Hallo Habrowsk. Der Unterricht beginnt heute in der ersten Gruppe des PostgreSQL- Kurses. In diesem Zusammenhang möchten wir Ihnen mitteilen, wie das offene Webinar für diesen Kurs stattgefunden hat.
In der
nächsten offenen Lektion sprachen
wir darüber, welchen Herausforderungen SQL-Datenbanken im Zeitalter von Clouds und Kubernetes ausgesetzt waren. Gleichzeitig haben wir untersucht, wie sich SQL-Datenbanken unter dem Einfluss dieser Aufrufe anpassen und verändern.
Das Webinar wurde von
Valery Bezrukov , Google Cloud Practice Delivery Manager bei EPAM Systems, moderiert.
Als die Bäume klein waren ...
Lassen Sie uns zunächst daran erinnern, wie die Auswahl eines DBMS Ende des letzten Jahrhunderts begann. Dies wird jedoch nicht schwierig sein, da die Auswahl eines DBMS in jenen Tagen mit
Oracle begann und endete.

In den späten 90er Jahren - Anfang der 90er Jahre - gab es tatsächlich keine besondere Wahl, wenn wir über industriell skalierbare Datenbanken sprechen. Ja, es gab IBM DB2, Sybase und einige andere Datenbanken, die erschienen und verschwanden, aber im Allgemeinen waren sie für Oracle nicht so auffällig. Dementsprechend waren die Fähigkeiten der damaligen Ingenieure in gewisser Weise an die einzige Wahl gebunden, die es gab.
Oracle DBA sollte in der Lage sein:
- Installieren Sie Oracle Server von der Distribution
- Oracle Server konfigurieren:
- erstelle:
- Tabellenbereiche
- Schemata
- Benutzer
- sichern und wiederherstellen;
- Überwachung durchführen;
- mit suboptimalen Anforderungen umgehen.
Gleichzeitig war Oracle DBA nicht besonders erforderlich:
- in der Lage sein, das optimale DBMS oder eine andere Datenspeicherungs- und -verarbeitungstechnologie auszuwählen;
- Bereitstellung von hoher Verfügbarkeit und horizontaler Skalierbarkeit (dies war nicht immer ein DBA-Problem);
- Gute Kenntnisse des Fachgebiets, der Infrastruktur, der angewandten Architektur, des Betriebssystems;
- Laden und Entladen von Daten durchführen, Datenmigration zwischen verschiedenen DBMS.
Wenn wir in jenen Tagen über die Wahl sprechen, dann ähnelt sie im Allgemeinen einer Wahl in einem sowjetischen Geschäft Ende der 80er Jahre:

Unsere Zeit
Seitdem sind natürlich die Bäume gewachsen, die Welt hat sich verändert und es ist irgendwie so geworden:

Auch der DBMS-Markt hat sich verändert. Dies geht aus dem aktuellen Gartner-Bericht deutlich hervor:

Und hier ist anzumerken, dass die Wolken ihre Nische besetzten, deren Popularität wächst. Wenn Sie denselben Gartner-Bericht lesen, sehen wir die folgenden Schlussfolgerungen:
- Viele Kunden sind unterwegs, um Anwendungen in die Cloud zu verlagern.
- Neue Technologien tauchen zuerst in der Cloud auf und nicht die Tatsache, dass sie jemals auf eine cloudfreie Infrastruktur umsteigen werden.
- Das Preismodell für umlagefinanzierte Produkte ist bekannt geworden. Jeder möchte nur für das bezahlen, was er nutzt, und dies ist nicht einmal ein Trend, sondern lediglich eine Tatsachenfeststellung.
Was jetzt?
Heute sind wir alle in der Cloud. Und diese Fragen, die wir haben, sind Fragen der Wahl. Und es ist riesig, auch wenn wir nur über die Auswahl der DBMS-Technologien im lokalen Format sprechen. Wir haben auch Services und SaaS verwaltet. Daher wird die Auswahl von Jahr zu Jahr komplizierter.
Neben
den Wahlfragen gelten auch
restriktive Faktoren :
- der Preis . Viele Technologien kosten immer noch Geld;
- Fähigkeiten . Wenn es sich um freie Software handelt, stellt sich die Frage nach den Fähigkeiten, denn freie Software erfordert Menschen, die sie mit ausreichender Kompetenz einsetzen und betreiben.
