Es war lange eine Idee zu sehen, was Sie mit ELK und improvisierten Quellen für Protokolle und Statistiken tun können. Auf den Seiten des Habr möchte ich ein praktisches Beispiel zeigen, wie Sie mit einem Heim-Mini-Server beispielsweise einen Honeypot mit einem Protokollanalysesystem auf der Basis des ELK-Stacks erstellen können. In diesem Artikel werde ich Ihnen das einfachste Beispiel für die Analyse von Firewall-Protokollen mit dem ELK-Stack erläutern. In Zukunft möchte ich die Umgebungseinstellungen für die Analyse von Netflow-Verkehr und PCAP-Dumps von Zeek beschreiben.
Wenn Sie eine öffentliche IP-Adresse und ein mehr oder weniger intelligentes Gerät als Gateway / Firewall haben, können Sie einen passiven Honeypot organisieren, indem Sie die Protokollierung eingehender Anforderungen an "köstlichen" TCP- und UDP-Ports konfigurieren. Es gibt ein Beispiel für die Konfiguration eines Mikrotik-Routers unter dem Cutter. Wenn Sie jedoch einen Router eines anderen Herstellers (oder ein anderes Sicherheitssystem) zur Hand haben, müssen Sie nur einige Datenformate und herstellerspezifische Einstellungen herausfinden, und Sie erhalten das gleiche Ergebnis.
Haftungsausschluss
Der Artikel gibt nicht vor, originell zu sein. Er befasst sich nicht mit Fragen der Fehlertoleranz von Diensten, der Sicherheit, bewährten Methoden usw. Es ist notwendig, dieses Material als akademisch zu betrachten. Es ist geeignet, um mit der Grundfunktionalität des ELK-Stacks und dem Protokollanalysemechanismus des Netzwerkgeräts vertraut zu werden. Es könnte jedoch auch für Anfänger interessant sein.
Das Projekt wird über die Docker-Compose-Datei gestartet. Die Bereitstellung einer ähnlichen Umgebung ist sehr einfach. Auch wenn Sie einen Router eines anderen Anbieters zur Hand haben, müssen Sie nur ein wenig über Datenformate und herstellerspezifische Einstellungen wissen. Im Übrigen habe ich versucht, alle mit der Konfiguration von Logstash-Pipelines und Elasticsearch-Zuordnungen in der aktuellen Version von ELK verbundenen Nuancen so detailliert wie möglich zu beschreiben. Alle Komponenten dieses Systems werden auf
github gehostet, einschließlich Dienstkonfigurationen. Am Ende des Artikels werde ich den Abschnitt Fehlerbehebung ausführen, in dem die Schritte zur Diagnose der gängigen Probleme beschrieben werden, mit denen Neulinge in diesem Geschäft konfrontiert sind.
Einleitung
Auf dem Server selbst habe ich das Proxmox-Virtualisierungssystem installiert, auf dem auf dem KVM-Rechner Docker-Container gestartet werden. Es wird davon ausgegangen, dass Sie wissen, wie Docker und Docker-Compose funktionieren, da es genügend Konfigurationsbeispiele zur Internetnutzung gibt. Ich werde nicht auf die Probleme bei der Installation von Docker eingehen, sondern ein wenig über Docker-Compose schreiben.
Die Idee, Honeypot auf den Markt zu bringen, entstand während des Studiums von Elasticsearch, Logstash und Kibana. In meiner beruflichen Laufbahn war ich noch nie mit der Verwaltung und allgemeinen Verwendung dieses Stacks befasst, aber ich habe Hobbyprojekte durchgeführt, die mich sehr daran interessiert haben, die Möglichkeiten der Elasticsearch- und Kibana-Suchmaschine zu erkunden, mit denen Daten analysiert und visualisiert werden können.
Mein nicht der neueste Mini-NUC-Server mit 8 GB RAM reicht gerade aus, um den ELK-Stack mit einem Elastic-Knoten zu starten. In Produktionsumgebungen ist dies natürlich nicht zu empfehlen, aber genau richtig für das Training. Zum Thema Sicherheit steht am Ende des Artikels eine Bemerkung.
Das Internet enthält
zahlreiche Anweisungen zum Installieren und Konfigurieren des ELK-Stacks für ähnliche Aufgaben (z. B.
Analysieren von Brute-Force-Angriffen auf ssh mit Logstash Version 2 ,
Analysieren von Suricata-Protokollen mit Filebeat Version 6 ). In den meisten Fällen wird jedoch nicht auf Details geachtet 90 Prozent des Materials werden für die Versionen 1 bis 6 sein (zum Zeitpunkt des Schreibens ist die aktuelle Version von ELK 7.5.0). Dies ist wichtig, da Elasticsearch ab Version 6
beschlossen hat, die Entität "Zuordnungstyp"
zu entfernen , wodurch die Abfragesyntax und die Zuordnungsstruktur geändert wurden. Das Zuordnen von Vorlagen in Elastic ist im Allgemeinen ein sehr wichtiges Objekt, und damit später keine Probleme mit der Datenerfassung und -visualisierung auftreten, rate ich Ihnen, sich nicht auf das Kopieren und Einfügen einzulassen und zu versuchen, zu verstehen, was Sie tun. Weiterhin werde ich versuchen klar zu erklären, was die beschriebenen Operationen und Konfigurationen bedeuten.
Router einrichten
Für das Heimnetzwerk verwende ich Mikrotik als Router, also wird ein Beispiel für ihn sein. Fast jedes System kann so konfiguriert werden, dass Syslog an einen Remote-Server gesendet wird, sei es ein Router, ein Server oder ein anderes Sicherheitssystem, das Protokolle erstellt.
