
Der Zweck dieses Artikels ist es, dem neuronalen Netzwerk beizubringen, das Life-Spiel zu spielen, ohne ihm die Spielregeln beizubringen.
Hallo habr Ich präsentiere Ihnen die Übersetzung des Artikels "Conways Spiel des Lebens mit Keras mithilfe eines neuronalen Faltungsnetzwerks" von kylewbanks.
Wenn Sie mit dem Spiel "Life" ( ein vom englischen Mathematiker John Conway 1970 erfundener Zellularautomat) nicht vertraut sind, gelten folgende Regeln.
Das Spieluniversum ist ein unendliches, zweidimensionales Gitter aus quadratischen Zellen, von denen sich jede in einem von zwei möglichen Zuständen befindet: lebend oder tot (oder bewohnt bzw. unbewohnt). Jede Zelle interagiert horizontal, vertikal oder diagonal mit ihren acht Nachbarn. Zu jedem Zeitschritt treten die folgenden Übergänge auf:
- Jede lebende Zelle mit weniger als zwei lebenden Nachbarn stirbt.
- Jede lebende Zelle mit zwei oder drei lebenden Nachbarn überlebt bis zur nächsten Generation.
- Jede lebende Zelle mit mehr als drei lebenden Nachbarn stirbt.
- Jede tote Zelle mit genau drei lebenden Nachbarn wird zu einer lebenden Zelle.
Die erste Generation wird durch gleichzeitiges Anwenden der oben genannten Regeln auf jede Zelle im Ausgangszustand erstellt. Geburt und Tod erfolgen gleichzeitig zu bestimmten Zeitpunkten. Jede Generation ist eine reine Funktion der vorherigen. Die Regeln gelten weiterhin für die neue Generation, um die nächste Generation zu erstellen.
Siehe Wikipedia für Details.
Warum das machen? Hauptsächlich zur Unterhaltung und um ein wenig über Faltungs-Neuronale Netze zu lernen.
Also ...
Spiellogik
Als Erstes müssen Sie eine Funktion definieren, die das Spielfeld als Eingabe verwendet und den nächsten Status zurückgibt.
Glücklicherweise stehen im Internet viele Implementierungen zur Verfügung, z. B .: https://jakevdp.imtqy.com/blog/2013/08/07/conways-game-of-life/ .
Tatsächlich wird die Matrix des Spielfelds als Eingabe verwendet, wobei 0 eine tote Zelle darstellt und 1 eine lebende Zelle darstellt und eine Matrix derselben Größe zurückgibt, die jedoch den Status jeder Zelle bei der nächsten Iteration des Spiels enthält.
import numpy as np def life_step(X): live_neighbors = sum(np.roll(np.roll(X, i, 0), j, 1) for i in (-1, 0, 1) for j in (-1, 0, 1) if (i != 0 or j != 0)) return (live_neighbors == 3) | (X & (live_neighbors == 2)).astype(int)
Spielfeldgenerierung
Nach der Spielelogik brauchen wir eine Möglichkeit, Spielfelder nach dem Zufallsprinzip zu generieren und sie zu visualisieren.
Die Funktion generate_frames erstellt num_frames zufälligen Spielfeldern mit einer bestimmten Form und einer festgelegten Wahrscheinlichkeit, dass jede Zelle "live" ist, und render_frames zeichnet zum Vergleich Darstellungen von Bildern zweier Spielfelder nebeneinander (lebende Zellen sind weiß und tote Zellen sind schwarz):
import matplotlib.pyplot as plt def generate_frames(num_frames, board_shape=(100,100), prob_alive=0.15): return np.array([ np.random.choice([False, True], size=board_shape, p=[1-prob_alive, prob_alive]) for _ in range(num_frames) ]).astype(int) def render_frames(frame1, frame2): plt.subplot(1, 2, 1) plt.imshow(frame1.flatten().reshape(board_shape), cmap='gray') plt.subplot(1, 2, 2) plt.imshow(frame2.flatten().reshape(board_shape), cmap='gray')
Mal sehen, wie diese Felder aussehen:
board_shape = (20, 20) board_size = board_shape[0] * board_shape[1] probability_alive = 0.15 frames = generate_frames(10, board_shape=board_shape, prob_alive=probability_alive) print(frames.shape)
(10, 20, 20)
print(frames[0])
[[0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1], [1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0]])
Als nächstes wird eine ganzzahlige Darstellung des Spielfelds aufgenommen und als Bild angezeigt.