- funktionell . Nicht alle Dienste, die in der Cloud verfügbar sind und beispielsweise auf der Grundlage derselben Postgres erstellt wurden, verfügen über dieselben Funktionen wie Postgres On-Premises. Dies ist ein wesentlicher Faktor, den Sie kennen und verstehen müssen. Darüber hinaus wird dieser Faktor wichtiger als die Kenntnis einiger verborgener Merkmale eines einzelnen DBMS.
Worauf warten die DA / DE:- ein gutes Verständnis des Fachgebiets und der angewandten Architektur;
- die Fähigkeit, die richtige DBMS-Technologie auszuwählen, unter Berücksichtigung der Aufgabe;
- die Möglichkeit, die optimale Methode für die Implementierung der ausgewählten Technologie im Kontext der bestehenden Einschränkungen auszuwählen
- Fähigkeit zur Datenmigration und -migration;
- die Fähigkeit, die ausgewählten Lösungen zu implementieren und zu betreiben.
Das folgende
auf GCP basierende Beispiel zeigt, wie die Auswahl einer bestimmten Technologie für die Arbeit mit Daten in Abhängigkeit von ihrer Struktur angeordnet ist:

Beachten Sie, dass PostgreSQL im Schema fehlt, und zwar nur, weil es sich unter der Terminologie von
Cloud SQL verbirgt . Und wenn wir in Cloud SQL einsteigen, müssen wir erneut eine Wahl treffen:

Es sollte beachtet werden, dass diese Wahl nicht immer klar ist, daher lassen sich Anwendungsentwickler oft von der Intuition leiten.
Gesamt:- Je weiter entfernt, desto relevanter ist die Frage der Wahl. Und selbst wenn Sie sich nur GCP, Managed Services und SaaS ansehen, wird RDBMS erst im vierten Schritt erwähnt (und es gibt Spanner in der Nähe). Außerdem wird die Auswahl von PostgreSQL im Allgemeinen im fünften Schritt angezeigt, und daneben gibt es auch MySQL und SQL Server, das heißt, es gibt eine Menge, aber Sie müssen auswählen .
- Wir dürfen die Beschränkungen des Hintergrunds von Versuchungen nicht vergessen. Meistens will jeder einen Schraubenschlüssel, aber es ist teuer. Infolgedessen sieht eine typische Abfrage folgendermaßen aus: "Bitte machen Sie Spanner für uns, aber für den Preis von Cloud SQL sind Sie Profis!"

Was zu tun
Sagen wir Folgendes, ohne vorzutäuschen, die ultimative Wahrheit zu sein:
Notwendigkeit, den Lernansatz zu ändern:- zu lernen, wie es vor DBA gelehrt wurde, macht keinen Sinn;
- Die Kenntnis eines Produkts reicht nicht mehr aus.
- Aber Dutzende auf der Ebene eines Menschen zu kennen, ist unmöglich.
Sie müssen nicht nur wissen, wie viel das Produkt kostet, sondern auch:
- Anwendungsfall;
- verschiedene Bereitstellungsmethoden;
- Vor- und Nachteile jeder Methode;
- ähnliche und alternative Produkte, um fundierte und optimale Entscheidungen zu treffen, und nicht immer zugunsten eines vertrauten Produkts.
Sie müssen auch in der Lage sein, Daten zu migrieren und die Grundprinzipien der Integration in ETL zu verstehen.
Wirklicher Fall
In der jüngeren Vergangenheit mussten Sie ein Backend für eine mobile Anwendung erstellen. Zu Beginn der Arbeit war das Backend bereits entwickelt und bereit zur Implementierung, und das Entwicklerteam verbrachte ungefähr zwei Jahre mit diesem Projekt. Folgende Aufgaben wurden gestellt:
- Build CI / CD;
- Architektur zu überprüfen;
- alles in betrieb nehmen.
Die Anwendung selbst war Microservice, und der Python / Django-Code wurde von Grund auf und sofort in GCP entwickelt. Für die Zielgruppe wurde angenommen, dass es zwei Regionen geben würde - USA und EU, und der Verkehr wurde über den Global Load Balancer verteilt. Alle Workloads und Computer-Workloads wurden in der Google Kubernetes Engine ausgeführt.
Zu den Daten gab es 3 Strukturen:
- Cloud-Speicher
- Datenspeicher;
- Cloud SQL (PostgreSQL).