Senden von Syslog-Nachrichten an einen Remote-Server
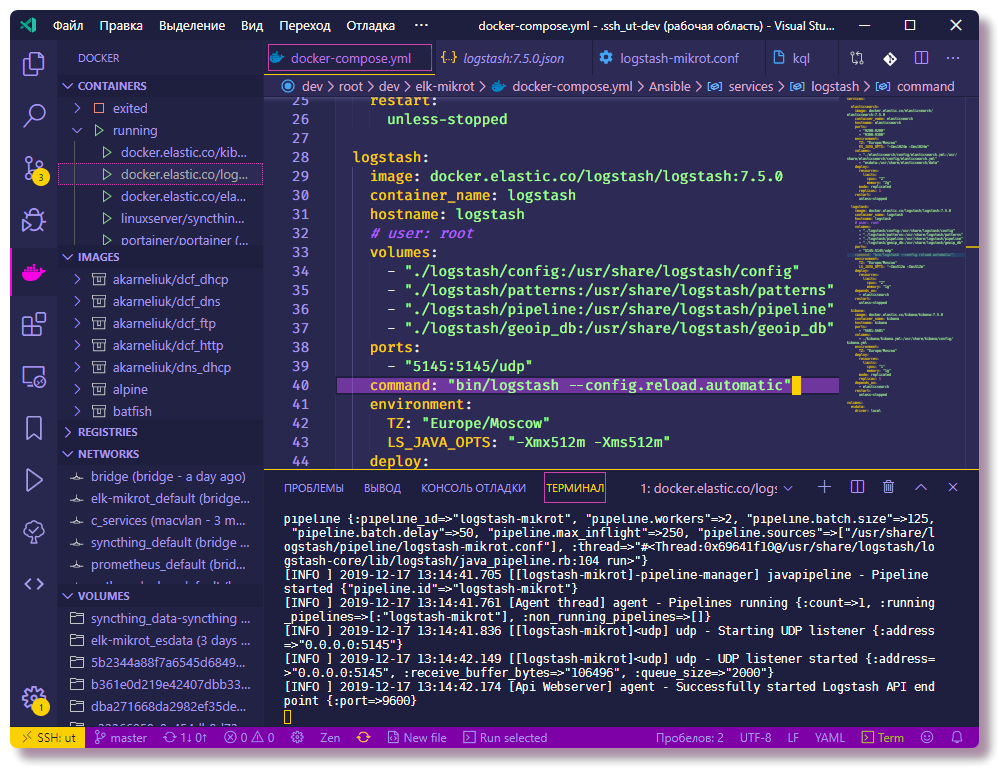
Um in Mikrotik die Protokollierung auf einem Remote-Server über die CLI zu konfigurieren, geben Sie einfach ein paar Befehle ein:
/system logging action add remote=192.168.88.130 remote-port=5145 src-address=192.168.88.1 name=logstash target=remote /system logging add action=logstash topics=info
Konfigurieren von Firewallregeln mit der Protokollierung
Wir interessieren uns nur für bestimmte Daten (Hostname, IP-Adresse, Benutzername, URL usw.), aus denen Sie eine schöne Visualisierung oder Auswahl erhalten können. Um Informationen zu Port-Scans und Zugriffsversuchen zu erhalten, müssen Sie im einfachsten Fall die Firewall-Komponente so konfigurieren, dass sie Regel-Trigger protokolliert. Ich habe die Regeln in der NAT-Tabelle in Mikrotik und nicht in Filter konfiguriert, da ich in Zukunft Chanipots einrichten werde, die die Arbeit von Diensten emulieren. Auf diese Weise kann ich mehr Informationen über das Verhalten von Botnetzen erhalten, dies ist jedoch ein fortgeschritteneres Szenario und nicht zu diesem Zeitpunkt.
Achtung! In der folgenden Konfiguration wird der Standard-TCP-Port des SSH-Dienstes (22) in das lokale Netzwerk eingeschleift. Wenn Sie mit SSH von außen auf den Router zugreifen und die Einstellungen über Port 22 verfügen (
IP-Dienst in der CLI
drucken und
IP> -Dienste in Winbox), sollten Sie den Port für Management-SSH neu zuweisen oder die letzte Regel nicht in die Tabelle eingeben.
Abhängig vom Namen der WAN-Schnittstelle (wenn die WAN-Bridge nicht verwendet wird) müssen Sie auch den Parameter für die
Schnittstelle in den entsprechenden ändern.
/ip firewall nat add action=netmap chain=dstnat comment="HONEYPOT RDP" dst-port=3389 in-interface=bridge-wan log=yes log-prefix=honeypot_rdp protocol=tcp to-addresses=192.168.88.201 to-ports=3389 add action=netmap chain=dstnat comment="HONEYPOT ELASTIC" dst-port=9200 in-interface=bridge-wan log=yes log-prefix=honeypot_elastic protocol=tcp to-addresses=192.168.88.201 to-ports=9211 add action=netmap chain=dstnat comment=" HONEYPOT TELNET" dst-port=23 in-interface=bridge-wan log=yes log-prefix=honeypot_telnet protocol=tcp to-addresses=192.168.88.201 to-ports=2325 add action=netmap chain=dstnat comment="HONEYPOT DNS" dst-port=53 in-interface=bridge-wan log=yes log-prefix=honeypot_dns protocol=udp to-addresses=192.168.88.201 to-ports=9953 add action=netmap chain=dstnat comment="HONEYPOT FTP" dst-port=21 in-interface=bridge-wan log=yes log-prefix=honeypot_ftp protocol=tcp to-addresses=192.168.88.201 to-ports=9921 add action=netmap chain=dstnat comment="HONEYPOT SMTP" dst-port=25 in-interface=bridge-wan log=yes log-prefix=honeypot_smtp protocol=tcp to-addresses=192.168.88.201 to-ports=9925 add action=netmap chain=dstnat comment="HONEYPOT SMB" dst-port=445 in-interface=bridge-wan log=yes log-prefix=honeypot_smb protocol=tcp to-addresses=192.168.88.201 to-ports=9445 add action=netmap chain=dstnat comment="HONEYPOT MQTT" dst-port=1883 in-interface=bridge-wan log=yes log-prefix=honeypot_mqtt protocol=tcp to-addresses=192.168.88.201 to-ports=9883 add action=netmap chain=dstnat comment="HONEYPOT SIP" dst-port=5060 in-interface=bridge-wan log=yes log-prefix=honeypot_sip protocol=tcp to-addresses=192.168.88.201 to-ports=9060 add action=dst-nat chain=dstnat comment="HONEYPOT SSH" dst-port=22 in-interface=bridge-wan log=yes log-prefix=honeypot_ssh protocol=tcp to-addresses=192.168.88.201 to-ports=9922
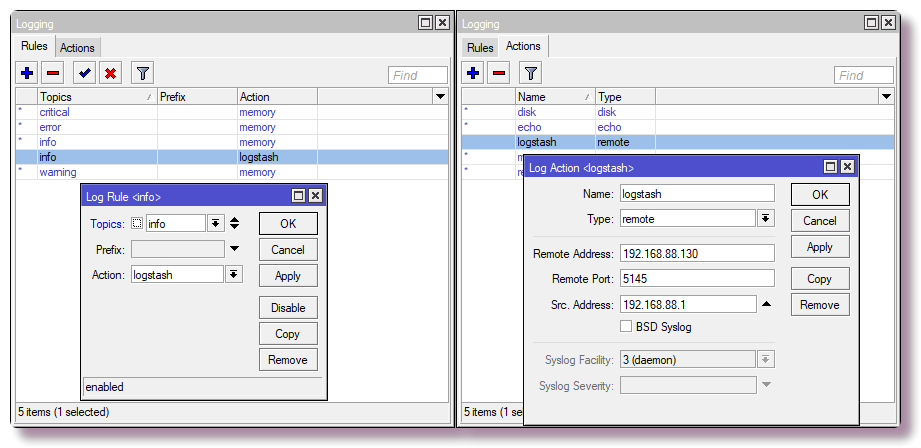
In Winbox wird dasselbe auf der
Registerkarte IP> Firewall> NAT konfiguriert.
Der Router leitet nun die empfangenen Pakete an die lokale Adresse 192.168.88.201 und den benutzerdefinierten Port weiter. Momentan hört niemand auf diese Ports, sodass die Verbindungen unterbrochen werden. In Zukunft können Sie in Docker Honeypot ausführen, von denen es für jeden Dienst viele gibt. Wenn dies nicht geplant ist, sollten Sie anstelle von NAT-Regeln eine Regel mit der Drop-Aktion in die Filterkette schreiben.