Der folgende Zustand des Spielfelds wird auch rechts mit der Funktion life_step :
ender_frames(frames[1], life_step(frames[1]))

Erstellen von Trainings- und Test-Sets
Jetzt können wir Daten für Schulungen, Überprüfungen und Tests generieren.
Jedes Element in den y_test y_train / y_val / y_test repräsentiert das nächste Spielfeld für jeden X_train in X_train / X_val / X_test .
def reshape_input(X): return X.reshape(X.shape[0], X.shape[1], X.shape[2], 1) def generate_dataset(num_frames, board_shape, prob_alive): X = generate_frames(num_frames, board_shape=board_shape, prob_alive=prob_alive) X = reshape_input(X) y = np.array([ life_step(frame) for frame in X ]) return X, y train_size = 70000 val_size = 10000 test_size = 20000
print("Training Set:") X_train, y_train = generate_dataset(train_size, board_shape, probability_alive) print(X_train.shape) print(y_train.shape)
Training Set: (70000, 20, 20, 1) (70000, 20, 20, 1)
print("Validation Set:") X_val, y_val = generate_dataset(val_size, board_shape, probability_alive) print(X_val.shape) print(y_val.shape)
Validation Set: (10000, 20, 20, 1) (10000, 20, 20, 1)
print("Test Set:") X_test, y_test = generate_dataset(test_size, board_shape, probability_alive) print(X_test.shape) print(y_test.shape)
Test Set: (20000, 20, 20, 1) (20000, 20, 20, 1)
Faltungsneuraler Netzwerkaufbau
Jetzt können wir den ersten Schritt zum Aufbau eines Faltungsnetzwerks mit Keras machen. Der entscheidende Punkt hierbei ist die Kernelgröße (3, 3) und Schritt 1. Sie weisen CNN an, eine 3 × 3-Matrix von umgebenden Zellen für jede Zelle in dem Feld zu verwenden, das sie betrachtet, einschließlich der aktuellen Zelle.
Wenn zum Beispiel das Folgende ein Spielfeld wäre und wir uns in der mittleren Zelle x , würde sie alle mit einem Ausrufezeichen markierten Zellen ansehen ! und Zelle
0 0 0 0 0 0! ! ! 0 0! x ! 0 0! ! ! 0 0 0 0 0 0
Der Rest des Netzwerks ist ziemlich einfach, daher werde ich nicht auf Details eingehen. Wenn Sie an etwas interessiert sind, empfehle ich, die Dokumentation zu lesen.
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Conv2D, MaxPool2D
Schauen Sie sich die Ausgabe der summary Funktion an:
model.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_9 (Conv2D) (None, 20, 20, 50) 500 _________________________________________________________________ dense_17 (Dense) (None, 20, 20, 100) 5100 _________________________________________________________________ dense_18 (Dense) (None, 20, 20, 1) 101 _________________________________________________________________ activation_9 (Activation) (None, 20, 20, 1) 0 ================================================================= Total params: 5,701 Trainable params: 5,701 Non-trainable params: 0 _________________________________________________________________
Ein Modell trainieren und speichern
Nachdem Sie CNN erstellt haben, trainieren Sie das Modell und speichern es auf der Festplatte:
def train(model, X_train, y_train, X_val, y_val, batch_size=50, epochs=2, filename_suffix=''): model.fit( X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_val, y_val) ) with open('cgol_cnn{}.json'.format(filename_suffix), 'w') as file: file.write(model.to_json()) model.save_weights('cgol_cnn{}.h5'.format(filename_suffix)) train(model, X_train, y_train, X_val, y_val, filename_suffix='_basic')
Train on 70000 samples, validate on 10000 samples Epoch 1/2 70000/70000 [==============================] - 27s 388us/step - loss: 0.1324 - acc: 0.9651 - val_loss: 0.0833 - val_acc: 0.9815 Epoch 2/2 70000/70000 [==============================] - 27s 383us/step - loss: 0.0819 - acc: 0.9817 - val_loss: 0.0823 - val_acc: 0.9816
Dieses Modell bietet eine Genauigkeit von etwas mehr als 98% für Trainings- und Testsätze, was für den ersten Durchgang sehr gut ist. Versuchen wir herauszufinden, wo wir Fehler machen.
