist
Y eine Darstellung der Helligkeit und es werden zwei Farbkanäle verwendet:
Cb (gesättigtes Blau) und
Cr (gesättigtes Rot). YCbCr kann aus RGB erhalten werden, ebenso ist die inverse Transformation möglich. Mit diesem Modell können wir Bilder in Farbe erstellen, wie wir unten sehen:

Konvertieren Sie zwischen YCbCr und RGB
Jemand wird Einwände erheben: Wie ist es möglich, alle Farben zu erhalten, wenn Grün nicht verwendet wird?
Konvertieren Sie RGB in YCbCr, um diese Frage zu beantworten. Wir verwenden die im
BT.601-Standard übernommenen Koeffizienten, die von der
ITU-R- Einheit empfohlen wurden. Dieses Gerät definiert digitale Videostandards. Zum Beispiel: Was ist 4K? Wie sollten die Bildrate, die Auflösung und das Farbmodell sein?
Zuerst berechnen wir die Helligkeit. Wir verwenden die von der ITU vorgeschlagenen Konstanten und ersetzen die RGB-Werte.
Y = 0,299
R + 0,587
G + 0,114
BNachdem wir die Helligkeit erhalten haben, werden wir die blauen und roten Farben trennen:
Cb = 0,564 (
B -
Y )
Cr = 0,713 (
R -
Y )
Und wir können mit YCbCr auch zurückkonvertieren und sogar grün werden:
R =
Y + 1,402
CrB =
Y + 1,772
CbG =
Y - 0,344
Cb - 0,714
CrIn der Regel verwenden Bildschirme (Monitore, Fernseher, Bildschirme usw.) nur das RGB-Modell. Dieses Modell kann jedoch auf verschiedene Arten organisiert werden:

Farb-Downsampling
Wenn das Bild als eine Kombination aus Helligkeit und Farbe dargestellt wird, können wir eine höhere Empfindlichkeit des menschlichen visuellen Systems für Helligkeit als für Farbe verwenden, wenn wir Informationen selektiv löschen. Farb-Downsampling ist eine Methode zum Codieren von Bildern mit einer niedrigeren Auflösung für Farbe als für Helligkeit.
Wie akzeptabel ist es, die Farbauflösung zu reduzieren?! Es stellt sich heraus, dass es bereits einige Schemata gibt, die beschreiben, wie Auflösung und Zusammenführung zu handhaben sind
(Endfarbe = Y + Cb + Cr).Diese Schemata sind als
Unterabtastsysteme bekannt und werden in Form eines 3-fachen Verhältnisses ausgedrückt -
a :
x :
y , das die Anzahl der Abtastungen von Luminanz- und Farbdifferenzsignalen bestimmt.
a - horizontale Standardabtastung (normalerweise gleich 4)
x - die Anzahl der Farbmuster in der ersten Pixelreihe (horizontale Auflösung relativ zu
a )
y ist die Anzahl der Farbmusteränderungen zwischen der ersten und der zweiten Pixelreihe.
Die Ausnahme ist 4 : 1 : 0 , wodurch ein Farbmuster in jedem 4 × 4-Helligkeitsauflösungsblock bereitgestellt wird.
Gängige Schemata, die in modernen Codecs verwendet werden:
- 4 : 4 : 4 (ohne Downsampling)
- 4 : 2 : 2
- 4 : 1 : 1
- 4 : 2 : 0
- 4 : 1 : 0
- 3 : 1 : 1
YCbCr 4: 2: 0 - Zusammenführungsbeispiel
Hier ist das kombinierte Bildfragment mit YCbCr 4: 2: 0. Bitte beachten Sie, dass wir nur 12 Bit pro Pixel ausgeben.
So sieht dasselbe Bild aus, das von den Haupttypen der Farbunterabtastung codiert wurde. Die erste Zeile ist das endgültige YCbCr, die untere Zeile zeigt die Farbauflösung. Aufgrund des geringen Qualitätsverlustes sehr gute Ergebnisse.

Denken Sie daran, wir haben 278 GB Speicherplatz für eine stundenlange Videodatei mit einer Auflösung von 720p und 30 Bildern pro Sekunde gezählt. Wenn wir YCbCr 4: 2: 0 verwenden, wird diese Größe um die Hälfte reduziert - 139 GB. Bisher ist es noch weit von einem akzeptablen Ergebnis entfernt.
Sie können das YCbCr-Histogramm selbst mit FFmpeg abrufen. In diesem Bild überwiegt Blau gegenüber Rot, was auf dem Histogramm selbst deutlich erkennbar ist.