Starten von ELK mit Docker-Compose
Als Nächstes können Sie die Komponente konfigurieren, die die Protokolle verarbeitet. Ich rate Ihnen, das Repository sofort zu üben und zu klonen, um die Konfigurationsdateien vollständig anzuzeigen. Alle beschriebenen Configs sind dort zu sehen, im Text des Artikels werde ich nur einen Teil der Configs kopieren.
❯❯ git clone https://github.com/mekhanme/elk-mikrot.git
In einer Test- oder Entwicklungsumgebung ist es am bequemsten, Docker-Container mit docker-compose auszuführen. In diesem Projekt verwende ich zur Zeit die Docker-Compose-Datei der neuesten
Version 3.7 . Sie erfordert die Docker-Engine-Version 18.06.0+. Es lohnt sich daher, den
Docker zu aktualisieren und
Docker-Compose zu verwenden .
❯❯ curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose ❯❯ chmod +x /usr/local/bin/docker-compose
Da in den letzten Versionen von Docker-Compose der Parameter mem_limit entfernt und Deploy hinzugefügt wurde, der nur im Schwarmmodus ausgeführt wird (
Docker-Stack-Deploy ), führt das Starten der
Docker-Compose-Up- Konfiguration mit Einschränkungen zu einem Fehler. Da ich keinen Schwarm verwende und Ressourcenlimits haben möchte, muss ich ihn mit der Option
--compatibility starten, mit der die Limits von Docker-Compose-Versionen in Nicht-Schweiß-Äquivalente konvertiert werden.
Testlauf aller Container (im Hintergrund -d):
❯❯ docker-compose --compatibility up -d
Sie müssen warten, bis alle Bilder heruntergeladen wurden, und nachdem der Start abgeschlossen ist, können Sie den Status der Container mit dem folgenden Befehl überprüfen:
❯❯ docker-compose --compatibility ps
Aufgrund der Tatsache, dass sich alle Container im selben Netzwerk befinden (wenn Sie das Netzwerk nicht explizit angeben, wird eine neue Brücke erstellt, die für dieses Szenario geeignet ist) und docker-compose.yml den Parameter container_name für alle
Container enthält , verfügen die Container bereits über eine Verbindung über das integrierte DNS Hafenarbeiter. Infolgedessen ist es nicht erforderlich, IP-Adressen in Container-Konfigurationen zu registrieren. In der Logstash-Konfiguration ist das Subnetz 192.168.88.0/24 als lokal registriert, weiter unten in der Konfiguration finden Sie nähere Erläuterungen, nach denen Sie das Beispiel der Konfiguration vor dem Start ablenken können.
Konfigurieren Sie ELK Services
Des Weiteren werden Erklärungen zur Konfiguration der Funktionen der ELK-Komponenten sowie einige weitere Aktionen gegeben, die in Elasticsearch ausgeführt werden müssen.
Um die geografischen Koordinaten anhand der IP-Adresse zu ermitteln, müssen Sie die kostenlose
GeoLite2- Datenbank von MaxMind herunterladen:
❯❯ cd elk-mikrot && mkdir logstash/geoip_db ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-City-CSV.zip && unzip GeoLite2-City-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-City-CSV.zip ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-ASN-CSV.zip && unzip GeoLite2-ASN-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-ASN-CSV.zip
Logstash-Setup
Die Hauptkonfigurationsdatei ist
logstash.yml , in der ich die Option zum automatischen
erneuten Laden der Konfiguration registriert habe. Die restlichen Einstellungen für die Testumgebung sind nicht von Bedeutung. Die Konfiguration der Datenverarbeitung (Protokolle) in Logstash wird in separaten
conf- Dateien beschrieben, die normalerweise im
Pipeline- Verzeichnis gespeichert sind. Wenn in dem Schema
mehrere Pipelines verwendet werden, beschreibt die Datei
pipelines.yml die aktivierten
Pipelines . Eine Pipeline ist eine Aktionskette für unstrukturierte Daten, um am Ausgang Daten mit einer bestimmten Struktur zu erhalten. Ein Schema mit separat konfigurierter
pipelines.yml ist optional. Sie können darauf verzichten, indem Sie alle configs aus dem bereitgestellten
Pipeline- Verzeichnis herunterladen. Mit einer bestimmten
pipelines.yml- Datei ist die Konfiguration jedoch flexibler, da Sie die
conf- Dateien aus dem
Pipeline- Verzeichnis
ein- und ausschalten können notwendige configs. Darüber hinaus funktioniert das Neuladen von Konfigurationen nur im Schema mit mehreren Pipelines.
❯❯ cat logstash/config/pipelines.yml - pipeline.id: logstash-mikrot path.config: "pipeline/logstash-mikrot.conf"
Als nächstes kommt der wichtigste Teil der Logstash-Konfiguration. Die Pipeline-Beschreibung besteht aus mehreren Abschnitten - zu Beginn werden die Plugins im Abschnitt
Input angezeigt, mit deren Hilfe Logstash Daten empfängt. Der einfachste Weg, Syslog von einem Netzwerkgerät zu sammeln, ist die Verwendung der
tcp /
udp- Eingabe-Plugins. Der einzige erforderliche Parameter für diese Plugins ist
port . Er muss wie in den Router-Einstellungen angegeben werden.
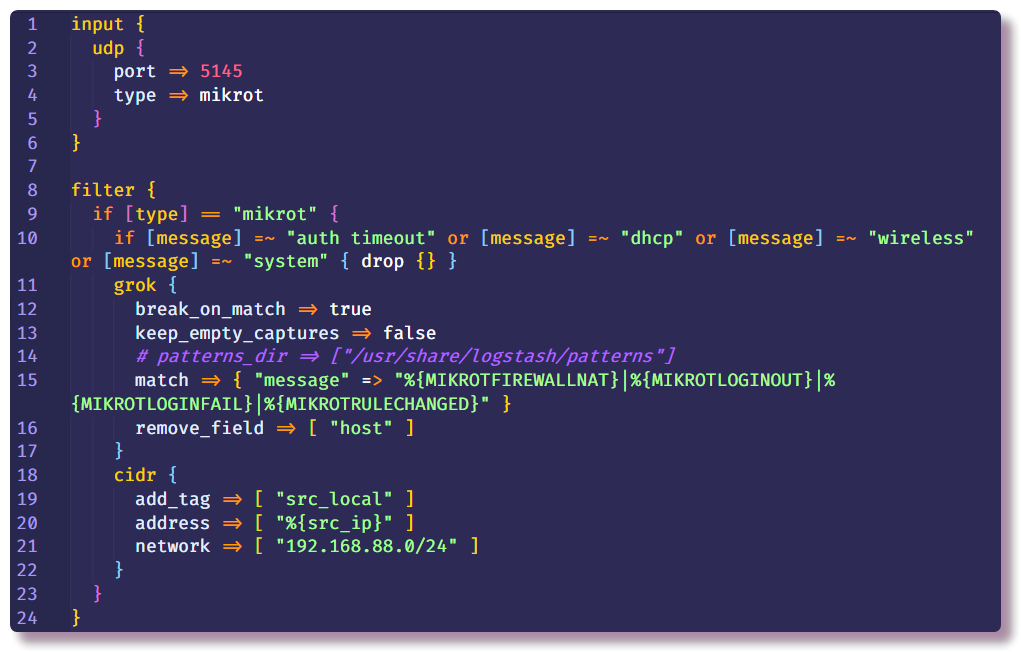
Der zweite Abschnitt ist
Filter , der weitere Aktionen mit Daten vorschreibt, die noch nicht strukturiert wurden. In meinem Beispiel werden unnötige Syslog-Nachrichten von einem Router mit bestimmtem Text gelöscht. Dies geschieht mit der Bedingung und der Standard-
Drop- Aktion, die die gesamte Nachricht verwirft, wenn die Bedingung erfüllt ist. In der
Bedingung wird das
Nachrichtenfeld auf das Vorhandensein von bestimmtem Text überprüft.