Versuchen Sie es
Schauen wir uns die Vorhersage für ein zufälliges Spielfeld an und wie es funktioniert. Erstellen Sie zunächst ein Spielfeld und schauen Sie sich das richtige nächste Bild an:
X, y = generate_dataset(1, board_shape=board_shape, prob_alive=probability_alive) render_frames(X[0].flatten().reshape(board_shape), y)

Als nächstes machen wir die Vorhersage und sehen, wie viele Zellen falsch vorhergesagt wurden:
pred = model.predict_classes(X) print(np.count_nonzero(pred.flatten() - y.flatten()), "incorrect cells.")
4 incorrect cells.
Als nächstes vergleichen wir den richtigen nächsten Schritt mit dem vorhergesagten Schritt:
render_frames(y, pred.flatten().reshape(board_shape))
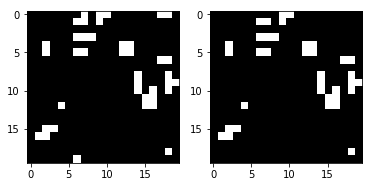
Es ist nicht beängstigend, aber sehen Sie, wo die Vorhersage fehlgeschlagen ist? Es scheint, dass das Netzwerk keine Zellen an den Rändern des Spielfelds vorhersagen kann. Schauen wir uns an, wo Werte ungleich Null auf falsche Vorhersagen hinweisen:
print(pred.flatten().reshape(board_shape) - y.flatten().reshape(board_shape))
[[ 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 -1 -1 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 0 0 0 0]]
Wie Sie sehen, befinden sich alle Nicht-Null-Werte an den Rändern des Spielfelds. Schauen wir uns die vollständige Testsuite an und bestätigen Sie, dass diese Beobachtung wahr ist.
Zeigen Sie Fehler in der Testsuite an
Wir werden eine Funktion schreiben, die eine Heatmap anzeigt, die zeigt, wo das Modell Fehler macht, und sie mit der gesamten Testsuite aufrufen:
def view_prediction_errors(model, X, y): y_pred = model.predict_classes(X) sum_y_pred = np.sum(y_pred, axis=0).flatten().reshape(board_shape) sum_y = np.sum(y, axis=0).flatten().reshape(board_shape) plt.imshow(sum_y_pred - sum_y, cmap='hot', interpolation='nearest') plt.show() view_prediction_errors(model, X_test, y_test)

Alle Fehler an den Kanten und Ecken. Das ist logisch, da CNN sich nicht umsehen kann, aber die Logik des Spiels in life_step tut dies. Betrachten Sie beispielsweise Folgendes. Betrachtet man die Randzelle x unten, sieht CNN nur x und ! Zellen:
0 0 0 0 0 ! ! 0 0 0 x ! 0 0 0 ! ! 0 0 0 0 0 0 0 0
Aber was wir wirklich wollen und was life_step tut, ist, die Zellen von der anderen Seite zu betrachten:
0 0 0 0 0 ! ! 0 0 ! x ! 0 0 ! ! ! 0 0 ! 0 0 0 0 0
Eine ähnliche Situation in den Ecken:
x ! 0 0 ! ! ! 0 0 ! 0 0 0 0 0 0 0 0 0 0 ! 0 0 0 !
Um dies zu beheben, muss Conv2D irgendwie auf die gegenüberliegende Seite des Spielfelds schauen. Alternativ kann jedes Eingabefeld vorverarbeitet werden, um die Kanten auf der gegenüberliegenden Seite auszufüllen, und Conv2D kann dann einfach die erste oder letzte Spalte und Zeile löschen. Da wir Keras und der darin enthaltenen Füllfunktionalität ausgeliefert sind, die nicht das unterstützen, wonach wir suchen, müssen wir auf das Hinzufügen unserer eigenen Füllung zurückgreifen.