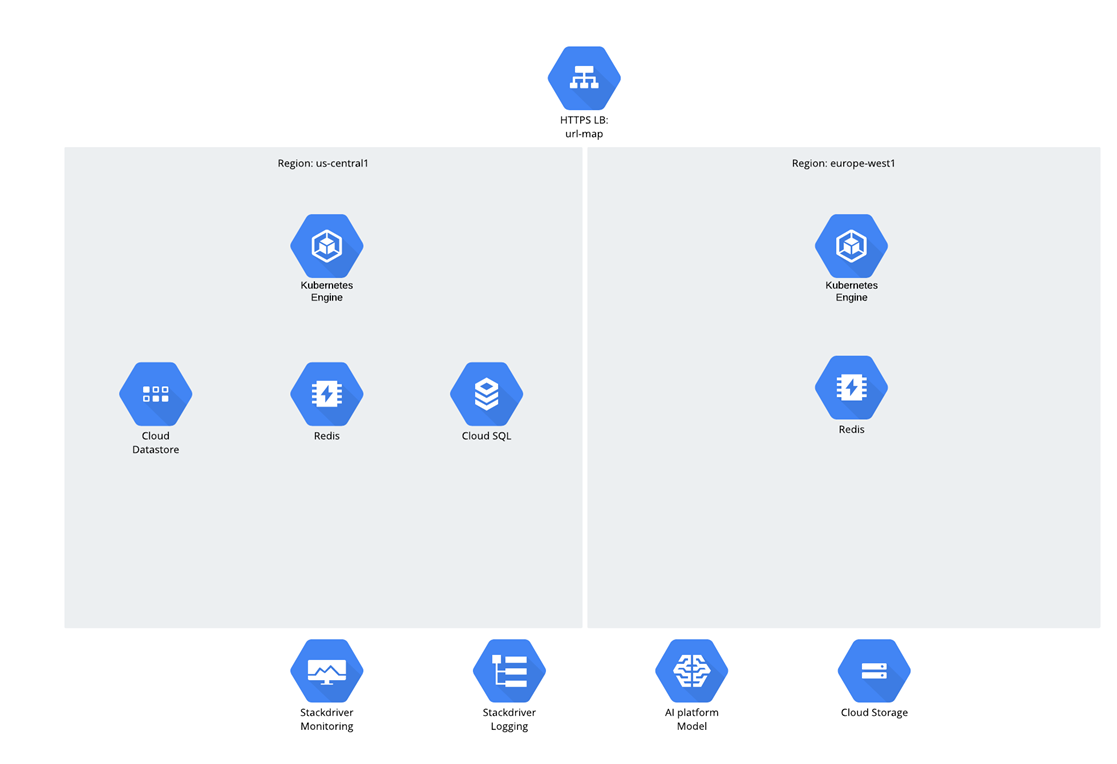
Sie fragen sich vielleicht, warum Cloud SQL ausgewählt wurde? Um ehrlich zu sein, hat eine solche Frage in den letzten Jahren einige unangenehme Pausen verursacht - es besteht das Gefühl, dass die Leute anfingen, relationale Datenbanken zu scheuen, sie aber weiterhin aktiv nutzen ;-).
Für unseren Fall wurde Cloud SQL aus folgenden Gründen gewählt:
- Wie bereits erwähnt, wurde die Anwendung mit Django entwickelt und verfügt über ein Modell für die Zuordnung persistenter Daten aus einer SQL-Datenbank zu Python-Objekten (Django ORM).
- Das Framework selbst unterstützte eine ziemlich begrenzte Liste von DBMSs:
- PostgreSQL
- MariaDB;
- MySQL
- Oracle
- SQLite
Dementsprechend wurde PostgreSQL intuitiv aus dieser Liste ausgewählt (tatsächlich handelt es sich nicht um Oracle).
Was fehlte:- Die Anwendung wurde nur in zwei Regionen bereitgestellt, und die Pläne wurden an dritter Stelle (Asien) aufgeführt.
- Die Datenbank befand sich in der nordamerikanischen Region (Iowa);
- Seitens des Kunden bestanden Bedenken hinsichtlich möglicher Verzögerungen beim Zugang aus Europa und Asien sowie Betriebsunterbrechungen im Falle einer DBMS-Ausfallzeit.