Wenn die Nachricht nicht abfällt, geht sie weiter die Kette hinunter und tritt in den
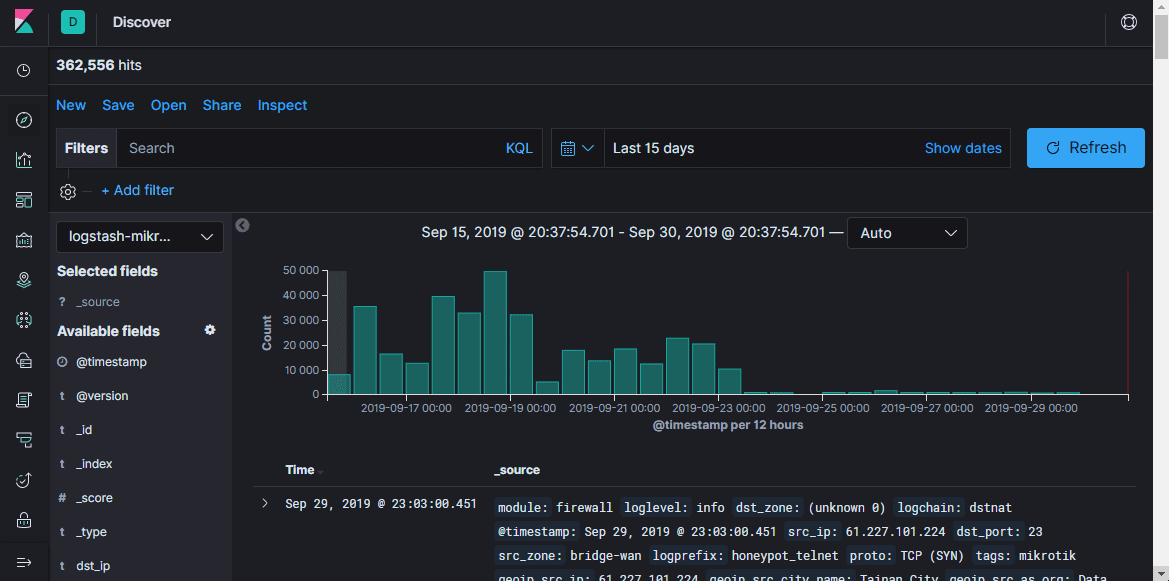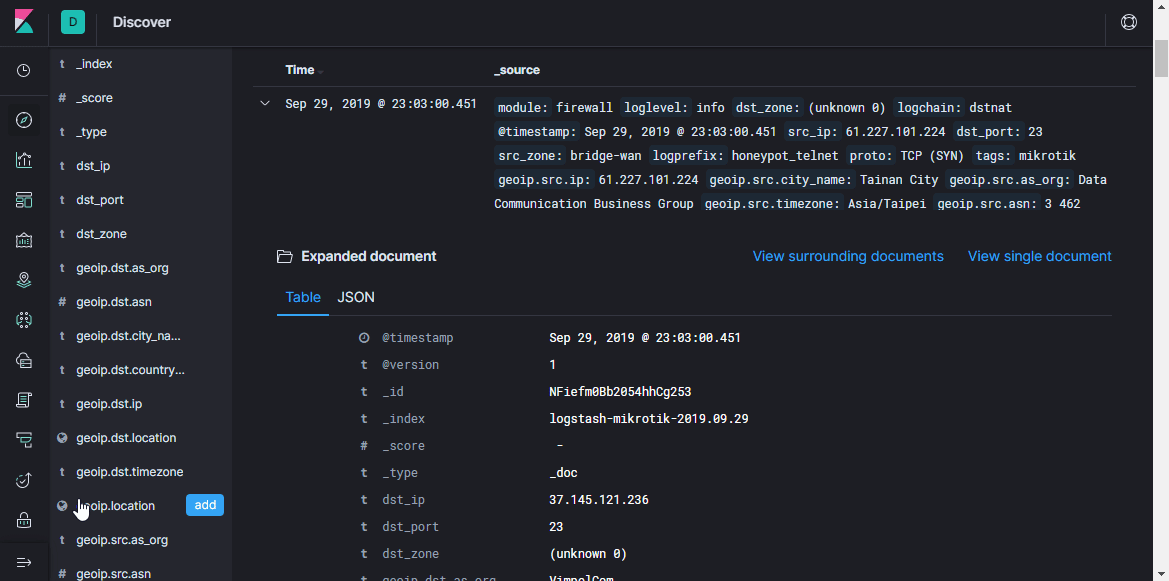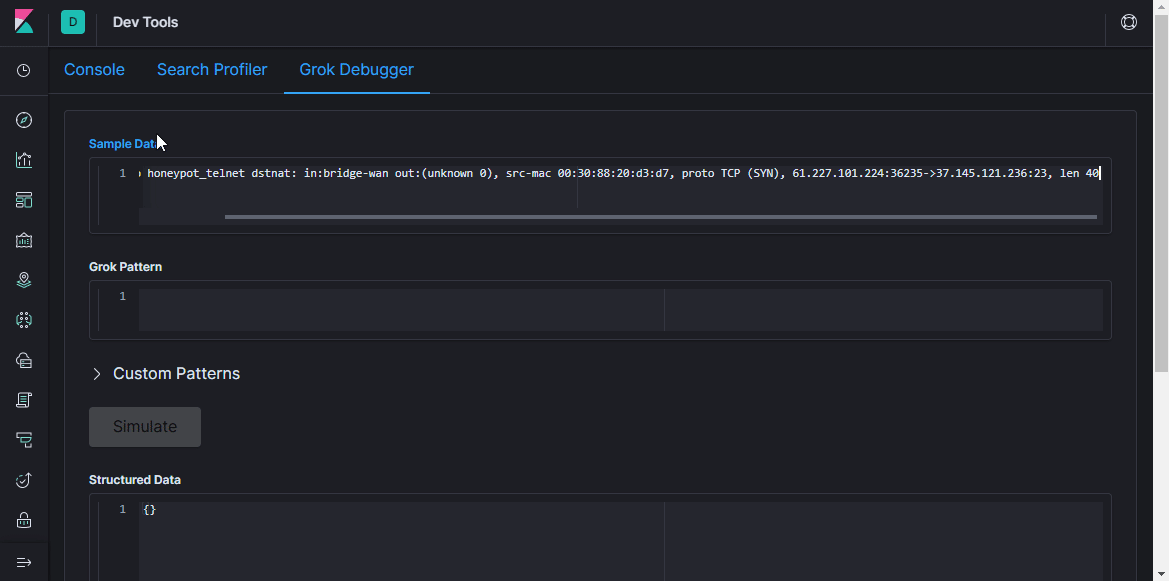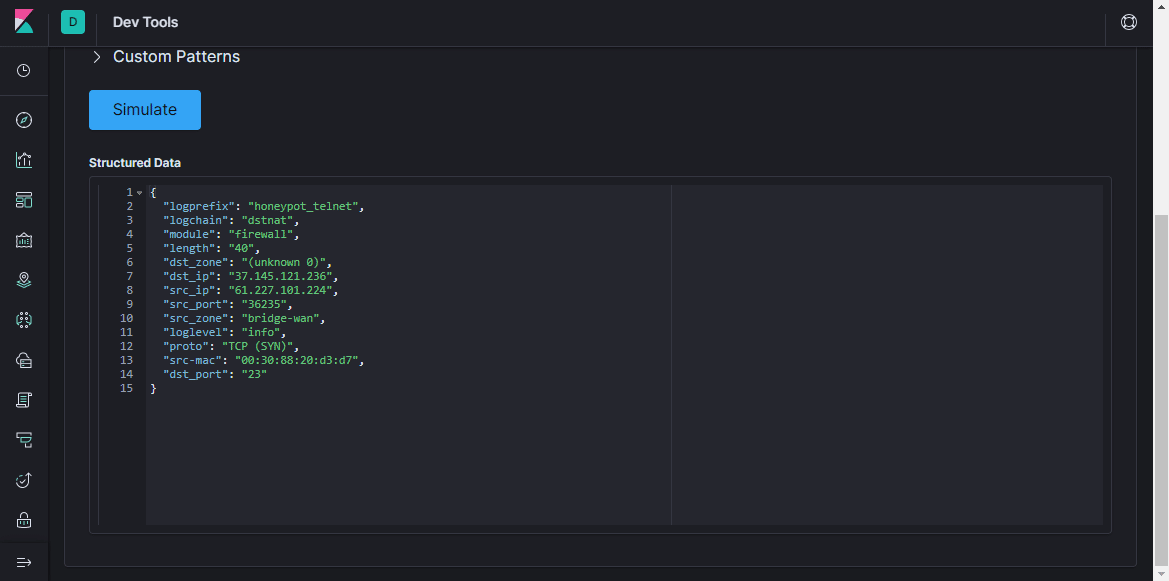
Grok- Filter ein. Wie die Dokumentation sagt, ist
grok eine großartige Möglichkeit, unstrukturierte Protokolldaten in strukturierte und abfragbare Daten zu zerlegen . Dieser Filter wird verwendet, um Protokolle verschiedener Systeme (Linux-Syslog, Webserver, Datenbank, Netzwerkgeräte usw.) zu verarbeiten. Basierend auf
vorgefertigten Mustern können Sie ohne großen Zeitaufwand einen Parser für mehr oder weniger sich wiederholende Sequenzen erstellen. Es ist praktisch, einen
Online-Parser zur Validierung zu verwenden (in der neuesten Version von Kibana finden Sie ähnliche Funktionen im Abschnitt
Entwicklungstools ).
Der
Datenträger "./logstash/patterns:/usr/share/logstash/patterns" ist in der Datei
docker-compose.yml registriert. Im
Verzeichnis patterns befindet sich eine Datei mit Standard-Community-Mustern (nur aus
Gründen der
Benutzerfreundlichkeit , falls ich das vergessen habe) sowie eine Datei mit Analog zu den Mustern verschiedener Arten von Mikrotik-Nachrichten (
Firewall- und
Auth- Module
) können Sie Ihre eigenen Vorlagen für Nachrichten mit einer anderen Struktur hinzufügen.
Die Standardoptionen
add_field und
remove_field ermöglichen das Hinzufügen oder Entfernen von Feldern zu der Nachricht, die in einem beliebigen Filter verarbeitet wird. In diesem Fall wird das
Hostfeld gelöscht, das den Hostnamen enthält, von dem die Nachricht empfangen wurde. In meinem Beispiel gibt es nur einen Host, sodass dieses Feld keinen Sinn macht.
Außerdem habe ich im
selben Filterabschnitt den
cidr- Filter registriert, der das Feld mit der IP-Adresse auf Übereinstimmung mit der Eintragsbedingung im angegebenen Subnetz überprüft und das Tag
