Reinforcement Learning nutzt häufig Neugier als Motivation für KI. Ihn zwingen, neue Empfindungen zu suchen und die Welt zu erforschen. Aber das Leben ist voller unangenehmer Überraschungen. Sie können von einer Klippe fallen und aus der Sicht der Neugier wird es immer sehr neue und interessante Empfindungen sein. Aber offensichtlich nicht das, wonach man streben soll.
Die Entwickler aus Berkeley stellten die Aufgabe für den virtuellen Agenten auf den Kopf: Nicht die Neugier machte die Hauptmotivation aus, sondern der Wunsch, Neuheiten auf alle Fälle zu vermeiden. Aber "nichts tun" war schwieriger als es sich anhört. In einer sich ständig verändernden Umgebung musste die KI komplexes Verhalten lernen, um neue Empfindungen zu vermeiden.
Reinforcement Learning unternimmt zaghafte Schritte, um eine starke KI aufzubauen. Und während alles auf sehr geringe Dimensionen beschränkt ist, erscheinen buchstäblich die Einheiten, in denen der virtuelle Agent (vorzugsweise vernünftigerweise) agieren muss, von Zeit zu Zeit neue Ideen, wie das Training der künstlichen Intelligenz verbessert werden kann.
Aber nicht nur Lernalgorithmen sind kompliziert. Die Umwelt wird auch schwieriger. Die meisten Bestärkungslernumgebungen sind sehr einfach und motivieren den Agenten, die Welt zu erkunden. Es kann ein Labyrinth sein, das vollständig umgangen werden muss, um einen Ausweg zu finden, oder ein Computerspiel, das bis zum Ende abgeschlossen sein muss.
Aber auf lange Sicht streben Lebewesen (vernünftig und nicht so) nicht nur danach, die Welt um sie herum zu erkunden. Aber auch, um all das Gute zu bewahren, das in ihrem kurzen (oder nicht so kurzen) Leben steckt.
Dies wird Homöostase genannt - der Wunsch des Körpers, einen konstanten Zustand aufrechtzuerhalten. In der einen oder anderen Form ist dies allen Lebewesen gemeinsam. Entwickler aus Berkeley geben ein so merkwürdiges Beispiel: Alle Errungenschaften der Menschheit sollen im Großen und Ganzen vor unangenehmen Überraschungen schützen. Zum Schutz vor einer immer größer werdenden Entropie der Umwelt. Wir bauen Häuser, in denen wir eine konstante Temperatur aufrechterhalten, die vor Wetteränderungen geschützt ist. Wir benutzen Medizin, um ständig gesund zu sein und so weiter.
Man kann damit streiten, aber in dieser Analogie steckt wirklich etwas.