Farbe, Helligkeit, Farbskala - Videoüberprüfung
Es wird empfohlen, dieses tolle Video anzuschauen. Dies erklärt, was Helligkeit ist, und tatsächlich sind alle Punkte in Bezug auf Helligkeit und Farbe darüber angeordnet.
Rahmentypen
Wir ziehen weiter. Versuchen wir, die Redundanz rechtzeitig zu beseitigen. Aber zuerst definieren wir eine grundlegende Terminologie. Angenommen, wir haben einen Film mit 30 Bildern pro Sekunde. Hier sind die ersten 4 Bilder:




Wir können viele Wiederholungen in Frames sehen: zum Beispiel einen blauen Hintergrund, der sich nicht von Frame zu Frame ändert. Um dieses Problem zu lösen, können wir sie abstrakt als drei Rahmentypen klassifizieren.
I-Frame ( I ntro Frame)
Der I-Frame (Referenzframe, Schlüsselframe, interner Frame) ist autonom. Unabhängig davon, was visualisiert werden muss, ist der I-Frame tatsächlich eine statische Fotografie. Der erste Frame ist normalerweise ein I-Frame, aber wir werden regelmäßig I-Frames weit entfernt von den ersten Frames beobachten.
P-Frame ( P redicted Frame)
Der P-Frame (Predicted Frame) nutzt die Tatsache, dass fast immer das aktuelle Bild mit dem vorherigen Frame abgespielt werden kann. Zum Beispiel ist im zweiten Frame die einzige Änderung der Vorwärtsball. Wir können Frame 2 erhalten, indem wir nur Frame 1 leicht modifizieren und nur den Unterschied zwischen diesen Frames verwenden. Informationen zum Erstellen von Frame 2 finden Sie in Frame 1, der vorangestellt ist.
←

B-Frame ( B i-prädiktiver Frame)
Was ist mit Links, die nicht nur auf frühere, sondern auch auf zukünftige Frames verweisen, um eine noch bessere Komprimierung zu erzielen? Dies ist im Grunde ein B-Frame (bidirektionaler Frame).
←
→
Zwischenrückzug
Diese Rahmentypen werden verwendet, um die beste Komprimierung zu erzielen. Wir werden im nächsten Abschnitt diskutieren, wie dies geschieht. In der Zwischenzeit stellen wir fest, dass der I-Frame im Hinblick auf den Speicher am „teuersten“ ist, der P-Frame viel billiger ist, aber der B-Frame die rentabelste Option für Video ist.

Zeitliche Redundanz (Inter-Frame-Vorhersage)
Schauen wir uns an, welche Möglichkeiten wir haben, um Zeitwiederholungen zu minimieren. Diese Art der Redundanz kann mit den Methoden der gegenseitigen Vorhersage gelöst werden.
Wir werden versuchen, so wenig Bits wie möglich für die Codierung einer Folge von Frames 0 und 1 zu verwenden.

Wir können
subtrahieren , nur Bild 1 von Bild 0 subtrahieren. Wir erhalten Bild 1, wir verwenden nur die Differenz zwischen diesem und dem vorherigen Bild, in der Tat codieren wir nur den resultierenden Rest.

Aber was ist, wenn ich Ihnen sage, dass es eine noch bessere Methode gibt, die noch weniger Bits verwendet? Lassen Sie uns zuerst Frame 0 in ein klares Raster von Blöcken aufteilen. Und dann versuchen wir, die Blöcke von Frame 0 mit Frame 1 zu vergleichen. Mit anderen Worten, wir bewerten die Bewegung zwischen Frames.
Aus Wikipedia - Bewegungskompensation blockieren
Die Blockbewegungskompensation unterteilt den aktuellen Frame in disjunkte Blöcke, und der Bewegungskompensationsvektor gibt den Ursprung der Blöcke an (ein häufiges Missverständnis ist, dass der vorherige Frame in disjunkte Blöcke unterteilt ist und Bewegungskompensationsvektoren angeben, wohin diese Blöcke gehen. Tatsächlich wird jedoch nicht der vorherige analysiert Der Rahmen und der nächste zeigen nicht, wo sich die Blöcke bewegen, sondern wo sie herkommen. Typischerweise überlappen sich die Quellblöcke im Quellrahmen. Einige Videokomprimierungsalgorithmen erfassen den aktuellen Frame aus Teilen nicht nur eines, sondern mehrerer zuvor übertragener Frames.

Im Auswertungsprozess sehen wir, dass sich der Ball von
( x = 0,
y = 25) nach
( x = 6,
y = 26) bewegt hat. Die Werte von
x und
y bestimmen den Bewegungsvektor. Ein weiterer Schritt, den wir unternehmen können, um die Bits zu speichern, besteht darin, nur die Differenz der Bewegungsvektoren zwischen der letzten Position des Blocks und der vorhergesagten Position zu codieren, sodass der endgültige Bewegungsvektor
(x = 6-0 = 6, y = 26-25 = 1) ist.In einer realen Situation würde dieser Ball in
n Blöcke unterteilt, aber dies ändert nichts am Wesen der Sache.
Objekte im Rahmen bewegen sich in drei Dimensionen. Wenn sich der Ball also bewegt, kann er optisch kleiner werden (oder mehr, wenn er sich in Richtung des Betrachters bewegt). Es ist normal, dass es keine perfekte Übereinstimmung zwischen Blöcken gibt. Hier ist eine kombinierte Ansicht unserer Einschätzung und des realen Bildes.