einfügt . Basierend auf dem Tag in der weiteren Kette werden Aktionen ausgeführt oder nicht ausgeführt (falls dies ausdrücklich der Fall ist, um in Zukunft keine Geoip-Suche nach lokalen Adressen durchzuführen).
Es kann eine beliebige Anzahl von
Filterabschnitten geben , sodass innerhalb eines Abschnitts weniger Bedingungen vorliegen. In dem neuen Abschnitt, den ich für Nachrichten ohne das
src_local- Tag definiert habe, werden Firewall-Ereignisse verarbeitet, an denen wir an der Quelladresse interessiert sind.
Jetzt müssen wir etwas mehr darüber sprechen, woher Logstash GeoIP-Informationen bezieht. Logstash unterstützt GeoLite2-Datenbanken. Es gibt mehrere Datenbankoptionen. Ich verwende zwei Datenbanken: GeoLite2 City (mit Informationen zu Land, Stadt, Zeitzone) und GeoLite2 ASN (Informationen zu dem autonomen System, zu dem die IP-Adresse gehört).

Das
GeoIP- Plugin ist auch am Hinzufügen von GeoIP-Informationen zur Nachricht beteiligt. In den Parametern müssen Sie das Feld angeben, das die IP-Adresse, die verwendete Basis und den Namen des neuen Felds enthält, in das die Informationen geschrieben werden. In meinem Beispiel wird dasselbe für Ziel-IP-Adressen gemacht, aber in diesem einfachen Szenario sind diese Informationen bisher nicht interessant, da die Zieladresse immer die Adresse des Routers ist. In Zukunft wird es jedoch möglich sein, dieser Pipeline Protokolle nicht nur von der Firewall aus hinzuzufügen, sondern auch von anderen Systemen, auf denen es wichtig ist, beide Adressen zu überprüfen.
Mit dem
Mutate- Filter können Sie die Nachrichtenfelder ändern und den Text in den Feldern selbst ändern. In der Dokumentation werden viele Beispiele für mögliche Aktionen ausführlich beschrieben. In diesem Fall wird es verwendet, um ein Tag hinzuzufügen, Felder umzubenennen (für die weitere Visualisierung von Protokollen in Kibana ist ein bestimmtes Format des
Geopunktobjekts erforderlich, ich werde dieses Thema weiter berühren) und unnötige Felder zu löschen.