Obwohl Django selbst mit mehreren Datenbanken parallel arbeiten und diese durch Lesen und Schreiben teilen kann, enthält die Anwendung nicht so viele Datensätze (mehr als 90% - Lesen). Und im Allgemeinen und wenn Sie eine
Kopie der Hauptbasis in Europa und Asien erstellen könnten, wäre dies eine Kompromisslösung. Nun, was ist so kompliziert?
Die Schwierigkeit bestand darin, dass der Kunde die Verwendung von Managed Services und Cloud SQL nicht ablehnen wollte. Und die Möglichkeiten von Cloud SQL sind derzeit begrenzt. Cloud SQL unterstützt Hochverfügbarkeit (HA) und Read Replica (RR), dieselbe RR wird jedoch nur in einer Region unterstützt. Nachdem eine Datenbank in der amerikanischen Region erstellt wurde, ist es unmöglich, in der europäischen Region mithilfe von Cloud SQL eine Lesereplik zu erstellen, obwohl Postgres selbst keine Interferenzen verursacht. Die Korrespondenz mit Google-Mitarbeitern führte zu nichts und endete mit Versprechungen im Stil von "Wir kennen das Problem und arbeiten daran, eines Tages wird das Problem behoben sein."
Wenn Sie die Thesis-Möglichkeiten von Cloud SQL auflisten, sieht es ungefähr so aus:
1. Hochverfügbarkeit (HA):- innerhalb einer Region;
- durch Festplattenreplikation
- PostgreSQL-Mechanismen werden nicht verwendet.
- automatische und manuelle Steuerung möglich - Failover / Failback;
- Beim Umschalten ist das DBMS für einige Minuten nicht verfügbar.
2. Replikat (RR) lesen:- innerhalb einer Region;
- heißer Standby;
- PostgreSQL-Streaming-Replikation.
Außerdem stößt man bei der Auswahl einer Technologie wie üblich auf einige
Einschränkungen :
- Der Kunde wollte keine Einheiten produzieren und IaaS verwenden, außer über GKE.
- Der Kunde möchte kein PostgreSQL / MySQL-Self-Service-System bereitstellen.
- Im Allgemeinen wäre Google Spanner durchaus geeignet, wenn es nicht für seinen Preis geeignet wäre. Django ORM kann jedoch nicht damit arbeiten. Die Sache ist also gut.
In Anbetracht der Situation erhielt der Kunde eine Auffüllfrage:
"Können Sie etwas Ähnliches tun, um es wie Google Spanner zu machen, aber es funktioniert auch mit Django ORM?"Option Nr. 0
Das erste, was mir in den Sinn kam:
- Bleiben Sie in CloudSQL
- Es wird keine integrierte Replikation zwischen Regionen in irgendeiner Form geben.
- Versuchen Sie, das Replikat mit PostgreSQL in die vorhandene Cloud-SQL zu integrieren.
- irgendwo und irgendwie die PostgreSQL-Instanz starten, aber zumindest Master nicht berühren.
Leider stellte sich heraus, dass dies nicht möglich ist, da es keinen Zugriff auf den Host gibt (es befindet sich im Allgemeinen in einem anderen Projekt) - pg_hba und so weiter, und es gibt immer noch keinen Zugriff unter Superuser.
Option Nr. 1
Nach weiterer Überlegung und unter Berücksichtigung der bisherigen Umstände änderte sich der Gedankengang etwas:
- Wir versuchen immer noch, im Rahmen von CloudSQL zu bleiben, aber wir wechseln zu MySQL, da Cloud SQL von MySQL einen externen Master hat, der:
- ist ein Proxy für externes MySQL;
- sieht aus wie eine MySQL-Instanz;
- Erfunden für die Datenmigration aus anderen Clouds oder vor Ort.
Da für die Einrichtung der MySQL-Replikation kein Zugriff auf den Host erforderlich ist, hat im Grunde alles funktioniert, ist aber sehr instabil und unpraktisch. Und als wir weitergingen, wurde es völlig beängstigend, weil wir die gesamte Struktur mit Terraform bereitstellten, und plötzlich stellte sich heraus, dass der externe Master nicht von Terraform unterstützt wurde. Ja, Google hat eine CLI, aber aus irgendeinem Grund hat ab und zu alles funktioniert - es wurde erstellt, es wird nicht erstellt. Vielleicht, weil die CLI für die Datenmigration außerhalb und nicht für Replikate erfunden wurde.
Tatsächlich hat dies deutlich gemacht, dass Cloud SQL überhaupt nicht zum Wort passt. Wie sie sagen, wir haben alles getan, was wir konnten.