Die Jungs stellten die Frage: Was passiert, wenn die Hauptmotivation für die KI darin besteht, Neuheiten zu vermeiden? Minimieren Sie mit anderen Worten das Chaos als objektive Lernfunktion.
Und sie haben den Agenten in eine sich ständig verändernde gefährliche Welt gebracht.
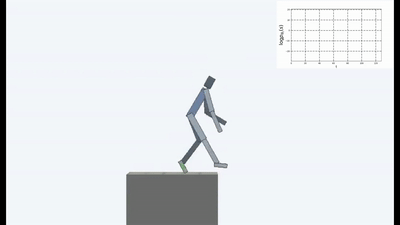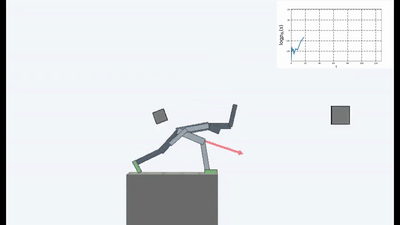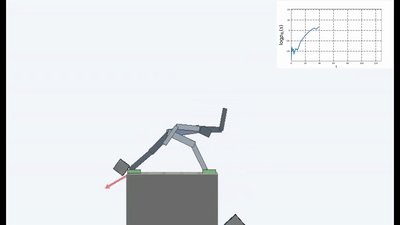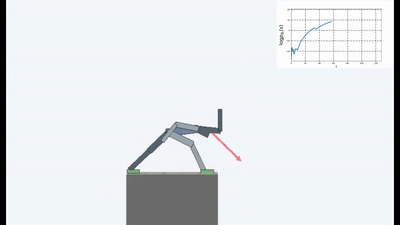
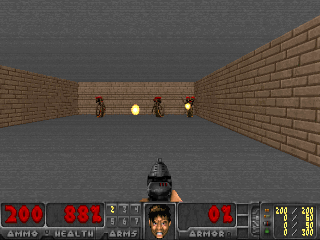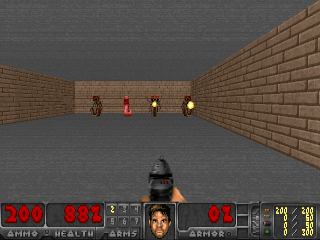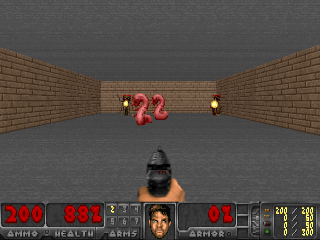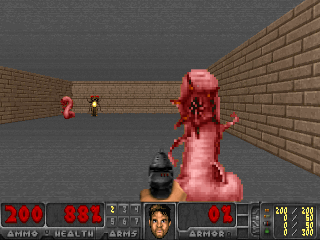
Die Ergebnisse waren interessant. In vielen Fällen hat ein solches Lernen das lehrplanbasierte Lernen übertroffen und kommt dem Lernen mit einem Lehrer in Bezug auf die Qualität meistens nahe. Das heißt, zu spezialisiertem Training, um ein bestimmtes Ziel zu erreichen - um das Spiel zu gewinnen, gehe durch das Labyrinth.
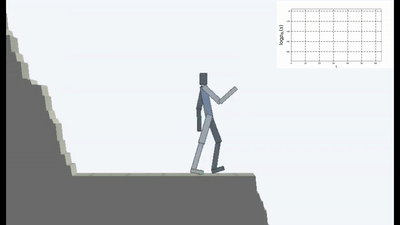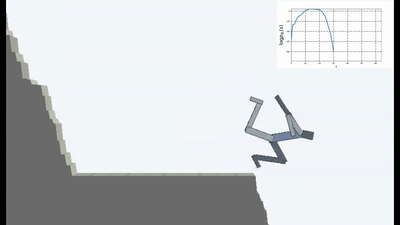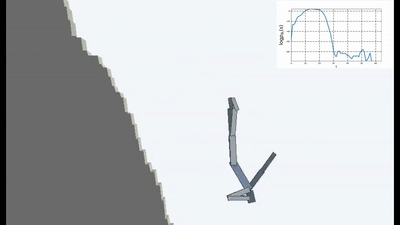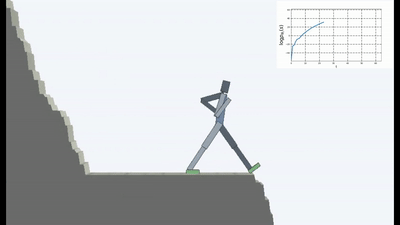
Das ist natürlich logisch, denn wenn Sie auf einer einstürzenden Brücke stehen, müssen Sie sich ständig von der Kante entfernen, um weiterhin auf ihr zu stehen (um die Konstanz aufrechtzuerhalten und neue Sturzgefühle zu vermeiden). Lauf mit aller Kraft davon, um still zu stehen, wie Alice sagte.

Tatsächlich gibt es in jedem Algorithmus zum Lernen der Verstärkung einen solchen Moment. Weil der Tod im Spiel und das schnelle Ende der Episode mit einer negativen Belohnung bestraft werden. Oder, abhängig vom Algorithmus, indem Sie die maximale Belohnung reduzieren, die ein Agent erhalten könnte, wenn er nicht kontinuierlich von der Klippe fällt.
Aber in einem solchen Umfeld, in dem die KI keine anderen Ziele verfolgt als den Wunsch, Neuheiten zu vermeiden, scheint es, als würde sie zum ersten Mal beim verstärkten Lernen eingesetzt.
Interessanterweise lernte der virtuelle Agent mit dieser Motivation, viele Spiele zu spielen, die ein Ziel haben, um zu gewinnen. Zum Beispiel Tetris.

Oder die Umgebung von Doom, in der Sie fliegenden Feuerbällen ausweichen und auf sich nähernde Gegner schießen müssen. Weil viele Aufgaben als Aufgaben zur Aufrechterhaltung der Konstanz formuliert werden können. Für Tetris ist dies der Wunsch, das Feld leer zu halten. Füllt sich der Bildschirm ständig? Oh je, was wird passieren, wenn es bis zum Ende gefüllt ist? Nein, nein, wir brauchen kein solches Glück. Zu viel Schock.