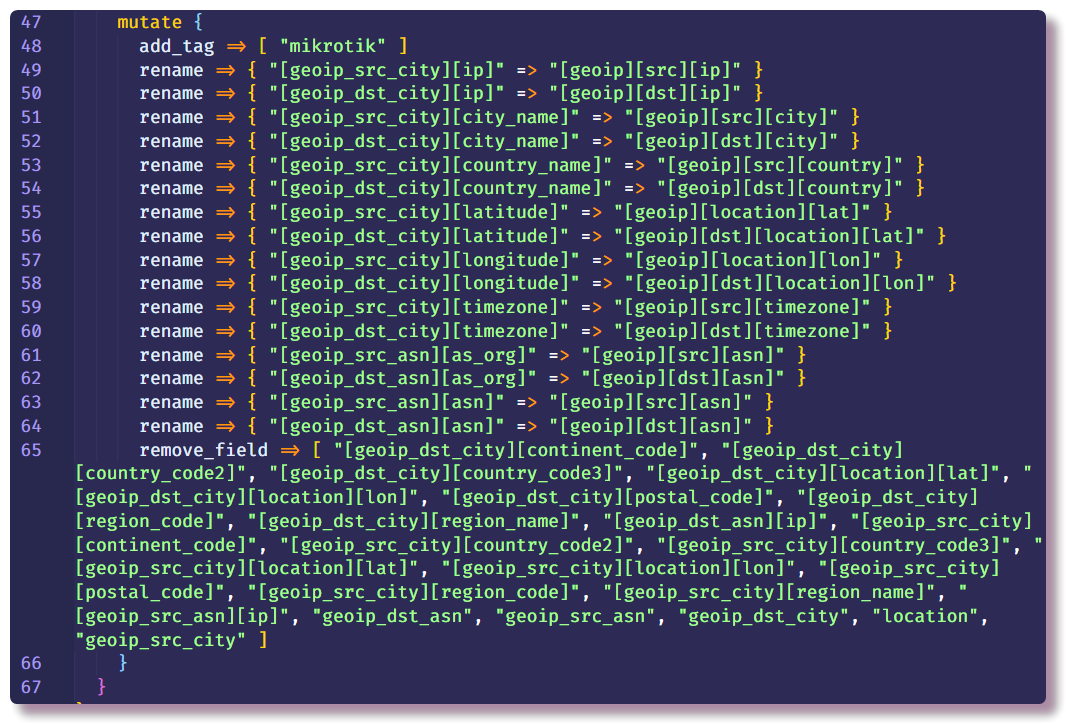
Dies beendet den Datenverarbeitungsabschnitt und kann nur angeben, wohin eine strukturierte Nachricht gesendet werden soll. In diesem Fall sammelt Elasticsearch Daten. Sie müssen nur die IP-Adresse, den Port und den Indexnamen eingeben. Es wird empfohlen, den Index mit einem variablen Datumsfeld einzugeben, damit jeden Tag ein neuer Index erstellt wird.
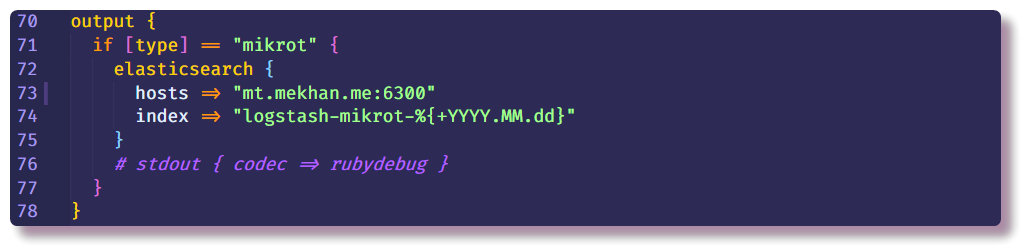
Elasticsearch einrichten
Zurück zur Elasticsuche. Zuerst müssen Sie sicherstellen, dass der Server betriebsbereit ist. Mit Elastic wird am effizientesten über die Rest-API in der CLI interagiert. Mit curl können Sie den Status des Knotens anzeigen (ersetzen Sie localhost durch die IP-Adresse des Host-Dockers):
❯❯ curl localhost:9200
Dann können Sie versuchen, Kibana bei zu öffnen
localhost : 5601. In der Kibana-Weboberfläche muss nichts konfiguriert werden (es sei denn, Sie ändern das Thema auf dunkel). Wir sind interessiert, ob ein Index erstellt wurde. Öffnen Sie dazu den Bereich
Verwaltung und wählen Sie
Elasticsearch-Indexverwaltung oben links aus. Hier können Sie sehen, wie viele Dokumente indiziert sind, wie viel Speicherplatz benötigt wird, und Informationen zur Indexzuordnung aus nützlichen Informationen abrufen.
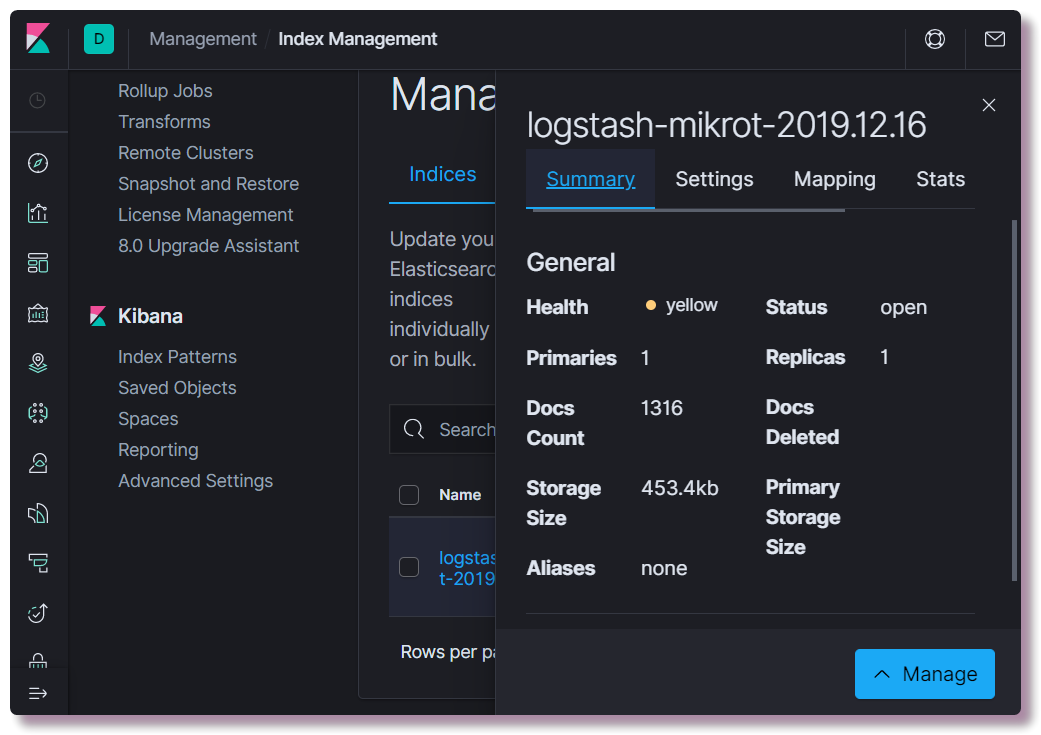
In diesem Fall müssen Sie die richtige Zuordnungsvorlage registrieren. Diese Informationen werden für Elastic benötigt, damit er versteht, welche Datentypen zu welchen Feldern gehören. Um beispielsweise eine spezielle Auswahl basierend auf IP-Adressen für das Feld "
src_ip" zu treffen , müssen
Sie den
IP- Datentyp explizit angeben.