Option 2
Da es nicht funktionierte, in Cloud SQL zu bleiben, haben wir versucht, Anforderungen für eine Kompromisslösung zu formulieren. Die Anforderungen waren wie folgt:
- Arbeit in Kubernetes, maximale Nutzung der Ressourcen und Fähigkeiten von Kubernetes (DCS, ...) und GCP (LB, ...);
- das Fehlen von Ballast von einem Haufen unnötiger Dinge in der Cloud wie einem HA-Proxy;
- die Fähigkeit, HA PostgreSQL oder MySQL in der Hauptregion auszuführen; in anderen Regionen - HA aus dem RR der Hauptregion plus seiner Kopie (aus Gründen der Zuverlässigkeit);
- multi master (wollte ihn nicht kontaktieren, war aber nicht sehr wichtig)
.
Infolge dieser Anforderungen tauchten am Horizont endlich
geeignete DBMS-Optionen und -Bindungen auf :
- MySQL Galera;
- CockroachDB;
- PostgreSQL-Werkzeuge
:
- pgpool-II;
- Patroni.
MySQL Galera
Die MySQL Galera-Technologie wurde von Codership entwickelt und ist ein Plugin für InnoDB. Eigenschaften:
- Multi-Master;
- synchrone Replikation
- Lesen von einem beliebigen Knoten;
- auf einen beliebigen Knoten aufnehmen;
- integrierter HA-Mechanismus;
- Es gibt eine Helmkarte von Bitnami.
Küchenschabe
Laut Beschreibung ist das Ding völlig bombastisch und ein Open Source-Projekt, das in Go geschrieben wurde. Der Hauptteilnehmer ist Cockroach Labs (gegründet von Einwanderern von Google). Dieses relationale DBMS wurde ursprünglich zur Verteilung (mit horizontaler Skalierung) und Fehlertoleranz erstellt. Die Autoren des Unternehmens skizzierten das Ziel, "den Reichtum der SQL-Funktionalität mit der horizontalen Verfügbarkeit zu kombinieren, die NoSQL-Lösungen vertraut sind".
Der nette Bonus ist die Unterstützung des Postgres-Verbindungsprotokolls.
Pgpool
Dies ist ein Add-On für PostgreSQL, eine neue Entität, die alle Verbindungen übernimmt und verarbeitet. Es verfügt über einen eigenen Loader Balancer und Parser, die unter der BSD-Lizenz lizenziert sind. Es bietet viele Möglichkeiten, sieht jedoch etwas beängstigend aus, da die Anwesenheit einer neuen Einheit eine Quelle zusätzlicher Abenteuer werden könnte.
Patroni
Dies ist das Letzte, worauf das Auge fiel, und wie sich herausstellte, nicht umsonst. Patroni ist ein Open Source-Dienstprogramm, bei dem es sich im Wesentlichen um einen Python-Daemon handelt, der PostgreSQL-Cluster mit verschiedenen Replikationsarten und automatischem Rollenwechsel automatisch verwaltet. Das Stück erwies sich als sehr interessant, da es sich gut in die Cuber integriert und keine neuen Entitäten trägt.
Was wählte letztendlich
Die Wahl war nicht einfach:
- CockroachDB - Feuer, aber dumm;
- MySQL Galera ist auch nicht schlecht, es wird viel benutzt, aber MySQL;
- Pgpool - viele zusätzliche Entitäten, so lala Integration mit der Cloud und K8s;
- Patroni - Hervorragende Integration mit K8s, keine zusätzlichen Einheiten, lässt sich gut in die GCP LB integrieren.
Somit fiel die Wahl auf Patroni.
Schlussfolgerungen
Die Zeit ist gekommen, um zusammenzufassen. Ja, die Welt der IT-Infrastruktur hat sich erheblich verändert, und dies ist nur der Anfang. Und wenn Clouds früher nur eine andere Art von Infrastruktur waren, ist jetzt alles anders. Darüber hinaus tauchen ständig Innovationen in den Wolken auf, und sie tauchen möglicherweise nur in den Wolken auf, und erst dann werden sie durch die Kräfte von Start-ups auf die lokalen Standorte übertragen.
Wie für SQL wird SQL leben. Dies bedeutet, dass PostgreSQL und MySQL bekannt sein müssen und Sie in der Lage sein müssen, mit ihnen zu arbeiten, aber vor allem, um sie korrekt anwenden zu können.