Von der technischen Seite ist es ganz einfach angeordnet. Wenn ein Agent einen neuen Status erhält, bewertet er, wie vertraut dieser Status ist. Das heißt, wie viel der neue Staat in der Verteilung des Staates enthalten ist, den er zuvor besucht hat. Der Agent wird umso vertrauter, je höher die Belohnung ist. Und die Aufgabe der Lernpolitik (all das sind die Begriffe aus dem Reinforcement Learning, wenn jemand sie nicht kennt) besteht darin, Maßnahmen zu wählen, die zum Übergang in den vertrautesten Zustand führen würden. Außerdem wird jeder neue Status verwendet, um die Statistiken bekannter Status zu aktualisieren, mit denen neue Status verglichen werden.
Interessanterweise lernte ich im Verlauf der KI spontan zu verstehen, dass neue Zustände das beeinflussen, was als Neuheit angesehen wird. Und dass Sie vertraute Zustände auf zwei Arten erreichen können: entweder in einen bereits bekannten Zustand. Oder gehen Sie in einen Zustand, der das Konzept der Persistenz / Vertrautheit der Umgebung aktualisiert , und der Agent wird in einem neuen, durch seine Handlungen gebildeten, vertrauten Zustand sein.
Dies zwingt den Agenten, komplexe koordinierte Aktionen durchzuführen, wenn auch nur, um nichts im Leben zu tun.
Paradoxerweise führt dies zu einem Analogon der Neugierde des gewöhnlichen Lernens und zwingt den Agenten, die Welt um ihn herum zu erkunden. Plötzlich gibt es irgendwo einen Ort, der noch sicherer ist als hier und jetzt? Dort können Sie sich vollkommen der Faulheit hingeben und absolut nichts tun, um Probleme und neue Empfindungen zu vermeiden. Es wäre keine Übertreibung zu sagen, dass solche Gedanken wahrscheinlich jedem von uns einfielen. Und für viele ist dies eine echte treibende Kraft im Leben. Obwohl im wirklichen Leben keiner von uns damit zu tun hatte, dass Tetris bis zum Rand aufgefüllt wurde, war dies natürlich nicht der Fall.
Um ehrlich zu sein, ist dies eine komplizierte Geschichte. Aber die Praxis zeigt, dass es funktioniert. Die Forscher verglichen diesen Algorithmus mit den neugierigsten Vertretern: ICM und RND . Der erste ist ein wirksamer Mechanismus der Neugier, der beim Lernen mit Verstärkung bereits zum Klassiker geworden ist. Der Agent strebt nicht einfach nach neuen ungewohnten und damit interessanten Zuständen. Die Unbekanntheit der Situation in solchen Algorithmen wird dadurch abgeschätzt, ob der Agent sie vorhersagen kann (in den früheren gab es buchstäblich Zähler für besuchte Zustände, aber jetzt ist alles auf die integrale Schätzung hinausgegangen, die das neuronale Netzwerk liefert). Aber in diesem Fall hätten die sich bewegenden Blätter auf den Bäumen oder das weiße Rauschen im Fernsehen für einen solchen Agenten eine unendliche Neuheit und ein unendliches Gefühl der Neugierde hervorgerufen. Weil er niemals alle möglichen neuen Zustände in einer völlig zufälligen Umgebung vorhersagen kann.
Daher sucht ein Agent in ICM nur nach den neuen Zuständen, die er mit seinen Aktionen beeinflussen kann. Kann AI weißes Rauschen im Fernsehen beeinflussen? Nein. So uninteressant. Und kann es den Ball beeinflussen, wenn Sie ihn bewegen? Ja Es ist also interessant, mit dem Ball zu spielen. Dazu verwendet ICM eine sehr coole Idee mit dem Inverse Model, mit dem das Forward Model verglichen wird. Weitere Details in der Originalarbeit .