Um den geografischen Standort zu bestimmen, müssen Sie das Feld "
geoip.location" in einem bestimmten Format definieren und den Typ "
geo_point" registrieren. Es müssen nicht alle möglichen Felder beschrieben werden, da bei neuen Feldern der Datentyp automatisch anhand dynamischer Muster ermittelt wird (
Long für Zahlen und
Keyword für Strings).
Sie können eine neue Vorlage entweder mit dem Einrollen oder direkt über die Kibana-Konsole schreiben (Abschnitt
Entwicklungstools ).
❯❯ curl -X POST -H "Content-Type: application/json" -d @elasticsearch/logstash_mikrot-template.json http://192.168.88.130:9200/_template/logstash-mikrot
Nach dem Ändern des Mappings müssen Sie den Index löschen:
❯❯ curl -X DELETE http://192.168.88.130:9200/logstash-mikrot-2019.12.16
Wenn mindestens eine Nachricht im Index eintrifft, überprüfen Sie die Zuordnung:
❯❯ curl http://192.168.88.130:9200/logstash-mikrot-2019.12.16/_mapping
Für die weitere Verwendung von Daten in Kibana müssen Sie unter
Verwaltung> Kibana-Indexmuster ein
Muster erstellen. Geben Sie den
Indexnamen mit dem Symbol * (
logstash-mikrot *) ein, damit alle Indizes übereinstimmen.
Wählen Sie das
Zeitstempelfeld als Feld mit Datum und Uhrzeit aus. In das Feld
Benutzerdefinierte Indexmuster- ID können Sie die Muster-ID eingeben (z. B.
logstash-mikrot ). Dies kann in Zukunft den Zugriff auf das Objekt vereinfachen.
Datenanalyse und Visualisierung in Kibana
Nachdem Sie das Indexmuster erstellt haben, können Sie mit der interessantesten Teiledatenanalyse und -visualisierung fortfahren. Kibana hat viele Funktionen und Abschnitte, aber bisher werden wir uns nur für zwei interessieren.
Entdecken
Hier können Sie Dokumente in Indizes anzeigen, empfangene Informationen filtern, suchen und anzeigen. Es ist wichtig, die Zeitachse nicht zu vergessen, die den Zeitrahmen in den Suchbedingungen festlegt.
Visualisieren
In diesem Abschnitt können Sie eine Visualisierung basierend auf den gesammelten Daten erstellen. Am einfachsten ist es, die Quellen für das Scannen von Botnetzen auf einer geografischen Karte (gepunktet oder in Form einer Heatmap) anzuzeigen. Es gibt auch viele Möglichkeiten, Diagramme zu erstellen, Auswahlen zu treffen usw.
In Zukunft möchte ich etwas mehr über die Datenverarbeitung, möglicherweise die Visualisierung und möglicherweise etwas anderes Interessantes erzählen. Während des Studiums werde ich versuchen, das Tutorial zu ergänzen.
Fehlerbehebung
Wenn der Index nicht in Elasticsearch angezeigt wird, sollten Sie sich zuerst die Logstash-Protokolle ansehen:
❯❯ docker logs logstash --tail 100 -f
Logstash funktioniert nicht, wenn keine Verbindung mit Elasticsearch besteht oder ein Fehler in der Pipelinekonfiguration der Hauptgrund ist. Dies wird nach einer sorgfältigen Untersuchung der Protokolle deutlich, die standardmäßig in json docker geschrieben werden.
Wenn das Protokoll keine Fehler enthält, müssen Sie sicherstellen, dass Logstash Nachrichten auf dem konfigurierten Socket abfängt. Für Debug-Zwecke können Sie
stdout als
Ausgabe verwenden :
stdout { codec => rubydebug }
Danach schreibt Logstash Debag-Informationen, wenn die Nachricht direkt im Protokoll eingeht.
Das Prüfen von Elasticsearch ist sehr einfach. Lassen Sie einfach eine GET-Anforderung für die IP-Adresse und den Port des Servers oder für einen bestimmten API-Endpunkt einrollen. Sehen Sie sich beispielsweise den Status von Indizes in einer für Menschen lesbaren Tabelle an:
❯❯ curl -s 'http://192.168.88.130:9200/_cat/indices?v'
Kibana startet auch dann nicht, wenn keine Verbindung zu Elasticsearch besteht. Dies ist anhand der Protokolle leicht zu erkennen.
Wenn sich das Webinterface nicht öffnen lässt, sollten Sie sicherstellen, dass die Firewall unter Linux richtig konfiguriert oder deaktiviert ist (in Centos gab es Probleme mit
iptables und
docker , die auf den Rat des
Themas hin behoben wurden). Es ist auch zu berücksichtigen, dass bei nicht sehr produktiven Geräten alle Komponenten mehrere Minuten lang geladen werden können. Bei Speichermangel werden die Dienste möglicherweise überhaupt nicht geladen. Anzeigen der Nutzung von Containerressourcen:
❯❯ docker stats
Wenn plötzlich jemand nicht mehr weiß, wie er die Konfiguration von Containern in der
Datei docker-compose.yml richtig ändern und die Container neu starten kann, müssen Sie
docker-compose.yml bearbeiten und denselben Befehl mit denselben Parametern erneut starten:
❯❯ docker-compose --compatibility up -d
Gleichzeitig werden in den geänderten Abschnitten alte Objekte (Container, Netzwerke, Volumes) gelöscht und neue entsprechend der Konfiguration neu erstellt. Die Daten von Diensten gehen nicht gleichzeitig verloren, da
benannte Volumes verwendet werden , die nicht mit dem Container gelöscht werden und die Konfigurationsdateien vom Hostsystem eingehängt werden. Logstash kann sogar die Konfigurationsdateien überwachen und die Pipeline-Konfiguration neu starten, wenn die Datei geändert wird.