Korrektur von Kantendefekten durch Füllung
Wir müssen jedes Spielfeld mit einem entgegengesetzten Wert ergänzen, um nachzuahmen, wie life_step für life_step funktioniert. Wir können hierfür np.pad mit mode = 'wrap' . Betrachten Sie beispielsweise das folgende Array und die erweiterte Ausgabe:
x = np.array([ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]) print(np.pad(x, (1, 1), mode='wrap'))
[[9, 7, 8, 9, 7], [3, 1, 2, 3, 1], [6, 4, 5, 6, 4], [9, 7, 8, 9, 7], [3, 1, 2, 3, 1]]
Beachten Sie, dass die erste Spalte / Zeile und die letzte Spalte / Zeile die entgegengesetzte Seite der ursprünglichen Matrix widerspiegeln und die mittlere 3x3-Matrix der ursprüngliche x Wert ist. Zum Beispiel wurde Zelle [1] [1] auf der gegenüberliegenden Seite in Zelle [4] [1] kopiert und enthält ähnlich wie [0] [1] [3] [1]. In alle Richtungen und sogar in Ecken wurde das Array so korrigiert, dass es die gegenüberliegende Seite enthielt. Auf diese Weise kann CNN das gesamte Spielfeld überprüfen und Extremfälle korrekt behandeln.
Jetzt können wir eine Funktion schreiben, um alle unsere Eingabematrizen zu füllen:
def pad_input(X): return reshape_input(np.array([ np.pad(x.reshape(board_shape), (1,1), mode='wrap') for x in X ])) X_train_padded = pad_input(X_train) X_val_padded = pad_input(X_val) X_test_padded = pad_input(X_test) print(X_train_padded.shape) print(X_val_padded.shape) print(X_test_padded.shape)
(70000, 22, 22, 1) (10000, 22, 22, 1) (20000, 22, 22, 1)
Alle Datensätze werden jetzt durch umbrochene Spalten / Zeilen ergänzt, life_step CNN wie life_step die gegenüberliegende Seite des Spielfelds sehen kann. Aus diesem Grund hat jedes Spielfeld jetzt eine Größe von 22 x 22 anstelle der ursprünglichen 20 x 20.
Dann sollte CNN neu aufgebaut werden, um das Auffüllen mit padding = 'valid' zu verwerfen (was Conv2D anweist, Kanten zu verwerfen, obwohl dies nicht sofort offensichtlich ist), und mit der neuen input_shape . Wenn wir also Spielfelder mit einer Größe von 22x22 überspringen, erhalten wir immer noch eine Größe von 20x20 als Ausgabe, da wir die erste und letzte Spalte / Zeile verwerfen. Der Rest bleibt identisch:
model_padded = Sequential() model_padded.add(Conv2D( filters, kernel_size, padding='valid', activation='relu', strides=strides, input_shape=(board_shape[0] + 2, board_shape[1] + 2, 1) )) model_padded.add(Dense(hidden_dims)) model_padded.add(Dense(1)) model_padded.add(Activation('sigmoid')) model_padded.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model_padded.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_10 (Conv2D) (None, 20, 20, 50) 500 _________________________________________________________________ dense_19 (Dense) (None, 20, 20, 100) 5100 _________________________________________________________________ dense_20 (Dense) (None, 20, 20, 1) 101 _________________________________________________________________ activation_10 (Activation) (None, 20, 20, 1) 0 ================================================================= Total params: 5,701 Trainable params: 5,701 Non-trainable params: 0 _________________________________________________________________
Jetzt können wir mit dem ausgerichteten Feld lernen:
train( model_padded, X_train_padded, y_train, X_val_padded, y_val, filename_suffix='_padded' )
Train on 70000 samples, validate on 10000 samples Epoch 1/2 70000/70000 [==============================] - 27s 389us/step - loss: 0.0604 - acc: 0.9807 - val_loss: 4.5475e-04 - val_acc: 1.0000 Epoch 2/2 70000/70000 [==============================] - 27s 382us/step - loss: 1.7058e-04 - acc: 1.0000 - val_loss: 5.9932e-05 - val_acc: 1.0000
Die Genauigkeit der Vorhersage liegt zwischen 98% und 100%, die wir vor dem Hinzufügen der Einrückung erhalten haben. Schauen wir uns den Fehler im Testfall an:
view_prediction_errors(model_padded, X_test_padded, y_test)

Großartig! Die schwarze Heatmap zeigt an, dass es keine Unterschiede in den Werten gibt. Dies bedeutet, dass wir jede Zelle für jedes Spiel erfolgreich vorhergesagt haben.
Es war eine lustige kleine Übung, mit Faltungsnetzwerken zu spielen, ohne einen großen Datensatz zu verwenden. Fühlen Sie sich frei, sich bei GitHub umzusehen .