RND ist eine neuere Entwicklung des Neugiermechanismus. Was in der Praxis ICM übertroffen hat. Kurz gesagt, das neuronale Netzwerk versucht, die Ausgaben eines anderen neuronalen Netzwerks vorherzusagen, das durch zufällige Gewichte initiiert wird und sich nie ändert. Es wird angenommen, dass das aktuelle neuronale Netzwerk umso häufiger in der Lage ist, zufällig initiierte Ausgaben vorherzusagen, je vertrauter die Situation ist (die dem Eingang beider neuronaler Netze zugeführt wird, aktuell und zufällig initiiert). Ich weiß nicht, wer das alles erfindet. Einerseits möchte ich einer solchen Person die Hand geben und andererseits einen Kick für solche Verzerrungen geben.
Aber auf die eine oder andere Art und Weise und mit dem Gedanken der Aufrechterhaltung der Homöostase und dem Versuch, Neuheiten zu vermeiden, wurde in der Praxis in vielen Fällen ein besseres Endergebnis erzielt als mit einem Lehrplan, der auf ICN oder RND basiert. Was spiegelt sich in den Grafiken wider?
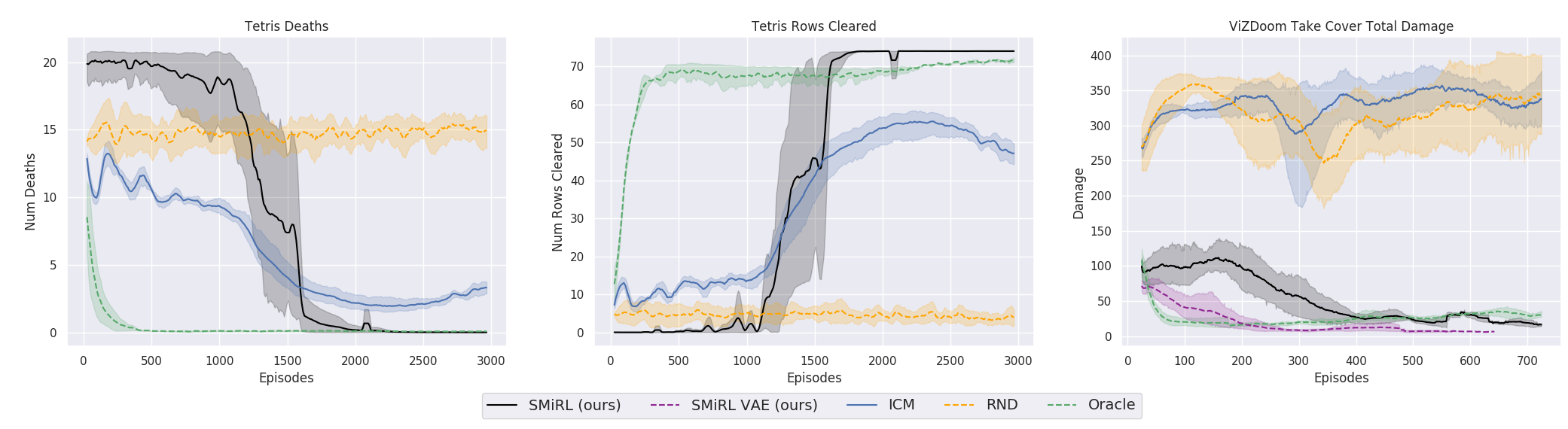
Hier muss jedoch klargestellt werden, dass dies nur für die Umgebungen gilt, die die Forscher in ihrer Arbeit verwendet haben. Sie sind gefährlich, zufällig, laut und mit zunehmender Entropie. Es kann wirklich rentabler sein, nichts in ihnen zu tun. Und nur gelegentlich bewegt es sich aktiv, wenn ein Feuerball in Ihnen fliegt oder die Brücke hinter Ihnen zusammenbricht. Forscher aus Berkeley bestehen jedoch offenbar aufgrund ihrer schwierigen Lebenserfahrung darauf, dass solche Umgebungen dem komplexen wirklichen Leben viel näher kommen als bisher im Verstärkungstraining. Nun, ich weiß es nicht, ich weiß es nicht. In meinem Leben werden Feuerbälle von Monstern, die in mich hineinfliegen, und unbewohnte Labyrinthe mit einem einzigen Ausgang mit ungefähr der gleichen Häufigkeit gefunden. Es ist jedoch nicht zu leugnen, dass der vorgeschlagene Ansatz trotz seiner Einfachheit erstaunliche Ergebnisse erbracht hat. Vielleicht sollten in Zukunft beide Ansätze sinnvoll kombiniert werden - Homöostase mit Erhalt der langfristigen positiven Konstanz und Neugier für aktuelle Umweltstudien.
Link zur Originalarbeit