Sie können den Dienst separat mit dem
Befehl docker restart neu starten (es ist nicht erforderlich, dass Sie sich mit
docker-compose.yml im Verzeichnis
befinden) :
❯❯ docker restart logstash
Sie können die
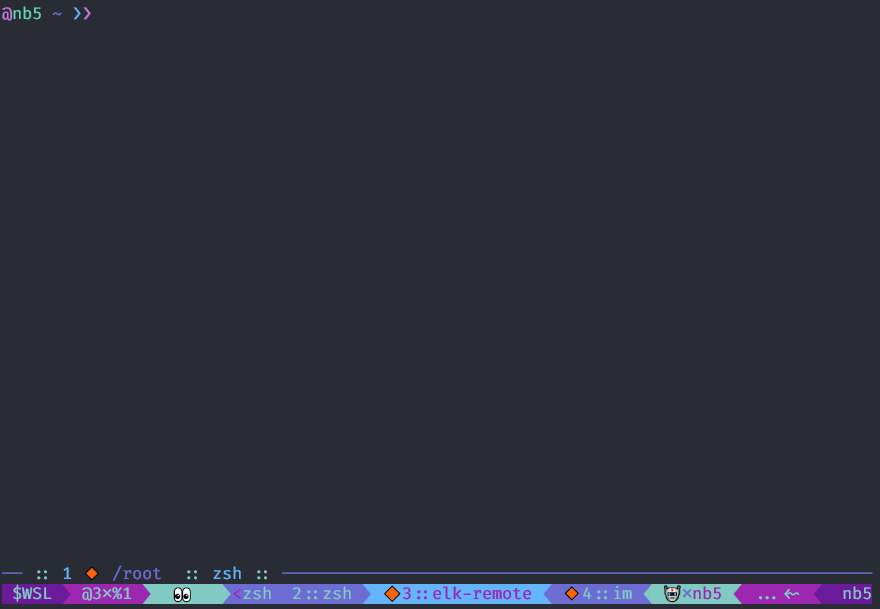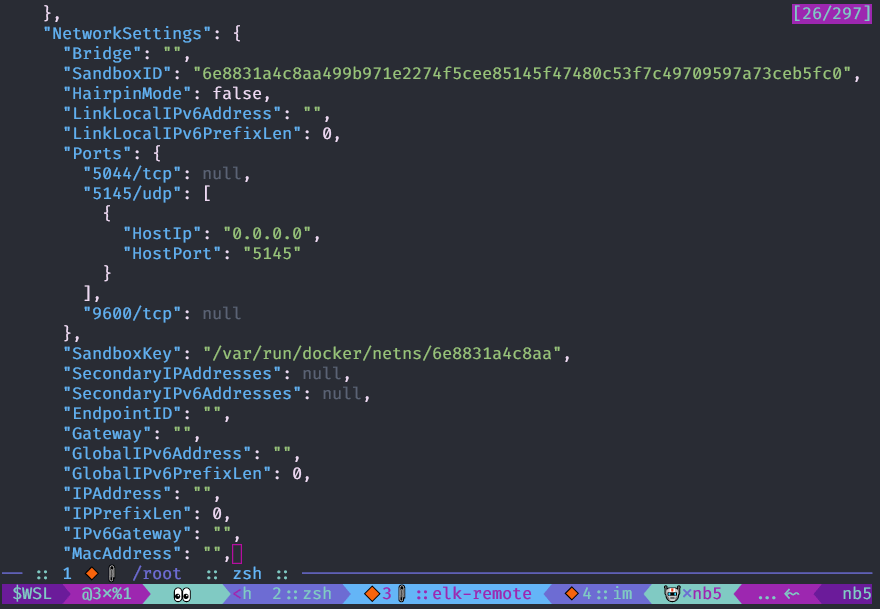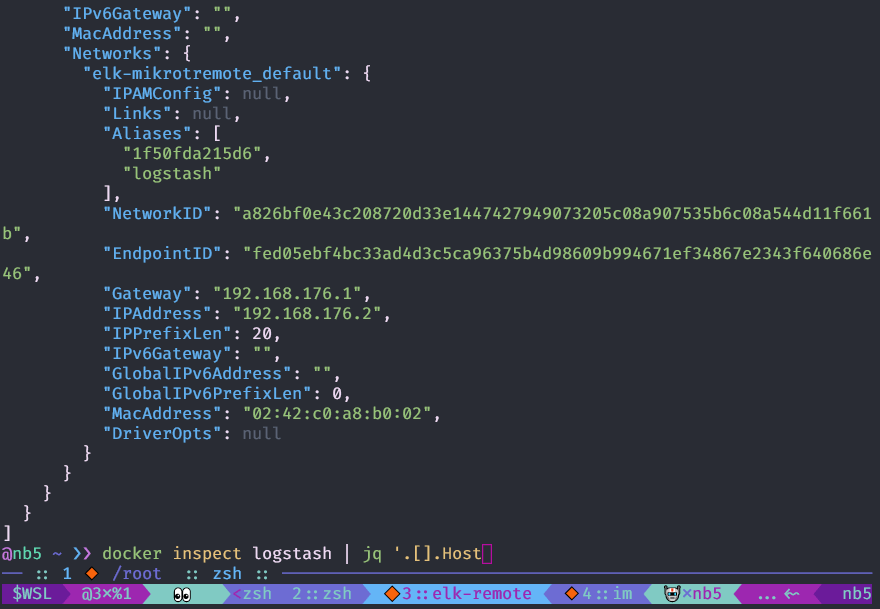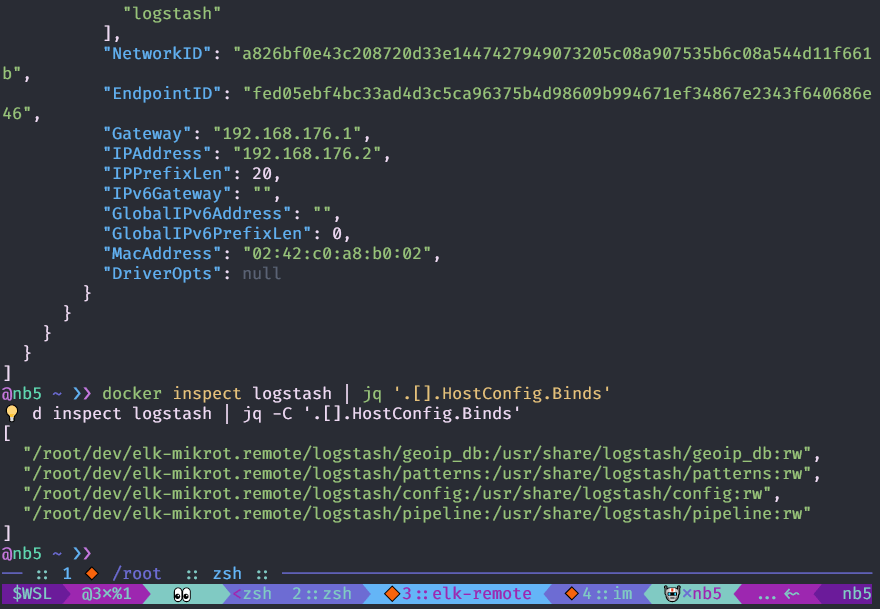
Docker- Objektkonfiguration mit dem
Befehl docker inspect anzeigen . Es ist praktischer, sie mit
jq zu verwenden .
Fazit
Ich möchte darauf hinweisen, dass die Sicherheit in diesem Projekt nicht gemeldet wurde, da es sich um eine Testumgebung handelt und keine Veröffentlichung außerhalb des Routers geplant ist. Wenn Sie es für eine ernstere Verwendung bereitstellen, müssen Sie die bewährten Methoden befolgen, Zertifikate für HTTPS installieren, Sicherungen erstellen und die normale Überwachung (die nicht neben dem Hauptsystem startet) ausführen. Übrigens läuft Traefik in meinem Docker auf meinem Server, der für einige Dienste ein Reverse-Proxy ist, und beendet TLS auf sich selbst und führt die Authentifizierung durch. Das heißt, dank des konfigurierten DNS und des Reverse-Proxys ist es möglich, über das Internet mit nicht konfiguriertem HTTPS und einem Kennwort auf das Kibana-Webinterface zuzugreifen (in der Community-Version unterstützt Kibana nach meinem Verständnis keinen Kennwortschutz für das Webinterface). Ich plane, meine Erfahrungen mit der Einrichtung von Traefik für die Verwendung in einem Heimnetzwerk mit Docker weiter zu beschreiben.