Wir sehen jedoch, dass bei Anwendung der Bewegungsschätzung die Daten für die Codierung merklich geringer sind als bei Verwendung der einfacheren Methode zur Berechnung des Deltas zwischen Frames.

Wie die eigentliche Bewegungskompensation aussehen wird
Diese Technik gilt sofort für alle Blöcke. Oft wird unser bedingter Bewegungsball in mehrere Blöcke gleichzeitig unterteilt.

,
Jupyter .
ffmpeg .
 ffmpeg") Intel Video Pro Analyzer
Intel Video Pro Analyzer ( , , ).
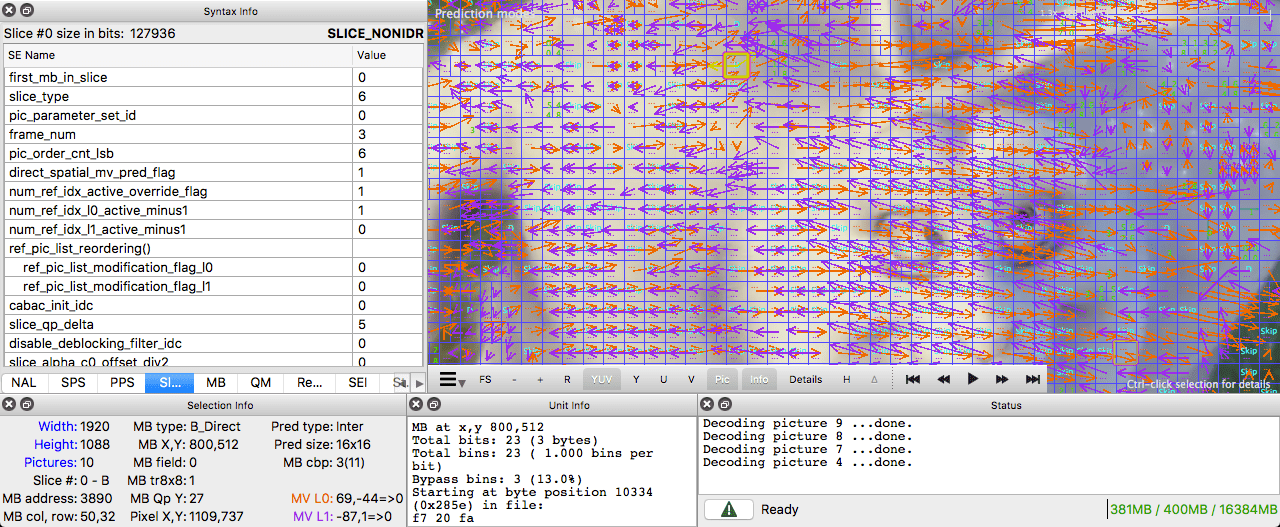
( )
, .

. .

I-. , . . , , - .
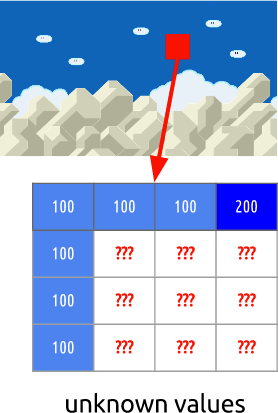
, . , .
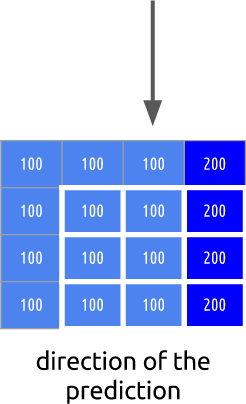
. ( ), . , .
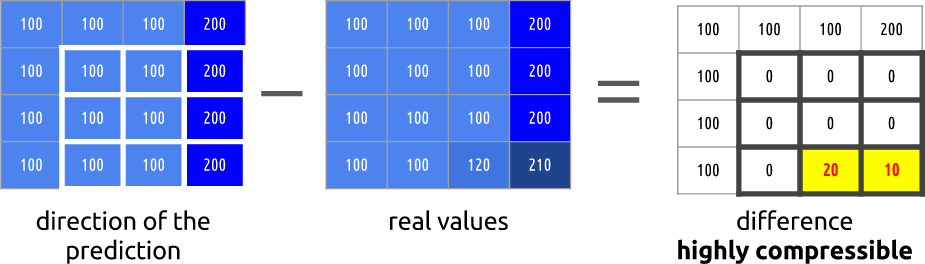
, ffmpeg. ffmpeg.
 ffmpeg")
Intel Video Pro Analyzer ( , 10 , ).

:

Lesen Sie auch den Blog
EDISON Unternehmen:
20 Bibliotheken für
spektakuläre iOS-Anwendung